C++入门和基础
目录
文章目录
前言
一、C++关键字
二、命名空间
2.1 命名空间的定义
2.2 命名空间的使用
2.3 标准命名空间
三、C++输入&输出
四、缺省参数
4.1 缺省参数的概念
4.2 缺省参数的分类
五、函数重载
5.1 函数重载的简介
5.2 函数重载的分类
六、引用
6.1 引用的概念
6.2 常引用
6.3 引用使用场景
6.4 引用和指针的区别
七、内联函数
八、auto关键字(C++11)
8.1 auto的使用简介
8.2 auto的使用细则
8.3 基于范围的for循环
九、指针空值nullptr(C++11)
总结
前言
C++是一种通用的编程语言,它是C语言的扩展。C++可以进行面向对象编程,支持类、继承、多态等面向对象的特性。它还提供了一些其他的功能,如模板、异常处理、动态内存管理等。C++是一种高级语言,可以用来开发各种应用程序,包括系统软件、桌面应用、游戏、嵌入式系统等。C++具有高性能和高效的特点,广泛应用于工业界和学术界。
一、C++关键字
C++对比C语言拓展了一些关键字,这里只是简单的给出,不对关键字进行详细的介绍。
二、命名空间
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化, 以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
#include <stdio.h>
#include <stdlib.h>
int rand = 10;
// C语言没办法解决类似这样的命名冲突问题,所以C++提出了namespace来解决
int main()
{printf("%d\n", rand);return 0;
}
// 编译后后报错:error C2365: “rand”: 重定义;以前的定义是“函数”2.1 命名空间的定义
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{} 中即为命名空间的成员。
1.正常的命名空间定义
namespace hh
{// 命名空间中可以定义变量/函数/类型int rand = 10;int Add(int left, int right){return left + right;}struct Node{struct Node* next;int val;};
}2.命名空间可以嵌套
namespace N1
{int a;int b;int Add(int left, int right){return left + right;}namespace N2{int c;int d;int Sub(int left, int right){return left - right;}}
}3.同一个工程中允许存在多个相同名称的命名空间, 编译器最后会合成同一个命名空间中。
ps:下面的代码中的test.h和test.cpp中的两个N1会被合并成一个
// test.h
namespace N1
{int Mul(int left, int right){return left * right;}
}// test.cpp
namespace N1
{int a;int b;int Add(int left, int right){return left + right;}namespace N2{int c;int d;int Sub(int left, int right){return left - right;}}
}注意:一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中。
2.2 命名空间的使用
命名空间的使用有三种方式:
1.加命名空间名称及作用域限定符
namespace hh
{int a = 6;
}int main()
{int b = hh::a;return 0;
}2.使用using将命名空间中某个成员引入
namespace hh
{int a = 6;
}using hh::a;int main()
{int b = a;return 0;
}3.使用using namespace 命名空间名称引入
namespace hh
{int a = 6;
}using namespace hh;int main()
{int b = a;return 0;
}2.3 标准命名空间
在C++中,标准命名空间(Standard Namespace)是指包含了许多标准库函数、类和对象的命名空间,这些函数、类和对象是C++标准库的一部分。
标准命名空间的名称是std,它位于全局命名空间中。为了使用标准命名空间中的函数、类或对象,可以使用std::前缀加上相应的名称。
例如,使用标准命名空间中的cout和endl:
#include <iostream>int main() {std::cout << "Hello, World!" << std::endl;return 0;
}
在这个例子中,我们使用std::cout来输出字符串"Hello, World!",使用std::endl来插入一个换行符。
为了避免每次都使用std::前缀,可以使用using namespace std;语句将std命名空间引入到当前作用域中。例如:
#include <iostream>using namespace std;int main() {cout << "Hello, World!" << endl;return 0;
}
这样就可以直接使用cout和endl,而不需要加上std::前缀。
需要注意的是,使用using namespace std;可能会引起命名冲突,特别是当引入多个命名空间时。因此,最好只在需要使用大量标准库函数、类和对象时才使用using namespace std;语句,以避免潜在的命名冲突问题。
std命名空间的使用惯例:
std是C++标准库的命名空间,如何展开std使用更合理呢?
1. 在日常练习中,建议直接using namespace std即可,这样就很方便。
2. using namespace std展开,标准库就全部暴露出来了,如果我们定义跟库重名的类型/对象/函数,就存在冲突问题。该问题在日常练习中很少出现,但是项目开发中代码较多、规模大,就很容易出现。所以建议在项目开发中使用,像std::cout这样使用时指定命名空间 + using std::cout展开常用的库对象/类型等方式。
三、C++输入&输出
在C++中,可以使用标准库中的iostream头文件来进行输入输出操作。
#include<iostream>
using namespace std;
int main()
{cout << "Hello world!!!" << endl;return 0;
}说明:
- 使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件以及按命名空间使用方法使用std。
- cout和cin是全局的流对象,endl是特殊的C++符号,表示换行输出,他们都包含在包含<iostream >头文件中。
- << 是流插入运算符, >> 是流提取运算符。
- 使用C++输入输出更方便,不需要像printf / scanf输入输出时那样,需要手动控制格式。C++的输入输出可以自动识别变量类型。
- 实际上cout和cin分别是ostream和istream类型的对象, >> 和 << 也涉及运算符重载等知识,但这里只是简单学习他们的使用。
#include <iostream>
using namespace std;
int main()
{int a;double b;char c;// 可以自动识别变量的类型cin >> a;cin >> b >> c;cout << a << endl;cout << b << " " << c << endl;return 0;
}ps:关于cout和cin还有很多更复杂的用法,比如控制浮点数输出精度,控制整形输出进制格式等等。因为C++兼容C语言的用法,这些又用得不是很多,我们这里就不展开讲解了。
四、缺省参数
4.1 缺省参数的概念
在C++中,缺省参数(Default Arguments)允许我们在函数声明或定义时为参数提供默认值。这意味着在调用函数时,如果没有为这些参数提供实际的值,则会使用默认值。
使用缺省参数可以使函数调用更加简洁,可以省略一些常用的参数,同时还能提供一些默认行为。
下面是一个使用缺省参数的函数示例:
void Func(int a = 0)
{cout << a << endl;
}int main()
{Func(); // 没有传参时,使用参数的默认值Func(10); // 传参时,使用指定的实参return 0;
}4.2 缺省参数的分类
- 全缺省参数
void Func(int a = 10, int b = 20, int c = 30)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl << endl;
}int main()
{Func(1, 2, 3);Func(1, 2);Func(1);Func();return 0;
}- 半缺省参数
void Func(int a, int b = 20, int c = 30)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl << endl;
}int main()
{Func(1, 2, 3);Func(1, 2);Func(1);return 0;
}注意:
- 半缺省参数必须从右往左依次来给出,不能间隔着给
- 缺省参数不能在函数声明和定义中同时出现,如果声明和定义分明,则应该在声明处给出
- 缺省值必须是常量或者全局变量
五、函数重载
5.1 函数重载的简介
在C++中,函数重载(Function Overloading)是指在同一个作用域内定义多个具有相同名称但参数列表不同的函数。这允许我们使用相同的函数名来执行不同的操作,根据函数参数的个数、类型或顺序的不同来选择正确的函数调用。
函数重载的特点如下:
- 函数名称相同,但参数列表不同。
- 参数列表可以有不同的类型、个数和顺序。
- 如果两个函数函数名和参数是一样的,返回值不同是不构成重载的,因为调用时编译器没办法区分。
需要注意的是,函数重载是在编译期间由编译器进行解析,而不是在运行时。编译器根据函数调用中传递的参数类型、个数和顺序来选择正确的函数。如果没有找到与函数调用匹配的函数,将会发生编译错误。
函数重载可以提高代码的可读性和可维护性,可以为不同的数据类型或参数组合提供适用的函数实现。但是在函数重载时,需要注意避免产生二义性的情况,即避免出现多个函数重载的参数列表相互之间存在模糊的匹配关系。
5.2 函数重载的分类
1.参数类型不同
int Add(int left, int right)
{cout << "int Add(int left, int right)" << endl;return left + right;
}double Add(double left, double right)
{cout << "double Add(double left, double right)" << endl;return left + right;
}2.参数个数不同
void f()
{cout << "f()" << endl;
}void f(int a)
{cout << "f(int a)" << endl;
}3.参数类型顺序不同(本质还是类型不同)
void f(int a, char b)
{cout << "f(int a,char b)" << endl;
}void f(char b, int a)
{cout << "f(char b, int a)" << endl;
}六、引用
6.1 引用的概念
在C++中,引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。通过引用,可以使用不同的名称访问同一个对象或函数,而不需要拷贝对象本身。引用提供了一种方便且高效的访问变量或函数的方式。引用在函数调用中可以做参数也可以做返回值。
引用语法:
类型 & 引用变量名 ( 对象名 ) = 引用实体;
void TestRef()
{int a = 10;int& ra = a; // 定义引用类型printf("%p\n", &a);printf("%p\n", &ra);
}引用的特性:
- 引用在定义时必须初始化
- 一个变量可以有多个引用
- 引用一旦引用一个实体,再不能引用其他实体
void TestRef()
{int a = 10;// int& ra; // 该条语句编译时会出错int& ra = a;int& rra = a;printf("%p %p %p\n", &a, &ra, &rra);
}6.2 常引用
常引用是指在声明引用时,使用const关键字限定引用所绑定的对象不能被修改。常引用提供了一种只读访问对象的方式,防止意外修改对象的值。常引用常常用于函数参数传递,可以防止函数内部对传递的对象进行修改。
void print(const int& num)
{// 使用常引用作为函数参数std::cout << num << std::endl;
}int main()
{int num = 10;const int& ref1 = num; // 常引用,绑定到非常对象numint num2 = 20;const int& ref2 = num2; // 常引用,绑定到非常对象num2const int constant = 30;const int& ref3 = constant; // 常引用,绑定到常对象constant// ref1 = 15; // 错误,常引用不允许修改所绑定的对象的值// ref2 = 25; // 错误,常引用不允许修改所绑定的对象的值const int& value = ref1 + ref3; // ref1 + ref3表达式的返回值是临时对象,临时对象具有常性std::cout << value << std::endl;print(10); // 通过常引用访问num的值print(num2); // 通过常引用访问num2的值print(constant); // 通过常引用访问constant的值return 0;
}6.3 引用使用场景
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。所以,我们可以使用引用来做参数和返回值。
1.做参数(a、输出型参数 b、对象比较大,减少拷贝,提高效率)这些效果,指针也可以,但是引用更方便,下面是输出型参数的例子:
void Swap(int& left, int& right)
{int temp = left;left = right;right = temp;
}做参数时传值和传引用的效率比较:
#include<iostream>
#include <time.h>
using namespace std;struct A
{int a[10000] = { 0 };
};void TestFunc1(A a) {}
void TestFunc2(A& a) {}
int main()
{A a;// 以值作为函数参数size_t begin1 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc1(a);size_t end1 = clock();// 以引用作为函数参数size_t begin2 = clock();for (size_t i = 0; i < 10000; ++i)TestFunc2(a);size_t end2 = clock();// 分别计算两个函数运行结束后的时间cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;return 0;
}2.做返回值(a、修改返回对象 b、减少拷贝提高效率)
int& Count()
{static int n = 0;n++;// ...return n;
}做参数时传值和传引用的效率比较:
#include<iostream>
#include <time.h>
using namespace std;struct A { int a[10000]; };
A a;
// 值返回
A TestFunc1() { return a; }
// 引用返回
A& TestFunc2() { return a; }int main()
{// 以值作为函数的返回值类型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();size_t end1 = clock();// 以引用作为函数的返回值类型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 计算两个函数运算完成之后的时间cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;return 0;
}注意:如果函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用引用返回,如果已经还给系统了,则必须使用传值返回。下面是一个错误示范:
// 错误示范
int& func()
{int a = 0;return a;
}int& fx()
{int b = 100;return b;
}int main()
{int& ret = func();cout << ret << endl;fx();cout << ret << endl;return 0;
}6.4 引用和指针的区别
在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。
int main()
{int a = 10;int& ra = a; //语法不开空间,底层开空间ra = 20;int* pa = &a; //语法开空间,底层开空间*pa = 20;return 0;
}我们来看下引用和指针的汇编代码对比:

引用和指针的不同点:
- 引用概念上定义一个变量的别名,指针存储一个变量地址。
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全
七、内联函数
内联函数(Inline Functions)是一种特殊类型的函数,在C++中使用关键字inline来声明。内联函数的特点是在每个调用点上将函数的代码插入到调用点上,而不是通过函数调用的方式进行执行。这样可以减少函数调用的开销,提高程序的执行效率。
内联函数的使用场景是在函数体相对简短的情况下,例如只有几行代码的函数,或者函数频繁被调用的情况下。内联函数一般适用于对函数调用时间敏感的场景,可以减少函数调用的开销,提高程序的执行速度。
下面是一个简单的内联函数的示例:
#include <iostream>// 声明内联函数
inline int add(int a, int b) {return a + b;
}int main() {int result = add(3, 4);std::cout << "Result: " << result << std::endl; // 输出: Result: 7return 0;
}
在上面的例子中,我们使用inline关键字声明了一个名为add的内联函数。这个函数只有一行代码,将两个整数相加并返回结果。在main函数中,我们直接调用了内联函数add,而不是通过函数调用的方式进行执行。
需要注意的是,内联函数只是对编译器的建议,并不是强制性要求。编译器会根据自身的策略来决定是否将函数作为内联函数来实现。如果函数体过于复杂或函数体内有循环、递归等不适合内联的情况,编译器可能会忽略inline关键字,将函数按照普通函数的方式进行调用。
此外,使用内联函数时需要注意以下几点:
- 内联函数通常适用于函数体简短的情况。
- 内联函数的定义通常放在头文件中,以便能够在使用时进行内联展开。
- 内联函数的编译产生的代码体积可能会增大,因为函数的代码被插入到每个调用点上。
- 内联函数的使用可以提高程序的执行效率,但也可能导致可执行文件的体积增大。
- 内联函数不能递归调用自身。
- inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到
总的来说,内联函数是一种用于提高程序执行效率的机制,适用于函数体较短且被频繁调用的情况。使用内联函数可以减少函数调用的开销,提高程序的执行速度。
八、auto关键字(C++11)
8.1 auto的使用简介
在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,但遗憾的 是一直没有人去使用它,大家可思考下为什么?
C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一 个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
为了避免与C++98中的auto发生混淆,C++11只保留了auto作为类型指示符的用法。
int TestAuto()
{return 10;
}int main()
{int a = 10;auto b = a;auto c = 'a';auto d = TestAuto();cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;cout << typeid(d).name() << endl;//auto e; 无法通过编译,使用auto定义变量时必须对其进行初始化return 0;
}【注意】
使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto 的实际类型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编 译期会将auto替换为变量实际的类型。
8.2 auto的使用细则
1. auto与指针和引用结合起来使用
用auto声明指针类型时,用auto和auto* 没有任何区别,但用auto声明引用类型时则必须加&
int main()
{int x = 10;auto a = &x;auto* b = &x;auto& c = x;cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;*a = 20;*b = 30;c = 40;return 0;
}2.在同一行定义多个变量
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
void TestAuto()
{auto a = 1, b = 2;auto c = 3, d = 4.0; // 该行代码会编译失败,因为c和d的初始化表达式类型不同
}3.auto不能作为函数的参数
// 此处代码编译失败,auto不能作为形参类型,因为编译器无法对a的实际类型进行推导
void TestAuto(auto a)
{}4.auto不能直接用来声明数组
// 编译失败
void TestAuto()
{int a[] = { 1,2,3 };auto b[] = { 4,5,6 };
}8.3 基于范围的for循环
对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此C++11中引入了基于范围的for循环。for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。
void TestFor()
{int array[] = { 1, 2, 3, 4, 5 };for (auto& e : array)e *= 2;for (auto e : array)cout << e << " ";
}注意:与普通循环类似,可以用continue来结束本次循环,也可以用break来跳出整个循环。
九、指针空值nullptr(C++11)
在良好的C / C++编程习惯中,声明一个变量时最好给该变量一个合适的初始值,否则可能会出现
不可预料的错误,比如未初始化的指针。如果一个指针没有合法的指向,我们基本都是按照如下
方式对其进行初始化:
void TestPtr()
{int* p1 = NULL;int* p2 = 0;// ……
}NULL实际是一个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:
#ifndef NULL#ifdef __cplusplus#define NULL 0#else#define NULL ((void *)0)#endif
#endif可以看到,C++中NULL被定义为字面常量0,这使在使用空值的指针时,不可避免的会遇到一些麻烦,比如:
void f(int)
{cout << "f(int)" << endl;
}void f(int*)
{cout << "f(int*)" << endl;
}int main()
{f(0);f(NULL);f((int*)NULL);return 0;
}程序本意是想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL被定义成0,因此与程序的初衷相悖,如果这里要使用NULL,就只能将NULL强转为(int*)。
在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器默认情况下将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void*)0。
注意:
- 在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的。
- 在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。
- 为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
总结
C++作为一种广泛应用的编程语言,具有强大的功能和高效的性能。无论您是编程初学者还是有一定经验的开发者,掌握C++基础知识都能为您的编程之旅打下坚实基础。通过本文的学习,您将能够掌握C++的入门知识,帮助您迅速上手并建立起编程信心。
相关文章:
C++入门和基础
目录 文章目录 前言 一、C关键字 二、命名空间 2.1 命名空间的定义 2.2 命名空间的使用 2.3 标准命名空间 三、C输入&输出 四、缺省参数 4.1 缺省参数的概念 4.2 缺省参数的分类 五、函数重载 5.1 函数重载的简介 5.2 函数重载的分类 六、引用 6.1 引用的…...
一些C语言知识
C语言的内置类型: char short int long float double C99中引入了bool类型,用来表示真假的变量类型,包含true,false。 这个代码的执行结果是什么?好好想想哦,坑挺多的。 #include <stdio.h>int mai…...
代码工具APEX的入门使用(未包含安装)
第一次使用APEX是2019年,这个技术成名已久只是我了解的比较晚。请看Oracle ACE的网站,这就是用APEX做的。实际上有一次我看O记的人操作他们的办公流程,都是用APEX做的。 那一年,我用APEX做了一个CMDB的管理系统。那时候还没有流行…...
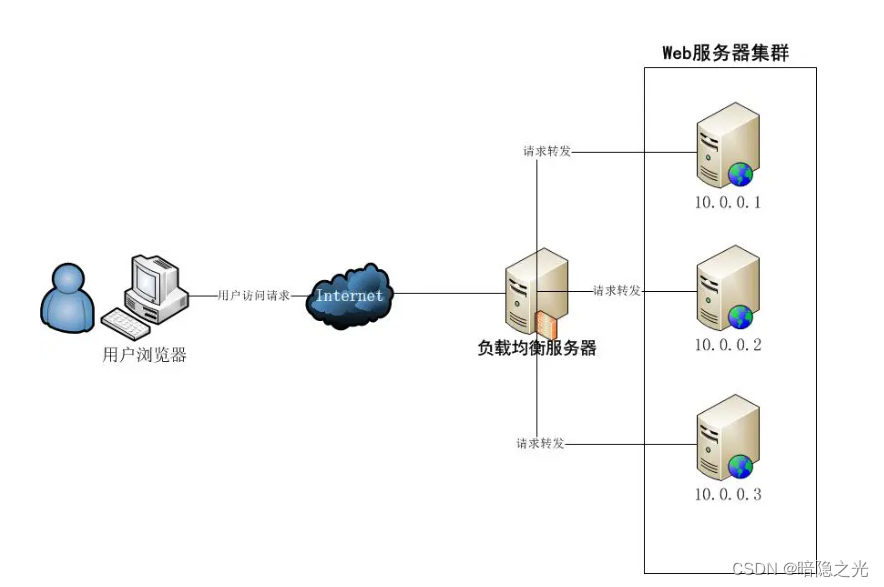
负载均衡.
简介: 将请求/数据【均匀】分摊到多个操作单元上执行,负载均衡的关键在于【均匀】。 负载均衡的分类: 网络通信分类 四层负载均衡:基于 IP 地址和端口进行请求的转发。七层负载均衡:根据访问用户的 HTTP 请求头、URL 信息将请求转发到特定的主机。 载体维度分类 硬…...

Git 指令深入浅出【2】—— 分支管理
Git 指令深入浅出【2】—— 分支管理 分支管理1. 常用分支管理指令2. 合并分支合并冲突合并模式 3. 实战演习 分支管理 1. 常用分支管理指令 # 查看本地分支 git branch# 查看远程分支 git branch -r# 查看全部分支 git branch -aHEAD 指向的才是当前的工作分支 # 查看当前分…...

工作流/任务卸载相关开源论文分享
decima-sim 概述: 图神经网络强化学习处理多工作流 用的spark的仿真环境,mit的论文,价值很高,高被引:663仓库地址:https://github.com/hongzimao/decima-sim论文:https://web.mit.edu/decima/co…...

为什么要用Python?
为什么要用Python? Python简单易用:提供大量的简单易用数据结构和内置库,语法结构也很简单易读,不需要使用括号来进行代码块分组,也不需要预声明变量或参数。Python开发效率高:简单易用的前提下࿰…...

北京大学发布,将试错引入大模型代理学习!
引言:探索语言智能的新边界 在人工智能的发展历程中,语言智能始终是一个核心的研究领域。随着大语言模型(LLM)的兴起,我们对语言智能的理解和应用已经迈入了一个新的阶段。这些模型不仅能够理解和生成自然语言&#x…...

Java 设计模式
编程设计模式六大原则 开闭原则(Open Close Principle):对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代码,实现一个热插拔的效果。简言之,是为了使程序的扩展性好&#…...

Kivy和BeeWare 开发APP的优缺点,及其发展历史
Kivy和BeeWare都是流行的Python框架,用于开发移动应用。它们各自有独特的特点和优势,同时也面临一些挑战和限制。下面是对这两个框架的开发优缺点及其发展历史的总结。 Kivy 发展历史 起源:Kivy诞生于2010年,旨在提供一个用于P…...

C++递推
统计每个月兔子的总数 #include<bits/stdc.h> using namespace std; int n,sum0; void f(int); int main() {int a[1000];cin>>n;a[1]1;a[2]2;for(int i3;i<1000;i){a[i]a[i-1]a[i-2];}cout<<a[n];return 0; } void f(int n){}猴子吃桃子 #include<b…...

C++ 面试题
一、基础语法 1. C 和 C的区别 i. C是面向对象的的编程语言,C是面向过程的编程语言 ii. C中的内存分配运算符是new/delete而C 中是malloc和free iii. C中有函数重载而C 中没有 iv. C中新增了引用的概念而C 中只有值和指针 2. struct 和 class的区别 i. struc…...
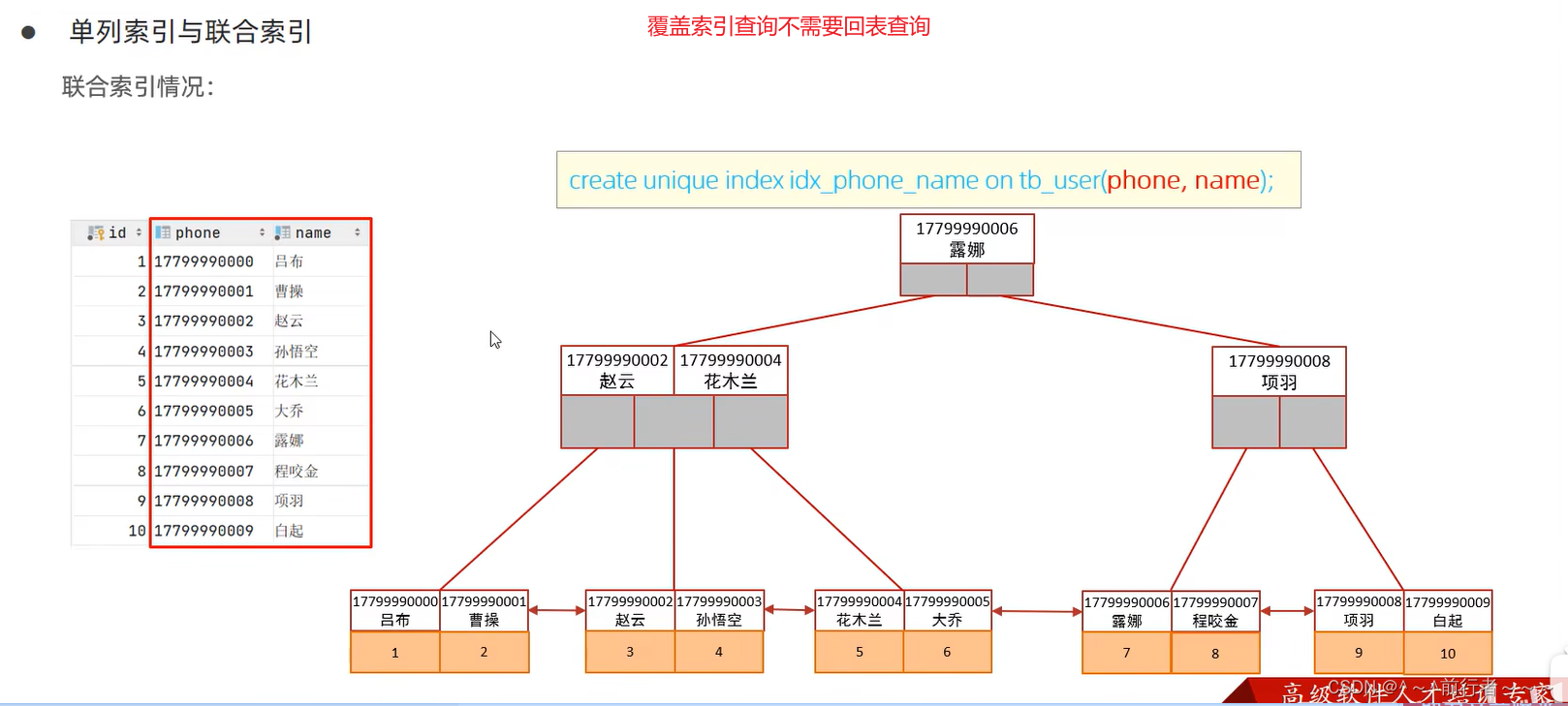
MySQL之索引详解
华子目录 索引概述优缺点 索引的原理索引的设计原则索引结构B-tree(多路平衡查找树)BtreeHash 为什么InnoDB存储引擎选择Btree?索引分类聚集索引选取规则 单列索引和多列索引前缀索引创建索引1.创建表时创建索引2.在已经存在的表上创建索引3.…...
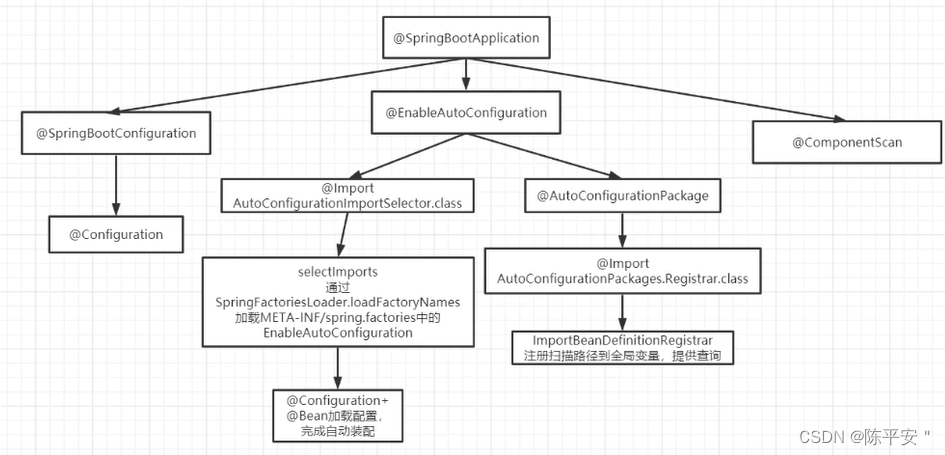
Java面试题总结8:springboot
Spring Boot自动配置原理 importConfigurationSpring spi 自动配置类由各个starter提供,使用ConfigurationBean定义配置类,放到META-INF/spring.factories下 使用Spring spi扫描META-INF/Spring.factories下的配置类 如何理解Spring Boot中Starter …...

Android 4.4 以下,OkHttp访问Https报错,设置了sslSocketFactory仍无效的解决方法
背景 Android 4.4 及以下,使用 OkHttp 发送 Https 请求,报以下错误: javax.net.ssl.SSLHandshakeException: javax.net.ssl.SSLProtocolException: SSL handshake aborted: ssl0x6b712c90: Failure in SSL library, usually a protocol erro…...
如何扫码查看企业介绍及填写招聘表?招聘二维码在线生成的方法
现在很多企业会通过生成二维码的方式来做企业介绍以及企业招聘,企业信息通过图片、文字、视频及其他内容展示,再创建合适的表单让扫码者按照制定的内容来填写对应的信息,从而完成扫码招聘的目的。 对于也想采用这种方式的小伙伴,…...

如何限制一个账号只在一处登陆
大家好,我是广漂程序员DevinRock! 1. 需求分析 前阵子,和问答群里一个前端朋友,随便唠了唠。期间他问了我一个问题,让我印象深刻。 他问的是,限制同一账号只能在一处设备上登录,是如何实现的…...

日常工作总结
日常工作总结 1000. JAVA基础1. 泛型1.1 泛型和Object的区别 1100. Spring1. 常用注解1.1 ControllerAdvice注解1.2 缓存Cacheable 2. 常用方法2.1 BeanUtils.copyProperties的用法 3. 常用功能组件3.1 过滤器Filter 2000. Linux应用 1000. JAVA基础 1. 泛型 1.1 泛型和Objec…...
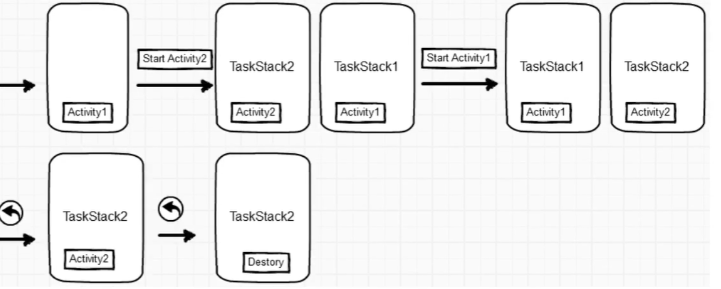
Android Activity启动模式
文章目录 Android Activity启动模式概述四种启动模式Intent标记二者区别 Android Activity启动模式 概述 Activity 的管理方式是任务栈。栈是先进后出的结构。 四种启动模式 启动模式说明适用场景standard标准模式默认模式,每次启动Activity都会创建一个新的Act…...

【JavaScript】面试手撕防抖
引入 防抖可是前端面试时最频繁考察的知识点了,首先,我们先了解防抖的概念是什么。咳咳。👀 防抖: 首先它是常见的性能优化技术,主要用于处理频繁触发的浏览器事件,如窗口大小变化、滚动事件、输入框内容…...

装上这个技能,让你的 OpenClaw 和 Hermes 变身私人旅行规划师
一句话说清楚给小龙虾和马装上 Voyago,以后你只需要说"帮我规划杭州两天一夜",它就会自动帮你查火车票、搜机票、找酒店、查门票、规划路线、搜小红书攻略、算预算,最终输出一份万字级的完整旅行方案——精确到每两个地点之间坐几号…...

从LR寄存器到问题函数:一次完整的Cortex-M HardFault调试实录与内存分析心得
从LR寄存器到问题函数:一次完整的Cortex-M HardFault调试实录与内存分析心得 引言:当MCU突然"罢工"时 那是一个周五的深夜,产品量产前的最后一周。测试工程师突然报告设备在特定操作序列下会无规律死机,串口日志最后一行…...

CentOS 7下Nginx集成SM2国密证书的完整实践指南
1. 为什么SM2证书在CentOS 7上配Nginx不是“装个包就能用”的事?你刚接到一个政务系统对接需求,对方明确要求必须使用国密SM2证书,且服务器环境锁定为CentOS 7。你信心满满地打开终端,yum install nginx,再把SM2证书丢…...

别再为Tesseract中文识别报错发愁了!手把手教你搞定chi_sim语言包和环境变量配置
Tesseract中文识别实战:从报错排查到精准配置的全流程指南 当你在终端兴奋地输入第一行Tesseract命令,却看到刺眼的Failed loading language chi_sim报错时,那种挫败感我深有体会。这个看似简单的错误背后,往往隐藏着路径配置、文…...

【NotebookLM效应量计算实战指南】:20年统计学专家亲授3大避坑法则与5步精准计算流程
更多请点击: https://kaifayun.com 第一章:NotebookLM效应量计算的核心概念与适用场景 NotebookLM 是 Google 推出的基于用户上传文档进行语义理解与推理的实验性 AI 工具。其“效应量计算”并非内置统计模块,而是指用户在利用 NotebookLM 对…...

JEECG AI应用平台深度解析:业内唯一 JAVA 版开源 AI 应用平台,如何成为企业级 Dify 替代方案
JeecgBoot AI专题研究 | JEECG AI应用平台的能力全景、对比 Dify 的差异化优势与企业落地实践 为什么企业需要一个「长在业务里」的 AI 应用平台 过去两年,几乎每家公司都在尝试把大模型接进自己的系统。最常见的路径是搭一套 Dify、FastGPT 之类的 LLM 应用平台&a…...

注意力的几何本质:一个空间与两个算子的统一框架
1. 项目概述:这不是又一篇讲Attention机制的“科普文”如果你最近翻过几篇顶会论文,或者在GitHub上扫过几个热门Transformer库的源码,大概率会在某个角落撞见“The Geometry of Attention: One Space, Two Operators”这个标题。它不像“Atte…...
完整技术方案:以字序生命模型(WOLM)为认知内核的双脑协同架构)
通用人工智能(AGI)完整技术方案:以字序生命模型(WOLM)为认知内核的双脑协同架构
一、AGI的终极定义在讨论技术方案之前,先定义什么是AGI。当前主流的AGI定义,强调一个系统能在绝大多数人类能做的智力任务上达到或超越人类水平。这个定义隐含了一个假设:AGI的核心是“智力”——逻辑推理、知识储备、创造力。我们的定义不同…...

通过curl命令快速测试Taotoken平台API连通性与模型列表
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken平台API连通性与模型列表 基础教程类,本文面向需要快速验证环境或进行排错的开发者&…...

Image2.0生成的PPT图片转换成可编辑的PPT的一种方法
老弟,PPT不想做,用AI生成的PPT图片编辑不了很烦恼是吧,俺有一法!~ Edit Banana(最强,开源免费) 能把 AI 图→可编辑 PPTX / DrawIO / SVG 原理:用 SAM 分割图标 / 形状,用…...