分布式数据库中全局自增序列的实现
自增序列广泛使用于数据库的开发和设计中,用于生产唯一主键、日志流水号等唯一ID的场景。传统数据库中使用Sequence和自增列的方式实现自增序列的功能,在分布式数据库中兼容Oracle和MySQL等传统数据库语法,也是基于Sequence和自增列的方式实现分布式架构下的全局唯一ID。本文简要介绍了传统数据库和分布式数据库的自增序列实现方式,并且突出NOCYCLE非循环使用的自增序列在监控上的策略。
1、传统数据库的自增序列实现
在关系型数据库的开发过程中,自增序列或自增列使用场景非常广泛,可以生成唯一ID作为主键、生成唯一标识符,也可以生成顺序编号如交易流水号、订单编号等。因此在传统的Oracle、DB2和MySQL等数据库中通过Sequence这一特殊的数据库对象或者自增列的方式实现自增序列,满足应用开发中唯一ID的需求和性能要求。
1.1 Sequence对象实现
1.1.1 Oracle数据库
Sequence是Oracle数据库中的特殊的数据库对象,用于生成唯一的序列。Oracle数据库中创建Sequence语法如下:
CREATE SEQUENCE sequence_name START WITH start_value INCREMENT BY increment_value [NO MAXVALUE] | [MAXVALUE max_value] [NO MINVALUE] | [MINVALUE min_value] [CACHE cache_value] [NO ORDER] | [ORDER] [CYCLE] | [NO CYCLE]
[RESET ON START] | [NO RESET ON START];
相关参数如下:
- sequence_name:Sequence的名称。
- START WITH start_value:指定Sequence的起始值。
- INCREMENT BY increment_value:指定每次调用Sequence时数值的增量。
- MAXVALUE max_value和MINVALUE min_value:指定Sequence的最大值和最小值。
- CACHE cache_value:指定预先生成的数值数量并存储在内存中以提高性能。
- NO ORDER和ORDER:指定Sequence值是否按请求顺序生成。
- CYCLE和NO CYCLE:指定当Sequence达到最大值或最小值后是否重新开始。
- RESET ON START 和 NO RESET ON START:指定在数据库重启后是否重置Sequence值。
注意CYCLE和NO CYCLE定义,指定自增列是否定义为循环使用。
2)Sequence的使用
Oracle中使用CURRVAL和NEXTVAL获取序列的当前值和下一个值,如下所示:
##获取当前值
select 序列名称.currval from dual
##获取下一个值
select 序列名称.nextval from dual
Sequence在使用上主要包括以下,对于一些子查询、关联查询或者GROUP BY/ORDER BY语句中是不可以使用sequence的:
- INSERT的VALUES子句、子查询
- 不包含子查询、snapshot、视图的SELECT语句中的列表
- UPDATE的SET子句
需要注意的是同个Sequence有多个用户并发使用时,每个用户只能获取一次Sequence的下一个值。如果需要确保并发访问时的唯一性,需要使用数据库锁或其他机制来控制并发访问。
1.1.2 DB2数据库
DB2数据库中sequence对象出现之前最早是Identify列(类似自增列的概念),后来为解决自增列的一些问题及合入其它功能,引入Sequence。创建Sequence语法与Oracle类似:
CREATE SEQUENCE sequence_name START WITH start_value INCREMENT BY increment_value [NO MAXVALUE] | [MAXVALUE max_value] [NO MINVALUE] | [MINVALUE min_value] [CACHE cache_value] [NO ORDER] | [ORDER] [CYCLE] | [NO CYCLE]
[RESET ON START] | [NO RESET ON START];
相关参数如下:
- sequence_name:Sequence的名称。
- START WITH start_value:指定Sequence的起始值。
- INCREMENT BY increment_value:指定每次调用Sequence时数值的增量。
- MAXVALUE max_value和MINVALUE min_value:指定Sequence的最大值和最小值。
- CACHE cache_value:指定预先生成的数值数量并存储在内存中以提高性能。
- NO ORDER和ORDER:指定Sequence值是否按请求顺序生成。
- CYCLE和NO CYCLE:指定当Sequence达到最大值或最小值后是否重新开始。
- RESET ON START 和 NO RESET ON START:指定在数据库重启后是否重置Sequence值。
创建好Sequence后,可以在SQL语句中使用sequence,如INSERT语句中插入自增序列值、select语句中查询自增值。
1)在INSERT语句中使用NEXTVAL FOR来获取Sequence的下一个值,并将其插入到表的相应列中
INSERT INTO USER(USER_ID, USER_NAME) VALUES(NEXTVAL FOR SEQ_USER_ID, 'username1');
2)通过查询Sequence来获取其当前值或下一个值
SELECT NEXTVAL FOR SEQ_USER_ID FROM SYSIBM.SYSDUMMY1;
1.2 自增列实现
1.2.1 Oracle数据库
Oracle数据库本身并不直接支持自增列(类似MySQL中的AUTO_INCREMENT)的创建,其提供了触发器结合Sequence来实现类似的功能。在创建了Sequence以后,创建一个BEFORE INSERT触发器,该触发器会在每次插入新行之前从序列中获取下一个值,并将其设置为自增列的值。
CREATE OR REPLACE TRIGGER trg_my_table_before_insert
BEFORE INSERT ON my_table
FOR EACH ROW
BEGIN SELECT seq_name.NEXTVAL INTO :new.id FROM dual;
END;
/
当插入数据时,不需要指定自增列的值,触发器会自动创建自增的序列值。
1.2.2 DB2数据库
DB2数据库在引入Sequence之前是使用identify列实现自增列,语法如下:
CREATE TABLE table_name ( column1 datatype [constraint], column2 datatype [constraint], identity_column datatype GENERATED ALWAYS AS IDENTITY ( START WITH start_value INCREMENT BY increment_value [NO MAXVALUE] | [MAXVALUE max_value] [NO MINVALUE] | [MINVALUE min_value] [CACHE cache_value] [CYCLE] | [NO CYCLE] ), ...
);
其中GENERATED ALWAYS AS IDENTITY指定该列为自增列。可以看到DB2中的自增列是在创建表时直接定义的,而不是在表创建后单独添加。此外,自增列只能用于表的主键,且每个表只能有一个自增列。和Sequence相比,自增列在使用上有限制,只能定义在单表上,另外对自增列的更改将导致表空间被置为Reorg-pending状态。
1.2.3 MySQL数据库
在MySQL数据库中没有Sequence这个数据库对象,但是通过为表的某一列设置AUTO_INCREMENT属性来创建一个自增列,并且通常作为主键。如下所示,在创建表时,在id列指定AUTO_INCREMENT属性,每次插入新行时,这一列的值就会自动递增。
CREATE TABLE t1 ( id INT NOT NULL AUTO_INCREMENT, c1 VARCHAR(50) NOT NULL, PRIMARY KEY (id)
);
另外在MySQL中有一些系统变量定义了自增列的属性:
mysql> show vaiables like 'AUTO_INCREMENT%'
+----------------------------------+-------+
| Variable_name | Value |
+----------------------------------+-------+
| auto_increment_increment | 1 |
| auto_increment_offset | 1 |
| auto_increment_wrap | 0 |
| auto_increment_for_each_replica | OFF |
+----------------------------------+-------+
相关参数解释如下:
- auto_increment_increment:控制自增列每次递增的量。默认值为1,意味着每次插入新行时自增列的值增加1。
- auto_increment_offset:在复制环境中,用于设置自增列的起始偏移量,以避免在多个服务器上生成相同的自增ID。默认值为1。
- auto_increment_wrap:当设置为非零值时,自增列的值会在达到最大值后回绕到最小值。这通常用于循环使用自增ID的场景。默认值为0,表示不启用回绕。相当于Sequence定义中的Cycle和Nocycle。
- auto_increment_for_each_replica: 在MySQL 8.0及更高版本中,当设置为ON时,每个复制从服务器将独立生成自增ID。这有助于避免在多个从服务器上生成相同的自增ID。默认值为OFF。
另外在mysql中多并发申请自增列时通过innodb_autoinc_lock_mode参数控制在插入新记录时如何锁定自增计数器,这个参数影响在并发插入操作中的性能和锁争用。
- 0 (TRADITIONAL):这是传统的锁定模式。在每次插入操作中,InnoDB 会对自增计数器进行锁定,以确保生成的自增 ID 是唯一的。这种模式下,并发插入可能会受到严重的限制,因为每次插入都需要等待前一个插入操作完成并释放锁。
- 1 (CONSECUTIVE):在这种模式下,InnoDB 会尝试在单个事务中预先分配多个自增 ID,然后逐个使用它们。这样可以减少锁定的次数,从而提高并发插入的性能。但是,如果事务被回滚,那么预先分配但未使用的 ID 会被浪费。
- 2 (INTERLEAVED):这是MySQL 5.6引入的新模式。在这种模式下,InnoDB会根据实际需要动态地选择是否预先分配多个自增 ID。这结合了前两种模式的优点,试图在并发性和ID浪费之间找到一个平衡点。
默认情况下是1,innodb_autoinc_lock_mode参数的修改要重启mysql实例才能生效。
1.3 Sequence和自增列对比
从上文中可以看到在传统数据库中自增序列的实现有两种方式:sequence和自增列,那么二者在使用上有哪些不同之处?如下表所示:

最主要的区别是Sequence是数据库中的对象,可以创建、修改和删除、授权等操作,并且在使用上更为灵活。
2、分布式数据库中自增序列实现
上文看到在传统数据库Oracle、DB2和MySQL中对自增序列的支持,当然在国产分布式数据库中对传统数据库语法的兼容,也支持通过Sequence对象和自增列的方式实现自增序列。不过与传统集中数据库不同之处是,分布式数据库中如何保证自增序列在分布式架构下的全局自增。
2.1 OceanBase数据库
OceanBase数据库中支持创建sequence对象和自增列两种方式实现自增序列。
1)Sequence实现
使用CREATE SEQUENCE语句可以创建sequence对象,语法如下:
CREATE SEQUENCE [ IF NOT EXISTS ] [ schema. ] sequence_name
{ START WITH int_value
|[ INCREMENT BY int_value ]
|[ MINVALUE int_value | NOMINVALUE ]
|[ MAXVALUE int_value | NOMAXVALUE ]
|[ CACHE int_value | NOCACHE ]
|[ ORDER | NOORDER ]
|[ CYCLE | NOCYCLE ]
}
;
语法上和传统数据库没有什么区别。创建序列后,可以在SQL语句中使用CURRVAL伪列返回序列当前值或使用NEXTVAL伪列返回递增的新值。
- Cache指在内存中预分配的自增值个数,默认为20
- CYCLE/NOCYCLE:CYCLE为默认值,指定序列在达到其最大值或最小值后无法生成更多值。
2)自增列AUTO_INCRREMENT
OceanBase作为分布式数据库,兼容MySQL的自增列特性,不同的是在分布式多实例的场景下自增列生成会出现跳变。
CREATE TABLE t1(id bigint not null auto_increment primary key,
c1 varchar(50));
Query OK, 0 rows affected
在OceanBase数据库V4.x版本开始新增了ORDER模式的自增列,以避免NOORDER模式中多机多分区生成自增值和通过INSERT语句插入指定的最大值等比较常用的使用场景下发生自增值跳变的问题。

ORDER模式的自增列会在所有OBServer节点中选取当前集群的Leader作为自增列服务的Leader,其它作为Follower的OBServer节点需要通过发送RPC请求来从作为Leader的OBServer节点处申请自增值,而作为Leader的OBServer节点会从内部表申请自增区间来作为自增缓存。
因此,在大部分场景下和单机MySQL一样可以生成连续的全局自增序列,但是在大并发场景下,ORDER模式的性能会较差。并且在Leader节点重启或宕机、切主等极端情况下,仍然会出现自增值的跳变情况。为了避免切主场景下出现自增值跳变的问题,发生切主的时候会将将原Leader的OBServer节点上的缓存区间清理掉。
2.2 TiDB数据库
1)Sequence使用
TiDB数据库v4.0版本开始支持序列功能,具体语法如下:
CREATE [TEMPORARY] SEQUENCE [IF NOT EXISTS] sequence_name[ INCREMENT [ BY | = ] increment ][ MINVALUE [=] minvalue | NO MINVALUE | NOMINVALUE ][ MAXVALUE [=] maxvalue | NO MAXVALUE | NOMAXVALUE ][ START [ WITH | = ] start ][ CACHE [=] cache | NOCACHE | NO CACHE][ CYCLE | NOCYCLE | NO CYCLE][table_options]
- Cache:指定每个TIDB实例本地缓存的大小,默认是1000
- CYCLE/COCYCLE:指定序列用完之后是否循环使用
定义完Sequence后,可以通过NEXTVAL、LASTVAL获取下一个序列值和上一次使用的序列值,SETVAL可以设置序列的增长返回一个满足增长值的序列值。
SELECT nextval(seq);
SELECT lastval(seq);
SELECT setval(seq, 10);
2)自增列auto_increment
TiDB中兼容MySQL数据库的auto_increment特性,在v6.4.0版本之前TiDB数据库和OceanBase一样存在自增值跳变的问题,v6.4.0版本之后支持在所有TiDB实例上全局单调自增。建表时候创建自增列语法如下:
CREATE TABLE t(id int PRIMARY KEY AUTO_INCREMENT, c int);
TiDB 在v6.4.0版本实现了中心化分配自增ID的服务,当前中心化分配服务内置在TiDB进程,类似于DDL Owner的工作模式。其中有一个TiDB实例将充当“主”的角色提供ID分配服务,而其它的TiDB实例将充当“备”角色。当“主”节点发生故障时,会自动进行“主备切换”,从而保证中心化服务的高可用。
在建表时将AUTO_ID_CACHE设置为1,表示使用MySQL兼容模式,该模式下能保证ID唯一、单调递增,行为几乎跟MySQL完全一致。只有当中心化服务的“主”TiDB实例异常崩溃时,才有可能造成少量ID不连续。这是因为主备切换时,“备”节点需要丢弃一部分之前的“主”节点可能已经分配的ID,以保证ID不出现重复。
2.3 GoldenDB数据库
GoldenDB分布式数据库中的自增序列有sequence和auto_increment两种方式,自增序列值由全局事务节点GTM统一分配和维护管理。
1)Sequence创建
Sequence创建的语法:
CREATE SEQUENCE schema.sequence
INCREMENT BY num
START WITH num
MAXVALUE num | NOMAXVALUE
MINVALUE num | NOMINVALUE
CYCLE | NOCYCLE
CACHE | NOCACHE
SEQUENCE默认CACHE为100,修改步长时会导致当前CACHE丢失。由于SEQUENCE的值是在SQL语句执行之前向GTM申请,语句执行失败的情形下申请的SEQUENCE值不能够回收,所以表中的数据会有不连续的情形。
2)自增列auto_increment
GoldenDB数据库兼容MySQL的自增列特性,在建表时候指定auto_increment即可:
CREATE TABLE t1 ( id INT NOT NULL AUTO_INCREMENT, c1 VARCHAR(50) NOT NULL, PRIMARY KEY (id)
);
GoldenDB数据库中的Sequence和自增列由GTM统一管理,定义后通过dbtool -gtm -show-seq命令可以查看自增列的信息:
dbtool -gtm -show-seq -clusterid=2
Send message to other module successfully!
The response message: RSP Code[0].{0:success; 1:provisional response; other: fail.}
Successful response:
clusterid|database|name,start,step,minval,maxval,cache,cycle,curvalue
1|testdb1|t_seq,10,10,1,9223372036854775807,5,0,160610
2|testdb2 |seq_test1,1,1,1,9223372036854775807,1,0,16016
~success~
在多并发申请自增列的场景中,GTM会先将请求放到一个队列中,再统一分配自增值,这样可以减少自增序列请求交互的开销、保证自增列的连续性,不过在极少数高并发场景下可能会存在一定的性能瓶颈。
2.4 TDSQL for MySQL数据库
TDSQL for MySQL分布式数据库版本中支持创建sequence和自增列。
1)Sequence支持
TDSQL支持使用sequence,需要注意的是Sequence为保证分布式全局数值唯一,导致性能较差,主要适用于并发不高的场景。语法如下:
CREATE TDSQL_SEQUENCE {DATABASE | SCHEMA} [IF NOT EXISTS] sequence_name
[ TDSQL_INCREMENT BY increment ]
[ START WITH startvalue ]
[ TDSQL_MINVALUE minvalue] | [ TDSQL_NOMINVALUE ]
[ TDSQL_MAXVALUE maxvalue] | [ TDSQL_NOMAXVALUE ]
[ TDSQL_CACHE cachevalue ] | [ TDSQL_NOCACHE ]
[ TDSQL_CYCLE ] | [ TDSQL_NOCYCLE ]
[ TDSQL_ORDER ] | [ TDSQL_NOORDER ]
-- 查看sequence建表语句
SHOW CREATE TDSQL_SEQUENCE sequence_name;
创建sequence后,可以通过nextval和lastval获取下一个序列值和上一次使用的值:
-- 使用Sequence获取下一个数值
select tdsql_nextval(test.seq2);
select next value for test.seq2;
-- 获取上一次的值
select tdsql_lastval(test.seq2);
select tdsql_previous value for test.seq2;
2)全局唯一序列auto_increment
TDSQL支持全局唯一数字序列(auto_increment)的使用;当前10.3.22版本暂时仅保证自增字段全局唯一和递增性,但是不保证单调递增(也就是OceanBase和TiDB之前版本出现的跳变问题)。全局唯一数字序列(auto_increment)长8字节,最大为18446744073709551616,建表时候创建自增列:
create table auto_inc
(a int,
b int auto_increment,
key auto(b),
primary key p(a,b))
shardkey=a;
通过select last_insert_id()命令获取最新自增值,暂不支持直接从Insert返回包获取。目前select last_insert_id()只能跟shard表和广播表的自增字段一起使用,不支持noshard表。
MySQL [test]> select last_insert_id();
+------------------+
| last_insert_id() |
+------------------+
| 1009 |
+------------------+
1 row in set (0.00 sec)
由于auto_increment仅保证自增字段全局唯一和递增性,如果在节点调度切换、重启等过程中,自增长字段中间会出现空洞。
2.5 GaussDB for OpenGauss数据库
GaussDB分布式数据库(for opengauss)版本中也支持sequence对象和自增列方式实现自增序列,并由GTM(全局事务管理器)统一维护管理,保证序列号全局唯一性。
- 建表时声明字段的类型为序列整型,由数据库在后台自动创建一个对应的Sequence。
- 使用CREATE SEQUENCE自定义一个新的Sequence,然后将nextval(‘sequence_name’)函数读取的序列值,指定为某一字段的默认值,这样该字段就可以作为唯一标识符。
1)Sequence对象
GaussDB中Sequence是一个存放等差数列的特殊表,该表受DBMS控制。这个表没有实际意义,通常用于为行或者表生成唯一的标识符。创建语法如下:
CREATE SEQUENCE name [ INCREMENT [ BY ] increment ][ MINVALUE minvalue | NO MINVALUE | NOMINVALUE ] [ MAXVALUE maxvalue | NO MAXVALUE | NOMAXVALUE] [ START [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE | NOCYCLE ] [ OWNED BY { table_name.column_name | NONE } ];
- Cache:为了快速访问,而在内存中预先存储序列号的个数,默认为1。
- CYCLE/NOCYCLE:用于使序列达到maxvalue或者minvalue后可循环并继续下去。若定义序列为CYCLE,则不能保证序列的唯一性。
在GaussDB中,不建议同时定义cache和maxvalue或minvalue。因为定义cache后不能保证序列的连续性,可能会产生空洞,造成序列号段浪费。如对并发性能有要求,指定参数session_sequence_cache。cache指定了单CN/DN一次向GTM中申请的值;session_sequence_cache指定的是单个会话一次向CN/DN申请缓存的值,会话结束后会自动丢弃。
2)声明字段类型为serial
gaussdb=# CREATE TABLE T1
(id serial,name text
);
在后台会自动创建一个sequence序列。另外,将sequence和一个表的指定字段关联后,当删除那个字段或其所在表的时候会自动删除已关联的sequence。
2.6 自增序列的维护和监控
从上文可以看到各个分布式数据库产品中已经实现了自增序列的功能保证全局唯一性,在实际使用过程中开发关心的是全局序列的唯一性和并发访问时候的性能,从运维视角来看主要是自增序列的使用值监控。Sequence在定义的时候有CYCLE和NOCYCLE两种模式,业务使用场景中不是所有的都能使用CYCLE循环模式,毕竟无法保证它的唯一性。如果是NOCYCLE模式,肯定有个上限,申请的序列值达到上限后,业务访问会报错,如何做好监控和维护?
1)Sequence序列对象的监控
Sequence对象在定义的时候指定了MAXVALUE或者使用系统默认的最大value,通过SQL语句查询当前的VALUE值CURRVAL和最大值比较获得使用率,并以定时任务或脚本方式部署到监控中。有些数据库如GoldenDB和GaussDB中,本身有管理组件GTM对sequence维护管理,由数据库本身实现sequence使用率的监控。
2)自增列的监控
自增列auto_increment随着业务的插入操作,自增值不断增长。在MySQL系列的数据库中,通过自定义视图来监控自增列的使用情况,以下是一个例子:
##1、从information_schema.full_columns中查出table_name,table_schema,column_name,data_type,column_type等信息##2、根据自增列的data_type得到最大值
case information_schema.full_columns.data_type when ‘tinyint’ then 255 when ‘smallint’ then 65535 when ‘mediumint’ then 16777215 when ‘int’ then 4294967295 when ‘bigint’ then 18446744073709551615)##3、从表information_schema.full_tables中获取auto_increment使用值
以上是自增序列的监控手段,实际操作过程中需要增加自增序列的使用这一监控指标并定制监控策略。
参考资料:
- https://www.oceanbase.com/docs
- https://docs.pingcap.com/zh/tidb/stable/
- https://cloud.tencent.com/document/product/557/47526
- GoldenDB分布式数据库SQL指南
- GaussDB云数据库操作指南
相关文章:
分布式数据库中全局自增序列的实现
自增序列广泛使用于数据库的开发和设计中,用于生产唯一主键、日志流水号等唯一ID的场景。传统数据库中使用Sequence和自增列的方式实现自增序列的功能,在分布式数据库中兼容Oracle和MySQL等传统数据库语法,也是基于Sequence和自增列的方式实现…...
【论文阅读】TensoRF: Tensorial Radiance Fields 张量辐射场
发表于ECCV2022. 论文地址:https://arxiv.org/abs/2203.09517 源码地址:https://github.com/apchenstu/TensoRF 项目地址:https://apchenstu.github.io/TensoRF/ 摘要 本文提出了TensoRF,一种建模和重建辐射场的新方法。不同于Ne…...

深入了解 Android 中的 FrameLayout 布局
FrameLayout 是 Android 中常用的布局之一,它允许子视图堆叠在一起,可以在不同位置放置子视图。在这篇博客中,我们将详细介绍 FrameLayout 的属性及其作用。 <FrameLayout xmlns:android"http://schemas.android.com/apk/res/androi…...
高级大数据技术 实验一 scala编程
高级大数据技术 实验一 scala编程 写的不是很好,大家多见谅! 1. 计算水仙花数 实验目标; (1) 掌握scala的数组,列表,映射的定义与使用 (2) 掌握scala的基本编程 实验说明 …...

使用Fabric创建的canvas画布背景图片,自适应画布宽高
之前的文章写过vue2使用fabric实现简单画图demo,完成批阅功能;但是功能不完善,对于很大的图片就只能显示一部分出来,不符合我们的需求。这就需要改进,对我们设置的背景图进行自适应。 有问题的canvas画布背景 修改后的…...
枚举与尺取法(蓝桥杯 c++ 模板 题目 代码 注解)
目录 组合型枚举(排列组合模板()): 排列型枚举(全排列)模板: 题目一(公平抽签 排列组合): 编辑 代码: 题目二(座次问题 全排…...

11、电源管理入门之Regulator驱动
目录 1. Regulator驱动是什么? 2. Regulator框架介绍 2.1 regulator consumer 2.2 regulator core 2.3 regulator driver 3. DTS配置文件及初始化 4. 运行时调用 5. Consumer API 5.1 Consumer Regulator Access (static & dynamic drivers) 5.2 Regulator Outp…...

24年证券从业考试注册报名流程详细图解,千万不要错过报名哦!
(一)时间安排 考生报名缴费时间:3月5日15时至3月8日15时 退费时间:3月7日15时至3月10日15时 准考证打印时间:3月20日15时至3月23日18时 (二)注册流程 1、进入中国证券业协会网站-从业人员管理-考…...
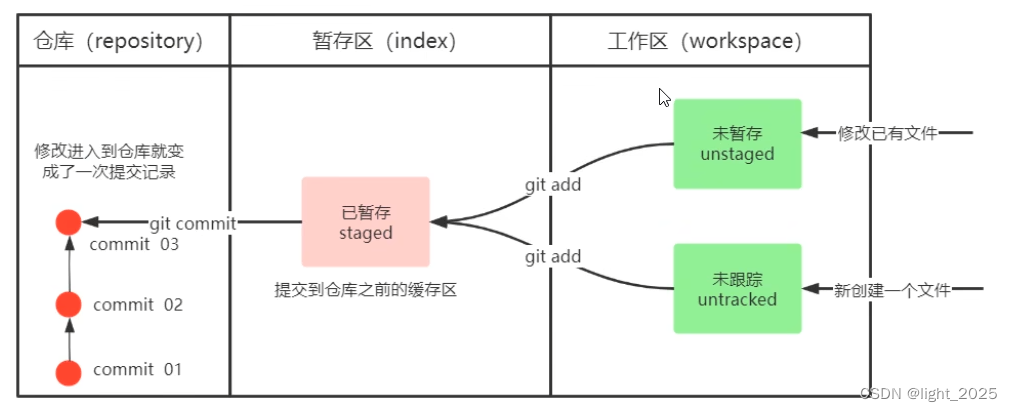
Git入门学习笔记
Git 是一个非常强大的分布式版本控制工具! 在下载好Git之后,鼠标右击就可以显示 Git Bash 和 Git GUI,Git Bash 就像是在电脑上安装了一个小型的 Linux 系统! 1. 打开 Git Bash 2. 设置用户信息(这是非常重要的&…...
⭐每天一道leetcode:27.移除元素(简单;vector)
⭐今日份题目 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。 元素的顺序可以改变。你不需要考虑数组中…...

如何处理Android内存泄漏和性能优化
处理Android内存泄漏和性能优化是一个复杂的过程,涉及到对应用的深入理解和良好的编程习惯。以下是一些关键的步骤和建议: 1. **理解内存泄漏的本质**: - 内存泄漏(Memory Leak)发生在程序中,当不再需要…...

应用方案 | D722 9MHz,轨对轨I/O CMOS运放,低噪声、低电压、低功耗运放,应用广泛
D722是低噪声、低电压、低功耗运放,应用广泛。D722具有9MHz的高增益带宽积,转换速率为8.5V/μs,静态电流为1.7mA(5V电源电压)。 D722具有低电压、低噪声的特点,并提供轨到轨输出能力,D722的最大…...

小程序常用样式和组件
常用样式和组件 1. 组件和样式介绍 在开 Web 网站的时候: 页面的结构由 HTML 进行编写,例如:经常会用到 div、p、 span、img、a 等标签 页面的样式由 CSS 进行编写,例如:经常会采用 .class 、#id 、element 等选择器…...
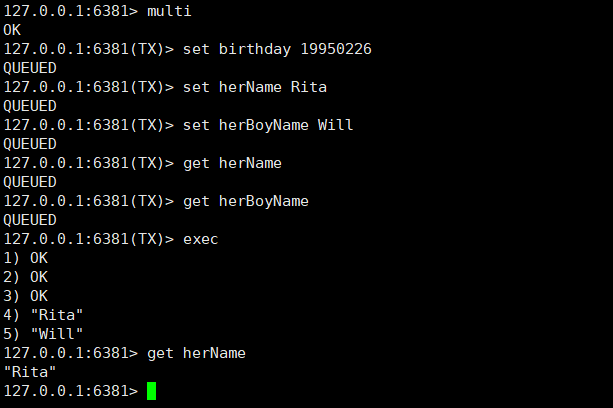
《Redis 设计与实现》读书概要
注: 《Redis 设计与实现》一书基于 Redis 2.9 版本编写,部分内容已过时,过时之处本文会有所说明。本文为读书笔记,部分简单和日常使用较少的知识点未记录。原书网页版地址 https://redisbook.com/ 一、底层数据结构 SDS(Simple Dy…...

Docker之数据卷自定义镜像
文章目录 前言一、数据卷二、自定义镜像 前言 Docker提供了一个持久化存储数据的机制,与容器生命周期分离,从而带来一系列好处: 总的来说Docker 数据卷提供了一种灵活、持久、可共享的存储机制,使得容器化应用在数据管理方面更加…...
Docker技术概论(4):Docker CLI 基本用法解析
Docker技术概论(4) Docker CLI 基本用法解析 - 文章信息 - Author: 李俊才 (jcLee95) Visit me at: https://jclee95.blog.csdn.netMy WebSite:http://thispage.tech/Email: 291148484163.com. Shenzhen ChinaAddress of this article:http…...

【JAVA重要知识 | 第五篇】暴打Java8新特性—(Lambda、方法引用、Stream流、函数式接口、Date Time API、Optional类)
文章目录 5.Java8新特性5.1新特性列表5.2Lambda 表达式5.2.1函数式思想5.2.2举例(1)方式一:创建对象(2)方式二:匿名内部类(3)方式三:Lambda 5.2.3Lambda表达式的标准格式…...

Docker Swarm全解析:实现微服务高可用与故障转移的秘密武器
🐇明明跟你说过:个人主页 🏅个人专栏:《Docker入门到精通》 《k8s入门到实战》🏅 🔖行路有良友,便是天堂🔖 目录 一、基本概念和介绍 1、Docker Swarm 是什么,它与 …...
)
编码规范(前端)
文章目录 1. 文档说明1.1 编制说明1.2 名词解释 2.前端研发规范2.1 HTML编码规范2.1.1 文档类型2.1.2 语言2.1.3 元数据2.1.4 资源加载2.1.5 页面标题2.1.6 编码风格2.1.7 标签2.1.8 属性2.1.9 语义化 2.2 CSS编码规范2.2.1 文件引用2.2.2 命名-组成元素 知识点 1. 文档说明 1…...

【JavaEE进阶】部署Web项目到Linux服务器
文章目录 🍃前言🍀什么是部署🌲环境配置🚩数据准备🚩程序配置⽂件修改 🎄构建项目并打包🎋上传Jar包到服务器,并运行🚩上传Jar包🚩运行程序🚩开放端口号 &…...
)
【限时解密】金融级Java代码审查SOP:Gemini+自定义规则包+合规检查矩阵(ISO 27001/等保2.0双认证适配版)
更多请点击: https://codechina.net 第一章:Gemini Java代码审查的核心价值与金融级适配逻辑 在高并发、强一致性、零容忍故障的金融系统中,Java代码质量直接关联资金安全、监管合规与交易连续性。Gemini并非通用AI辅助工具,而是…...

Taotoken用量看板与成本管理功能实操体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板与成本管理功能实操体验 在将多个大模型API集成到实际项目中时,除了对接的便利性,团队往往…...

清华PPT模板:如何在5分钟内打造专业学术演示文稿
清华PPT模板:如何在5分钟内打造专业学术演示文稿 【免费下载链接】THU-PPT-Theme 清华主题PPT模板 项目地址: https://gitcode.com/gh_mirrors/th/THU-PPT-Theme 还在为学术汇报PPT设计而烦恼吗?面对即将到来的答辩、会议或课堂展示,你…...

CVPR 2023五大技术断层:泛化性、实时性与边缘部署的工程真相
1. 这不是会议速记,而是一份“CVPR 2023技术脉络手绘地图”如果你在搜索引擎里输入“CVPR 2023 summary”,大概率会看到一堆标题党文章:什么“十大突破”、什么“最火模型TOP5”、什么“必看论文清单”。我翻过不下二十篇,结果发现…...

华为OD机试真题 新系统 2026-05-20 JavaGoC语言 实现【多模型版本的最优调度】
目录 题目 思路 Code 题目 在大语言模型推理服务中,有多个不同大小的模型版本可供选择。每个模型版本有不同的准确率和推理延迟。给定查询次数 N 和总时间预算 T,为每个查询选择一个模型版本,使得在不超过时间预算的前提下,总准…...

Oracle替代之路:企业去O过程中常见的坑与避坑指南
📌 关键词:Oracle替代、国产数据库、去O、数据库迁移、信创、兼容性、高可用大家好!我是数据库小学妹 👋 最近发现一个有意思的现象:不管是金融、运营商还是政务单位,聊到数据库规划,三句话不离…...

解决RTL8821CU无线网卡在Linux下的3大痛点:从识别到稳定连接的全攻略
解决RTL8821CU无线网卡在Linux下的3大痛点:从识别到稳定连接的全攻略 【免费下载链接】rtl8821CU Realtek RTL8811CU/RTL8821CU USB Wi-Fi adapter driver for Linux 项目地址: https://gitcode.com/gh_mirrors/rt/rtl8821CU 你是否曾经在Linux系统上连接RTL…...

初创团队如何利用Taotoken控制大模型API成本并保持开发灵活性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用Taotoken控制大模型API成本并保持开发灵活性 对于初创团队而言,大模型API是加速产品原型验证和功能开…...

Healthy Care辅酶Q10怎么选?
当代社会,心脏健康养护早已不是中老年人的专属需求。长期熬夜的年轻人、高压职场人群、作息紊乱的轮班从业者、体力消耗偏大的服务行业工作者,都容易出现心脏能量不足的信号:爬楼容易气喘、安静状态下莫名心慌、睡眠充足却依旧浑身疲惫。这类…...

多模型选型实验场景下Taotoken模型广场的价值与应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多模型选型实验场景下Taotoken模型广场的价值与应用 在模型技术快速迭代的今天,无论是学术研究还是产品开发࿰…...