Java多线程——如何保证原子性

目录
- 引出
- 原子性保障
- 原子性
- CAS
- 创建线程有几种方式?
- 方式1:继承Thread创建线程
- 方式2:通过Runnable
- 方式3:通过Callable创建线程
- 方式4:通过线程池
- 概述
- ThreadPoolExecutor API
- 代码实现
- 源码分析
- 工作原理:
- 线程池的阻塞队列选择
- 线程池已满又有新任务?
- 拒绝策略
- 如何优化线程池配置?
- Executors
- 总结
引出
Java多线程——如何保证原子性
原子性保障
可见性:synchronize、volatile
原子性:synchronize、AtomicInteger
volatile保证数据的可见性,但是不保证原子性(多线程进行写操作,不保证线程安全);而synchronized是一种排他(互斥)的机制。
i = i + 1 不是一个原则操作,由四个操作组成,读取i,读取1,执行i+1, 赋值
原子性
如果要把一个变量从主内存中复制到工作内存中,就需要按顺序地执行read和load操作,如果把变量从工作内存中同步到主内存中,就需要按顺序地执行store和write操作。但Java内存模型只要求上述操作必须按顺序执行,而没有保证必须是连续执行。
对应如下的流程图:
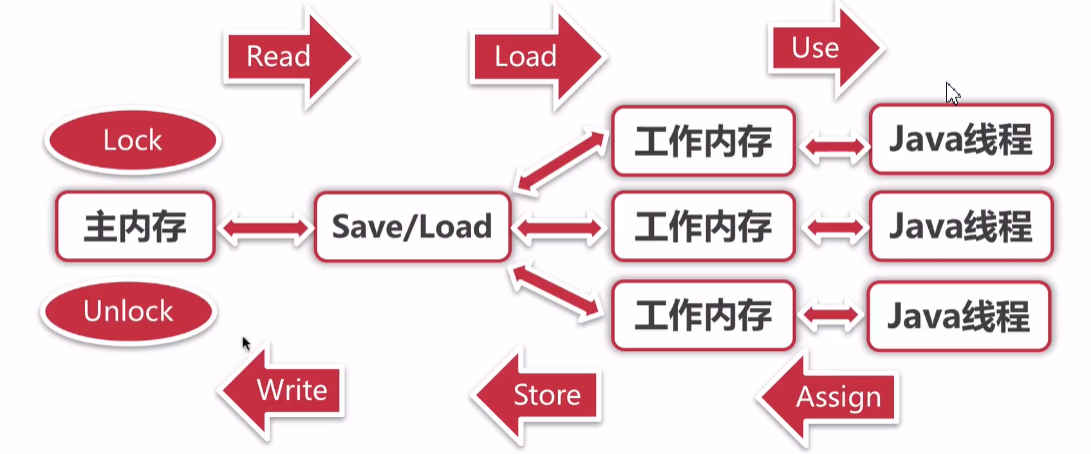
数据操作的原子性,可以通过lock和unlock来达到目的。但是JVM并没有把lock和unlock操作直接开放给用户使用,我们的java代码中,就是大家所熟知的synchronized关键字保证原子性。
1、非原子操作存在的问题
public class App15 {private static Integer num = 0;public static void main(String[] args) throws Exception {Runnable runnable = () -> {for (int i = 0; i < 100; i++) {num++;}};for (int i = 0; i < 100; i++) {new Thread(runnable).start();}Thread.sleep(20);// 结果不一定是10000System.out.println("num = " + num);}
}
2、synchronize 解决原子性问题
public class App{private static Integer num = 0;public static void main(String[] args) throws Exception {Runnable runnable = () -> {for (int i = 0; i < 100; i++) {synchronized (App11.class) { // 解决原子性问题num++;}}};for (int i = 0; i < 100; i++) {new Thread(runnable).start();}Thread.sleep(20);System.out.println("num = " + num);}
}
3、AtomicInteger 解决原子性问题
public class App {private static AtomicInteger atomicInteger= new AtomicInteger(0);public static void main(String[] args) throws Exception {Runnable runnable = () -> {for (int i = 0; i < 100; i++) {// 原子方式实现递增,线程安全atomicInteger.getAndIncrement();}};for (int i = 0; i < 100; i++) {new Thread(runnable).start();}Thread.sleep(20);System.out.println("num = " + atomicInteger.get());}
}
通过上锁保障操作的原子性,两种方式,一种是悲观锁,一种是乐观锁。
CAS
CAS 是 “Compare And Swap”(比较并交换)的缩写,是一种并发编程中常用的原子性操作,用于解决多线程环境下的竞态条件问题。
CAS 操作通常用于实现无锁算法,它可以在不使用传统锁机制的情况下实现对共享数据的原子操作。这在高并发场景下非常有用,因为传统锁会引入线程间的等待和切换,导致性能下降。CAS 操作基于底层硬件的支持,在许多现代处理器上都有对应的原子指令集,因此它可以在硬件层面保证原子性,避免了多线程竞争带来的问题。
CAS 操作的基本思想是:
- 首先,读取当前的值(旧值)。
- 然后,与期望的值进行比较。
- 如果相等,说明当前值没有被其他线程修改,可以将新值写入,完成操作。
- 如果不相等,说明当前值已被其他线程修改,操作失败,需要重试或执行其他逻辑。
在 Java 中,Atomic 类和相关的原子类使用了 CAS 操作来实现并发安全的操作,例如 AtomicInteger、AtomicLong、AtomicReference 等。这些类提供了方法来执行类似于 getAndSet、compareAndSet、getAndAdd 等操作,以及其他一些基于 CAS 的原子操作,用于管理并发情况下的共享数据。

CAS中的ABA问题
问题描述:
线程A 获取的旧值为5,当线程A要比较并修改之前。线程B进来,获取的值为5,然后修改成6,修改成功。接着线程C进来,获取的值为6,将值修改为5,修改成功。
此时,线程A进行比较并修改,5 == 5,比较成功,进行值的修改。
也就是说,A线程在修改值的操作的时候,线程B,线程C都对值进行修改过了。
解决ABA问题,添加版本号,每次操作一次,版本号增加1。
创建线程有几种方式?
方式1:继承Thread创建线程
public class MyThread extends Thread {@Overridepublic void run() {for (int i = 0; i < 20; i++) {System.out.println(Thread.currentThread().getName() + ":" + i);}}public static void main(String[] args) {MyThread t1 = new MyThread();t1.start();MyThread t2 = new MyThread();t2.start();}
}
方式2:通过Runnable
public class App2 {public static void main(String[] args) {new Thread(()->{for (int i = 0; i < 20; i++) {System.out.println("i = " + i);}}).start();}
}
方式3:通过Callable创建线程
一个可取消的异步计算。FutureTask提供了对Future的基本实现,可以调用方法去开始和取消一个计算,可以查询计算是否完成并且获取计算结果。只有当计算完成时才能获取到计算结果,一旦计算完成,计算将不能被重启或者被取消,除非调用runAndReset方法。
总的来说,如果你需要在线程任务执行完毕后获取返回结果,或者需要在任务中处理受检查异常,那么你应该使用 Callable 接口。如果你只需要执行一个简单的线程任务而不关心返回结果,那么使用 Runnable 接口更加合适。
package cn.test;
import java.util.concurrent.*;
public class App3 {public static void main(String[] args) {//1、计算任务,实现Callable接口Callable<String> callable = ()->{int sum = 0;for (int i = 0; i < 20; i++) {sum += i;// 耗时操作Thread.sleep(100);}return "计算结果:" + sum;};//2、创建FutureTask,传入callable对象FutureTask<String> futureTask = new FutureTask<>(callable);//3、创建启动线程Thread thread = new Thread(futureTask);thread.start();try {String result = futureTask.get(1, TimeUnit.SECONDS);System.out.println("result = " + result);} catch (InterruptedException e) {e.printStackTrace();} catch (ExecutionException e) {e.printStackTrace();} catch (TimeoutException e) {e.printStackTrace();// 超时中断执行futureTask.cancel(true);System.out.println("超时中断执行");}}
}
方式4:通过线程池
概述
线程过多会带来额外的开销,频繁创建和销毁大量线程需要占用系统资源,消耗大量时间。其中包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机的整体性能。线程池维护多个线程,等待监督管理者分配可并发执行的任务。这种做法,一方面避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
ThreadPoolExecutor API
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler) {
corePoolSize :核心池的大小,如果调用了prestartAllCoreThreads()或者prestartCoreThread()方法,会直接预先创建corePoolSize指定大小的线程,否则当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中;这样做的好处是,如果任务量很小,那么甚至就不需要缓存任务,corePoolSize的线程就可以应对;
maximumPoolSize:线程池最大线程数,表示在线程池中最多能创建多少个线程,如果运行中的线程超过了这个数字,那么相当于线程池已满,新来的任务会使用RejectedExecutionHandler 进行处理;
keepAliveTime:表示线程没有任务执行时最多保持多久时间会终止,然后线程池的数目维持在corePoolSize 大小;
unit:参数keepAliveTime的时间单位;
workQueue:一个阻塞队列,用来存储等待执行的任务,如果当前对线程的需求超过了corePoolSize大小,才会放在这里;
threadFactory:线程工厂,主要用来创建线程,比如可以指定线程的名字;
handler:如果线程池已满,新的任务的处理方式
代码实现
public class App4 {// 线程池的核心线程数private static final int CORE_POOL_SIZE = 5;// 线程池的最大线程数private static final int MAX_POOL_SIZE = 10;// 当线程数大于核心线程数时,多余的空闲线程存活的最长时间private static final int KEEP_ALLOW_TIME = 100;// 任务队列大小,用来存储等待执行任务的队列private static final int QUEUE_CAPACITY = 100;public static void main(String[] args) {// handler 指定拒绝策略,当提交的任务过多不能及时处理,我们通过定制的策略处理任务ThreadPoolExecutor executor = new ThreadPoolExecutor(CORE_POOL_SIZE,MAX_POOL_SIZE,KEEP_ALLOW_TIME,TimeUnit.SECONDS,new ArrayBlockingQueue<>(QUEUE_CAPACITY),new ThreadPoolExecutor.CallerRunsPolicy());//executor.prestartAllCoreThreads();for (int i = 0; i < 10; i++) {Runnable runnable = () -> {System.out.println(Thread.currentThread().getName() + ":start");try {Thread.sleep(3000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println(Thread.currentThread().getName() + ":end");};// 运行线程executor.execute(runnable);}// 终止线程池executor.shutdown();while (!executor.isTerminated()) {}System.out.println("Finish All");}
}
源码分析
/*The main pool control state, ctl, is an atomic integer packing* two conceptual fields* workerCount, indicating the effective number of threads* runState, indicating whether running, shutting down etc */
// 存放线程池的线程池内有效线程的数量 (workerCount)和运行状态 (runState) private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));private static int workerCountOf(int c) {return c & CAPACITY;}private final BlockingQueue<Runnable> workQueue;public void execute(Runnable command) {// 如果任务为null,则抛出异常。if (command == null)throw new NullPointerException();// ctl 中保存的线程池当前的一些状态信息int c = ctl.get();// 下面会涉及到 3 步 操作// 1.首先判断当前线程池中之行的任务数量是否小于 corePoolSize// 如果小于的话,通过addWorker(command, true)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true))return;c = ctl.get();}// 2.如果当前之行的任务数量大于等于 corePoolSize 的时候就会走到这里// 通过 isRunning 方法判断线程池状态,线程池处于 RUNNING 状态才会被并且队列可以加入任务,该任务才会被加入进去if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();// 再次获取线程池状态,如果线程池状态不是 RUNNING 状态就需要从任务队列中移除任务,并尝试判断线程是否全部执行完毕。同时执行拒绝策略。if (!isRunning(recheck) && remove(command))reject(command);// 如果当前线程池为空就新创建一个线程并执行。else if (workerCountOf(recheck) == 0)addWorker(null, false);}//3. 通过addWorker(command, false)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。//如果addWorker(command, false)执行失败,则通过reject()执行相应的拒绝策略的内容。else if (!addWorker(command, false))reject(command);}
工作原理:
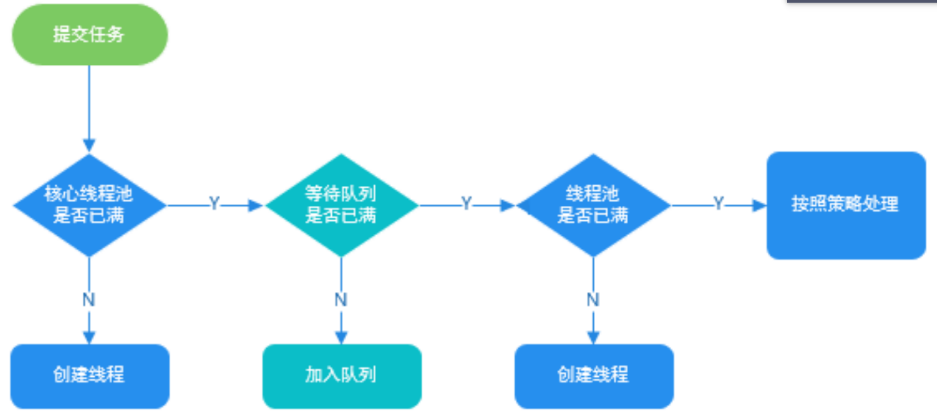
- 线程池刚创建时,里面没有一个线程。任务队列是作为参数传进来的。不过,就算队列里面有任务,线程池也不会马上执行它们。
- 当调用 execute() 方法添加一个任务时,线程池会做如下判断:
- 如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务;
- 如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列。
- 如果这时候队列满了,而且正在运行的线程数量小于 maximumPoolSize,那么还是要创建线程运行这个任务;
- 如果队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会抛出异常,告诉调用者“我不能再接受任务了”。
3,当一个线程完成任务时,它会从队列中取下一个任务来执行。
4,当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
这样的过程说明,并不是先加入任务就一定会先执行。假设队列大小为 10,corePoolSize 为 3,maximumPoolSize 为 6,那么当加入 20 个任务时,执行的顺序就是这样的:首先执行任务 1、2、3,然后任务 4~13 被放入队列。这时候队列满了,任务 14、15、16 会被马上执行,而任务 17~20 则会抛出异常。最终顺序是:1、2、3、14、15、16、4、5、6、7、8、9、10、11、12、13。
线程池的阻塞队列选择
如果线程数超过了corePoolSize,则开始把线程先放到阻塞队列里,相当于生产者消费者的一个数据通道,有以下一些阻塞队列可供选择:
-
ArrayBlockingQueue
ArrayBlockingQueue是一个有边界的阻塞队列,它的内部实现是一个数组。有边界的意思是它的容量是有限的,我们必须在其初始化的时候指定它的容量大小,容量大小一旦指定就不可改变。
-
DelayQueue
DelayQueue阻塞的是其内部元素,DelayQueue中的元素必须实现 java.util.concurrent.Delayed接口,该接口只有一个方法就是long getDelay(TimeUnit unit),返回值就是队列元素被释放前的保持时间,如果返回0或者一个负值,就意味着该元素已经到期需要被释放,此时DelayedQueue会通过其take()方法释放此对象,DelayQueue可应用于定时关闭连接、缓存对象,超时处理等各种场景;
-
LinkedBlockingQueue
LinkedBlockingQueue阻塞队列大小的配置是可选的,如果我们初始化时指定一个大小,它就是有边界的,如果不指定,它就是无边界的。说是无边界,其实是采用了默认大小为Integer.MAX_VALUE的容量 。它的内部实现是一个链表。
-
PriorityBlockingQueue
PriorityBlockingQueue是一个没有边界的队列,它的排序规则和 java.util.PriorityQueue一样。需要注意,PriorityBlockingQueue中允许插入null对象。所有插入PriorityBlockingQueue的对象必须实现 java.lang.Comparable接口,队列优先级的排序规则就是按照我们对这个接口的实现来定义的。
-
SynchronousQueue
SynchronousQueue队列内部仅允许容纳一个元素。当一个线程插入一个元素后会被阻塞,除非这个元素被另一个线程消费。
使用的最多的应该是LinkedBlockingQueue,注意一般情况下要配置一下队列大小,设置成有界队列,否则JVM内存会被撑爆!
线程池已满又有新任务?
如果线程池已经满了可是还有新的任务提交怎么办?
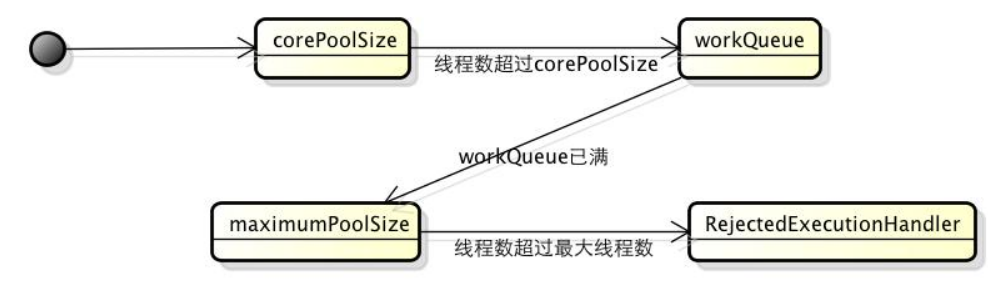
线程池已满的定义,是指运行线程数==maximumPoolSize,并且workQueue是有界队列并且已满(如果是无界队列当然永远不会满);
这时候再提交任务怎么办呢?线程池会将任务传递给最后一个参数RejectedExecutionHandler来处理,比如打印报错日志、抛出异常、存储到Mysql/redis用于后续处理等等,线程池默认也提供了几种处理方式,详见下一章:
拒绝策略
拒绝策略指的就是线程池已满情况下任务的处理策略,默认有以下几种:
1、ThreadPoolExecutor.AbortPolicy 中,处理程序遭到拒绝将抛出运行时RejectedExecutionException。
/*** A handler for rejected tasks that throws a* {@code RejectedExecutionException}.*/public static class AbortPolicy implements RejectedExecutionHandler {/*** Creates an {@code AbortPolicy}.*/public AbortPolicy() { }/*** Always throws RejectedExecutionException.** @param r the runnable task requested to be executed* @param e the executor attempting to execute this task* @throws RejectedExecutionException always*/public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {throw new RejectedExecutionException("Task " + r.toString() +" rejected from " +e.toString());}}
2、在 ThreadPoolExecutor.CallerRunsPolicy,交给线程池调用所在的线程进行处理。
/*** A handler for rejected tasks that runs the rejected task* directly in the calling thread of the {@code execute} method,* unless the executor has been shut down, in which case the task* is discarded.*/public static class CallerRunsPolicy implements RejectedExecutionHandler {/*** Creates a {@code CallerRunsPolicy}.*/public CallerRunsPolicy() { }/*** Executes task r in the caller's thread, unless the executor* has been shut down, in which case the task is discarded.** @param r the runnable task requested to be executed* @param e the executor attempting to execute this task*/public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {if (!e.isShutdown()) {r.run();}}}
3、在 ThreadPoolExecutor.DiscardPolicy 中,直接丢弃后来的任务
/*** A handler for rejected tasks that silently discards the* rejected task.*/public static class DiscardPolicy implements RejectedExecutionHandler {/*** Creates a {@code DiscardPolicy}.*/public DiscardPolicy() { }/*** Does nothing, which has the effect of discarding task r.** @param r the runnable task requested to be executed* @param e the executor attempting to execute this task*/public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {}}
4、在 ThreadPoolExecutor.DiscardOldestPolicy 丢弃队列里最老的任务,将当前这个任务继续提交给线程池。
/*** A handler for rejected tasks that discards the oldest unhandled* request and then retries {@code execute}, unless the executor* is shut down, in which case the task is discarded.*/public static class DiscardOldestPolicy implements RejectedExecutionHandler {/*** Creates a {@code DiscardOldestPolicy} for the given executor.*/public DiscardOldestPolicy() { }/*** Obtains and ignores the next task that the executor* would otherwise execute, if one is immediately available,* and then retries execution of task r, unless the executor* is shut down, in which case task r is instead discarded.** @param r the runnable task requested to be executed* @param e the executor attempting to execute this task*/public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {if (!e.isShutdown()) {e.getQueue().poll();e.execute(r);}}}
5、当然也可以自己实现处理策略类,继承RejectedExecutionHandler接口即可,该接口只有一个方法:
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
如何优化线程池配置?
如何合理配置线程池大小,仅供参考。
一般需要根据任务的类型来配置线程池大小:
如果是CPU密集型任务,就需要尽量压榨CPU,参考值可以设为【(CPU总核数)】 或者 【(CPU总核数+1)】
如果是IO密集型任务,类似 网络I/O、数据库、磁盘I/O 等,参考值可以设置为【(2 * CPU总核数)】
当然,这只是一个参考值,具体的设置还需要根据实际情况进行调整,比如可以先将线程池大小设置为参考值,
再观察任务运行情况和系统负载、资源利用率来进行适当调整。
其中NCPU的指的是CPU的核心数,可以使用下面方式来获取;
public static void main(String[] args) {int ncpu = Runtime.getRuntime().availableProcessors();System.out.println("cpu核数 = " + ncpu);}
Executors
通过Executors类提供四种线程池。创建方法为静态方式创建。
Executors.newFixedThreadPool();
返回线程池对象。创建的是有界线程池,也就是池中的线程个数可以指定最大数量。
public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}
可见该方法让keepAliveTime为0,即限制了线程数必须小于等于corePoolSize。而多出的线程则会被无界队列所存储,在其中排队。
Executors.newCachedThreadPool();
创建一个可缓存线程池,线程池长度超过处理需要时,可灵活回收空闲线程,若无可回收线程则新建线程。
public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());}
该方法中所有线程均由SynchronousQueue管理,且不设置线程数量上限。对于SynchronousQueue,每个插入线程必须等待另一线程的对应移除操作。(即该队列没有容量,仅试图取得元素时元素才存在)因而,该方法实现了,如果有线程空闲,则使用空闲线程进行操作,否则就会创建新线程。
Executors.newScheduledThreadPool();
创建一个定长线程池,相对于FixedThreadPool,它支持周期性执行和延期执行。
1、延迟3秒执行
public static void main(String[] args) {ScheduledExecutorService executorService = Executors.newScheduledThreadPool(2);executorService.schedule(()->{System.out.println(Thread.currentThread().getName()+":线程启动");},3, TimeUnit.SECONDS);executorService.shutdown();
}
2、每三秒隔一秒执行
public static void main(String[] args) {ScheduledExecutorService executorService = Executors.newScheduledThreadPool(2);executorService.scheduleAtFixedRate(()->{System.out.println(Thread.currentThread().getName()+":线程启动");},1,3, TimeUnit.SECONDS);
}
Executors.newSingleThreadExecutor();
创建一个单线程线程池,只会用唯一的工作线程执行任务,保证所有任务按FIFO,LIFO的优先级执行。
在实现上,其相当于一个线程数为1的FixedThreadPool
public static ExecutorService newSingleThreadExecutor() {return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));}
总结
Java多线程——如何保证原子性
相关文章:
Java多线程——如何保证原子性
目录 引出原子性保障原子性CAS 创建线程有几种方式?方式1:继承Thread创建线程方式2:通过Runnable方式3:通过Callable创建线程方式4:通过线程池概述ThreadPoolExecutor API代码实现源码分析工作原理:线程池的…...

stm32消息和邮箱使用
邮箱管里介绍 邮箱是C/OS-II中另一种通讯机制,它可以使一个任务或者中断服务子程序向另一个任务发送一个指针型的变量。该指针指向一个包含了特定“消息”的数据结构。为了在C/OS-II中使用邮箱,必须将OS_CFG.H中的OS_MBOX_EN常数置为1。使用邮箱之前,必须先建立该邮箱。该操…...

银行数字化转型导师坚鹏:银行数字化转型案例研究
银行数字化转型案例研究 课程背景: 数字化背景下,很多银行存在以下问题: 不清楚银行科技金融数智化案例? 不清楚银行供应链金融数智化案例? 不清楚银行普惠金融数智化案例? 不清楚银行跨境金融数智…...

142.乐理基础-音程的构唱练习
内容参考于:三分钟音乐社 上一个内容:141.乐理基础-男声女声音域、模唱、记谱与实际音高等若干问题说明-CSDN博客 本次内容最好去看视频: https://apphq3npvwg1926.h5.xiaoeknow.com/p/course/column/p_5fdc7b16e4b0231ba88d94f4?l_progra…...
【比较mybatis、lazy、sqltoy、mybatis-flex操作数据】操作批量新增、分页查询(二)
orm框架使用性能比较 环境: idea jdk17 spring boot 3.0.7 mysql 8.0比较mybatis、lazy、sqltoy、mybatis-flex操作数据 测试条件常规对象 orm 框架是否支持xml是否支持 Lambda对比版本mybatis☑️☑️3.5.4sqltoy☑️☑️5.2.98lazy✖️☑️1.2.4-JDK17-SNAPS…...
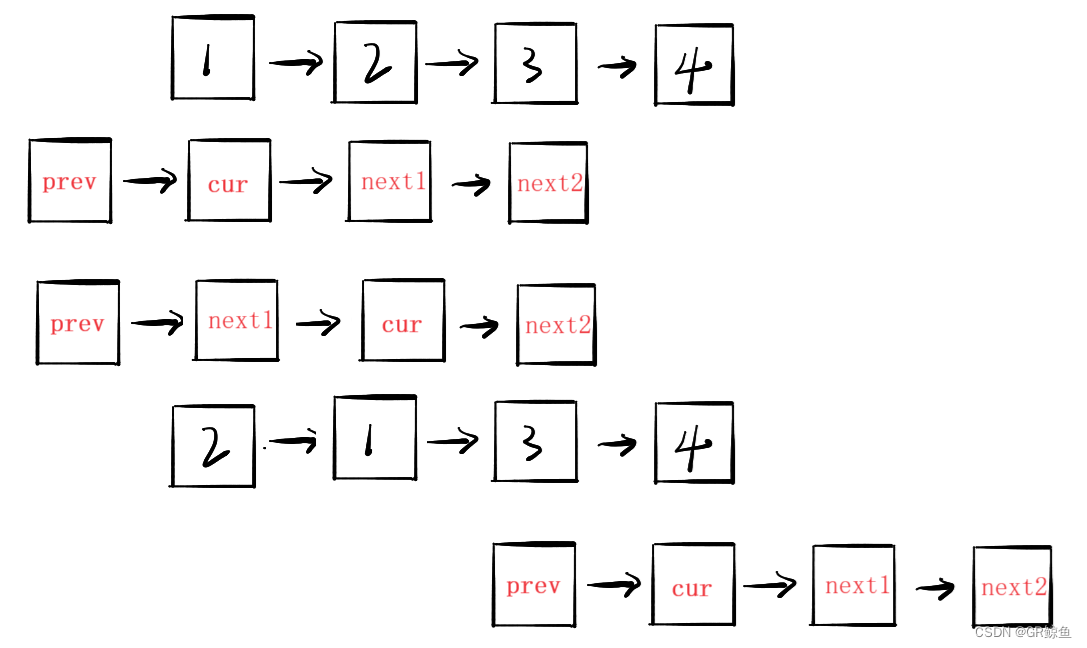
每日OJ题_链表②_力扣24. 两两交换链表中的节点
目录 力扣24. 两两交换链表中的节点 解析代码 力扣24. 两两交换链表中的节点 24. 两两交换链表中的节点 难度 中等 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即&…...
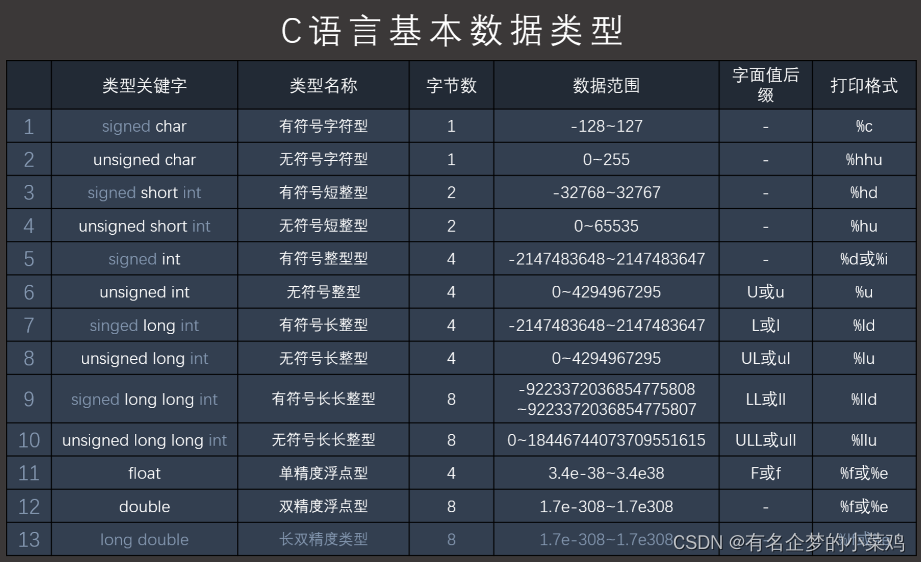
C语言数据类型详解及相关题——各种奇奇怪怪的偏难怪
文章目录 一、C语言基本数据类型溢出 二、存储原理符号位原码反码补码补码操作的例子 三、赋值中的类型转换常见返回类型——巨坑总结 一、C语言基本数据类型 溢出 因为数据范围(即存储单元的位的数量)的限制,可以表达的位数是有限的。 溢出…...

经典语义分割(二)医学图像分割模型UNet
经典语义分割(二)医学图像分割模型UNet 我们之前介绍了全卷积神经网络( FCN) ,FCN是基于深度学习的语义分割算法的开山之作。 今天我们介绍另一个语义分割的经典模型—UNet,它兼具轻量化与高性能,通常作为语义分割任务的基线测试模型&#x…...
三天学会阿里分布式事务框架Seata-seata事务日志mysql持久化配置
锋哥原创的分布式事务框架Seata视频教程: 实战阿里分布式事务框架Seata视频教程(无废话,通俗易懂版)_哔哩哔哩_bilibili实战阿里分布式事务框架Seata视频教程(无废话,通俗易懂版)共计10条视频&…...
C语言-简单实现单片机中的malloc示例
概述 在实际项目中,有些单片机资源紧缺,需要mallloc内存,库又没有自带malloc函数时,此时,就需要手动编写,在此做个笔录。(已在项目上使用),还可进入对齐管理机制。 直接…...

外包干了2年,技术退步明显
先说一下自己的情况,研究生,19年进入广州某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测试…...
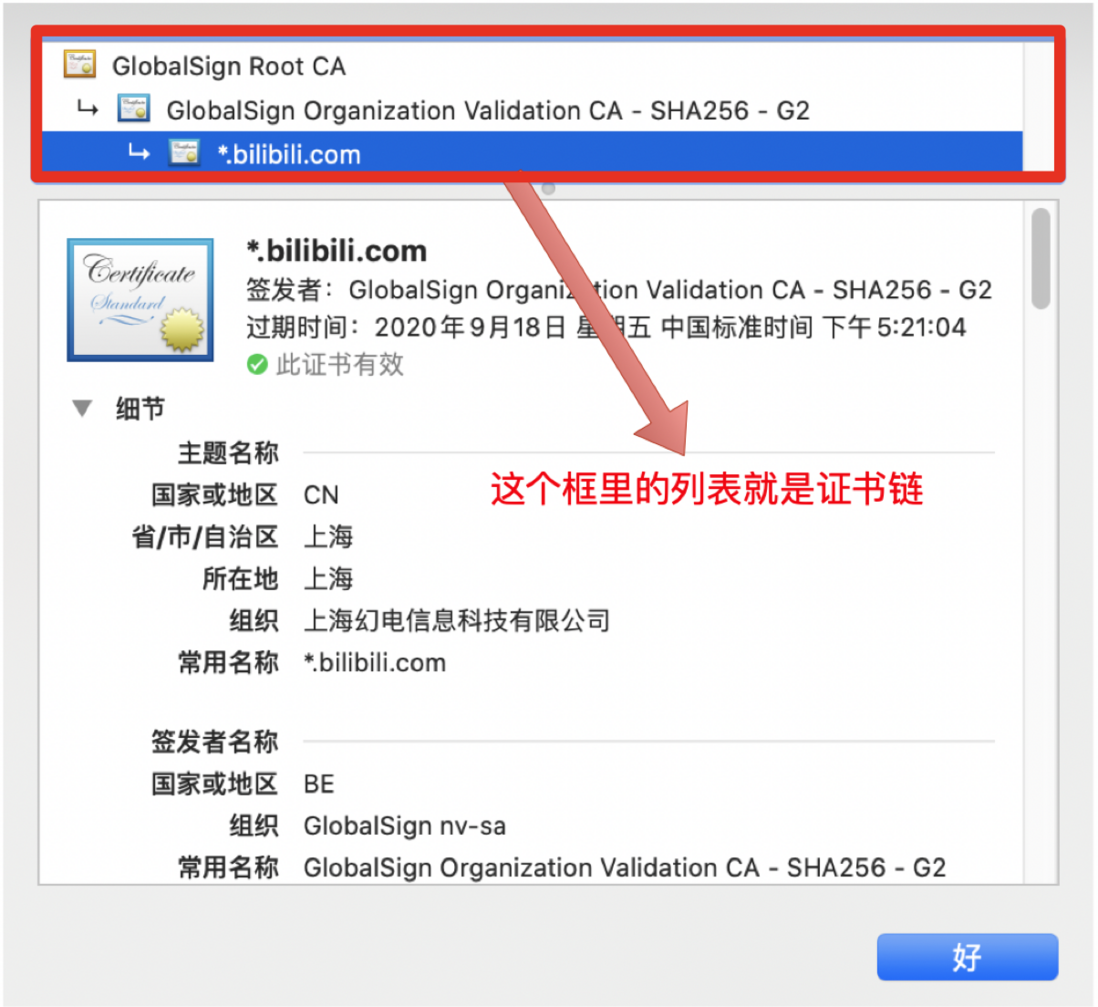
计算机网络面经-HTTPS加密过程
前言 在上篇文章HTTPS详解一中,我已经为大家介绍了 HTTPS 的详细原理和通信流程,但总感觉少了点什么,应该是少了对安全层的针对性介绍,那么这篇文章就算是对HTTPS 详解一的补充吧。还记得这张图吧。 HTTPS 和 HTTP的区别 显然&am…...

2024年最佳硬盘!为台式电脑、NAS等产品量身定做的顶级机械硬盘
机械硬盘(HDD)可能看起来像是古老的技术,但它们仍然在许多地方提供“足够好”的性能,并且它们很容易以同等的价格提供最多的存储空间。 尽管最好的SSD将为你的操作系统和引导驱动器提供最好的体验,并提供比HDD更好的应…...
)
串的匹配算法——BF算法(朴素查找算法)
串的模式匹配:在主串str的pos位置查找子串sub,找到返回下标,没有找到返回-1。 1.BF算法思想 相等则继续比较,不相等则回退;回退是i退到刚才位置的下一个(i-j1);j退到0;利用子串是否…...
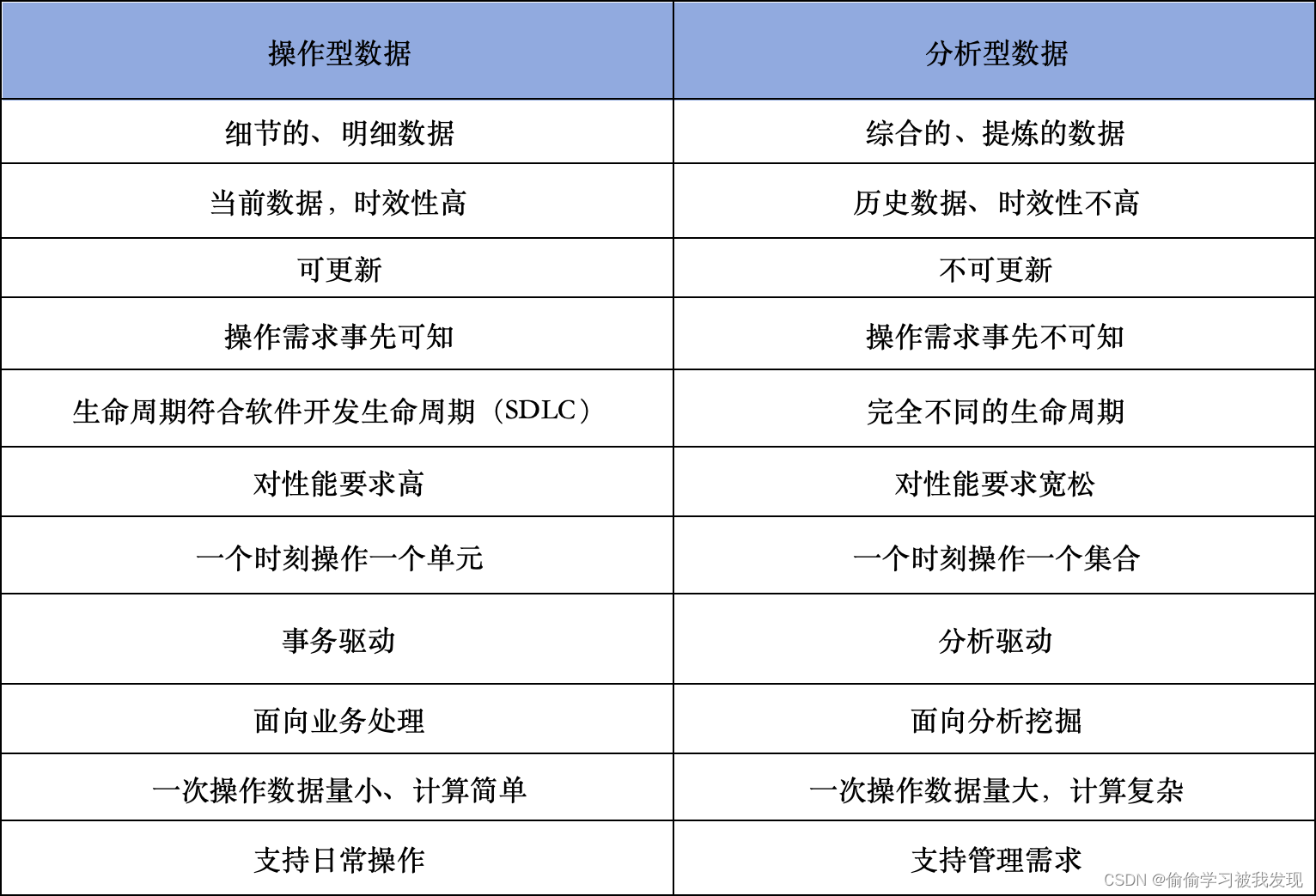
数据处理分类、数据仓库产生原因
个人看书学习心得及日常复习思考记录,个人随笔。 数据处理分类 操作型数据处理(基础) 操作型数据处理主要完成数据的收集、整理、存储、查询和增删改操作等,主要由一般工作人员和基层管理人员完成。 联机事务处理系统ÿ…...

【力扣100】 118.杨辉三角
添加链接描述 思路: 递推公式是[n,x][n-1,x-1][n-1,x] class Solution:def generate(self, numRows: int) -> List[List[int]]:if numRows1:return [[1]]if numRows2:return [[1],[1,1]]res[[1],[1,1]]for i in range(2,numRows): # i代表的是层数的下标&…...
好物周刊#44:现代终端工具
https://github.com/cunyu1943 村雨遥的好物周刊,记录每周看到的有价值的信息,主要针对计算机领域,每周五发布。 一、项目 1. Github-Hosts 通过修改 Hosts 解决国内 Github 经常抽风访问不到,每日更新。 2. 餐饮点餐商城 针对…...

每日五道java面试题之springMVC篇(一)
目录: 第一题. 什么是Spring MVC?简单介绍下你对Spring MVC的理解?第二题. Spring MVC的优点第三题. Spring MVC的主要组件?第四题. 什么是DispatcherServlet?第五题. 什么是Spring MVC框架的控制器? 第一题. 什么是S…...

【GStreamer】basic-tutorial-4:媒体播放状态、跳转seek操作
【目录】郭老二博文之:图像视频汇总 1、示例注释 #include <gst/gst.h>typedef struct _CustomData {GstElement *playbin; /* 本例只有一个元素*/gboolean playing; /* 是否处于播放状态? */gboolean terminate;...
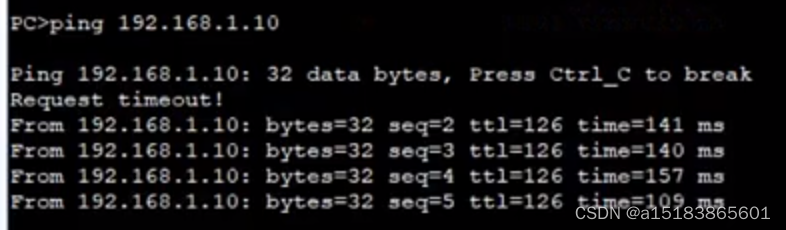
IPSEC VPN 网关模式实验
要求:FW1与FW3建立IPSEC通道,保证10.0.2.0/24网段能访问192.168.1.0/24网段 因为FW1与FW3都处于边界,所以使用网关部署模式来建立IPSEC VPN FW1 这里选择主模式跟隧道模式 FW3与FW1配置类似,与FW1的源目地址反过来,…...

5分钟上手biliTickerBuy:开源B站会员购抢票自动化工具终极指南
5分钟上手biliTickerBuy:开源B站会员购抢票自动化工具终极指南 【免费下载链接】biliTickerBuy b站会员购购票辅助工具 项目地址: https://gitcode.com/GitHub_Trending/bi/biliTickerBuy biliTickerBuy是一款开源免费的B站会员购辅助工具,专为技…...

嵌入式Linux信号量实战:多线程互斥点灯程序设计与实现
1. 项目概述与核心思路最近在整理嵌入式Linux开发笔记时,翻到了一个挺有意思的小项目:用Linux信号量来实现一个互斥的点灯程序。听起来可能有点“杀鸡用牛刀”的感觉,毕竟点个灯用个全局变量或者简单的标志位也能搞定。但这个小项目背后的价值…...

HunterPie完全指南:如何在《怪物猎人世界》中获得实时数据监控优势
HunterPie完全指南:如何在《怪物猎人世界》中获得实时数据监控优势 【免费下载链接】HunterPie-legacy A complete, modern and clean overlay with Discord Rich Presence integration for Monster Hunter: World. 项目地址: https://gitcode.com/gh_mirrors/hu/…...

RIS辅助无人机通信的能效优化与深度强化学习应用
1. 项目概述:RIS辅助无人机通信的能效革命在应急救灾、偏远地区覆盖等场景中,无人机(UAV)通信系统常面临两大核心挑战:一是复杂地形导致的信号遮挡问题,二是无人机有限的续航能力制约了长期作业。传统解决方案如增加中继节点会引入…...

对比直接使用厂商 API 通过 Taotoken 聚合调用的账单清晰度差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 与通过 Taotoken 聚合调用的账单清晰度差异 在集成多个大语言模型到业务中时,开发者通常会面临一…...

专业无人机日志分析工具:UAV Log Viewer 让飞行数据分析更简单高效
专业无人机日志分析工具:UAV Log Viewer 让飞行数据分析更简单高效 【免费下载链接】UAVLogViewer An online viewer for UAV log files 项目地址: https://gitcode.com/gh_mirrors/ua/UAVLogViewer 无人机飞行日志分析是每个飞手和专业团队必须掌握的技能&a…...

3分钟彻底移除Windows Defender:释放30%系统性能的实战指南
3分钟彻底移除Windows Defender:释放30%系统性能的实战指南 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_mirror…...

开源对话机器人平台Dialoqbase:基于RAG与微服务架构的快速部署指南
1. 项目概述:一个开源的对话机器人构建平台最近在折腾AI应用,想自己搭个智能客服或者知识库问答机器人,发现市面上的SaaS服务要么太贵,要么定制性太差。后来在GitHub上翻到了一个叫dialoqbase的开源项目,眼前一亮。这玩…...

第20章:Skill ≠ Prompt——从提示词到可复用技能的范式升级
第20章:Skill ≠ Prompt——从提示词到可复用技能的范式升级 20.1 问题定义:为什么"保存Prompt"不够 很多团队的做法是:把常用的Prompt保存在文档或笔记中,需要时复制粘贴。这看起来合理,但存在三个根本问题: 不可版本化:Prompt是散落的文本片段,没有版本号…...

避坑指南:STM32驱动DHT11温湿度传感器,为什么你的读数总是不准?
STM32驱动DHT11温湿度传感器的五大实战避坑指南 1. 单总线时序的精确控制 DHT11作为典型的单总线设备,对时序控制的要求极为严苛。许多开发者遇到的第一个坑就是未能准确实现协议要求的时序。根据实测数据,DHT11的启动信号需要主机拉低至少18msÿ…...