根据xlsx文件第一列的网址爬虫
selenium+Xpath
在与该ipynb文件同文件下新增一个111.xlsx,第一列放一堆需要爬虫的同样式网页
然后使用selenium+Xpath爬虫
from selenium import webdriver
from selenium.webdriver.common.by import By
import openpyxl
import timedef crawl_data(driver, url):driver.get(url)time.sleep(5) # 等待页面加载# 爬取指定的XPath内容xpath1 = '//*[@id="main"]/div/div/div[2]/div[1]/div/div[1]/div'xpath2 = '//*[@id="main"]/div/div/div[2]/div[1]/div/div[1]/p/span'xpath3 = '//*[@id="descriptionDiv"]/p'xpath4 = '//*[@id="introductionDiv"]/p'content1 = driver.find_element(By.XPATH, xpath1).textcontent2 = driver.find_element(By.XPATH, xpath2).textcontent3 = driver.find_element(By.XPATH, xpath3).textcontent4 = driver.find_element(By.XPATH, xpath4).textreturn content1, content2, content3, content4# 启动Chrome浏览器
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)# 打开Excel文件
file_path = "111.xlsx"
wb = openpyxl.load_workbook(file_path)
ws = wb.active# 获取第一列的网址
urls = [cell.value for cell in ws["A"]]# 逐个处理每个网址
for i, url in enumerate(urls, start=1):print(f"处理第{i}个网址: {url}")url_str = str(url) if url is not None else ""# 爬取数据data1, data2, data3, data4 = crawl_data(driver, url_str)# 写回Excel文件ws.cell(row=i, column=2, value=data1)ws.cell(row=i, column=3, value=data2)ws.cell(row=i, column=4, value=data3)ws.cell(row=i, column=5, value=data4)# 保存Excel文件
wb.save(file_path)# 关闭浏览器
driver.quit()
使用Xpath方法相比css定位的好处:如果页面的层级结构非常复杂,XPath提供了更复杂的选择和过滤方式,可以更灵活地定位元素
相比id、class定位的好处:XPath可以根据元素的属性值进行定位,这在某些情况下很有用,尤其是在没有独特标识符(如ID)的情况下
同样使用selenium其它定位的方法
按ID、类名
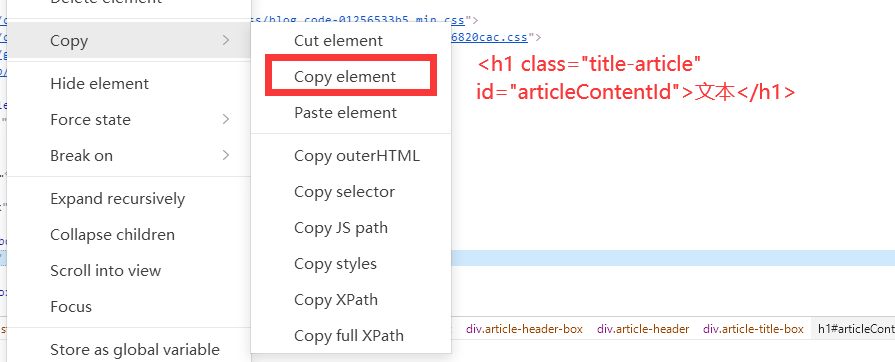
# 以ID定位元素
element_by_id = driver.find_element(By.ID, 'articleContentId')
print("Element by ID:", element_by_id.text)# 以类名定位元素
element_by_class = driver.find_element(By.CLASS_NAME, 'title-article')
print("Element by Class Name:", element_by_class.text)按css选择器
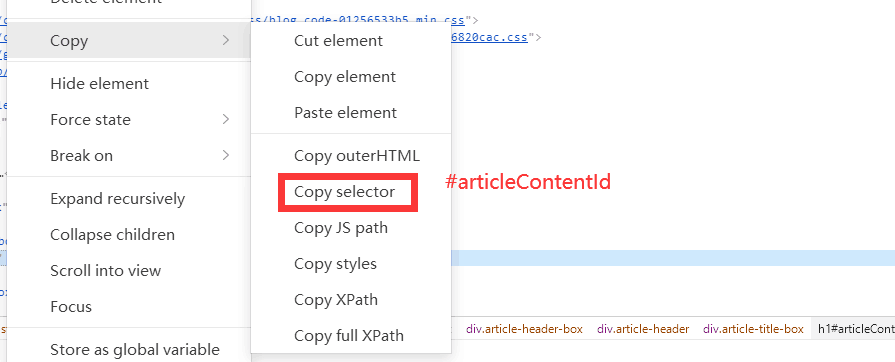
# 以CSS选择器定位元素
element_by_css = driver.find_element(By.CSS_SELECTOR, '#articleContentId')
print("Element by CSS Selector:", element_by_css.text)
不用selenium
Requests + BeautifulSoup
使用BeautifulSoup时,通常通过选择器(CSS选择器)而不是XPath来提取元素
import requests
from bs4 import BeautifulSoupurl = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')# 使用CSS选择器
title_element = soup.select_one('#articleContentId')
title = title_element.text if title_element else "Title not found"paragraphs = soup.select('#articleContentId + div.content p')# 输出结果
print(f"Title: {title}")
for paragraph in paragraphs:print(paragraph.text)
Scrapy
在Scrapy中,可以使用XPath或CSS选择器,具体取决于你的喜好或页面的结构。
XPath
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['https://example.com']def parse(self, response):# 使用XPathtitle = response.xpath('//*[@id="articleContentId"]/text()').get()paragraphs = response.xpath('//*[@id="articleContentId"]/following-sibling::div[@class="content"]/p/text()').getall()# 输出结果print(f"Title: {title}")for paragraph in paragraphs:print(paragraph)
css
import scrapyclass MySpider(scrapy.Spider):name = 'myspider'start_urls = ['https://example.com']def parse(self, response):# 使用CSS选择器title = response.css('#articleContentId::text').get()paragraphs = response.css('#articleContentId + div.content p::text').getall()# 输出结果print(f"Title: {title}")for paragraph in paragraphs:print(paragraph)
Pyppeteer / Playwright
使用Pyppeteer或Playwright时,你可以通过JavaScript在页面上执行脚本来获取数据,而不是直接使用XPath
XPath
from pyppeteer import launchasync def crawl_data(url):browser = await launch()page = await browser.newPage()await page.goto(url)# 使用JavaScript执行脚本获取内容title = await page.evaluate('document.evaluate("//*[@id=\"articleContentId\"]", document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue.textContent')paragraphs = await page.evaluate('Array.from(document.evaluate("//*[@id=\"articleContentId\"]//p", document, null, XPathResult.ORDERED_NODE_SNAPSHOT_TYPE, null)).map(p => p.textContent)')# 输出结果print(f"Title: {title}")for paragraph in paragraphs:print(paragraph)await browser.close()# 使用asyncio来运行异步代码
import asyncio
asyncio.get_event_loop().run_until_complete(crawl_data('https://example.com'))
element选择器
Element选择器实际上是通过HTML元素的标签名来选择元素,而不是通过ID或类名。
HTML元素的标签名就是元素的名称,通常是由尖括号括起来的部分。下述h1、p、a就是HTML元素的标签名
<h1>这是一个标题</h1>
<p>这是一个段落</p>
<a href="https://www.example.com">这是一个链接</a>
所以,如果你想使用element选择器,你可以这样修改代码:
from pyppeteer import launchasync def crawl_data(url):browser = await launch()page = await browser.newPage()await page.goto(url)# 使用JavaScript执行脚本获取内容title = await page.evaluate('document.querySelector("h1#articleContentId").textContent')paragraphs = await page.evaluate('Array.from(document.querySelector("h1#articleContentId + div.content").querySelectorAll("p")).map(p => p.textContent)')# 输出结果print(f"Title: {title}")for paragraph in paragraphs:print(paragraph)await browser.close()# 使用asyncio来运行异步代码
import asyncio
asyncio.get_event_loop().run_until_complete(crawl_data('https://example.com'))
在这个例子中,我们使用了document.querySelector("h1#articleContentId")来选择ID为articleContentId的h1元素,以及document.querySelector("h1#articleContentId + div.content").querySelectorAll("p")来选择与该h1元素相邻的div元素内的所有p元素。
css
from pyppeteer import launchasync def crawl_data(url):browser = await launch()page = await browser.newPage()await page.goto(url)# 使用JavaScript执行脚本获取内容title = await page.evaluate('document.querySelector("#articleContentId").textContent')paragraphs = await page.evaluate('Array.from(document.querySelectorAll("#articleContentId p")).map(p => p.textContent)')# 输出结果print(f"Title: {title}")for paragraph in paragraphs:print(paragraph)await browser.close()# 使用asyncio来运行异步代码
import asyncio
asyncio.get_event_loop().run_until_complete(crawl_data('https://example.com'))
相关文章:
根据xlsx文件第一列的网址爬虫
seleniumXpath 在与该ipynb文件同文件下新增一个111.xlsx,第一列放一堆需要爬虫的同样式网页 然后使用seleniumXpath爬虫 from selenium import webdriver from selenium.webdriver.common.by import By import openpyxl import timedef crawl_data(driver, url)…...

【Linux】 yum —— Linux 的软件包管理器
Linux 的软件包管理器 yum yum 是什么什么是软件包查看软件包 yum 命令行工具yum 配置文件yum 凭什么可以支持下载呢?yum 生态yum 社区yum 的故障排除和资源支持yum 的持续集成和持续交付 yum 是什么 Yum(Yellowdog Updater Modified)是一个…...
及部分求值)
函数柯里化(function currying)及部分求值
函数柯里化(function currying) currying又称部分求值。一个currying的函数首先会接受一些参数,接受了这些参数之后,该函数并不会立即求值,而是继续返回另外一个函数,刚才传入的参数在函数形成的闭包中被保…...

R语言简介、环境与基础语法及注释
R语言是一种功能强大的开源统计分析语言和编程环境。它提供了丰富的数据处理、数据可视化和统计分析函数,适用于各种数据分析和建模任务。 R语言的环境主要包括R编程环境和RStudio集成开发环境(IDE)。R编程环境是R语言的核心,它提…...

React报错 之 Objects are not valid as a React child
原文链接: 1、React报错之Objects are not valid as a React child 2、Objects are not valid as a React child error [Solved] 作者:Borislav Hadzhiev 以下文中涉及到的链接均来自于该作者,他写了很多相关的文章,可以多看看他的…...
看一看阿里云,如何把抽象云概念,用可视化表达出来。
云数据库RDS_关系型数据库 云数据库RDS_关系型数据库 专有宿主机 云数据库RDS_关系型数据库_MySQL源码优化版 内容协作平台CCP-企业网盘协同办公-文件实时共享...

软考笔记--系统架构评估
系统架构评估是在对架构分析、评估的基础上,对架构策略的选取进行决策。它利用数据或逻辑分析技术,针对系统的一致性,正确性,质量属性,规划结果等不同方面,提供描述性,预测性和指令性的分析结果…...

AI产品摄影丨香水
AI电商产品拍摄丨(可指定产品) 均为概念图 可换产品 可指定产品,可换logo 工具:StartAI 搭配“手机摄影”风格使用效果更佳哦 咒语:anha perfume in bottle on stone surface, in the style of everyday american…...

Linux系统——tee命令
目录 一、命令简介 二、命令使用 1.命令帮助 2.查看块设备列表并记录到文件存档 3.重复多次标准输入内容 4.将文件复制多份 5.静默输出到文件 6.使用追加方式写入文件 7.将错误信息也输出到文件 8.直接通过键盘往文件输入 9.参数使用案例 三、选项 一、命令简介 t…...
Java agent技术的注入利用与避坑点
什么是Java agent技术? Java代理(Java agent)是一种Java技术,它允许开发人员在运行时以某种方式修改或增强Java应用程序的行为。Java代理通过在Java虚拟机(JVM)启动时以"代理"(agent…...

Linux每日练习
第一部分 1.打开桌面的主文件夹,在图片文件夹下新建一个名为111的文件夹,在视频文件夹下创建一个名为222的文件夹 [rootxcz7 desk]# mkdir -p ./pic/111 [rootxcz7 desk]# mkdir -p ./video/2222.在桌面打开终端,先切换到根目录下ÿ…...
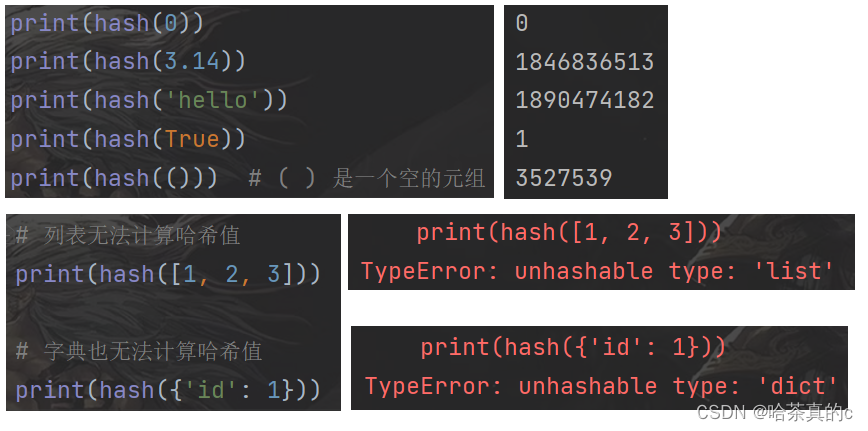
【Python】6. 基础语法(4) -- 列表+元组+字典篇
列表和元组 列表是什么, 元组是什么 编程中, 经常需要使用变量, 来保存/表示数据. 如果代码中需要表示的数据个数比较少, 我们直接创建多个变量即可. num1 10 num2 20 num3 30 ......但是有的时候, 代码中需要表示的数据特别多, 甚至也不知道要表示多少个数据. 这个时候,…...
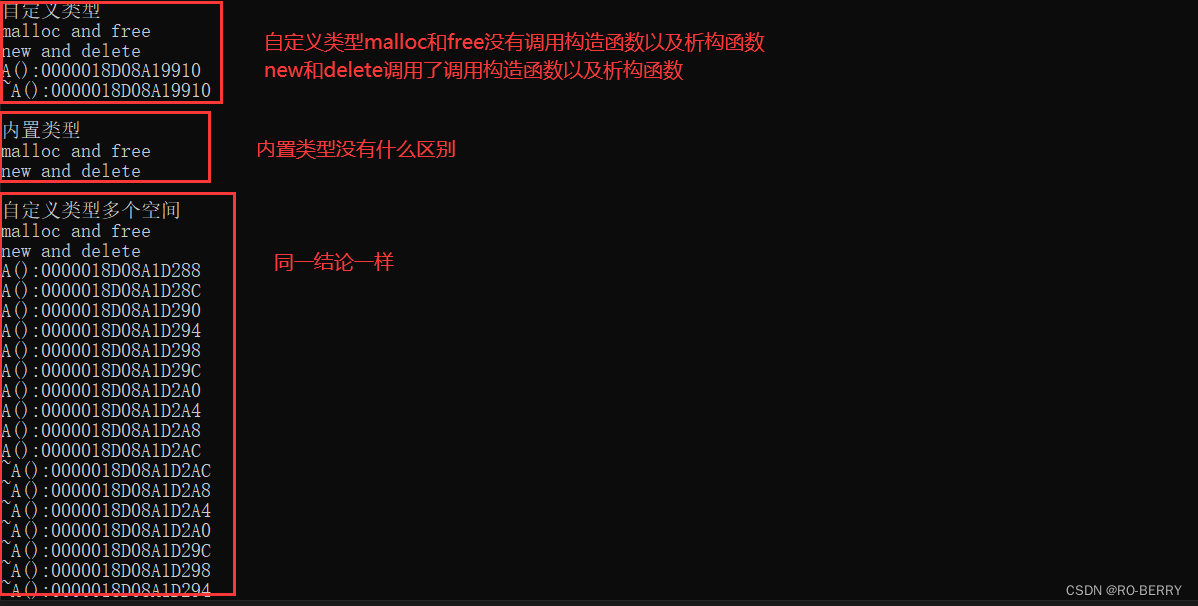
【C++庖丁解牛】C++内存管理 | new和delete的使用以及使用原理
📙 作者简介 :RO-BERRY 📗 学习方向:致力于C、C、数据结构、TCP/IP、数据库等等一系列知识 📒 日后方向 : 偏向于CPP开发以及大数据方向,欢迎各位关注,谢谢各位的支持 目录 1. C/C内存分布2. C语…...

go调用 c++中数组指针相关
要在Go语言中调用C编译的DLL(动态链接库)并传递数组,你需要遵循以下步骤: 编写C代码:首先,你需要有一个C的DLL,它提供了你想要在Go中调用的函数。为了确保Go可以调用它,你需要使用C…...

NTFS Disk by Omi NTFS for mac v1.1.4中文版
NTFS Disk by Omi NTFS for Mac:NTFS文件系统的无缝桥梁 软件下载:NTFS Disk by Omi NTFS for mac v1.1.4中文版 🌐 跨平台访问,文件无阻 NTFS Disk by Omi NTFS for Mac 为您的Mac提供了对NTFS文件系统的无缝访问。无论您是在Win…...
Arduino应用开发——使用GUI-Guider制作LVGL UI并导入ESP32运行
Arduino应用开发——使用GUI-Guider制作LVGL UI并导入ESP32运行 目录 Arduino应用开发——使用GUI-Guider制作LVGL UI并导入ESP32运行前言1 使用GUI-Guider设计UI1.1 创建工程1.2 设计UI 2 ESP工程导入UI2.1 移植LVGL2.2 移植UI文件2.3 调用UI文件2.4 烧录测试 结束语 前言 GU…...

前端WebRTC局域网1V1视频通话
基本概念 WebRTC(Web Real-Time Communications) 网络实时通讯,它允许网络应用或者站点,在不借助中间媒介的情况下,建立点对点(Peer-to-Peer)的连接,实现视频流和音频流或者其他任…...

设计模式之构建者模式
构建者模式(Builder) 定义 将一个复杂对象的构建与其表示分离,使得同样的构建过程可以创建不同的表示 使用场景 主要角色 产品 Product建造者接口 Builder具体的建造者 Concrete Builder指挥者 Director:组织构建过程 示例代码 Data p…...
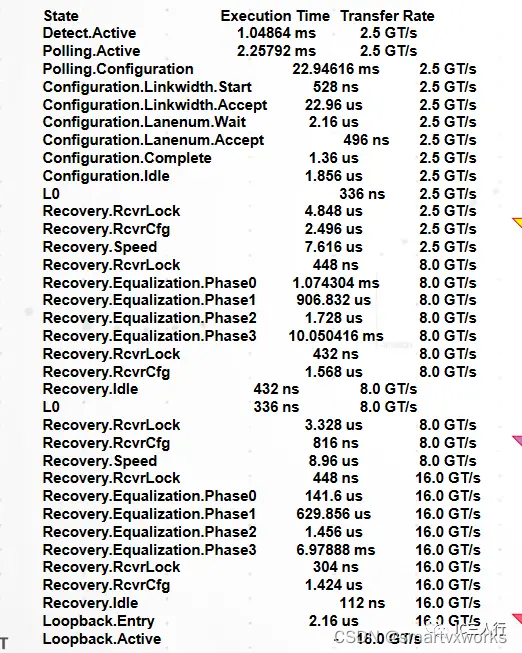
【PCIe 链路训练】之均衡(equalization)
1、概述 这篇文章简单介绍一下PCIE phy的均衡原理和过程,USB phy,ethernet phy这些高速的串行serdes也有相同或者相似的结构。可以不用太关注其中的细节,等到debug的时候可以查询协议,但是需要了解这个故事讲的大概内容。整个equalization过程是controller和phy一起配合完成…...

P1059 [NOIP2006 普及组] 明明的随机数
题目描述 明明想在学校中请一些同学一起做一项问卷调查,为了实验的客观性,他先用计算机生成了 N 个 1 到 1000 之间的随机整数 (N≤100),对于其中重复的数字,只保留一个,把其余相同的数去掉,不同的数对应着…...

【20年SRE亲授】Docker 27存储驱动黄金配置清单:仅需修改3个参数,即可规避92%的生产环境存储崩坏事故
第一章:Docker 27存储驱动演进与生产事故根因图谱Docker 存储驱动是容器镜像分层、写时复制(Copy-on-Write)及运行时文件系统隔离的核心机制。自 Docker 1.0 引入 aufs 起,历经 overlay、overlay2、btrfs、zfs、devicemapper 等十…...

5个创新方案重新定义GitHub中文化插件:从界面翻译到深度本地化体验
5个创新方案重新定义GitHub中文化插件:从界面翻译到深度本地化体验 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese GitHub…...

从map到base_link:深入解析ROS激光SLAM中的坐标变换链与数据流
1. 激光SLAM中的坐标系基础认知 第一次接触ROS激光SLAM时,我被各种坐标系搞得晕头转向。直到有次调试机器人导航时,发现地图总是偏移,才真正意识到坐标系理解的重要性。在激光SLAM系统中,数据就像接力赛跑,需要经过多个…...
)
AD9361 LVDS接口时序详解:手把手教你搞定FPGA与射频收发器的数据对齐(附时序图分析)
AD9361 LVDS接口时序深度解析:从理论到实战的FPGA数据对齐指南 当射频工程师第一次将AD9361与FPGA平台对接时,往往会被LVDS接口的时序问题困扰——明明SPI配置正确,示波器上的差分信号也看似完美,但FPGA接收到的数据却总是出现错位…...

redis_version:6.2.21默认自带布隆过滤器吗?
结论:不,Redis 6.2.21 官方原生版本(Open Source)默认【不包含】布隆过滤器(Bloom Filter)。 这是一个非常常见的误区。布隆过滤器是 RedisBloom 模块的功能,而不是 Redis 核心代码的一部分。一…...

7个技巧彻底释放你的硬件潜能:原神帧率解锁工具深度解析
7个技巧彻底释放你的硬件潜能:原神帧率解锁工具深度解析 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 当你的显卡和显示器都支持144Hz甚至更高刷新率,而游戏却被…...

告别点灯:用STM32CubeIDE和HAL库,给你的SSD1306 OLED做个动态仪表盘
用STM32CubeIDE和HAL库打造SSD1306 OLED动态仪表盘 在嵌入式开发中,OLED屏幕因其高对比度、低功耗和快速响应等特性,成为数据显示的理想选择。本文将带你从零开始,使用STM32CubeIDE和HAL库,为SSD1306 OLED屏幕开发一个功能丰富的动…...
)
微信小程序开发:wx.request实战避坑指南(从配置域名到调试技巧)
微信小程序网络请求全流程实战:从域名配置到高效调试 最近在帮几个团队做小程序项目复盘时,发现80%的网络请求问题都集中在域名配置和调试环节。有个团队甚至因为没搞清备案流程,导致项目延期两周。本文将用真实项目经验,带你系统…...

易语言大漠多线程避坑指南:免注册调用时线程崩溃的3个原因
易语言大漠多线程开发实战:深度解析免注册调用的稳定性陷阱 在易语言结合大漠插件进行自动化开发的场景中,免注册调用方式因其部署便捷性备受青睐。但当开发者尝试将单线程方案扩展到多线程环境时,往往会遭遇程序随机崩溃、对象创建失败等棘手…...

python bcrypt
# 聊聊Python里的加密库:PyCryptodome 今天想和大家分享一个在Python加密领域里经常被用到的库,叫PyCryptodome。如果你在项目里处理过密码、加密文件或者设计过安全通信,很可能已经和它打过交道了。这个库表面上看起来只是一个工具集&#x…...