docker本地搭建spark yarn hive环境
docker本地搭建spark yarn hive环境
- 前言
- 软件版本
- 准备工作
- 使用说明
- 构建基础镜像
- spark on yarn模式
- 构建on-yarn镜像
- 启动on-yarn集群
- 手动方式
- 自动方式
- spark on yarn with hive(derby server)模式
- 构建on-yarn-hive镜像
- 启动on-yarn-hive集群
- 手动方式
- 自动方式
- 常用示例
- spark执行sh脚本
- Java远程提交Yarn任务
- maven部分依赖
- java代码
- 参考资料
前言
为了学习大数据处理相关技术,需要相关软件环境作为支撑实践的工具。而这些组件的部署相对繁琐,对于初学者来说不够友好。本人因为工作中涉及到该部分内容,通过参考网上的资料,经过几天摸索,实现了既简单又快捷的本地环境搭建方法。特写下该文章,加以记录,以期能够给初学者一些参考和帮助。
本文主要介绍基于docker在本地搭建spark on yarn以及hive(采用derby服务模式)。为什么没有使用mysql作为hive的metastore呢?因为既然是作为学习和测试用的环境,尽量让其保持简单,derby数据库不需要单独配置,直接启动即可使用,足够轻量和简便。
完整的代码已经提交到gitee spark-on-yarn-hive-derby
软件版本
| 组件 | 版本 |
|---|---|
| spark镜像 | bitnami/spark:3.1.2 |
| hadoop | 3.2.0 |
| hive | 3.1.2 |
| derby | 10.14.2.0 |
准备工作
- 下载gitee代码 https://gitee.com/crazypandariy/spark-on-yarn-hive-derby
- 下载derby(https://archive.apache.org/dist/db/derby/db-derby-10.14.2.0/db-derby-10.14.2.0-bin.tar.gz) ,移动到spark-on-yarn-hive-derby-master目录(和start-hadoop.sh处于同级目录中)
- 下载hadoop(https://archive.apache.org/dist/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz),移动到spark-on-yarn-hive-derby-master目录
使用说明
config/workers中配置的是作为工作节点的hostname,这个必须要和docker-compose-.yml中定义的hostname;保持一致
config/ssh_config用于免密登录
config中涉及到hostname的配置文件有core-site.xml、hive-site.xml、spark-hive-site.xml、yarn-site.xml,一定要和docker-compose-.yml中定义的hostname保持一致;
- 构建基础镜像
- 构建on-yarn 镜像
- 构建on-yarn-hive镜像
构建基础镜像
采用spark成熟镜像方案 bitnami/spark:3.1.2 作为原始镜像,在此基础上安装openssh,制作免密登录的基础镜像。由于master和worker节点均基于该基础镜像,其中的ssh密钥均相同,可以简化安装部署。
docker build -t my/spark-base:3.1.2 base/Dockerfile .
spark on yarn模式
构建on-yarn镜像
docker build -t my/spark-hadoop:3.1.2 -f on-yarn/Dockerfile .
启动on-yarn集群
手动方式
# 创建集群
docker-compose -f on-yarn/docker-compose-manul.yml -p spark up -d
# 启动hadoop
docker exec -it spark-master-1 sh /opt/start-hadoop.sh# 停止集群
docker-compose -f on-yarn/docker-compose-manul.yml -p spark stop
# 删除集群
docker-compose -f on-yarn/docker-compose-manul.yml -p spark down# 启动集群
docker-compose -f on-yarn/docker-compose-manul.yml -p spark start
# 启动hadoop
docker exec -it spark-master-1 sh /opt/start-hadoop.sh
自动方式
# 创建集群
docker-compose -f on-yarn/docker-compose-auto.yml -p spark up -d
# 停止集群
docker-compose -f on-yarn/docker-compose-auto.yml -p spark stop
# 启动集群
docker-compose -f on-yarn/docker-compose-auto.yml -p spark start
# 删除集群
docker-compose -f on-yarn/docker-compose-auto.yml -p spark down
spark on yarn with hive(derby server)模式
构建on-yarn-hive镜像
docker build -t my/spark-hadoop-hive:3.1.2 -f on-yarn-hive/Dockerfile .
启动on-yarn-hive集群
手动方式
# 创建集群
docker-compose -f on-yarn-hive/docker-compose-manul.yml -p spark up -d
# 启动hadoop
docker exec -it spark-master-1 sh /opt/start-hadoop.sh
# 启动hive
docker exec -it spark-master-1 sh /opt/start-hive.sh# 停止集群
docker-compose -f on-yarn-hive/docker-compose-manul.yml -p spark stop
# 删除集群
docker-compose -f on-yarn-hive/docker-compose-manul.yml -p spark down# 启动集群
docker-compose -f on-yarn-hive/docker-compose-manul.yml -p spark start
# 启动hadoop
docker exec -it spark-master-1 sh /opt/start-hadoop.sh
# 启动hive
docker exec -it spark-master-1 sh /opt/start-hive.sh
自动方式
# 创建集群
docker-compose -f on-yarn-hive/docker-compose-auto.yml -p spark up -d
# 停止集群
docker-compose -f on-yarn-hive/docker-compose-auto.yml -p spark stop
# 启动集群
docker-compose -f on-yarn-hive/docker-compose-auto.yml -p spark start
# 删除集群
docker-compose -f on-yarn-hive/docker-compose-auto.yml -p spark down
常用示例
spark执行sh脚本
spark-shell --master yarn << EOF
// 脚本内容
// 示例
val data = Array(1,2,3,4,5)
val distData = sc.parallelize(data)
val sum = distData.reduce((a,b)=>a+b)
println("Sum: "+sum)
EOF
Java远程提交Yarn任务
- 进入master容器,创建demo表,命令
hive -e "create table demo(name string)" - 创建maven项目,将core-site.xml yarn-site.xml hdfs-site.xml hive-site.xml等文件拷贝到src/main/resources
- 将 local-spark-worker1 和 local-spark-master 指向本地虚拟网络适配器的IP地址
例如,我用的是windows系统,则使用SwitchHosts软件,修改上述hostname指向的IP地址,其中192.168.138.1是虚拟网络适配器的IP
192.168.138.1 local-spark-worker1
192.168.138.1 local-spark-master
上传spark依赖jar包
hdfs dfs -mkdir -p /spark/jars
hdfs dfs -put -f /opt/bitnami/spark/jars/* /spark/jars
maven部分依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.1.2</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-yarn_2.12</artifactId><version>3.1.2</version></dependency><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter</artifactId><version>5.9.1</version><scope>test</scope></dependency>
java代码
以cluster模式提交spark-sql;浏览器输入http://localhost:9870打开hdfs管理界面,创建目录/user/my,进入该目录并上传spark-sql-cluster.jar
package org.demo.spark;import org.apache.spark.SparkConf;
import org.apache.spark.deploy.yarn.Client;
import org.apache.spark.deploy.yarn.ClientArguments;
import org.junit.jupiter.api.Test;public class SparkOnYarnTest {@Testpublic void yarnApiSubmit() {// prepare arguments to be passed to // org.apache.spark.deploy.yarn.Client objectString[] args = new String[] {"--jar","hdfs:///user/my/spark-sql-cluster.jar","--class", "org.apache.spark.sql.hive.cluster.SparkSqlCliClusterDriver","--arg", "spark-internal","--arg", "-e","--arg", "\\\"insert into demo(name) values('zhangsan')\\\""};// identify that you will be using Spark as YARN mode
// System.setProperty("SPARK_YARN_MODE", "true");// create an instance of SparkConf objectString appName = "Yarn Client Remote App";SparkConf sparkConf = new SparkConf();sparkConf.setMaster("yarn");sparkConf.setAppName(appName);sparkConf.set("spark.submit.deployMode", "cluster");sparkConf.set("spark.yarn.jars", "hdfs:///spark/jars/*.jar");sparkConf.set("spark.hadoop.yarn.resourcemanager.hostname", "local-spark-master");sparkConf.set("spark.hadoop.yarn.resourcemanager.address", "local-spark-master:8032");sparkConf.set("spark.hadoop.yarn.resourcemanager.scheduler.address", "local-spark-master:8030");// create ClientArguments, which will be passed to ClientClientArguments cArgs = new ClientArguments(args);// create an instance of yarn Client clientClient client = new Client(cArgs, sparkConf, null);// submit Spark job to YARNclient.run();}
}
参考资料
使用 Docker 快速部署 Spark + Hadoop 大数据集群
SparkSQL 与 Hive 整合关键步骤解析
spark-sql-for-cluster
相关文章:

docker本地搭建spark yarn hive环境
docker本地搭建spark yarn hive环境 前言软件版本准备工作使用说明构建基础镜像spark on yarn模式构建on-yarn镜像启动on-yarn集群手动方式自动方式 spark on yarn with hive(derby server)模式构建on-yarn-hive镜像启动on-yarn-hive集群手动方式自动方式 常用示例spark执行sh脚…...

每日学习笔记:C++ 11的Tuple
#include <tuple> Tuple介绍(不定数的值组--可理解为pair的升级版) 定义 创建 取值 初始化 获取tuple元素个数、获取tuple某元素类型、将2个tuple类型串接为1个新tuple类型...

MongoDB聚合运算符;$dateToParts
$dateToParts聚合运算符将日期表达式拆分成多个字段放在一个文档返回,属性有year、month、day、hour、minute、second和millisecond。如果iso8601属性设置为true,返回的各部分用ISO周日期返回,属性分别是:isoWeekYear、isoWeek、i…...

Spring MVC RequestMappingHandlerAdapter原理解析
在Spring MVC框架中,RequestMappingHandlerAdapter是一个核心的组件,负责将请求映射到具体的处理器方法上,并调用这些方法来处理请求。其中,invokeHandlerMethod方法是这个适配器中的一个关键方法,它负责实际调用处理器…...

反射整理学习
目录 1、反射介绍 2、反射API 2.1 获取类对应的字节码的对象(三种) 2.2 常用方法 3、反射的应用 3.1 创建 : 测试物料类 3.2 获取类对象 3.3 获取成员变量 3.4 通过字节码对象获取类的成员方法 3.5 通过字节码对象获取类的构造方法 4、创建对象…...

JavaScript 运算规则详解
在 JavaScript 中,运算规则是非常重要的基础知识,了解这些规则可以帮助我们正确地编写代码并避免一些常见的错误。本教程将详细介绍 JavaScript 中的各种运算规则,包括基本运算符、类型转换、运算优先级等内容。 1. 基本运算符 JavaScript …...

C++篇 语 句
到目前为止,我们只见过两种语句: return 语句和表达式语句。根据语句对执行顺 序的影响,C 语言其余语句大多属于以下 3 大类。 选择语句: if 语句和 switch 语句。循环语句: while 语句, do...while 语句和…...

简洁的在线观影开源项目
公众号:【可乐前端】,每天3分钟学习一个优秀的开源项目,分享web面试与实战知识。 每天3分钟开源 hi,这里是每天3分钟开源,很高兴又跟大家见面了,今天介绍的开源项目简介如下: 仓库名࿱…...

VB超级模块函数VB读写记事本-防止乱码支持UTF-8和GB2312编码
Private Sub Command1_Click() Writein “C:\Users\Administrator\Desktop\1.txt”, “文本文内容” End Sub Private Sub Form_Load() Text1 ReadANSI(“C:\Users\Administrator\Desktop\1.txt”) Text2 ReadUTF8(“C:\Users\Administrator\Desktop\1.txt”) End Sub 写入…...
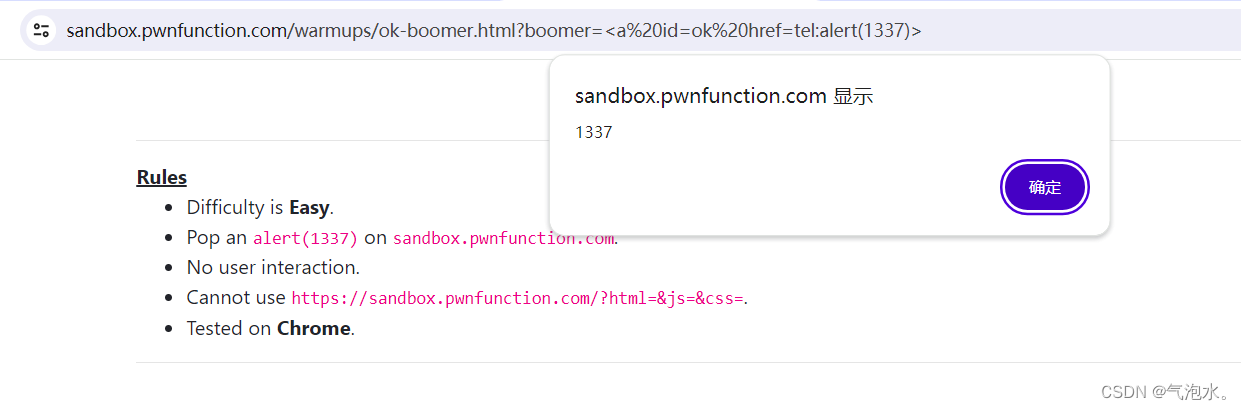
XSS靶场-DOM型初级关卡
一、环境 XSS靶场 二、闯关 1、第一关 先看源码 使用DOM型,获取h2标签,使用innerHTML将内容插入到h2中 我们直接插入<script>标签试一下 明显插入到h2标签中了,为什么不显示呢?看一下官方文档 尽管插入进去了࿰…...
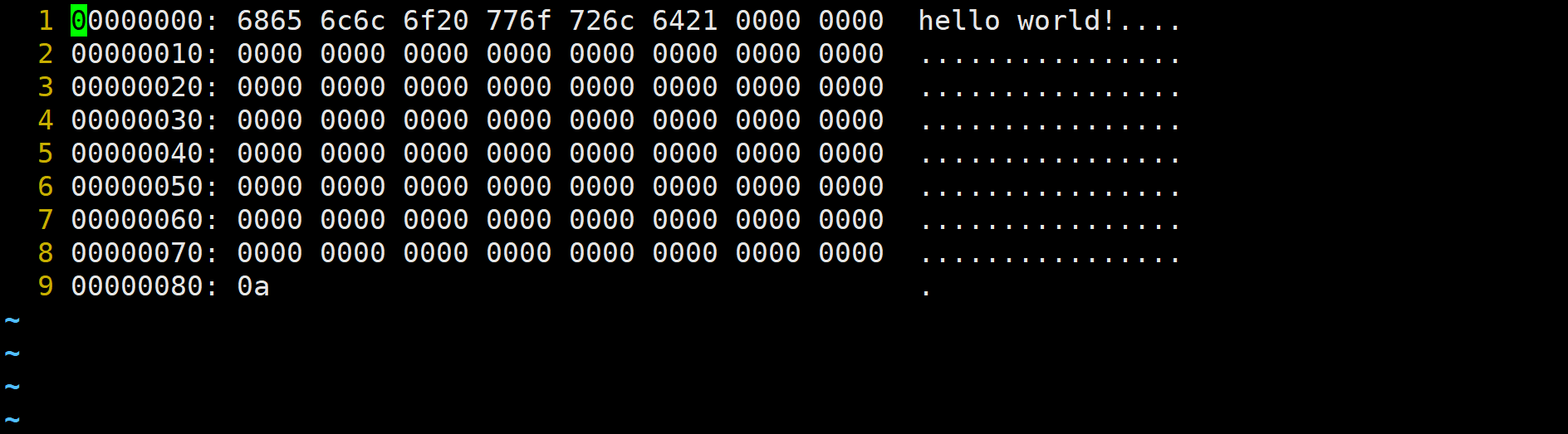
【嵌入式高级C语言】10:C语言文件
文章目录 1 文件的概述1.1 文件分类(存储介质)1.2 磁盘文件分类(存储方式)1.3 二进制文件和文本文件的区别 2 文件缓冲区3 文件指针4 文件的API4.1 打开文件4.2 关闭文件4.3 重新定位流4.3.1 fseek4.3.2 ftell4.3.3 rewind 4.4 字…...

创建数据表
Oracle从入门到总裁:https://blog.csdn.net/weixin_67859959/article/details/135209645 如果要进行数据表的创建 create table 表名称 (列名称 类型 [DEFAULT 默认值 ] ,列名称 类型 [DEFAULT 默认值 ] ,列名称 类型 [DEFAULT 默认值 ] ,...列名称 类型 [DEFAULT 默认值 ] )…...
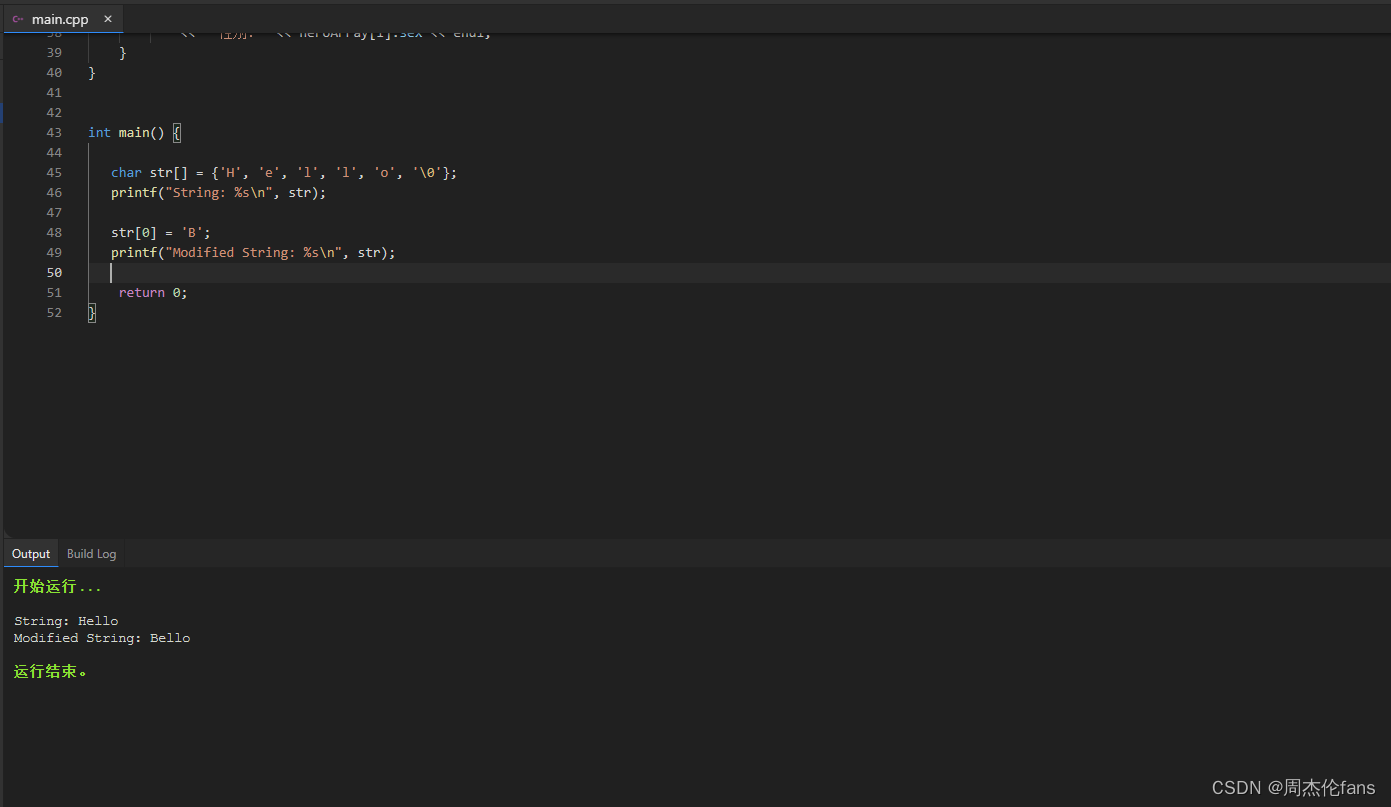
C语言字符串型常量
在C语言中,字符串型常量是由一系列字符组成的常量。字符串常量在C中以双引号(")括起来,例如:“Hello, World!”。字符串常量在C中是不可变的,也就是说,一旦定义,就不能修改其内…...

计算机网络 八股
计算机网络体系结构 OSI:物理层、数据链路层、网络层、运输层、会话层、表示层、应用层...

深入了解 Jetpack Compose 中的 Modifier
Jetpack Compose 是 Android 中用于构建用户界面的现代化工具包。其中,Modifier 是一个非常重要的概念,它允许我们对 UI 组件进行各种样式和布局的调整。在本篇博客中,我们将深入了解 Modifier,以及如何在 Compose 中使用它。 什…...

【数据库】聚合函数|group by分组|having|where|排序|函数 关键字的使用
目录 一、聚合函数 1、max() 2、min() 3、avg() 4、sum() 5、count() 二、group by 分组汇总 一般聚合函数配合着group by(分组)语句进行使用 把一组的数据放到一起,再配合聚合函数进行使用 三、having having语句 做筛选的 四、where和having的作用以及区…...
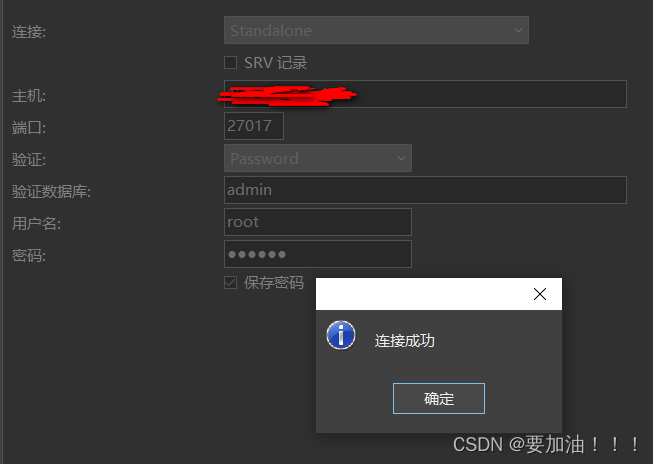
docker安装mongoDB及使用
一.mongodb是什么? MongoDB是一个NoSQL的非关系型数据库 ,支持海量数据存储,高性能的读写 1.mongo的体系结构 SQL术语/概念MongoDB术语/概念解释/说明databasedatabase数据库tablecollection数据库表/集合rowdocument数据记录行/文档colum…...

Linux 之五:权限管理(文件权限和用户管理)
1. 文件权限 在Linux系统中,文件权限是一个非常基础且重要的安全机制。它决定了用户和用户组对文件或目录的访问控制级别。 每个文件或目录都有一个包含9个字符的权限模式,这些字符分为三组,每组三个字符,分别对应文件所有者的权限…...

基于YOLOv8深度学习的葡萄病害智能诊断与防治系统【python源码+Pyqt5界面+数据集+训练代码】深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...

MySQL 在聚合函数查询的结构中继续过滤
HAVING HAVING 关键字和 WHERE 关键字都可以用来过滤数据,且 HAVING 支持 WHERE 关键字中所有的操作符和语法,如果想要从 GROUP BY 分组中进行筛选的话,不是用 WHERE 而是使用 HAVING 来进行聚合函数的筛选。 语法 SELECT <列名1>, <列名2>,…...

如何快速掌握Path of Building:流放之路离线构筑模拟器的终极指南
如何快速掌握Path of Building:流放之路离线构筑模拟器的终极指南 【免费下载链接】PathOfBuilding Offline build planner for Path of Exile. 项目地址: https://gitcode.com/gh_mirrors/pat/PathOfBuilding 还在为《流放之路》复杂的角色构筑而烦恼吗&…...

Vue3项目里嵌入Luckysheet在线表格,从导入Excel到导出下载的完整实现
Vue3深度整合Luckysheet实战:从Excel导入到导出下载的完整解决方案 在数据密集型的后台管理系统开发中,在线表格编辑功能已成为提升用户体验的关键组件。Luckysheet作为国产开源电子表格库,以其轻量级和高度可定制性赢得了开发者的青睐。本文…...

告别手动MIGO!用Python脚本批量调用BAPI_GOODSMVT_CREATE实现物料凭证自动化
Python自动化SAP物料凭证:告别MIGO手工操作的终极方案 每天面对数百条物料移动记录,在SAP系统中重复点击MIGO界面,填写相同的字段,检查数据准确性——这可能是许多SAP运维人员和业务顾问的日常噩梦。当企业规模扩大,物…...

ITK-SNAP医学图像分割:当传统算法遇上现代交互的深度技术融合
ITK-SNAP医学图像分割:当传统算法遇上现代交互的深度技术融合 【免费下载链接】itksnap ITK-SNAP medical image segmentation tool 项目地址: https://gitcode.com/gh_mirrors/it/itksnap 你是否曾面对复杂的医学影像数据,在手动标注的耗时与自动…...
)
别再手动推导了!用MATLAB的firpm函数5分钟搞定数字微分器设计(附完整代码)
5分钟用MATLAB打造高精度数字微分器:从理论到实战的firpm函数指南 在信号处理领域,数字微分器就像一位隐形的工程师,默默完成着速度估计、边缘检测、生物医学信号分析等关键任务。传统手动设计方法不仅耗时费力,还容易在系数计算和…...

终极指南:Snap.Hutao - 让原神玩家效率翻倍的Windows桌面工具箱
终极指南:Snap.Hutao - 让原神玩家效率翻倍的Windows桌面工具箱 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitHub_Trending/sn…...

OAI基站配置文件命名规则全解析:从gnb.sa.band78到usrpb210,新手也能看懂
OAI基站配置文件命名规则全解析:从gnb.sa.band78到usrpb210,新手也能看懂 当你第一次打开OAI的/targets/PROJECTS/目录,看到像gnb.sa.band78.fr1.106PRB.usrpb210.conf这样的文件名时,是不是感觉像在解读外星密码?别担…...

不到百元捡漏乐视Astra Pro深度摄像头,手把手教你用Python+OpenCV玩转深度图与彩色图
不到百元捡漏乐视Astra Pro深度摄像头,手把手教你用PythonOpenCV玩转深度图与彩色图 去年在二手平台淘到一台乐视Astra Pro深度摄像头时,我完全没想到这个不到百元的小设备能带来这么多可能性。作为一款曾经售价数千元的专业设备,它现在以极…...

大模型学习-python基础Day9
一.模块与包模块是包含Python代码的文件,通常以.py为扩展名。模块可以包含函数、类、变量或可执行代码,用于将相关功能组织在一起,便于代码复用和维护。模块的作用代码复用:将常用功能封装为模块,避免重复编写相同代码…...

3分钟搞定演唱会门票:大麦网抢票脚本让你告别抢票焦虑
3分钟搞定演唱会门票:大麦网抢票脚本让你告别抢票焦虑 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 还在为抢不到心仪的演唱会门票而烦恼吗?每次开票瞬间秒光࿰…...