FLatten Transformer_ Vision Transformer using Focused Linear Attention
paper: https://arxiv.org/abs/2308.00442
code: https://github.com/LeapLabTHU/FLatten-Transformer
摘要
当将transformer模型应用于视觉任务时,自注意的二次计算复杂度( n 2 n^2 n2)一直是一个持续存在的挑战。另一方面,线性注意通过精心设计的映射函数来近似Softmax操作,提供了一个更有效的替代方法。然而,当前的线性注意方法要么遭受显著的性能下降,要么从映射函数中引入额外的计算开销。在本文中,作者提出了一种新的聚焦线性注意模块,以实现高效率和表达性。具体来说,首先从聚焦能力和特征多样性两个角度分析了导致线性注意性能下降的因素。为了克服这些限制,引入了一个简单而有效的映射函数和一个高效的秩恢复模块,在保持低计算复杂度的同时提高自我注意的表达性。大量的实验表明,线性注意模块适用于各种高级视觉transorfomer,并在多个基准上取得了持续改进的性能。
介绍
将transorfomer应用于视觉模型是一项艰巨的任务。在将自注意力机制应用于全局感受野,与轻量级卷积神经网络不同,相对于序列长度 n n n的二次计算复杂度 O ( n 2 ) O(n^2) O(n2)导致了较高的计算成本。之前的工作通过限制全局感受野为一个更小的区域感受野,比如稀疏的全局注意模式、更小的注意力窗口。尽管这些方法很有效,但由于它们的注意力模式,它们要么倾向于忽略其他区域的信息特征,要么不可避免地牺牲了建模长期依赖关系的能力。
另一方面,线性注意被认为是一种简单而有效的替代方法,通过降低一般的复杂性来解决计算困境。早期的研究利用了一种局部敏感的哈希方案,该方案将计算复杂度从 O ( n 2 ) O(n^2) O(n2)压缩为 O ( n l o g ( n ) ) O(nlog(n)) O(nlog(n))。然而,它在复杂度项之前引入了一个很大的常数,这使得它在常见情况下仍然负担不起。最近的研究注意到,在自注意操作中使用Softmax函数实际上迫使所有查询和键之间进行两两计算,从而导致主要的 O ( n 2 ) O(n^2) O(n2)复杂度。为了解决这个问题,一些方法开始采用简单的激活函数或者定制映射函数去近似原始的Softmax函数。如图1所示,通过将计算顺序从(查询键)值改为查询值(键值),可以将整体计算复杂度降低到 O ( n ) O (n) O(n)。然而,与Softmax注意相比,目前的线性注意方法仍然存在严重的性能下降,可能涉及映射函数的额外计算开销,从而限制了其实际应用。

本文针对当前线性注意方法的局限性,提出了一种新的Focused Linear Attention,该模块既具有高效率和表达性。具体来说,对导致线性关注性能下降的因素进行了双管齐下的分析,并提出了相应的解决方案。首先,前一种线性注意模块的注意权重分布相对平滑,缺乏处理信息最丰富的特征的聚焦能力。作为一种补救措施,本文提出了一个简单的映射函数来调整查询和键的特征方向,使注意力权重更容易区分。其次,注意矩阵的秩的减少限制了线性注意特征的多样性。为了解决这一问题,提出了一个对原始注意矩阵进行深度卷积(DWC)的秩恢复模块,这有助于恢复矩阵的秩,并保持不同位置的输出特征多样化。利用这些改进的技术,模块展示了与Softmax的同类产品相当或更优越的性能,同时享受了低计算复杂度的好处。
相关工作
Vision Transformer
transformer和自我注意机制首次引入自然语言处理领域,在计算机视觉领域获得了广泛的研究兴趣。然而,自注意集的高计算复杂度限制了其直接应用于视觉任务。之前的视觉transformer考虑通过将相邻像素合并为单个令牌来降低输入分辨率。接下来的研究也采用了类似的见解,也扩展到下游任务。另一项研究逐渐降低了特征的分辨率,并采用了精心设计的注意模式来限制token数量。例如,PVT 使用一个稀疏的注意模式,并从全局的角度选择注意令牌。AT 遵循该路径,设计了一个可变形的注意模块,以实现数据依赖的注意模式。Swin变压器通过将输入划分为孤立的窗口来局部选择注意令牌。NAT在卷积中遵循以查询为中心的模式,并为所有查询设计独立的注意标记。一些研究也注意到,卷积运算对变压器模型很有价值,可能有助于提高整体效率。CMT将变压器块与高效的卷积算子相结合,像深度可分离卷积(depthwise convolution),并实现了更好的效率和性能的权衡。ACmix 共享了卷积和自注意的计算开销,并以有限的成本集成了这两个模块。并提出了有效训练变压器的方法。
然而,这些方法仍然依赖于Softmax算子,其继承了较高的计算复杂度,不可避免地给模型架构设计和实际应用带来了不便。
Linear Attention
除了上述方法外,另一项研究利用线性注意解决高计算复杂度。具体地说,线性注意用单独的核函数代替了自注意中的Softmax函数。在这种情况下,线性注意不需要首先计算成对相似度 Q K T QK^T QKT,正如图1所示,这种情况softmax函数将不可用,因此需要再设计一个映射函数。如何设计与softmax注意力机制一样有效的线性注意模块仍然是一个重要的问题。Performer近似于具有正交随机特征的Softmax操作。Efficient attention 将Softmax函数分别应用于Q和K,这自然保证了每一行 Q K T QK^T QKT的总和为1。Nystromformer和SOFT通过矩阵分解近似全自注意矩阵。Hydra attention用余弦相似度代替Softmax。EfficientVit利用深度可分离卷积来提高线性注意的局部特征提取能力。然而,目前的线性注意设计要么没有足够的表达能力来赶上sotmax注意,要么涉及来自复杂核函数的额外计算开销。在本研究中,作者从聚焦能力和特征多样性的角度分析了线性注意性能下降的原因。在此基础上,作者提出了一种新的线性注意模块,称为聚焦线性注意,它在计算复杂度较低的情况下比Softmax注意更好的性能(图2)。

具体来说:
自注意力机制公式:对于每一个token有 O i = ∑ j = 1 N S i m ( Q i , K j ) ∑ j = 1 N S i m ( Q i , K j ) V j O_i = \sum_{j=1}^N\frac{Sim(Q_i,K_j)}{\sum_{j=1}^N Sim(Q_i,K_j)}V_j Oi=∑j=1N∑j=1NSim(Qi,Kj)Sim(Qi,Kj)Vj, S i m Sim Sim表示相似度函数, S i m ( Q i , K j ) = e x p ( Q j K j T / d ) Sim(Q_i,K_j)=exp(Q_j{K_j}^T/\sqrt{d}) Sim(Qi,Kj)=exp(QjKjT/d)
线性注意力机制:精心设计的核作为原始相似度函数的近似值 S i m ( Q i , K j ) = ϕ ( Q i ) ϕ ( K j ) T Sim(Q_i,K_j)=\phi (Q_i)\phi(K_j)^T Sim(Qi,Kj)=ϕ(Qi)ϕ(Kj)T
那么自注意力机制公式就可以被重写为 O i = ∑ j = 1 N ϕ ( Q i ) ϕ ( K i ) T ∑ j = 1 N ϕ ( Q i ) ϕ ( K j ) T V j O_i = \sum_{j=1}^N\frac{\phi(Q_i)\phi(K_i)^T}{\sum_{j=1}^N\phi(Q_i)\phi(K_j)T}V_j Oi=∑j=1N∑j=1Nϕ(Qi)ϕ(Kj)Tϕ(Qi)ϕ(Ki)TVj
这样就可以将 ( Q K T ) V (QK^T)V (QKT)V转化为 Q ( K T V ) Q(K^TV) Q(KTV),即 O i = ϕ ( Q i ) ( ∑ j = 1 N ϕ ( K j ) T V j ) ϕ ( Q i ) ( ∑ j = 1 N ϕ ( K I ) T ) O_i = \frac{\phi(Q_i)(\sum_{j=1}^N\phi(K_j)^TV_j)}{\phi(Q_i)(\sum_{j=1}^N\phi(K_I)^T)} Oi=ϕ(Qi)(∑j=1Nϕ(KI)T)ϕ(Qi)(∑j=1Nϕ(Kj)TVj)
注意 Q i Q_i Qi为query向量, K j K_j Kj为key向量, V j V_j Vj为value向量。
方法(Focused Linear Attention)
Focus ability
softmax注意力机制实际上提供了一种非线性重加权机制,使其很容易集中在重要的特征。如图3所示,来自Softmax注意的注意图在某些区域的分布特别明显,如前景物体。相比之下,线性注意的分布是相对的平滑,使其输出更接近所有特征的平均值,而不能关注信息更丰富的区域。

作为补救措施,作者提出了一个简单而有效的解决方案,通过调整每个查询和关键特征的方向,接近相似的查询键对,同时消除不同的查询键对。具体来说,作者提出了一个简单的映射函数 f p f_p fp,称为Focused函数:
S i m ( Q i , K j ) = ϕ p ( Q i ) ϕ p ( K j ) T Sim(Q_i,K_j)=\phi_p(Q_i)\phi_p(K_j)^T Sim(Qi,Kj)=ϕp(Qi)ϕp(Kj)T
where ϕ p ( x ) = f p ( R e L U ( x ) ) , f p ( x ) = ∣ ∣ x ∣ ∣ ∣ ∣ x ∗ ∗ p ∣ ∣ x ∗ ∗ p \phi_p(x)=f_p(ReLU(x)),f_p(x)=\frac{||x||}{||x^{**p}||}x^{**p} ϕp(x)=fp(ReLU(x)),fp(x)=∣∣x∗∗p∣∣∣∣x∣∣x∗∗p
其中 x ∗ ∗ p x^{**p} x∗∗p表示x按元素的p次方。作者证明了所提出的映射函数 f p f_p fp实际上影响了注意力的分布。
命题1: f p f_p fp调整特征方向
令 x = ( x 1 , . . . , x n ) , y = ( y 1 , . . . , y n ) ∈ R n , x i , y i ≥ 0 x=(x_1,...,x_n),y=(y_1,...,y_n) \in \mathbb{R}^n,x_i,y_i\ge 0 x=(x1,...,xn),y=(y1,...,yn)∈Rn,xi,yi≥0假设x和y分别有一个最大的值 x m x_m xm和 y n y_n yn。
当 m = n m=n m=n时,有 ∃ p > 1 , s . t . ⟨ ϕ p ( x ) , ϕ p ( y ) ⟩ > ⟨ x , y ⟩ \exists p> 1, s.t. \left \langle \phi_p(x),\phi_p(y) \right \rangle > \left \langle x,y \right \rangle ∃p>1,s.t.⟨ϕp(x),ϕp(y)⟩>⟨x,y⟩
当 m ≠ n m\ne n m=n时,有 ∃ p > 1 , s . t . ⟨ ϕ p ( x ) , ϕ p ( y ) ⟩ < ⟨ x , y ⟩ \exists p> 1, s.t. \left \langle \phi_p(x),\phi_p(y) \right \rangle < \left \langle x,y \right \rangle ∃p>1,s.t.⟨ϕp(x),ϕp(y)⟩<⟨x,y⟩
⟨ x , y ⟩ \left \langle x,y \right \rangle ⟨x,y⟩表示內积 x y T xy^T xyT
这个命题可以这样理解, f p f_p fp使相似的query-key更明显的区别( m = n m=n m=n时內积相比原始值变大),不相似的query-key恢复了尖锐的注意力分布作为原来的Softmax函数( m ≠ n m\ne n m=n內积更小),从而实现focus ablity。
为了更好地理解,我们给出了一个例子来显示图4中 f p f_p fp的影响。可以看出, f p f_p fp实际上将每个向量“拉”到它最近的轴上,而p决定了这种“拉”的程度。通过这样做, f p f_p fp有助于根据特征最近的轴将特征划分为几个组,提高每个组内的相似性,同时减少组之间的相似性。可视化与我们上面的分析一致。

Feature diversity
除了focus ablity外,特征多样性也是限制线性注意表达能力的因素之一。其中一个可能的原因可能归功于注意力矩阵的秩,其中可以看到显著的差异。以 N = 14 × 14 N=14×14 N=14×14的DeiT-Tiny的transformer层为例,从图5 (a)可以看出,注意力矩阵具有完整的秩(196中的196),显示了从值聚合特征时的多样性。

然而,在线性注意的情况下,这一点很难实现。事实上,注意矩阵在线性注意中的秩受到每个头部的令牌数N和通道维数d的限制: r a n k ( ϕ ( Q ) ϕ ( K ) T ) ≤ m i n { r a n k ( ϕ ( Q ) ) , r a n k ( ϕ ( Q ) ) } ≤ m i n { N , d } rank(\phi(Q)\phi(K)^T) \le min\{rank(\phi(Q)),rank(\phi (Q))\} \le min\{N,d\} rank(ϕ(Q)ϕ(K)T)≤min{rank(ϕ(Q)),rank(ϕ(Q))}≤min{N,d}
因为d通常小于N,所以线性注意力机制的注意力矩阵小于等于d,而softmax注意力小于等于N(大概率是等于d和等于n)。在这种情况下,注意矩阵秩的上界被限制在一个较低的比率,这表明注意映射的许多行被严重均质化。由于自注意力的输出是同一组V的加权和,注意力权重的均匀化不可避免地导致聚合特征之间的相似性。
为了更好地说明,我们将DeiT-Tiny中的原始Softmax注意替换为线性注意,并显示了图5 (b).中的注意图的rank,可以观察到,rank大大下降(196中有54),注意矩阵的许多行是相似的。
作为一种补救方法,我们提出了一个简单而有效的解决方案来解决线性注意的限制。具体地说,在注意矩阵中添加了一个深度卷积(DWC,depthwise convolution)模块,输出可以表示为: O = ϕ ( Q ) ϕ ( K ) T V + D W C ( V ) O=\phi(Q)\phi(K)^TV+DWC(V) O=ϕ(Q)ϕ(K)TV+DWC(V)
为了更好地理解这个DWC模块的效果,我们可以把它看作是一种attention,即每个query只关注空间中的几个相邻特征,而不是所有特征V。这种局部性保证了即使两个查询对应的线性注意值相同,我们仍然可以从不同的局部特征中得到不同的输出,从而保持特征的多样性。DWC的影响也可以从矩阵秩的角度来解释:
O = ( ϕ ( Q ) ϕ ( K ) T + M D W C ) V = M e q V O=(\phi(Q)\phi(K)^T+M_{DWC})V=M_{eq}V O=(ϕ(Q)ϕ(K)T+MDWC)V=MeqV
M D W C M_{DWC} MDWC是深度卷积的稀疏矩阵, M e q M_{eq} Meq对应于注意力矩阵,因为 M D W C M_{DWC} MDWC是满秩,所以 M e q M_{eq} Meq大概率也满秩。
为了更好地说明,我们在DeiT-Tiny上进行了类似的修改。通过附加的DWC模块,注意图在线性注意中的秩可以恢复到全秩(196/196,如图5©所示),从而保持特征多样性作为原来的Softmax注意。
模块构成
我们的模块可以表述为: O = S i m ( Q , K ) V = ϕ p ( Q ) ϕ p ( K ) T V + D W C ( V ) O=Sim(Q,K)V=\phi_p(Q)\phi_p(K)^TV+DWC(V) O=Sim(Q,K)V=ϕp(Q)ϕp(K)TV+DWC(V)
相关文章:
FLatten Transformer_ Vision Transformer using Focused Linear Attention
paper: https://arxiv.org/abs/2308.00442 code: https://github.com/LeapLabTHU/FLatten-Transformer 摘要 当将transformer模型应用于视觉任务时,自注意的二次计算复杂度( n 2 n^2 n2)一直是一个持续存在的挑战。另一方面,线性注意通过精心设计的映射…...

STM32CubeMX学习笔记17--- FSMC
1.1 TFTLCD简介 TFT-LCD(thin film transistor-liquid crystal display)即薄膜晶体管液晶显示器。液晶显示屏的每一个像素上都设置有一个薄膜晶体管(TFT),每个像素都可以通过点脉冲直接控制,因而每个节点都…...
)
【MogDB】实战MogDB数据库适配Halo博客系统1.6版本(基于springframework+hibernate+HikariPool)
前言 前一篇文章说了MogDB适配Halo,【MogDB】将流行的博客系统Halo后端的数据库设置为MogDB,但是适配的是2.x版本,由于2.x版本已经引入了对postgresql的支持,而MogDB对于postgresql有很好的兼容性,因此适配起来很简单。但是由于halo2.x的版本…...

Python与FPGA——局部二值化
文章目录 前言一、局部二值化二、Python局部二值化三、FPGA局部二值化总结 前言 局部二值化较全局二值化难,我们将在此实现Python与FPGA的局部二值化处理。 一、局部二值化 局部二值化就是使用一个窗口,在图像上进行扫描,每扫出9个像素求平均…...

shell文本处理工具-shell三剑客1
shell脚本常用基础命令2 shell脚本常用基础命令 shell脚本常用基础命令2一、grep用法二、sed用法2.1p参数 (显示)n参数(只显示处理过的行) 文本处理三剑客:grep sed awk 一、grep用法 grep -E egrep (扩展搜索正文表…...

函数的传入参数-传参定义
基于函数的定义语法: def 函数名(传入参数)函数体return 返回值 可以有如下函数定义: def add(x,y):return xyprint(f"{x} {y}的结果是:{result}") 实现了,每次计算的是xy,而非…...
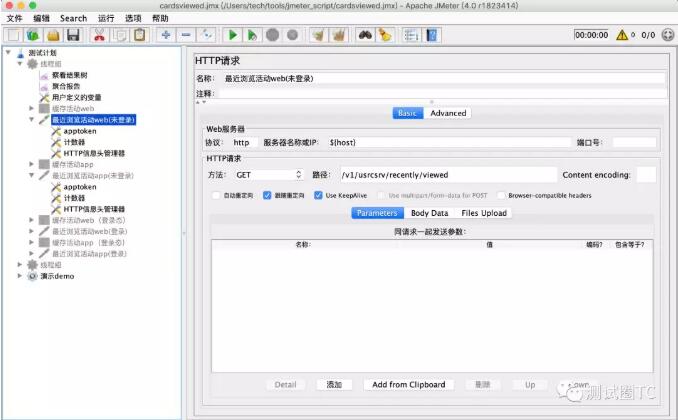
主流接口测试框架对比,究竟哪个更好用
公司计划系统的开展接口自动化测试,需要我这边调研一下主流的接口测试框架给后端测试(主要测试接口)的同事介绍一下每个框架的特定和使用方式。后端同事根据他们接口的特点提出一下需求,看哪个框架更适合我们。 需求 1、接口编写…...

常用python模板
1.简单脚本模板 def main():#代码逻辑if __name__"__main__":main() 2.类定义模板 Class Myclass:def __init__(self,parameter):self.parameterparameterdef my_method(self):#方法逻辑 3.函数定义模板 def my_function(parameter):#代码逻辑return result 4.…...
)
53. 最大子数组和(力扣LeetCode)
文章目录 53. 最大子数组和题目描述暴力(运行超时)贪心 53. 最大子数组和 题目描述 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 子数组是数组…...

如何远程SSH连接在家的服务器主机
当您需要通过SSH远程连接到家里的服务器主机时,以下是更详细的实施步骤: 1. 确保服务器主机已开启SSH服务 安装SSH服务:首先,确保您的服务器主机上安装了SSH服务。根据您的操作系统,您可以使用相应的包管理器来安装。…...
【亲测有效】解决三月八号ChatGPT 发消息无响应!
背景 今天忽然发现 ChatGPT 无法发送消息,能查看历史对话,但是无法发送消息。 可能的原因 出现这个问题的各位,应该都是点击登录后顶部弹窗邀请 [加入多语言 alapha 测试] 了,并且语言选择了中文,抓包看到 ab.chatg…...
vue结合vue-electron创建应用程序
这里写自定义目录标题 安装electron第一种方式:vue init electron-vue第二种方式:vue add electron-builder 启动electron调试功能:background操作和使用1、覆盖窗口的菜单上下文、右键菜单2、监听关闭事件、阻止默认行为3、创建悬浮窗口4、窗…...
【C++】STL(二) string容器
一、string基本概念 1、本质 string是C风格的字符串,而string本质上是一个类 string和char * 区别: char * 是一个指针 string是一个类,类内部封装了char*,管理这个字符串,是一个char*型的容器。 2、特点 1、stri…...

PyCM:Python中的混淆矩阵库
PyCM:Python中的混淆矩阵库 在机器学习和数据科学领域,评估模型的性能是至关重要的。混淆矩阵是一种常用的评估工具,用于可视化和量化分类模型的预测结果。PyCM是一个开源的Python库,提供了丰富的功能来计算和分析混淆矩阵。本文将…...
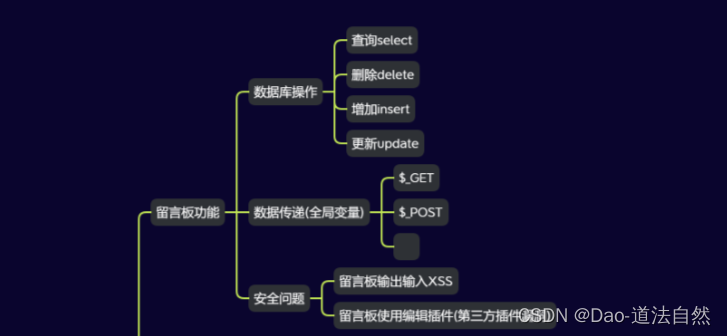
Day22:安全开发-PHP应用留言板功能超全局变量数据库操作第三方插件引用
目录 开发环境 数据导入-mysql架构&库表列 数据库操作-mysqli函数&增删改查 数据接收输出-html混编&超全局变量 第三方插件引用-js传参&函数对象调用 完整源码 思维导图 PHP知识点: 功能:新闻列表,会员中心࿰…...

IOS面试题object-c 61-70
61. 阐述isKindOfClass、isMemberOfClass、selector作用分别是什么?isKindOfClass:作用是某个对象属于某个类型或者继承自某类型。 isMemberOfClass:某个对象确切属于某个类型。 selector:通过方法名,获取在内存中的函…...

Git指令reset的参数soft、mixed与hard三者之间的区别
主要内容 reset默认不写参数,与使用mixed参数含义一样 为了描述简洁,使用下图说明: #mermaid-svg-LtChquRXlEV1j6og {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-LtChquRXlEV1j…...

RGMII 接口调试
目录 硬件检查 软件检查 调试步骤 硬件检查 硬件工程师检查原理图和PCB,核查RGMII线路连接是否正确,PHY的 TX连接对端 RX,PHY的RX连接对端TX,原理图上以引脚序号引脚名 引脚类型(输入还是输出)逐一核查RGMII接口各个网络&#…...

Ubuntu 24.04 抢先体验换国内源 清华源 阿里源 中科大源 163源
Update 240307:Ubuntu 24.04 LTS 进入功能冻结期 预计4月25日正式发布。 Ubuntu22.04换源 Ubuntu 24.04重要升级daily版本下载换源步骤 (阿里源)清华源中科大源网易163源 Ubuntu 24.04 LTS,代号 「Noble Numbat」,即将与我们见面! Canonica…...

软件设计模式:模板方法模式
1. 简介 模板方法模式是一种行为型设计模式,它定义了一个算法的骨架,将一些步骤延迟到子类中实现。这样,可以在不改变算法结构的情况下,重新定义算法中的某些步骤。 2. 使用条件 模板方法模式适用于以下情况: 算法…...
)
2026奇点智能技术大会核心成果(视觉导航Agent工业级部署白皮书首曝)
第一章:2026奇点智能技术大会:AIAgent视觉导航 2026奇点智能技术大会(https://ml-summit.org) 核心突破:端到端视觉-动作联合建模 本届大会首次公开部署的AIAgent视觉导航系统,摒弃传统SLAM路径规划分层架构,采用统一…...

探索DebToIPA核心技术:解密.deb到.ipa的架构突破与移动应用格式革命
探索DebToIPA核心技术:解密.deb到.ipa的架构突破与移动应用格式革命 【免费下载链接】DebToIPA Convert .deb apps to .ipa files, on iOS, locally 项目地址: https://gitcode.com/gh_mirrors/de/DebToIPA 在移动应用生态系统的技术演进中,跨平台…...

CLIP-GmP-ViT-L-14保姆级教学:7860端口访问失败的5种解决方案
CLIP-GmP-ViT-L-14保姆级教学:7860端口访问失败的5种解决方案 你是不是刚部署好CLIP-GmP-ViT-L-14模型,满心欢喜地打开浏览器,输入http://localhost:7860,结果却只看到一个无法访问的页面?别着急,这个问题…...

python opencv-python
# 聊聊 OpenCV-Python 那点事儿 如果你在计算机视觉这个圈子里待过一阵子,大概率会听过 OpenCV 的大名。而 OpenCV-Python,可以看作是这座庞大宫殿的一扇侧门——它保留了宫殿里绝大多数珍宝,却提供了一条更轻快、更亲切的进入路径。 它究竟是…...
|3种方法一步步教会你)
如何把PPT做成讲解视频(新手指南)|3种方法一步步教会你
很多人都有这样的需求:做课程讲解做培训视频做知识分享但卡在一个关键问题:👉 怎么把PPT变成“会讲解”的视频?注意,这里不是简单导出视频,而是:✅ 有讲解 ✅ 有节奏 ✅ 有字幕这篇文章…...

Arduino ESP32开发板终极安装指南:从零开始快速上手物联网开发 [特殊字符]
Arduino ESP32开发板终极安装指南:从零开始快速上手物联网开发 🚀 【免费下载链接】arduino-esp32 Arduino core for the ESP32 项目地址: https://gitcode.com/GitHub_Trending/ar/arduino-esp32 还在为ESP32开发板安装配置而烦恼吗?…...

深入解析PVT corner:wcl、wc、lt、tc、ml对cell delay的影响
1. PVT corner基础:理解工艺、电压、温度的三角关系 在芯片设计的世界里,PVT(工艺Process、电压Voltage、温度Temperature)就像决定电路性能的"天气系统"。想象你正在驾驶一辆车:工艺是发动机的性能…...

GPUStack 在华为昇腾 I A 服务器上的保姆级部署指南首
开发个什么Skill呢? 通过 Skill,我们可以将某些能力进行模块化封装,从而实现特定的工作流编排、专家领域知识沉淀以及各类工具的集成。 这里我打算来一次“套娃式”的实践:创建一个用于自动生成 Skill 的 Skill,一是用…...

网盘下载慢?试试 OpenSpeedy!100 倍加su
OpenSpeedy是一款进程加速的软件,介绍这款软件其实是让大家提高某网盘的下载速度,但是其实他不仅提高下载速度,还可以加速任何软件。 软件是绿色版,打开以后,选择某个进程,然后把变速速率调到100倍即可。 然…...
)
告别404!用Docker Compose一键部署GeoServer(含汉化与TIF影像发布避坑指南)
从零到一:Docker Compose全栈部署GeoServer实战手册 当你在深夜调试GeoServer时,突然看到屏幕上那个刺眼的404错误页面,是否也曾想把键盘摔在地上?作为GIS开发者,我们都经历过这种绝望时刻——明明按照教程一步步操作&…...