spark兼容性验证
前言
Apache Spark是专门为大规模数据处理而设计的快速通用的计算引擎,Spark拥有Hadoop MapReduce所具有的优点,但不同于Mapreduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好的适用于数据挖掘与机器学习等需要迭代的MapReduce。
Spark是一种与hadoop相似的开源集群计算环境,但是两者之间还存在一些不同之处,Spark启用了内存分布数据集群,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark特点:
1、更快的速度:内存计算下,Spark比Hadoop快100倍
2、易用性:可以使用java、scala、python、R和SQL语言进行spark开发,Spark提供了80多个高级运算符
3、通用性:Spark提供了大量的库,包括Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX。开发者可以在一个应用程序中无缝组合使用这些库
4、多种运行环境:Spark可在Hadoop、Apache Mesos、Kubernetes、standalone或其他云环境上运行
参考链接:https://blog.csdn.net/cuiyaonan2000/article/details/116048663
spark适用场景:
1、spark是基于内存的迭代计算,适合多次操作特定数据集的场合
2、数据量不是特别大,但要求实时统计分析需求
3、不适用异步细粒更新状态的应用,如web服务器存储、增量的web爬虫和索引
spark运行模式:
1、可以运行在一台机器上,称为Local(本地)运行模式
2、可以使用spark自带的资源调度系统,称为Standalone模式
3、可以使用Yarn、Mesos、kubernetes作为底层资源调度系统,称为Spark On Yarn、Spark On Mesos、Spark On K8s
参考链接:https://blog.csdn.net/jiayi_yao/article/details/125545826#t8
一、安装启动
安装spark及其依赖
yum install java-1.8.0-openjdk curl tar python3
mkdir -p /usr/local/spark
cd /usr/local/spark
wget https://mirrors.aliyun.com/apache/spark/spark-3.3.2/spark-3.3.2-bin-hadoop3.tgz
tar -xvf spark-3.3.2-bin-hadoop3.tgz
- 启动spark-master
cd /usr/local/spark/spark-3.3.2-bin-hadoop3/
[root@bogon spark-3.3.2-bin-hadoop3]# ./sbin/start-master.sh
可以看到类似如下的输出:
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/spark-3.3.2-bin-hadoop3/logs/spark-root-org.apache.spark.deploy.master.Master-1-bogon.out
用tail命令查看执行日志
[root@bogon spark-3.3.2-bin-hadoop3]# tail logs/spark-root-org.apache.spark.deploy.master.Master-1-bogon.out
23/03/06 14:35:44 INFO SecurityManager: Changing modify acls to: root
23/03/06 14:35:44 INFO SecurityManager: Changing view acls groups to:
23/03/06 14:35:44 INFO SecurityManager: Changing modify acls groups to:
23/03/06 14:35:44 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
23/03/06 14:35:45 INFO Utils: Successfully started service 'sparkMaster' on port 7077.
23/03/06 14:35:45 INFO Master: Starting Spark master at spark://bogon:7077
23/03/06 14:35:45 INFO Master: Running Spark version 3.3.2
23/03/06 14:35:45 INFO Utils: Successfully started service 'MasterUI' on port 8080.
23/03/06 14:35:45 INFO MasterWebUI: Bound MasterWebUI to 0.0.0.0, and started at http://bogon:8080
23/03/06 14:35:46 INFO Master: I have been elected leader! New state: ALIVE
- 启动spark-worker
cd /usr/local/spark/spark-3.3.2-bin-hadoop3/
[root@bogon spark-3.3.2-bin-hadoop3]# ./sbin/start-worker.sh spark://bogon:7077
可以看到类似如下的输出:
starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/spark-3.3.2-bin-hadoop3/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bogon.out
用tail命令查看执行日志
[root@bogon spark-3.3.2-bin-hadoop3]# tail logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bogon.out
23/03/06 14:52:17 INFO Worker: Spark home: /usr/local/spark/spark-3.3.2-bin-hadoop3
23/03/06 14:52:17 INFO ResourceUtils: ==============================================================
23/03/06 14:52:17 INFO ResourceUtils: No custom resources configured for spark.worker.
23/03/06 14:52:17 INFO ResourceUtils: ==============================================================
23/03/06 14:52:17 WARN Utils: Service 'WorkerUI' could not bind on port 8081. Attempting port 8082.
23/03/06 14:52:17 INFO Utils: Successfully started service 'WorkerUI' on port 8082.
23/03/06 14:52:17 INFO WorkerWebUI: Bound WorkerWebUI to 0.0.0.0, and started at http://bogon:8082
23/03/06 14:52:17 INFO Worker: Connecting to master bogon:7077...
23/03/06 14:52:17 INFO TransportClientFactory: Successfully created connection to bogon/10.130.0.73:7077 after 85 ms (0 ms spent in bootstraps)
23/03/06 14:52:18 INFO Worker: Successfully registered with master spark://bogon:7077
二、测试
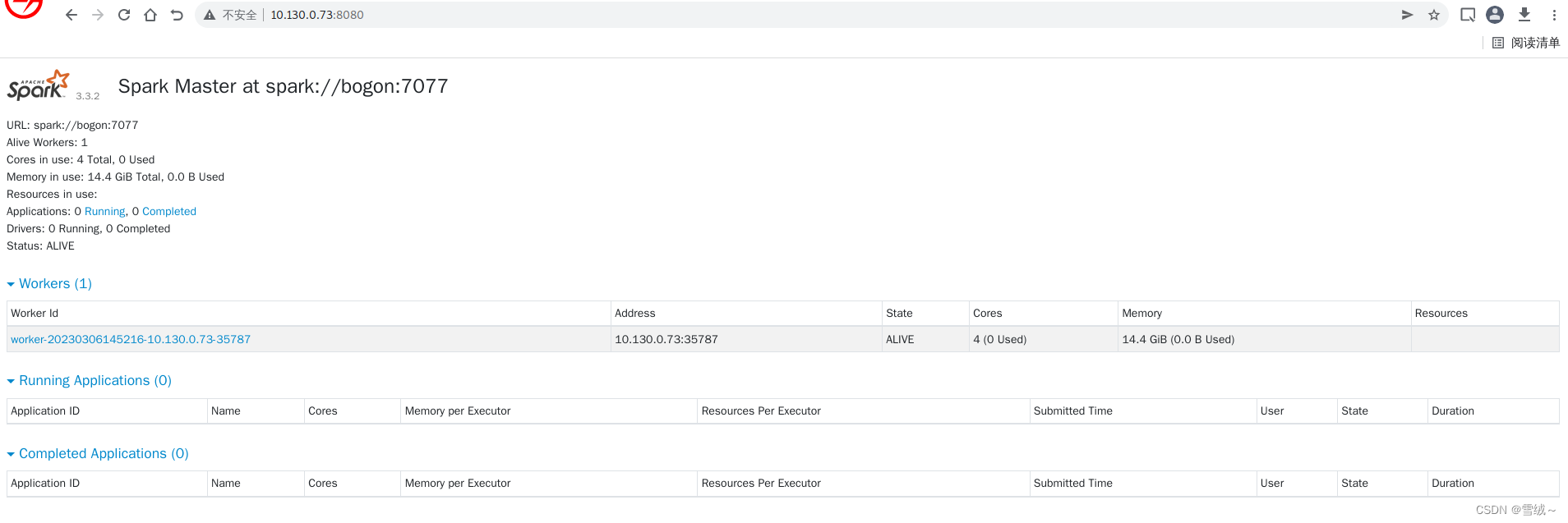
- 通过http://$IP:8080 访问master页面,获取资源消耗等的摘要信息
如果部署成功,我们可以看到类似如下的返回结果
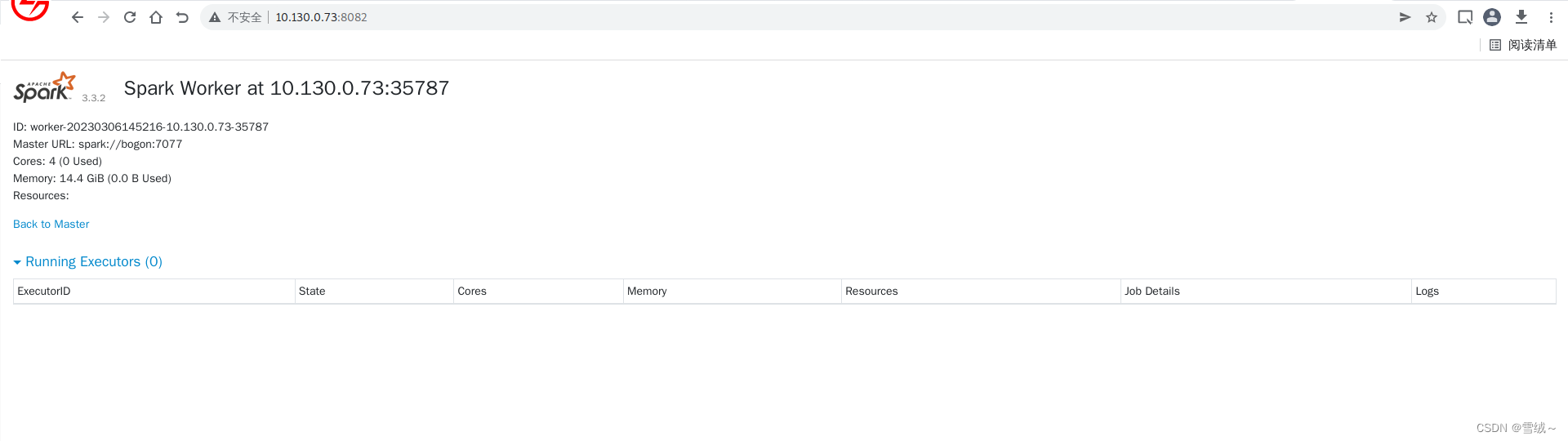
- 也可以通过web浏览器请求对应服务器8082端口(默认8081端口,可通过日志查看具体的端口号),查看worker的基本情况
- 提交测试任务,计算pi,提交命令如下
./bin/spark-submit --master spark://bogon:7077 examples/src/main/python/pi.py 1000
可以看到类似如下的输出:
23/03/06 16:32:55 INFO TaskSetManager: Starting task 999.0 in stage 0.0 (TID 999) (10.130.0.73, executor 0, partition 999, PROCESS_LOCAL, 4437 bytes) taskResourceAssignments Map()
23/03/06 16:32:55 INFO TaskSetManager: Finished task 995.0 in stage 0.0 (TID 995) in 217 ms on 10.130.0.73 (executor 0) (996/1000)
23/03/06 16:32:55 INFO TaskSetManager: Finished task 996.0 in stage 0.0 (TID 996) in 220 ms on 10.130.0.73 (executor 0) (997/1000)
23/03/06 16:32:55 INFO TaskSetManager: Finished task 997.0 in stage 0.0 (TID 997) in 198 ms on 10.130.0.73 (executor 0) (998/1000)
23/03/06 16:32:55 INFO TaskSetManager: Finished task 998.0 in stage 0.0 (TID 998) in 189 ms on 10.130.0.73 (executor 0) (999/1000)
23/03/06 16:32:55 INFO TaskSetManager: Finished task 999.0 in stage 0.0 (TID 999) in 238 ms on 10.130.0.73 (executor 0) (1000/1000)
23/03/06 16:32:55 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
23/03/06 16:32:55 INFO DAGScheduler: ResultStage 0 (reduce at /usr/local/spark/spark-3.3.2-bin-hadoop3/examples/src/main/python/pi.py:42) finished in 64.352 s
23/03/06 16:32:55 INFO DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job
23/03/06 16:32:55 INFO TaskSchedulerImpl: Killing all running tasks in stage 0: Stage finished
23/03/06 16:32:55 INFO DAGScheduler: Job 0 finished: reduce at /usr/local/spark/spark-3.3.2-bin-hadoop3/examples/src/main/python/pi.py:42, took 64.938378 s
Pi is roughly 3.133640
23/03/06 16:32:55 INFO SparkUI: Stopped Spark web UI at http://bogon:4040
23/03/06 16:32:55 INFO StandaloneSchedulerBackend: Shutting down all executors
23/03/06 16:32:55 INFO CoarseGrainedSchedulerBackend$DriverEndpoint: Asking each executor to shut down
23/03/06 16:32:55 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
23/03/06 16:32:55 INFO MemoryStore: MemoryStore cleared
23/03/06 16:32:55 INFO BlockManager: BlockManager stopped
23/03/06 16:32:55 INFO BlockManagerMaster: BlockManagerMaster stopped
23/03/06 16:32:55 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
23/03/06 16:32:55 INFO SparkContext: Successfully stopped SparkContext
23/03/06 16:32:56 INFO ShutdownHookManager: Shutdown hook called
23/03/06 16:32:56 INFO ShutdownHookManager: Deleting directory /tmp/spark-087c8a21-8641-4b20-8b65-be47b77f26c5
23/03/06 16:32:56 INFO ShutdownHookManager: Deleting directory /tmp/spark-24d1bc1a-841a-435e-8263-ad891e2aaa97/pyspark-f67ad2cb-ec86-41eb-ae7c-8fcb46e66827
23/03/06 16:32:56 INFO ShutdownHookManager: Deleting directory /tmp/spark-24d1bc1a-841a-435e-8263-ad891e2aaa97
可以在网页界面看到运行结果
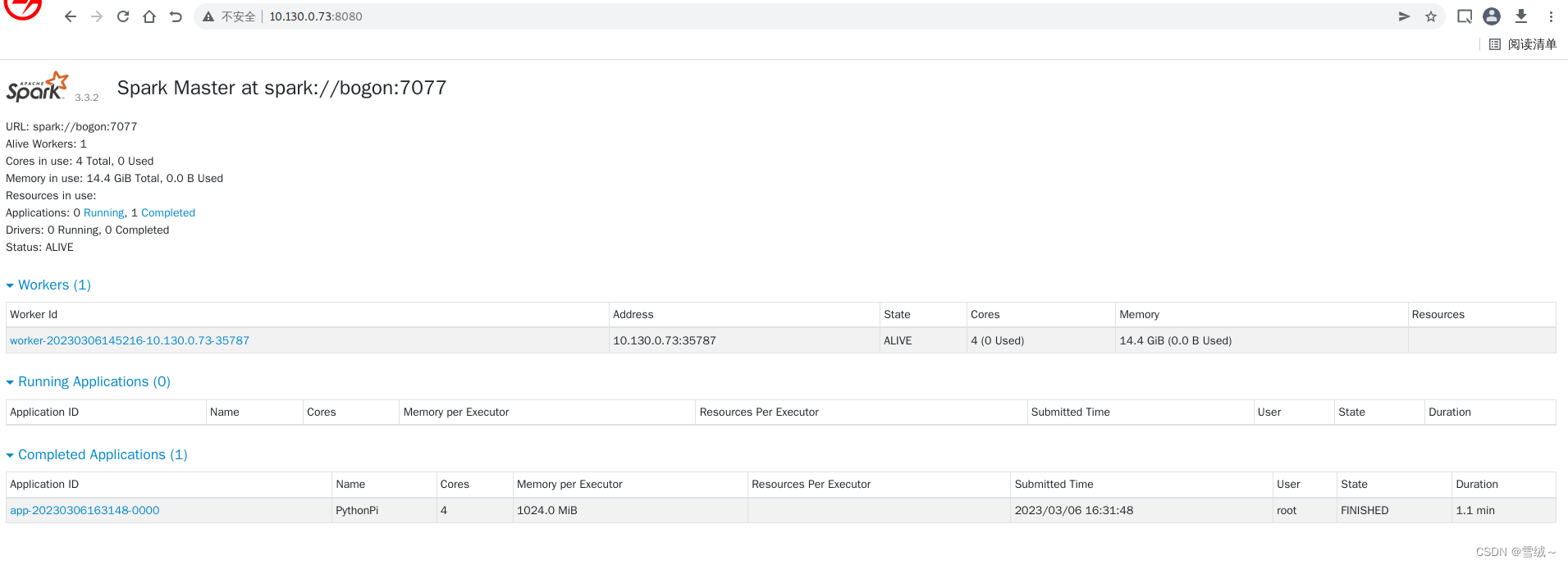
也可以查看执行日志
[root@bogon spark-3.3.2-bin-hadoop3]# tail logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bogon.out
23/03/06 16:31:48 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); groups with view permissions: Set(); users with modify permissions: Set(root); groups with modify permissions: Set()
23/03/06 16:31:48 INFO ExecutorRunner: Launch command: "/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-8.1.10.lns8.loongarch64/jre/bin/java" "-cp" "/usr/local/spark/spark-3.3.2-bin-hadoop3/conf/:/usr/local/spark/spark-3.3.2-bin-hadoop3/jars/*" "-Xmx1024M" "-Dspark.driver.port=46821" "-XX:+IgnoreUnrecognizedVMOptions" "--add-opens=java.base/java.lang=ALL-UNNAMED" "--add-opens=java.base/java.lang.invoke=ALL-UNNAMED" "--add-opens=java.base/java.lang.reflect=ALL-UNNAMED" "--add-opens=java.base/java.io=ALL-UNNAMED" "--add-opens=java.base/java.net=ALL-UNNAMED" "--add-opens=java.base/java.nio=ALL-UNNAMED" "--add-opens=java.base/java.util=ALL-UNNAMED" "--add-opens=java.base/java.util.concurrent=ALL-UNNAMED" "--add-opens=java.base/java.util.concurrent.atomic=ALL-UNNAMED" "--add-opens=java.base/sun.nio.ch=ALL-UNNAMED" "--add-opens=java.base/sun.nio.cs=ALL-UNNAMED" "--add-opens=java.base/sun.security.action=ALL-UNNAMED" "--add-opens=java.base/sun.util.calendar=ALL-UNNAMED" "--add-opens=java.security.jgss/sun.security.krb5=ALL-UNNAMED" "org.apache.spark.executor.CoarseGrainedExecutorBackend" "--driver-url" "spark://CoarseGrainedScheduler@bogon:46821" "--executor-id" "0" "--hostname" "10.130.0.73" "--cores" "4" "--app-id" "app-20230306163148-0000" "--worker-url" "spark://Worker@10.130.0.73:35787"
23/03/06 16:32:55 INFO Worker: Asked to kill executor app-20230306163148-0000/0
23/03/06 16:32:55 INFO ExecutorRunner: Runner thread for executor app-20230306163148-0000/0 interrupted
23/03/06 16:32:55 INFO ExecutorRunner: Killing process!
23/03/06 16:32:55 INFO Worker: Executor app-20230306163148-0000/0 finished with state KILLED exitStatus 143
23/03/06 16:32:55 INFO ExternalShuffleBlockResolver: Clean up non-shuffle and non-RDD files associated with the finished executor 0
23/03/06 16:32:55 INFO ExternalShuffleBlockResolver: Executor is not registered (appId=app-20230306163148-0000, execId=0)
23/03/06 16:32:55 INFO Worker: Cleaning up local directories for application app-20230306163148-0000
23/03/06 16:32:55 INFO ExternalShuffleBlockResolver: Application app-20230306163148-0000 removed, cleanupLocalDirs = true
清理环境
./sbin/stop-worker.sh
./sbin/stop-master.sh
rm -rf /usr/local/spark
相关文章:
spark兼容性验证
前言 Apache Spark是专门为大规模数据处理而设计的快速通用的计算引擎,Spark拥有Hadoop MapReduce所具有的优点,但不同于Mapreduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好的适用于数据挖掘与…...

docker逃逸复现--pid=host模式下的逃逸
漏洞原理当docker以--pidhost模式启动时,你可以通过在容器进程中注入一些shellcode进行逃逸。相当于给了docker Linux中的CAP_SYS_PTRACE权限--pidhost:意味着宿主机与容器公享一套pid,如此做容器就可以访问并跟踪宿主机的进程Linux中的CAP_S…...

【环境配置】Windows系统下搭建Pytorch框架
【环境配置】Windows系统下搭建Pytorch框架 在Windows Serve 2019系统下搭建Pytorch框架 目录 【环境配置】Windows系统下搭建Pytorch框架1.用驱动总裁安装显卡驱动2.在cmd运行nvidia-smi3.安装cuda4.安装cudnn5.安装pytorch的命令1.首次安装2.操作失误需要重新安装6.安装torc…...
Dockerfile简单使用入门
什么是 Dockerfile? Dockerfile 是一个用来构建镜像的文本文件,文本内容包含了一条条构建镜像所需的指令和说明。 docker build命令用于从Dockerfile构建映像。可以在docker build命令中使用-f标志指向文件系统中任何位置的Dockerfile。 例如࿱…...

什么是CCC认证3C强制认证机构
什么是CCC认证3C强制认证机构? 3C认证的全称为“强迫性产物认证轨制”,它是中国政府为掩护消费者人身平安和国度平安、增强产物品质治理、按照法律法规履行的一种产物及格评定轨制。所谓3C认证,便是中国强迫性产物认证轨制,英文名…...

C语言-基础了解-18-C共用体
C共用体 一、共用体 共用体是一种特殊的数据类型,允许您在相同的内存位置存储不同的数据类型。您可以定义一个带有多成员的共用体,但是任何时候只能有一个成员带有值。共用体提供了一种使用相同的内存位置的有效方式 二、定义共同体 为了定义共用体&…...
Vue基础18之github案例、vue-resource
Vue基础18github案例静态页面第三方样式引入(以bootstrap举例)App.vueSearch.vueList.vue列表展示接口地址使用全局事件总线进行兄弟间组件通信Search.vueList.vue完善案例List.vueSearch.vue补充知识点:{...this.info,...this.dataObj}效果呈…...
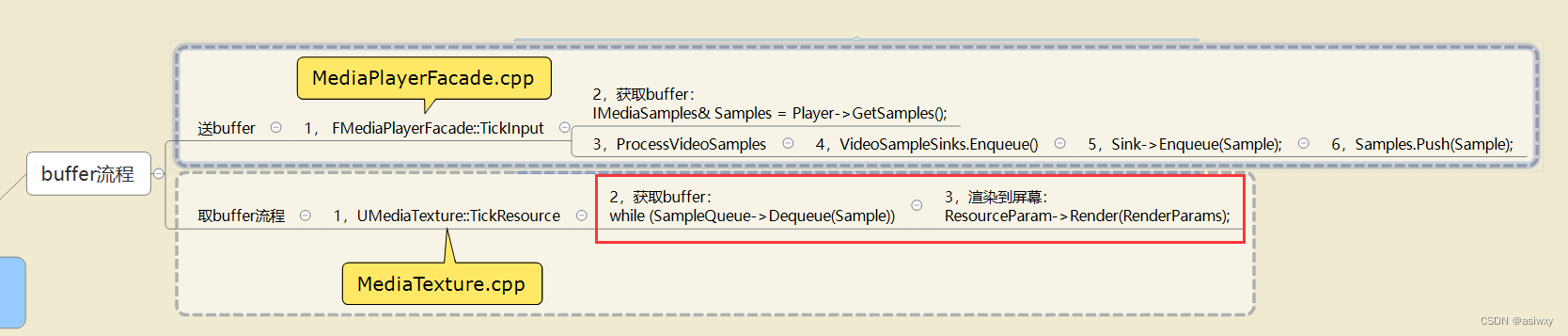
UE4 c++ Mediaplayer取消自动播放,运行时首帧为黑屏的问题
0,前言 工作需要使用C制作一个ue4的视频插件,其中一个功能是能够选择 运行时是否自动播放 视频的功能。 在实现时遇见了一个问题,取消自动播放之后,运行时首帧是没有取到的,在场景里面看是黑色的。就这个问题我想到了使…...

C语言-基础了解-17-C结构体
C结构体一、c结构体C 数组允许定义可存储相同类型数据项的变量,结构是 C 编程中另一种用户自定义的可用的数据类型,它允许您存储不同类型的数据项。结构体中的数据成员可以是基本数据类型(如 int、float、char 等),也可…...
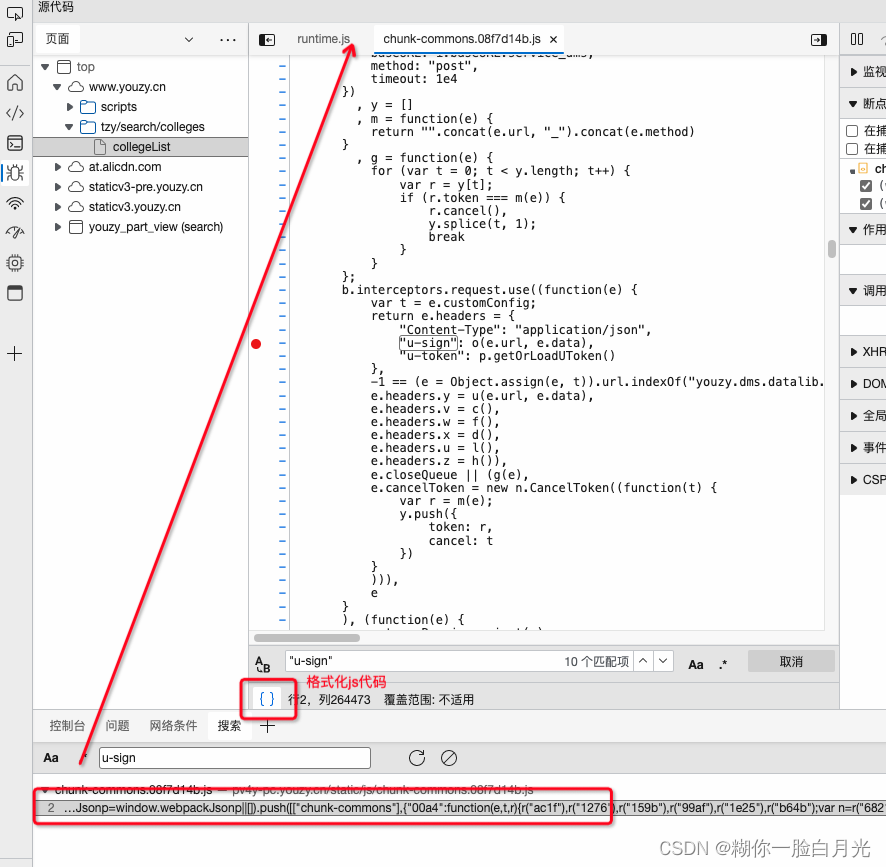
Python爬虫实践:优志愿 院校列表
https://www.youzy.cn/tzy/search/colleges/collegeList获取目标网址等信息打开开发人员工具(F12),拿到调用接口的地址,以及接口请求参数等信息,如下curl https://uwf7de983aad7a717eb.youzy.cn/youzy.dms.basiclib.ap…...

Java框架学习 | MySQL和Maven笔记
1.MySQL提问式思考 为什么要有数据库?MySQL的优劣势?Java的优劣势? JavaMySQL开源具有大量的社区成员和丰富的资源免费/具有大量的社区成员和丰富的资源可扩展性多态、继承和接口等分区、复制和集群等方式扩展数据库的容量和性能安全性有许…...

C++入门教程||C++ 变量作用域||C++ 常量
C 变量作用域 作用域是程序的一个区域,一般来说有三个地方可以声明变量: 在函数或一个代码块内部声明的变量,称为局部变量。在函数参数的定义中声明的变量,称为形式参数。在所有函数外部声明的变量,称为全局变量。 我…...
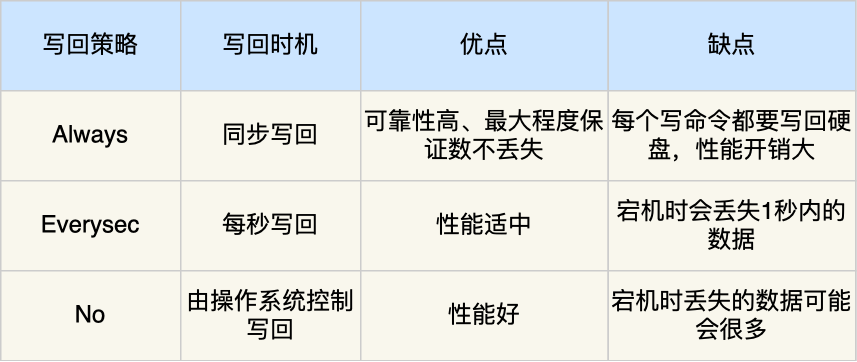
想找工作,这一篇15w字数+的文章帮你解决
文章目录前言一 专业技能1. 熟悉GoLang语言1.1 Slice1.2 Map1.3 Channel1.4 Goroutine1.5 GMP调度1.6 垃圾回收机制1.7 其他知识点2. 掌握Web框架Gin和微服务框架Micro2.1 Gin框架2.2 Micro框架2.3 Viper2.4 Swagger2.5 Zap2.6 JWT3. 熟悉使用 MySQL 数据库3.1 索引3.2 事务3.3…...

Mac brew搭建php整套开发环境
Homebrew完整版,安装时间较长/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)"精简版/bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)" speednginxBrew sear…...

111 e
全部 答对 答错 单选题 4.一个项目已经执行了两个多月,出乎意料的是,项目经理收到一封来自高级管理层的电子邮件,指出项目发起人正在请求变更项目开工会议的日期,项目经理未能执行哪项活动? A为项目管理计划制定基准…...

Cookie和Session
1. Cookie饼干 1.1 什么是Cookie? Cookie翻译过来就是饼干的意思Cookie是服务器通知客户端保存键值对的一种技术客户端有了Cookie后,每次请求都发送给服务器每个Cookie的大小不能超过4kb 1.2 如何创建Cookie BaseServlet 程序 package com.gdhd;impo…...

git上传下载
拉取: 先在电脑中创建一个文件夹用来存放要从码云上拉下来的项目并且用Git打开输入 git remote add origin + (想要下拉的项目的地址http/ssh)第一次拉取代码,输入码云的用户名(自己设置的个人地址名)和码云的账号密码 git pull origin master 拉取完成OK 上传: 进行 G…...
如何使用码匠连接 Oracle
目录 在码匠中集成 Oracle 在码匠中使用 Oracle 关于码匠 Oracle 是一种关系型数据库,可用于存储和管理大量结构化数据。Oracle 数据源支持多种操作系统,包括 Windows、Linux 和 Unix 等,同时也提供了各种工具和服务,例如 Orac…...

【Git】git常用命令集合
目录最常用的git命令git拉取代码git本地如何合并分支上传文件识别大小写开发分支(dev)上的代码达到上线的标准后,要合并到master分支当master代码改动了,需要更新开发分支(dev)上的代码git本地版本回退与远…...

基于 WebSocket、Spring Boot 教你实现“QQ聊天功能”的底层简易demo
目录 前言 一、分析 1.1、qq聊天功能分析 1.2、WebSocket介绍 1.2.1、什么是消息推送呢? 1.2.2、原理解析 1.2.3、报文格式 二、简易demo 2.1、后端实现 2.1.1、引入依赖 2.1.2、继承TextWebSocketHandler 2.1.3、实现 WebSocketConfigurer 接口 2.2、…...

Z-Image-GGUF模型量化与压缩教程:在低显存GPU上运行大模型
Z-Image-GGUF模型量化与压缩教程:在低显存GPU上运行大模型 想用AI生成图片,但一看模型大小和显存要求就头疼?手头只有一张8GB显存的消费级显卡,是不是就只能和那些功能强大的图像生成模型说再见了? 别急着放弃。今天…...

清北博雅考研集训营:沉浸式封闭备考,为考研人铺就上岸之路
考研的赛道上,从来都不缺努力的人,缺的是科学的规划、优质的师资和沉浸式的备考环境。清北博雅教育集团深耕考研辅导领域十余载,凭借专业的教学体系、大咖级师资团队、完善的教学服务和亮眼的上岸成果,打造了专属考研人的集训营备…...

光伏板缺陷检测实战:从数据集构建到YOLO模型训练全流程解析
1. 光伏板缺陷检测的现实意义 光伏发电作为清洁能源的重要组成部分,其运维效率直接影响发电量收益。我在实地考察中发现,一块被鸟粪覆盖的光伏板,发电效率可能下降30%以上;而热斑效应更会导致组件永久性损伤。传统人工巡检每天最多…...

避坑指南:lidar_align标定IMU外参时,loader.cpp源码修改与运动轨迹设计的那些关键细节
避坑指南:lidar_align标定IMU外参的核心细节与实战优化 在自动驾驶和机器人定位领域,激光雷达与IMU的联合标定是系统搭建的关键环节。许多开发者在初次使用lidar_align工具时会遇到各种问题——从源码适配的困惑到标定结果的不可靠。本文将深入剖析两个最…...
20260331-001篇)
网络基础知识整理(精简通用版)20260331-001篇
文章目录 网络基础知识整理(精简通用版) 一、网络基本概念 二、网络拓扑结构 三、OSI 七层模型(核心参考) 四、TCP/IP 模型(实际互联网标准) 五、IP 地址基础 六、传输层协议(TCP vs UDP) TCP(传输控制协议) UDP(用户数据报协议) 七、常见网络协议与端口 八、网络设…...

Vivado平台下PCIe IP核选型指南:从硬核到XDMA的实战抉择
1. PCIe技术基础与Vivado开发环境搭建 第一次接触PCIe接口开发时,我被各种专业术语搞得晕头转向。后来才发现,理解PCIe就像理解高速公路系统一样简单。PCIe本质上是一种点对点的高速串行总线,就像城市间修建的多车道高速公路。每个"车道…...

Maven Versions Plugin 使用指南
以下是对你提供内容的补充和整理,形成一篇关于 Maven Versions Plugin 使用指南的文章:Maven Versions Plugin 使用指南 Maven Versions Plugin 是一套用于管理项目版本、依赖版本和父版本的工具集合。它可以帮助你高效地更新项目版本号、检查依赖更新、…...

Java泛型中的List
本文将详细回答java泛型中的listt extends base>使用问题。 在java中,泛型提供了强大的类型安全机制,但其一些特点也容易引起混淆,如listt extends base>开发者经常感到困难。假设sub是base的子类:public class base { }pub…...

运算放大器入门难?这篇超详细运算放大器原理与应用指南帮你轻松上手!
1. 运算放大器到底是什么? 第一次接触运算放大器时,我也被这个专业名词吓到了。但后来发现,它其实就是个"超级放大镜"——能把微弱的电信号放大成千上万倍。想象一下医生用的听诊器,它能将微弱的心跳声放大到清晰可闻&a…...

AzurLaneAutoScript:碧蓝航线终极自动化助手完全指南
AzurLaneAutoScript:碧蓝航线终极自动化助手完全指南 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 在碧蓝航线…...