6.Java并发编程—深入剖析Java Executors:探索创建线程的5种神奇方式
Executors快速创建线程池的方法
Java通过Executors 工厂提供了5种创建线程池的方法,具体方法如下
| 方法名 | 描述 |
|---|---|
newSingleThreadExecutor() | 创建一个单线程的线程池,该线程池中只有一个工作线程。所有任务按照提交的顺序依次执行,保证任务的顺序性。当工作线程意外终止时,会创建一个新的线程来替代它。适用于需要顺序执行任务且保证任务安全性的场景。 |
newFixedThreadPool(int nThreads) | 创建一个固定大小的线程池,该线程池中的线程数量固定为指定的数量。当有新任务提交时,如果线程池中有空闲线程,则立即使用空闲线程执行任务;如果没有空闲线程,则任务将被放入任务队列等待执行。 |
newCachedThreadPool() | 创建一个缓存线程池,该线程池中的线程数量不固定,可以根据任务的需求动态调整线程数量。空闲线程会被保留一段时间,如果在保留时间内没有任务执行,则这些线程将被终止并从线程池中删除。适用于执行大量短期任务的场景 |
newScheduledThreadPool(int corePoolSize) | 创建一个可调度的线程池,该线程池能够按照一定的调度策略执行任务。除了执行任务外,还可以按照指定的延迟时间或周期性地执行任务。适用于需要按照计划执行任务、定时任务或周期性任务的场景。 |
newWorkStealingPool(int parallelism) | newWorkStealingPool(int parallelism)方法用于创建一个工作窃取线程池。工作窃取线程池是一种特殊的线程池,它根据一定的调度策略执行任务。除了执行任务外,工作窃取线程池还可以按照指定的延迟时间或周期性地执行任务。 |
ThreadFactory
在学习Executor创建线程池之前,我们先来学习一下
ThreadFactory是一个接口,用于创建线程对象的工厂。它定义了一个方法newThread,用于创建新的线程。
在Java中,线程的创建通常通过Thread类的构造函数进行,但是使用ThreadFactory可以将线程的创建过程与线程的执行逻辑分离开来。通过自定义的ThreadFactory,我们可以对线程进行更加灵活的配置和管理,例如指定线程名称、设置线程优先级、设置线程是否为守护线程等。
ThreadFactory接口只有一个方法:
Thread newThread(Runnable runnable);
该方法接受一个Runnable对象作为参数,并返回一个新的Thread对象。
一般情况下,我们可以通过实现ThreadFactory接口来自定义线程的创建。以下是一个示例的自定义ThreadFactory实现:
public class MyThreadFactory implements ThreadFactory {// 自定义线程的名称private final String namePrefix = "test-async-thread";private final AtomicInteger threadNumber = new AtomicInteger(1);public MyThreadFactory(String namePrefix) {this.namePrefix = namePrefix;}@Overridepublic Thread newThread(Runnable runnable) {Thread thread = new Thread(runnable);thread.setName(namePrefix + "-" + threadNumber.getAndIncrement());thread.setPriority(Thread.NORM_PRIORITY);thread.setDaemon(false);return thread;}
}
在上面的示例中,MyThreadFactory实现了ThreadFactory接口,并通过构造函数传入一个namePrefix参数,用于指定线程的名称前缀。
在newThread方法中,首先创建一个新的Thread对象,并设置线程的名称为namePrefix加上一个递增的数字。然后,可以根据需要设置线程的优先级、是否为守护线程等属性。
newSingleThreadExecutor() 创建单线程化线程池
该方法用于创建一个单线程化的线程池,也就是只有一个线程的线程池。该线程池中只有一个工作线程,它负责按照任务的提交顺序依次执行任务。当有任务提交时,会创建一个新的线程来执行任务。如果工作线程意外终止,线程池会创建一个新的线程来替代它,确保线程池中始终有一个可用的线程。
newSingleThreadExecutor()方法返回的线程池实例实现了ExecutorService接口,因此可以使用submit()方法提交任务并获取Future对象,或使用execute()方法提交任务。
该线程池适用于需要顺序执行任务且保证任务之间不会发生并发冲突的场景。由于只有一个工作线程,所以不存在线程间的竞争和并发问题,可以确保任务的安全性。
此外,newSingleThreadExecutor()方法创建的线程池还可以用于任务的异常处理。当任务抛出异常时,线程池会捕获异常并记录或处理异常,避免异常导致整个应用程序崩溃。
需要注意的是,由于该线程池只有一个线程,如果任务执行时间过长或任务量过大,可能会导致任务队列堆积,造成应用程序的性能问题。所以在使用该线程池时,需要根据任务的特性和需求进行适当的评估和调优。
下面我们使用Executors中newSingleThreadExecutor()方法创建一个单线程线程池
/*** 这里创建的线程是 是Executors.newSingleThreadExecutor() 一样 保证只有一个线程来进行执行 并且按照提交的顺序进行执行* <pre>* {@code* public static ExecutorService newSingleThreadExecutor() {* return new Executors.FinalizableDelegatedExecutorService (* new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()));* }* }* </pre>*/@Testpublic void test10() {// 如果有多个任务提交到线程池中,那么这个线程池中的线程会依次执行任务 和ExecutorService executorService = Executors.newSingleThreadExecutor();// 创建线程 1Thread t1 = new Thread(() -> {logger.error("t1 ----> 开始执行了~");}, "t1");// 创建线程 2Thread t2 = new Thread(() -> {logger.error("t2 ----> 开始执行了~");}, "t2");// 创建线程 3Thread t3 = new Thread(() -> {logger.error("t3 ----> 开始执行了~");}, "t3");// Executor 这个接口定义的功能很有限,同时也只支持 Runnale 形式的异步任务// 向线程池提交任务executorService.submit(t1);executorService.submit(t2);executorService.submit(t3);// 关闭线程池executorService.shutdown();}
首先,通过Executors.newSingleThreadExecutor();创建了一个单线程化的线程池。
然后,创建了三个线程t1、t2和t3,分别用于执行不同的任务。
接着,通过executorService.submit(t1)将t1线程提交到线程池中进行执行。同样地,也将t2和t3线程提交到线程池中。
最后,通过executorService.shutdown()关闭线程池。
执行时,可以观察到日志输出的顺序。由于线程池中只有一个线程,所以任务会依次按照提交的顺序进行执行。
需要注意的是,通过线程池执行任务后,线程的名称不再是我们自定义的线程名称,而是线程池的名称(如pool-2-thread-1)。这是因为具体的执行任务是交给线程池来管理和执行的。
从输出中我们可以看出,该线程池有以下特点:
-
单线程化的线程池中的任务,都是按照提交的顺序来进行执行的。
-
该线程池中的唯一线程存活时间是无限的
-
当线程池中唯一的线程正在繁忙时,新提交的任务会进入到其内部的阻塞队列中,而且阻塞队列的容量是无限的
-
// 这是 newSingleThreadExecutor 一个无参的构造方法 public static ExecutorService newSingleThreadExecutor() {// 创建一个FinalizableDelegatedExecutorService实例,该实例是ExecutorService接口的一个包装类// 将上面创建的ThreadPoolExecutor实例作为参数传入// 这样就得到了一个单线程化的线程池return new FinalizableDelegatedExecutorService( // 创建一个ThreadPoolExecutor实例,指定参数如下:// corePoolSize: 1,线程池中核心线程的数量为1// maximumPoolSize: 1,线程池中最大线程的数量为1// keepAliveTime: 0L,空闲线程的存活时间为0毫秒,即空闲线程立即被回收// unit: TimeUnit.MILLISECONDS,存活时间的时间单位是毫秒// workQueue: new LinkedBlockingQueue<Runnable>(),使用无界阻塞队列作为任务队列new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));}// 其中 阻塞队列大小,如果不传容量,默认是整形的最大值 public LinkedBlockingQueue() {this(Integer.MAX_VALUE); } -
总体来说:
ewSingleThreadExecutor();适用于按照任务提交次序,一个接一个的执行场景

newFixedThreadPool 创建固定数量的线程池
该方法用于创建一个
固定数量的线程池,其中唯一的参数是用于设置线程池中线程的数量
newFixedThreadPool是Executors类提供的一个静态方法,用于创建一个固定大小的线程池。方法具体如下
public static ExecutorService newFixedThreadPool(int nThreads)参数
nThreads表示线程池中的线程数量,即固定的线程数量。线程池中的线程数不会根据任务的多少进行动态调整,即使有空闲线程也不会销毁,除非调用了线程池的shutdown方法。
newFixedThreadPool方法返回一个ExecutorService对象,它是Executor接口的子接口,提供了更加丰富的任务提交和管理方法。通过创建固定大小的线程池,可以在任务并发量较高且预期的任务数量固定的情况下,提供一定程度的线程复用和线程调度控制。线程池会根据固定的线程数量来创建对应数量的线程,并将任务分配给这些线程进行执行。
线程池的工作原理如下:
- 当有任务提交到线程池时,线程池中的某个线程会被唤醒来执行任务。
- 如果所有线程都在执行任务,新的任务会被放入一个任务队列中等待执行。
- 当任务队列已满时,线程池会根据配置的拒绝策略来处理无法执行的任务。
需要注意的是,由于线程池的大小是固定的,如果任务数量超过线程池的容量,任务会在任务队列中等待执行。这可能会导致任务等待时间增加或任务堆积,进而影响系统的响应性能。因此,在选择线程池大小时,需要根据系统的负载情况和任务特点进行合理的配置。
下面我们通过代码来了解一下 newFixedThreadPool
@Testpublic void test18() {ThreadPoolExecutor executor = (ThreadPoolExecutor) Executors.newFixedThreadPool(2);executor.submit(new Runnable() {@Overridepublic void run() {// 随机睡觉timeSleep();printPoolInfo(executor, "*[耗时线程-1]");}});executor.submit(new Runnable() {@Overridepublic void run() {// 随机睡觉timeSleep();printPoolInfo(executor, "*[耗时线程-2]");}});executor.submit(new Runnable() {@Overridepublic void run() {timeSleep();printPoolInfo(executor, "*[耗时线程-3]");}});for (int i = 0; i < 5; i++) {int finalI = i;executor.submit(new Runnable() {@Overridepublic void run() {printPoolInfo(executor, "普通线程");}});}// 优雅关闭线程池executor.shutdown();waitPoolExecutedEnd(executor);}// 这个方法用于等待线程全部执行结束public void waitPoolExecutedEnd(ThreadPoolExecutor executor) {// 确保主线程完全等待子线程执行完毕try {// 等待线程池中的任务执行完毕,最多等待1天if (!executor.awaitTermination(5, TimeUnit.MINUTES)) {logger.error("线程池中的任务还未全部执行完毕~");}} catch (InterruptedException e) {logger.error("等待线程池中的任务被中断~");}}
这段代码创建了一个固定大小为2的线程池 executor,并向其中提交了多个任务。其中:
- 通过
Executors.newFixedThreadPool(2)创建了一个固定大小为2的线程池。 - 向线程池中提交了多个任务,包括两个耗时任务和五个普通任务。
- 每个耗时任务都会执行
timeSleep()方法进行一段随机时间的睡眠,然后执行printPoolInfo()方法输出当前线程池的信息。 - 普通任务直接执行
printPoolInfo()方法输出当前线程池的信息。 - 在所有任务提交完毕后,调用
executor.shutdown()方法优雅地关闭线程池,并调用waitPoolExecutedEnd(executor)方法等待线程池中的任务执行完毕。
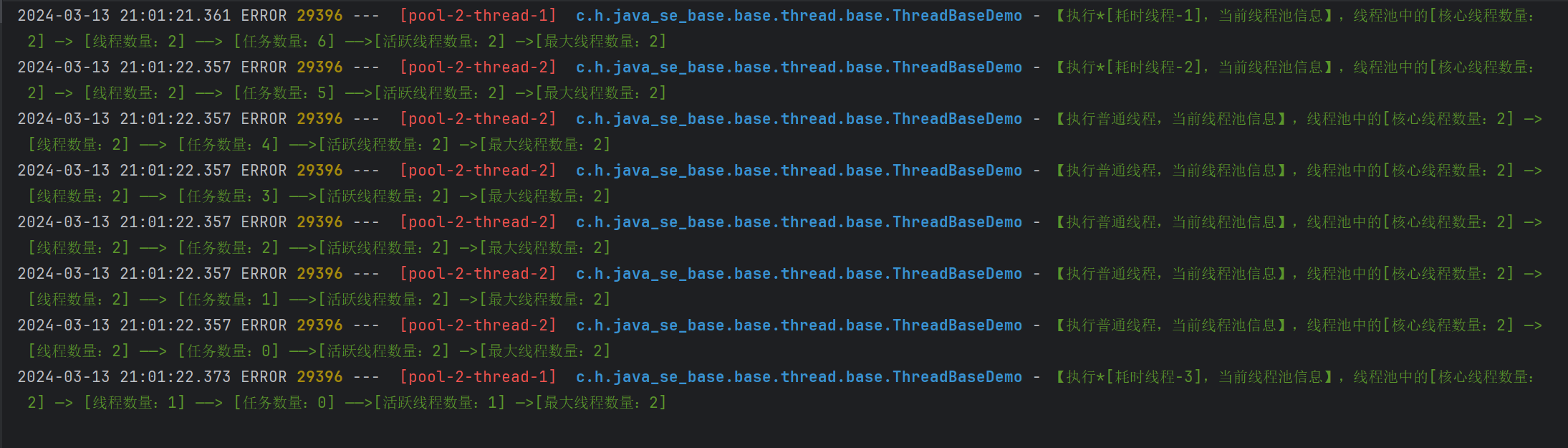
根据输出的结果 我们可以观察到
- 当第一个耗时任务执行时,线程池中有2个核心线程在工作。
- 当第三个任务执行时,线程池中的任务数量已经达到5个,但是活跃线程数量仍然为2,说明任务正在等待空闲线程来执行。
- 所有任务执行完成后,线程池中的线程数量仍然保持为2,这是因为线程池是一个固定大小的线程池。
- 在任务执行的过程中,线程池的核心线程数量一直为2,线程数量也一直保持在2个,因为线程池的大小是固定的。
固定大小线程池适用于以下场景:
- 资源受限场景:当系统资源受限,无法创建过多线程时,固定大小线程池能够限制线程数量,防止系统资源被耗尽。
- 稳定的任务处理:适用于稳定的任务处理场景,例如批量数据处理、定时任务等,因为固定大小线程池能够保持一定数量的线程长时间运行,避免线程的频繁创建和销毁。
- 控制并发数量:在需要限制并发数量的场景下,固定大小线程池能够控制同时执行的任务数量,防止系统过载。
- 避免资源竞争:固定大小线程池可以避免多个任务争夺系统资源而导致的竞争和性能下降。
- 稳定的性能预测:在需要稳定的性能预测下,固定大小线程池能够提供一致的性能表现,因为线程数量是固定的,可以更好地进行性能测试和预测。
newCachedThreadPool 创建可以缓存的线程池
newCachedThreadPool 用于创建一个
可以缓存的线程池,如果线程内的某些线程无事可干,那么就会成为空线程,可缓存线程池,可以灵活回收这些空闲线程
newCachedThreadPool是Executors类提供的一个静态方法,用于创建一个缓存型线程池。方法定义如下
public static ExecutorService newCachedThreadPool()
newCachedThreadPool方法返回一个ExecutorService对象,它是Executor接口的子接口,提供了更加丰富的任务提交和管理方法。缓存型线程池会根据需要自动创建和回收线程,线程池的大小可以根据任务的数量自动调整。如果当前没有可用的空闲线程,会创建新的线程来执行任务;如果有空闲线程并且它们在指定的时间内没有执行任务,那么这些空闲线程将会被回收。
使用缓存型线程池的优点是可以根据任务的数量动态调整线程池的大小,以适应不同的负载情况。当任务数量较少时,线程池会减少线程的数量以节省资源;当任务数量增加时,线程池会增加线程的数量以提高并发性。
需要注意的是,由于缓存型线程池的大小是不限制的,它可能会创建大量的线程,如果任务的提交速度超过了线程执行任务的速度,可能会导致系统资源消耗过多,甚至造成系统崩溃。因此,在使用缓存型线程池时,需要根据任务特点和系统资源情况进行合理的配置。
下面我们通过一个案例,来了解一下newCachedThreadPool,但是了解newCachedThreadPool之前,我们先来熟悉一个阻塞队列,这个会在后面的阻塞队列专题中详细介绍,这里只是作为了解
SynchronousQueue
- 无内部存储容量:与其他阻塞队列不同,SynchronousQueue 不存储元素,其容量为零。换句话说,它是一个零容量的队列,用于在线程之间同步传输数据。
- 阻塞队列:作为 BlockingQueue 接口的一个实现,SynchronousQueue 提供了阻塞操作,允许线程在队列的插入和移除操作上进行阻塞等待。
- 匹配插入和移除操作:在 SynchronousQueue 中,每个插入操作必须等待另一个线程的移除操作,反之亦然。换句话说,发送线程必须等待接收线程,而接收线程也必须等待发送线程,才能够完成操作。这样的特性保证了数据的可靠传输,只有在有线程与之匹配时,才会进行数据传输。
- 不支持 peek 操作:由于 SynchronousQueue 内部没有存储元素,因此不能调用 peek 操作。只有在移除元素时才会有元素可供操作。
- 支持公平和非公平模式:SynchronousQueue 可以在构造时指定为公平或非公平模式。在公平模式下,队列会按照线程的到达顺序进行操作;而在非公平模式下,则不保证操作的顺序。
SynchronousQueue 在多线程并发编程中常用于一些特定场景,例如生产者-消费者模式中,用于传输数据的场景,以及一些任务执行器中用于任务的传递等。其特殊的同步机制保证了线程之间数据的可靠传输和同步操作。
基于SynchronousQueue 一个小案例
/*** 理解SynchronousQueue* SynchronousQueue,实际上它不是一个真正的队列,因为SynchronousQueue没有容量。与其他BlockingQueue(阻塞队列)不同,* SynchronousQueue是一个不存储元素的BlockingQueue。只是它维护一组线程,这些线程在等待着把元素加入或移出队列。* 我们简单分为以下几种特点:* 内部没有存储(容量为0)* 阻塞队列(也是blockingqueue的一个实现)* 发送或者消费线程会阻塞,只有有一对消费和发送线程匹配上,才同时退出。* (其中每个插入操作必须等待另一个线程的移除操作,同样任何一个移除操作都等待另一个线程的插入操作。因此此队列内部其 实没有任何一个元素,因此不能调用peek操作,因为只有移除元素时才有元素。)* 配对有公平模式和非公平模式(默认)*/@Testpublic void test19() throws InterruptedException {SynchronousQueue<String> queue = new SynchronousQueue<>();// 我们通过线程内 入队 和 出队 了解下 SynchronousQueue的特性new Thread(new Runnable() {@Overridepublic void run() {try {// 入队logger.error("---- 喜羊羊进锅,沐浴~ ----");queue.put("喜羊羊!");logger.error("---- 懒羊羊进锅,沐浴~ ----");queue.put("懒羊羊!");logger.error("---- 美羊羊进锅,沐浴~ ----");queue.put("美羊羊!");} catch (InterruptedException e) {throw new RuntimeException(e);}}}, "t1").start();new Thread(new Runnable() {@Overridepublic void run() {try {// 入队Thread.sleep(5000);String node1 = queue.take();logger.error("---- {} 出锅~ ----", node1);Thread.sleep(10000);String node2 = queue.take();logger.error("---- {} 出锅~ ----", node2);Thread.sleep(5000);String node3 = queue.take();logger.error("---- {} 出锅~ ----", node3);} catch (InterruptedException e) {throw new RuntimeException(e);}}}, "t2").start();Thread.sleep(Integer.MAX_VALUE);}

// 根据 结果可以发现, 三只羊同时进锅,但是一个锅只能容纳一只羊,所以只有一只羊能进锅,其他的羊只能等待,直到锅里的羊出锅,才能进锅// 也就是说,SynchronousQueue是一个不存储元素的BlockingQueue。只是它维护一组线程,这些线程在等待着把元素加入或移出队列。// 喜羊羊进锅,然后等待 5s后 喜羊羊出锅,此时美羊羊开始进锅
了解这个阻塞队列后,我们再来了解一下newCachedThreadPool这个线程池,还是通过一个案例来进行了解一下具体用法
/*** newCachedThreadPool 创建可以缓存的线程池*/@Testpublic void test17() {// 创建可以缓存的线程池// 创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。// keepAliveTime为60S,意味着线程空闲时间超过60S就会被杀死(60L)ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) Executors.newCachedThreadPool();// 这里使用两个线程,异步执行// 此处 羊羊线程是不休眠的,直接放入线程池new Thread(() -> {for (int i = 0; i < 2; i++) {int finalI = i;threadPoolExecutor.submit(() -> {printPoolInfo(threadPoolExecutor, "羊羊线程" + finalI + "-正在执行");});}}, "任务线程-1").start();// 狼狼线程 此时第一个线程也是不会进行阻塞,此时应该是 三个线程 (两个羊羊+一个狼狼 同时进线程池)new Thread(() -> {for (int i = 0; i < 5; i++) {if (i == 1 || i == 2) {try {Thread.sleep(TimeUnit.SECONDS.toMillis(5));} catch (InterruptedException e) {throw new RuntimeException(e);}}int finalI = i;threadPoolExecutor.submit(() -> {printPoolInfo(threadPoolExecutor, "狼狼线程" + finalI + "-正在执行");});}}, "任务线程-2").start();// 等待全部线程都执行完毕waitPoolExecutedEnd(threadPoolExecutor);threadPoolExecutor.shutdown();}这段代码的主要逻辑如下
- 使用
Executors.newCachedThreadPool()创建了一个可缓存的线程池threadPoolExecutor。这种线程池的特点是,如果线程池长度超过当前任务需求,它会灵活地回收空闲线程;若没有可回收的线程,则会新建线程来处理任务。线程的空闲时间超过60秒后,就会被回收。 - 创建了两个新的线程,分别用于提交任务到线程池中执行。其中,一个线程负责提交羊羊线程,另一个线程负责提交狼狼线程。
- 羊羊线程的任务不会进行阻塞,直接提交到线程池中执行。
- 狼狼线程的任务中,当
i等于1或2时,会进行5秒的睡眠,模拟任务的耗时操作,然后再提交到线程池中执行。 - 使用
waitPoolExecutedEnd(threadPoolExecutor)方法等待线程池中的任务执行完毕。 - 在所有任务执行完毕后,调用
threadPoolExecutor.shutdown()方法关闭线程池。
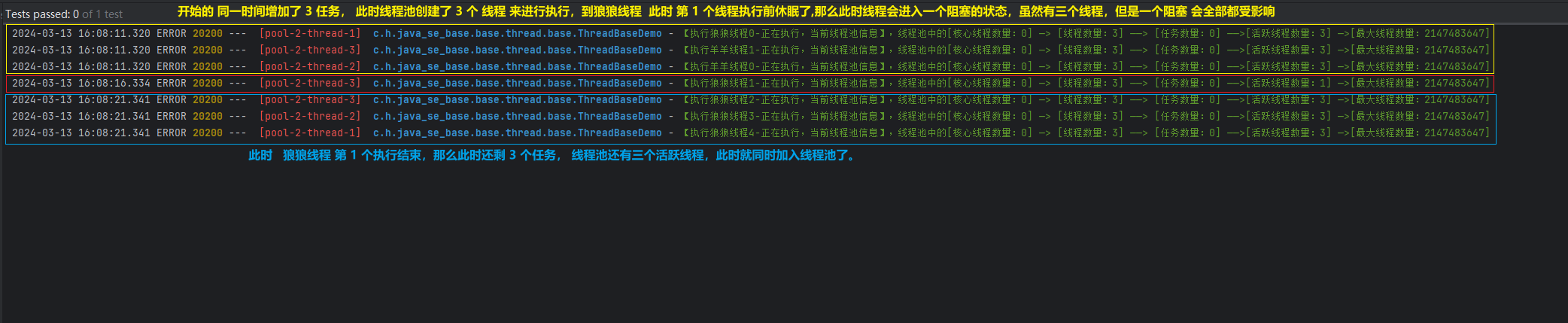
- 通过结果可以看到每个任务的执行都是间隔5秒执行一次。
- 线程池信息中的线程数量始终为3,这是因为
Executors.newCachedThreadPool()创建的是一个可缓存的线程池,其最大线程数量为 Integer.MAX_VALUE,因此当任务提交到线程池时,如果没有空闲线程可用,则会新建线程来处理任务,线程数量会一直增加,直到达到设定的最大值。 - 在任务提交时,活跃线程数量始终为3,这是因为每次提交任务时,都有空闲线程可用,所以不需要新建线程,而是直接使用已存在的线程执行任务。
- 狼狼线程的任务会进行5秒的睡眠操作,模拟耗时操作,因此在执行任务期间,线程池中的活跃线程数量会减少,直到任务执行完毕后,线程池会继续维持3个活跃线程数量。
- 在执行完所有任务后,线程池并不会立即关闭,因为线程池是可缓存的,会等待一段时间后空闲线程自动被回收。
应用场景:
- 短期任务处理:适用于处理大量短期任务的场景,因为它能够根据需要动态地创建线程,处理任务,处理完毕后又自动回收线程,避免了线程过多占用资源的问题。
- 任务处理时间不确定:适用于任务处理时间不确定的场景,因为它能够根据实际情况动态调整线程数量,保证任务能够及时得到处理,提高系统的响应速度。
- 需要快速响应的任务:适用于需要快速响应的任务,因为它能够快速地创建线程来处理任务,缩短任务等待的时间,提高任务的处理效率。
- 任务负载波动大:适用于任务负载波动大的场景,因为它能够根据负载情况动态调整线程数量,使系统能够更好地适应负载的变化。
缺点:
- 线程数量不受限制:由于
newCachedThreadPool的最大线程数量为 Integer.MAX_VALUE,因此在大量任务提交的情况下,可能会导致线程数量过多,占用大量系统资源,导致系统负载过高,甚至引发系统崩溃。 - 不适用于长时间任务:由于它的线程数量不受限制,适用于处理短期任务,但不适用于长时间任务,因为长时间任务可能会导致线程数量过多,占用大量系统资源。
- 可能导致频繁创建和销毁线程:由于
newCachedThreadPool是一个动态的线程池类型,可能会频繁地创建和销毁线程,这种线程的创建和销毁操作会带来一定的性能开销。
综上所述,newCachedThreadPool 适用于任务处理时间不确定、负载波动大、需要快速响应的场景,但在大量长时间任务的情况下,需要慎重选择以避免占用过多系统资源。
newScheduledThreadPool 创建可调度的线程池
项目中经常会遇到一些非分布式的调度任务,需要在未来的某个时刻周期性执行。实现这样的功能,我们有多种方式可以选择:
- Timer类, jdk1.3引入,不推荐
- 它所有任务都是串行执行的,同一时间只能有一个任务在执行,而且前一个任务的延迟或异常都将会影响到之后的任务。
- Spring的@Scheduled注解,不是很推荐
- 这种方式底层虽然是用线程池实现,但是有个最大的问题,所有的任务都使用的同一个线程池,可能会导致长周期的任务运行影响短周期任务运行,造成线程池"饥饿",更加推荐的做法是同种类型的任务使用同一个线程池。
- 自定义ScheduledThreadPoolExecutor实现调度任务
这也是下面重点讲解的方式,通过自定义ScheduledThreadPoolExecutor调度线程池,提交调度任务才是最优解。
newScheduledThreadPool用于创建一个可调度的线程,newScheduledThreadPool是Executors类提供的一个静态方法方法如下
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
newScheduledThreadPool方法返回一个ScheduledExecutorService对象,它是ExecutorService接口的子接口,提供了任务调度的能力。可调度的线程池可以用于延时执行任务和周期性执行任务。它可以根据需要自动创建和回收线程,并且可以在指定的延时时间后执行任务,或在指定的时间间隔内重复执行任务。
使用
newScheduledThreadPool创建的可调度线程池有以下特点:
corePoolSize参数指定了线程池的核心线程数,即线程池中同时执行任务的最大线程数。- 当任务的延时时间到达时,线程池会创建新的线程来执行任务。
- 如果线程池中的线程数量超过核心线程数,空闲的线程会在指定的时间内被回收。
- 可以使用
schedule方法来延时执行任务,也可以使用scheduleAtFixedRate方法或scheduleWithFixedDelay方法来周期性执行任务。使用示例:
ScheduledExecutorService executor = Executors.newScheduledThreadPool(3); executor.schedule(() -> {// 延时执行的任务逻辑 }, 5, TimeUnit.SECONDS);executor.scheduleAtFixedRate(() -> {// 周期性执行的任务逻辑 }, 1, 3, TimeUnit.SECONDS);executor.scheduleWithFixedDelay(() -> {// 周期性执行的任务逻辑 }, 2, 4, TimeUnit.SECONDS);在示例中,
schedule方法用于延时执行任务,它接受一个任务和延时时间,表示在指定的延时时间后执行任务。
scheduleAtFixedRate方法用于周期性执行任务,它接受一个任务、初始延时时间和周期时间,表示在初始延时时间后开始执行任务,并以指定的周期时间重复执行任务。
scheduleWithFixedDelay方法也用于周期性执行任务,它接受一个任务、初始延时时间和周期时间,表示在初始延时时间后开始执行任务,并在任务执行完成后等待指定的周期时间,然后再执行下一个任务。总之,
newScheduledThreadPool方法用于创建一个可调度的线程池,可以用于延时执行任务和周期性执行任务。通过合理配置延时时间和周期时间,可以满足不同场景下的任务调度需求。
下面我们通过一个案例来了解如何创建延时线程 和 定时线程
@Testpublic void test20() {// 使用Executors.newScheduledThreadPool 创建线程池ScheduledThreadPoolExecutor scheduledThreadPool = (ScheduledThreadPoolExecutor) Executors.newScheduledThreadPool(5, new ThreadFactory() {@Overridepublic Thread newThread(Runnable r) {// 对线程名称进行自定义return new Thread(r, "my-scheduled-job-" + r.hashCode());}});// 准备工作DelayedThread delayedThread = new DelayedThread();LoopThread loopThread = new LoopThread();// 执行延时线程 (延时 10s开始执行 )logger.error("延时线程工作准备结束!");scheduledThreadPool.schedule(delayedThread, 10, TimeUnit.SECONDS);// 执行循环线程// scheduleAtFixedRate(Runnable command,long initialDelay,long period,TimeUnit unit)// command: 执行的任务// initialDelay: 初始延迟的时间// delay: 上次执行结束,延迟多久执行// unit:单位logger.error("循环线程工作准备结束!");scheduledThreadPool.scheduleAtFixedRate(loopThread, 10, 5, TimeUnit.SECONDS);waitPoolExecutedEnd(scheduledThreadPool);scheduledThreadPool.shutdown();}static class DelayedThread implements Runnable {@Overridepublic void run() {logger.error("延时线程正在开始执行~~");}}static class LoopThread implements Runnable {@Overridepublic void run() {logger.error("循环线程开始执行~~");}}
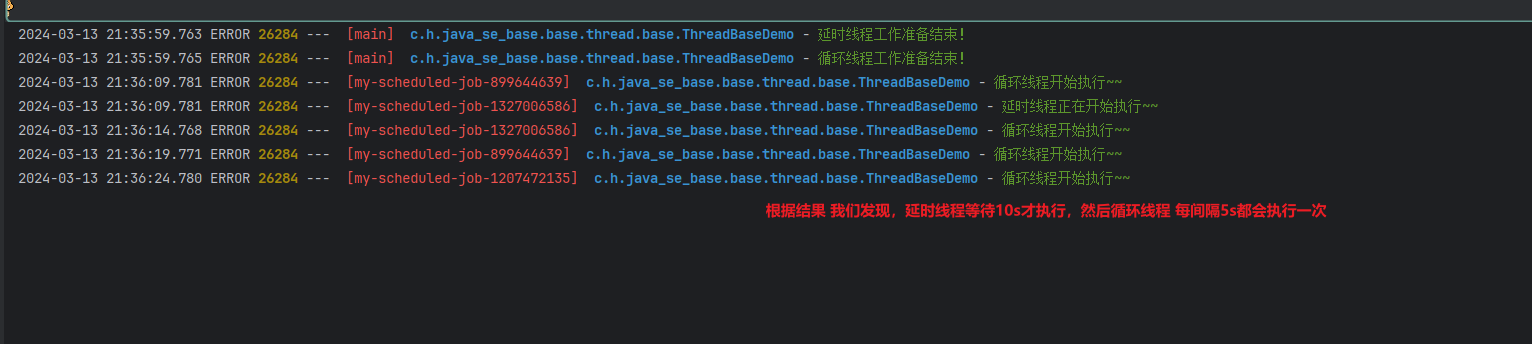
首先,通过Executors.newScheduledThreadPool方法创建了一个可调度的线程池ScheduledThreadPoolExecutor,并指定了线程池的核心线程数为5。同时,通过自定义的ThreadFactory来创建线程,并给线程指定了自定义的名称。
接下来,定义了两个任务类DelayedThread和LoopThread,分别实现Runnable接口。
在测试方法中,首先创建了DelayedThread和LoopThread的实例。
然后,在测试方法中,首先创建了DelayedThread和LoopThread的实例。
然后,通过调用scheduledThreadPool.schedule方法,将DelayedThread任务提交给线程池,并指定延时时间为10秒。这意味着DelayedThread任务将在10秒后执行。
接着,通过调用scheduledThreadPool.scheduleAtFixedRate方法,将LoopThread任务提交给线程池,并指定初始延时时间为10秒、周期时间为5秒。这意味着LoopThread任务将在初始延时时间后开始执行,并且每隔5秒重复执行一次。
最后,调用waitPoolExecutedEnd方法等待线程池中的任务执行完毕,并调用线程池的shutdown方法关闭线程池。
总结起来,这段代码演示了使用Executors.newScheduledThreadPool创建可调度的线程池,并展示了延时执行和周期性执行的例子。通过合理配置延时时间和周期时间,可以实现在指定的时间点或时间间隔内执行任务。
newWorkStealingPool 创建一个可窃取任务的线程池
newWorkStealingPool(int parallelism)方法用于创建一个工作窃取线程池。工作窃取线程池是一种特殊的线程池,它根据一定的调度策略执行任务。除了执行任务外,工作窃取线程池还可以按照指定的延迟时间或周期性地执行任务。工作窃取线程池最早由美国计算机科学家 Charles E. Leiserson 和 John C. Bains 发明,他们在 1994 年的论文《Scheduling Multithreaded Computations by Work Stealing》中首次提出了这一概念。
工作窃取线程池的设计初衷是为了解决并行计算中独立任务的负载均衡问题。在并行计算中,通常存在大量的独立任务需要并行执行,而这些独立任务的执行时间往往不一致。如果简单地将任务平均分配给每个线程,那些执行时间较短的任务将会导致线程空闲,而执行时间较长的任务则可能导致线程被阻塞,从而降低整体的执行效率。
为了解决这个问题,工作窃取线程池引入了工作窃取算法。该算法允许空闲线程从其他线程的任务队列末尾窃取任务来执行,以实现负载均衡。每个线程都维护一个自己的任务队列,当线程自己的任务执行完毕后,它会尝试从其他线程的任务队列末尾窃取任务执行。这样,任务的分配和执行可以更加均衡,避免线程之间出现明显的负载不均衡。
我们了解 newWorkStealingPool 先来了解一下Fork/Join
Fork/Join框架是Java提供的一种并行执行任务的框架,它基于工作窃取算法实现任务的自动调度和负载均衡。在Fork/Join框架中,工作窃取线程池是其中的核心组件。
Fork/Join框架的工作原理如下:
- 每个任务被划分为更小的子任务,这个过程通常被称为"fork"。
- 当一个线程执行"fork"操作时,它会将子任务放入自己的工作队列中。
- 当一个线程完成自己的任务后,它会从其他线程的工作队列中"steal"(窃取)任务来执行。
- 窃取的任务通常是其他线程工作队列的末尾的任务,这样可以减少线程之间的竞争。
工作窃取线程池在Fork/Join框架中的应用主要体现在以下几个方面:
- 任务分割: 在Fork/Join框架中,任务被递归地分割成更小的子任务,直到达到某个终止条件。工作窃取线程池中的线程负责执行这些任务。
每个线程都有自己的任务队列,当一个线程执行完自己的任务后,会从自己的队列中获取新的任务来执行。 - 负载均衡: 工作窃取线程池通过
工作窃取算法实现负载均衡。当一个线程的任务队列为空时,它会从其他线程的任务队列中窃取任务来执行,以保持各个线程的工作量相对均衡。这种负载均衡策略可以避免线程之间出现明显的负载不均衡,提高整体的执行效率。 - 递归任务执行: Fork/Join框架中的任务通常是
递归执行的。当一个任务被分割成多个子任务时,每个子任务会被提交到工作窃取线程池中执行。如果子任务还可以进一步分割,线程会继续执行这个过程,直到任务不能再分割为止。这种递归的任务执行方式能够充分利用线程池中的线程资源,提高并行任务的执行效率。 - Join操作: 在Fork/Join框架中,
一个任务可以等待其子任务执行完成后再继续执行,这个操作被称为"join"。工作窃取线程池在执行任务时会自动进行join操作,确保任务的执行顺序满足依赖关系。这样可以避免线程之间的竞争和冲突,保证任务的正确性。
总的来说,工作窃取线程池在Fork/Join框架中扮演着重要的角色。它通过工作窃取算法和负载均衡策略,实现了并行任务的自动调度和执行。通过递归任务执行和join操作,工作窃取线程池能够高效地处理大量的并行任务,并充分利用系统的并行计算能力。
newWorkStealingPool 是一个创建工作窃取线程池的方法,它使用了ForkJoinPool,并根据CPU核心数动态调整线程数量。这种线程池适用于CPU密集型的任务。
与其他四种线程池不同,newWorkStealingPool 使用了ForkJoinPool。它的优势在于将一个任务拆分成多个小任务,并将这些小任务分发给多个线程并行执行。当所有小任务都执行完成后,再将它们的结果合并。
相较于之前的线程池,newWorkStealingPool 中的每个线程都拥有自己的任务队列,而不是多个线程共享一个阻塞队列。
当一个线程发现自己的任务队列为空时,它会去其他线程的队列中窃取任务来执行。可以将这个过程简单理解为"窃取"。为了降低冲突,一般情况下,自己的本地队列采用后进先出(LIFO)的顺序,而窃取时则采用先进先出(FIFO)的顺序。由于窃取的动作非常快速,这种冲突会大大降低,从而提高了性能。这也是一种优化方式。
下面我们通过一个案例 来了解一下 newWorkStealingPool
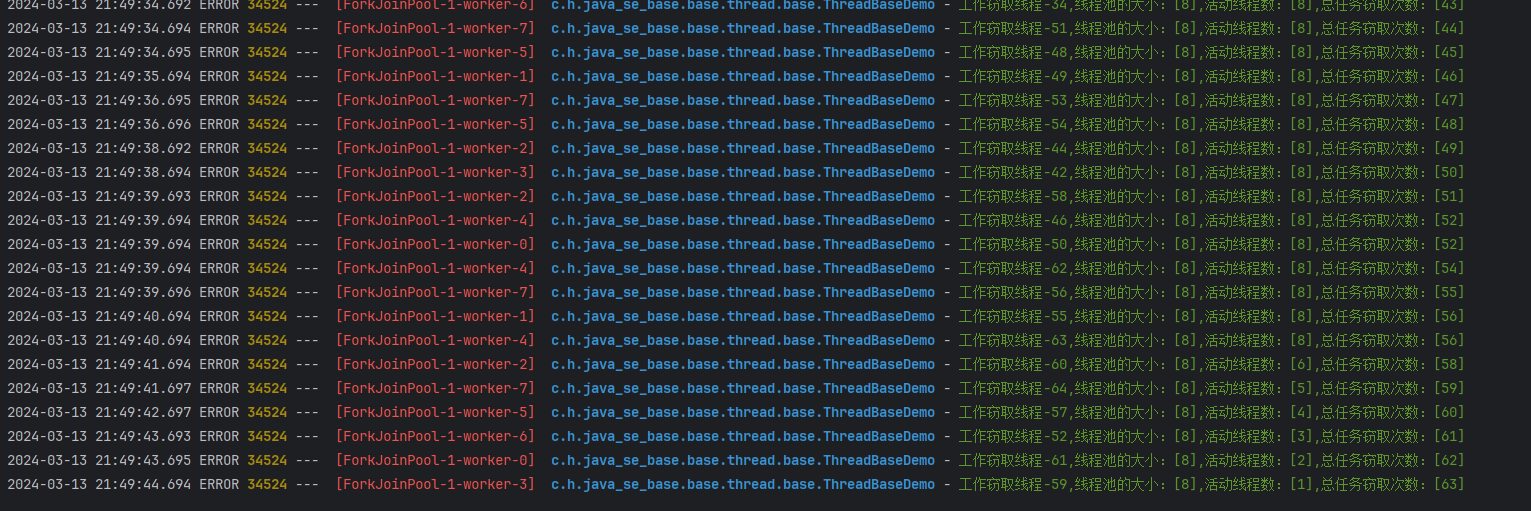
@Testpublic void test21() {// 返回可用的计算资源int core = Runtime.getRuntime().availableProcessors();logger.error("cpu 可以计算机资源 :{}", core);// 无参数的话,会根据cpu当前核心数据 动态分配// ExecutorService executorService = Executors.newWorkStealingPool();// 当传入参数,就可以指定cpu的一个并行数量ForkJoinPool forkJoinPool = (ForkJoinPool) Executors.newWorkStealingPool(8);for (int i = 1; i <= core * 2; i++) {WorkStealThread workStealThread = new WorkStealThread(i, forkJoinPool);forkJoinPool.submit(workStealThread);}// 优雅关闭forkJoinPool.shutdown();// 为了防止 主线程 没有完全执行结束try {Thread.sleep(Integer.MAX_VALUE);} catch (InterruptedException e) {throw new RuntimeException(e);}}static class WorkStealThread implements Runnable {private int i;private ForkJoinPool forkJoinPool;WorkStealThread() {}WorkStealThread(int i, ForkJoinPool forkJoinPool) {this.i = i;this.forkJoinPool = forkJoinPool;}@Overridepublic void run() {try {// 随机休眠Thread.sleep(TimeUnit.SECONDS.toMillis(new Random().nextInt(10)));} catch (InterruptedException e) {throw new RuntimeException(e);}logger.error("工作窃取线程-{},线程池的大小:[{}],活动线程数:[{}],总任务窃取次数:[{}]",i, forkJoinPool.getPoolSize(), forkJoinPool.getActiveThreadCount(), forkJoinPool.getStealCount());}}当代码运行时,首先通过Runtime.getRuntime().availableProcessors()获取可用的计算资源,即CPU核心数,并将其记录在日志中。
接下来,使用Executors.newWorkStealingPool(8)创建一个工作窃取线程池,其中参数8表示线程池的并行度,即同时执行的线程数。这个线程池是基于ForkJoinPool实现的,具有任务窃取的特性。
然后,通过一个循环将一些工作窃取线程提交到线程池中进行并行执行。每个工作窃取线程都有一个编号,从1到核心数的两倍。这些线程使用WorkStealThread类实现了Runnable接口。
WorkStealThread类中的run方法定义了线程的执行逻辑。首先,线程会随机休眠一段时间,模拟执行一些耗时的任务。然后,它会输出一些关于线程池状态的信息,包括线程池的大小、活动线程数和总任务窃取次数。这些信息会记录在日志中。
最后,线程池会被优雅地关闭,确保所有任务都能执行完毕。为了防止主线程提前结束,使用Thread.sleep(Integer.MAX_VALUE)使主线程休眠,直到被中断或抛出异常。
通过以上代码,我们可以了解到如何使用newWorkStealingPool方法创建工作窃取线程池,并通过工作窃取线程实现并行执行。同时,通过获取线程池的状态信息,我们可以了解线程池的工作情况,包括活动线程数和任务窃取次数。
通过观察结果,我们可以发现,当前线程执行完毕,如果空闲的话,会去执行别的线程任务
相关文章:
6.Java并发编程—深入剖析Java Executors:探索创建线程的5种神奇方式
Executors快速创建线程池的方法 Java通过Executors 工厂提供了5种创建线程池的方法,具体方法如下 方法名描述newSingleThreadExecutor()创建一个单线程的线程池,该线程池中只有一个工作线程。所有任务按照提交的顺序依次执行,保证任务的顺序性…...

英语阅读挑战
英语阅读真是令人头痛的东西。可怜的子航想利用寒假时间突破英语难题。当他拿到一篇英语阅读时,他很好奇作者最喜欢用那些字母。 输入 一句30词以内的英语句子 输出 统计每个字母出现的次数 样例输入 复制 However,the British dont have a history of exporting th…...

备战蓝桥之思维
平台重叠真的坑 给你一句样例,如果你觉得自己的代码没问题那就试试吧 2 1 1 3 1 0 4 正确答案 0 0 0 0 P1105 平台 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) import java.awt.Checkbox; import java.awt.PageAttributes.OriginType; import java.io.B…...

09 string的实现
注意 实现仿cplus官网的的string类,对部分主要功能实现 实现 头文件 #pragma once #include <iostream> #include <assert.h> #include <string>namespace mystring {class string{friend std::ostream& operator<<(std::ostream&a…...

Git 进行版本控制时,配置 user.name 和 user.email
在使用 Git 进行版本控制时,配置 user.name 和 user.email 是一个非常重要的初始步骤,但不是绝对必须的。这两个配置项定义了当你进行提交(commit)时用于标识提交者的信息。 为什么建议配置 user.name 和 user.email 标识提交者…...

传统开发读写优化与HBase
目录: 一、传统开发数据读写性能优化 1. Mysql 分表、主从复制与读写分离 2. Redis(缓存型数据库)主从复制与读写分离 二、HBase 一、传统开发数据读写性能优化 1、Mysql 分表、主从复制与读写分离 mysql分库分表方案 一种分表方案:设置表A 表B 表A 自增列从1开始…...

【OpenGL实现 03】纹理贴图原理和实现
目录 一、说明二、纹理贴图原理2.1 纹理融合原理2.2 UV坐标原理 三、生成纹理对象3.1 需要在VAO上绑定纹理坐标3.2 纹理传递3.3 纹理buffer生成 四、代码实现:五、着色器4.1 片段4.2 顶点 五、后记 一、说明 本篇叙述在画出图元的时候,如何贴图纹理图片…...

FDU 2021 | 二叉树关键节点的个数
文章目录 1. 题目描述2. 我的尝试 1. 题目描述 给定一颗二叉树,树的每个节点的值为一个正整数。如果从根节点到节点 N 的路径上不存在比节点 N 的值大的节点,那么节点 N 被认为是树上的关键节点。求树上所有的关键节点的个数。请写出程序,并…...
精读《React Conf 2019 - Day2》
1 引言 这是继 精读《React Conf 2019 - Day1》 之后的第二篇,补充了 React Conf 2019 第二天的内容。 2 概述 & 精读 第二天的内容更为精彩,笔者会重点介绍比较干货的部分。 Fast refresh Fast refresh 是更好的 react-hot-loader 替代方案&am…...

向ChatGPT高效提问模板
PS: ChatGPT无限次数,无需魔法,登录即可使用,网页打开下面 tj4.mnsfdx.net [点击跳转链接](http://tj4.mnsfdx.net/) 我想请你XXXX,请问我应该如何向你提问才能得到最满意的答案,请提供全面、详细的建议,针对每一个建…...

android metaRTC编译
参考文章: metaRTC3.0稳定版本编译指南_metartc 编译-CSDN博客 源码下载: Releases metartc/metaRTC GitHub 版本v6.0-b4即可...

HDFS面试重点
文章目录 1. HDFS的架构2. HDFS的读写流程3.HDFS中,文件为什么以block块的方式存储? 1. HDFS的架构 HDFS的架构可以分为以下几个主要组件: NameNode(名称节点): NameNode是HDFS的关键组件之一,…...

Java中的IO流是什么?
Java中的IO流(Input/Output Stream)是Java编程语言中用于处理输入和输出操作的一种重要机制。在Java中,IO流被用来读取和写入数据,这些数据可以来自各种来源,如文件、网络连接、内存缓冲区等。Java的IO流提供了丰富的类…...
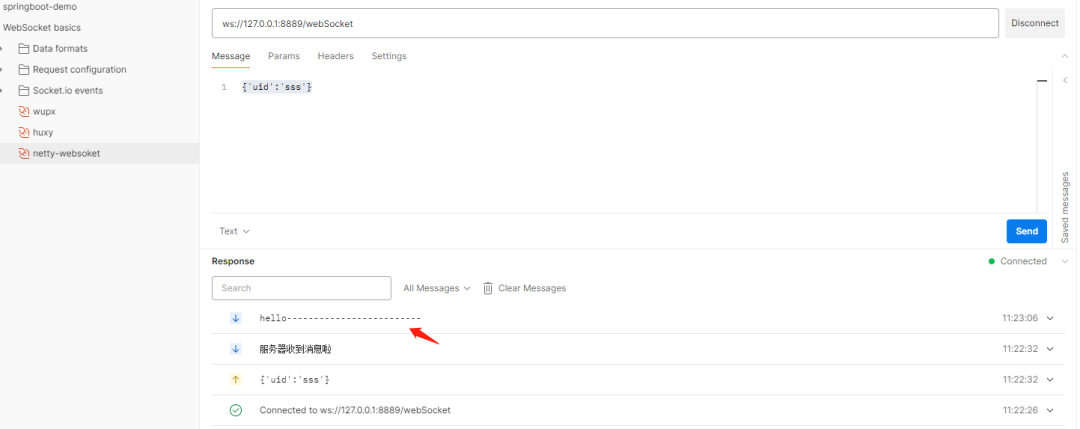
Spring boot 集成netty实现websocket通信
一、netty介绍 Netty 是一个基于NIO的客户、服务器端的编程框架,使用Netty 可以确保你快速和简单的开发出一个网络应用,例如实现了某种协议的客户、服务端应用。Netty相当于简化和流线化了网络应用的编程开发过程,例如:基于TCP和U…...
数码管的动态显示(二)
1.原理 这个十六进制是右边的dp为高位。 数码管的动态显示,在第一个计数周期显示个位,在第二个周期显示十位,在第三个周期显示百位由于人眼的视觉和数码管的特性,感觉就是显示了234,每个数码管的显示需要从输入的数据里…...
【JavaScript】数据类型转换 ① ( 隐式转换 和 显式转换 | 常用的 数据类型转换 | 转为 字符串类型 方法 )
文章目录 一、 JavaScript 数据类型转换1、数据类型转换2、隐式转换 和 显式转换3、常用的 数据类型转换4、转为 字符串类型 方法 一、 JavaScript 数据类型转换 1、数据类型转换 在 网页端 使用 HTML 表单 和 浏览器输入框 prompt 函数 , 接收的数据 是 字符串类型 变量 , 该…...
git学习(创建项目提交代码)
操作步骤如下 git init //初始化git remote add origin https://gitee.com/aydvvs.git //建立连接git remote -v //查看git add . //添加到暂存区git push 返送到暂存区git status // 查看提交代码git commit -m初次提交git push -u origin "master"//提交远程分支 …...
Day36:安全开发-JavaEE应用第三方组件Log4j日志FastJson序列化JNDI注入
目录 Java-项目管理-工具配置 Java-三方组件-Log4J&JNDI Java-三方组件-FastJson&反射 思维导图 Java知识点: 功能:数据库操作,文件操作,序列化数据,身份验证,框架开发,第三方库使用…...
HTML5+CSS3+JS小实例:全屏范围滑块
实例:全屏范围滑块 技术栈:HTML+CSS+JS 效果: 源码: 【HTML】 <!DOCTYPE html> <html lang="zh-CN"> <head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale…...

ctf杂项总结
1.文件无法打开 1.1.文件拓展名损坏/错误导致 方法: 1.使用kali当中的file命令查看,之后修改为正确的后缀即可 2.通过16进制编辑器打开查看文件头 3.文件头残缺/错误,可以先使用kail当中的file命令查看它的类型,之后再通过 16…...

为什么92%的Sora 2初学者卡在第4步?——帧一致性崩塌诊断工具包+时间轴锚点校准法
更多请点击: https://kaifayun.com 第一章:Sora 2视频生成的核心原理与环境准备 Sora 2并非OpenAI官方发布的模型,而是社区基于Sora技术理念构建的开源复现与增强框架,其核心依托于时空联合建模的扩散变换器(Spacetim…...

癫痫手术精准定位:基于脑电信号昼夜节律与多生物标志物的机器学习分析框架
1. 项目概述:当机器学习遇见脑电信号,如何让癫痫手术更精准?作为一名长期耕耘在生物医学信号处理与机器学习交叉领域的工程师,我常常思考如何将算法模型从实验室的“玩具”变成临床医生手中可靠的“手术刀”。癫痫,这个…...

Taotoken的TokenPlan套餐如何实现更经济的模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的TokenPlan套餐如何实现更经济的模型调用 1. 理解TokenPlan的计费模式 在模型应用开发过程中,成本的可预测性…...

本地柴油发电机组排行2023年最新榜单
柴油发电机是通过燃烧柴油驱动发动机,进而发电的设备,广泛应用于电力中断或无电网地区。1. 柴油发电机的核心工作原理是什么?柴油发电机是一种将化学能转化为电能的设备,其核心是柴油发动机与交流发电机的组合。当柴油在发动机内燃…...

用STM32CubeMX和HAL库快速上手WS2812B:告别手动计算延时,一键生成驱动框架
基于STM32CubeMX的WS2812B智能灯光控制:从零构建现代化驱动方案在智能硬件和物联网设备快速发展的今天,WS2812B可编程LED灯带因其丰富的色彩表现和简单的单线控制方式,成为创客和工程师们最喜爱的显示组件之一。然而,传统的寄存器…...

SSH工具对比:新手用户和熟练运维,选型逻辑有什么不同
结论 新手用户和熟练运维在选择 SSH 工具时,关注点往往完全不同。 新手更在意的是:能不能顺利连接、界面是否直观、文件和配置是否容易找到、网站出问题时能不能快速定位。 而熟练运维更在意的是:连接效率、命令自由度、多服务器管理能力、原…...
适合全体毕业生)
口碑最好的AI论文写作工具推荐(从文献整理到论文成稿全流程)适合全体毕业生
还在为选题方向纠结、文献资料翻找耗时、开题报告无从下手、论文框架反复修改、查重率居高不下、降重过程痛苦不堪,甚至答辩PPT还要临时抱佛脚?作为学术新手、应届生或本科硕士毕业生,面对论文写作的重重关卡,流程复杂、操作门槛高…...

qobuz-dl终极实战指南:专业无损音乐下载工具架构解析与高效应用
qobuz-dl终极实战指南:专业无损音乐下载工具架构解析与高效应用 【免费下载链接】qobuz-dl A complete Lossless and Hi-Res music downloader for Qobuz 项目地址: https://gitcode.com/gh_mirrors/qo/qobuz-dl 在数字音乐时代,追求极致音质的音…...

Metabase:零代码 BI 数据可视化工具,自建数据看板
Metabase:零代码 BI 数据可视化工具,自建数据看板 在数据驱动决策的时代,能快速看到业务数据的变化趋势至关重要。然而,专业 BI 工具(如 Tableau、Power BI)价格昂贵,而让每个业务同学都学 SQL …...

CA-CFAR、GO-CFAR、SO-CFAR怎么选?一张图看懂三种恒虚警检测算法的适用场景与避坑指南
CA-CFAR、GO-CFAR、SO-CFAR工程选型指南:从算法原理到场景适配 雷达信号处理工程师常常面临一个经典难题:在复杂环境中如何选择合适的恒虚警检测算法?当海面杂波、多目标干扰或低信噪比条件同时出现时,CA、GO、SO三种CFAR变体的性…...