软件杯 深度学习 opencv python 公式识别(图像识别 机器视觉)
文章目录
- 0 前言
- 1 课题说明
- 2 效果展示
- 3 具体实现
- 4 关键代码实现
- 5 算法综合效果
- 6 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 基于深度学习的数学公式识别算法实现
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:4分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题说明
手写数学公式识别较传统OCR问题而言,是一个更复杂的二维手写识别问题,其内部复杂的二维空间结构使得其很难被解析,传统方法的识别效果不佳。随着深度学习在各领域的成功应用,基于深度学习的端到端离线数学公式算法,并在公开数据集上较传统方法获得了显著提升,开辟了全新的数学公式识别框架。然而在线手写数学公式识别框架还未被提出,论文TAP则是首个基于深度学习的端到端在线手写数学公式识别模型,且针对数学公式识别的任务特性提出了多种优化。
公式识别是OCR领域一个非常有挑战性的工作,工作的难点在于它是一个二维的数据,因此无法用传统的CRNN进行识别。
2 效果展示
这里简单的展示一下效果


3 具体实现
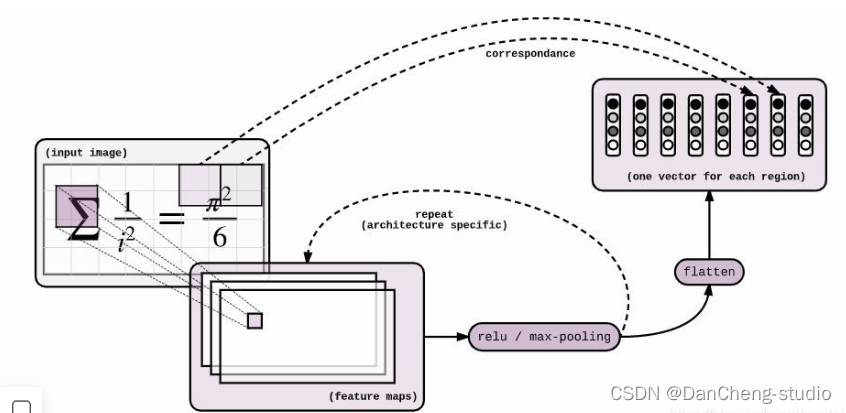
神经网络模型是 Seq2Seq + Attention + Beam
Search。Seq2Seq的Encoder是CNN,Decoder是LSTM。Encoder和Decoder之间插入Attention层,具体操作是这样:Encoder到Decoder有个扁平化的过程,Attention就是在这里插入的。具体模型的可视化结果如下
4 关键代码实现
class Encoder(object):"""Class with a __call__ method that applies convolutions to an image"""def __init__(self, config):self._config = configdef __call__(self, img, dropout):"""Applies convolutions to the imageArgs:img: batch of img, shape = (?, height, width, channels), of type tf.uint8tf.uint8 因为 2^8 = 256,所以元素值区间 [0, 255],线性压缩到 [-1, 1] 上就是 img = (img - 128) / 128Returns:the encoded images, shape = (?, h', w', c')"""with tf.variable_scope("Encoder"):img = tf.cast(img, tf.float32) - 128.img = img / 128.with tf.variable_scope("convolutional_encoder"):# conv + max pool -> /2# 64 个 3*3 filters, strike = (1, 1), output_img.shape = ceil(L/S) = ceil(input/strike) = (H, W)out = tf.layers.conv2d(img, 64, 3, 1, "SAME", activation=tf.nn.relu)image_summary("out_1_layer", out)out = tf.layers.max_pooling2d(out, 2, 2, "SAME")# conv + max pool -> /2out = tf.layers.conv2d(out, 128, 3, 1, "SAME", activation=tf.nn.relu)image_summary("out_2_layer", out)out = tf.layers.max_pooling2d(out, 2, 2, "SAME")# regular conv -> idout = tf.layers.conv2d(out, 256, 3, 1, "SAME", activation=tf.nn.relu)image_summary("out_3_layer", out)out = tf.layers.conv2d(out, 256, 3, 1, "SAME", activation=tf.nn.relu)image_summary("out_4_layer", out)if self._config.encoder_cnn == "vanilla":out = tf.layers.max_pooling2d(out, (2, 1), (2, 1), "SAME")out = tf.layers.conv2d(out, 512, 3, 1, "SAME", activation=tf.nn.relu)image_summary("out_5_layer", out)if self._config.encoder_cnn == "vanilla":out = tf.layers.max_pooling2d(out, (1, 2), (1, 2), "SAME")if self._config.encoder_cnn == "cnn":# conv with stride /2 (replaces the 2 max pool)out = tf.layers.conv2d(out, 512, (2, 4), 2, "SAME")# convout = tf.layers.conv2d(out, 512, 3, 1, "VALID", activation=tf.nn.relu)image_summary("out_6_layer", out)if self._config.positional_embeddings:# from tensor2tensor lib - positional embeddings# 嵌入位置信息(positional)# 后面将会有一个 flatten 的过程,会丢失掉位置信息,所以现在必须把位置信息嵌入# 嵌入的方法有很多,比如加,乘,缩放等等,这里用 tensor2tensor 的实现out = add_timing_signal_nd(out)image_summary("out_7_layer", out)return out学长编码的部分采用的是传统的卷积神经网络,该网络主要有6层组成,最终得到[N x H x W x C ]大小的特征。
其中:N表示数据的batch数;W、H表示输出的大小,这里W,H是不固定的,从数据集的输入来看我们的输入为固定的buckets,具体如何解决得到不同解码维度的问题稍后再讲;
C为输入的通道数,这里最后得到的通道数为512。
当我们得到特征图之后,我们需要进行reshape操作对特征图进行扁平化,代码具体操作如下:
N = tf.shape(img)[0]
H, W = tf.shape(img)[1], tf.shape(img)[2] # image
C = img.shape[3].value # channels
self._img = tf.reshape(img, shape=[N, H*W, C])
当我们在进行解码的时候,我们可以直接运用seq2seq来得到我们想要的结果,这个结果可能无法达到我们的预期。因为这个过程会相应的丢失一些位置信息。
位置信息嵌入(Positional Embeddings)
通过位置信息的嵌入,我不需要增加额外的参数的情况下,通过计算512维的向量来表示该图片的位置信息。具体计算公式如下:
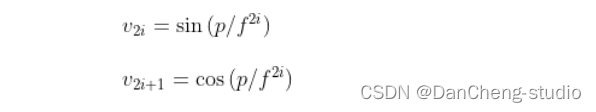
其中:p为位置信息;f为频率参数。从上式可得,图像中的像素的相对位置信息可由sin()或cos表示。
我们知道,sin(a+b)或cos(a+b)可由cos(a)、sin(a)、cos(b)以及sin(b)等表示。也就是说sin(a+b)或cos(a+b)与cos(a)、sin(a)、cos(b)以及sin(b)线性相关,这也可以看作用像素的相对位置正、余弦信息来等效计算相对位置的信息的嵌入。
这个计算过程在tensor2tensor库中已经实现,下面我们看看代码是怎么进行位置信息嵌入。代码实现位于:/model/components/positional.py。
def add_timing_signal_nd(x, min_timescale=1.0, max_timescale=1.0e4):static_shape = x.get_shape().as_list() # [20, 14, 14, 512]num_dims = len(static_shape) - 2 # 2channels = tf.shape(x)[-1] # 512num_timescales = channels // (num_dims * 2) # 512 // (2*2) = 128log_timescale_increment = (math.log(float(max_timescale) / float(min_timescale)) /(tf.to_float(num_timescales) - 1)) # -0.1 / 127inv_timescales = min_timescale * tf.exp(tf.to_float(tf.range(num_timescales)) * -log_timescale_increment) # len == 128 计算128个维度方向的频率信息for dim in range(num_dims): # dim == 0; 1length = tf.shape(x)[dim + 1] # 14 获取特征图宽/高position = tf.to_float(tf.range(length)) # len == 14 计算x或y方向的位置信息[0,1,2...,13]scaled_time = tf.expand_dims(position, 1) * tf.expand_dims(inv_timescales, 0) # pos = [14, 1], inv = [1, 128], scaled_time = [14, 128] 计算频率信息与位置信息的乘积signal = tf.concat([tf.sin(scaled_time), tf.cos(scaled_time)], axis=1) # [14, 256] 合并两个方向的位置信息向量prepad = dim * 2 * num_timescales # 0; 256postpad = channels - (dim + 1) * 2 * num_timescales # 512-(1;2)*2*128 = 256; 0signal = tf.pad(signal, [[0, 0], [prepad, postpad]]) # [14, 512] 分别在矩阵的上下左右填充0for _ in range(1 + dim): # 1; 2signal = tf.expand_dims(signal, 0)for _ in range(num_dims - 1 - dim): # 1, 0signal = tf.expand_dims(signal, -2)x += signal # [1, 14, 1, 512]; [1, 1, 14, 512]return x
得到公式图片x,y方向的位置信息后,只需要要将其添加到原始特征图像上即可。
5 算法综合效果
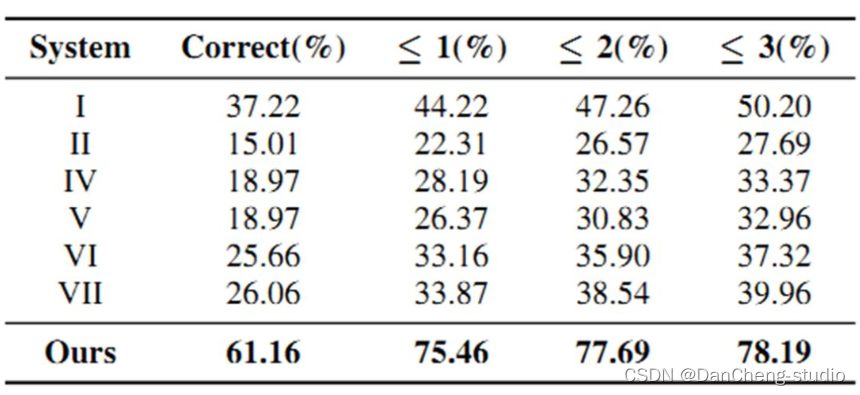
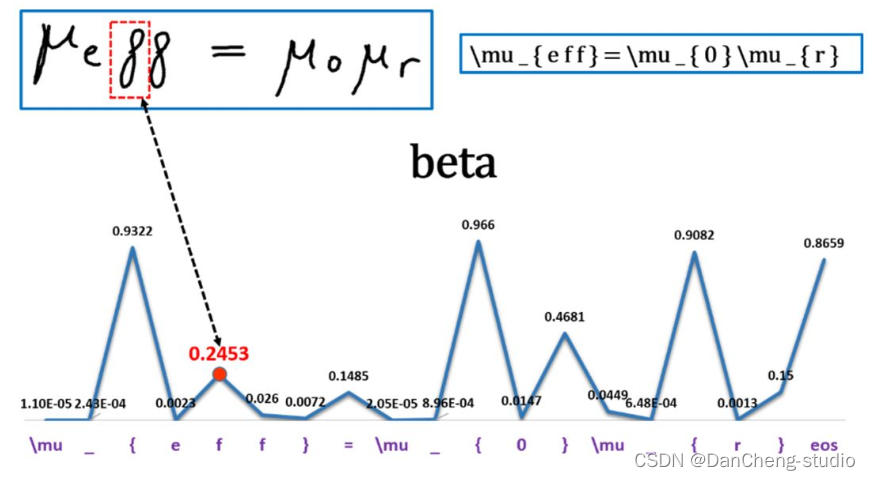
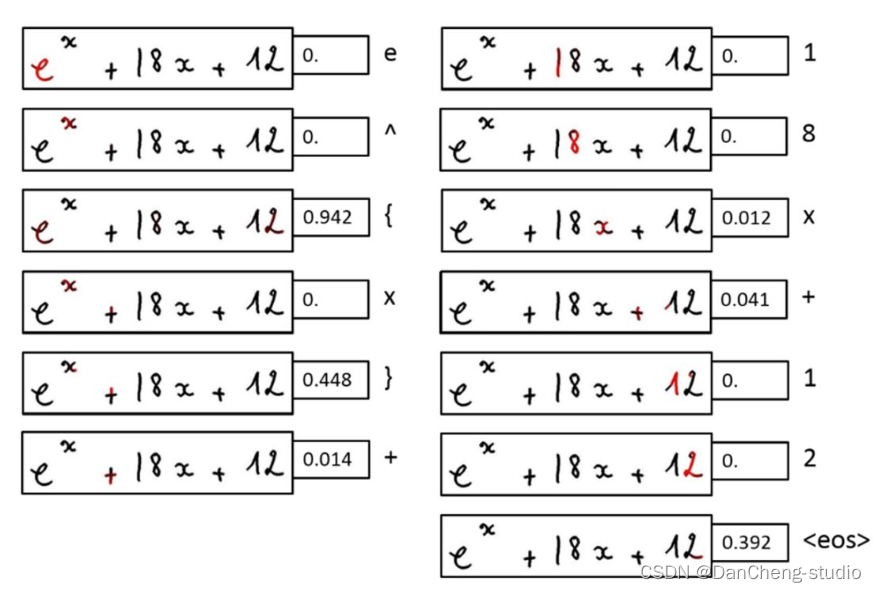
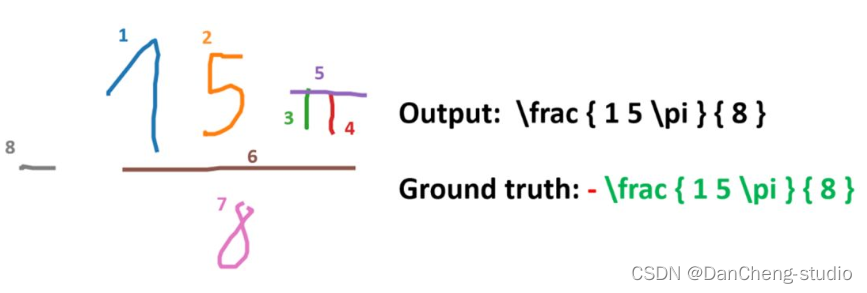
6 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
软件杯 深度学习 opencv python 公式识别(图像识别 机器视觉)
文章目录 0 前言1 课题说明2 效果展示3 具体实现4 关键代码实现5 算法综合效果6 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 基于深度学习的数学公式识别算法实现 该项目较为新颖,适合作为竞赛课题方向,学…...
vscode通过多个跳板机连接目标机(两种方案亲测成功)
1、ProxyJump(推荐使用) 需要OpenSSH 7.3以上版本才可使用,可用下列命令查看: ssh -V ProxyJump命令行使用方法 ssh -J [email protected]:port1,[email protected]:port2 一层跳板机: ssh dst_usernamedst_ip -…...

C++基础复习003
vector去重 第一种,利用set容器的特性进行去重: #include <iostream> #include <vector> #include <set> using namespace std; int main() {vector<int>test{1,2,3,3,3,4,2,3,5,2,63,56,34,24};set<int>s(test.begin(),…...

Docker Commit提交
Docker Commit提交 Docker Commit镜像提交 以一个正在运行的tomcat为例因为docker拉取的镜像都是删减版,所以需要将webapp.dist的文件内容复制到webapps中再将自己制作的镜像放在正在运行服务器上,不是云端服务器上 #进入tomcat,这是一个正…...

百度现在应该怎么去做搜索SEO优化?(川圣SEO)蜘蛛池
baidu搜索:如何联系八爪鱼SEO? baidu搜索:如何联系八爪鱼SEO? baidu搜索:如何联系八爪鱼SEO? 百度搜索引擎优化(SEO)是一种通过优化网站,提升网页在百度搜索结果中的排…...

登录凭证------
为什么需要登录凭证? web开发中,我们使用的协议http是无状态协议,http每次请求都是一个单独的请求,和之前的请求没有关系,服务器就不知道上一步你做了什么操作,我们需要一个办法证明我没登录过 制作登录凭…...
matplotlib系统学习记录
日期:2024.03.12 内容:将matplotlib的常用方法做一个记录,方便后续查找。 基本使用 # demo01 from matplotlib import pyplot as plt # 设置图片大小,也就是画布大小 fig plt.figure(figsize(20,8),dpi80)#图片大小,清晰度# 准…...

【DL】ML系统学习笔记 1
【DL】ML系统学习笔记 1 1. 机器学习定义2. 机器学习三大任务3. 机器学习定义回归举例4. Gradient Descent 优化5. Gradient Descent 优化步骤6. 回归步骤小姐7. Linear models8. 核心步骤流程9. 模型优化9. 深度学习引出1. 机器学习定义 Machine Learning Looking for Functio…...

ffmpeg视频处理常用命令
1.ffmpeg主要参数 -f fmt(输入/输出) 强制输入或输出文件格式。 格式通常是自动检测输入文件, 并从输出文件的文件扩展名中猜测出来,所以在大多数情况下这个选项是不需要的。-i url(输入) 输入文件的网址-…...

前端npm和yarn更换国内淘宝镜像
NPM 查询当前镜像 npm get registry 设置为淘宝镜像 npm config set registry https://registry.npm.taobao.org/ (旧地址) npm config set registry https://registry.npmmirror.com/ (最新地址) 设置为官方镜像 npm config set registry https://registry.n…...
华为配置OSPF的Stub区域示例
配置OSPF的Stub区域示例 组网图形 图1 配置OSPF Stub区域组网图 Stub区域简介配置注意事项组网需求配置思路操作步骤配置文件 Stub区域简介 Stub区域的ABR不传播它们接收到的自治系统外部路由,在Stub区域中路由器的路由表规模以及路由信息传递的数量都会大大减少…...
学会Web UI框架--Bootstrap,快速搭建出漂亮的前端界面
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 所属的专栏:前端泛海 景天的主页:景天科技苑 文章目录 Bootstrap1.Bootstrap介绍2.简单使用3.布局容器4.Bootstrap实现轮播…...

C语言学习大纲
笔者看了下某二本的C语言考研大纲,供平常学习参考,主要考察知识点: C语言概述 (1) 了解程序设计语言的语法 (2) 掌握C语言的特点 (3) 掌握问题求解的过程数据描述 (1&am…...
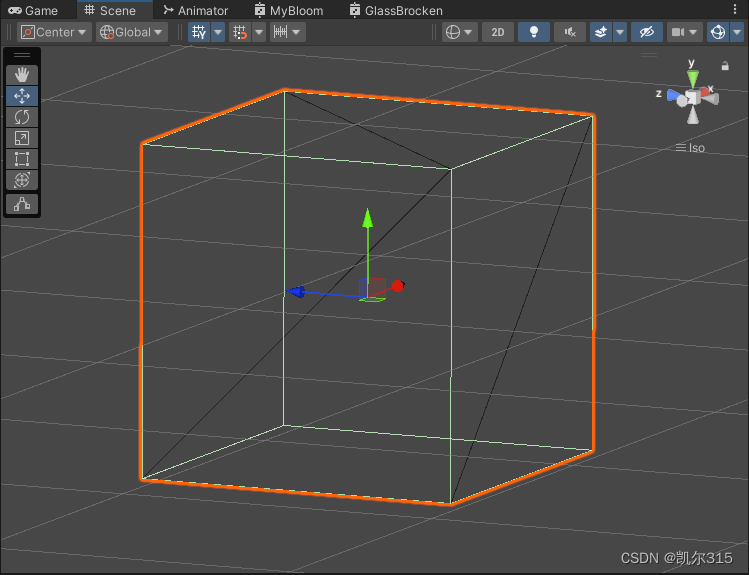
Unity URP 如何写基础的曲面细分着色器
左边是默认Cube在网格模式下经过曲面细分的结果,右边是原状态。 曲面细分着色器在顶点着色器、几何着色器之后,像素着色器之前。 它的作用时根据配置信息生成额外的顶点以切割原本的面片。 关于这部分有一个详细的英文教程,感兴趣可以看一…...

android pdf框架-8,图片缓存
解码会产生很多图片,滑过后不要显示,如果直接回收,会浪费不少资源. 在没有缓存的情况下,会看到gc还是比较频繁的. 有了缓存后,明显gc少了. 目录 常用的缓存 自定义缓存 显示相关的内存缓存 解码缓存池 内存缓存实现: 解码缓存池实现: 常用的缓存 lrucache,这是最常用…...

UE5.2 SmartObject使用实践
SmartObject是UE5新出的一项针对AI的功能,可为开发者提供如公园长椅、货摊等交互对象的统一外观封装,如UE的CitySample(黑客帝国Demo)中就运用到了SmartObject。 但SmartObject实践起来较为繁琐,主要依赖于AI及行为树…...

奇舞周刊第521期:实现vue3响应式系统核心-MVP 模型
奇舞推荐 ■ ■ ■ 实现vue3响应式系统核心-MVP 模型 手把手带你实现一个 vue3 响应式系统,代码并没有按照源码的方式去进行组织,目的是学习、实现 vue3 响应式系统的核心,用最少的代码去实现最核心的能力,减少我们的学习负担&…...

Mybatis-plus手写SQL如何使用条件构造器和分页
Mybatis-plus手写SQL如何使用条件构造器和分页插件 前言:在使用mybatis-plus过程中,使用条件构造器和分页插件非常效率的提升开发速度,但有些业务需要使用连表查询,此时还想使用条件构造器和使用分页时应该如何操作呢?…...

Vue的table组件合并行方法
/*** param {Array} data - 原始数据集合* param {string} addParamer - 这个是自定义的参数,向每个对象中添加一个参数 按照这个参数的个数进行合并* param {} args - 剩余参数 这个是合并规则 ,比如按照时间合并 那就传入对象中的时间参数date…...

5. C语言字符串处理常用方法
在 C 语言中,字符串是以字符数组的形式表示的,以空字符 \0 结尾。C 语言提供了一系列的字符串处理函数,可以用于字符串的操作、查找、比较等。以下是一些常用的 C 语言字符串处理函数: 1. 字符串定义与初始化 #include <stdio.h> #include <string.h>int mai…...

无机布防火卷帘门价格怎么算?按尺寸定制,按需报价
无机布防火卷帘门作为建筑防火分区的核心设备,价格一直是工程采购的关注重点。很多用户在询价时,会发现不同厂家的报价差异较大,这是因为无机布防火卷帘门的价格并非按统一单价计算,而是完全根据项目的实际需求定制化核算。 &…...

App无辜躺枪?手把手教你搞定腾讯手机管家误报导致的应用商店下架
当合规应用遭遇误报下架:开发者系统性应对指南运动健康类应用被标记为金融诈骗软件?社交工具因"病毒风险"被各大商店紧急下架?这类看似荒谬的误报事件,正在成为中小开发团队的"无妄之灾"。某知名运动App开发团…...

物理引导的机器学习工作流:气候建模的融合创新与实践
1. 项目概述:当气候建模遇见机器学习如果你像我一样,在气候模拟这个领域摸爬滚打超过十年,就会深刻体会到一种“甜蜜的负担”:我们构建的地球系统模型(ESM)越来越精细,物理过程越来越复杂&#…...

Tftpd32/Tftpd64不止是TFTP!手把手教你玩转它的DHCP和Syslog服务器功能
Tftpd32/Tftpd64:解锁DHCP与Syslog服务的隐藏潜力当大多数人提起Tftpd32/Tftpd64时,第一反应往往是它作为TFTP服务器的功能。这款轻量级工具确实在文件传输领域表现出色,但它的能力远不止于此。今天,我们将深入探索这款软件中两个…...

ARM PMU外部接口与性能监控寄存器详解
1. ARM性能监控寄存器外部接口深度解析性能监控单元(PMU)是现代处理器架构中用于硬件性能分析的核心模块,它通过一组可编程计数器实时捕获处理器微架构层面的各类事件。在ARMv8/v9架构中,PMU不仅可以通过系统寄存器访问,还提供了标准化的外部…...
到底在‘看’什么?)
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?想象一下,你刚搬到一个新社区,想快速了解周围的邻居。最直接的方式是什么?不是挨家挨户敲门,而是通过社区活动认识几位关…...
)
第二周(第12周)
1.单电源供电的二阶低通滤波器2.功率放大电路...

3分钟掌握HashCalculator:你的文件完整性守护专家
3分钟掌握HashCalculator:你的文件完整性守护专家 【免费下载链接】HashCalculator 哈希值计算工具,批量计算/批量校验/查找重复文件/改变哈希值等,支持集成到系统右键菜单 项目地址: https://gitcode.com/gh_mirrors/ha/HashCalculator …...
)
放弃编码器!纯靠MPU6050和PID算法,手把手教你用TT马达实现平衡小车稳定控制(STM32F103C8T6实战)
纯MPU6050STM32F103的TT马达平衡车实战:无编码器PID控制全解析当大多数平衡小车方案都在强调编码器对速度反馈的不可或缺性时,我们决定挑战一个更极简的配置:仅用5美元的TT马达、9轴的MPU6050和STM32F103C8T6最小系统板,完全舍弃编…...

FM3773 低功耗离线式恒流/恒压 PSR 控制器
概述 FM3773 是一种高性能的交流/直流用于电池充电器和适配器的电源控制器,内置 850V 功率三极管。该设备采用脉冲频率调制(PFM)的方法来建立非连续导通模式(DCM)反激式电源。 FM3773 提供精确的恒定电压,恒…...