Clickhouse MergeTree 原理(一)
作者:俊达
MergeTree是Clickhouse里最核心的存储引擎。Clickhouse里有一系列以MergeTree为基础的引擎(见下图),理解了基础MergeTree,就能理解整个系列的MergeTree引擎的核心原理。

本文对MergeTree的基本原理进行介绍。
1 MergeTree引擎表创建
1、基本语法:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],...INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
2、关键属性说明
[partition by expr] : 分区键,分区键可以指定一个或多个字段,若不指定分区键时默认为其生成一个名为all的分区。[选填]
[order by expr] : 排序键,指定一个数据段内的数据排序规则。默认情况下主键与排序键相同。排序键可以是一个或多个字段。[必填]
[primary key expr] : 主键,若设置表primary key,表数据会按照主键字段生成一级索引;若无显式执行primary key,则使用order by字段作为主键排序。MergeTree主键允许重复数据。[选填]
[sample by expr] : 抽样表达式,声明使用何种方式进行抽样采集。[选填]
上面的这些属性,只有Order by是必填的。
下面是一个具体的例子:
CREATE TABLE local.metrics
(`tt` DateTime,`tags` Map(String, String),`metric` String,`value` Float64,`str_value` String
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(tt)
ORDER BY (metric, tt)
SETTINGS index_granularity = 8192
2 MergeTree物理存储结构
1、Clickhouse中,一个MergeTree引擎表,由一个或多个分区(partition)组成。如果建表时没有制定分区条件,则所有的数据都位于同一个分区。
2、每一个分区,由1个或多个part组成。每一个part,对应clickhouse数据目录中的一个目录,该目录下存储了part对应的数据。
3、part是clickhouse数据存储、数据复制、数据合并的基本单位。每次insert数据,会写入到单独的part中。
4、part的数据一旦写入,就不会发生变化。只有在数据合并时,才会将被合并的part设置为inactive,等后台进程清理。
5、数据合并时,会对同一个分区(partition)中的part进行合并。不同分区的数据不会合并到一起。
我们可以通过system库中的parts表查看part信息。
ck01 :) select * from system.parts where table='metrics'\GSELECT *
FROM system.parts
WHERE table = 'metrics'Query id: 2948f29c-1f23-4f5e-b9a5-ac6006ce5383Row 1:
──────
partition: 20221129
name: 20221129_1_4_2
uuid: 00000000-0000-0000-0000-000000000000
part_type: Compact
active: 1
marks: 2
rows: 3
bytes_on_disk: 412
data_compressed_bytes: 203
data_uncompressed_bytes: 92
marks_bytes: 176
min_block_number: 1
max_block_number: 4
level: 2
data_version: 1
primary_key_bytes_in_memory: 36
primary_key_bytes_in_memory_allocated: 8256
is_frozen: 0
database: local
table: metrics
engine: MergeTree
disk_name: default
path: /data/clickhouse/clickhouse/store/def/def88518-fd7b-418d-a7dd-6564e38bba39/20221129_1_4_2/
...
分区目录命名规则
分区目录的命名规范为: PartitionID_MinBlockNum_MaxBlockNum_Level
PartitionID : 分区ID。
MinBlockNum、MaxBlockNum : 最小数据块编号、最大数据块编号,数据块编号由1开始自增长。
Level : 合并操作层级,随着合并的次数递增。
分区目录内容

checksums.txt : 校验文件,使用二进制格式存储。记录了各类文件的大小以及大小的hash值
columns.txt : 列信息文件,使用明文存格式储。存储了该分区下的表字段信息。
count.txt : 计数文件,存储了当前分区下的数据行数。
default_compression_codec.txt :
[column].bin : 列字段数据文件,默认使用LZ4格式压缩存储。
[column].mrk2 : 列字段标记文件,使用二进制格式存储,标记文件中保存了[column].bin文件中数据的偏移量。标记文件是一级索引文件与数据文件之间进行关联的桥梁。
primary.idx : 一级索引文件,使用二进制格式存储。存储了该分区的稀疏索引,MergeTree通过primary by或order by声明一级索引的定义。
skip_idx[column].idx、skip_idx[column].mrk2 : 如果建表语句中声明了相关的二级索引(跳数索引),则会生成相关二级索引的索引文件与标记文件。
clickhouse part数据存储分两种格式:
-
compact: 所有字段的数据都存储道data.bin中。如上图中part的格式就是compact。
-
wide: 每个字段都存储到单独的文件中
存储格式受参数min_bytes_for_wide_part和min_rows_for_wide_part控制。只有当纪录数或记录占用的空间超过配置参数,才以wide格式存储。
part合并过程
当多个同分区的分区目录进行合并时:
- 分区ID相同
- MinBlockNum取所有待合并分区目录中最小的MinBlockNum值
- MaxBlockNum取所有待合并分区目录中最大的MaxBlockNum值
- Level取所有待合并分区目录中最大Level+1
更多技术信息请查看云掣官网https://yunche.pro/?t=yrgw
相关文章:
Clickhouse MergeTree 原理(一)
作者:俊达 MergeTree是Clickhouse里最核心的存储引擎。Clickhouse里有一系列以MergeTree为基础的引擎(见下图),理解了基础MergeTree,就能理解整个系列的MergeTree引擎的核心原理。 本文对MergeTree的基本原理进行介绍…...

【C语言】字符串函数上
👑个人主页:啊Q闻 🎇收录专栏:《C语言》 🎉道阻且长,行则将至 前言 这篇博客是字符串函数上篇,主要是关于长度不受限制的字符串函数(strlen,strcpy,strcat,strcm…...

Java集合基础知识总结(绝对经典)
List接口继承了Collection接口,定义一个允许重复项的有序集合。该接口不但能够对列表的一部分进行处理,还添加了面向位置的操作。 实际上有两种list:一种是基本的ArrayList,其优点在于随机访问元素,另一种是更强大的L…...

Linux:导出环境变量命令export
相关阅读 Linuxhttps://blog.csdn.net/weixin_45791458/category_12234591.html?spm1001.2014.3001.5482 Linux中的内建命令export命令用于创建一个环境变量,或将一个普通变量导出为环境变量,并且在这个过程中,可以给该环境变量赋值。 下面…...
案例--某站视频爬取
众所周知,某站的视频是: 由视频和音频分开的。 所以我们进行获取,需要分别获得它的音频和视频数据,然后进行音视频合并。 这么多年了,某站还是老样子,只要加个防盗链就能绕过。(防止403…...

清华把大模型用于城市规划,回龙观和大红门地区成研究对象
引言:参与式城市规划的新篇章 随着城市化的不断推进,传统的城市规划方法面临着越来越多的挑战。这些方法往往需要大量的时间和人力,且严重依赖于经验丰富的城市规划师。为了应对这些挑战,参与式城市规划应运而生,它强…...

Vue+SpringBoot打造创意工坊双创管理系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 管理员端2.2 Web 端2.3 移动端 三、系统展示四、核心代码4.1 查询项目4.2 移动端新增团队4.3 查询讲座4.4 讲座收藏4.5 小程序登录 五、免责说明 一、摘要 1.1 项目介绍 基于JAVAVueSpringBootMySQL的创意工坊双创管理…...
Web框架开发-Django简介
一、MVC和MTV模型 MVC 所谓MVC就是把web应用分为模型(M),控制器(C)和视图(V)三层,他们之间以一种插件式的,松耦合的方式连接在一起,模型负责业务对象与数据库…...
VB播放器(动态服务器获取歌词)-183-(代码+说明)
转载地址: http://www.3q2008.com/soft/search.asp?keyword183 VBASP vb动态从服务器读取歌词 VB asp交互 程序, 模式不一样, 与普通的MP3播放器不一样, 这个是可以实现歌词从服务器上查询功能的. 看好了在咨询 我可以給您演示 目 录 前 言 1 1 . 简述 2 1.1 开发…...
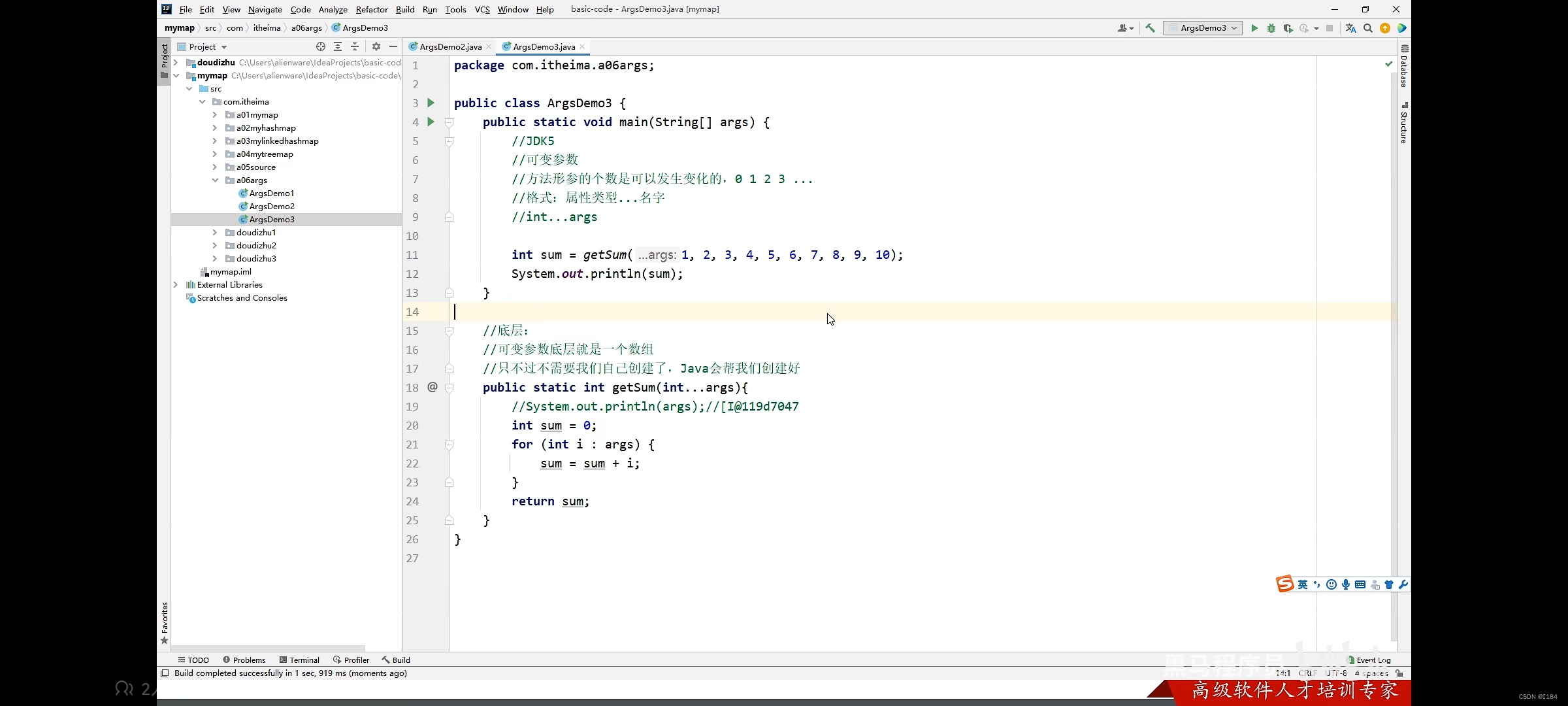
java-可变参数
可变参数是什么? 可变参数就是指传入的参数个数是可变的,不是固定的 为什么要可变参数? 当我们要传入大量的形参时,我们就可以用到可变参数了 定义格式 数据类型...变量名; 例如int ...a; 可变参数的细节: &…...
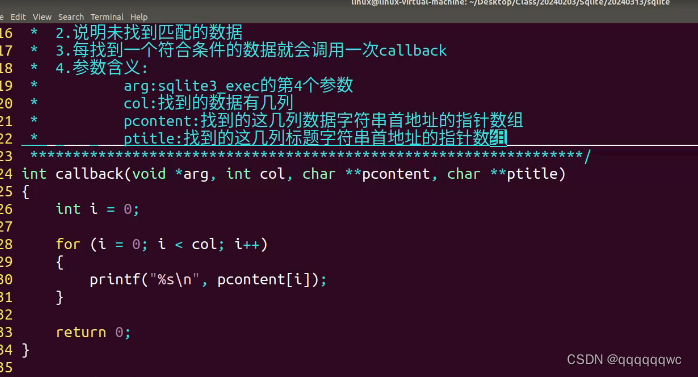
嵌入式学习day37 数据结构
1.sqlite3_open int sqlite3_open( const char *filename, /* Database filename (UTF-8) */ sqlite3 **ppDb /* OUT: SQLite db handle */ ); 功能: 打开数据库文件(创建一个数据库连接) 参数: filename:数据库文…...

嵌入式学习39-程序创建数据库及查找
1.sqlite3_open int sqlite3_open( const char *filename, /* Database filename (UTF-8) */ sqlite3 **ppDb /* OUT: SQLite db handle */ ); 功能: 打开 数据库文件(创建一个数据库连接) 参数: filename: …...

科研三维模型高精度三维扫描服务3d逆向测绘建模工业产品抄数设计
三维抄数技术在科研三维模型的应用已经日益广泛,其高精度、高效率的特点使得科研工作者能够更快速、更准确地获取和分析数据。这一技术的核心在于通过专业的三维扫描仪对实物进行高精度测量,再将这些数据转化为三维数字模型,为后续的研究提供…...
【LeetCode热题100】141. 环形链表(链表)
一.题目要求 给你一个链表的头节点 head ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置…...
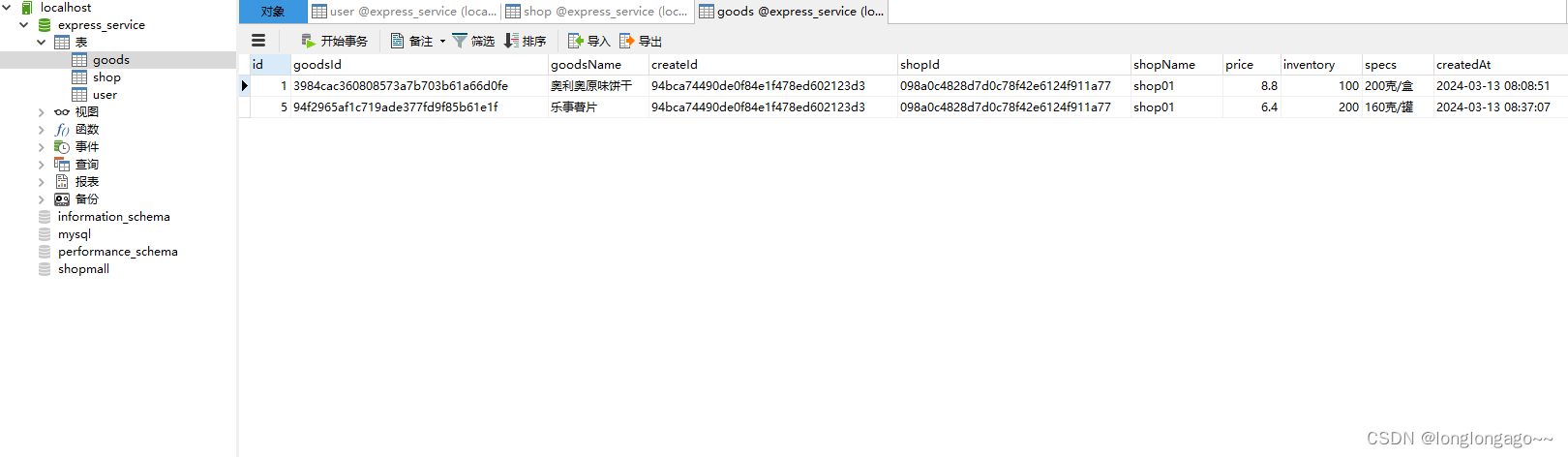
express+mysql+vue,从零搭建一个商城管理系统11--使用Sequelize
提示:学习express,搭建管理系统 文章目录 前言一、安装sequelize和mysql2二、修改config/db.js三、修改models/user.js,models/shop.js,models/goods.js四、新建dao/user.js,dao/shop.js,dao/goods.js五、修…...

霹雳学习笔记——6.1 ResNet网络结构、BN以及迁移学习
一、ResNet结构 ResNet是一个突破一千层的网络架构。主要是卷积层Conv和池化层的堆叠。但是普通的堆叠会使得错误率更高,如下图所述,这是因为会产生梯度消失/梯度爆炸等。(梯度就是增量,有大小有方向) 解决方法&#…...
Gitee的注册和代码提交(附有下载链接)
目录 一、Git的下载和安装二、安装图形化界面工具三、在Gitee上创建仓库四、如何把仓库开源五、Clone远程仓库到本地六、拷贝代码到本地的仓库七、Add-Commit-Push到远程仓库八、可能出现的问题8.1 建议在本地仓库直接创建项目8.2 第一次Push可能出现的问题8.3 怎么删除Gitee上…...

机器学习是什么?
机器学习是一种人工智能(AI)的分支,其主要目标是使计算机系统能够通过数据和经验来改进和学习,而无需明确地编程。在机器学习中,计算机系统会通过对大量数据进行学习和分析,从中发现模式和规律,…...
复盘-PPT
调整PPT编号起始页码在设计→幻灯片大小 设置所有以及文本项目符号 ## 打开母版,找到对应级别设置重置 当自动生成的smartart图形不符合预期时 1 2...

springcloud gateway网关动态配置限流
上一篇记录了gateway网关的基础功能和配置,并且使用了默认的限流功能。 springcloud gateway网关-CSDN博客 这里简单记录一下gateway网关集成mybatisPlus实现动态限流。gateway网关默认的限流方式各项限流参数都是在配置文件中配置,不够灵活࿰…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

软阴影:那个让虚拟世界“温柔起来“的光影小秘密
一、从一只小猫的影子说起 前几天我在朋友家做客,他家养了一只胖乎乎的橘猫,正趴在阳台的窗边晒太阳。我无意间瞥了一眼那只猫脚边的影子,突然被一个细节震撼了—— 那只猫的影子——并不是一片均匀的黑。 仔细看——猫肚子紧贴地板的地方——…...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

6款高效降AI率工具 改写实力出众
写论文时反复检测出的AI痕迹总让你提心吊胆?别担心,这里整理了6款真正好用的论文降AI率工具,堪称应对AI生成特征的“得力助手”。它们能有效识别并消除AI生成的痕迹,改写能力出众,帮你快速降低查重率,顺利通…...

2026智慧校园规划必读:如何在预算吃紧下选到高性价比方案
✅作者简介:合肥自友科技 📌核心产品:智慧校园平台(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...

Taotoken平台快速获取APIKey并开始你的第一个Python调用示例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台快速获取APIKey并开始你的第一个Python调用示例 1. 准备工作:注册与登录 要开始使用Taotoken,…...

如何进行TVA仿真引擎的“光照地狱”训练?
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait
别再死记硬背了!用5个生活化比喻彻底搞懂Linux进程的fork、exec和wait想象你正在厨房准备一顿大餐。菜谱上写着"切菜"、"炒菜"、"装盘"等步骤,但突然发现需要同时处理多道菜品——这时候,你会本能地让家人分工…...

从“DOC/PDF”到“WPS”:细看GJB438C-2021文档格式要求背后的国产化信号与落地指南
从“DOC/PDF”到“WPS”:GJB438C-2021文档格式变革的深度解读与实施策略 当一份国家军用标准在文档格式描述中刻意删除"DOC/PDF"字样,转而明确标注"(WPS)文档处理器"时,这绝非简单的技术参数调整。…...

Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题
Godot4 2D游戏开发避坑指南:TileMap绘制、节点顺序与相机设置的三个常见问题当你第一次用Godot4完成一个2D场景搭建时,那种成就感往往会被几个突如其来的bug瞬间击碎——角色神秘消失、背景纹丝不动、屏幕边缘出现诡异黑边。这些问题看似简单,…...