【机器学习】进阶学习:详细解析Sklearn中的MinMaxScaler---原理、应用、源码与注意事项
【机器学习】进阶学习:详细解析Sklearn中的MinMaxScaler—原理、应用、源码与注意事项
这篇文章的质量分达到了97分,虽然满分是100分,但已经相当接近完美了。请您耐心阅读,我相信您一定能从中获得不少宝贵的收获和启发~

🌈 个人主页:高斯小哥
🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希望得到您的订阅和支持~
💡 创作高质量博文(平均质量分92+),分享更多关于深度学习、PyTorch、Python领域的优质内容!(希望得到您的关注~)
🌵文章目录🌵
- 🧠 一、MinMaxScaler简介
- 🔧 二、MinMaxScaler原理与应用
- 🔍 三、MinMaxScaler源码的简单复现与解析
- 💡 四、注意事项
- 🔄 五、MinMaxScaler与StandardScaler的比较
- 📚 六、总结
🧠 一、MinMaxScaler简介
MinMaxScaler是Scikit-learn库中的一个重要工具,主要用于数据的归一化处理。归一化是将数据按比例缩放,使之落入一个小的特定区间,如[0,1]或[-1,1]。MinMaxScaler通过计算特征列的最小值和最大值来实现归一化,它对于稳定模型的训练过程和提高模型的性能非常重要。
归一化的主要好处包括但不限于:
- 提高模型的收敛速度,因为特征都在相近的尺度上。
- 提高模型的精度,因为一些算法在特征尺度相近时表现更好。
- 使得不同单位的特征之间可以进行比较和加权。
🔧 二、MinMaxScaler原理与应用
MinMaxScaler的原理很简单,它使用下面的公式进行归一化:
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std * (max - min) + min
其中,X 是原始数据,min 和 max 是你想要缩放到的范围,通常是[0, 1]。
在应用归一化后,有时候我们需要将数据从归一化的范围转换回原始的范围,这个过程称为反归一化。使用MinMaxScaler进行反归一化的过程相对简单,只需按照下面的公式进行:
X_original = X_scaled * (max_original - min_original) + min_original
这里,max_original 和 min_original 是原始数据的最小值和最大值。
在Sklearn中,使用MinMaxScaler进行归一化和反归一化的示例如下:
from sklearn.preprocessing import MinMaxScaler
import numpy as np# 示例数据
data = np.array([[1, 2], [3, 4], [5, 6]])# 创建MinMaxScaler对象
scaler = MinMaxScaler(feature_range=(0, 1))# 使用fit_transform方法拟合数据并进行转换
scaled_data = scaler.fit_transform(data)print("Original data:\n", data)
print("Scaled data:\n", scaled_data)# 使用inverse_transform方法将缩放后的数据转换回原始尺度
original_data = scaler.inverse_transform(scaled_data)print("Data after inverse transformation:\n", original_data)
代码输出:
Original data:[[1 2][3 4][5 6]]
Scaled data:[[0. 0. ][0.5 0.5][1. 1. ]]
Data after inverse transformation:[[1. 2.][3. 4.][5. 6.]]
在这个示例中,MinMaxScaler首先使用fit_transform方法拟合数据并计算每个特征(即每列分别计算)的最小值和最大值,然后将数据缩放到指定的范围(在这个例子中是[0, 1])。之后,使用inverse_transform方法可以将缩放后的数据还原到原始尺度。
MinMaxScaler的应用非常广泛,特别是在需要对数据进行归一化处理以消除量纲影响的机器学习算法中。通过将数据缩放到相同的范围,MinMaxScaler可以帮助算法更好地学习和优化。然而,需要注意的是,MinMaxScaler对异常值非常敏感,因为异常值会影响最小值和最大值的计算,从而影响缩放效果。在处理包含异常值的数据时,可能需要考虑使用其他的归一化方法,如RobustScaler或StandardScaler。
🔍 三、MinMaxScaler源码的简单复现与解析
MinMaxScaler的源码包含了fit、fit_transform以及inverse_transform等关键方法:
- fit方法用于计算训练数据的最小值和最大值
- fit_transform方法则用于根据这些最小值和最大值来缩放数据
- inverse_transform方法则用于将缩放后的数据转换回原始尺度。
以下是MinMaxScaler源码的一个简化版本,包括这些主要方法:
import numpy as npclass MinMaxScaler:def __init__(self, feature_range=(0, 1)):self.feature_range = feature_rangeself.min_ = Noneself.data_min_ = Noneself.data_max_ = Nonedef fit(self, X):"""计算训练集的最小值和最大值"""self.data_min_ = np.min(X, axis=0)self.data_max_ = np.max(X, axis=0)self.min_ = np.min(self.data_min_)return selfdef fit_transform(self, X):"""根据拟合的最小值和缩放比例转换数据"""if self.min_ is None:raise ValueError("This MinMaxScaler instance is not fitted yet. Call 'fit' with some data first.")X_std = (X - self.data_min_) / (self.data_max_ - self.data_min_)X_scaled = X_std * (self.feature_range[1] - self.feature_range[0]) + self.feature_range[0]return X_scaleddef inverse_transform(self, X):"""将缩放后的数据转换回原始尺度"""if self.min_ is None:raise ValueError("This MinMaxScaler instance is not fitted yet. Call 'fit' with some data first.")X_std = (X - self.feature_range[0]) / (self.feature_range[1] - self.feature_range[0])X_original = X_std * (self.data_max_ - self.data_min_) + self.data_min_return X_original# 假设我们有一些原始数据
original_data = np.array([[1, 2], [3, 4], [5, 6]])# 创建一个MinMaxScaler对象
scaler = MinMaxScaler()# 使用fit_transform方法对数据进行归一化
scaler.fit(original_data)
normalized_data = scaler.fit_transform(original_data)
print("Normalized data:")
print(normalized_data)# 使用inverse_transform方法进行反归一化
original_data_reconstructed = scaler.inverse_transform(normalized_data)
print("Reconstructed original data:")
print(original_data_reconstructed)
代码输出:
Normalized data:
[[0. 0. ][0.5 0.5][1. 1. ]]
Reconstructed original data:
[[1. 2.][3. 4.][5. 6.]]
在上面的代码中,fit方法计算了训练数据集X中每个特征的最小值和最大值。fit_transform方法则利用这些参数将输入数据X转换为指定范围feature_range内的值。inverse_transform方法则执行相反的操作,将缩放后的数据转换回原始尺度。
需要注意的是,这个简化版本假设输入数据X至少包含一个特征(尚未对空值进行异常处理),并且所有特征的最小值和最大值都不相同(避免出现除0情况)。在实际应用中,Scikit-learn的MinMaxScaler实现会包含更多的错误检查和边界情况处理。
通过解析源码,我们可以更好地理解MinMaxScaler的工作原理,并在必要时自定义或扩展其功能。然而,在实际应用中,通常推荐使用Scikit-learn库中经过优化和测试的完整实现。
💡 四、注意事项
在使用MinMaxScaler时,需要注意以下几点:
-
数据的分布:MinMaxScaler对数据的分布没有假设,但如果数据集中存在异常值,它们会对最小值和最大值的计算产生很大影响,进而影响到归一化的效果。
-
新数据的处理:当使用fit方法计算了训练数据的最小值和最大值后,如果有新的数据需要归一化,应使用相同的最小值和最大值。如果直接使用新数据再次调用fit方法,会导致归一化结果的不一致。
-
特征重要性:归一化可能会改变特征之间的相对重要性。因为MinMaxScaler仅仅是将数据缩放到指定的范围,而不考虑特征的分布或其他属性,所以它不会保留任何关于原始特征重要性的信息。在需要特征重要性的场景中,可能需要结合其他方法,如使用特征选择算法或考虑特征的统计属性。
-
数据泄露问题:在机器学习的实践中,尤其是在构建预测模型时,需要特别注意避免数据泄露。如果在训练过程中,测试集或验证集的数据被用于MinMaxScaler的fit方法,那么模型可能会因为“看到”了测试集的信息而表现出过高的性能,这会导致对模型泛化能力的错误估计。因此,应该始终确保只使用训练集数据来fit MinMaxScaler。
-
数据类型和缺失值:MinMaxScaler默认处理数值型数据。如果数据集中包含非数值型特征或缺失值,需要预先进行处理。例如,可以将非数值型特征进行编码,或者用适当的方法填充或删除含有缺失值的样本。
-
保留原始数据:在进行归一化或其他预处理操作后,建议保留原始数据。这是因为某些情况下,可能需要重新访问或分析原始数据,或者将归一化后的数据与其他未归一化的数据合并。
-
与深度学习框架的集成:当使用深度学习框架(如TensorFlow或PyTorch)时,可能需要自定义归一化层或操作,以便在模型训练过程中直接应用归一化。虽然Scikit-learn的MinMaxScaler可以与这些框架一起使用,但了解如何在框架内部实现归一化也是很重要的。
总之,MinMaxScaler是一个简单而有效的工具,但在使用时需要注意上述事项,以确保归一化过程不会对模型性能产生负面影响,并能够充分利用归一化带来的好处。
🔄 五、MinMaxScaler与StandardScaler的比较
MinMaxScaler和StandardScaler都是Scikit-learn中常用的特征缩放方法,但它们的工作原理和适用场景有所不同:
-
MinMaxScaler通过线性变换将特征值缩放到给定的范围(通常是[0, 1]),它直接依赖于数据的最大值和最小值。这种方法对于有界特征或需要保持特征之间相对大小关系的场景特别有用。然而,由于MinMaxScaler对异常值敏感,因此如果数据集中包含极端值,可能会导致缩放后的数据不稳定或失去有意义的结构。
-
StandardScaler使用均值和标准差来缩放特征,使其具有零均值和单位方差。这种方法更适合于那些假设特征服从正态分布或近似正态分布的场景。StandardScaler对异常值的鲁棒性更好,因为它基于整个数据集的统计属性进行缩放,而不是仅仅依赖于最大值和最小值。
在选择使用MinMaxScaler还是StandardScaler时,需要考虑数据的特性、模型的假设以及具体的应用场景。例如,在处理像素值或百分比等具有明确边界的数据时,MinMaxScaler可能更合适;而在处理连续型特征且假设它们服从正态分布时,StandardScaler可能更合适。
此外,值得注意的是,除了MinMaxScaler和StandardScaler之外,还有其他一些特征缩放方法可供选择,如MaxAbsScaler、RobustScaler等。每种方法都有其特定的应用场景和优缺点,因此在实际应用中需要根据具体情况进行选择。
📚 六、总结
本文详细解析了Scikit-learn中的MinMaxScaler的原理、应用、源码和注意事项。通过深入了解其工作原理和适用场景,我们可以更好地利用这一工具来优化机器学习模型的性能。同时,我们也讨论了MinMaxScaler与StandardScaler之间的比较,以便在实际应用中根据数据特性和模型需求做出合适的选择。
在使用MinMaxScaler时,需要注意数据的分布、新数据的处理、特征重要性、数据泄露问题以及数据类型和缺失值等方面。此外,与深度学习框架的集成也是一个值得考虑的问题。
总之,MinMaxScaler是一个强大而灵活的工具,通过合理使用它,我们可以提高机器学习模型的稳定性和性能。希望本文能够帮助你更好地理解和应用MinMaxScaler,并在实际项目中取得更好的效果。🚀
相关文章:
【机器学习】进阶学习:详细解析Sklearn中的MinMaxScaler---原理、应用、源码与注意事项
【机器学习】进阶学习:详细解析Sklearn中的MinMaxScaler—原理、应用、源码与注意事项 这篇文章的质量分达到了97分,虽然满分是100分,但已经相当接近完美了。请您耐心阅读,我相信您一定能从中获得不少宝贵的收获和启发~ …...

数据库是什么?数据库连接、管理与分析工具推荐
一、数据库是什么? 数据库是一种结构化的数据存储系统,用于有效地组织、存储和管理大量的数据。它是一个集中化的数据存储库,通常由一个或多个数据表组成,每个数据表包含多个行和列,用于存储特定类型的数据。数据表中…...

【C#算法实现】可见的山峰对数量
文章目录 前言一、题目要求二、算法设计及代码实现2.1 算法思想2.2 代码实现 前言 本文是【程序员代码面试指南(第二版)学习笔记】C#版算法实现系列之一,用C#实现了《程序员代码面试指南》(第二版)栈和队列中的可见的…...
Selenium 隐藏浏览器指纹特征的几种方式
文章转载于:https://mp.weixin.qq.com/s/sXRXwMDqekUHfU2SnL-PYg 我们使用 Selenium 对网页进行爬虫时,如果不做任何处理直接进行爬取,会导致很多特征是暴露的 对一些做了反爬的网站,做了特征检测,用来阻止一些恶意爬虫…...

k8s发布nacos-server,nodeport配置注意事项
k8s发布nacos-server注册不上问题 问题描述:分析过程: 问题描述: k8s发布nacos-server做服务公用使用,nodeport暴漏服务给客户端注册, nacos:端口 8848:30601 9848:30701 分析过程:…...
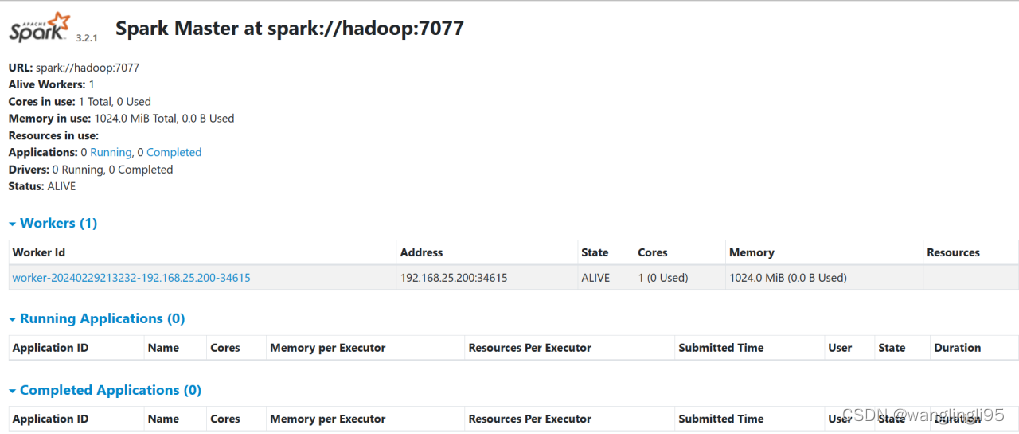
伪分布式Spark集群搭建
一、软件环境 软 件 版 本 安 装 包 VMware虚拟机 16 VMware-workstation-full-16.2.2-19200509.exe SSH连接工具 FinalShell Linux OS CentOS7.5 CentOS-7.5-x86_64-DVD-1804.iso JDK 1.8 jdk-8u161-linux-x64.tar.gz Spark 3.2.1 spark-3.2.1-bin-…...

Android 监听卫星导航系统状态及卫星测量数据变化
源码 package com.android.circlescalebar;import androidx.annotation.NonNull; import androidx.appcompat.app.AppCompatActivity; import androidx.core.app.ActivityCompat; import androidx.core.content.ContextCompat; import android.Manifest; import android.conte…...

鸿蒙培训开发:就业市场的新热点~
金三银四在即,随着春节假期结束,各行各业纷纷复工复产,2024年的春季招聘市场也迎来了火爆的局面。最近发布的《2024年春招市场行情周报(第一期)》显示,尽管整体就业市场仍处于人才饱和状态,但华…...

【C++】string的底层剖析以及模拟实现
一、字符串类的认识 C语言中,字符串是以\0结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列的库函数, 但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户自己管理&a…...
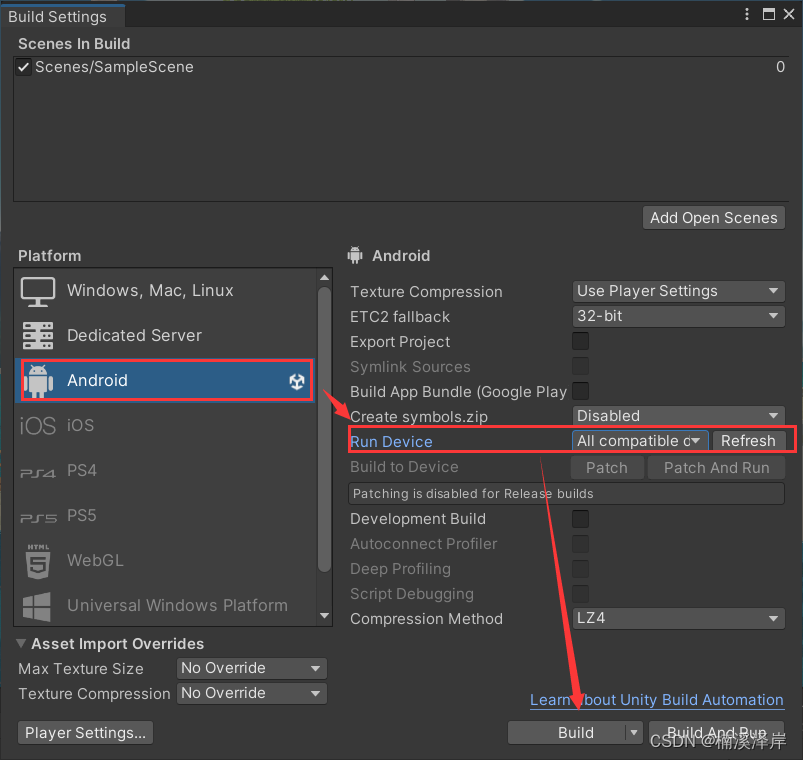
Unity的PICO项目基础环境搭建笔记(调试与构建应用篇)
文章目录 前言一、为设备开启开发者模式1、开启PICO VR一体机。前往设置>通用>关于本机>软件版本号2、一直点击 软件版本号 ,直到出现 开发者 选项3、进入 开发者模式,打开 USB调试,选择 文件传输 二、实时预览应用场景1、下载PC端的…...
电脑远程桌面选项变成灰色没办法勾选怎么办?
有些人在使用Windows系统自带的远程桌面工具时,会发现系统属性远程桌面选项卡中勾选启用“允许远程连接到此计算机”。 导致此问题出现的原因主要是由于组策略或者注册表设置错误造成的。 修复远程桌面选项变灰的两种方法! 方法一:设置本地组…...

2024.3.14
1.成员函数版本实现算术运算符的重载,全局函数版本实现算术运算符的重载 #include <iostream>using namespace std;class Room {friend const Room operator-(const Room &a,const Room &b); private:string a;int b; public:Room(){}Room(string a,int b):a(a)…...
chatGPT的耳朵!OpenAI的开源语音识别AI:Whisper !
语音识别是通用人工智能的重要一环!可以说是AI的耳朵! 它可以让机器理解人类的语音,并将其转换为文本或其他形式的输出。 语音识别的应用场景非常广泛,比如智能助理、语音搜索、语音翻译、语音输入等等。 然而,语音…...
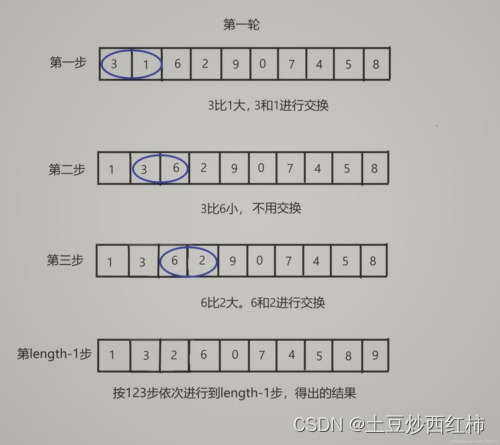
C语言冒泡排序
冒泡排序是一种简单的排序算法,通过重复遍历要排序的数列,依次比较两个相邻的元素,如果它们的顺序错误则交换它们。这个过程会重复进行,直到没有相邻的元素需要交换,也就是数列已经排序完成。 冒泡排序的名字来源于其工…...

vue2 elementui 封装一个动态表单复杂组件
封装一个动态表单组件在 Vue 2 和 Element UI 中需要考虑到表单字段的动态添加、删除以及验证等复杂功能。下面是一个简单的例子,展示如何创建一个可以动态添加和删除字段的表单组件。 首先,你需要安装并引入 Element UI: bash 复制 npm in…...
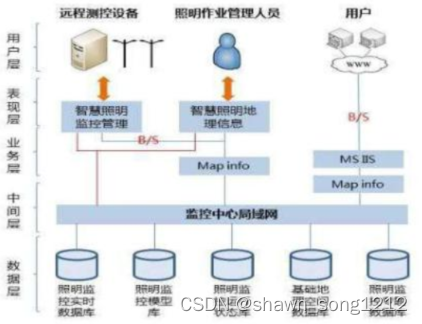
基于智慧灯杆的智慧城市解决方案(2)
功能规划 智慧照明功能 智慧路灯的基本功能仍然是道路照明, 因此对照明功能的智慧化提升是最基本的一项要求。 对道路照明管理进行智慧化提升, 实施智慧照明, 必然将成为智慧城市中道路照明发展的主要方向之一。 智慧照明是集计算机网络技术、 通信技术、 控制技术、 数据…...

「Paraverse平行云」亮相HKSTP OPENHOUSE活动
🚀11月7日,「Paraverse平行云」参展香港科学园HKSTP一年一度的Open House活动! ✨ 众多专家、同行与我们驻足深入交流,探索实时云渲染解决方案LarkXR在在数字人、数字孪生、建筑信息模型(BIM)、3D建模、建筑…...

CubeMX使用教程(5)——定时器PWM输出
本篇我们将利用CubeMX产生频率固定、占空比可调的两路PWM信号输出 例如PA6引脚输出100Hz的PWM;PA7引脚输出500Hz的PWM,双路同时输出 我们还是利用上一章定时器中断的工程进行学习,这样比较方便 首先打开CubeMX对PA6、PA7进行GPIO配置 注&a…...
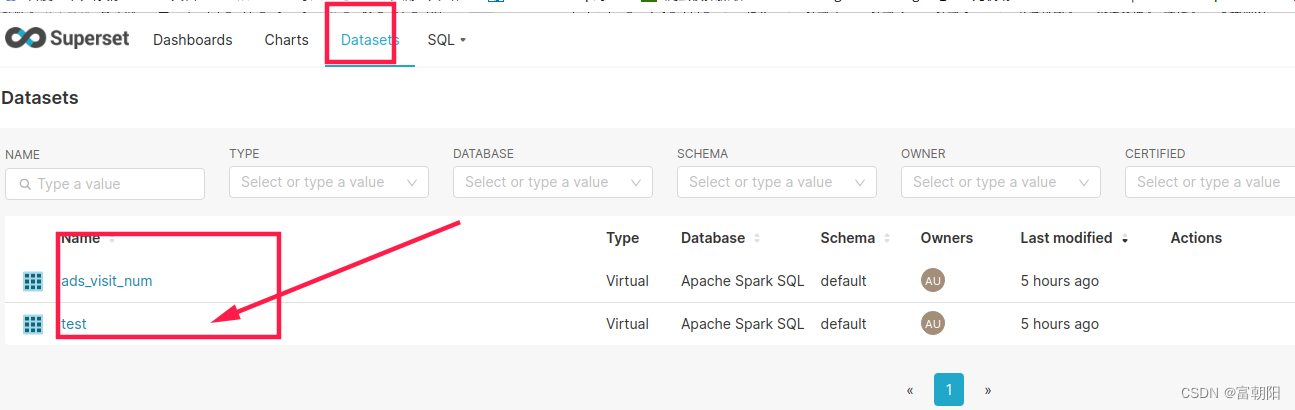
superset连接Apache Spark SQL(hive)过程中的各种报错解决
superset连接数据库官方文档:Installing Database Drivers | Superset 我们用的是Apache Spark SQL,所以首先需要安装下pyhive #命令既下载了pyhive也下载了它所依赖的其他安装包 pip install pyhive#多个命令也可下载 pip install sasl pip install th…...

Pulsar IO实战
一、引言 今天跟着 官方文档 基于docker玩一把Pulsar IO吧 二、概要 在用户能够轻松的将消息队列跟其他系统(数据库、其他消息系统)一起使用时,消息队列的作用才是最强大的。而Pulsar IO connectors可以让你很轻松的创建、部署以及管理这些跟外部系统的连接&#…...

微信M4A文件打不开怎么办?m4a转MP3只需一招,小白也能操作
很多人会遇到这种情况:别人通过微信发来一段录音、会议音频、课程音频或者采访素材,文件后缀是.m4a,在微信里可能能播放,但保存到手机本地、发到电脑、导入剪辑软件或者复制到U盘后,就可能出现打不开、无法识别、格式不…...

Palworld存档迁移终极解决方案:palworld-host-save-fix完整教程
Palworld存档迁移终极解决方案:palworld-host-save-fix完整教程 【免费下载链接】palworld-host-save-fix Fixes the bug which forces a player to create a new character when they already have a save. Useful for migrating maps from co-op to dedicated ser…...

毫米波雷达非接触生命体征监测技术解密:从8.6米远距探测到医疗级精准分析
毫米波雷达非接触生命体征监测技术解密:从8.6米远距探测到医疗级精准分析 【免费下载链接】mmVital-Signs mmVital-Signs project aims at vital signs detection and provide standard python API from Texas Instrument (TI) mmWave hardware, such as xWR14xx, x…...

数据分析智能体:推荐2026-05-19 17:33字号
SmartHey5月19日消息,腾讯云今日正式发布大数据智能体工作台——DataBuddy。用户仅需通过自然语言对话,即可一站式完成数据接入、开发、治理与分析等全链路任务,无需在多个系统页面间跳转。一句话明确目标,Agent自动拆解、规划并执…...

卖包装薄膜怎么找客户?下游工厂在哪里
卖包装薄膜找客户,本质是找用膜的下游工厂,核心难点是把这些真实在产、真实消耗薄膜的下游厂的名单和联系人系统拿到手——报价单发不出去、拜访找不到门,问题往往出在名单环节而不是产品本身。 包装薄膜的下游客户到底是谁 包装薄膜品类多样…...
)
别再重启了!Win11开机卡死/间歇性卡顿的终极排查与修复指南(附免费工具)
Win11系统卡顿终极自救指南:从根源排查到永久修复 每次开机都像在玩俄罗斯轮盘赌——今天Win11会卡死吗?鼠标指针变成沙漏图标的那一刻,血压瞬间飙升的场景想必每个Win11用户都经历过。不同于网上那些"重启试试"的敷衍建议…...

ChatGPT企业版安全合规全解析:如何在72小时内完成GDPR/等保2.0双认证接入?
更多请点击: https://intelliparadigm.com 第一章:ChatGPT企业版核心架构与合规定位 ChatGPT企业版并非简单叠加访问权限的SaaS服务,而是基于隔离部署、数据主权保障与策略可编程性构建的合规优先架构。其底层采用多租户物理隔离的专用基础设…...

百度网盘Mac版SVIP破解插件:从龟速到极速的下载体验优化指南
百度网盘Mac版SVIP破解插件:从龟速到极速的下载体验优化指南 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 你是否曾经面对百度网盘那令人…...

ShopXO任意文件读取漏洞CNVD-2021-15822深度解析
1. 这不是“读文件”,而是绕过权限边界的系统级失守 ShopXO 是国内中小电商项目中出镜率极高的开源系统,轻量、模板丰富、部署快,很多本地生活类小程序后台、县域特产商城、校园二手平台都用它打底。但就在2021年CNVD公布的编号 CNVD-2021-15…...

2026论文降AI率必备清单:AI率92%暴降至5%!实测10款AI智能降重工具!学生党狂喜!
2026 年各大高校和期刊平台的 AI 检测系统又升级了,知网 AIGC、维普 AI、万方智能检测三大平台的算法迭代速度越来越快,上个月能蒙混过关的改写方式,这个月直接就会被标红预警。单纯的同义词替换、语序调整早就不管用了,想要有效降…...