springboot Mongo大数据查询优化方案
前言
因为项目需要把传感器的数据保存起来,当时设计的时是mongo来存储,后期需要从mongo DB里查询传感器的数据记录。由于传感器每秒都会像mongo数据库存500条左右的数据,1天就有4320万条数据,要想按照时间条件去查询,经常会被卡死。以下是我的解决过程和方案。
解决方案
水平分表
按照传感器类型分表
将不同不同传感器的数据,分别存入不同的表(集合)中,这样每个表的数据就成倍减少,但是过了一段时间发现查询嗨是很慢,每个传感器每秒需要保存的数据也有100条左右,一天就是864万条数据。仅靠类型分表是不行的。
按照日期分表
每个表每天的数据有864万条数据,一个月就是2.6亿条数据。于是按照日期,每天对每个传感器类型建设了一个表 表(集合)名格式如 ‘temperature_sensor_20240310’。
如保存数据时候自动创建分表代码如下:
@Asyncpublic <T> void insertSharding(Collection<? extends T> batchToSave, String collectionName) {String collectionNameSharding = collectionName + "_" + DateUtil.today();if (CollectionUtil.isNotEmpty(batchToSave)) {mongoTemplate.insert(batchToSave, collectionNameSharding);}}
- DateUtil.today() 是我工具类里的方法等效于 DateUtil.format(new Date(),“yyyyMMdd”)
- 注意请保证每个传入的对象里都有一个createTime字段,查询的时候会用到
按照时间查询分表的方法,代码如下:
public <T> List<T> getSecondData(LocalDateTime start, LocalDateTime end, Class<T> entityClass, String collectionName) {String collectionNameSharding =collectionName+"_"+DateUtil.format(start,"yyyyMMdd");// 设置时间范围查询条件Criteria criteria = Criteria.where("createTime").gte(start).lte(end);// 查询数据return mongoTemplate.find(Query.query(criteria).limit(1000).skip(0), entityClass,collectionNameSharding);}
-
代码中的 .limit(1000) 表示限制查询结果的数量,即最多返回1000条匹配的文档记录。这对于分页查询或者批量处理数据时非常有用,可以避免一次性加载过多数据导致内存溢出或响应延迟。
-
而 .skip(0) 则表示跳过前0条匹配的文档记录,从第一条开始返回。在分页查询场景下,如果你想获取第二页的数据,通常会将skip的参数设置为每页大小(假设也是1000),即 .skip(1000),这样就会跳过前1000条,然后取接下来的1000条数据。
经过以上操作查询数据的时候不会被卡顿了,但是查询速度需要2s左右,项目需求查询速度至少得在200ms内,所以还得继续优化。
建立索引
因为mongo水平分表的缘故,不可能人工去对每个字段创建的表(集合)去建立时间索引,需要代码实现,创建表的同时,自动创建时间索引。
- 修改分表数据保存方法如下:
@Asyncpublic <T> void insertSharding(Collection<? extends T> batchToSave, String collectionName) {String collectionNameSharding = collectionName + "_" + DateUtil.today();if (!mongoTemplate.collectionExists(collectionNameSharding)) {mongoTemplate.createCollection(collectionNameSharding);IndexOperations indexOps = mongoTemplate.indexOps(collectionNameSharding);indexOps.ensureIndex(new Index().on("createTime", Sort.Direction.ASC).named(collectionNameSharding+"_createTime"));}if (CollectionUtil.isNotEmpty(batchToSave)) {mongoTemplate.insert(batchToSave, collectionNameSharding);}}
- named(collectionNameSharding+“_createTime”)) 即创建索引的名称
- on(“createTime”, Sort.Direction.ASC) 即使用集合中的createTime字段按照升序建立索引。
总结
经过以上水平分表和建立索引的方法,按照时间条件去查询的方法已经可以优化到200ms左右了。本篇教程到此未知,如果觉得不错,记得一键三连,感谢各位的支持!!!
相关文章:

springboot Mongo大数据查询优化方案
前言 因为项目需要把传感器的数据保存起来,当时设计的时是mongo来存储,后期需要从mongo DB里查询传感器的数据记录。由于传感器每秒都会像mongo数据库存500条左右的数据,1天就有4320万条数据,要想按照时间条件去查询,…...
Ollama管理本地开源大模型,用Open WebUI访问Ollama接口
现在开源大模型一个接一个的,而且各个都说自己的性能非常厉害,但是对于我们这些使用者,用起来就比较尴尬了。因为一个模型一个调用的方式,先得下载模型,下完模型,写加载代码,麻烦得很。 对于程…...
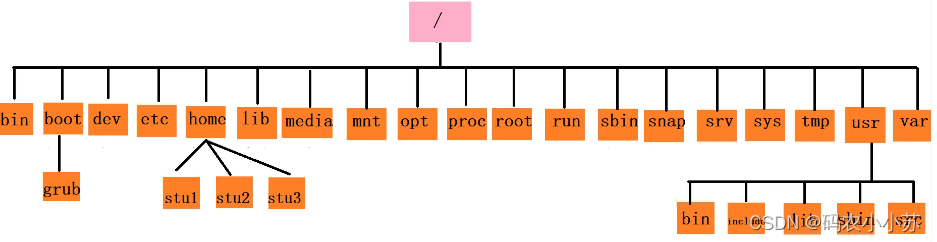
Linux--基本知识入门
一.几个基本知识 终端: CtrlAltT 或者桌面/文件夹右键,打开终端切换为管理员: sudo su 退出:exit查看内核版本号: uname -a内核版本号含义: 5 代表主版本号;13代表次版本号;0代表修订版本号;30代表修订版本的第几次微调;数字越大表示内核越新. 二.目录…...
基于springboot+vue实现的大学计算机课程管理平台的设计与实现(全套资料)
一、系统架构 前端:vue | antv 后端:springboot | mybatis-plus 环境:jdk17 | mysql | maven | node | redis 二、代码及数据库 三、功能介绍 01. 登录页 02. 首页 03. 系统基础模块-用户管理 04. 系统基础模块-部门…...
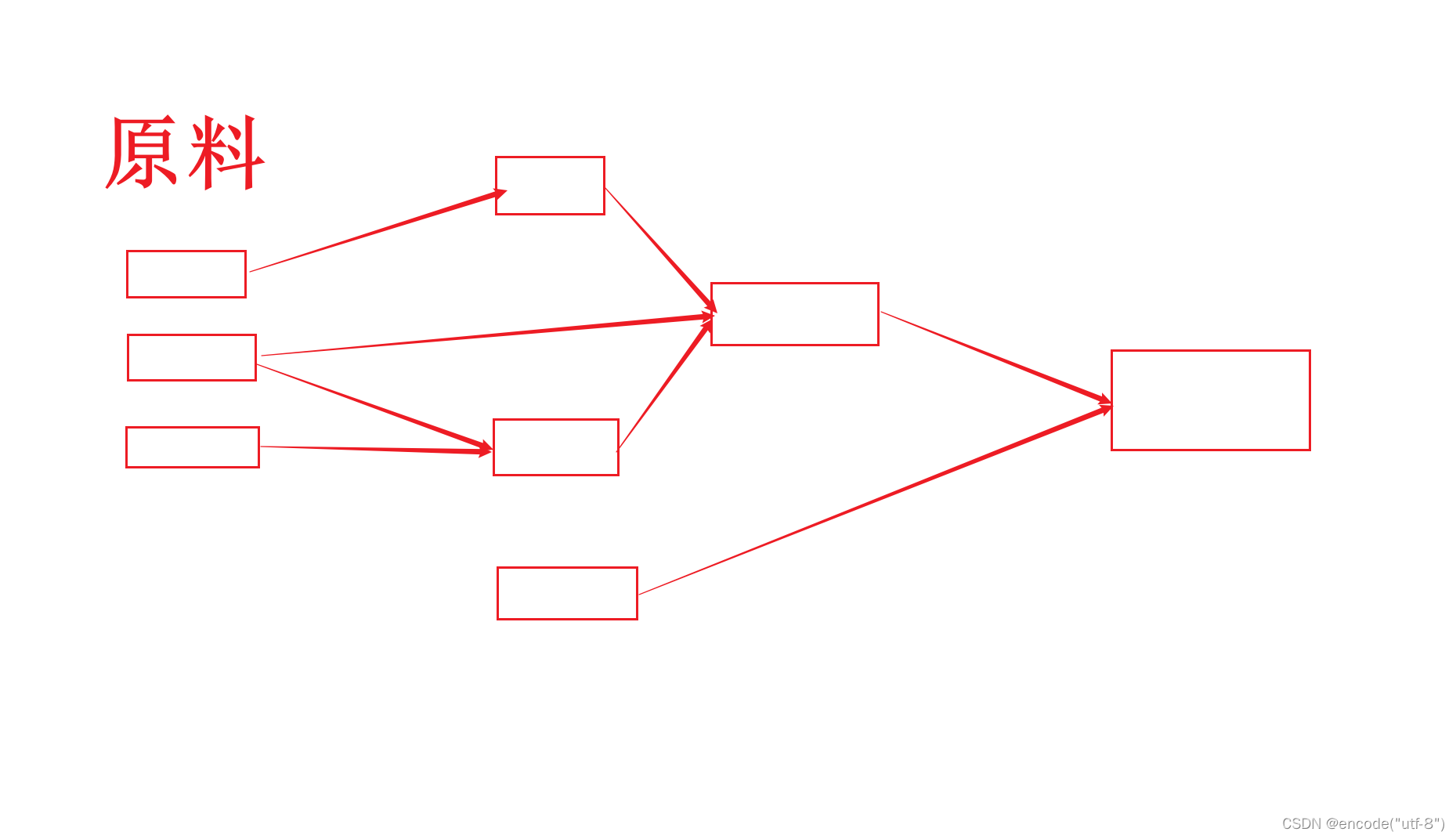
LeetCode2115. 从给定原材料中找到所有可以做出的菜
拓扑排序 题面 题目链接:2115. 从给定原材料中找到所有可以做出的菜 - 力扣(LeetCode) 你有 n 道不同菜的信息。给你一个字符串数组 recipes 和一个二维字符串数组 ingredients 。第 i 道菜的名字为 recipes[i] ,如果你有它 所有…...
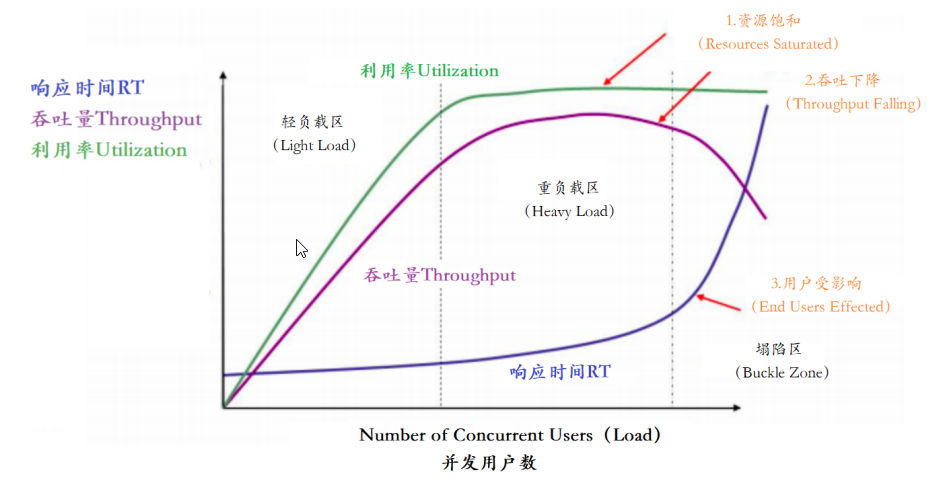
项目性能优化—性能优化的指标、目标
项目性能优化—性能优化的指标、目标 性能优化的终极目标是什么 性能优化的目标实际上是为了更好的用户体验: 一般我们认为用户体验是下面的公式: 用户体验 产品设计(非技术) 系统性能 ≈ 系统性能 快 那什么样的体验叫快呢…...
)
蓝桥杯刷题(三)
一、P8752 [蓝桥杯 2021 省 B2] 特殊年份(洛谷) 题目描述 今年是 2021 年,2021 这个数字非常特殊, 它的千位和十位相等, 个位比百位大 1,我们称满足这样条件的年份为特殊年份。 输入 5 个年份,请计算这里面有多少个…...

20240312-算法复习打卡day21||● 530.二叉搜索树的最小绝对差 ● 501.二叉搜索树中的众数 ● 236. 二叉树的最近公共祖先
530.二叉搜索树的最小绝对差 1.中序遍历得到升序数组 class Solution { private:vector<int> vec;void traversal(TreeNode* root) {if (root NULL) return;if (root->left) traversal(root->left);vec.push_back(root->val);if (root->right) traversal(r…...

今天我们来学习一下关于MySQL数据库
目录 前言: 1.MySQL定义: 1.1基础概念: 1.1.1数据库(Database): 1.1.2表(Table): 1.1.3记录(Record)与字段(Field): …...

长期护理保险可改善老年人心理健康 | CHARLS CLHLS CFPS 公共数据库周报(3.6)...
欢迎报名2024年“真实世界临床研究”课程! 本周郑老师开讲:“真实世界临床研究”培训班,3月16-17日两天,欢迎报名! CHARLS公共数据库 CHARLS数据库简介中国健康与养老追踪调查(China Health and Retirement Longitud…...
49、C++/友元、常成员函数和常对象、运算符重载学习20240314
一、封装类 用其成员函数实现(对该类的)数学运算符的重载(加法),并封装一个全局函数实现(对该类的)数学运算符的重载(减法)。 代码: #include <iostream…...

SQL Server错误:15404
执行维护计划失败,提示SQL Server Error 15404 无法获取有关... 异常如下图: 原因:数据库用户名与计算机名称不一致 解决办法:1.重名称数据库用户名 将前缀改成计算机名 2.重启SQL Server代理...
Halcon文件操作
1、Region读写操作 region(区域)是一种重要的数据类型,用于表示图像中的特定区域。这些区域可以代表图像中的目标、感兴趣的区域、边缘、形状等等 read_image (Image, printer_chip/printer_chip_01) dev_open_window (0, 0, 512, 512, black…...

【测试知识】业务面试问答突击版1
高内聚低耦合 高内聚指的是将相关的功能或数据组织在一起,使得模块内部的各个元素紧密地联系在一起,完成特定的任务。 低耦合指的是模块之间的依赖关系尽可能地降低,模块之间的接口简单清晰,减少模块之间的相互影响。 文章目录 整…...
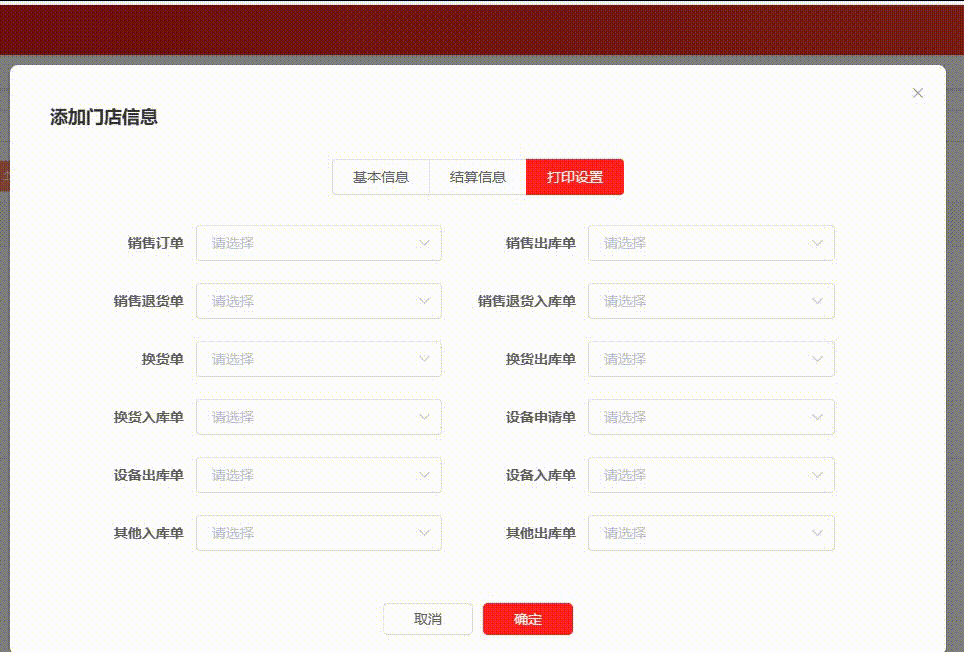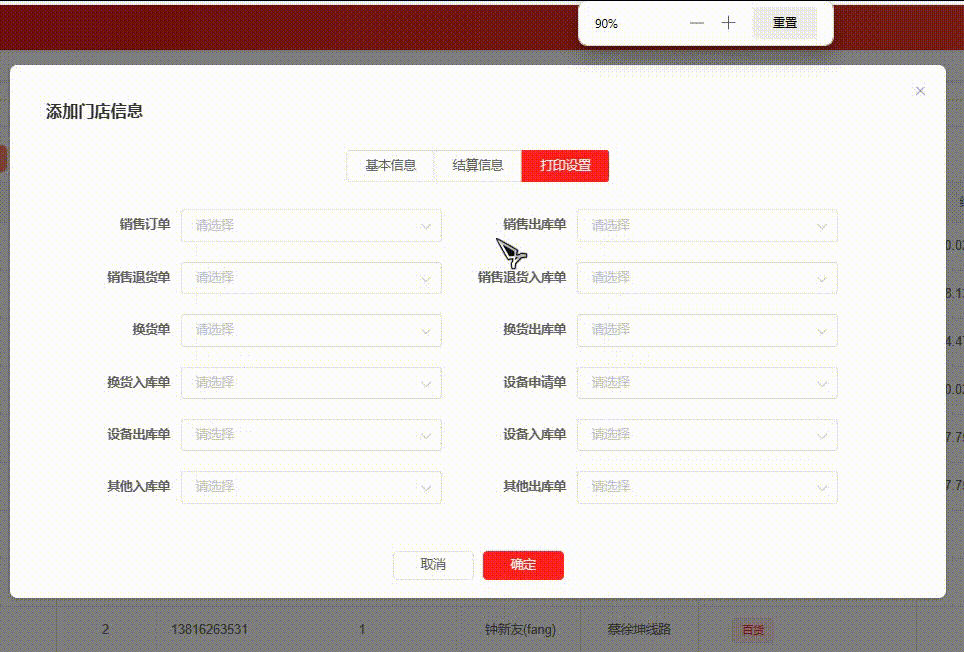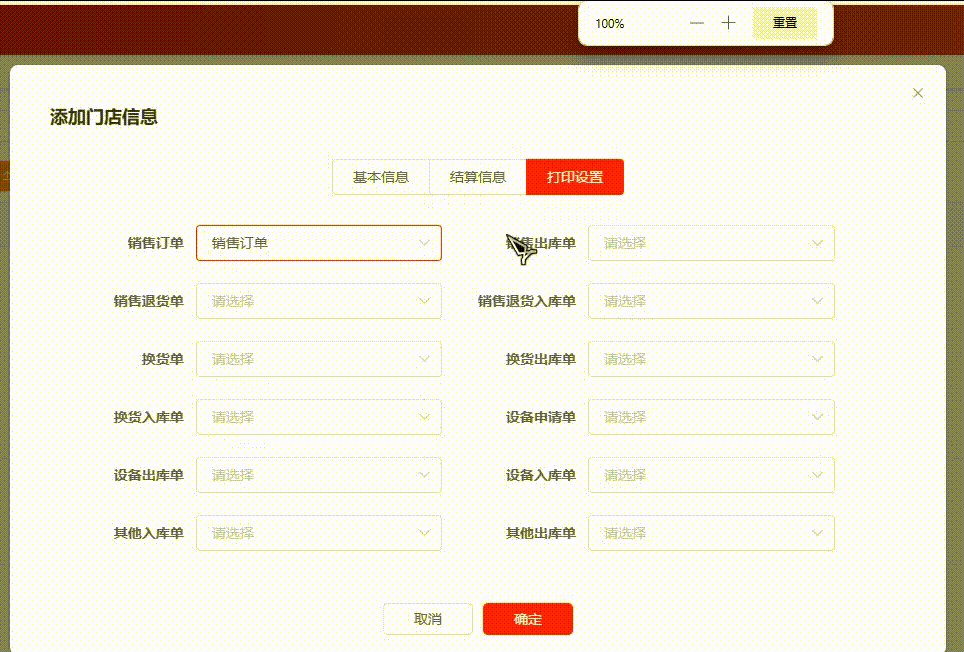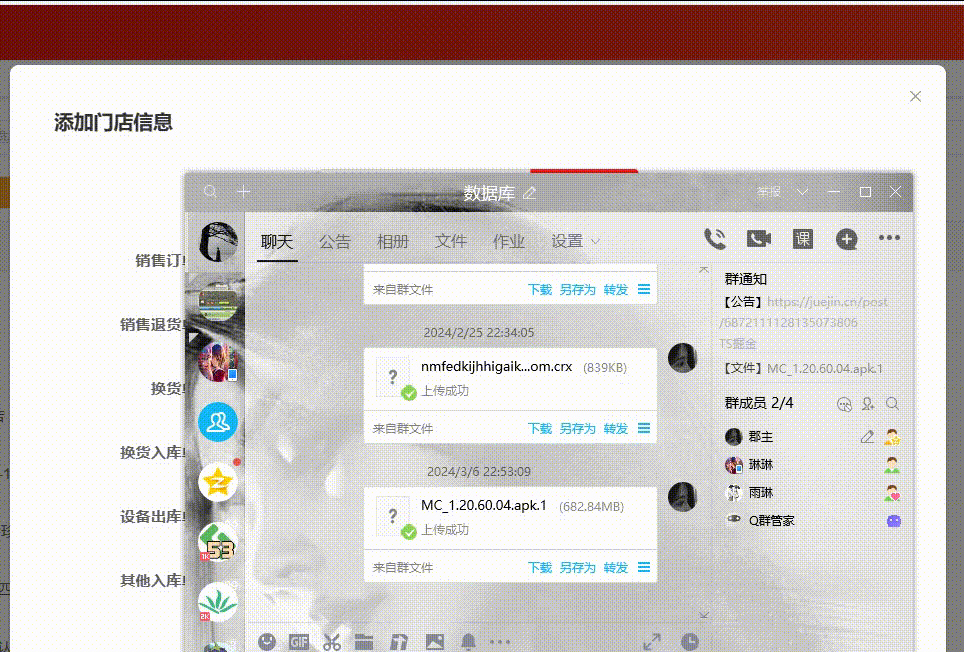
使用el-row及el-col页面缩放时出现空行解决方案
问题: 当缩放到90%或者110%,选中下拉后,下方就会出现空行 如下图所示: 关于el-row 和 el-col : 参数说明类型可选值默认值span栅格占据的列数number—24offset栅格左侧的间隔格数number—0push栅格向右移动格数number…...
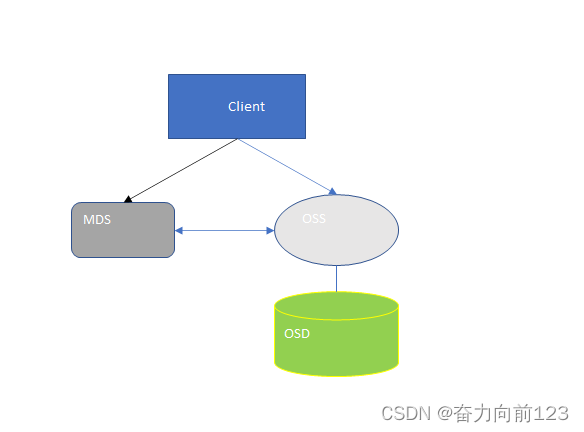
java中几种对象存储(文件存储)中间件的介绍
一、前言 在博主得到系统中使用的对象存储主要有OSS(阿里云的对象存储) COS(腾讯云的对象存储)OBS(华为云的对象存储)还有就是MinIO 这些玩意。其实这种东西大差不差,几乎实现方式都是一样&…...
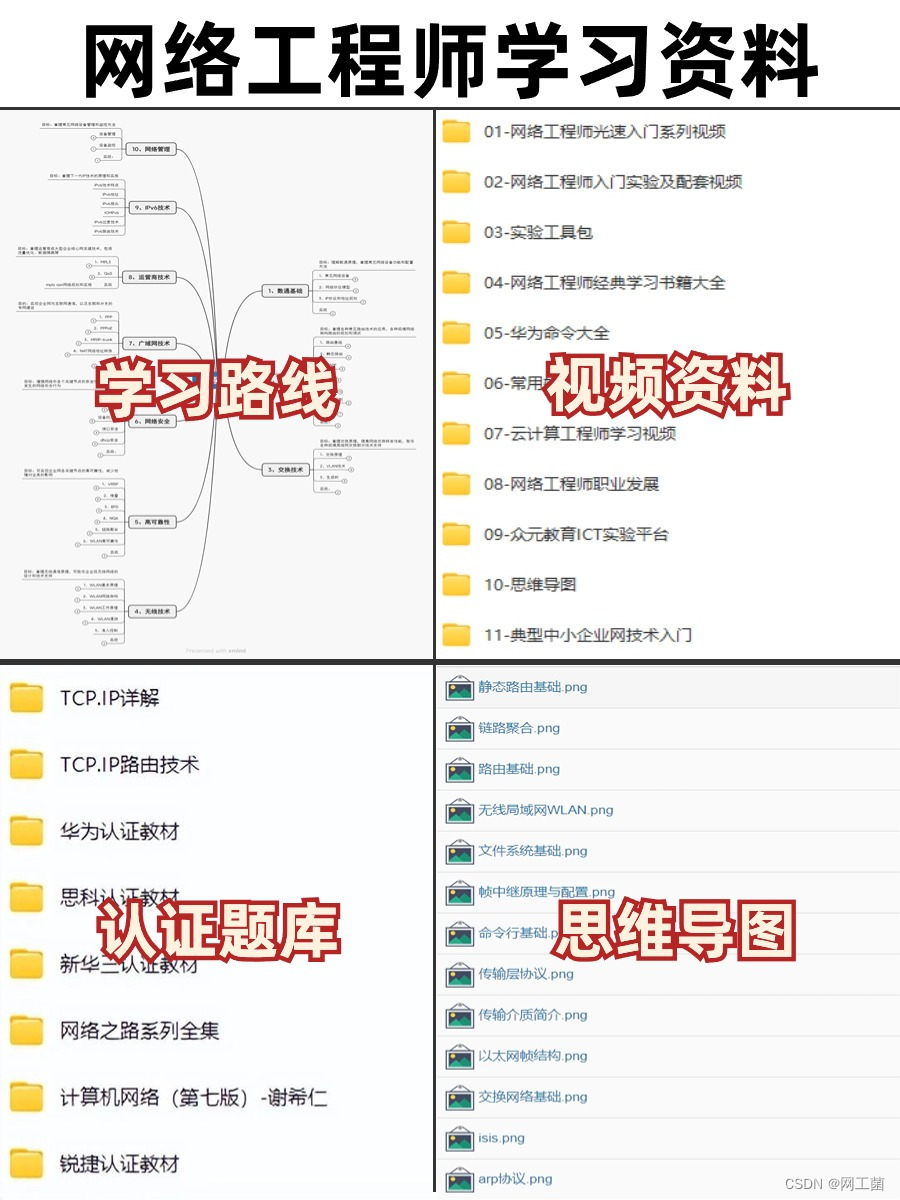
网络工程师——2024自学
一、怎样从零开始学习网络工程师 当今社会,人人离不开网络。整个IT互联网行业,最好入门的,网络工程师算是一个了。 什么是网络工程师呢,简单来说,就是互联网从设计、建设到运行和维护,都需要网络工程师来…...

SwiftUI的Picker
SwiftUI的Picker 本章来记录一下SwiftUI中三种不同Picker的用法 ,分别为normalPicker , wheelPicker, segmentedPicker 。可以根据不同需求展示不同的Picker import SwiftUIstruct PickerBootCamp: View {State var selection: String &quo…...

物联网技术助力智慧城市转型升级:智能、高效、可持续
目录 一、物联网技术概述及其在智慧城市中的应用 二、物联网技术助力智慧城市转型升级的路径 1、提升城市基础设施智能化水平 2、推动公共服务智能化升级 3、促进城市治理现代化 三、物联网技术助力智慧城市转型升级的成效与展望 1、成效显著 2、展望未来 四、物联网技…...

YOLOv7_pose-Openvino和ONNXRuntime推理【CPU】
纯检测系列: YOLOv5-Openvino和ONNXRuntime推理【CPU】 YOLOv6-Openvino和ONNXRuntime推理【CPU】 YOLOv8-Openvino和ONNXRuntime推理【CPU】 YOLOv7-Openvino和ONNXRuntime推理【CPU】 YOLOv9-Openvino和ONNXRuntime推理【CPU】 跟踪系列: YOLOv5/6/7-O…...

DS89C420片上SRAM的启用与配置详解
1. 项目概述:DS89C420片上SRAM的启用与配置 在嵌入式开发领域,Dallas Semiconductor(后被Maxim Integrated收购)的DS89C420系列微控制器因其高性能和丰富的外设资源受到工程师青睐。这款基于8051架构的芯片有一个容易被忽视的特性…...

VutronMusic:构建现代化跨平台音乐播放器的技术实现方案
VutronMusic:构建现代化跨平台音乐播放器的技术实现方案 【免费下载链接】VutronMusic 高颜值的第三方网易云播放器;支持流媒体音乐,如navidrome、jellyfin、emby;支持本地音乐播放、离线歌单、逐字歌词、桌面歌词、Touch Bar歌词…...

终极指南:5分钟搭建Rust高性能HTTP文件服务器,告别繁琐配置
终极指南:5分钟搭建Rust高性能HTTP文件服务器,告别繁琐配置 【免费下载链接】simple-http-server Simple http server in Rust (Windows/Mac/Linux) 项目地址: https://gitcode.com/gh_mirrors/si/simple-http-server Simple HTTP Server是一款基…...

在 Taotoken 平台管理账单与下载历史消费记录的便利性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Taotoken 平台管理账单与下载历史消费记录的便利性 对于需要将大模型 API 调用成本纳入项目预算或团队核算的开发者而言&#x…...

聚焦养老服务管理 以 AI 课堂革新实训教学模式
一、引言在养老产业数智化转型背景下,智慧健康养老服务与管理专业实训室建设需紧扣产业需求。AI 课堂作为教学数字化升级的核心载体,可有效破解传统实训教学与岗位需求脱节、高危场景难实操、教学评价不精准等痛点,为实训室建设提供实用可行的…...

简单说明--程序系统如何对用户身份证实名认证接口api
程序系统对注册用户身份认证,接口将【身份证号码、姓名】上传至接口API判断是否匹配 请求数据: bodys.put("idNo", "330421190210182345"); bodys.put("name", "张某某");响应数据: {"name&quo…...

如何解决跨平台资源下载难题:res-downloader的完整使用指南
如何解决跨平台资源下载难题:res-downloader的完整使用指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否…...

【纳瓦尔宝典】财富篇精读:程序员实现财富自由的底层逻辑
本文是《纳瓦尔宝典》第一部分"财富"与第二部分"判断力"的完整精读笔记,专为程序员群体量身打造。结合技术职场实际,拆解每一个核心观点,提供可落地的行动指南。一、积累财富:不是靠打工,而是靠创…...

别再手动刷新了!用HomePage v0.8.2+Docker Compose,一键监控所有容器和网站状态
别再手动刷新了!用HomePage v0.8.2Docker Compose,一键监控所有容器和网站状态 每次登录服务器都要挨个检查容器是否运行正常?网站挂了却要等用户反馈才知道?这种被动式运维早该淘汰了。今天介绍的这套方案,能让你的H…...

ENSP实验避坑指南:搭建园区网时,VLAN间通信、MSTP负载分担、VRRP主备切换这些细节你配对了吗?
ENSP园区网实战排错手册:从VLAN间通信到VRRP主备切换的深度解析 刚完成ENSP园区网搭建实验的网络工程师小王盯着屏幕,眉头紧锁——所有配置明明都按照教程一步步操作,可VLAN间的PC就是无法互通,MSTP负载分担也没生效。这种"…...