Python数据分析实验一:Python数据采集与存储
目录
- 一、实验目的与要求
- 二、实验过程
- 三、主要程序清单和运行结果
- 1、爬取 “中国南海网” 站点上的相关信息
- 2、爬取天气网站上的北京的历史天气信息
- 四、程序运行结果
- 五、实验体会
一、实验目的与要求
1、目的:
理解抓取网页数据的一般处理过程;熟悉应用 Chrome 浏览器的工具分析网页的基本操作步骤;掌握使用 Requests 库获取静态网页的基本方法;掌握 Beautiful Soup 提取静态网页信息的主要技术。
理解网络数据采集的 Robots 协议的基本要求,能合规地进行网络数据采集。
2、要求:
编写一个网络爬虫,爬取某个网站的信息并存储到文件或数据库中。学生既可以使用 Requests/Beautiful Soup 库来实现信息采集,也可以自选其他爬虫技术,对爬取的网站也允许自选,但需要符合相关网站的规定。推荐如下的两个网址,可以选择其中之一采集网页上的信息:
(1)爬取 “中国南海网” 站点上的相关信息。
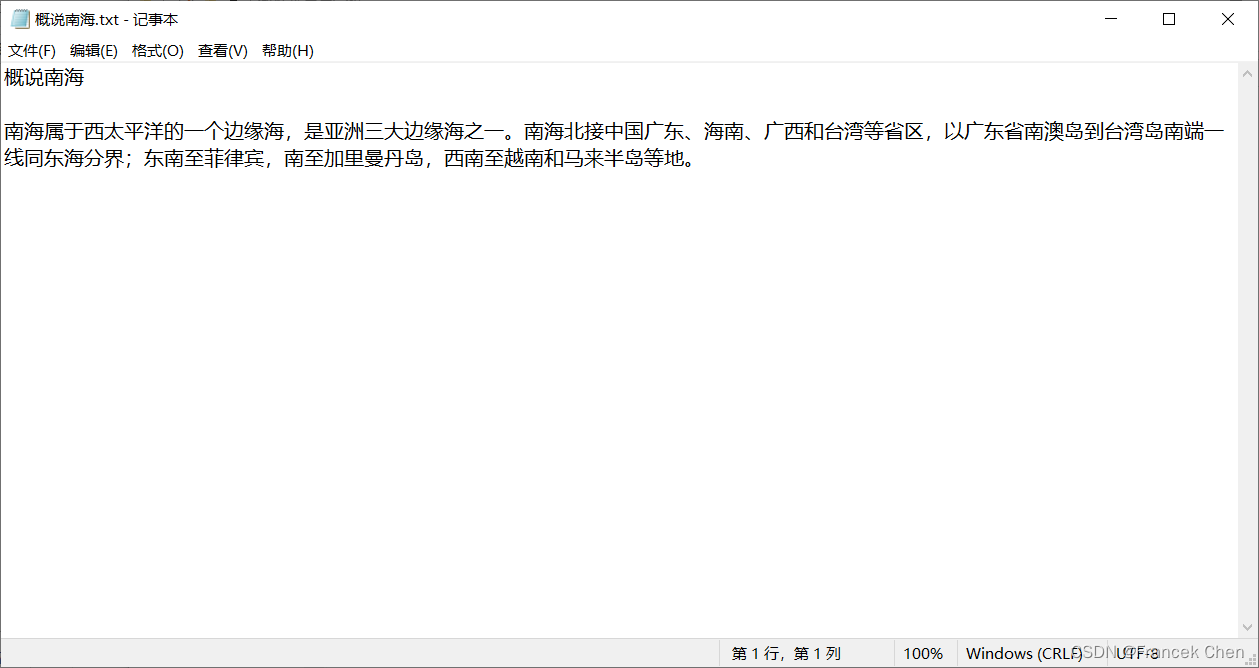
图1是中国南海网上特定页面(http://www.thesouthchinasea.org.cn/about.html)的部分截图,请爬取该网页中某一栏目的内容并保存在一个TXT文件中,爬取结果如图2所示。


(2)爬取天气网站上的北京的历史天气信息。
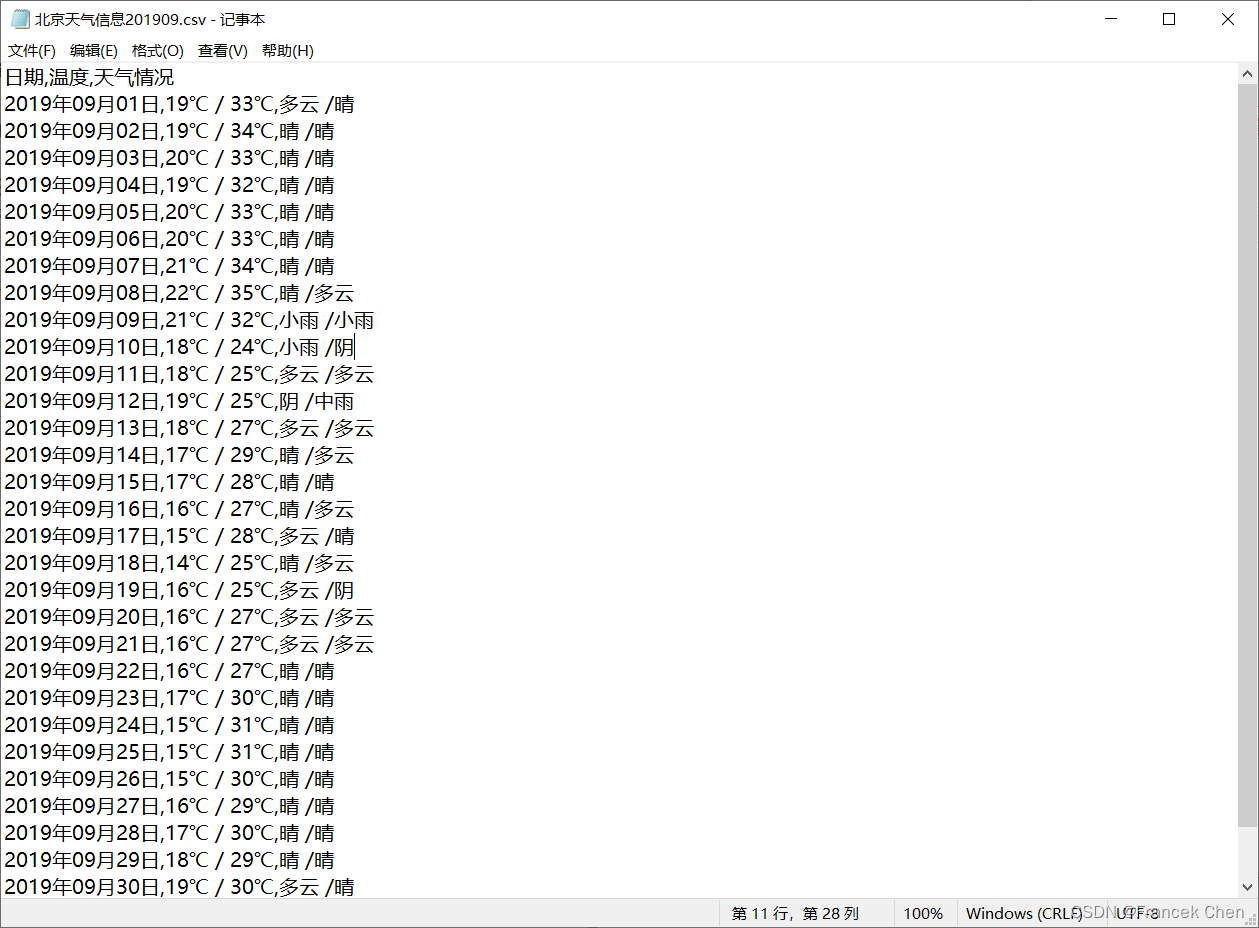
图3是天气网关于北京2019年9月份天气信息的部分截图,请爬取该网页(http://www.tianqihoubao.com/lishi/beijing/month/201909.html)中的天气信息并保存在一个 CSV 文件中,爬取结果如图4所示。


二、实验过程
1、观察所爬取网站的Robots协议的相关内容:
https://www.baidu.com/robots.txt

2、网络爬虫抓取网页数据的一般处理过程:
(1)确定目标网站:首先,需要明确自己想要获取哪个网站上的数据。通常情况下,我们需要先通过浏览器访问该网站,并查看其源代码,以便更好地了解其网页结构和所需数据所在位置。
(2)分析目标网站:接着,需要对目标网站进行分析。这包括查看该网站的 robots.txt 文件,了解其对爬虫的限制;查看其页面结构和 URL 规则,以便编写相应的爬虫程序。
(3)编写爬虫程序:在确定了目标网站并分析了其结构后,就可以开始编写爬虫程序了。这需要使用一些编程语言和相关库来实现。在编写程序时,需要注意多线程处理、异常处理等问题。
(4)发送 HTTP 请求:在编写好爬虫程序后,就可以向目标网站发送 HTTP 请求了。这需要使用相应的库或工具来实现。在发送请求时,需要注意设置请求头、代理等参数,以避免被目标网站封禁。
(5)解析 HTML 页面:当爬虫程序成功获取到目标网站返回的响应后,就需要对其进行解析。这需要使用一些 HTML 解析器来实现。在解析页面时,需要注意处理页面中的各种标签、属性等信息,并将所需数据提取出来。
(6)存储数据:在提取出所需数据后,就需要将其存储下来。这可以使用各种数据库或文件系统来实现。在存储数据时,需要考虑数据格式、存储方式等问题。
(7)去重处理:由于同一个网站上可能存在多个相同的页面或数据,因此需要对已经获取过的页面或数据进行去重处理。
三、主要程序清单和运行结果
1、爬取 “中国南海网” 站点上的相关信息
import requests
from bs4 import BeautifulSoup# 发起请求
url = 'http://www.thesouthchinasea.org.cn/about.html'
response = requests.get(url)# 解析HTML内容
soup = BeautifulSoup(response.content, 'html.parser')# 查找包含标题为“概说南海”的元素
section = soup.find('h3', text='概说南海')if section:# 获取概说南海栏目标题和内容content = f"{section.get_text(strip=True)}\n\n"next_element = section.find_next_sibling()while next_element and next_element.name != "h3":if next_element.name == "p": # 只获取段落内容paragraph_text = next_element.get_text(strip=True)paragraph_text = paragraph_text.replace("[更多]", "")content += paragraph_text + "\n"next_element = next_element.find_next()# 将内容存储到文件中with open('概说南海.txt', 'w', encoding='utf-8') as file:file.write(content)print('“概说南海”内容已成功爬取并保存到概说南海.txt文件中。')
else:print('未找到“概说南海”栏目的内容。')
用于从指定的 URL(在这个例子中是http://www.thesouthchinasea.org.cn/about.html)爬取标题为“概说南海”的内容,并将这些内容保存到本地文件“概说南海.txt”中。这个过程涉及到发送 HTTP 请求、解析 HTML 内容、文本处理以及文件操作等多个环节。以下是对这个代码的简要分析:
-
发送HTTP请求:使用
requests.get(url)向指定的URL发起GET请求,获取网页内容。 -
解析HTML内容:利用
BeautifulSoup(response.content, 'html.parser')解析服务器返回的内容。这里,response.content得到的是原始的字节流,而'html.parser'是指定的解析器。 -
查找特定元素:通过
soup.find('h3', text='概说南海')查找页面上文本为“概说南海”的<h3>标签,这是定位需要抓取内容的起点。 -
提取并处理内容:从找到的
<h3>标签开始,遍历其后的同级元素,直到遇到下一个<h3>标签为止(或者没有更多同级元素)。在这个过程中,如果遇到的是<p>标签,则提取其文本内容,并去除其中的 “[更多]” 字符串。 -
保存到文件:将处理后的文本内容写入名为
“概说南海.txt”的文件中,文件编码为UTF-8。 -
异常处理:如果在页面中没有找到标题为
“概说南海”的部分,会打印提示信息。
此脚本展示了 Python 在网络爬虫方面的应用,尤其是使用requests库进行网络请求和BeautifulSoup库进行 HTML 解析的实践。
2、爬取天气网站上的北京的历史天气信息
import requests
from bs4 import BeautifulSoup# 目标网页的URL
url = "http://www.tianqihoubao.com/lishi/beijing/month/201909.html"
# 使用requests库获取网页内容
response = requests.get(url)
# 使用BeautifulSoup解析获取到的网页内容
soup = BeautifulSoup(response.text, "html.parser")
# 在解析后的网页中找到包含天气信息的表格,假设它的class为"b"
weather_table = soup.find("table", class_="b")
# 从表格中找到所有的行(tr元素),跳过第一行(标题行)
rows = weather_table.find_all("tr")[1:]# 打开(或创建)一个名为"北京天气信息201909.csv"的文件用于写入
with open("北京天气信息201909.csv", mode="w", encoding="utf-8") as file:# 写入CSV文件头file.write("日期,温度,天气情况\n")# 遍历每一行天气数据for row in rows:columns = row.find_all("td") # 在当前行中找到所有的单元格(td元素)date = columns[0].text.strip() # 提取日期数据,并去除两端多余的空白字符temperature = ' '.join(columns[2].text.strip().split()) # 提取温度数据,将多余的空白字符替换为单个空格weather = ' '.join(columns[1].text.strip().split()) # 提取天气情况数据,同样将多余的空白字符替换为单个空格# 将提取的数据写入CSV文件的一行中# 注意CSV中的数据项通常由逗号分隔,如果数据本身包含逗号,则需要用引号包围该数据项file.write(f"{date},{temperature},{weather}\n")# 数据保存完成后打印提示信息
print("天气信息已保存在 北京天气信息201909.csv 文件中。") 这段代码是用 Python 编写的一个简单的网络爬虫脚本,旨在从指定的网页中提取北京市2019年9月份的天气信息,并将提取到的数据保存到CSV文件“北京天气信息201909.csv”中。以下是对代码的简要分析:
-
发送HTTP请求:使用
requests.get(url)向指定的URL发起GET请求,获取网页内容。 -
解析HTML内容:利用
BeautifulSoup(response.text, 'html.parser')解析服务器返回的HTML内容。这里,response.text包含了网页的文本内容,而'html.parser'是指定的HTML解析器。 -
查找特定元素:通过
soup.find("table", class_="b")查找页面上class为"b"的表格元素,用于定位包含天气信息的表格。 -
提取并处理内容:遍历表格中的每一行,提取日期、温度和天气情况数据,并进行适当的清洗(去除空白字符)。
-
保存到文件:将提取的天气信息按照CSV格式写入到名为
“北京天气信息201909.csv”的文件中,每行包含日期、温度和天气情况。 -
CSV文件格式:CSV文件中的数据项通常由逗号分隔,如果数据本身包含逗号,则需要用引号包围该数据项。
-
异常处理:代码中没有显式的异常处理逻辑,如果在实际运行中出现网络连接问题或者页面结构变化,可能会导致程序出错。
请注意,网页的结构和内容经常会发生变化,因此需要定期检查和更新代码以适应目标网站的变化。同时,在实际应用中,也应该尊重网站的robots.txt协议,避免对网站造成不必要的负担。
四、程序运行结果
1、爬取 “中国南海网” 站点上的相关信息
运行结果:
2、爬取天气网站上的北京的历史天气信息
运行结果:
五、实验体会
通过实践,对网络爬虫如何工作有一个直观的认识,包括如何发送 HTTP 请求、如何解析网页内容、如何提取和处理数据等。这个过程能更好地理解网络协议、网页结构(HTML、CSS、JavaScript)以及服务器响应等概念。
在 Python 数据采集与存储实验中,你接触并使用多种第三方库,比如 requests 用于发起网络请求,BeautifulSoup 或 lxml 用于解析 HTML 文档,pandas 用于数据处理,sqlite3 或其他数据库模块用于数据存储等。这些库大大简化了数据采集和处理的过程,提高了开发效率。数据采集后的处理和存储是非常重要的一环。学会如何清洗数据、转换数据格式、有效地存储数据。这包括了解不同数据存储方式的特点,如文件存储(CSV、JSON等)、数据库存储(关系型数据库如 MySQL、SQLite ;非关系型数据库如 MongoDB)等。
在进行网络爬虫实验的过程中,更加深切地意识到遵守目标网站的 robots.txt 协议、尊重版权、保护个人隐私等法律法规和伦理道德的重要性。这不仅是合法合规的要求,也是作为一名负责任的开发者应有的职业操守。
相关文章:
Python数据分析实验一:Python数据采集与存储
目录 一、实验目的与要求二、实验过程三、主要程序清单和运行结果1、爬取 “中国南海网” 站点上的相关信息2、爬取天气网站上的北京的历史天气信息 四、程序运行结果五、实验体会 一、实验目的与要求 1、目的: 理解抓取网页数据的一般处理过程;熟悉应用…...

丘一丘正则表达式
正则表达式(regular expression,regex,RE) 正则表达式是一种用来简洁表达一组字符串的表达式正则表达式是一种通用的字符串表达框架正则表达式是一种针对字符串表达“简洁”和“特征”思想的工具正则表达式可以用来判断某字符串的特征归属 正则表达式常用操作符 操作符说明实…...

工业物联网平台在水务环保、暖通制冷、电力能源等行业的应用
随着科技的不断发展,工业物联网平台作为连接物理世界与数字世界的桥梁,正逐渐成为推动各行业智能化转型的关键力量。在水务环保、暖通制冷、电力能源等行业,工业物联网平台的应用尤为广泛,对于提升运营效率、降低能耗、优化管理等…...

【研发日记】Matlab/Simulink技能解锁(二)——在Matlab Function编辑窗口Debug
文章目录 前言 行断点 条件断点 按行步进 Watch Value 分析和应用 总结 前言 见《【研发日记】Matlab/Simulink技能解锁(一)——在Simulink编辑窗口Debug》 行断点 当Matlab Function出现异常时,如果能确定大致的代码段,就可以在相应的行上设置一…...

从键盘输入两个数,求它们的和并输出 从键盘输入三个数到a,b,c中,按公式值输出
别急别急,先看完 (从初学者出发) 从键盘输入两个数,求它们的和并输出 作者 陈春晖 单位 浙江大学 本题目要求读入2个整数A和B,然后输出它们的和。 输入格式: 在一行中给出一个被加数 在另一行中给出一个加数 输出格式: 在…...
(JavaPythonC++Node.jsC语言))
密码解密 C卷(100%用例)(JavaPythonC++Node.jsC语言)
给定一段“密文“字符串s,其中字符都是经过"密码本”映射的,现需要将"密文"解密并且输出 映射的规则(a-i)分别用(1-9)表示;(j-z")分别用(10-"26”)表示 约束:映射始终唯一 输入描述: “密文”字符串 输出描述: 明文字符串 补充说明: 翻译后的文本…...
因为manifest.json文件引起的 android-chrome-192x192.png 404 (Not Found)
H5项目打包之后,总是有这个报错,有时候还有别的icon也找不见 一通调查之后,发现是因为引入了一个vue插件 这个插件引入之后,webpack打包的时候就会自动在dist文件夹中产生一个manifest.json文件这个文件里面主要就是一些icon地址的…...

『 Linux 』进程替换( Process replacement ) 及 简单Shell的实现(万字)
文章目录 🦄 进程替换🦩 execl()函数🦩 execlp()函数🦩 execle()函数🦩 execv()函数🦩 execvp()函数🦩 execvpe()函数🦩 execve()函数 🦄 简单Shell命令行解释器的实现&a…...
【Linux】从零开始认识进程 — 前篇
我从来不相信什么懒洋洋的自由。我向往的自由是通过勤奋和努力实现的更广阔的人生。。——山本耀司 从零开始认识进程 1 认识冯诺依曼体系2 操作系统3 进程3.1 什么是进程???3.2 进程管理PCB 3.3 Linux中的进程深入理解 3.4 进程创建总结 送给…...

公众号留言功能恢复了,你的开通了吗?
了解公众号的人都知道,腾讯在2018年3月宣布暂停新注册公众号的留言功能,这之后注册的公众号都不具备留言功能。 这成了很多号主运营人的一块心病,也包括我。 没有留言,就好似一个人玩单机游戏,无法与读者互动ÿ…...
C语言葵花宝典之——文件操作
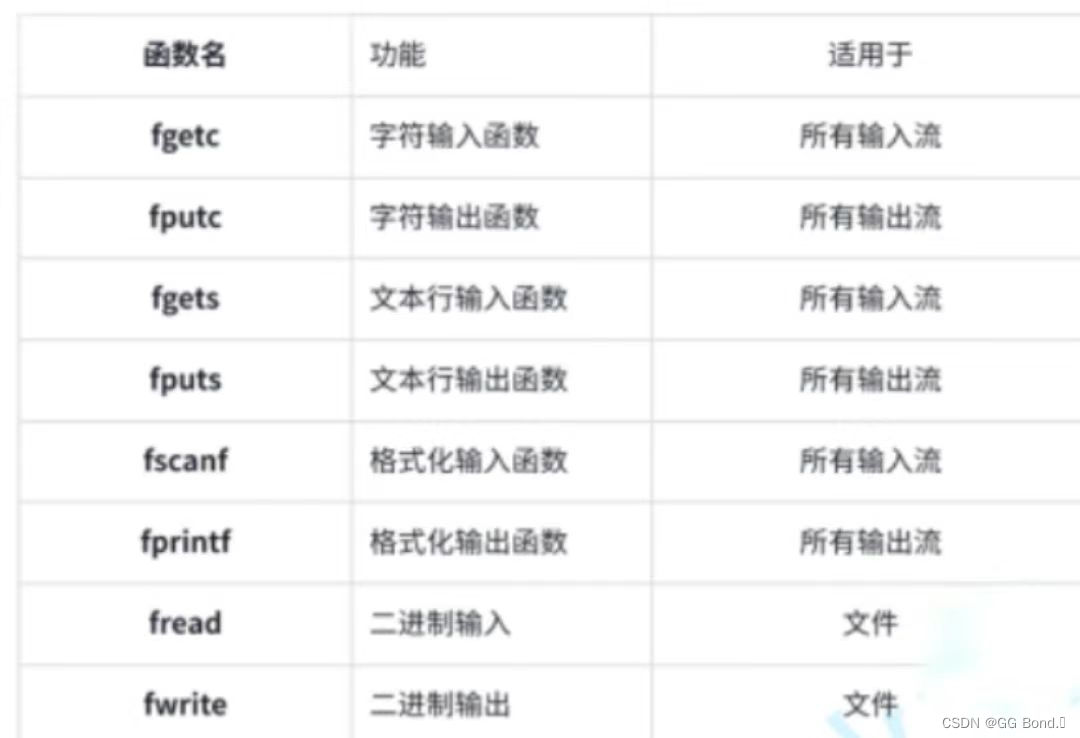
前言: 在之前的学习中,我们所写的C语言程序总是在运行结束之后,就会自动销毁,那如果我们想将一个结果进行长期存储应该如何操作呢?这时候就需要我们用文件来操作。 目录 1、什么是文件? 1.1 程序文件 1.2…...

SSM框架,MyBatis-Plus的学习(下)
条件构造器 使用MyBatis-Plus的条件构造器,可以构建灵活高效的查询条件,可以通过链式调用来组合多个条件。 条件构造器的继承结构 Wrapper : 条件构造抽象类,最顶端父类 AbstractWrapper : 用于查询条件封装…...

边缘计算网关的工作原理及其在工业领域的应用价值-天拓四方
随着物联网技术的快速发展,物联网时代已经悄然来临。在这个时代,数以亿计的设备相互连接,共享数据,共同构建智慧的世界。边缘计算网关通过将计算能力和数据存储推向网络的边缘,实现了对海量数据的实时处理,…...

下载指定版本的pytorch
下载网址:https://download.pytorch.org/whl/torch_stable.html 参考博客网址:https://blog.csdn.net/wusuoweiieq/article/details/132773977...

STL:List从0到1
🎉个人名片: 🐼作者简介:一名乐于分享在学习道路上收获的大二在校生 🙈个人主页🎉:GOTXX 🐼个人WeChat:ILXOXVJE 🐼本文由GOTXX原创,首发CSDN&…...

利用高分五号02星高光谱数据进行地物识别
高分五号02星搭载了一台60公里幅宽、330谱段、30米分辨率的可见短波红外高光谱相机(AHSI),可见近红外(400~1000nm)和短波红外光谱(1000~2500nm)分辨率分别达到5纳米和10纳米。单看参数性能优越&…...

前端如何识别上传的二维码---jsQR
npm npm i -d jsqrhtml <el-button click"$refs.input.click()">识别</el-button> <input type"file" style"display: none" id"input" input"upload">js import jsQR from "jsqr";decodeQR…...
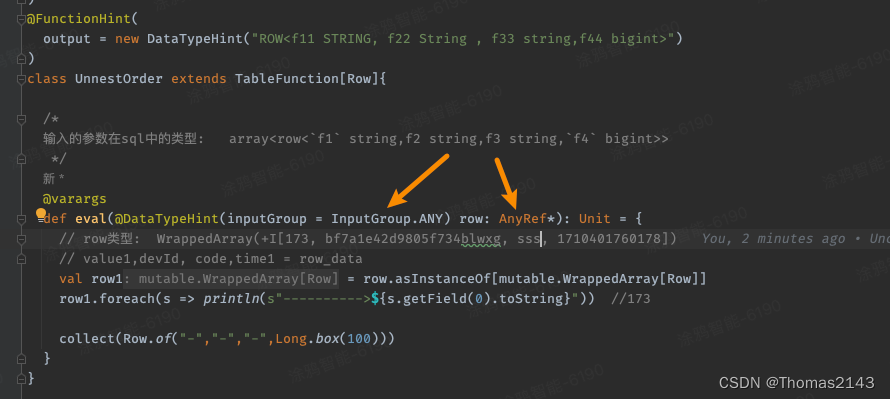
flink1.18.0 自定义函数 接收row类型的参数
比如sql中某字段类型 array<row<f1 string,f2 string,f3 string,f4 bigint>> 现在需要编写 tableFunction 需要接受的参数如上 解决方案 用户定义函数|阿帕奇弗林克 --- User-defined Functions | Apache Flink...
JDK8和JDK11在Ubuntu18上切换(解决nvvp启动报错)
本文主要介绍JDK8和JDK11在Ubuntu18上切换,以供读者能够理解该技术的定义、原理、应用。 🎬个人简介:一个全栈工程师的升级之路! 📋个人专栏:计算机杂记 🎀CSDN主页 发狂的小花 🌄人…...
基于eleiment-plus的表格select控件
控件不是我写的,来源于scui,但在使用中遇到了一些问题,希望能把过程记录下来,同时把这个问题修复掉。 在使用的时候对控件进行二级封装,比如我的一个商品组件,再很多地方可以用到,于是 <template>&l…...

③ AI副业第一步:如何找到适合自己的AI赚钱赛道
③ AI副业第一步:如何找到适合自己的AI赚钱赛道选对赛道,努力才有意义。选错赛道,越努力离钱越远。前言:为什么大多数人AI副业做不起来? 我观察了100想做AI副业的人,失败的原因高度一致: 失败路…...

古戏台构件声学特性的时域有限差分方法【附模型】
✨ 长期致力于时域有限差分法、窑洞、戏台、八字墙、共形技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)曲面共形网格快速生成算法: …...

AArch64内存管理:MAIR_EL3寄存器详解与应用
1. AArch64内存管理基础与MAIR_EL3寄存器定位 在Armv8-A/v9-A架构中,内存管理单元(MMU)通过多级页表实现虚拟地址到物理地址的转换。当处理器执行内存访问时,MMU会遍历页表条目(Translation Table Entry),其中包含两个关键信息:目…...

OpenClaw 连接阿里云百炼图文教程
OpenClaw 连接阿里云百炼图文教程 前置准备 已安装并可以正常打开 OpenClaw Windows。 OpenClaw 顶部 Gateway 状态保持在线。 已准备好可正常登录的阿里云账号。 可以正常访问阿里云百炼登录地址:https://bailian.console.aliyun.com/cn-beijing#/home 建议提…...

内网环境下Win7系统批量离线补丁部署实战指南
1. 内网Win7补丁部署的挑战与解决方案老旧Win7系统在内网环境中的安全隐患就像漏雨的屋顶,看似不影响日常使用,但随时可能引发严重后果。我经手过几十家单位的系统加固项目,发现这些场景存在三个典型痛点:首先是补丁来源问题&…...

量子软件测试的挑战与优化策略
1. 量子软件测试的挑战与机遇量子计算正在从实验室走向实际应用,随之而来的是对可靠量子软件的需求激增。与传统软件不同,量子程序面临三大独特挑战:首先,量子态的叠加性和纠缠性使得测试变得异常复杂。一个n量子比特系统可以同时…...

ARM PMU性能监控单元原理与实践指南
1. ARM PMU性能监控单元概述性能监控单元(PMU)是现代ARM处理器中用于硬件级性能分析的核心组件。它通过一组可编程的硬件计数器,实现对处理器内部各种关键事件的精确测量。这些事件涵盖了从指令执行、缓存访问到内存子系统行为等处理器活动的…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

0.2毫秒快速启动的操作系统
在工业控制以及航空航天等核心场景,极速启动就是高可靠系统的生命线。0.2毫秒超快启动搭配硬件看门狗,让设备在掉电重启、异常恢复时瞬时归位,关键任务永不延误! https://www.bilibili.com/video/BV11mLY6VERt/?spm_id_from333.1…...

为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队用DeepSeek生成方案仍需人工重写?揭秘缺失的2个元认知层与1套校验协议 当团队将DeepSeek-R1或DeepSeek-VL模型用于技术方案生成时,表面看响应迅速、逻辑连贯&…...