java:Druid工具类解析sql获取表名
java:Druid工具类解析sql获取表名
1 前言
alibaba的druid连接池除了sql执行的功能外,还有sql语法解析的工具提供,参考依赖如下:
<dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.2.15</version>
</dependency>
2 使用
参考druid的工具类:com.alibaba.druid.sql.parser.SQLParserUtils#getTables(String sql, DbType dbType)方法,可以用于获取sql的表名:
比如针对mysql的select语句:
package com.xiaoxu.parser;import com.alibaba.druid.DbType;
import com.alibaba.druid.sql.parser.SQLParserUtils;import java.util.List;/*** @author xiaoxu* @date 2024-03-11* java_demo2:com.xiaoxu.parser.SQLParserTest*/
public class SQLParserTest {public static void main(String[] args) {List<String> tables = SQLParserUtils.getTables("select * from my_fuitrs_99 where id = ?", DbType.mysql);System.out.println(tables);String nihao_99 = "select * from my_fuitrs_99 where id = ?".replace(tables.get(0), "my_fuitrs");System.out.println(nihao_99);}}
执行结果如下:

该方法的本质是根据自定义的hash值,对于每个标识符,能唯一生成一个hashCode,将标识符与存入map中的标识符来比对。比如当lexer.token获取的是com.alibaba.druid.sql.parser.Token类中的FROM(“FROM”)时,先执行lexer.nextToken()方法调用,获取到用户自定义的from后续的标识符(from关键字后续跟着的空格等字符会跳过),判断在没有获取到,则将其置为:Token.IDENTIFIER,表示用户自定义的identifier标识符。如下 keywords.getKeyword(hashLCase) 如果获取的标识符不存在,则将判断为用户自定义的标识符。
参考com.alibaba.druid.sql.parser.Lexer的scanIdentifier()方法:
public void scanIdentifier() {this.hashLCase = 0;this.hash = 0;final char first = ch;if (ch == '`') {mark = pos;bufPos = 1;char ch;int startPos = pos + 1;int quoteIndex = text.indexOf('`', startPos);if (quoteIndex == -1) {throw new ParserException("illegal identifier. " + info());}hashLCase = 0xcbf29ce484222325L;hash = 0xcbf29ce484222325L;for (int i = startPos; i < quoteIndex; ++i) {ch = text.charAt(i);hashLCase ^= ((ch >= 'A' && ch <= 'Z') ? (ch + 32) : ch);hashLCase *= 0x100000001b3L;hash ^= ch;hash *= 0x100000001b3L;}stringVal = MySqlLexer.quoteTable.addSymbol(text, pos, quoteIndex + 1 - pos, hash);//stringVal = text.substring(mark, pos);pos = quoteIndex + 1;this.ch = charAt(pos);token = Token.IDENTIFIER;return;}final boolean firstFlag = isFirstIdentifierChar(first);if (!firstFlag) {throw new ParserException("illegal identifier. " + info());}hashLCase = 0xcbf29ce484222325L;hash = 0xcbf29ce484222325L;hashLCase ^= ((ch >= 'A' && ch <= 'Z') ? (ch + 32) : ch);hashLCase *= 0x100000001b3L;hash ^= ch;hash *= 0x100000001b3L;mark = pos;bufPos = 1;char ch = 0;for (; ; ) {char c0 = ch;ch = charAt(++pos);if (!isIdentifierChar(ch)) {if ((ch == '(' || ch == ')') && c0 > 256) {bufPos++;continue;}break;}hashLCase ^= ((ch >= 'A' && ch <= 'Z') ? (ch + 32) : ch);hashLCase *= 0x100000001b3L;hash ^= ch;hash *= 0x100000001b3L;bufPos++;continue;}this.ch = charAt(pos);if (bufPos == 1) {switch (first) {case '(':token = Token.LPAREN;return;case ')':token = Token.RPAREN;return;default:break;}token = Token.IDENTIFIER;stringVal = CharTypes.valueOf(first);if (stringVal == null) {stringVal = Character.toString(first);}return;}Token tok = keywords.getKeyword(hashLCase);if (tok != null) {token = tok;if (token == Token.IDENTIFIER) {stringVal = SymbolTable.global.addSymbol(text, mark, bufPos, hash);} else {stringVal = null;}} else {token = Token.IDENTIFIER;stringVal = SymbolTable.global.addSymbol(text, mark, bufPos, hash);}
}
获取表名的工具类方法:
public static List<String> getTables(String sql, DbType dbType) {Set<String> tables = new LinkedHashSet<>();boolean set = false;Lexer lexer = createLexer(sql, dbType);lexer.nextToken();SQLExprParser exprParser;switch (dbType) {case odps:exprParser = new OdpsExprParser(lexer);break;case mysql:exprParser = new MySqlExprParser(lexer);break;default:exprParser = new SQLExprParser(lexer);break;}for_:for (; lexer.token != Token.EOF; ) {switch (lexer.token) {case CREATE:case DROP:case ALTER:set = false;lexer.nextToken();if (lexer.token == Token.TABLE) {lexer.nextToken();if (lexer.token == Token.IF) {lexer.nextToken();if (lexer.token == Token.NOT) {lexer.nextToken();}if (lexer.token == Token.EXISTS) {lexer.nextToken();}}SQLName name = exprParser.name();tables.add(name.toString());if (lexer.token == Token.AS) {lexer.nextToken();}}continue for_;case FROM:case JOIN:lexer.nextToken();if (lexer.token != Token.LPAREN&& lexer.token != Token.VALUES) {SQLName name = exprParser.name();tables.add(name.toString());}continue for_;case SEMI:set = false;break;case SET:set = true;break;case EQ:if (set && dbType == DbType.odps) {lexer.nextTokenForSet();continue for_;}break;default:break;}lexer.nextToken();}return new ArrayList<>(tables);
}
比如上述的from关键字,当执行完lexer.nextToken()方法后,lexer.stringVal()方法即可以通过字符串的头尾下标切割字符串并返回该标识符,比如表名,也就是我们自定义的标识符。同时关注源码逻辑可知,数据库的表名,druid工具类会将大写字符、小写字符(大写字母A-Z的ASCII码值范围是65-90,而小写字母的ASCII码值范围是97-122,在大写字母的ASCII码值上+32即可转换成小写字母)判定为标识符,同时druid在处理时,除了大小写字母外,下划线(_)、美元符号($)、数字(0-9,ASCII码值范围是48-57)等等,均可判定为标识符。
修改表名含有大写字母,如下获取sql的表名:
List<String> tables = SQLParserUtils.getTables("select * from my_fuitrs_99 where id = ?", DbType.mysql);
System.out.println(tables);
String nihao_99 = "select * from my_fuitrs_99 where id = ?".replace(tables.get(0), "my_fuitrs");
System.out.println(nihao_99);
List<String> tables2 = SQLParserUtils.getTables("select * from MY_fuitrs_99 where id = ?", DbType.mysql);
System.out.println(tables2);
重新执行执行结果如下:
[my_fuitrs_99]
select * from my_fuitrs where id = ?
[MY_fuitrs_99]
3 举一反三
那么我们可以根据上面的工具,简单自定义实现一个替换sql表名的工具,工具类如下:
SQLParserUtil:
package com.xiaoxu.parser;import com.alibaba.druid.DbType;
import com.alibaba.druid.sql.ast.SQLName;
import com.alibaba.druid.sql.dialect.mysql.parser.MySqlExprParser;
import com.alibaba.druid.sql.dialect.mysql.parser.MySqlLexer;
import com.alibaba.druid.sql.parser.Lexer;
import com.alibaba.druid.sql.parser.SQLExprParser;
import com.alibaba.druid.sql.parser.SQLParserFeature;
import com.alibaba.druid.sql.parser.Token;
import org.springframework.lang.Nullable;
import org.springframework.util.StringUtils;/*** @author xiaoxu* @date 2024-03-12* java_demo2:com.xiaoxu.parser.SQLParserUtil*/
@SuppressWarnings("all")
public class SQLParserUtil {public static String getSqlFromReplaceNameIfNeccessary(String sql, DbType dbType, @Nullable String replaceTableName) {String table = null;String newSql = sql;Lexer lexer = createLexer(sql, dbType);lexer.nextToken();SQLExprParser exprParser;switch (dbType) {case mysql:exprParser = new MySqlExprParser(lexer);break;default:exprParser = new SQLExprParser(lexer);break;}for_:for (; lexer.token() != Token.EOF; ) {switch (lexer.token()) {case FROM:case INTO:lexer.nextToken();if (lexer.token() != Token.LPAREN && lexer.token() != Token.VALUES) {if (StringUtils.hasText(replaceTableName)) {int mark = ((MLexer) lexer).getMark();int bufPoss = ((MLexer) lexer).getBufPos();StringBuilder sbd = new StringBuilder();sbd.append(sql.substring(0, mark));sbd.append(replaceTableName);sbd.append(sql.substring(mark + bufPoss));newSql = sbd.toString();}SQLName name = exprParser.name();table = name.toString();}break for_;default:break;}lexer.nextToken();}System.out.println("原本的表名:" + table);System.out.println("替换表名为:" + replaceTableName + "后的sql:" + newSql);return newSql;}public static Lexer createLexer(String sql, DbType dbType) {return createLexer(sql, dbType, new SQLParserFeature[0]);}public static Lexer createLexer(String sql, DbType dbType, SQLParserFeature... features) {if (dbType == null) {dbType = DbType.mysql;}switch (dbType) {case mysql:return new MLexer(sql);default:return new Lexer(sql, null, dbType);}}private static class MLexer extends MySqlLexer {public MLexer(char[] input, int inputLength, boolean skipComment) {super(input, inputLength, skipComment);}public MLexer(String input) {super(input);}public MLexer(String input, SQLParserFeature... features) {super(input, features);}public MLexer(String input, boolean skipComment, boolean keepComments) {super(input, skipComment, keepComments);}public int getBufPos() {return this.bufPos;}public int getMark() {return this.mark;}}}
测试下我们自定义的SQLParserUtil工具类:
package com.xiaoxu.parser;import com.alibaba.druid.DbType;/*** @author xiaoxu* @date 2024-03-12* java_demo2:com.xiaoxu.parser.SQLParserTest2*/
public class SQLParserTest2 {public static void main(String[] args) {String sql = SQLParserUtil.getSqlFromReplaceNameIfNeccessary("select * from my_fruits_99 where id = ?",DbType.mysql, "xiaoxu_88");System.out.println(sql);System.out.println("\n");String sql2 = SQLParserUtil.getSqlFromReplaceNameIfNeccessary("insert into apple_$66 values()",DbType.mysql, "Pear$_88");System.out.println(sql2);}}
执行结果如下:

可以看到,上面工具针对扫描到标识符为FROM(比如select * from语句)或者INTO(比如insert into语句)时,可以实现替换sql的表名功能,其余类似功能参考druid的工具类自行实现即可。
再来举个栗子,新增方法getSqlInHoldCountIfNeccessary如下:
package com.xiaoxu.parser;import com.alibaba.druid.DbType;
import com.alibaba.druid.sql.ast.SQLName;
import com.alibaba.druid.sql.dialect.mysql.parser.MySqlExprParser;
import com.alibaba.druid.sql.dialect.mysql.parser.MySqlLexer;
import com.alibaba.druid.sql.parser.Lexer;
import com.alibaba.druid.sql.parser.SQLExprParser;
import com.alibaba.druid.sql.parser.SQLParserFeature;
import com.alibaba.druid.sql.parser.Token;
import com.google.common.collect.Lists;
import org.springframework.lang.Nullable;
import org.springframework.util.StringUtils;import java.util.List;/*** @author xiaoxu* @date 2024-03-12* java_demo2:com.xiaoxu.parser.SQLParserUtil*/
@SuppressWarnings("all")
public class SQLParserUtil {public static String getSqlInHoldCountIfNeccessary(String sql, DbType dbType, @Nullable Integer[] count) {StringBuilder tempSql = new StringBuilder();Lexer lexer = createLexer(sql, dbType);lexer.nextToken();int posInc = 0;int startPos = 0;int endPos = 0;int subStartPos = 0;for_:for (; lexer.token() != Token.EOF; ) {switch (lexer.token()) {case IN:lexer.nextToken();startPos = endPos;endPos = ((MLexer) lexer).getPos();if (lexer.token() == Token.LPAREN) {tempSql.append(sql, startPos, endPos);subStartPos = endPos;do {endPos = ((MLexer) lexer).getPos();lexer.nextToken();} while (lexer.token() != Token.RPAREN);String replaceMent = sql.substring(subStartPos, endPos);if (count != null && count.length > posInc && count[posInc] != null && count[posInc] > 0) {List<String> incStrs = Lists.newArrayList();for (int i = 0; i < count[posInc]; i++) {incStrs.add("?");}tempSql.append(String.join(",", incStrs));} else {tempSql.append(replaceMent);}posInc++;}continue for_;default:break;}lexer.nextToken();}tempSql.append(sql.substring(endPos));return tempSql.toString();}public static String getSqlFromReplaceNameIfNeccessary(String sql, DbType dbType, @Nullable String replaceTableName) {String table = null;String newSql = sql;Lexer lexer = createLexer(sql, dbType);lexer.nextToken();SQLExprParser exprParser;switch (dbType) {case mysql:exprParser = new MySqlExprParser(lexer);break;default:exprParser = new SQLExprParser(lexer);break;}for_:for (; lexer.token() != Token.EOF; ) {switch (lexer.token()) {case FROM:case INTO:lexer.nextToken();if (lexer.token() != Token.LPAREN && lexer.token() != Token.VALUES) {if (StringUtils.hasText(replaceTableName)) {int mark = ((MLexer) lexer).getMark();int bufPoss = ((MLexer) lexer).getBufPos();StringBuilder sbd = new StringBuilder();sbd.append(sql.substring(0, mark));sbd.append(replaceTableName);sbd.append(sql.substring(mark + bufPoss));newSql = sbd.toString();}SQLName name = exprParser.name();table = name.toString();}break for_;default:break;}lexer.nextToken();}System.out.println("原本的表名:" + table);System.out.println("替换表名为:" + replaceTableName + "后的sql:" + newSql);return newSql;}public static Lexer createLexer(String sql, DbType dbType) {return createLexer(sql, dbType, new SQLParserFeature[0]);}public static Lexer createLexer(String sql, DbType dbType, SQLParserFeature... features) {if (dbType == null) {dbType = DbType.mysql;}switch (dbType) {case mysql:return new MLexer(sql);default:return new Lexer(sql, null, dbType);}}private static class MLexer extends MySqlLexer {public MLexer(char[] input, int inputLength, boolean skipComment) {super(input, inputLength, skipComment);}public MLexer(String input) {super(input);}public MLexer(String input, SQLParserFeature... features) {super(input, features);}public MLexer(String input, boolean skipComment, boolean keepComments) {super(input, skipComment, keepComments);}public int getBufPos() {return this.bufPos;}public int getMark() {return this.mark;}public int getPos() {return this.pos;}}}
getSqlInHoldCountIfNeccessary方法的效果是,我们知道在mysql的子查询IN中,假设一个sql有多处具有子查询IN,假定为:in (?)。但是我们需要自定义IN子查询后续的参数个数,意即类似更新sql的子查询参数数目为in (?,?,?),同时不改变原有sql的语句,那么通过我们自定义的该方法可以达到效果,测试如下:
package com.xiaoxu.parser;import com.alibaba.druid.DbType;/*** @author xiaoxu* @date 2024-03-12* java_demo2:com.xiaoxu.parser.SQLParserTest2*/
public class SQLParserTest2 {public static void main(String[] args) {String sql = SQLParserUtil.getSqlInHoldCountIfNeccessary("select * from my where id in( ?,?) and status is not null and name in (?) and ot ='N' and pr in ()",DbType.mysql, new Integer[]{null, 4});System.out.println("最终结果是:");System.out.println(sql);String sql2 = SQLParserUtil.getSqlInHoldCountIfNeccessary("select * from my where id in (?)",DbType.mysql, new Integer[]{3});System.out.println(sql2);String sql3 = SQLParserUtil.getSqlInHoldCountIfNeccessary("select * from my where id = ?",DbType.mysql, new Integer[]{3});System.out.println(sql3);}}
执行结果如下:

其中参数new Integer[]{null, 4}的效果是,第一个IN子查询不变,第二个子查询更新为in (?,?,?,?)。该逻辑是按照顺序更新IN的后续参数数目,同时不改变原有的sql。
相关文章:
java:Druid工具类解析sql获取表名
java:Druid工具类解析sql获取表名 1 前言 alibaba的druid连接池除了sql执行的功能外,还有sql语法解析的工具提供,参考依赖如下: <dependency><groupId>com.alibaba</groupId><artifactId>druid</ar…...

MySQL--深入理解MVCC机制原理
什么是MVCC? MVCC全称 Multi-Version Concurrency Control,即多版本并发控制,维持一个数据的多个版本,主要是为了提升数据库的并发访问性能,用更高性能的方式去处理数据库读写冲突问题,实现无锁并发。 什…...

数据挖掘简介与应用领域概述
数据挖掘,作为信息技术领域中的重要分支之一,旨在从大量数据中发现潜在的模式、关联和趋势,以提取有用的信息和知识。在信息爆炸时代,大量数据的积累成为了常态,数据挖掘技术的出现填补了人们处理这些数据的空白&#…...
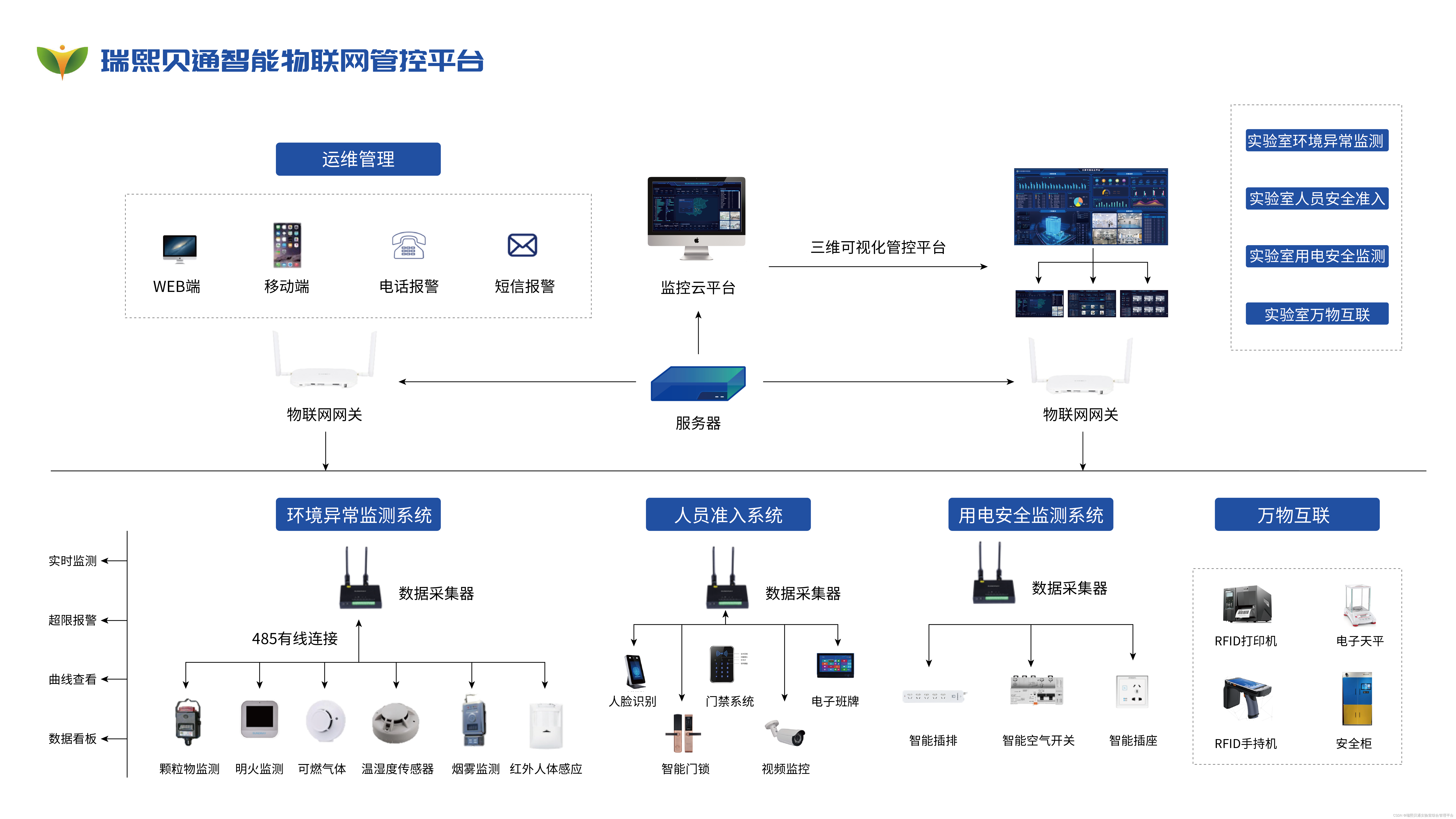
瑞熙贝通打造智慧校园实验室安全综合管理平台
一、建设思路 瑞熙贝通实验室安全综合管理平台是基于以实验室安全,用现代化管理思想与人工智能、大数据、互联网技术、物联网技术、云计算技术、人体感应技术、语音技术、生物识别技术、手机APP、自动化仪器分析技术有机结合,通过建立以实验室为中心的管…...

openstack调整虚拟机CPU 内存 磁盘 --来自gpt
在OpenStack中调整虚拟机(即实例)的CPU、内存(RAM)和磁盘大小通常涉及到以下几个步骤:首先,确定你要修改的实例名称或ID;其次,根据需要调整的资源类型,使用相应的命令进行…...
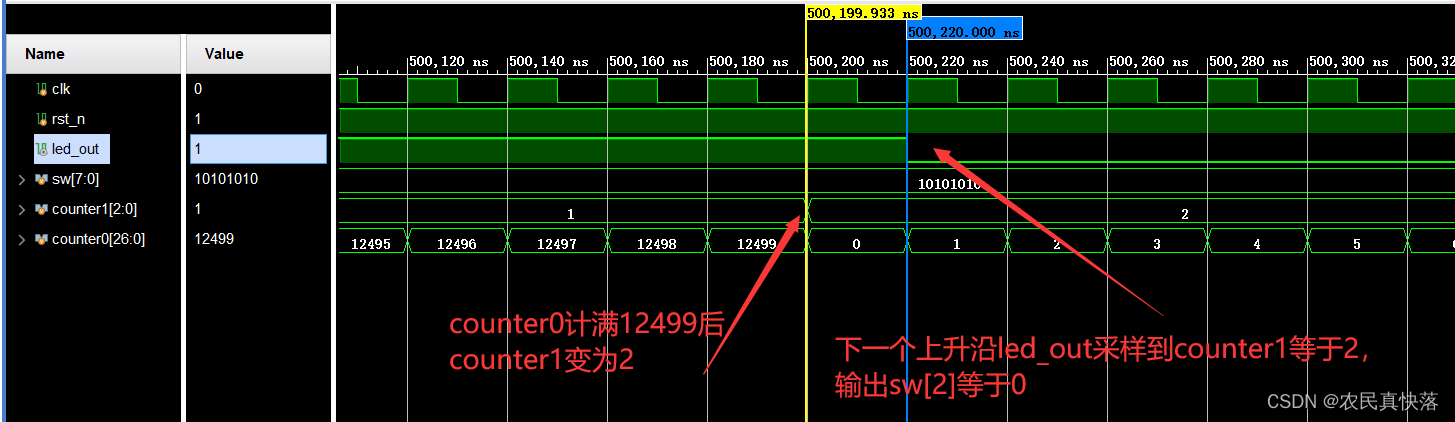
【IC设计】Verilog线性序列机点灯案例(三)(小梅哥课程)
声明:案例和代码来自小梅哥课程,本人仅对知识点做做笔记,如有学习需要请支持官方正版。 文章目录 该系列目录设计目标设计思路RTL及Testbench代码RTL代码Testbench代码 仿真结果上板视频 该系列目录 Verilog线性序列机点灯案例(一)ÿ…...

【打工日常】使用Docker部署团队协作文档工具
一、ShowDoc介绍 ShowDoc是一个适合IT团队共同协作API文档、技术文档的工具。通过showdoc,可以方便地使用markdown语法来书写出API文档、数据字典文档、技术文档、在线excel文档等等。 响应式网页设计:可将项目文档分享到电脑或移动设备查看。同时也可…...
(一)Neo4j下载安装以及初次使用
(一)下载 官网地址:Neo4j Graph Database & AnamConnect data as its stored with Neo4j. Perform powerful, complex queries at scale and speed with our graph data platform.https://neo4j.com/ (二)安装并配…...

QT for Mcu的学习建议
QT for MCU(微控制器单元)是一个相对较新的领域,它允许在资源受限的微控制器上运行Qt框架,从而为嵌入式设备带来丰富的用户界面和跨平台的开发体验。以下是一些建议,可以帮助你开始学习Qt for MCU: 理解Qt…...
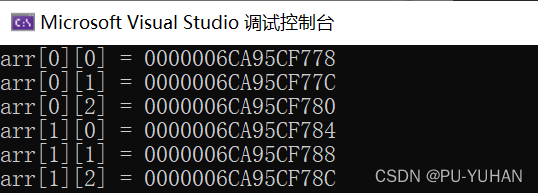
【C语言初阶(五)】数组
❣博主主页: 33的博客❣ ▶文章专栏分类: C语言从入门到精通◀ 🚚我的代码仓库: 33的代码仓库🚚 目录 1. 前言2.一维数组的概念3.一维数组的创建和初始化3.1数组的创建3.2数组的初始化3.3数组的类型 4.一维数组的使用4.1数组下标4.2数组元素打印4.4数组元…...

词令微信小程序怎么添加到我的小程序?
微信小程序怎么添加到我的小程序? 1、找到并打开要添加的小程序; 2、打开小程序后,点击右上角的「…」 3、点击后底部弹窗更多选项,请找到并点击「添加到我的小程序」; 4、添加成功后,就可以在首页下拉我的…...

【PyTorch】基础学习:在Pycharm等IDE中打印或查看Pytorch版本信息
【PyTorch】基础学习:在Pycharm等IDE中打印或查看Pytorch版本信息 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程…...
——南向接口)
SDN网络简单认识(2)——南向接口
目录 一、概述 二、南向接口与南向协议 2.1 南向接口(Southbound Interfaces) 2.2 南向协议(Southbound Protocols) 2.3 区别与联系 三、常见南向协议 2.1 OpenFlow 2.2 OVSDB(Open vSwitch Database Manageme…...
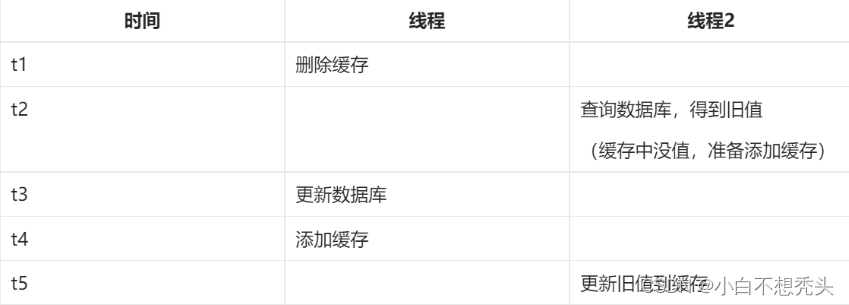
如何保存缓存和MySQL的双写一致呢?
如何保存缓存和MySQL的双写一致呢? 所谓的双写一致指的是,在同时使用缓存(如Redis)和数据库(如MySQL)的场景下,确保数据在缓存和数据库中的更新操作保持一致。当对数据进行修改的时候,无论是先修改缓存还是先修改数据库,最终都要保…...
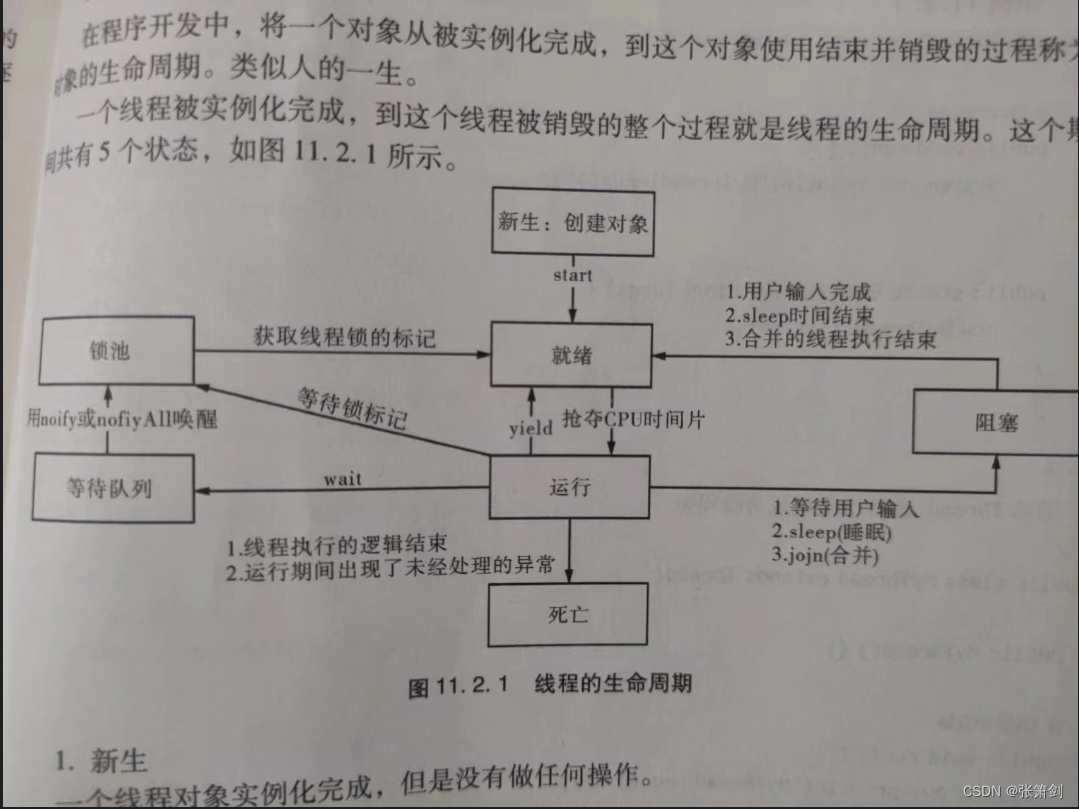
第十三篇:复习Java面向对象
文章目录 一、面向对象的概念二、类和对象1. 如何定义/使用类2. 定义类的补充注意事项 三、面向对象三大特征1. 封装2. 继承2.1 例子2.2 继承类型2.3 继承的特性2.4 继承中的关键字2.4.1 extend2.4.2 implements2.4.3 super/this2.4.4 final 3. 多态4. 抽象类4.1 抽象类4.2 抽象…...
)
PyTorch学习笔记之基础函数篇(四)
文章目录 2.8 torch.logspace函数讲解2.9 torch.ones函数2.10 torch.rand函数2.11 torch.randn函数2.12 torch.zeros函数 2.8 torch.logspace函数讲解 torch.logspace 函数在 PyTorch 中用于生成一个在对数尺度上均匀分布的张量(tensor)。这意味着张量中…...
)
C++/CLI学习笔记3(快速打通c++与c#相互调用的桥梁)
c/cli变量和操作符 3.1:什么是变里 变量是存储数据以便应用程序临时使用的内存位置,具有名称、类型和值。变量值在应用程序执行期间可能改变,变量名也是。变量使用前必须声明,即指定类型和提供名称。变量的类型决定了值的范围以及能执行的操…...
unity
Unity官方下载_Unity最新版_从Unity Hub下载安装 | Unity中国官网 Unity Remote - Unity 手册 登陆账号,找到一个3d 免费资源 3D Animations & Models | Unity Asset Store unity 里面window->package Manager 里面可以看到自己的asset ,下载后…...

考研复习C语言初阶(3)
目录 一.函数是什么? 二.C语言中函数的分类 2.1库函数 2.2自定义函数 三.函数的参数 3.1实际参数(实参) 3.2 形式参数(形参) 四.函数的调用 4.1 传值调用 4.2 传址调用 五. 函数的嵌套调用和链式访问 5.1 嵌套调用 5…...
)
CCF 202009-3 点亮数字人生(拓扑排序)
题目背景 土豪大学的计算机系开了一门数字逻辑电路课,第一个实验叫做“点亮数字人生”,要用最基础的逻辑元件组装出实际可用的电路。时间已经是深夜了,尽管实验箱上密密麻麻的连线已经拆装了好几遍,小君同学却依旧没能让她的电路正…...
:这份内部测试SOP已被3家头部科技公司紧急采购)
DeepSeek-R1补全能力封测倒计时(仅剩72小时开放API灰度权限):这份内部测试SOP已被3家头部科技公司紧急采购
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1代码补全能力封测全景概览 DeepSeek-R1 是深度求索(DeepSeek)推出的高性能开源推理模型,在代码补全场景中展现出显著的上下文理解力与多语言泛化能力。本…...

如何高效批量下载音乐歌词:智能歌词管理完整指南
如何高效批量下载音乐歌词:智能歌词管理完整指南 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX ZonyLrcToolsX 是一款专业的跨平台歌词下载工具,…...

告别浪费!SolidWorks企业级共享方案,实现降本增效全攻略
还在为 SolidWorks 高昂的硬件投入和混乱的图纸管理头疼?告别“一人一机”的浪费模式,企业级共享方案才是降本增效的正解。这套攻略基于“1 台高性能服务器 云飞云共享云桌面”架构,帮你把硬件成本砍掉 60%,把软件利用率翻倍。一…...

2026智慧校园规划必读:如何在预算吃紧下选到高性价比方案
✅作者简介:合肥自友科技 📌核心产品:智慧校园平台(包括教工管理、学工管理、教务管理、考务管理、后勤管理、德育管理、资产管理、公寓管理、实习管理、就业管理、离校管理、科研平台、档案管理、学生平台等26个子平台) 。公司所有人员均有多…...

WarcraftHelper:魔兽争霸III现代兼容性问题的终极解决方案指南
WarcraftHelper:魔兽争霸III现代兼容性问题的终极解决方案指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸III作为经典即时战…...

LangGraph状态机工程:构建复杂AI工作流的完整指南
传统RAG(检索增强生成)在处理简单的"单跳"问题时表现良好——“文章里提到了什么” “这个概念是什么意思”——但当问题涉及多个实体之间的关系、需要跨多个文档推理时,传统RAG就显得力不从心。GraphRAG(Graph-based R…...

探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破
探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破 【免费下载链接】WSA-Windows-10 This is a backport of Windows Subsystem for Android to Windows 10. 项目地址: https://gitcode.com/gh_mirrors/ws/WSA-Windows-10 想象一下&#…...

Unity塔防底层架构:ScriptableObject驱动的数据契约设计
1. 这不是“又一个塔防模板”,而是塔防开发的底层操作系统我第一次在Asset Store点开Tower Defense Toolkit 4(TDTK-4)的预览图时,下意识划走了——界面太“干净”了,没有炫酷的粒子特效演示,没有满屏飞舞的…...

XZ1018,100V,40A,NMOS 封装:TO252
封装:TO252类型:NVDS:100V VGS: 20V ID:40ARDS(ON):10V <14mΩRDS(ON):4.5V <19mΩ型号: XZ1018 封装:TO252类型…...

泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅
泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you cha…...