【Flink SQL】Flink SQL 基础概念(三):SQL 动态表 连续查询
《Flink SQL 基础概念》系列,共包含以下 5 篇文章:
- Flink SQL 基础概念(一):SQL & Table 运行环境、基本概念及常用 API
- Flink SQL 基础概念(二):数据类型
- Flink SQL 基础概念(三):SQL 动态表 & 连续查询
- Flink SQL 基础概念(四):SQL 的时间属性
- Flink SQL 基础概念(五):SQL 时区问题
😊 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 🚀🚀🚀 吧 (点赞 🧡、关注 💛、收藏 💚)!!!您的支持 💖💖💖 将激励 🔥 博主输出更多优质内容!!!
Flink SQL 基础概念(三):SQL 动态表 & 连续查询
- 1.SQL 应用于流处理的思路
- 2.流批处理的异同点及将 SQL 应用于流处理核心解决的问题
- 3.SQL 流处理的输入:输入流映射为 SQL 动态输入表
- 4.SQL 流处理的计算:实时处理底层技术 - SQL 连续查询
- 5.SQL 流处理实际应用:动态表 & 连续查询技术的两个实战案例
- 5.1 查询案例一
- 5.2 查询案例二
- 6.SQL 连续查询的两种类型:更新(Update)查询 & 追加(Append)查询
- 7.SQL 流处理的输出:动态输出表转化为输出数据
- 8.补充知识:SQL 与关系代数
1.SQL 应用于流处理的思路
在流式 SQL 诞生之前,所有的基于 SQL 的数据查询都是基于批数据的,没有将 SQL 应用到流数据处理这一说法。
那么如果我们想将 SQL 应用到流处理中,必然要站在巨人的肩膀(批数据处理的流程)上面进行,那么具体的分析思路如下:
- 1️⃣ 先比较 批处理 与 流处理 的异同之处:如果有相同的部分,那么可以直接复用;不同之处才是我们需要重点克服和关注的。
- 2️⃣ 摘出 1️⃣ 中说到的不同之处,分析如果要满足这个不同之处,目前有哪些技术是类似的。
- 3️⃣ 再从这些类似的技术上进一步发展,以满足将 SQL 应用于流任务中。
博主下文就会根据上述三个步骤来一步一步介绍 动态表 诞生的背景以及这个概念是如何诞生的。
2.流批处理的异同点及将 SQL 应用于流处理核心解决的问题
首先对比一下常见的 批处理 和 流处理 中 数据源(输入表)、处理逻辑、数据汇(结果表)的异同点。
| | | | |
|---|---|---|---|
| 批处理 | 静态表:输入数据有限、是有界集合 | 批式计算:每次执行查询能够访问到完整的输入数据,然后计算,输出完整的结果数据 | 静态表:数据有限 |
| 流处理 | 动态表:输入数据无限,数据实时增加,并且源源不断 | 流式计算:执行时不能够访问到完整的输入数据,每次计算的结果都是一个中间结果 | 动态表:数据无限 |
对比上述流批处理之后,我们得到了要将 SQL 应用于流式任务的三个要解决的核心点:
- 1️⃣ SQL 输入表:分析如何将一个实时的,源源不断的输入流数据表示为 SQL 中的输入表。
- 2️⃣ SQL 处理计算:分析将 SQL 查询逻辑翻译成什么样的底层处理技术才能够实时的处理流式输入数据,然后产出流式输出数据。
- 3️⃣ SQL 输出表:分析如何将 SQL 查询输出的源源不断的流数据表示为一个 SQL 中的输出表。
将上面 3 个点总结一下,也就引出了本节的 动态表 和 连续查询 两种技术方案:
- 动态表:源源不断的输入、输出流数据映射到动态表。
- 连续查询:实时处理输入数据,产出输出数据的实时处理技术。
3.SQL 流处理的输入:输入流映射为 SQL 动态输入表
动态表。这里的动态其实是相比于批处理的静态(有界)来说的。
- 静态表:应用于批处理数据中,静态表可以理解为是不随着时间实时进行变化的。一般都是一天、一小时的粒度新生成一个分区。
- 动态表:动态表是随时间实时进行变化的。是将 SQL 体系中表的概念应用到 Flink 上面的的核心点。
来看一个具体的案例,下图显示了点击事件流(左侧)如何转换为动态表(右侧)。当数据源生成更多的点击事件记录时,映射出来的动态表也会不断增长,这就是动态表的概念:

4.SQL 流处理的计算:实时处理底层技术 - SQL 连续查询
部分高级关系数据库系统提供了一个称为 物化视图(Materialized Views)的特性。
物化视图其实就是一条 SQL 查询,就像常规的虚拟视图 VIEW 一样。但与虚拟视图不同的是,物化视图会缓存查询的结果,因此在请求访问视图时不需要对查询进行重新计算,可以直接获取物化视图的结果,小伙伴萌可以认为物化视图其实就是把结果缓存了下来。
举个例子:批处理中,如果以 Hive 天级别的物化视图来说,其实就是每天等数据源准备好之后,调度物化视图的 SQL 执行然后产生新的结果提供服务。那么就可以认为一条表示了输入、处理、输出的 SQL 就是一个构建物化视图的过程。
映射到我们的流任务中,输入、处理逻辑、输出这一套流程也是一个物化视图的概念。相比批处理来说,流处理中,我们的数据源表的数据是源源不断的。那么从输入、处理、输出的整个物化视图的维护流程也必须是实时的。
因此我们就需要引入一种 实时视图维护(Eager View Maintenance)的技术去做到:一旦更新了物化视图的数据源表就立即更新视图的结果,从而保证输出的结果也是最新的。
这种实时视图维护的技术就叫做 连续查询(Continuous Query)。
注意:
- 连续查询 不断的消费动态输入表的的数据,不断的更新动态结果表的数据。
- 连续查询 的产出的结果 = = = 批处理模式在输入表的上执行的相同查询的结果。相同的 SQL,对应于同一个输入数据,虽然执行方式不同,但是流处理和批处理的结果是永远都会相同的。
5.SQL 流处理实际应用:动态表 & 连续查询技术的两个实战案例
动态表 & 连续查询 两项技术在一条流 SQL 中的执行流程总共包含了三个步骤,如下图及总结所示:

- 1️⃣ 将数据输入流转换为 SQL 中的动态输入表。这里的转化其实就是指将输入流映射(绑定)为一个动态输入表。上图虽然分开画了,但是可以理解为一个东西。
- 2️⃣ 在动态输入表上执行一个连续查询,然后生成一个新的动态结果表。
- 3️⃣ 生成的动态结果表被转换回数据输出流。
我们实际介绍一个案例来看看其运行方式,以上文介绍到的点击事件流为例,点击事件流数据的字段如下:
[user: VARCHAR, // 用户名cTime: TIMESTAMP, // 访问 URL 的时间url: VARCHAR // 用户访问的 URL
]
第一步,将输入数据流映射为一个动态输入表。以下图为例,我们将点击事件流(图左)转换为动态表(图右)。当点击数据源源不断的来到时,动态表的数据也会不断的增加。

第二步,在点击事件流映射的动态输入表上执行一个连续查询,并生成一个新的动态输出表。
下面介绍两个查询的案例。
5.1 查询案例一
第一个查询:一个简单的 GROUP BY COUNT 聚合查询,写过 SQL 的都不会陌生吧,这种应该都是最基础,最常用的对数据按照类别分组的方法。
如下图所示 group by 聚合的常用案例。

那么本案例中呢,是基于 clicks 表中 user 字段对 clicks 表(点击事件流)进行分组,来统计每一个 user 的访问的 URL 的数量。下面的图展示了当 clicks 输入表来了新数据(即表更新时),连续查询 的计算逻辑。

当查询开始,clicks 表(左侧)是空的。
- 当第一行数据被插入到
clicks表时,连续查询开始计算结果数据。数据源表第一行数据[Mary,./home]输入后,会计算结果[Mary, 1]插入结果表。 - 当第二行
[Bob, ./cart]插入到clicks表时,连续查询会计算结果[Bob, 1],并插入到结果表。 - 第三行
[Mary, ./prod?id=1]输出时,会计算出[Mary, 2](user为Mary的数据总共来过两条,所以为 2),并更新结果表,[Mary, 1]更新成[Mary, 2]。 - 最后,当第四行数据加入
clicks表时,查询将第三行[Liz, 1]插入结果表中。
注意上述特殊标记出来的字体,可以看到连续查询对于结果的数据输出方式有两种:
- 插入(
insert)结果表 - 更新(
update)结果表
大家对于 插入(insert)结果表这件事都比较好理解,因为离线数据都只有插入这个概念。但是 更新(update)结果表就是离线处理中没有概念了。这就是连续查询中中比较重要一个概念。后文会介绍。
5.2 查询案例二
接下来介绍第二条查询语句。第二条查询与第一条类似,但是 group by 中除了 user 字段之外,还 group by 了 tumble,其代表开了个滚动窗口(后面会详细说明滚动窗口的作用),然后计算 url 数量。
group by user,是按照类别(横向)给数据分组,group by tumble 滚动窗口是按时间粒度(纵向)给数据进行分组。如下图所示。

图形化一解释就很好理解了,两种都是对数据进行分组,一个是按照 类别 分组,另一种是按照 时间 分组。
与前面一样,左边显示了输入表 clicks。查询每小时持续计算结果并更新结果表。clicks 表有三列,user,cTime,url。其中 cTime 代表数据的时间戳,用于给数据按照时间粒度分组。

我们的滚动窗口的步长为 1 小时,即时间粒度上面的分组为 1 小时。其中时间戳在 12:00:00 - 12:59:59 之间有四条数据。13:00:00 - 13:59:59 有三条数据。14:00:00 - 14:59:59 之间有四条数据。
- 当
12:00:00 - 12:59:59数据输入之后,1 小时的窗口,连续查询计算的结果如上图所示,将[Mary, 3],[Bob, 1]插入结果表。 - 当
13:00:00 - 13:59:59数据输入之后,1 小时的窗口,连续查询计算的结果如上图所示,将[Bob, 1],[Liz, 2]插入结果表。 - 当
14:00:00 - 14:59:59数据输入之后,1 小时的窗口,连续查询计算的结果如上图所示,将[Mary, 1],[Bob, 2],[Liz, 1]插入结果表。
而这个查询只有 插入(insert)结果表这个行为。
6.SQL 连续查询的两种类型:更新(Update)查询 & 追加(Append)查询
虽然前一节的两个查询看起来非常相似(都计算分组进行计数聚合),但它们在一个重要方面不同:
- 第一个查询(
group by user),即Update查询:会更新先前输出的结果,即结果表流数据中 包含 INSERT 和 UPDATE 数据。小伙伴萌可以理解为group by user这条语句当中,输入源的数据是一直有的,源源不断的,同一个user的数据之后可能还是会有的,因此可以认为此 SQL 的每次的输出结果都是一个中间结果, 当同一个user下一条数据到来的时候,就要用新结果把上一次的产出中间结果(旧结果)给UPDATE了。所以这就是UPDATE查询的由来(其中INSERT就是第一条数据到来的时候,没有之前的中间结果,所以是INSERT)。 - 第二个查询(
group by user, tumble(xxx)),即Append查询:只追加到结果表,即结果表流数据中 只包含 INSERT 的数据。小伙伴萌可以理解为虽然group by user, tumble(xxx)上游也是一个源源不断的数据,但是这个查询本质上是对时间上的划分,而时间都是越变越大的,当前这个滚动窗口结束之后,后面来的数据的时间都会比这个滚动窗口的结束时间大,都归属于之后的窗口了,当前这个滚动窗口的结果数据就不会再改变了,因此这条查询只有INSERT数据,即一个Append查询。
上面是 Flink SQL 连续查询处理机制上面的两类查询方式。我们可以发现连续查询的处理机制不一样,产出到结果表中的结果数据也是不一样的。针对上面两种结果表的更新方式,Flink SQL 提出了 changelog 表的概念来进行兼容。
changelog 表这个概念其实就和 MySQL binlog 是一样的。会包含 INSERT、UPDATE、DELETE 三种数据,通过这三种数据的处理来描述实时处理技术对于动态表的变更:
changelog表:即第一个查询的输出表,输出结果数据不但会追加,还会发生更新。changelog insert-only表:即第二个查询的输出表,输出结果数据只会追加,不会发生更新。
7.SQL 流处理的输出:动态输出表转化为输出数据
可以看到我们的标题都是随着一个 SQL 的生命周期的。从 输入流映射为 SQL 动态输入表、实时处理底层技术 - SQL 连续查询 到本小节的 SQL 动态输出表转化为输出数据。都是有逻辑关系的。
我们上面介绍到了连续查询的输出结果表是一个 changelog。其可以像普通数据库表一样通过 INSERT、UPDATE 和 DELETE 来不断修改。
它可能是一个只有一行、不断更新 changelog 表,也可能是一个 insert-only 的 changelog 表,没有 UPDATE 和 DELETE 修改,或者介于两者之间的其他表。
在将动态表转换为流或将其写入外部系统时,需要对这些不同状态的数据进行编码。Flink 的 Table API 和 SQL API 支持三种方式来编码一个动态表的变化:
- 1️⃣ Append-only 流:输出的结果只有
INSERT操作的数据。 - 2️⃣ Retract 流:
- Retract 流包含两种类型的 message:
add messages和retract messages。其将INSERT操作编码为add message、将DELETE操作编码为retract message、将UPDATE操作编码为更新先前行的retract message和更新新行的add message,从而将动态表转换为 Retract 流。 - Retract 流写入到输出结果表的数据如下图所示,有
-,+两种,分别-代表撤回旧数据,+代表输出最新的数据。这两种数据最终都会写入到输出的数据引擎中。 - 如果下游还有任务去消费这条流的话,要注意需要正确处理
-,+两种数据,防止数据计算重复或者错误。
- Retract 流包含两种类型的 message:

- 3️⃣ Upsert 流:
- Upsert 流包含两种类型的 message:
upsert messages和delete messages。转换为 Upsert 流的动态表需要唯一键(唯一键可以由多个字段组合而成)。其会将INSERT和UPDATE操作编码为upsert message,将DELETE操作编码为delete message。 - Upsert 流写入到输出结果表的数据如下图所示,每次输出的结果都是当前每一个
user的最新结果数据,不会有 Retract 中的-回撤数据。 - 如果下游还有一个任务去消费这条流的话,消费流的算子需要知道唯一键(即
user),以便正确地根据唯一键(user)去拿到每一个user当前最新的状态。其与 Retract 流的主要区别在于UPDATE操作是用单个 message 编码的,因此效率更高。下图显示了将动态表转换为 Upsert 流的过程。
- Upsert 流包含两种类型的 message:

8.补充知识:SQL 与关系代数
小伙伴萌会问到,关系代数是啥东西?
其实关系代数就是对于数据集(即表)的一系列的 操作(即查询语句)。常见关系代数有:

那么 SQL 和关系代数是啥关系呢?
SQL 就是能够表示关系代数一种面向用户的接口:即 用户能使用 SQL 表达关系代数的处理逻辑,也就是我们可以用 SQL 去在表(数据集)上执行我们的业务逻辑操作(关系代数操作)。
相关文章:
【Flink SQL】Flink SQL 基础概念(三):SQL 动态表 连续查询
《Flink SQL 基础概念》系列,共包含以下 5 篇文章: Flink SQL 基础概念(一):SQL & Table 运行环境、基本概念及常用 APIFlink SQL 基础概念(二):数据类型Flink SQL 基础概念&am…...

科研绘图一:箱线图(添加贝赛尔曲线)
R语言绘图系列—箱线图贝赛尔曲线 (一): 科研绘图一:箱线图(添加贝赛尔曲线) 文章目录 R语言绘图系列---箱线图贝赛尔曲线(一): 科研绘图一:箱线图(添加贝赛尔曲线&…...

最佳实践:Swagger 自动生成 Api 文档
自动生成 API 文档的好处不言而喻,它可以提供给你的团队或者外部协作者,方便 API 使用者准确地调用到你的 API。为了降低手动编写文档带来的错误,很多 API 开发者会偏向于寻找一些好的方法来自动生成 API 文档。本文将会介绍一些常用的文档生…...

搬砖。。。
0搬砖 - 蓝桥云课 (lanqiao.cn) 问题描述 这天,小明在搬砖 他一共有n块砖他发现第砖的重量为w价值为i。他突然想从这些砖中选一些出来从下到上堆成一座塔,并且对于塔中的每一块砖来说,它上面所有砖的重量和不能超过它自身的价值。 他想知道这样堆成的塔的…...
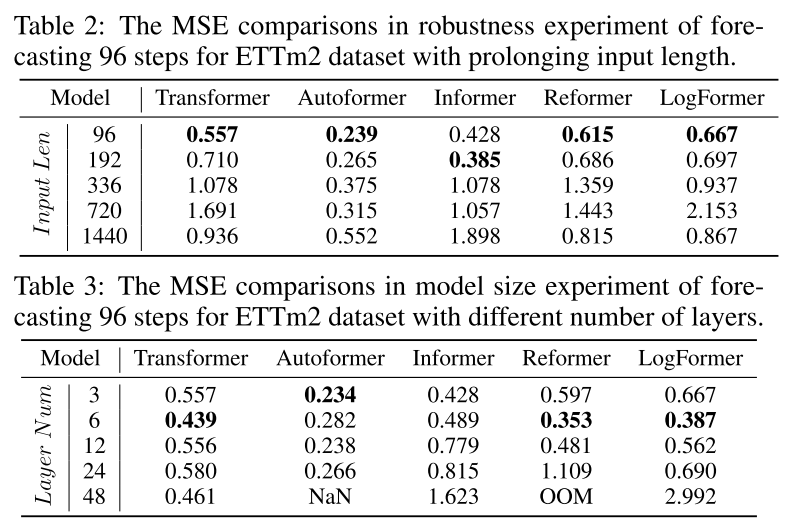
【论文笔记合集】Transformers in Time Series A Survey综述总结
本文作者: slience_me 文章目录 Transformers in Time Series A Survey综述总结1 Introduction2 Transformer的组成Preliminaries of the Transformer2.1 Vanilla Transformer2.2 输入编码和位置编码 Input Encoding and Positional Encoding绝对位置编码 Absolute …...

HarmonyOS(二十)——管理应用拥有的状态之LocalStorage(页面级UI状态存储)
LocalStorage是页面级的UI状态存储,通过Entry装饰器接收的参数可以在页面内共享同一个LocalStorage实例。LocalStorage也可以在UIAbility实例内,在页面间共享状态。 本文仅介绍LocalStorage使用场景和相关的装饰器:LocalStorageProp和LocalS…...
Linux系统安全②SNAT与DNAT
目录 一.SNAT 1.定义 2.实验环境准备 (1)三台服务器:PC1客户端、PC2网关、PC3服务端。 (2)硬件要求:PC1和PC3均只需一块网卡、PC2需要2块网卡 (3)网络模式要求:PC1…...
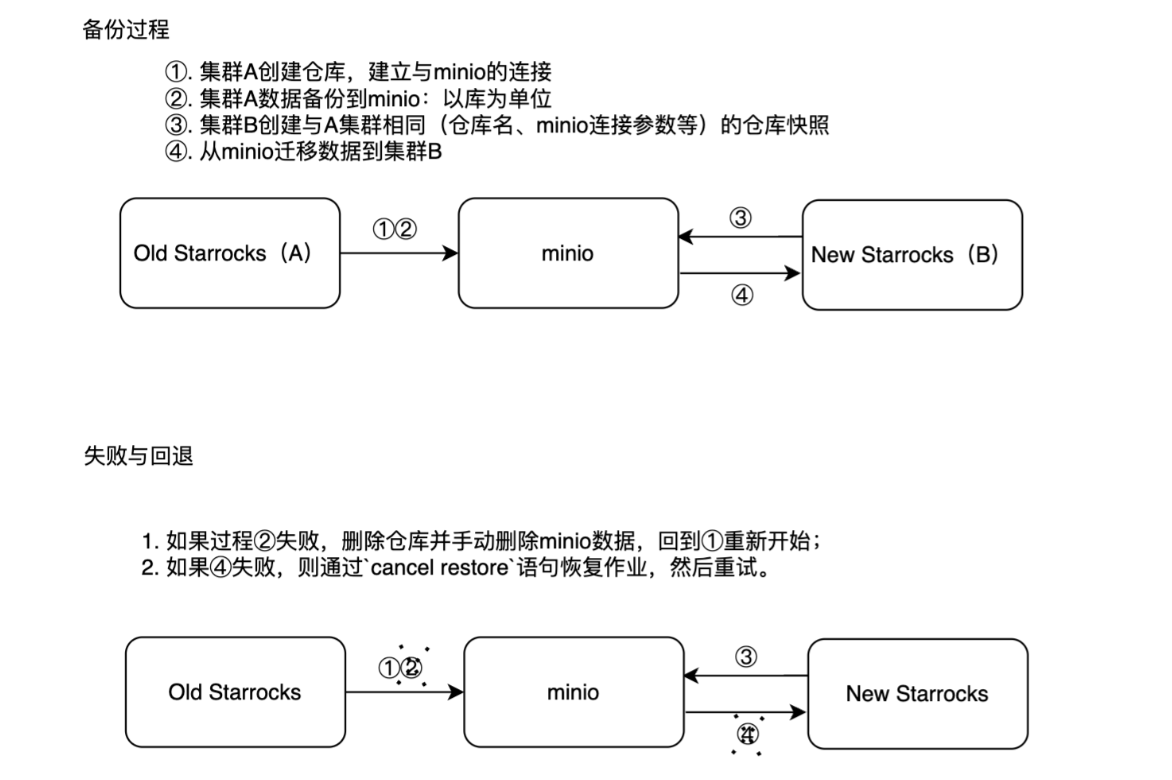
【运维】StarRocks数据迁移到新集群(针对于集群互通、不互通的情况)
文章目录 一. 迁移整体思路1. 对于新旧集群互通的情况2. 对于新旧集群不互通的情况二、迁移过程(两个集群互通的情况)1. 备份过程1.1. 通过mysqlclient与starrocks进行关联1.2. 创建仓库与minio建立联系1.3. 备份数据到minio2. 迁移过程2.1. 通过mysqlclient与starrocks进行关…...
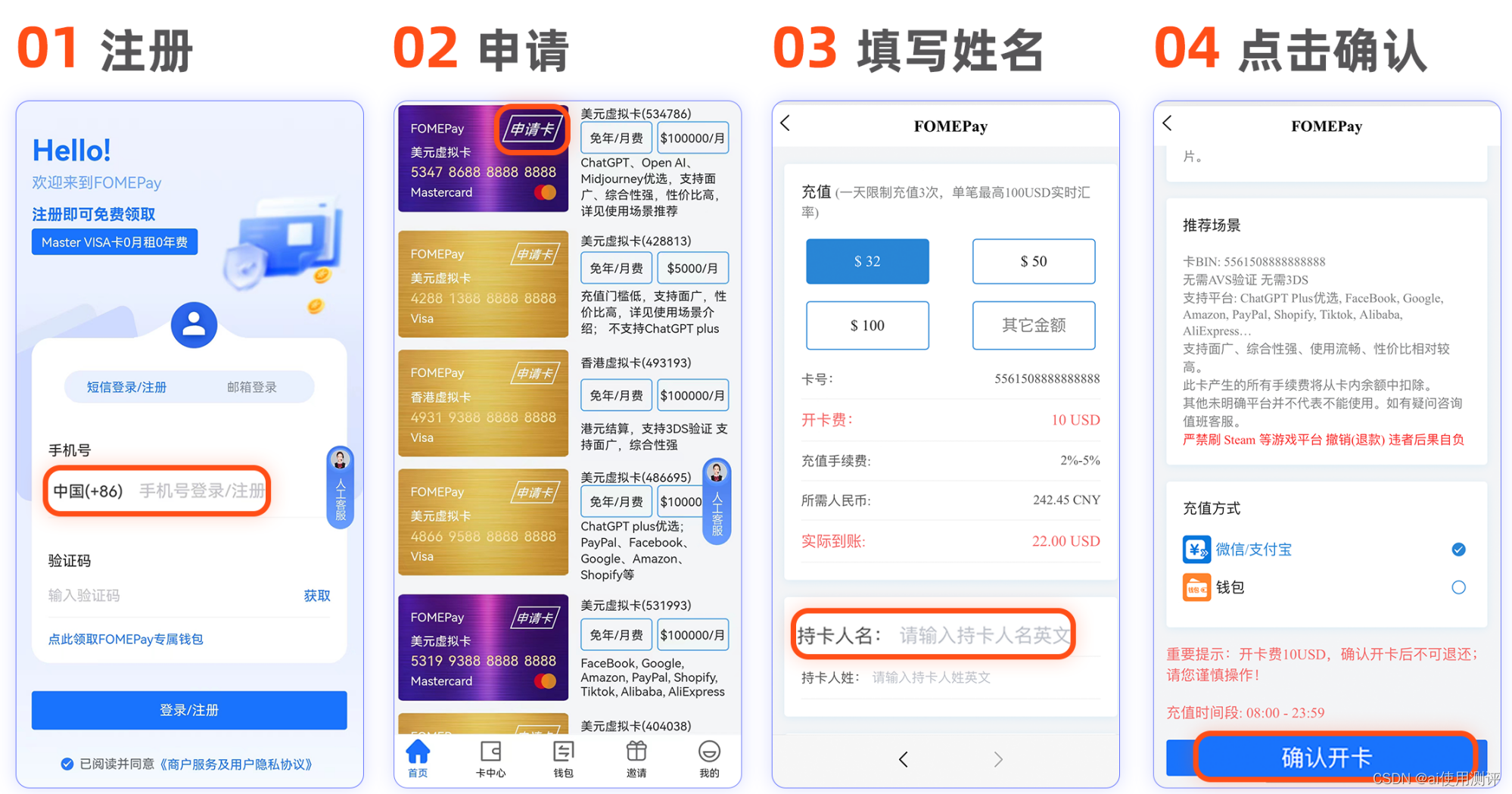
facebook个人广告账户充值方式有哪些?看这一篇就够了
可以使用虚拟信用卡进行充值,也可以使用虚拟卡绑定paypal进行充值 点击获取虚拟卡 开卡步骤如下图 Facebook如何添加支付方式 1.前往支付设置。 2.在支付方式版块,点击添加支付方式。 3.选择要添加的支付方式,填写相关信息,然…...

蓝桥杯算法练习系统—作物杂交【第十一届】【省赛】【C组】
问题描述 作物杂交是作物栽培中重要的一步。已知有 N 种作物(编号 1 至 N ),第 i 种作物从播种到成熟的时间为 Ti。 作物之间两两可以进行杂交,杂交时间取两种中时间较长的一方。如作物 A 种植时间为 5 天,作物 B 种植时间为 7 天࿰…...
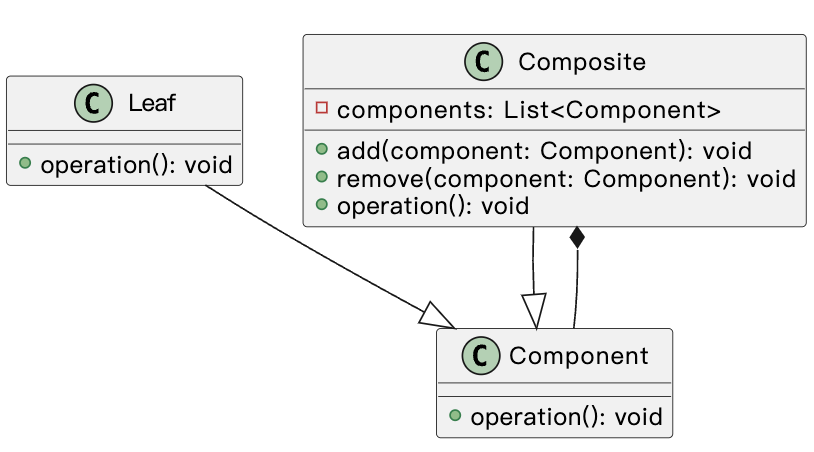
java组合模式揭秘:如何构建可扩展的树形结构
组合模式(Composite Pattern)是一种结构型设计模式,它允许将对象组合成树形结构以表示整体/部分层次结构。组合模式使得客户端可以统一对待单个对象和组合对象,从而使得客户端可以处理更复杂的结构。 组合模式的主要组成部分包括&…...
pycharm 历史版本下载地址
pycharm 历史版本下载地址 老版本能用就行,不需要搞最新的,当然了,有些小伙伴就是喜欢新的(最先吃螃蟹) 博主就不搞最新了,哈哈 上菜: https://www.jetbrains.com/pycharm/download/other.html…...
Day39:安全开发-JavaEE应用SpringBoot框架Actuator监控泄漏Swagger自动化
目录 SpringBoot-监控系统-Actuator SpringBoot-接口系统-Swagger 思维导图 Java知识点: 功能:数据库操作,文件操作,序列化数据,身份验证,框架开发,第三方组件使用等. 框架库:MyB…...
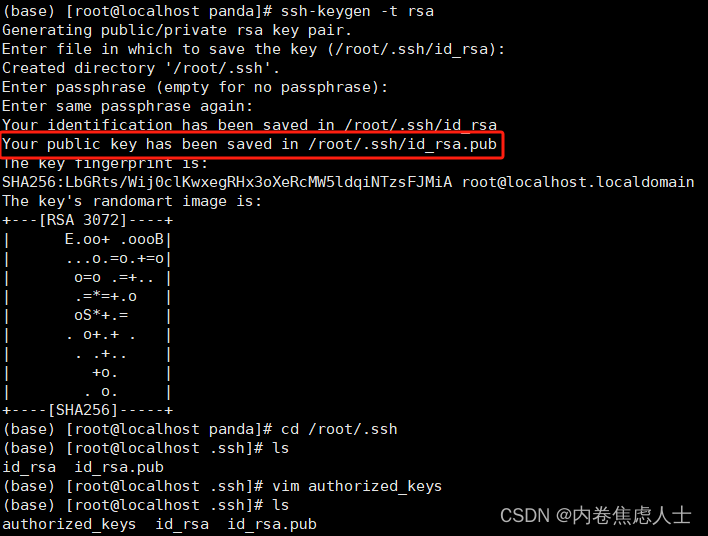
VsCode免密登录
创建本地密匙 按下WinR输入cmd,输入 ssh-keygen -t rsa然后连续回车直到结束 找到Your public key has been saved in C:\Users\Administrator/.ssh/id_rsa.pub,每个人都不一样找到密匙所在地 打开id_rsa.pub这个文件,可以用记事本打开&am…...

蓝桥杯第八届A组:分巧克力
题目描述 儿童节那天有 K 位小朋友到小明家做客。小明拿出了珍藏的巧克力招待小朋友们。 小明一共有 NN 块巧克力,其中第 ii 块是 HiWiHiWi 的方格组成的长方形。为了公平起见, 小明需要从这 NN 块巧克力中切出 K 块巧克力分给小朋友们。切出的巧克…...
前端框架的发展史介绍框架特点
目录 1.前端框架的发展历程 2.官网、优缺点、使用场景 2.1 jQuery 2.2 AngularJS 2.3 React 2.4 Vue.js 2.5 Angular 1.前端框架的发展历程 jQuery(2006年):jQuery是一个非常流行的JavaScript库,用于简化DOM操作和事件处理…...
【MatLab】之:Simulink安装
一、内容简介 本文介绍如何在 MatLab 中安装 Simulink 仿真工具包。 二、所需原材料 MatLab R2020b(教学使用) 三、安装步骤 1. 点击菜单中的“附加功能”,进入附加功能管理器: 2. 在左侧的“按类别筛选”下选择Using Simulin…...

动手学习深度学习之环境配置
创建conda虚拟环境 下载anaconda,安装到计算机,修改镜像源到国内 show_channel_urls: true channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/- http://mirrors.tu…...
【机器学习300问】35、什么是随机森林?
〇、让我们准备一些训练数据 idx0x1x2x3x4y04.34.94.14.75.5013.96.15.95.55.9022.74.84.15.05.6036.64.44.53.95.9146.52.94.74.66.1152.76.74.25.34.81 表格中的x0到x4一共有5个特征,y是目标值只有0,1两个值说明是一个二分类问题。 关于决策树相关的前置知识&am…...
用云服务器构建gpt和stable-diffusion大模型
用云服务器构建gpt和stable-diffusion大模型 一、前置知识二、用云端属于自己的聊天chatGLM3step1、项目配置step2、环境配置1、前置知识2、环境配置流程 step3、创建镜像1、前置知识2、创建镜像流程 step4、通过 Gradio 创建ChatGLM交互界面1、前置知识2、创建ChatGLM交互界面…...

强化学习在并行机构人形机器人控制中的应用
1. 项目概述在机器人控制领域,强化学习(RL)正逐渐成为解决复杂动力学系统问题的有力工具。然而,当面对具有并行驱动机构的人形机器人时,传统RL训练方法往往面临一个关键挑战:大多数仿真环境无法准确模拟闭环运动链(Closed Kinemat…...

tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南
tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南 【免费下载链接】tools Assorted useful tools, almost entirely generated using LLMs 项目地址: https://gitcode.com/gh_mirrors/tools23/tools tools.simonwillison.net图像处理工具集是一…...

CentOS 7下‘Development Tools’和‘开发工具’组有区别吗?实测告诉你答案
CentOS 7下‘Development Tools’与‘开发工具’的隐藏关联:技术细节全解析在Linux系统管理中,yum的软件包组功能一直是个既实用又充满谜团的领域。特别是当系统语言环境与软件包元数据语言不一致时,开发者们常常会遇到一个有趣的现象&#x…...

新手村任务:成为一个架构师需要哪些装备?
新手村任务:成为一个架构师需要哪些装备? 一、前言 如果你刚入行不久,想成为一名架构师,那这篇文章就是为你写的。 我们把成为架构师比作一个RPG游戏,你是主角,需要收集各种装备、刷经验、升级技能。 新手村的第一个任务就是:了解你需要哪些装备。 二、架构师技能树…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...

人类防伪指南:为什么你越写错字,HR越信你是真人?
前言各位码农、算法侠、CtrlC/V十级学者请注意:你有没有过这样的经历?辛辛苦苦肝了一晚上文档,逻辑严密、语法丝滑、连Markdown都对齐得像军训方阵,结果老板幽幽来一句:“这真是你自己写的?”那一刻&#x…...

LeagueAkari:英雄联盟终极自动化助手革命性指南
LeagueAkari:英雄联盟终极自动化助手革命性指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否在英雄联盟游戏中反复经历这…...

如何用免费工具解锁QQ音乐、网易云音乐等加密格式:3分钟解决音乐播放限制
如何用免费工具解锁QQ音乐、网易云音乐等加密格式:3分钟解决音乐播放限制 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web…...
)
Lindy多步骤任务自动化落地全图谱(企业级架构师压箱底实践)
更多请点击: https://codechina.net 第一章:Lindy多步骤任务自动化落地全图谱(企业级架构师压箱底实践) Lindy效应在自动化系统设计中揭示了一个关键洞察:越久经考验的实践,其未来预期寿命越长。Lindy多步…...

SpringBoot WebClient 介绍
目录一、什么是 WebClient?二、 WebClient 能解决什么问题?三、WebClient 和 RestTemplate 的区别四、WebClient 的核心优势1. 非阻塞(Non-Blocking)2. 支持异步3. 链式 API 更现代五、WebClient 的核心对象六、Mono 和 Flux 是什…...