十四、GPT
在GPT-1之前,传统的 NLP 模型往往使用大量的数据对有监督的模型进行任务相关的模型训练,但是这种有监督学习的任务存在两个缺点:预训练语言模型之GPT
- 需要大量的标注数据,高质量的标注数据往往很难获得,因为在很多任务中,标签并不是唯一的或者实例标签并不存在明确的边界;
- 根据一个任务训练的模型很难泛化到其它任务中,这个模型只能叫做“领域专家”而不是真正的理解了 NLP。
1 GPT-1
生成式预训练 Transfomer 模型(Generative Pre-Trained Transformer,GPT),将无监督学习应用到有监督模型的预训练目标。参考GPT的前世今生
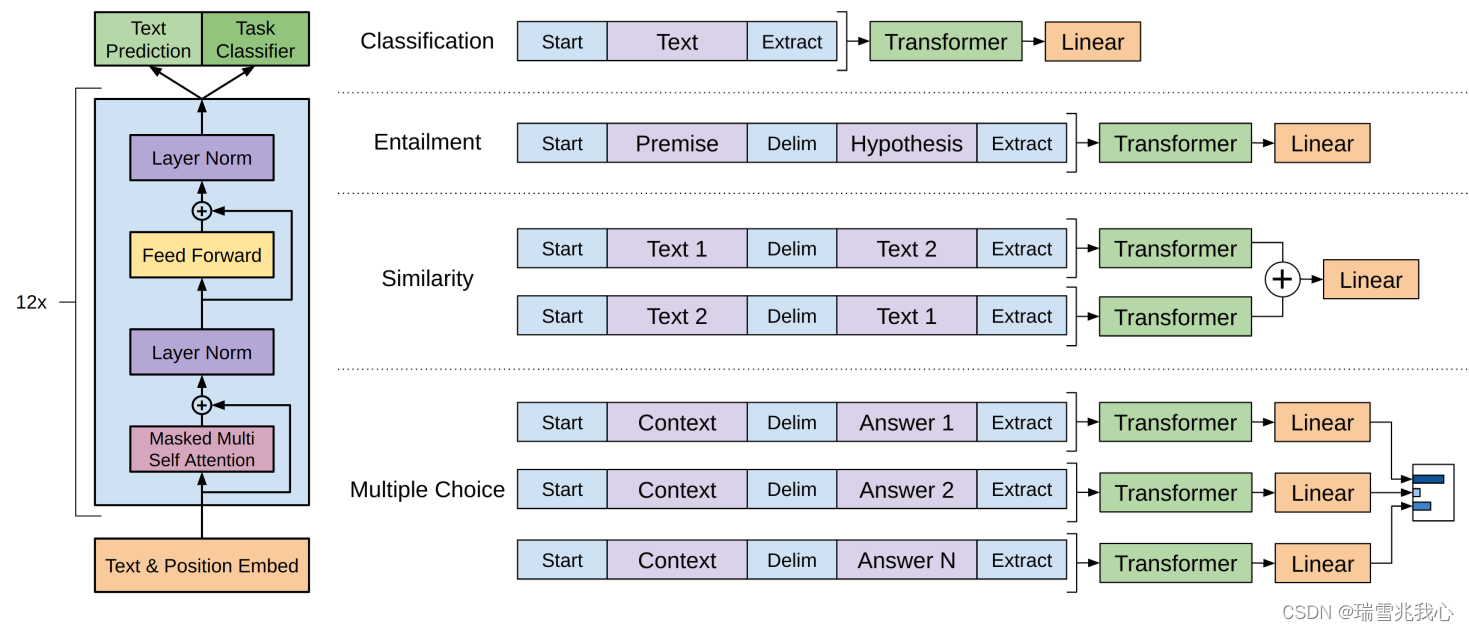
GPT-1 语言模型结构上对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention。
GPT-1 语言模型通过大量的无监督预训练(Unsupervised Pre-Training)(无监督是指不需要人工介入,不需要标注数据集的预训练),再通过少量有监督微调(Supervised Fine-Tuning)来修正其理解能力。监督训练和无监督训练是什么参考2.1部分
- 在预训练阶段,GPT-1 使用无标注文本数据集(数据量约 5 GB 大小,模型自身参数 1.17 亿,Transfomer Layer 堆叠 12 层),通过最大化预训练数据集上的似然函数 log-likelihood 来训练模型参数。
- 在微调阶段,GPT-1 将预训练模型的参数用于特定的自然语言处理任务。
2 GPT-2
GPT-2 的目标旨在训练一个泛化能力更强的词向量模型,它并没有对 GPT-1 的网络进行过多的结构的创新与设计,只是使用了更多的网络参数和更大的数据集。GPT语言模型详细介绍
GPT-2 模型主推零样本学习(Zero Shot Learning),使用了更多的数据(数据集增加 40 GB大小,模型自身参数高达15亿,Transfomer Layer 堆叠 48 层)进行预训练 Pre_Training,将有监督 Fine-Tuning 微调阶段变成了一个无监督的模型,同时增加了预训练多任务 MultiTask 模式(即主张不通过专门的标注数据集训练专用的AI,而是喂取了海量数据后,任意任务都可以完成)。
3 GPT-3
从理论上讲 GPT-3 也是支持 Fine-Tuning 的,但是 Fine-Tuning 需要利用海量的标注数据进行训练才能获得比较好的效果,但是这样也会造成对其它未训练过的任务上表现差,所以 GPT-3 并没有尝试 Fine-Tuning。
零样本学习(Zero-Shot Learning)是一种能够在没有任何样本的情况下学习新类别的方法。通常情况下,模型只能识别它在训练集中见过的类别。但通过零样本学习,模型能够利用一些辅助信息来进行推理,并推广到从未见过的类别上。这些辅助信息可以是关于类别的语义描述、属性或其他先验知识。 Zero-Shot, One-Shot 和 Few-Shot Learning概念介绍
一次样本学习(One-Shot Learning)是一种只需要一个样本就能学习新类别的方法。这种方法试图通过学习样本之间的相似性来进行分类。例如,当我们只有一张狮子的照片时,一次样本学习可以帮助我们将新的狮子图像正确分类。
少样本学习(Few-Shot Learning)是介于零样本学习和一次样本学习之间的方法。它允许模型在有限数量的示例下学习新的类别。相比于零样本学习,少样本学习提供了更多的训练数据,但仍然相对较少。这使得模型能够从少量示例中学习新的类别,并在面对新的输入时进行准确分类。
元学习(Meta Learning)的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果(对于一个少样本的任务来说,模型的初始化值非常重要,从一个好的初始化值作为起点,模型能够尽快收敛,使得到的结果非常快的逼近全局最优解)。
GPT-3 模型使用更多的高质量的数据(数据集增加 45 TB大小,模型自身参数高达 1750 亿,Transformer Layer 也从48层提升到 96 层),使用 MAML(Model Agnostic Meta Learning)算法学习一组 Meta-Initialization,能够快速应用到其它任务中。
4 ChatGPT
ChatGPT 基于 GPT-3.5 架构的有监督精调 (Supervised Fine-Tuning, SFT),训练一个奖励模型(Reward Model,RM),使用来自人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)进行优化训练,通过近端策略优化(Proximal Policy Optimization)算法进行微调。参考ChatGPT原理详解
该方法包括以下三个步骤: 一文读懂ChatGPT中的强化学习
- 第一步:带监督的微调,预训练语言模型对由标注人员管理的相对较少的演示数据进行微调,以学习监督策略(SFT模型),根据选定的提示列表生成输出,这表示基线模型;
- 第二步:“模仿人类偏好” ,要求标注人员对相对较多的 SFT 模型输出进行投票,创建一个由对比数据组成的新数据集。在该数据集上训练一个新的奖励模型(RM);
- 第三步:近端策略优化(PPO),对奖励模型进一步微调以改进 SFT 模型。这一步的结果就是所谓的策略模型。
- 步骤 1 只进行一次,而步骤 2 和步骤 3 可以连续迭代,在当前的最佳策略模型上收集更多的比较数据,训练出一个新的奖励模型,然后在此基础上再训练出一个新的策略。
相关文章:
十四、GPT
在GPT-1之前,传统的 NLP 模型往往使用大量的数据对有监督的模型进行任务相关的模型训练,但是这种有监督学习的任务存在两个缺点:预训练语言模型之GPT 需要大量的标注数据,高质量的标注数据往往很难获得,因为在很多任务…...

五款优秀的FTP工具
一、WinSCP WinSCP是一个Windows环境下使用SSH的开源图形化SFTP客户端。同时支持SCP协议。它的主要功能就是在本地与远程计算机间安全的复制文件。.winscp也可以链接其他系统,比如linux系统。 官网:https://winscp.net/ 二、FileZilla FileZilla是一个免费开源的…...

十八、软考-系统架构设计师笔记-真题解析-2022年真题
软考-系统架构设计师-2022年上午选择题真题 考试时间 8:30 ~ 11:00 150分钟 1.云计算服务体系结构如下图所示,图中①、②、③分别与SaaS、PaaS、IaaS相对应,图中①、②、③应为( )。 A.应用层、基础设施层、平台层 B.应用层、平台层、基础设施层 C.平…...
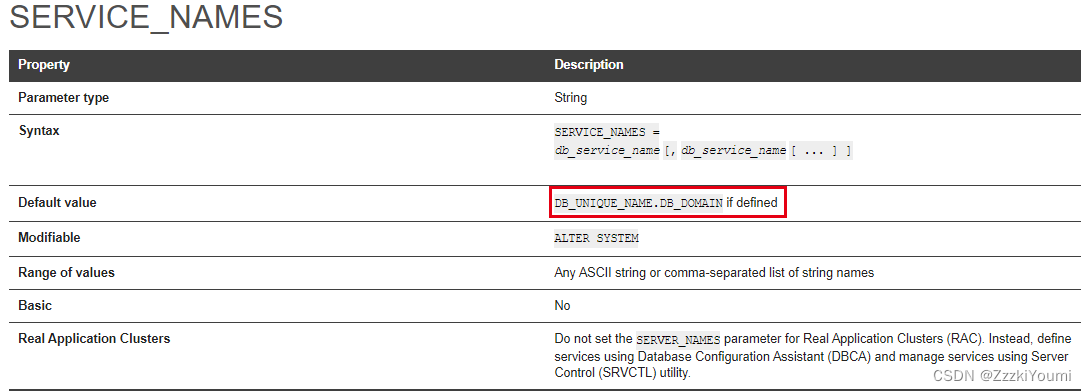
oracle数据库名、实例名、服务名等区分
DB_NAME: ①是数据库名,长度不能超过8个字符,记录在datafile、redolog和control file中 ②在DataGuard环境中DB_NAME相同而DB_UNIQUE_NAME不同 ③在RAC环境中,各个节点的DB_NAME 都相同,但是INSTANCE_NAME不同 ④DB_NA…...

MQ横向对比:RocketMQ、Kafka、RabbitMQ、ActiveMQ、ZeroMQ
前言 本文将从多个角度全方位对比目前比较常用的几个MQ: RocketMQKafkaRabbitMQActiveMQZeroMQ将单独说明。 表格对比 特性RocketMQKafkaRabbitMQActiveMQ单机吞吐量10 万级,支撑高吞吐10 几万级,吞吐量非常高,甚至有文献称&a…...

html5cssjs代码 018颜色表
html5&css&js代码 018颜色表 一、代码二、效果三、解释 这段代码展示了一个基本的颜色表,方便参考使用,同时也应用了各种样式应用方式。 一、代码 <!DOCTYPE html> <html lang"zh-cn"> <head><title>编程笔记…...

力扣刷题Days20-151. 反转字符串中的单词(js)
目录 1,题目 2,代码 1,利用js函数 2,双指针 3,双指针加队列 3,学习与总结 1,正则表达式 / \s /: 2,结合使用 split 和正则表达式: 1,题目 给你一个字符串 s &am…...
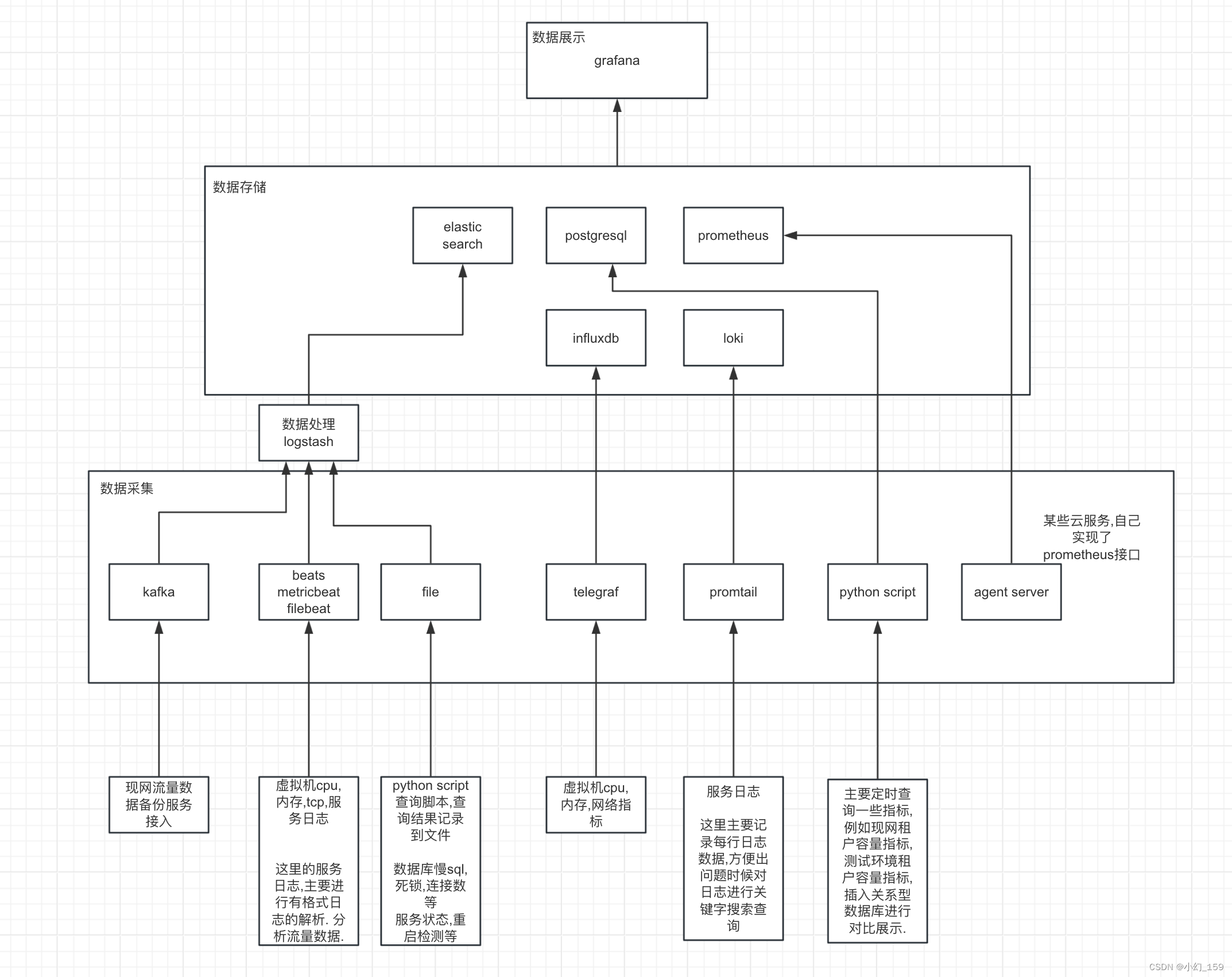
基于grafana+elk等开源组件的 云服务监控大屏架构
本套大屏,在某云服务大规模测试环境,良好运行3年. 本文主要展示这套监控大屏的逻辑架构.不做具体操作与配置的解释. 监控主要分为三部分: 数据展示部分数据存储数据采集 1. 数据展示 数据展示方面主要使用grafana 2. 数据存储 根据数据种类和特性和用途的不同,本套监控采用…...
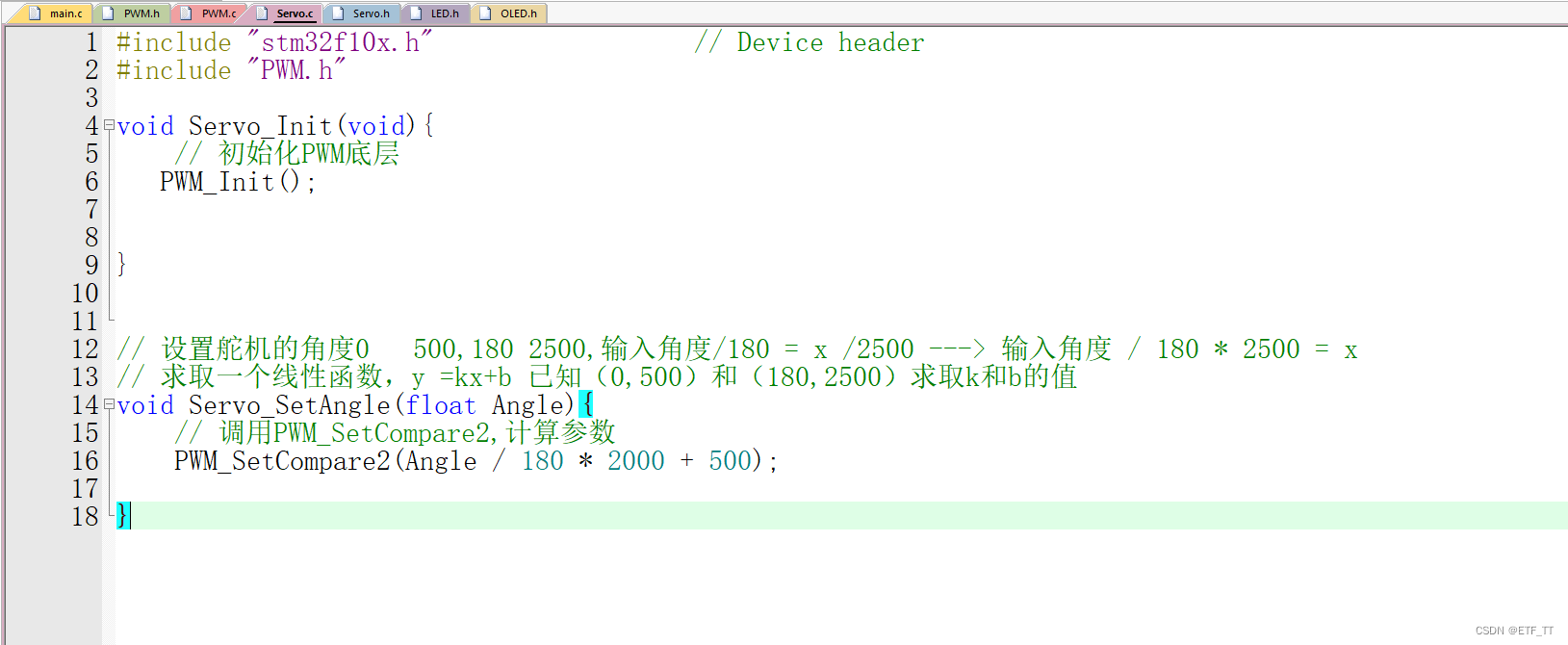
PWM驱动舵机
PWM驱动舵机 接线图 程序结构图: pwm.c部分代码 #include "stm32f10x.h" // Device headervoid PWM_Init(void){// 开启时钟,这里TIM2是通用寄存器RCC_APB1PeriphClockCmd(RCC_APB1Periph_TIM2,ENABLE);// GPIO初始化代…...

处理Centos 7 中buff/cache高的问题
在CentOS 7中,如果发现 buff/cache 栏目的值过高占用了大量内存,可以尝试以下方法来释放部分缓存: 清理页面缓存 Linux内核会缓存最近使用过的内存页面,以提高访问速度。你可以使用以下命令清理页面缓存: sudo sync && sudo echo 1 > /proc/sys/vm/drop_caches …...

【送书福利第五期】:ARM汇编与逆向工程
文章目录 📑前言一、ARM汇编与逆向工程1.1 书封面1.2 内容概括1.3 目录 二、作者简介三、译者介绍🌤️、粉丝福利 📑前言 与传统的CISC(Complex Instruction Set Computer,复杂指令集计算机)架构相比&#…...
STM32的USART能否支持9位数据格式话题
1、问题描述 STM32L051 这款单片机。平常的 USART 串口传输是 8 位数据,但是他的项目需要用串口传输 9 位数据。当设置为 8 位数据时,串口响应中断正常。但是,当设置为 9 位数据时,串口就不产生中断了。USART2 的 ISR 寄存器 RXN…...

OLAP与数据仓库和数据湖
OLAP与数据仓库和数据湖 本文阐述了OLAP、数据仓库和数据湖方面的基础知识以及相关论文。同时记录了我如何通过ChatGPT以及类似产品(通义千问、文心一言)来学习知识的。通过这个过程让我对于用AI科技提升学习和工作效率有了实践经验和切身感受。 预热 …...

zookeeper快速入门三:zookeeper的基本操作
在zookeeper的bin目录下,输入./zkServer.sh start和./zkCli.sh启动服务端和客户端,然后我们就可以进行zookeeper的基本操作了。如果是windows,请参考前面章节zookeeper快速入门一:zookeeper安装与启动 目录 一、节点的增删改查 …...
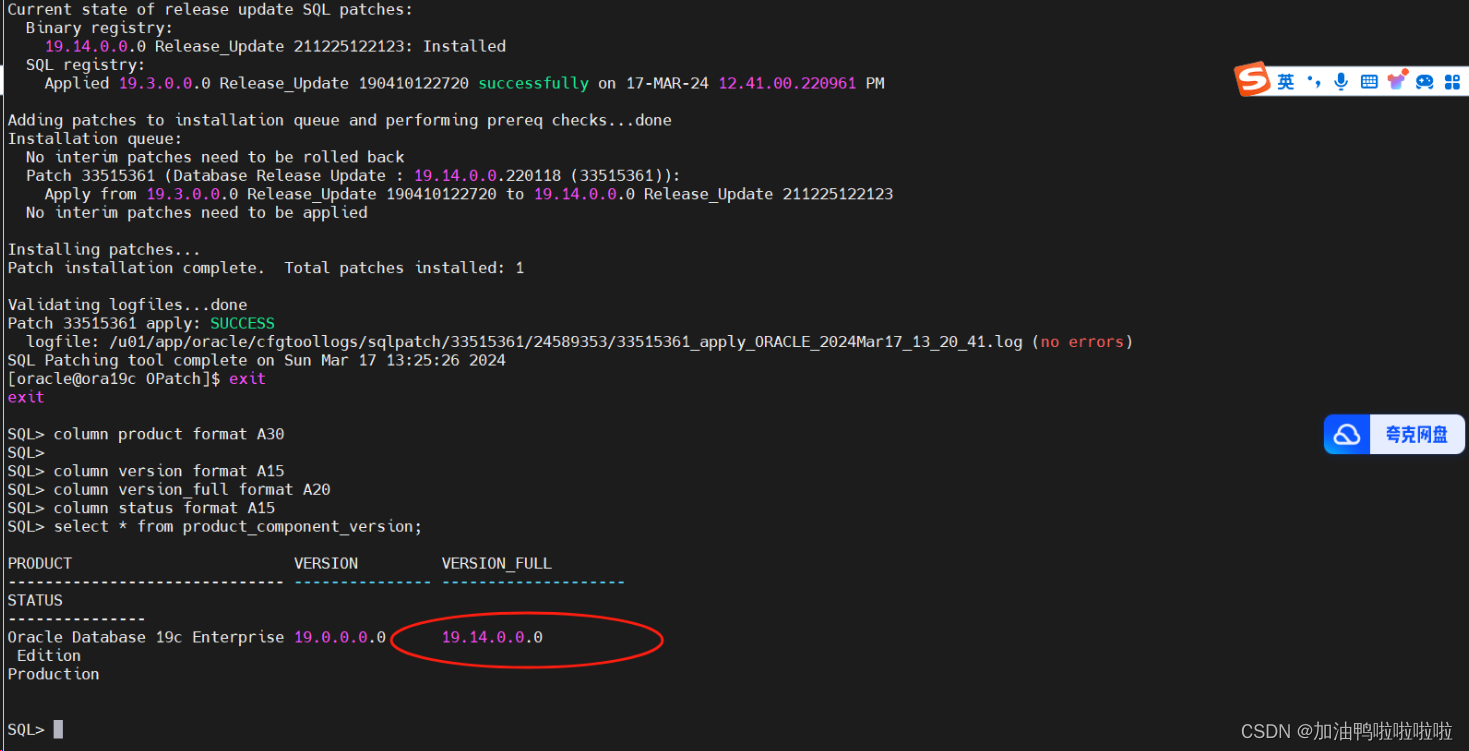
oracle 19c打补丁到19.14
oracle 19c打补丁到19.14 oracle 19.3打补丁到19.14 查看oracle的版本: SQL> column product format A30 SQL> column version format A15 SQL> column version_full format A20 SQL> column status format A15 SQL> select * from product_compo…...
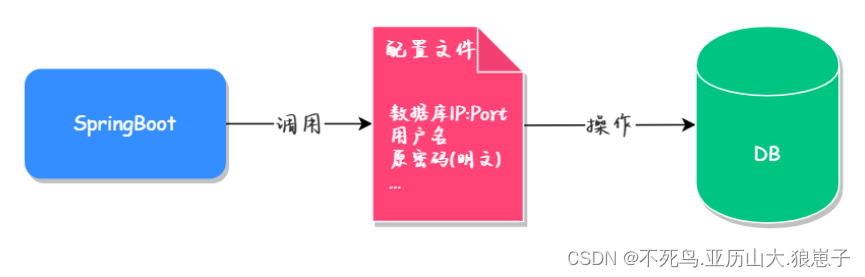
Spring Boot(六十九):利用Alibaba Druid对数据库密码进行加密
1 Alibaba Druid简介 之前介绍过Alibaba Druid的,章节如下,这里就不介绍了: Spring Boot(六十六):集成Alibaba Druid 连接池 这章使用Alibaba Druid进行数据库密码加密,在上面的代码上进行修改,这章只介绍密码加密的步骤。 目前越来越严的安全等级要求,我们在做产品…...
51单片机—DS18B20温度传感器
目录 一.元件介绍及原理 二,应用:DS18B20读取温度 一.元件介绍及原理 1.元件 2.内部介绍 本次元件使用的是单总线 以下为单总线的介绍 时序结构 操作流程 本次需要使用的是SKIP ROM 跳过, CONVERT T温度变化,READ SCRATCHPAD…...
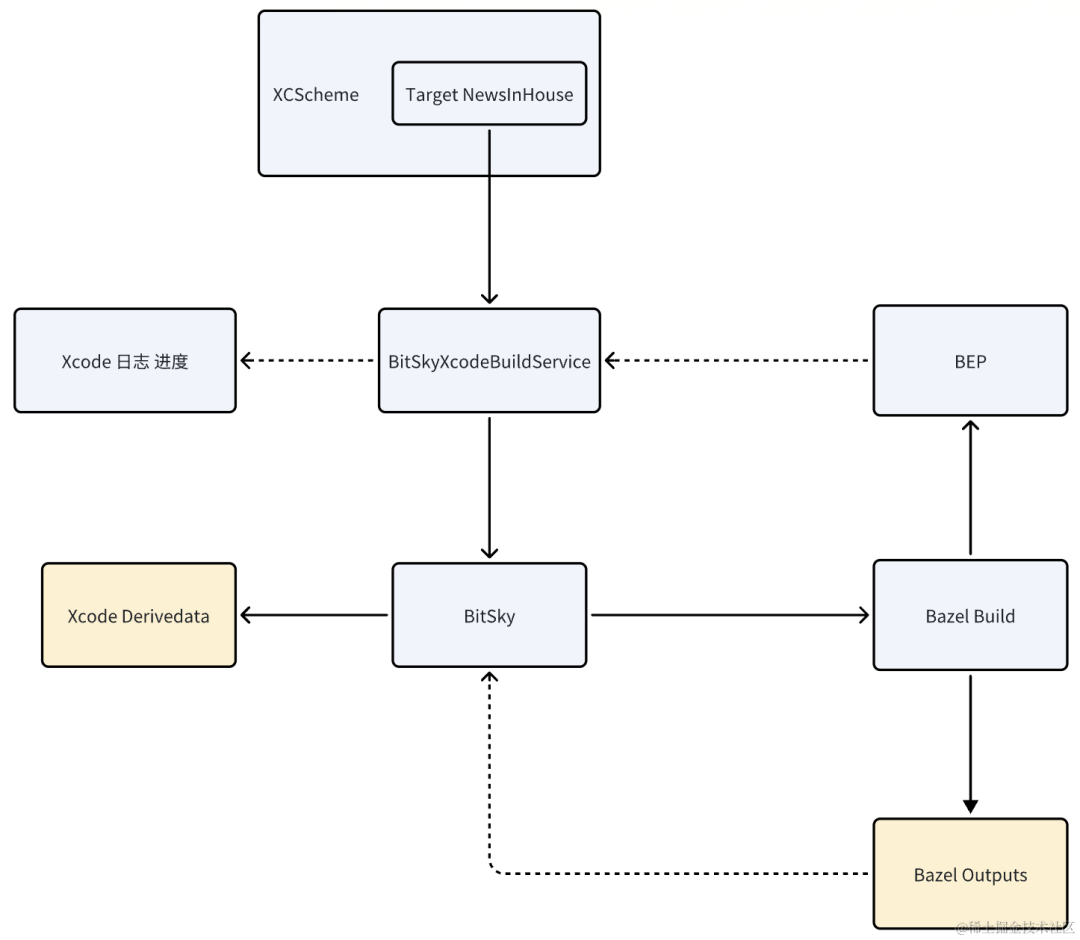
Monorepo 解决方案 — 基于 Bazel 的 Xcode 性能优化实践
背景介绍 书接上回《Monorepo 解决方案 — Bazel 在头条 iOS 的实践》,在头条工程切换至 Bazel 构建系统后,为了支持用户使用 Xcode 开发的习惯,我们使用了开源项目 Tulsi 作为生成工具,用于将 Bazel 工程转换为 Xcode 工程。但是…...
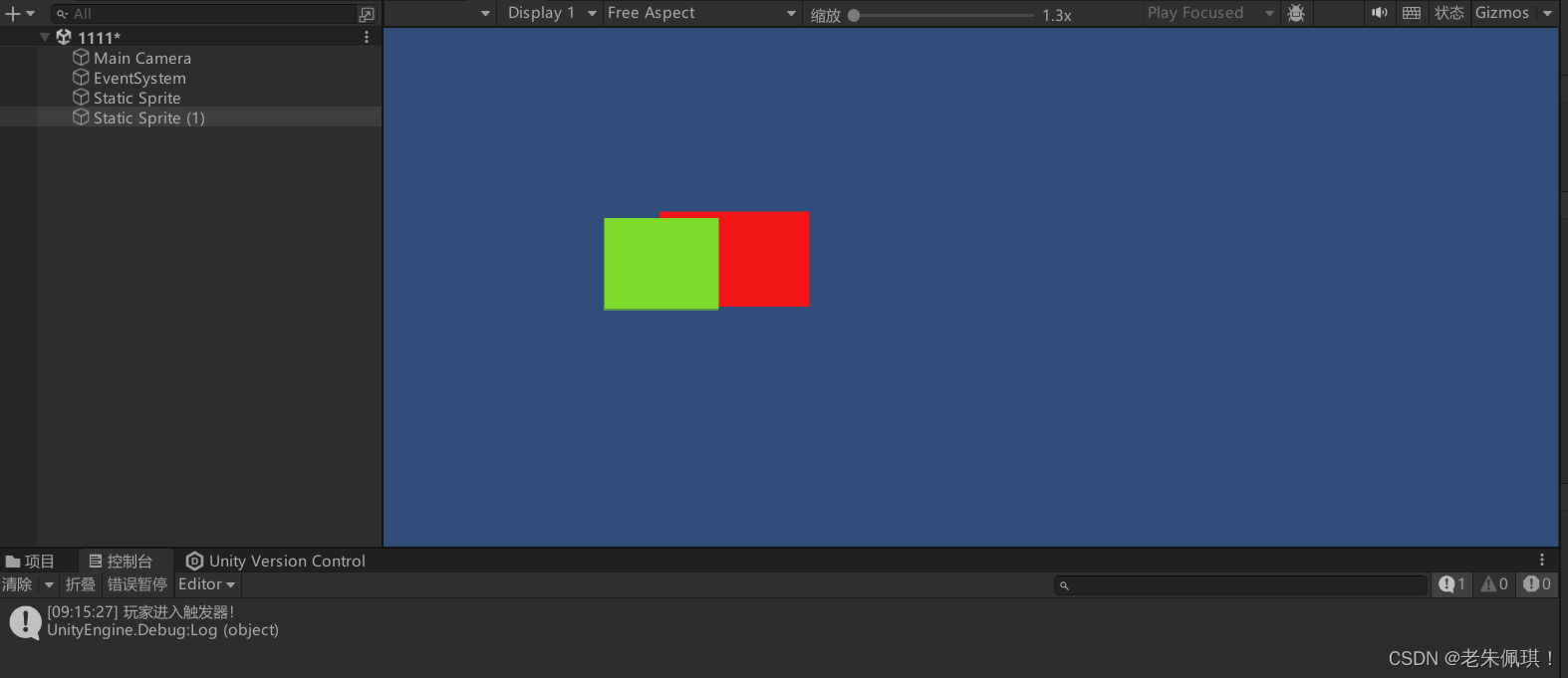
Unity触发器的使用
1.首先建立两个静态精灵(并给其中一个物体添加"jj"标签) 2.添加触发器 3.给其中一个物体添加刚体组件(如果这里是静态的碰撞的时候将不会触发效果,如果另一个物体有刚体可以将它移除,或者将它的刚体属性设置…...
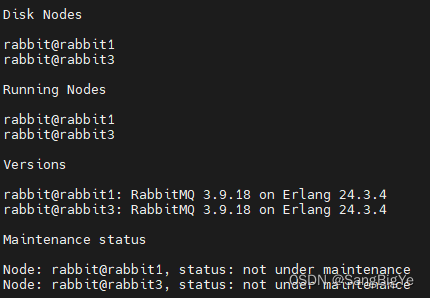
docker compose部署rabbitmq集群
docker compose 配置 假设有两台电脑 A电脑的ip为192.168.1.100 B电脑的ip为192.168.1.103 A电脑的docker compose 配置 version: 3services:rabbitmq:restart: alwaysimage: rabbitmq:3.9.18-managementcontainer_name: rabbitmq-node-1hostname: rabbit1extra_hosts:- &quo…...
)
VMware升级后Ubuntu 22.04虚拟机网卡‘消失’?别慌,这6个命令帮你一键找回(附排查思路)
VMware升级后Ubuntu 22.04虚拟机网卡异常修复指南当你满怀期待地将VMware Workstation从15版升级到17版,准备体验新功能时,突然发现原本运行良好的Ubuntu 22.04虚拟机无法联网了——ifconfig只显示lo回环接口,网络设置里空空如也。这种"…...

量子通信技术突破:量子处理器如何提升经典通信容量
1. 量子通信技术的新范式:量子处理器辅助经典通信在传统通信领域,香农极限长期被视为不可逾越的理论边界。然而,量子计算技术的快速发展正在颠覆这一认知。我们团队最新研究发现,通过量子处理器辅助的经典通信系统,可以…...

物理生物学研究报告【20260015】
文章目录抛球入框实验报告一、实验目的二、实验装置三、实验方法四、实验结果4.1 无弹跳实验(A组)4.2 允许弹跳实验(B组)五、分析与讨论5.1 无弹跳与弹跳的参数差异5.2 恢复系数的影响5.3 误差来源六、结论七、致谢抛球入框实验报…...

LLM:大语言模型的主要任务
大语言模型(Large Language Model,LLM)是以深度学习为基础、通过大规模文本或多模态数据训练得到的生成式模型。它的核心能力并不是完成某一个固定任务,而是围绕语言理解、文本生成、信息处理、推理协助、代码生成、工具调用和多模…...

键盘定制指南:从硬件到软件,开启实用又有趣的键盘使用体验!
引言 我钟情于键盘,因其是高效的人机交互接口,且充满“趣味”。用力敲击大按键,无需思索;体验精确组合的键盘快捷键带来的掌控感,皆是乐事。看着屏幕内容随操作而变,特别是那些契合自身工作方式的反馈&…...

Kubernetes安全加固指南:构建安全的容器平台
Kubernetes安全加固指南:构建安全的容器平台 一、Kubernetes安全概述 Kubernetes安全涉及多个层面,包括网络安全、Pod安全、数据安全、访问控制等。构建安全的Kubernetes集群需要从多个维度进行加固。 1.1 安全维度 维度说明关注点网络安全Pod间通信…...

DLSS Swapper深度解析:如何实现跨平台游戏DLSS版本智能管理
DLSS Swapper深度解析:如何实现跨平台游戏DLSS版本智能管理 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 在NVIDIA DLSS技术成为现代PC游戏性能优化的关键要素后,玩家面临一个实际的技术挑战&…...

高校科研项目如何借助Taotoken管理多模型API调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 高校科研项目如何借助Taotoken管理多模型API调用 在高校的实验室或科研团队中,进行人工智能相关的探索时,常…...

人机协同闭环:AI 时代邮件安全 “人在回路” 防御体系研究
摘要 2026 年,生成式 AI 全面渗透网络钓鱼攻击链,攻击从批量群发转向精准定制、从静态模板转向动态逃逸,传统纯技术防护出现显著盲区。数据显示,AI 自动化鱼叉式钓鱼点击率达 54%,攻击从投放至全面入侵的窗口压缩至秒级…...

DeepSeek免费额度到底能跑几个大模型?揭秘2024最新配额规则与5个隐藏续费技巧
更多请点击: https://codechina.net 第一章:DeepSeek免费额度到底能跑几个大模型? DeepSeek 官方为新注册用户提供 100 万 Token 的免费调用额度(截至 2024 年底政策),但不同模型的 Token 消耗差异显著——…...