Hello,Spider!入门第一个爬虫程序
在各大编程语言中,初学者要学会编写的第一个简单程序一般就是“Hello, World!”,即通过程序来在屏幕上输出一行“Hello, World!”这样的文字,在Python中,只需一行代码就可以做到。我们把这第一个爬虫就称之为“HelloSpider”,见下例。
import lxml.html,requests
url = 'https://www.python.org/dev/peps/pep-0020/'
xpath = '//*[@id="the-zen-of-python"]/pre/text()'
res = requests.get(url)
ht = lxml.html.fromstring(res.text)
text = ht.xpath(xpath)
print('Hello,\n'+''.join(text))
运行结果:
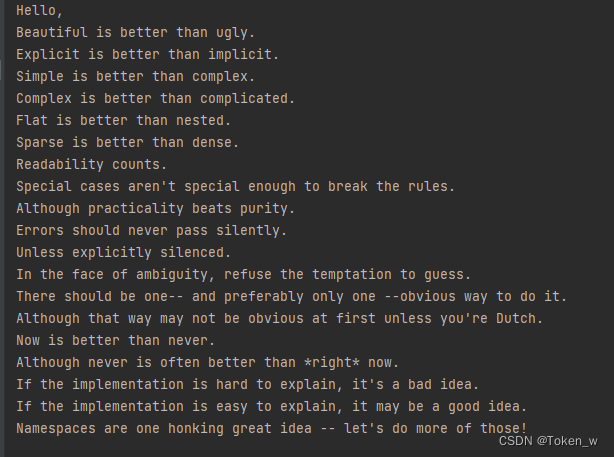
代码分析:
- 导入模块
import lxml.html,requests
这里我们使用import导入了两个模块,分别是lxml库中的html以及python中著名的requests库。lxml是用于解析XML和HTML的工具,可以使用xpath和css来定位元素,而requests则是著名的Python HTTP库,其口号是“给人类用的HTTP”,相比于Python自带的urllib库而言,requests的有着不少优点,使用起来十分简单,接口设计也非常合理。实际上,对Python比较熟悉的话就会知道,在Python 2中一度存在着urllib, urllib2, urllib3, httplib, httplib2等一堆让人易于混淆的库,可能官方也察觉到了这个缺点,Python 3中的新标准库urllib就比Python 2好用一些。曾有人在网上问道“urllib, urllib2, urllib3的区别是什么,怎么用”,有人回答“为什么不去用requests呢?”,可见requests的确有着十分突出的优点。同时也建议读者,尤其是刚刚接触网络爬虫的人采用requests,可谓省时省力。
- 定义变量
url = 'https://www.python.org/dev/peps/pep-0020/'
xpath = '//*[@id="the-zen-of-python"]/pre/text()'
这里我们定义了两个变量,Python不需要声明变量的类型,url和xpath会自动被识别为字符串类型。url是一个网页的链接,可以直接在浏览器中打开,页面中包含了Python之禅的文本信息。xpath变量则是一个xpath路径表达式,我们刚才提到,lxml库可以使用xpath来定位元素,当然,定位网页中元素的方法不止xpath一种,以后我们会介绍更多的定位方法。
- re get 数据
res = requests.get(url)
使用了requests中的get方法,对url发送了一个HTTP GET请求,返回值被赋值给res,于是我们便得到了一个名为res的Response对象,接下来就可以从这个Response对象中获取我们想要的信息。
- 处理html
ht = lxml.html.fromstring(res.text)
lxml.html是lxml下的一个模块,顾名思义,主要负责处理HTML。fromstring方法传入的参数是res.text,即刚才我们提到的Response对象的text(文本)内容。在fromstring函数的doc string中(文档字符串,即此方法的说明)说道,这个方法可以“Parse the html, returning a single element/document.”即fromstring根据这段文本来构建一个lxml中的HtmlElement对象。
- 输出
text = ht.xpath(xpath)
print('Hello,\n'+''.join(text))
这两行代码使用xpath来定位HtmlElement中的信息,并进行输出。text就是我们得到的结果,“.join()”是一个字符串方法,用于将序列中的元素以指定的字符连接生成一个新的字符串。因为我们的text是一个list对象,所以使用‘’这个空字符来连接。
如果不进行这个操作而直接输出:程序会报错,出现‘TypeError: Can’t convert ‘list’ object to str implicitly’这样的错误。当然,对于list序列而言,我们还可以通过一段循环来输出其中的内容。
思考
通过刚才这个十分简单的爬虫示例,我们不难发现,爬虫的核心任务就是访问某个站点(一般为一个URL地址)然后提取其中的特定信息,之后对数据进行处理(在这个例子中只是简单地输出)。当然,根据具体的应用场景,爬虫可能还需要很多其他的功能,比如自动抓取多个页面、处理表单、对数据进行存储或者清洗等等。
其实,如果我们只是想获取特定网站所提供的关键数据,而每个网站都提供了自己的API (应用程序接口,Application Programming Interface),那么我们对于网络爬虫的需求可能就没有那么大了。毕竟,如果网站已经为我们准备好了特定格式的数据,只需要访问API就能够得到所需的信息,那么又有谁愿意费时费力地编写复杂的信息抽取程序呢?现实是,虽然有很多网站都提供了可供普通用户使用的API,但其中很多功能往往是面向商业的收费服务。另外,API毕竟是官方定义的,免费的格式化数据不一定能够满足我们的需求。掌握一些网络爬虫编写,不仅能够做出只属于自己的功能,还能在某种程度上拥有一个高度个性化的“浏览器”,因此,学习爬虫相关知识还是很有必要的。
相关文章:
Hello,Spider!入门第一个爬虫程序
在各大编程语言中,初学者要学会编写的第一个简单程序一般就是“Hello, World!”,即通过程序来在屏幕上输出一行“Hello, World!”这样的文字,在Python中,只需一行代码就可以做到。我们把这第一个爬虫就称之为“HelloSpider”&…...
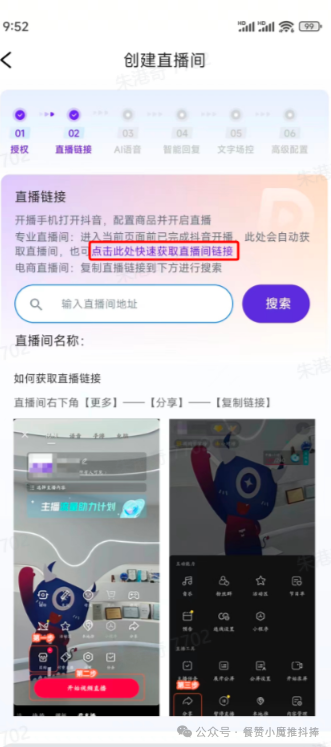
AI实景无人自动直播间怎么搭建?三步教你轻松使用
最近很多朋友看到AI自动直播带货玩法,也想开启自己的自动直播间,但还是有些问题比较担心,这种自动讲解、自动回复做带货的直播间是不是很麻烦? 实景无人自动直播 实际上这种直播间搭建相当简单便捷!今天跟着笔者&…...
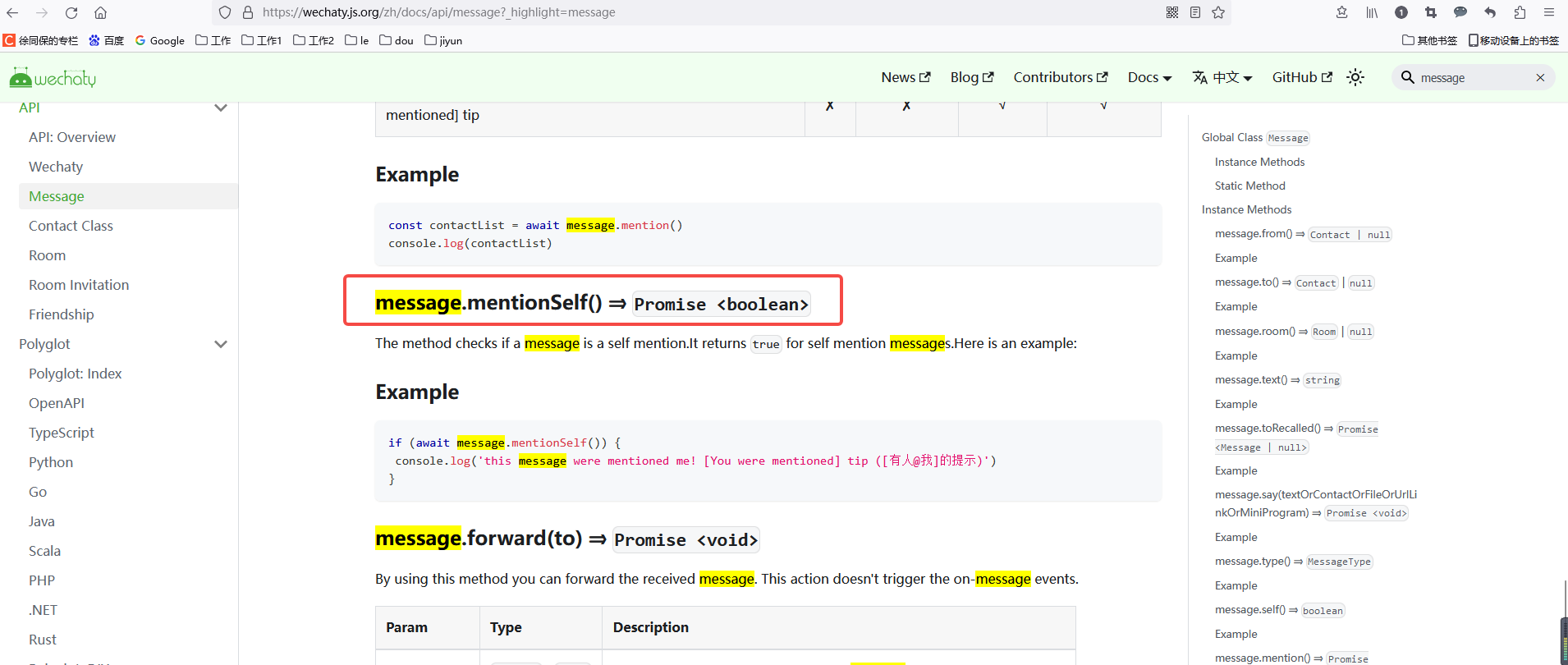
wechaty微信机器人,当机器人被@时做出响应
https://wechaty.js.org/zh/docs/api/message?_highlightmessage if (await msg.mentionSelf()) {console.log(this message were mentioned me! [You were mentioned] tip ([有人我]的提示))await room.say(不要微信机器人)} 我开发的人工智能学习网站: https://…...

8.6 Springboot项目实战 Spring Cache注解方式使用Redis
文章目录 前言一、配置Spring Cache1. @EnableCaching2. 配置CacheManager3. application.properties配置二、使用注解缓存数据1. 使用**@Cacheable** 改造查询代码2. 使用**@CacheEvict** 改造更新代码前言 在上文中我们使用Redis缓存热点数据时,使用的是手写代码的方式,这…...
rust引用本地crate
我们可以动态引用crate,build时从crate.io下载,但可能因无法下载导致build失败。首次正常引用三方crate,build时自动下载的crate源码,我们将其拷贝到固定目录中; build后可在RustRover中按住Ctrl键,在crat…...

分布式(计算机算法)
目录 分布式计算 分布式编辑 分布式和集群 分布式和集群的应用场景 分布式应用场景 集群应用场景 哪种技术更优、更快、更好呢 性能 稳定性 以下概念来源于百度百科 分布式计算 分布式计算是近年提出的一种新的计算方式。所谓分布式计算就是在两个或多个软件互相共享信息…...

CSS概念及入门
文章目录 1. CSS 概念及入门1.1. 简介1.2. 组成1.2.1. 选择器1.2.2. 属性 1.3. 区别 2. CSS 引入方式2.1. 行内样式2.1.1. 语法2.1.2. 特点 2.2. 内部样式2.2.1. 语法2.2.2. 特点 2.3. 外部样式2.3.1. 特点 2.4. 三种引入优先级 1. CSS 概念及入门 1.1. 简介 CSS 的全称为&am…...

用 C 语言模拟 Rust 的 Result 类型
在 Rust 中,Result<T, E> 类型是一个枚举,它表示一个操作可能成功并返回一个值 T,或者失败并返回一个错误 E。在 C 语言中,没有直接对应的 Result 类型,但我们可以使用结构体和枚举来模拟它。 下面是一个用 C 语…...
git基础命令(四)之分支命令
目录 基础概念git branch-r-a-v-vv-avv重命名分支删除分支git branch -h git checkout创建新的分支追踪远程分支同时切换到该分支创建新的分支并切换到该分支撤销对文件的修改,恢复到最近的提交状态:丢弃本地所有修改git checkout -h git merge合并指定分…...
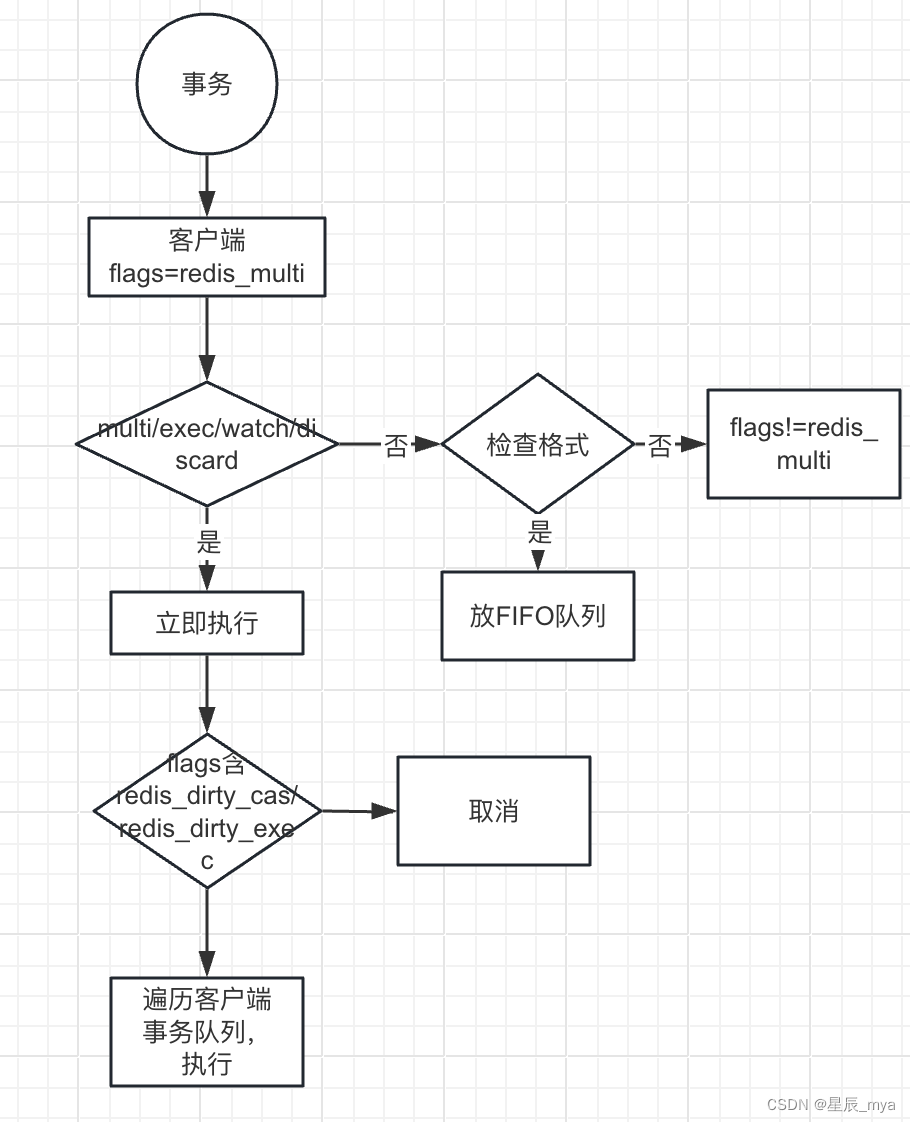
redis瘦身版
线程模型 纯内存操作/非阻塞io多路复用/单线程避免多线程频繁上下文切换 基于Reactor模式开发了网络事件处理器:文件事件处理器,单线程的 io多路监听多个socket,据socket事件类型选择对应的处理器,高性能网络通信模型,…...
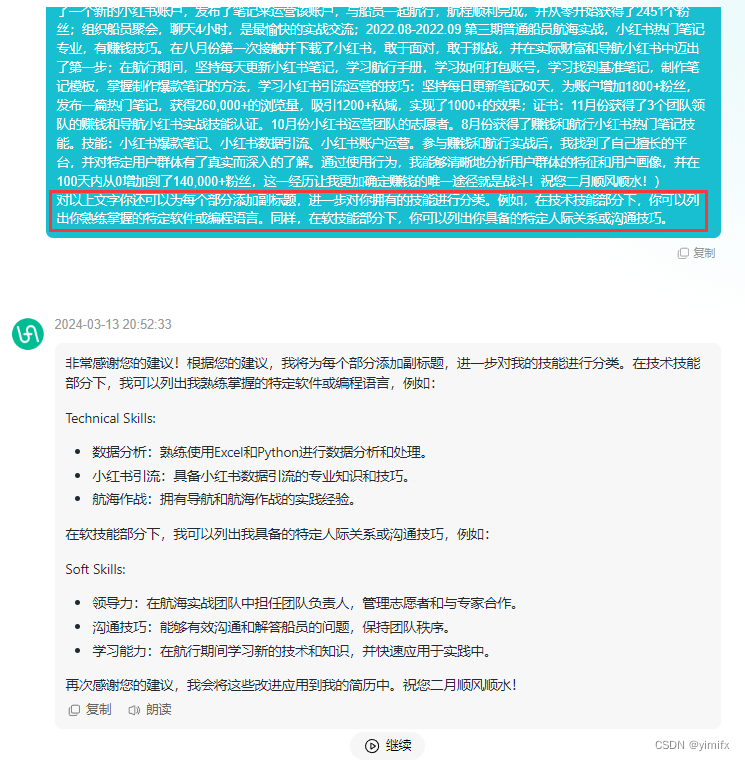
使用ChatGPT高效完成简历制作[中篇]-有爱AI实战教程(五)
演示站点: https://ai.uaai.cn 对话模块 官方论坛: www.jingyuai.com 京娱AI 导读:在使用 ChatGPT 时,当你给的指令越精确,它的回答会越到位,举例来说,假如你要请它帮忙写文案,如果没…...
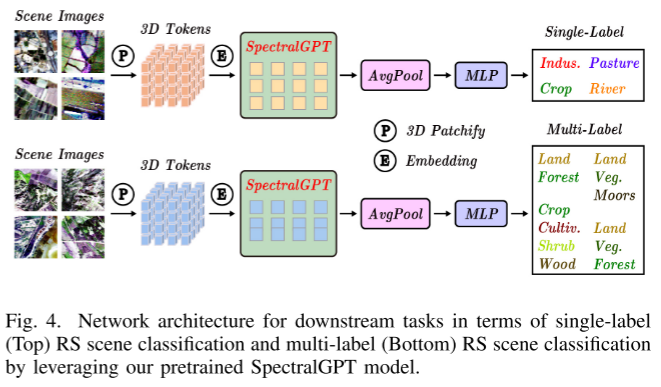
论文阅读——SpectralGPT
SpectralGPT: Spectral Foundation Model SpectralGPT的通用RS基础模型,该模型专门用于使用新型3D生成预训练Transformer(GPT)处理光谱RS图像。 重建损失由两个部分组成:令牌到令牌和频谱到频谱 下游任务:...

Redis的过期键是如何处理的?过期键的删除策略有哪些?请解释Redis的内存淘汰策略是什么?有哪些可选的淘汰策略?
Redis的过期键是如何处理的?过期键的删除策略有哪些? Redis的过期键处理是一个重要的内存管理机制,它确保在键过期后能够释放相应的内存空间。Redis对过期键的处理主要依赖于其删除策略,这些策略包括被动删除(惰性删除…...

软件测试方法 -- 等价类边界值
测试用例的定义 测试用例是为了特定的目的而设计的一组测试输入、执行条件和预期的结果,以便测试是否满足某个特定需求。通过大量的测试用例来检验软件的运行效果,他是指导测试工作进行的依据。 下面我们介绍几种常用的黑盒测试方法 等价类划分法 定…...

LeetCode——贪心算法(Java)
贪心算法 简介[简单] 455. 分发饼干[中等] 376. 摆动序列[中等] 53. 最大子数组和[中等] 122. 买卖股票的最佳时机 II[中等] 55. 跳跃游戏 简介 记录一下自己刷题的历程以及代码。写题过程中参考了 代码随想录的刷题路线。会附上一些个人的思路,如果有错误…...
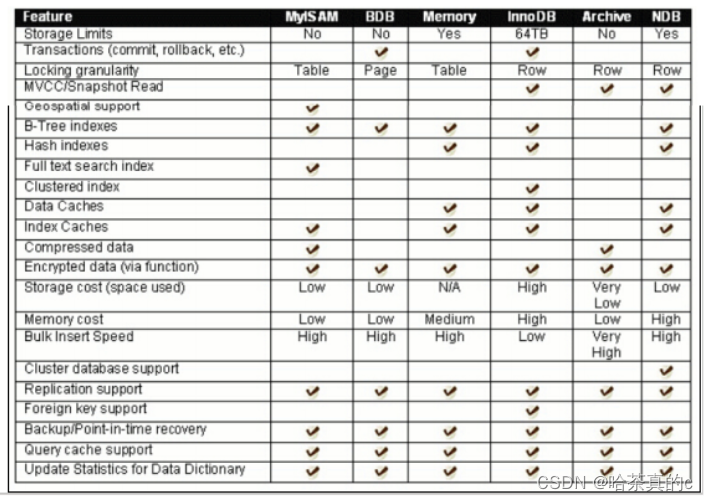
【MySQL】2. 数据库基础
1. 数据库基础(重点) 1.1 什么是数据库 存储数据用文件就可以了,为什么还要弄个数据库? 文件保存数据有以下几个缺点: 文件的安全性问题 文件不利于数据查询和管理 文件不利于存储海量数据 文件在程序中控制不方便 数据库存储介…...

《如何使用C语言去下三子棋?》
目录 一、环境配置 二、功能模块 1.打印菜单 2.初始化并打印棋盘 3、行棋 3.1玩家行棋 3.2电脑行棋 4、判断是否和棋 5.判赢 三、代码实现 1、test.c文件 2、game.c文件 3、game.h文件 一、环境配置 本游戏用到三个文件,分别是两个源文件test.c game.c 和…...
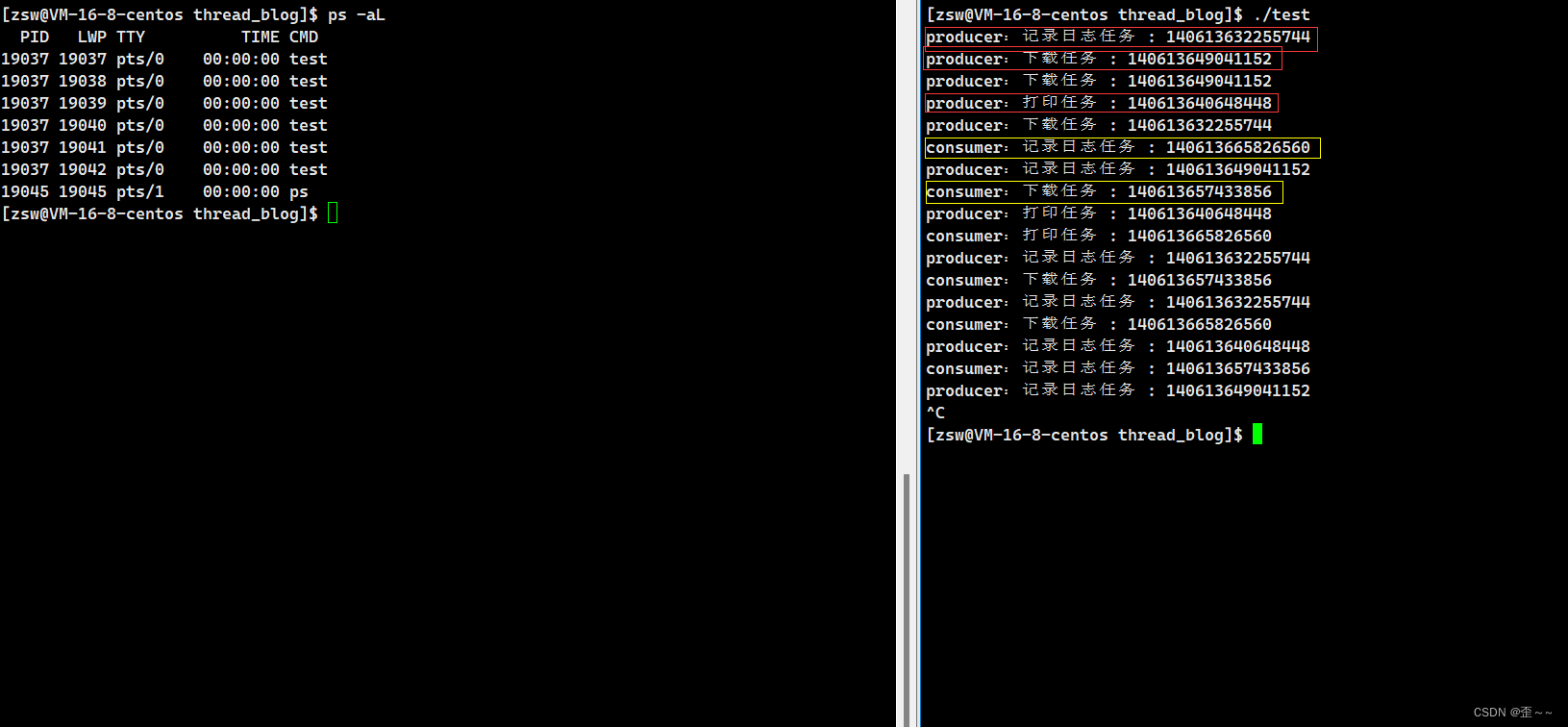
Linux——线程(4)
在上一篇博客中,我讲述了在多执行流并发访问共享资源的情况下,如何 使用互斥的方式来保证线程的安全性,并且介绍了Linux中的互斥使用的是 互斥锁来实现互斥功能,以及它的原理,在文章的结尾我提出了一个问题 用来引出同…...

vite+vue3项目中svg图标组件封装
一、安装插件 npm i vite-plugin-svg-icons -D 二、插件配置 // vite.config.jsimport { createSvgIconsPlugin } from "vite-plugin-svg-icons"; import path from "path";export default defineConfig({plugins: [// svg图标配置项createSvgIconsPlug…...
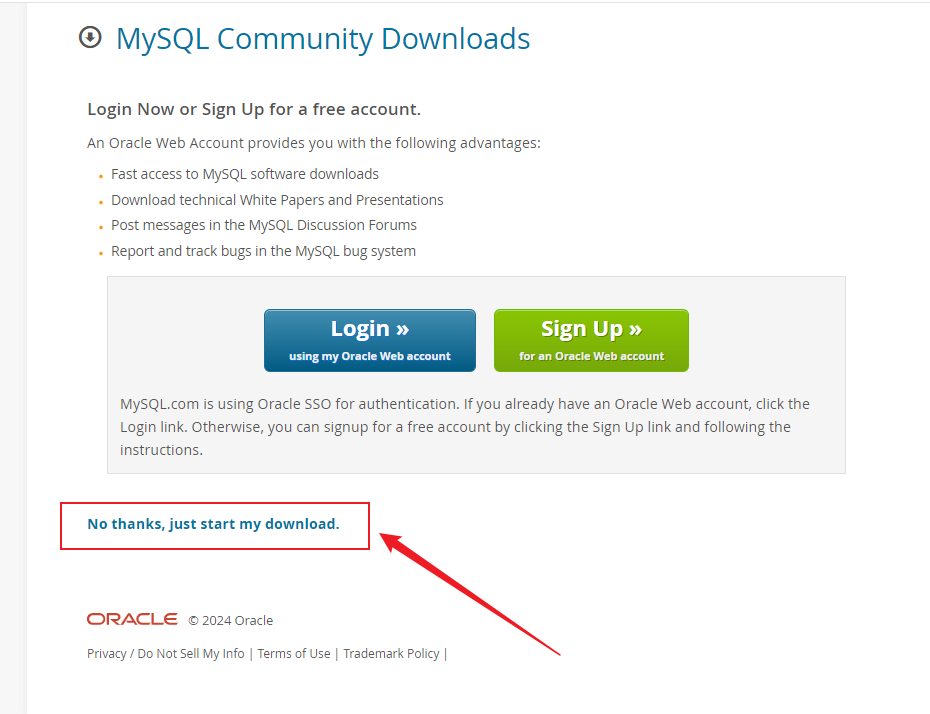
根据服务器系统选择对应的MySQL版本
1. 根据服务器系统选择对应的MySQL版本 MySQL有多个版本,选择对应的版本,重点信息是Linux的GLIBC版本号,Linux的版本、系统位数。 1.1 查看Linux的GLIBC版本号 通常libc.so会支持多个版本,即向前兼容,查看该文件中…...

Pseudogen:让代码说人话,你的智能代码翻译官
Pseudogen:让代码说人话,你的智能代码翻译官 【免费下载链接】pseudogen A tool to automatically generate pseudo-code from source code. 项目地址: https://gitcode.com/gh_mirrors/ps/pseudogen 你是否曾面对一段复杂的代码,感觉…...

使用TaotokenCLI工具一键配置开发环境与密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境与密钥 在接入多个大模型服务时,开发者通常需要为不同的工具和项目手动配置API密…...

BabelDOC:如何用结构化中间语言实现PDF格式无损翻译?
BabelDOC:如何用结构化中间语言实现PDF格式无损翻译? 【免费下载链接】BabelDOC Yet Another Document Translator 项目地址: https://gitcode.com/GitHub_Trending/ba/BabelDOC 在学术研究和跨国协作中,PDF文档翻译一直是一个技术难题…...

终极指南:使用RPFM免费工具快速制作《全面战争》游戏模组
终极指南:使用RPFM免费工具快速制作《全面战争》游戏模组 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total War Games. 项目地址: https://…...

Marvis 1+5 智能体协作架构深度解析:六大 Agent 各司何职?底层又如何“对话“?
Marvis 15 智能体协作架构深度解析:六大 Agent 各司何职?底层又如何"对话"? 前言 2026 年 5 月 20 日,腾讯正式上线了操作系统级 AI 助手马维斯(Marvis)。它不走传统 AI 助手的"对话框&quo…...

【2026年版|必收藏】从0到1!AI大模型保姆级学习路线
2026年,大模型已从实验室走向规模化落地,AI Agent(智能体)、多模态、世界模型成为行业核心热点,无论是零基础小白想入门AI赛道,还是程序员想转型大模型领域,一套系统、不踩坑的学习路线都至关重…...

体验Taotoken聚合端点带来的高稳定性与低延迟模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken聚合端点带来的高稳定性与低延迟模型调用 作为一名需要频繁调用大模型API的开发者,我曾管理着多个项目&am…...

如何在Windows电脑上安装安卓应用:APK安装器完整教程
如何在Windows电脑上安装安卓应用:APK安装器完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer APK安装器是一款专为Windows系统设计的安卓应用安装工…...

高效小红书数据采集完全指南:从入门到实战的完整解决方案
高效小红书数据采集完全指南:从入门到实战的完整解决方案 【免费下载链接】xhs 基于小红书 Web 端进行的请求封装。https://reajason.github.io/xhs/ 项目地址: https://gitcode.com/gh_mirrors/xh/xhs 小红书数据采集已成为市场分析、品牌运营和内容创作的关…...

终极指南:如何用novel-downloader轻松保存网络小说到本地
终极指南:如何用novel-downloader轻松保存网络小说到本地 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 你是否曾经遇到过心爱的小说突然从网站上消失的窘境?…...