mybatis-plus 的saveBatch性能分析
Mybatis-Plus 的批量保存saveBatch 性能分析
目录
- `Mybatis-Plus` 的批量保存`saveBatch` 性能分析
- 背景
- 批量保存的使用方案
- 循环插入
- 使用`PreparedStatement `预编译
- 优点:
- 缺点:
- `Mybatis-Plus `的`saveBatch`
- `Mybatis-Plus`实现真正的批量插入
- 自定义`sql`注入器
- 定义通用`mapper``CommonMapper`
- 将自定义的注入器加载到容器中
- 业务`mapper`
- 测试
- 优化
- 执行性能比较
- `rewriteBatchedStatements` 参数分析
背景
昨天同事问我,mybatis-plus 自动生成的service 里面提供的savebatch 最后生成的批量插入语句是多条insert ,而不是insert...vaues (),()的语句,这样是不是跟我们使用循环调用没区别,这样的批量插入是不是有性能问题?下面我们就此问题来进行分析一下。
批量保存的使用方案
循环插入
使用 for 循环一条一条的插入,这个方式比较简单直观,灵活,但是这个 对于大型数据集,使用for循环逐条插入数据可能会导致性能问题,特别是在网络延迟高或数据库负载大的情况下。使用for循环进行数据插入时,需要注意事务管理,确保数据的一致性和完整性。如果不适当地管理事务,可能会导致数据不一致或丢失。而且每次循环迭代都需要建立和关闭数据库连接,这可能会导致额外的数据库连接开销,影响性能。
使用PreparedStatement 预编译
使用预处理的方式进行批量插入是一种常见的优化方法,它可以显著提高插入操作的性能。
优点:
-
性能提升: 预处理可以减少每次插入操作中的数据库通信次数,从而降低了网络通信的开销,提高了插入操作的效率和性能。
-
减少数据库负载: 将多条数据组合成批量插入的方式可以减少数据库服务器的负载,降低了数据库系统的压力,有助于提高整个系统的性能。
-
减少连接开销: 预处理可以减少每次循环迭代中建立和关闭数据库连接的开销,从而节省了系统资源,提高了连接的复用率。
-
事务管理:可以将多个插入操作放在一个事务中,以确保数据的一致性和完整性,并在发生错误时进行回滚,从而保证数据的安全性。
缺点:
-
内存消耗: 将多条数据组合成批量插入的方式可能会增加内存消耗,特别是在处理大量数据时。因此,需要注意内存的使用情况,以避免内存溢出或性能下降。
-
数据格式转换: 在将数据组合成批量插入时,可能需要进行数据格式转换或数据清洗操作,这可能会增加代码的复杂度和维护成本。
-
可读性降低: 预处理方式可能会使代码结构变得复杂,降低了代码的可读性和可维护性,特别是对于一些初学者或新加入团队的开发人员来说可能会造成困扰
所以由此可见预编译方式性能较好,如果想避免内存问题的话,其实使用分批插入也可以解决这个问题。
Mybatis-Plus 的saveBatch
直接看源码
/*** 批量插入** @param entityList ignore* @param batchSize ignore* @return ignore*/@Transactional(rollbackFor = Exception.class)@Overridepublic boolean saveBatch(Collection<T> entityList, int batchSize) {String sqlStatement = getSqlStatement(SqlMethod.INSERT_ONE);return executeBatch(entityList, batchSize, (sqlSession, entity) -> sqlSession.insert(sqlStatement, entity));}/*** 执行批量操作** @param entityClass 实体类* @param log 日志对象* @param list 数据集合* @param batchSize 批次大小* @param consumer consumer* @param <E> T* @return 操作结果* @since 3.4.0*/public static <E> boolean executeBatch(Class<?> entityClass, Log log, Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) {Assert.isFalse(batchSize < 1, "batchSize must not be less than one");return !CollectionUtils.isEmpty(list) && executeBatch(entityClass, log, sqlSession -> {int size = list.size();int idxLimit = Math.min(batchSize, size);int i = 1;for (E element : list) {consumer.accept(sqlSession, element);if (i == idxLimit) {sqlSession.flushStatements();idxLimit = Math.min(idxLimit + batchSize, size);}i++;}});}通过代码可以发现2个点,第一个就是批量保存的时候会默认进行分批,每批的大小为1000条数据;第二点就是通过代码
return executeBatch(entityList, batchSize, (sqlSession, entity) -> sqlSession.insert(sqlStatement, entity));
和
for (E element : list) {consumer.accept(sqlSession, element);if (i == idxLimit) {sqlSession.flushStatements();idxLimit = Math.min(idxLimit + batchSize, size);}i++;}
可以看出插入是循环插入,并没有进行拼接处理。但是这里唯一不同与循环插入的是可以看到这里是通过sqlSession.flushStatements()将一个个单条插入的insert语句分批次进行提交,用的是同一个sqlSession。
这里其实就可以看出来mybatis-plus的批量插入实际上不是真正意义上的批量插入。那如果想实现真正的批量插入就只能手动拼接脚本吗?其实mybatis-plus提供了sql注入器,我们可以自定义方法来满足业务的实际开发需求。官方文档:https://baomidou.com/pages/42ea4a/

Mybatis-Plus实现真正的批量插入
自定义sql注入器
/*** @author leo* @date 2024年03月13日 15:16*/
public class BatchSqlInjector extends DefaultSqlInjector {@Overridepublic List<AbstractMethod> getMethodList(Class<?> mapperClass, TableInfo tableInfo) {List<AbstractMethod> methodList = super.getMethodList(mapperClass,tableInfo);//更新时自动填充的字段,不用插入值methodList.add(new InsertBatchSomeColumn(i -> i.getFieldFill() != FieldFill.UPDATE));return methodList;}
}
定义通用mapper``CommonMapper
/*** @author leo* @date 2024年03月13日 16:34*/
public interface CommonMapper<T> extends BaseMapper<T> {/*** 真正的批量插入* @param entityList* @return*/int insertBatch(List<T> entityList);
}
将自定义的注入器加载到容器中
/*** @author leo* @date 2024年03月13日 15:41*/
@Configuration
public class MybatisPlusConfig {@Beanpublic BatchSqlInjector sqlInjector() {return new BatchSqlInjector();}
}业务mapper
/**** @author leo* @since 2024-01-11*/
public interface LlfInfoMapper extends CommonMapper<LlfInfoEntity> {}
测试
List<LlfInfoEntity> llfInfoEntities = new ArrayList<>();for (int i = 0; i <= 10; i++) {LlfInfoEntity llfInfoEntity = new LlfInfoEntity();llfInfoEntity.setChannelNum(i + "");llfInfoEntity.setGroupNumber(i+"");llfInfoEntity.setFlight(i+1);llfInfoEntity.setIdNumber(i+"sadsadsad");llfInfoEntities.add(llfInfoEntity);}llfInfoMapper.insertBatch(llfInfoEntities);
这里我们看下控制台打印的语句:

很明显,达到了我们的效果。
优化
这里可以看到InsertBatchSomeColumn 方法没有批次的概念,如果没有批次的话,那这里地方可能会有性能问题,你想想如果这个条数无穷大的话,我那这个sql语句会非常大,不仅会超出mysql的执行sql的长度限制,也会造成oom。那么这里我们就需要自己实现一下批次插入了,不知道大家还有没有印象前面的saveBatch()方法是怎么实现批次插入的。我们也可以参考一下实现方式。直接上代码
public boolean executeBatch(Collection<LlfInfoEntity> list, int batchSize) {int size = list.size();int idxLimit = Math.min(batchSize, size);int i = 1;List<LlfInfoEntity> batchList = new ArrayList<>();for (LlfInfoEntity element : list) {batchList.add(element);if (i == idxLimit) {llfInfoMapper.insertBatchSomeColumn(batchList);batchList.clear();idxLimit = Math.min(idxLimit + batchSize, size);}i++;}return true;}
测试代码:
List<LlfInfoEntity> llfInfoEntities = new ArrayList<>();for (int i = 0; i <= 10; i++) {LlfInfoEntity llfInfoEntity = new LlfInfoEntity();llfInfoEntity.setChannelNum(i + "");llfInfoEntity.setGroupNumber(i + "");llfInfoEntity.setFlight(i + 1);llfInfoEntity.setIdNumber(i + "sadsadsad");llfInfoEntities.add(llfInfoEntity);}executeBatch(llfInfoEntities,5);看执行结果:

这里就实现了真正的批量插入了。
执行性能比较
这里我就不去具体展现测试数据了,直接下结论了。
首先最快的肯定是手动拼sql脚本和mybatis-plus的方式速度最快,其次是mybatis-plus的saveBatch。这里要说下有很多文章都说需要单独配置rewriteBatchedStatements参数,才会启用saveBatch的批量插入方式。但是我这边跟进源码进行查看的时候默认值就是true,所以我猜测可能是版本问题,下面会附上版本以及源码供大家参考。
rewriteBatchedStatements 参数分析
首选我们通过com.baomidou.mybatisplus.extension.toolkit.SqlHelper#executeBatch(java.lang.Class<?>, org.apache.ibatis.logging.Log, java.util.Collection<E>, int, java.util.function.BiConsumer<org.apache.ibatis.session.SqlSession,E>)l里面的sqlSession.flushStatements();代码可以跟踪到,mysql驱动包里面的com.mysql.cj.jdbc.StatementImpl#executeBatch下面这段代码
@Overridepublic int[] executeBatch() throws SQLException {return Util.truncateAndConvertToInt(executeBatchInternal());}protected long[] executeBatchInternal() throws SQLException {JdbcConnection locallyScopedConn = checkClosed();synchronized (locallyScopedConn.getConnectionMutex()) {if (locallyScopedConn.isReadOnly()) {throw SQLError.createSQLException(Messages.getString("Statement.34") + Messages.getString("Statement.35"),MysqlErrorNumbers.SQL_STATE_ILLEGAL_ARGUMENT, getExceptionInterceptor());}implicitlyCloseAllOpenResults();List<Object> batchedArgs = this.query.getBatchedArgs();if (batchedArgs == null || batchedArgs.size() == 0) {return new long[0];}// we timeout the entire batch, not individual statementsint individualStatementTimeout = getTimeoutInMillis();setTimeoutInMillis(0);CancelQueryTask timeoutTask = null;try {resetCancelledState();statementBegins();try {this.retrieveGeneratedKeys = true; // The JDBC spec doesn't forbid this, but doesn't provide for it either...we do..long[] updateCounts = null;if (batchedArgs != null) {int nbrCommands = batchedArgs.size();this.batchedGeneratedKeys = new ArrayList<>(batchedArgs.size());boolean multiQueriesEnabled = locallyScopedConn.getPropertySet().getBooleanProperty(PropertyKey.allowMultiQueries).getValue();if (multiQueriesEnabled || this.rewriteBatchedStatements.getValue() && nbrCommands > 4) {return executeBatchUsingMultiQueries(multiQueriesEnabled, nbrCommands, individualStatementTimeout);}timeoutTask = startQueryTimer(this, individualStatementTimeout);updateCounts = new long[nbrCommands];for (int i = 0; i < nbrCommands; i++) {updateCounts[i] = -3;}SQLException sqlEx = null;int commandIndex = 0;for (commandIndex = 0; commandIndex < nbrCommands; commandIndex++) {try {String sql = (String) batchedArgs.get(commandIndex);updateCounts[commandIndex] = executeUpdateInternal(sql, true, true);if (timeoutTask != null) {// we need to check the cancel state on each iteration to generate timeout exception if neededcheckCancelTimeout();}// limit one generated key per OnDuplicateKey statementgetBatchedGeneratedKeys(this.results.getFirstCharOfQuery() == 'I' && containsOnDuplicateKeyInString(sql) ? 1 : 0);} catch (SQLException ex) {updateCounts[commandIndex] = EXECUTE_FAILED;if (this.continueBatchOnError && !(ex instanceof MySQLTimeoutException) && !(ex instanceof MySQLStatementCancelledException)&& !hasDeadlockOrTimeoutRolledBackTx(ex)) {sqlEx = ex;} else {long[] newUpdateCounts = new long[commandIndex];if (hasDeadlockOrTimeoutRolledBackTx(ex)) {for (int i = 0; i < newUpdateCounts.length; i++) {newUpdateCounts[i] = java.sql.Statement.EXECUTE_FAILED;}} else {System.arraycopy(updateCounts, 0, newUpdateCounts, 0, commandIndex);}sqlEx = ex;break;//throw SQLError.createBatchUpdateException(ex, newUpdateCounts, getExceptionInterceptor());}}}if (sqlEx != null) {throw SQLError.createBatchUpdateException(sqlEx, updateCounts, getExceptionInterceptor());}}if (timeoutTask != null) {stopQueryTimer(timeoutTask, true, true);timeoutTask = null;}return (updateCounts != null) ? updateCounts : new long[0];} finally {this.query.getStatementExecuting().set(false);}} finally {stopQueryTimer(timeoutTask, false, false);resetCancelledState();setTimeoutInMillis(individualStatementTimeout);clearBatch();}}}我们主要核心看一下这个代码:
if (multiQueriesEnabled || this.rewriteBatchedStatements.getValue() && nbrCommands > 4) {return executeBatchUsingMultiQueries(multiQueriesEnabled, nbrCommands, individualStatementTimeout);}
能进入if语句,并执行批处理方法 executeBatchUsingMultiQueryies 的条件如下:
allowMultiQueries = truerewriteBatchedStatements=true- 数据总条数 > 4条
PropertyKey.java中定义了 multiQueriesEnables和 rewriteBatchedStatements 的枚举值,com.mysql.cj.conf.PropertyKey如下:


可以看出这个参数都是true。所以我这边默认就是支持批量操作的。
mybatis-plus 版本:3.5.10
mysql-connector-java版本:8.0.31
Queryies` 的条件如下:
allowMultiQueries = truerewriteBatchedStatements=true- 数据总条数 > 4条
PropertyKey.java中定义了 multiQueriesEnables和 rewriteBatchedStatements 的枚举值,com.mysql.cj.conf.PropertyKey如下:
[外链图片转存中…(img-nwh8oV0y-1710751858305)]
[外链图片转存中…(img-AmPKylvo-1710751858305)]
可以看出这个参数都是true。所以我这边默认就是支持批量操作的。
mybatis-plus 版本:3.5.10
mysql-connector-java版本:8.0.31
相关文章:
mybatis-plus 的saveBatch性能分析
Mybatis-Plus 的批量保存saveBatch 性能分析 目录 Mybatis-Plus 的批量保存saveBatch 性能分析背景批量保存的使用方案循环插入使用PreparedStatement 预编译优点:缺点: Mybatis-Plus 的saveBatchMybatis-Plus实现真正的批量插入自定义sql注入器定义通用…...

python异常:pythonIOError异常python打开文件异常
1.python读取不存在的文件时,抛出异常 通过 open()方法以读“r”的方式打开一个 abc.txt 的文件(该文件不存在),执行 open()打开一个不存在的文件时会抛 IOError 异常,通过 Python 所提供的 try...except...语句来接收…...

电话机器人语音识别用哪家更好精准度更高。
语音识别系统的选择取决于你的具体需求,包括但不限于识别精度、速度、易用性、价格等因素。以下是一些在语音识别领域表现较好的公司和产品: 科大讯飞:科大讯飞是中国最大的语音识别技术提供商之一,其语音识别技术被广泛应用于各…...
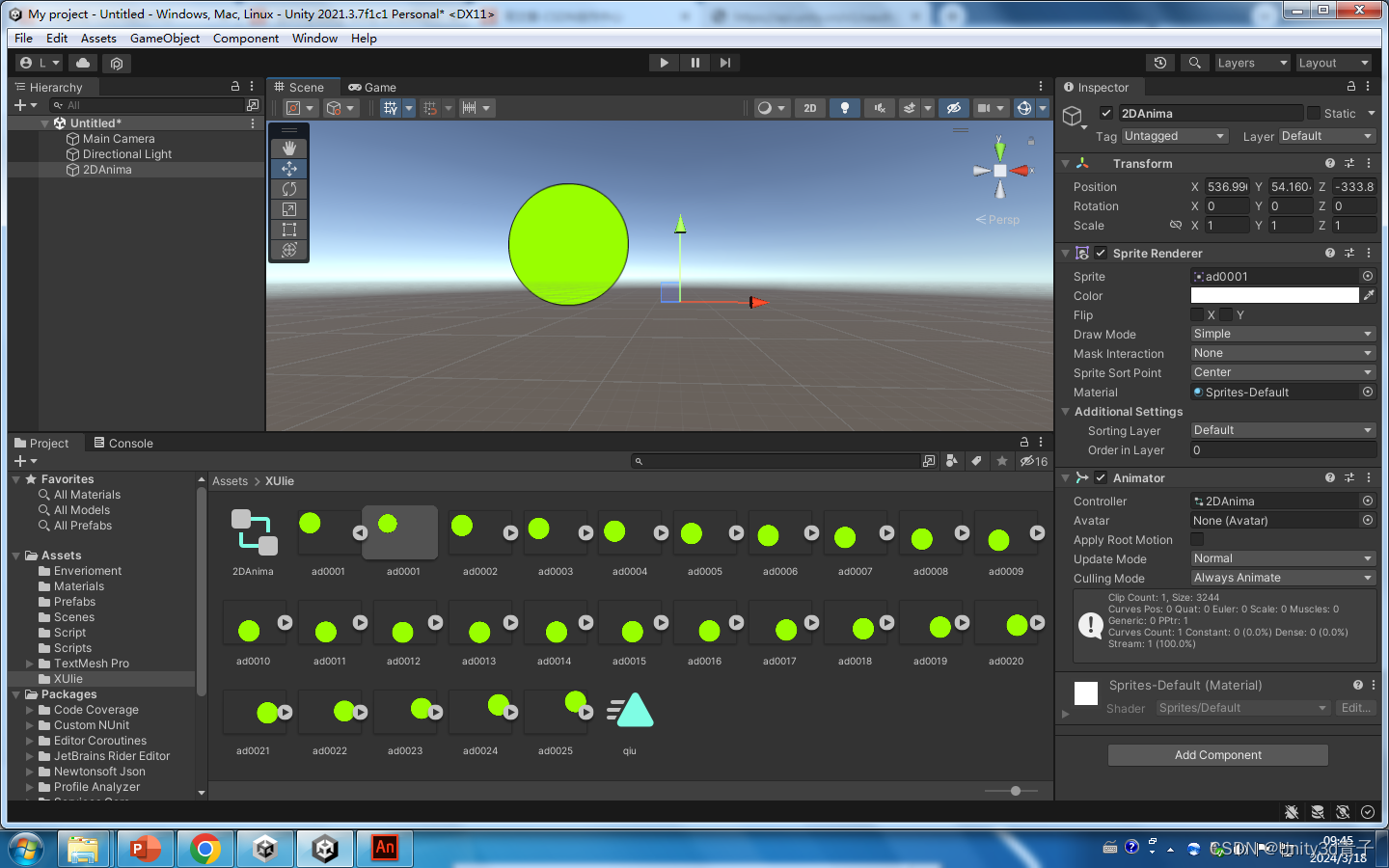
【Unity动画】Unity如何导入序列帧动画(GIF)
Unity 不支持GIF动画的直接播放,我们需要使用序列帧的方式 01准备好序列帧 02全部拖到Unity 仓库文件夹中 03全选修改成精灵模式Sprite 2D ,根据需要修改尺寸,点击Apply 04 创建一个空物体 拖动序列上去 然后全选所有序列帧,拖到这个空物体…...

uniapp APP 上传文件
/*** 上传文件*/uploadPhoneFile:function(callback,params {}) {let fileType [.pdf,.doc,.xlsx,.docx,.xls]// #ifdef APP-PLUSplus.io.chooseFile({title: 选择文件, filetypes: [doc, docx], // 允许的文件类型 multiple: false, // 是否允许多选 },(e)>{const tem…...
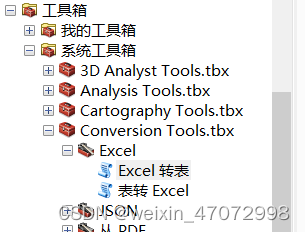
arcgis数据导出到excel
将arcgis属性数据导出到excel: 1) 工具箱\系统工具箱\Conversion Tools.tbx\Excel\Excel 转表 2)用excel打开导出的图层文件中后缀为.dbf的数据(方便快捷,但是中文易乱码)...

吴恩达深度学习环境本地化构建wsl+docker+tensorflow+cuda
Tensorflow2 on wsl using cuda 动机环境选择安装步骤1. WSL安装2. docker安装2.1 配置Docker Desktop2.2 WSL上的docker使用2.3 Docker Destop的登陆2.4 测试一下 3. 在WSL上安装CUDA3.1 Software list needed3.2 [CUDA Support for WSL 2](https://docs.nvidia.com/cuda/wsl-…...

R语言:microeco:一个用于微生物群落生态学数据挖掘的R包:第七:trans_network class
# 网络是研究微生物生态共现模式的常用方法。在这一部分中,我们描述了trans_network类的所有核心内容。 # 网络构建方法可分为基于关联的和非基于关联的两种。有几种方法可以用来计算相关性和显著性。 #我们首先介绍了基于关联的网络。trans_network中的cal_cor参数…...

ubuntu下在vscode中配置matplotlibcpp
ubuntu下在vscode中配置matplotlibcpp 系统:ubuntu IDE:vscode 库:matplotlib-cpp matplotlibcpp.h文件可以此网址下载:https://github.com/lava/matplotlib-cpp 下载的压缩包中有该头文件,以及若干实例程序。 参考…...

Vue面试题,背就完事了
1.vue的生命周期有哪些及每个生命周期做了什么? Vue.js 的生命周期可以分为以下几个核心阶段,每个阶段都伴随着特定的钩子函数(生命周期钩子)来执行相应的操作: 创建阶段: beforeCreate:实例被创建后、数…...
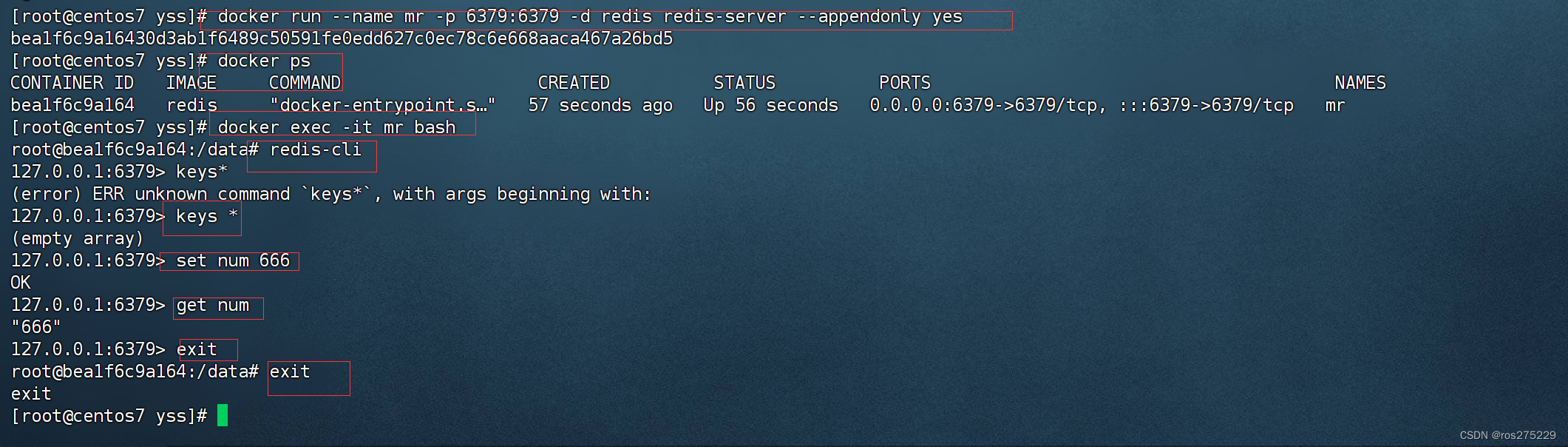
centos创建并运行一个redis容器 并支持数据持久化
步骤 : 创建redis容器命令 docker run --name mr -p 6379:6379 -d redis redis-server --appendonly yes 进入容器 : docker exec -it mr bash 链接redis : redis-cli 查看数据 : keys * 存入一个数据 : set num 666 获取数据 : get num 退出客户端 : exit 再退…...
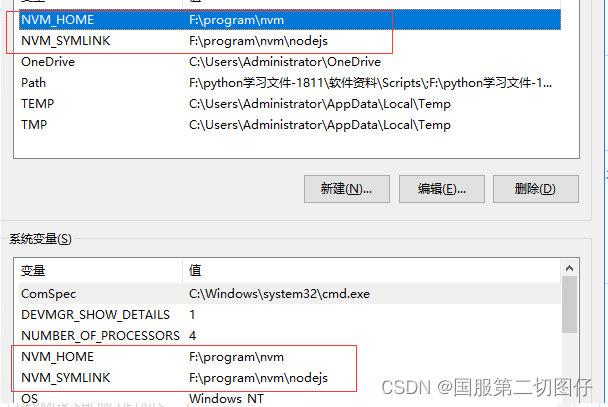
nvm安装和使用保姆级教程(详细)
一、 nvm是什么 : nvm全英文也叫node.js version management,是一个nodejs的版本管理工具。nvm和npm都是node.js版本管理工具,为了解决node.js各种版本存在不兼容现象可以通过它可以安装和切换不同版本的node.js。 二、卸载之前安装的node: …...
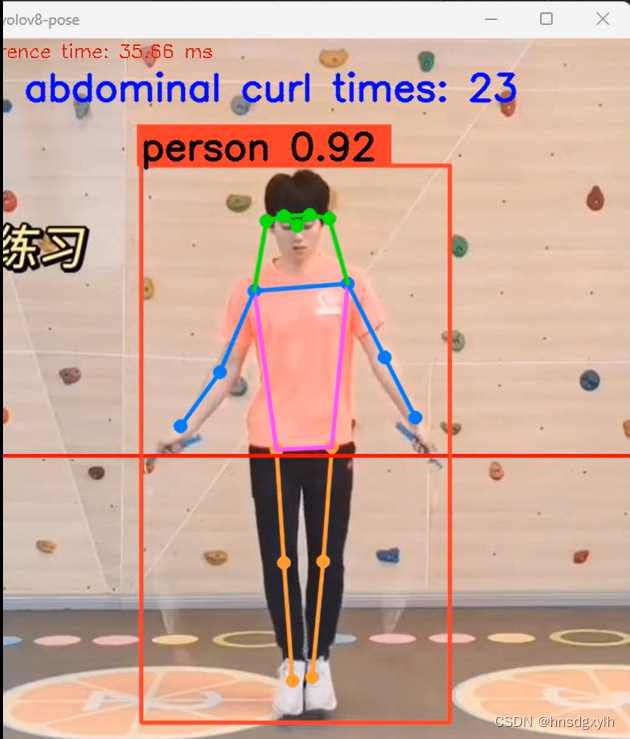
跳绳计数,YOLOV8POSE
跳绳计数,YOLOV8POSE 通过计算腰部跟最初位置的上下波动,计算跳绳的次数...

阿里云ecs服务器配置反向代理上传图片
本文所有软件地址: 链接:https://pan.baidu.com/s/12OSFilS-HNsHeXTOM47iaA 提取码:dqph 为什么要使用阿里云服务器? 项目想让别人通过外网进行访问就需要部署到我们的服务器当中 1.国内知名的服务器介绍 国内比较知名的一些…...

免费阅读篇 | 芒果YOLOv8改进110:注意力机制GAM:用于保留信息以增强渠道空间互动
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可 该专栏完整目录链接: 芒果YOLOv8深度改进教程 该篇博客为免费阅读内容,直接改进即可🚀🚀…...
返回值及含义)
GetLastError()返回值及含义
https://www.cnblogs.com/ericsun/archive/2012/08/10/2631808.html 〖0〗-操作成功完成。 〖1〗-功能错误。 〖2〗-系统找不到指定的文件。 〖3〗-系统找不到指定的路径。 〖4〗-系统无法打开文件。 〖5〗-拒绝访问。 〖6〗-句柄无效。 〖7〗-存储控制块被损坏。 〖8〗-存储空…...

k8s admin 用户生成token
k8s 版本 1.28 创建一个admin的命名空间 admin-namespce.yaml kind: Namespace apiVersion: v1 metadata: name: admin labels: name: admin 部署进k8s kubectl apply -f admin-namespce.yaml 查看k8s namespace 的列表 kubectl get namespace查看当前生效的…...
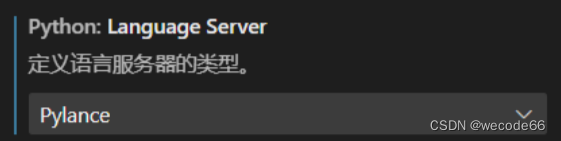
【vscode】vscode重命名变量后多了很多空白行
这种情况,一般出现在重新安装 vscode 后出现。 原因大概率是语言服务器没设置好或设置对。 以 Python 为例,到设置里搜索 "python.languageServer",将 Python 的语言服务器设置为 Pylance 即可。...
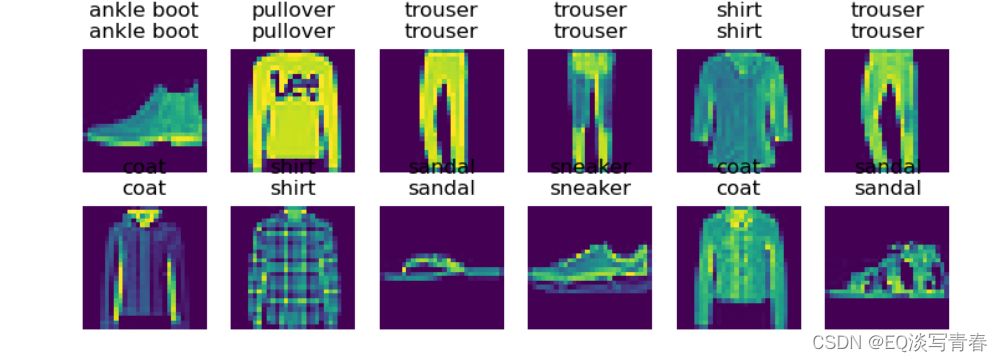
深度学习实战模拟——softmax回归(图像识别并分类)
目录 1、数据集: 2、完整代码 1、数据集: 1.1 Fashion-MNIST是一个服装分类数据集,由10个类别的图像组成,分别为t-shirt(T恤)、trouser(裤子)、pullover(套衫…...
vue实现element-UI中table表格背景颜色设置
目前在style中设置不了,那么就在前面组件给设置上 :header-cell-style"{ color: #ffffff, fontSize: 14px, backgroundColor: #0E2152 }" :cell-style"{ color: #ffffff, fontSize: 14px, backgroundColor: #0E2152 }"...

工业AI落地:自定义数据集与交叉验证的动态选择策略
1. 这不是选择题,而是控制权与可信度的平衡术你手头刚攒够2000张标注好的工业缺陷图,模型在验证集上跑出了92.3%的准确率——但上线三天后,产线新批次的钢板表面反光角度变了,准确率直接掉到68%。或者,你用sklearn的St…...

校园项目 / 课程设计:如何包装成求职加分项
前言:你的校园项目,是不是写得像“课程作业汇报”? “完成课程设计《图书管理系统》,使用Java+MySQL开发,实现增删改查功能”——如果你还在这么写校园项目,恭喜你!成功加入“HR扫一眼就划走”豪华套餐。 现在的求职市场卷成什么样?某互联网大厂HR透露:“每天收到50…...

深度学习的缺失数据革命:使用MIDAS实现高效多重插补
深度学习的缺失数据革命:使用MIDAS实现高效多重插补 【免费下载链接】MIDAS Multiple imputation utilising denoising autoencoder for approximate Bayesian inference 项目地址: https://gitcode.com/gh_mirrors/midas3/MIDAS 在数据科学和机器学习领域&a…...
)
告别野指针和内存泄漏:用Cppcheck给你的C/C++项目做个免费‘体检’(附VS项目集成教程)
用Cppcheck为C/C项目构建自动化代码质量防护网 在软件开发领域,代码质量直接影响着产品的稳定性和安全性。对于C/C这类系统级语言来说,内存泄漏、野指针等问题往往潜伏在代码深处,直到运行时才突然爆发。而静态代码分析工具就像一位经验丰富的…...

Poppler Windows版:终极PDF处理方案,3分钟零配置部署指南
Poppler Windows版:终极PDF处理方案,3分钟零配置部署指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 还在为Windows上复…...

基于 Git Flow 的团队协作与发布流程实践
在软件开发过程中,随着团队规模扩大、需求频繁迭代以及线上版本持续演进,如何管理代码分支成为影响研发效率的重要问题。上图展示的是一种经典的 Git 分支管理模型 —— Git Flow。 它通过明确的分支职责与合并策略,实现:功能开发…...

工厂MES数据自动采集怎样用AI完成?资深架构师的非侵入式集成落地指南
摘要: 我是架构师老王。在2026年工业数字化转型的深水区,工厂MES数据自动采集已不再是简单的“连线接口”,而是演变为一场关于“感知、决策与执行”的架构革命。面对老旧系统API缺失、烟囱式架构林立以及信创环境下严苛的安全合规要求&#x…...

Taotoken多模型路由在单一服务故障时的体验保障
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken多模型路由在单一服务故障时的体验保障 1. 引言 在构建依赖大模型能力的应用时,服务的稳定性是开发者必须面对…...

SpringBoot-Scan:面向红队的SpringBoot资产指纹与测绘工作流
1. 这不是又一个“SpringBoot漏洞扫描器”教程,而是一份真实红队队员的资产测绘工作流你有没有遇到过这样的情况:手头刚拿到一个目标域名,技术栈标注着“SpringBoot 2.7.x”,但连它到底跑在哪个端口、是否启用了Actuator、有没有暴…...

不止于编译:深入OpenWifi驱动与内核的版本绑定机制,及如何管理你的SDRPi镜像
深入OpenWifi驱动与内核的版本绑定机制:SDRPi镜像管理的工程化实践 在嵌入式Linux开发中,内核与驱动的版本一致性往往成为项目长期维护的隐形陷阱。当我们使用SDRPi运行OpenWifi这样的复杂系统时,一个看似简单的内核更新就可能导致整套无线功…...