爬虫技术实战案例解析
目录
前言
案例背景
案例实现
案例总结
结语

前言
作者简介: 懒大王敲代码,计算机专业应届生
今天给大家聊聊爬虫技术实战案例解析,希望大家能觉得实用!
欢迎大家点赞 👍 收藏 ⭐ 加关注哦!💖💖个人主页:
懒大王敲代码-CSDN博客
https://blog.csdn.net/weixin_58070962?type=blog
其他专栏:
技术分享专栏

在当今信息化社会,网络爬虫技术以其强大的数据抓取能力,在各行各业得到了广泛应用。无论是商业智能分析、竞争对手监测,还是学术研究、数据挖掘,爬虫技术都发挥着不可或缺的作用。本文将通过一个具体的爬虫实战案例,深入剖析爬虫技术的实现过程,并结合代码案例进行详细讲解。
案例背景
假设我们是一家电商公司的数据分析团队,需要对竞争对手的商品价格、销量等信息进行持续监控。为了实现这一目标,我们决定采用爬虫技术,自动抓取竞争对手网站上的商品数据。
案例实现
- 目标网站分析
在开始编写爬虫之前,我们需要对目标网站进行分析,确定其网页结构、数据格式以及反爬虫机制等。通过浏览目标网站的商品页面,我们发现商品信息主要包含在HTML标签中,且页面采用了Ajax动态加载的方式。此外,网站还设置了访问频率限制和验证码验证等反爬虫机制。
- 爬虫框架选择
考虑到目标网站的复杂性和反爬虫机制,我们选择使用Scrapy框架来构建我们的爬虫。Scrapy是一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试,信息处理和历史档案等大量应用。
- 编写爬虫代码
(1)创建Scrapy项目
首先,我们需要使用Scrapy命令行工具创建一个新的Scrapy项目。在终端中执行以下命令:
bash
scrapy startproject myspider
cd myspider(2)定义爬虫结构
在myspider项目的spiders目录下,创建一个新的Python文件,如competitor_spider.py,用于定义我们的爬虫。在该文件中,我们需要导入必要的模块,并定义一个继承自scrapy.Spider的爬虫类。
python
import scrapy
from scrapy.http import FormRequest
from myspider.items import CompetitorItem class CompetitorSpider(scrapy.Spider): name = 'competitor' allowed_domains = ['competitor.com'] start_urls = ['http://competitor.com/products'] def parse(self, response): # 解析商品列表页面,提取商品链接 product_links = response.css('a.product-link::attr(href)').getall() for link in product_links: yield scrapy.Request(url=response.urljoin(link), callback=self.parse_product) def parse_product(self, response): # 解析商品详情页面,提取商品信息 item = CompetitorItem() item['name'] = response.css('h1.product-name::text').get() item['price'] = response.css('span.product-price::text').get() item['sales'] = response.css('span.product-sales::text').get() yield item在上面的代码中,我们定义了一个名为CompetitorSpider的爬虫类。在parse方法中,我们解析商品列表页面,提取出每个商品的链接,并发送请求到这些链接对应的商品详情页面。在parse_product方法中,我们解析商品详情页面,提取出商品的名称、价格和销量等信息,并将其保存到一个CompetitorItem对象中。
(3)处理反爬虫机制
针对目标网站的反爬虫机制,我们需要采取一些措施来绕过这些限制。例如,我们可以设置合理的请求间隔,避免过于频繁的访问;对于验证码验证,我们可以使用图像识别技术来自动填写验证码;对于Ajax动态加载的内容,我们可以使用Scrapy的FormRequest或Selenium等工具来模拟浏览器行为,触发Ajax请求并获取数据。
在本案例中,我们假设目标网站设置了访问频率限制。为了遵守这一限制,我们可以在Scrapy的设置文件中设置DOWNLOAD_DELAY参数来控制请求间隔。此外,我们还可以使用Scrapy的AutoThrottle扩展来自动调整请求间隔,以适应目标网站的负载情况。
(4)运行爬虫并保存数据
完成爬虫代码编写后,我们可以使用Scrapy命令行工具来运行爬虫并保存数据。在终端中执行以下命令:
bash
scrapy crawl competitor -o output.csv上述命令将启动名为competitor的爬虫,并将抓取到的数据保存为CSV格式的文件output.csv。当然,Scrapy还支持将数据保存为其他格式,如JSON、XML等,具体可以根据需求进行设置。
案例总结
通过本案例的实战演练,我们深入了解了爬虫技术的实现过程,包括目标网站分析、爬虫框架选择、代码编写以及反爬虫。
结语
关于爬虫技术实战案例解析,懒大王就先分享到这里了,如果你认为这篇文章对你有帮助,请给懒大王点个赞点个关注吧,如果发现什么问题,欢迎评论区留言!!💕💕
个人主页:
懒大王敲代码-CSDN博客
其他专栏
技术分享专栏

相关文章:
爬虫技术实战案例解析
目录 前言 案例背景 案例实现 案例总结 结语 前言 作者简介: 懒大王敲代码,计算机专业应届生 今天给大家聊聊爬虫技术实战案例解析,希望大家能觉得实用! 欢迎大家点赞 👍 收藏 ⭐ 加关注哦!…...
Git 使用笔记
基本操作: 初始化 (git init) 使用背景和作用: 在本地建立一个文件夹后,基于这个文件夹进行git 操作,赋予git操作本文件夹的权限 。查看当前文件夹状态(git status) 每次打开文件夹…...

python -- 语法与变量
你好, 我是木木, 目前正在做两件事 1. 沉淀自己的专业知识 2. 探索了解各种副业项目,同时将探索过程进行分享,帮助自己以及更多朋友找到副业, 做好副业 文末有惊喜 语法的简要说明 每种语言都有自己的语法,不管是自然语言(…...

24计算机考研调剂 | 太原科技大学
2024年太原科技大学 力学专业 接收研究生调剂通告 考研调剂招生信息 招生专业: 080100(力学) 01先进材料变形行为及力学性能 02 计算力学及其应用 03结构动力学与无损检测 04复合材料断裂理论与结构设计 补充内容 调剂考生基本要求 &…...

Leetcode 204. 计数质数 java题解
https://leetcode.cn/problems/count-primes/description/ 法一 class Solution {public int countPrimes(int n) {int count0;for(int i2;i<n;i){//判断i是否质数boolean ftrue;for(int j1;j*j<i;j){//因子if(j!1&&j!i&&(i%j0)){ffalse;break;}}if(f){…...
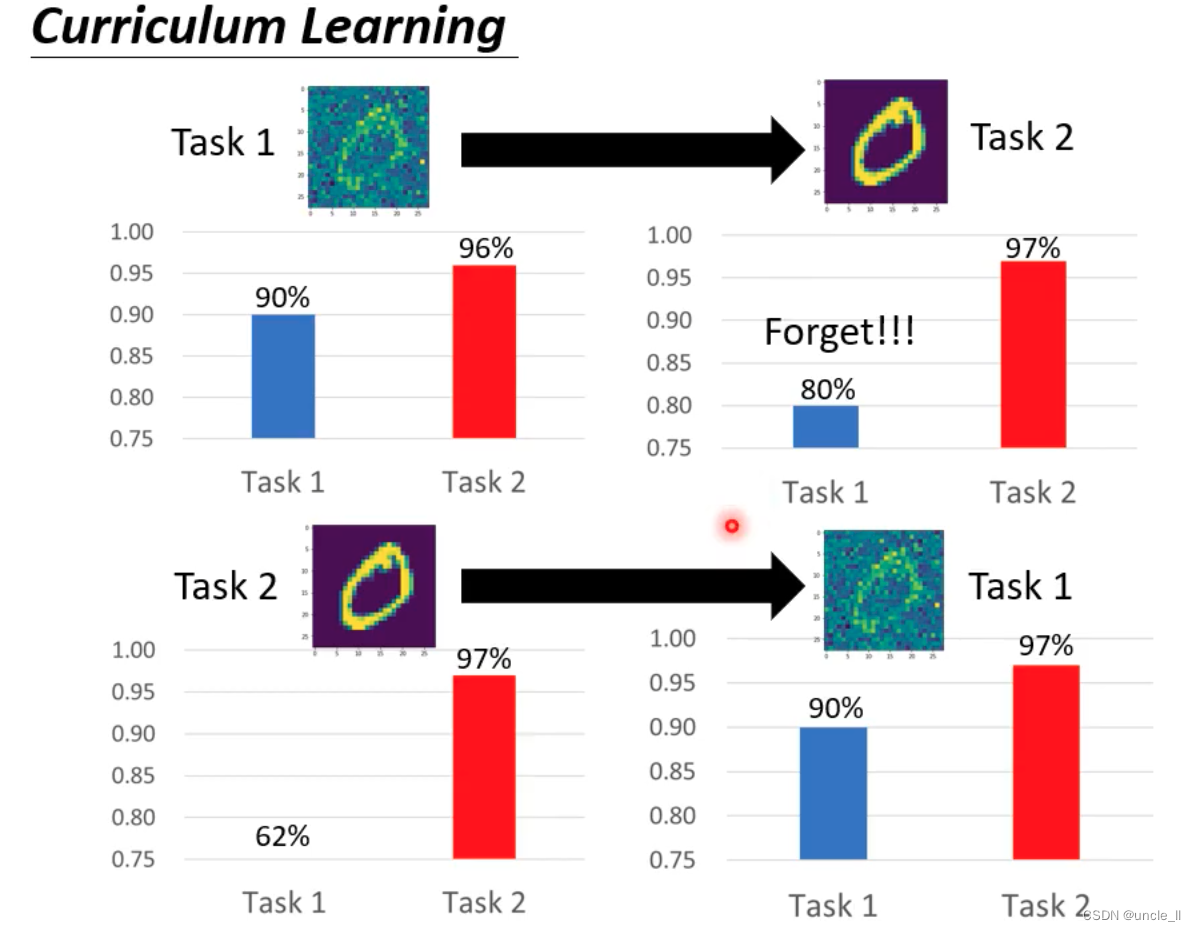
机器学习——终身学习
终身学习 AI不断学习新的任务,最终进化成天网控制人类终身学习(LLL),持续学习,永不停止的学习,增量学习 用线上收集的资料不断的训练模型 问题就是对之前的任务进行遗忘,在之前的任务上表现不好…...
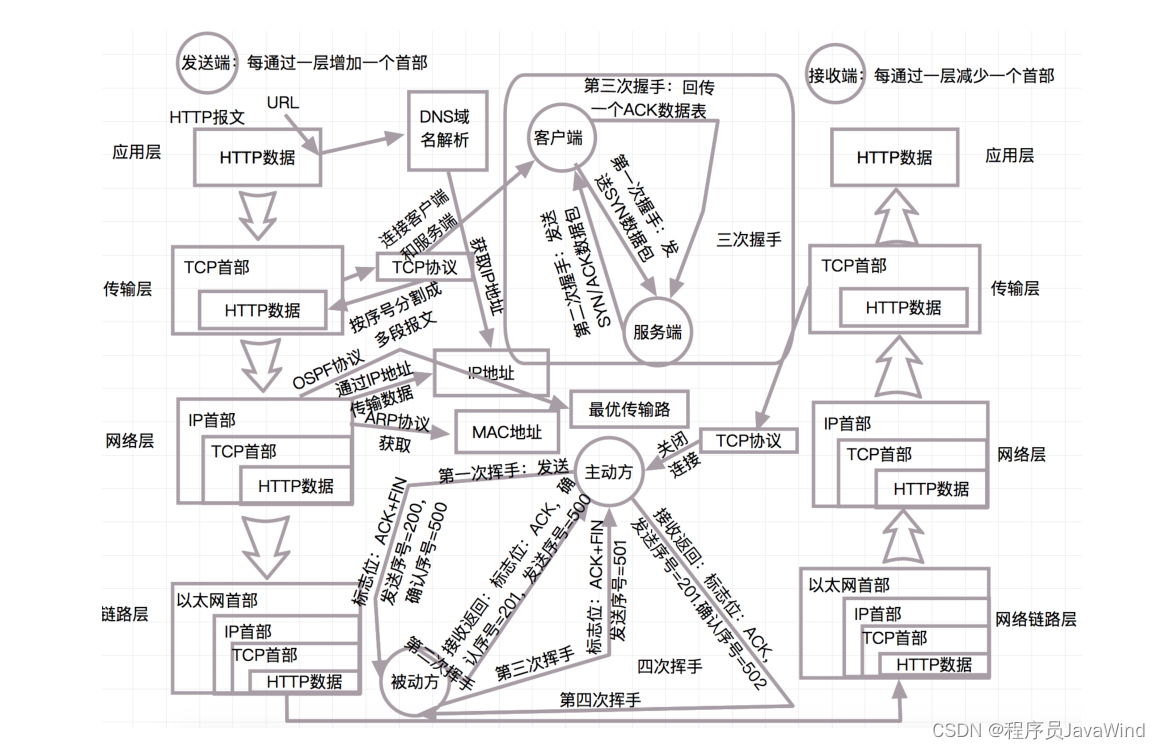
一次完整的 HTTP 请求所经历的步骤
1: DNS 解析(通过访问的域名找出其 IP 地址,递归搜索)。 2: HTTP 请求,当输入一个请求时,建立一个 Socket 连接发起 TCP的 3 次握手。如果是 HTTPS 请求,会略微有不同。 3: 客户端向服务器发…...

OpenGL学习笔记【1】——简介
一、OpenGL概念 OpenGL (Open Graphics Library,译名:开放式图形库开放式图形库) 是一种用于渲染 2D 和 3D 图形的跨语言、跨平台的编程接口(API)。 二、OpenGL跨语言 OpenGL 是一个 C 语言库,因此理解 C 语言(或 C)的…...

C语言课后作业 20 题+考研上机应用题
题目 1: 计算圆的面积 描述: 输入圆的半径,计算并输出圆的面积。 题目 2: 判断一个年份是否为闰年 描述: 输入一个年份,判断并输出该年份是否为闰年。 题目 3: 计算并输出斐波那契数列的前10个数 描述: 输出斐波那…...

macOS上基于httpd-dav搭建WebDav服务
文章目录 配置 Apache httpd修改 ServerName启动验证 httpd 服务启用 Dav 扩展服务配置 配置 httpd 扩展 Dav 服务设置共享目录文件夹配置 DavLockDB 目录创建 WebDAV 访客用户 httpd-dav.conf 主要改动部分BasicDigest共享多个目录 授予 httpd 完全磁盘访问权限验证更新配置重…...

Java-设计模式-单例模式
单例模式 从单例加载的时机区分,有懒汉模式/饥饿模式。 从实现方式区分有双重检查模式,内部类模式/Enum模式/Map模式等。在《Effective Java》中,作者提出利用Enum时实现单例模式的最佳实践。 内容概要 实现单例模式的几个关键点 利用Enu…...

图片html5提供的懒加载与vue-lazyload的区别
原生HTML lazy loading特性 <img src"/images/ocean.jpeg" alt"Ocean" loading"lazy"> loading"lazy" 是HTML5的一个原生特性,它允许浏览器延迟加载图片直至图片距离视口很近或者即将进入视口时。这是一种由浏览器…...

golang 根据某个特定字段对结构体的顺序进行排序
文章目录 方法一方法二方法三 在Go语言中,我们可以使用 sort.Slice() 函数对结构体进行排序。假设你有一个结构体,并且希望根据其中的某个字段进行排序,你可以使用自定义的排序函数。 方法一 下面是一个示例代码,假设有一个包含…...

React Router 参数使用详解
React Router 参数使用详解 React Router 是 React 中用于处理路由的常用库,它提供了丰富的功能来管理应用程序的导航和路由状态。在 React Router 中,我们经常需要使用不同类型的参数来处理路由信息,包括 params 参数、search 参数和 state…...

Vue中$set用法解析
当一个 Vue 实例被创建时,它向 Vue 的响应式系统中加入了其 data 对象中能找到的所有的属性。当这些属性的值发生改变时,视图将会产生“响应”,即匹配更新为新的值,但是遇到以下情况不会进行数据的双向绑定。 当你利用索引直接改…...

进制,码制及其表示范围
一 进制 1 常见的进制及其简写 十进制(Dec)二进制(Binary)十六进制(Hex)八进制(Octal) 2 进制之间的相互转换 二 码制 1 常用的码制 三 各码制在定点整数时表示的范围 个人推导…...

钡铼技术R40工业4G路由器加速推进农田水利设施智能化
钡铼技术R40工业4G路由器作为一种先进的通信设备,正在被广泛应用于各行各业,其中包括农田水利设施的智能化改造。通过结合钡铼技术R40工业4G路由器,农田水利设施可以实现更高效的管理和运营,提升农田灌溉、排水等工作效率…...
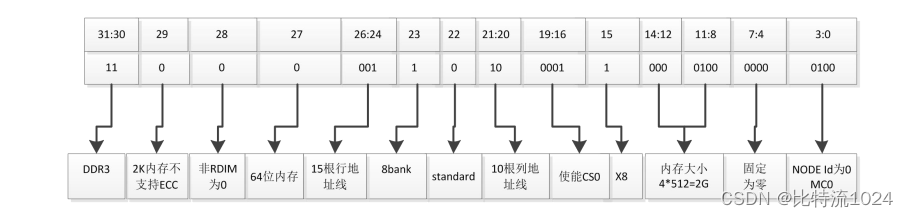
基于龙芯2k1000 mips架构ddr调试心得(一)
1、基础知识 DDR2的I/O频率是DDR的2倍,也就是266、333、400MHz。 DDR3传输速率介于 800~1600 MT/s之间 DDR4的传输速率目前可达2133~3200 MT/s 2k1000内存:板载2GB DDR3 ,可选4GB 使用龙芯芯片最好用他们自己的Bo…...

智能合约语言(eDSL)—— 使用rust实现eDSL的原理
为理解rust变成eDSL的实现原理,我们需要简单了解元编程与宏的概念,元编程被描述成一种计算机程序可以将代码看待成数据的能力,使用元编程技术编写的程序能够像普通程序在运行时更新、替换变量那样操作更新、替换代码。宏在 Rust 语言中是一种功能&#x…...

敏捷开发——elementUI/Vue使用/服务器部署
1. 创建vue项目 2. 安装element-ui组件库 npm i -S element-ui或 npm install element-ui3. 在main.js中导入element-ui组件 import ElementUI from element-ui import element-ui/lib/theme-chalk/index.css Vue.use(ElementUI)element-ui 组件库地址:Element …...

2025年09月CCF-GESP编程能力等级认证Python编程四级真题解析
本文收录于专栏《Python等级认证CCF-GESP真题解析》,专栏总目录:点这里,订阅后可阅读专栏内所有文章。 一、单选题(每题 2 分,共 30 分) 第 1 题 人工智能现在非常火,小杨就想多了解一下,其中就经常听人提到 “大模型”。那么请问这里说的 “大模型” 最贴切是指 ( )…...
)
别再只懂原理了!动手用C++实现一个Redis风格的LRU缓存(支持TTL过期)
从零构建工业级LRU缓存:C实现与TTL过期策略深度解析 在分布式系统和高性能服务架构中,缓存组件扮演着至关重要的角色。当我们需要自己动手实现一个类似Redis的内存缓存时,如何设计高效的LRU(最近最少使用)算法并整合TT…...

如何快速掌握Ultimate Plumber:Linux管道即时预览工具完全指南
如何快速掌握Ultimate Plumber:Linux管道即时预览工具完全指南 【免费下载链接】up Ultimate Plumber is a tool for writing Linux pipes with instant live preview 项目地址: https://gitcode.com/gh_mirrors/up1/up Ultimate Plumber(简称up&…...

Fela SSR完全指南:服务端渲染和客户端水合最佳实践
Fela SSR完全指南:服务端渲染和客户端水合最佳实践 【免费下载链接】fela State-Driven Styling in JavaScript 项目地址: https://gitcode.com/gh_mirrors/fe/fela Fela 是一个强大的 JavaScript 样式库,支持 State-Driven Styling,并…...
)
geography (Google Earth)
google 三维立体地图 geography (Google Earth) 地理学习...

Xftp 7免费版隐藏功能大揭秘:从图像预览到OpenSSH证书认证,不止是传文件
Xftp 7进阶实战:解锁专业用户都在用的高效文件管理技巧 每次在服务器间来回传输日志文件时,我总忍不住想起第一次用Xftp 7的场景——那时我只把它当作普通FTP工具,直到偶然发现它的图像预览功能,才意识到自己错过了多少效率神器。…...
)
告别ArcGIS手动操作:用Python脚本批量处理MCD12Q2植被物候数据(附完整代码)
用Python全自动处理MODIS物候数据:从HDF到生长季分析的完整解决方案 在植被物候研究中,MCD12Q2数据集因其高时间分辨率和全球覆盖能力成为不可替代的数据源。但面对动辄数十GB的HDF文件,传统ArcGIS点选操作不仅效率低下,更难以应对…...

Ryzen SDT 1.37:深度解析AMD处理器底层调试与性能调优工具
Ryzen SDT 1.37:深度解析AMD处理器底层调试与性能调优工具 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...

如何快速掌握DREAM3D:材料科学3D数据分析的完整开源解决方案
如何快速掌握DREAM3D:材料科学3D数据分析的完整开源解决方案 【免费下载链接】DREAM3D Data Analysis program and framework for materials science data analytics, based on the managing framework SIMPL framework. 项目地址: https://gitcode.com/gh_mirror…...

告别Techpoint和Nextchip!实测国产XS9922A/B芯片在车载DVR上的完整替换流程
国产XS9922A/B芯片在车载DVR中的实战替换指南 最近两年,车载电子行业面临着一个共同的挑战:进口芯片供应不稳定导致项目延期风险陡增。作为一名长期从事车载DVR设计的硬件工程师,我亲历了从Techpoint TP9930到国产XS9922B的完整替换过程。这…...