一起学数据分析_2
写在前面:代码运行环境为jupyter,如果结果显示不出来的地方就加一个print()函数。
一、数据基本处理
缺失值处理:
import numpy as np
import pandas as pd#加载数据train.csv
df = pd.read_csv('train_chinese.csv')
df.head()# 查看数据基本信息(非空值数量、数据类型)
df.info()# 查看每个数据是否为空值,每个特征中空值总数
df.isnull().sum()# 年龄列填充缺失值为0,到一个副本
df.fillna({'年龄':0}).head(7)
df.loc[df['客舱'].isnull(), '客舱'] = 0
# 同理可以填充平均值,众数等……df.isnull().sum()# 整张表处理(缺失值处填0)
df = df.fillna(0)
df.head()重复值(删除):
数据表里重复值其所有信息一样:(0行与1行重复)
| name | age | hobby | |
| 0 | xx | 20 | gg |
| 1 | nn | 19 | f |
| 2 | xx | 20 | gg |
# 定义一个数据表
a = pd.DataFrame({'name':['xx','dd','ff','gg','xx'],'habits':[11,22,33,44,11]})
print(a)# 查看是否有重复行(所有信息重复)
print(a.duplicated())# 处理(删除陈重复行):
a.drop_duplicates()离散化处理(分箱):
# 将连续变量Age划分为[0,5) [5,15) [15,30) [30,50) [50,80)五个年龄段,并分别用类别变量12345表示
# 左闭右开:right=False
df['age_bins'] = pd.cut(df['年龄'], [0,15,25,35,45,80], right=False, labels = list('abcde'))df.tail()# 按百分比分段
df['age_binsPercent'] = pd.qcut(df['年龄'],[.1,.2,.3,.5,.7,.9],duplicates="drop",labels=list('12345'))
df.head()变换文本变量:
例如性别包括男和女,用0表示男,1表示女。
# 查看有哪些类型
df['性别'].unique()
df['客舱'].unique()
df['登船港口'].unique()# 将男/女替换为0/1
# inplace默认为False,返回一个副本df['性别'].replace({"male",'female'},{0,1}, inplace = True)
df.head()# 按顺序替换为数字
from sklearn.preprocessing import LabelEncoderdf['客舱'] = LabelEncoder().fit_transform(df['客舱'])
df['登船港口'] = LabelEncoder().fit_transform(df['登船港口'])
df.head() 
one-hot编码:
# one-hot编码
for column in ['登船港口','性别']:# 函数x = pd.get_dummies(df[column],prefix=column)# 拼接在一起df = pd.concat([df,x],axis=1)
df.head() 
提取字符串里的某一部分:
这里用到正则表达式。里面的称呼特点是都有后缀(.)

df['title'] = df.姓名.str.extract('([A-Za-z]+)\.')
df 
二、数据的横向与纵向合并
这里进行数据重构操作
横向合并:
| hobby1 | hobby2 | |
| 0 | gg | 11 |
| 1 | ff | 22 |
| 2 | gg | 33 |
| name | age | |
| 0 | xx | 20 |
| 1 | nn | 19 |
| 2 | xx | 20 |
| name | age | hobby1 | hobby2 | |
| 0 | xx | 20 | gg | 11 |
| 1 | nn | 19 | ff | 22 |
| 2 | xx | 20 | gg | 33 |
# 导入基本库
import numpy as np
import pandas as pd# 载入data中的文件
left_up = pd.read_csv('data/train-left-up.csv')
left_down = pd.read_csv('data/train-left-down.csv')right_up = pd.read_csv('data/train-right-up.csv')
right_down = pd.read_csv('data/train-right-down.csv')#将两个数据横向合并
result_up = pd.concat([left_up, right_up], axis = 1)
result_down = pd.concat([left_down , right_down], axis = 1)result_up.head()# 横向合并
up = left_up.join(right_up)
down = left_down.join(right_down)up.head()纵向合并:
| name | age | |
| 0 | xx | 20 |
| name | age | |
| 1 | nn | 19 |
| 2 | xx | 20 |
| name | age | |
| 0 | xx | 20 |
| 1 | nn | 19 |
| 2 | xx | 20 |
# 两个数据up和down
up = left_up.join(right_up)
down = left_down.join(right_down)# 纵向合并
result1 = up.append(down)
result1.head()# 横向连接
up2 = pd.merge(left_up,right_up, left_index=True, right_index=True)
up2.head()down2 = pd.merge(left_down,right_down, left_index=True, right_index=True)
down2.head()# 纵向合并
result2 = up.append(down)
result2.head()
result2.shaperesult2.to_csv('result.csv')将DataFrame数据变为Series类型的数据:
data = pd.read_csv('result.csv')
data.head()# 转换
data.stack()三、数据重构
groupby函数:
# 载入data文件中的:result.csv
text = pd.read_csv('result.csv')
text.head()# 查看性别中的0是什么:(所以女性的数据)
list(text.groupby('Sex'))[0]# 找到不同性别的数据
group = text.groupby('Sex')
# 计算这些特征数据的统计描述
print(group.describe())# 只想得到关于年龄的信息(加一个Age索引)
print(text.groupby('Sex')['Age'].describe())
# 只得到平均值
print(text.groupby('Sex')['Age'].mean())# 计算泰坦尼克号男性与女性的平均票价
# 修改索引为票价
print(text.groupby('Sex')['Fare'].mean())
# method__2
df = text['Fare'].groupby(text['Sex'])
means = df.mean()
means# 统计泰坦尼克号中男女的存活人数
survived_sex = text.groupby('Sex')['Survived'].sum()survived_sex = text['Survived'].groupby(text['Sex']).sum()
survived_sex.head()# 计算客舱不同等级的存活人数
survived_pclass = text.groupby('Pclass')['Survived'].sum()survived_pclass = text['Survived'].groupby(text['Pclass'])
survived_pclass.sum()agg函数:
# agg里面可以使用多个方法
survived_pclass = text.groupby('Pclass')['Survived'].sum()
survived_pclass = text.groupby('Pclass').agg({'Survived':'sum'})# 性别中对费用求平均,对存活求和
text.groupby('Sex').agg({'Fare': 'mean', 'Survived': 'count'})# 重命名方便阅读,显示为‘mean_fare’
text.groupby('Sex').agg({'Fare': 'mean', 'Pclass': 'count'}).rename(columns={'Fare': 'mean_fare', 'Pclass': 'count_pclass'})
# 统计在不同等级的票中的不同年龄的船票花费的平均值
# 再加一个Pclass
text.groupby(['Pclass','Age'])['Fare'].mean().head()# 将任务二和任务三的数据合并,并保存到sex_fare_survived.csv
# 使用index查看列索引,相同则可以合并
# 我在上面没有赋值,使用这个元素不存在
means.index
survived_sex.index
# 确定类型,使用merge不能是series
type(means)# 变为dataframe
means.to_frame()# 保存起来使用merge
result = pd.merge(means,survived_sex,on='Sex')
resultresult.to_csv('sex_fare_survived.csv')# 得出不同年龄的总的存活人数,然后找出存活人数最多的年龄段,最后计算存活人数最高的存活率(存活人数/总人数#不同年龄的存活人数
text.groupby(['Age'])['Survived'].sum()survived_age = text['Survived'].groupby(text['Age']).sum()
survived_age.head()#找出最大值的年龄段
survived_age[survived_age.values==survived_age.max()]#首先计算总人数
_sum = text['Survived'].sum()print("sum of person:"+str(_sum))precetn =survived_age.max()/_sumprint("最大存活率:"+str(precetn))四、数据可视化
import numpy as np
import pandas as pd
# 画图用
import matplotlib.pyplot as plttext = pd.read_csv(r'result.csv')
text.head()# 男女中生存人数分布情况
sex = text.groupby('Sex')['Survived'].sum()
# 柱状图bar
sex.plot.bar()
# 标题
plt.title('survived_count')
plt.show() 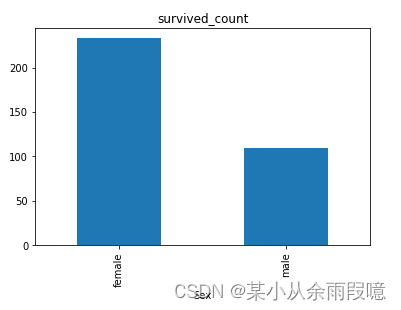
# 男女中生存人与死亡人数的比例图# unstack:旋转数据,转置
s = text.groupby(['Sex','Survived'])['Survived'].count().unstack()
# 绘制男女死亡人数柱状图
died = s[0]
died.plot.bar()
plt.title('died')

s.plot.bar()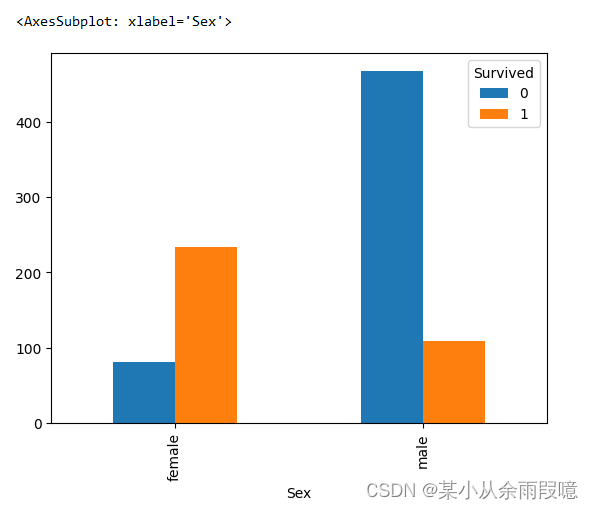
# 提示:计算男女中死亡人数 1表示生存,0表示死亡
# 柱子叠起来,参数:stacked='True'
text.groupby(['Sex','Survived'])['Survived'].count().unstack().plot(kind='bar',stacked='True')
plt.title('survived_count')
plt.ylabel('count')
# 查看不同票价的生存死亡人数
c = text.groupby(['Fare','Survived'])['Survived'].count().unstack()
c
c.plot()
# 1表示生存,0表示死亡
# 不同仓位等级的人生存和死亡人员的分布情况
pclass_sur = text.groupby(['Pclass'])['Survived'].value_counts()
pclass_surimport seaborn as sns
sns.countplot(x="Pclass", hue="Survived", data=text)
# 不同年龄的人生存与死亡人数分布情况
# 0表示死亡人数,1生存。不同年龄的死亡人数
# 画频率直方图。分区间:bins; alpha :颜色透明度
# density密度
text.Age[text.Survived == 0].hist(bins=5, alpha = .5, density=1)
text.Age[text.Survived == 1].hist(bins=5,alpha = .5, density=1)# 密度曲线
text.Age[text.Survived == 0].plot.density()
text.Age[text.Survived == 1].plot.density()# 图例
plt.legend((0,1))
plt.xlabel('age')
# plt.ylabel('count')
plt.ylabel('density') 
# 参考代码
facet = sns.FacetGrid(text, hue="Survived",aspect=3)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, text['Age'].max()))
facet.add_legend()
# 不同仓位等级的人年龄分布情况
# 查看种类
unique_placss = text.Pclass.unique()print(unique_placss)for i in unique_placss:# 密度曲线text.Age[text.Pclass == i].plot.density()
# 图例
plt.legend(unique_placss)
plt.xlabel('age')
# plt.ylabel('count')
plt.ylabel('density') 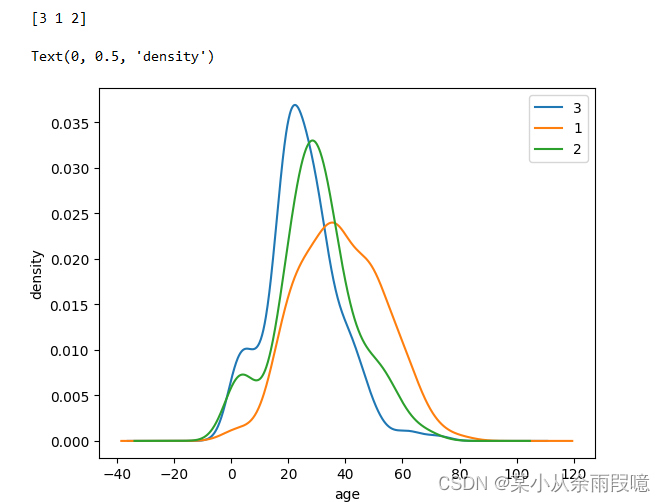
import seaborn as sns
for i in unique_placss:# 密度曲线sns.kdeplot(text.Age[text.Pclass == i])# 不同仓位等级的人年龄分布情况
text.Age[text.Pclass == 1].plot(kind='kde')
text.Age[text.Pclass == 2].plot(kind='kde')
text.Age[text.Pclass == 3].plot(kind='kde')
plt.xlabel("age")
plt.legend((1,2,3),loc="best")相关文章:
一起学数据分析_2
写在前面:代码运行环境为jupyter,如果结果显示不出来的地方就加一个print()函数。 一、数据基本处理 缺失值处理: import numpy as np import pandas as pd#加载数据train.csv df pd.read_csv(train_chinese.csv) df.head()# 查看数据基本…...

请解释Redis是什么?它有哪些主要应用场景?Redis支持哪些数据类型?并描述每种数据类型的特性和使用场景。
请解释Redis是什么?它有哪些主要应用场景? Redis是一款内存高速缓存NoSQL数据库,使用C语言编写,它支持丰富的数据类型,如String、list、set、zset、hash等,并且这些数据类型都直接支持数据的原子性操作&…...
在centos8中部署Tomcat和Jenkins
参考链接1:tomcat安装和部署jenkins_jenkins和tomcat-CSDN博客 参考链接2:--配置开机启动tomcat文件 x超详细:Centos8安装Tomcat并配置开机自动启动_centos设置tomcat开机自启-CSDN博客文章浏览阅读4.4k次,点赞4次&…...

机器学习模型—K means
文章目录 机器学习模型—K means聚类的目标k 均值原理k 均值 的实现手动实现Python 实现K 的确定 手肘法总结机器学习模型—K means K-Means 聚类是一种无监督机器学习算法,它将未标记的数据集分为不同的簇。本文旨在探讨 k 均值聚类的基本原理和工作原理以及实现。 无监督机…...

QT UI设计
在QT中添加VTK 在main函数中初始化 //VTK的初始化语句 #ifndef INITIAL_OPENGL #define INITIAL_OPENGL #include <vtkAutoInit.h> VTK_MODULE_INIT(vtkRenderingOpenGL); VTK_MODULE_INIT(vtkInteractionStyle); VTK_MODULE_INIT(vtkRenderingVolumeOpenGL); VTK_MODU…...
)
前端小白的学习之路(CSS3 一)
提示:CSS3 是 Cascading Style Sheets(层叠样式表)的第三个主要版本,引入了许多新的特性和增强功能,用于设计和布局网页。本章记录CSS3新增选择器,盒子模型。 目录 一、C3新增选择器 1) 属性选择器 1.[c…...
春暖花开,一起来看看2024年品牌春分海报吧!
春分(Vernal equinox)已至,春花烂漫、燕子归来、百草回芽。 今天我们要分享的是2024年品牌发布的春分节气海报合集,快来随我们一起感受这昂扬、蓬勃的春意吧! (1)泸州老窖 (2)BD…...
golang面试题总结
零、go与其他语言 0、什么是面向对象 在了解 Go 语言是不是面向对象(简称:OOP) 之前,我们必须先知道 OOP 是啥,得先给他 “下定义” 根据 Wikipedia 的定义,我们梳理出 OOP 的几个基本认知: …...
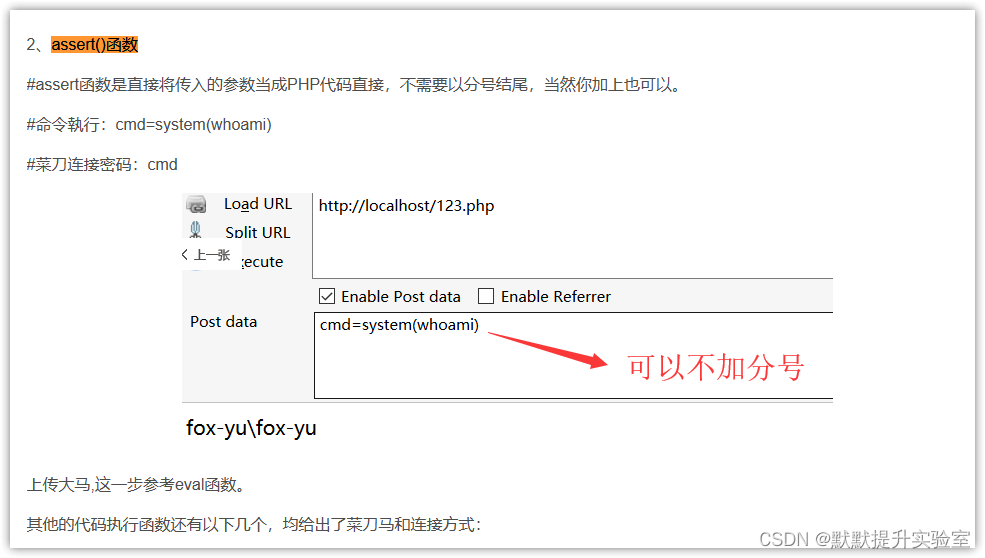
BUGKU-WEB shell
题目描述 题目截图如下: 描述: $poc "a#s#s#e#r#t";$poc_1 explode("#", $poc);$poc_2 $poc_1[0].$poc_1[1].$poc_1[2].$poc_1[3].$poc_1[4].$poc_1[5];$poc_2($_GET[s])进入场景看看:是一个空白的界面 解题思路 …...
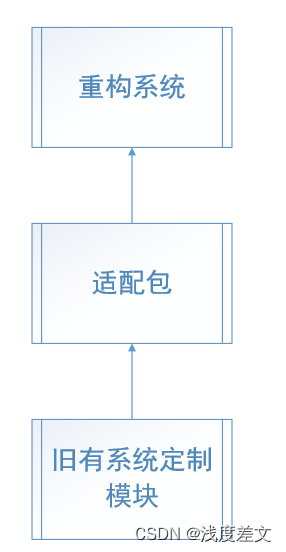
系统重构后,对项目定制开发的兼容性问题
公司自实施产品线战略以来,基本推翻了全部旧有业务模块。后续以标准产品二次开发的模式进行项目开发。但在涉及到一些旧有系统二期、三期升级改造过程中。不可避免的需要解决旧有系统的客户定制化开发兼容性问题。也就是旧有系统定制开发的模块不能丢弃。重新开发从…...

Linux---基本操作命令之用户管理命令
1.1useradd 添加新用户 root用户:/root 普通用户:/home/ 创建的用户还是david,只是在dave文件夹下 1.2 passwd 设置密码 给用户tony设置密码: 123456 1.3 id 查看用户是否存在 查看有没有这个用户:id 名字 gid:用…...
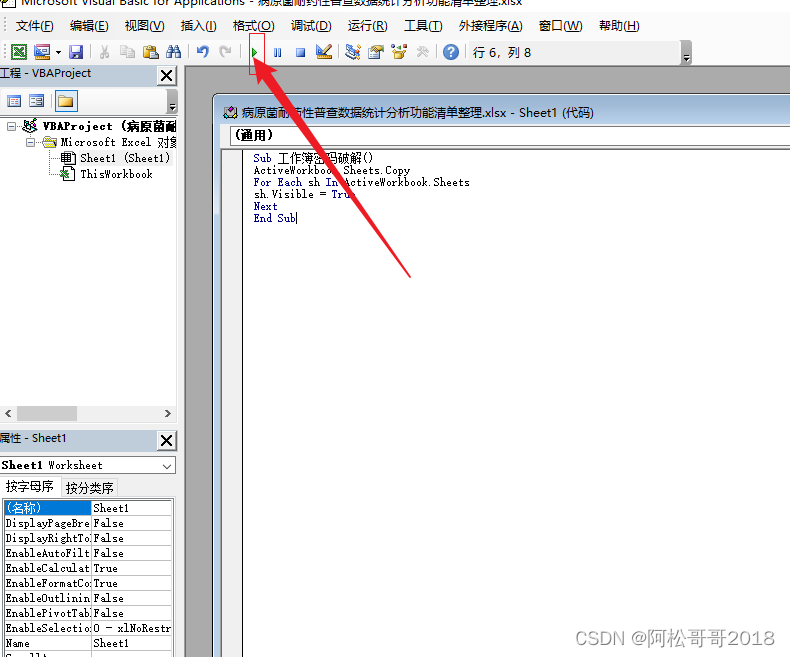
excel 破解 保护工作簿及保护工作表
excel 破解 保护工作簿及保护工作表 对于这种 保护工作簿及保护工作表 不知道密码时,可以使用以下方法破解 保护工作簿破解 打开受保存的excel 右键点击sheet名称 —> 查看代码 复制以下代码,粘贴到代码区域 Sub 工作簿密码破解() ActiveWorkbook.…...
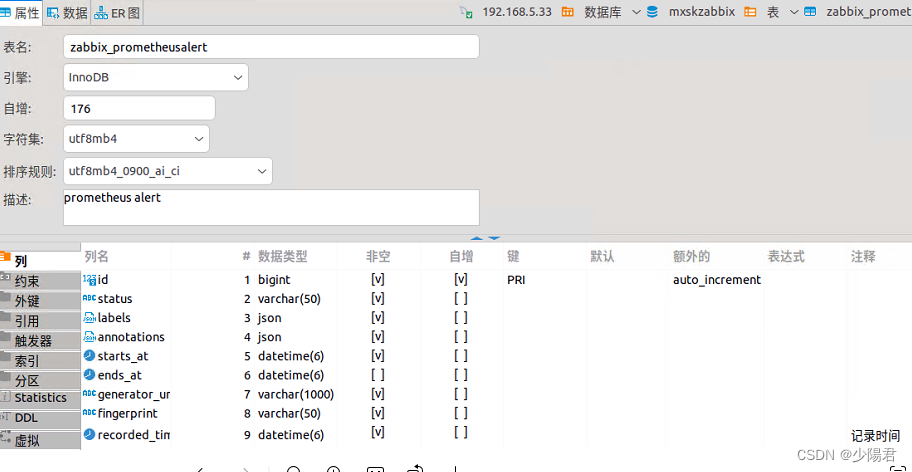
django-comment-migrate 模型注释的使用
django-comment-migrate 的使用 django-comment-migrate 是一个 Django 应用,用于将模型注释自动迁移到数据库表注释中。它可以帮助您保持数据库表注释与模型定义的一致性,并提高代码的可读性。 安装 要使用 django-comment-migrate,您需要…...

Python学习:列表
Python 列表概念 在Python中,列表(List)是一种有序、可变、允许重复元素的数据结构。列表使用方括号 []来表示,可以包含任意类型的元素,如整数、字符串、列表等。 Python 访问列表中的值 在Python中࿰…...

C语言每日一题—判断是否为魔方矩阵
魔方矩阵 在魔方阵中,所有的行、列和对角线都拥有相同的和。例如:17 24 1 8 15 23 5 7 14 16 4 9 24 6 13 20 22 和 3 5 710 12 19 21 3 8 1 611 18 25 2 9 写一个程序读入一个二维整型数组并…...

Java数组新手冷知识
J a v a Java Java 中,数组是对象,当你将一个数组传递给方法时,你其实是传递了数组的引用(地址),而不是数组的副本。因此,在 m m m 方法中修改了数组 n n n 的内容后,这种改变在方…...
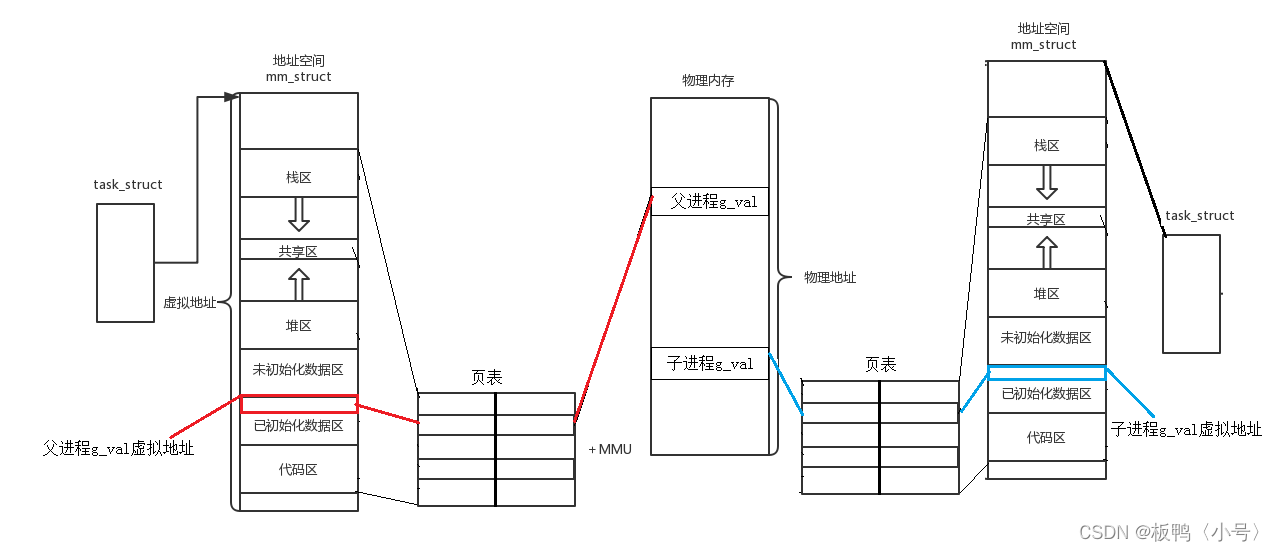
Linux——程序地址空间
我们先来看这样一段代码: #include <stdio.h> #include <unistd.h> #include <stdlib.h>int g_val 0;int main() {pid_t id fork();if(id < 0){perror("fork");return 0;}else if(id 0){ //child,子进程肯定先跑完,也…...
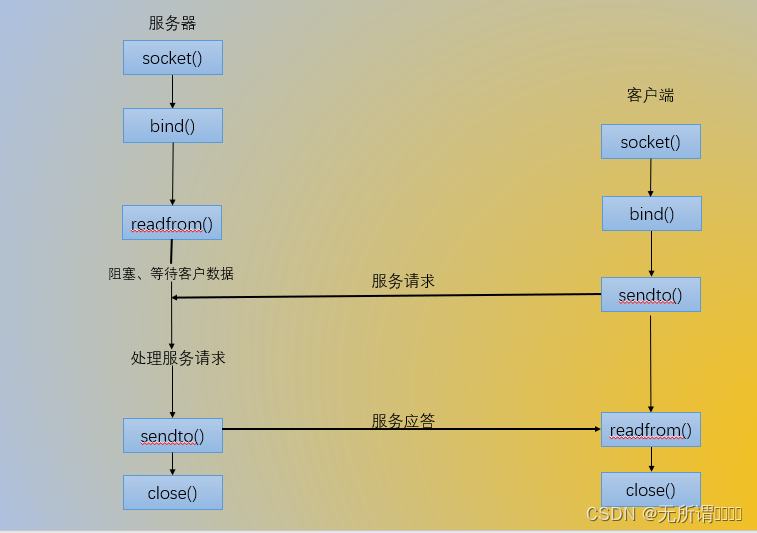
Linux编程4.9 网络编程-建立连接
1、TCP的连接与断开 三次握手与四次挥手 2、服务器端并发性处理 2.1 多进程模型 一个父进程,多个子进程父进程负责等待并接受客户端连接子进程: 完成通信,接受一个客户端连接,就创建一个子进程用于通信。 2.2 多线程模型 多线程服务器是…...

威胁检测与分析--云图大师
威胁检测与分析--云图大师 当 Internet 在 1960 年代创建时,被设想为一个革命性的计算机网络,供几千名研究人员使用。创建这个快速可靠的网络使用了许多资源,其开发人员考虑的安全措施主要是为了防止军事威胁和潜在的强大入侵者。 在那个时代…...

Python基础入门 --- 7.函数
Python基础入门 第七章: 7.函数 7.1 函数多返回值 按照返回值顺序,写对应顺序的多个变量接收,变量之间用逗号分隔,支持不同数据类型return def test_return():return 1,"hello", Truex, y, z test_return() print…...

新手必读:极客卸载零基础入门与常见问题解答
对于初次接触系统维护工具的用户,极客卸载是一款理想的入门选择。 其简洁的界面和直观的操作方式降低了使用门槛。 本文将为新手用户提供完整的入门指导,帮助大家快速掌握这款实用工具。 获取极客卸载的第一步是访问官方网站。 用户可以在搜索引擎中搜索…...

终极解决方案:Scroll Reverser如何彻底解决Mac滚动方向混乱问题
终极解决方案:Scroll Reverser如何彻底解决Mac滚动方向混乱问题 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否每天都要在触控板的自然滚动和鼠标的传统滚动之…...
构建AlgoTutor的安全代码执行沙箱)
山东大学项目实训个人博客(1)构建AlgoTutor的安全代码执行沙箱
允许用户提交任意代码执行是最大的安全风险。本文将详细阐述我为AlgoTutor构建安全沙箱的“纵深防御”策略,从进程隔离、资源限制到系统调用过滤,确保100%的沙箱逃逸防御成功率。我的核心任务之一是打造一个“牢笼”,让用户代码在其中安全…...

告别仿真日志海:UVM报告机制深度实操,灵活控制Synopsys VIP输出
UVM报告机制实战:构建智能日志管理系统 在芯片验证领域,仿真日志就像一把双刃剑——过多的信息会淹没关键错误,而过少的输出又可能遗漏重要线索。面对Synopsys VIP和其他验证组件产生的海量日志,如何实现精准控制成为验证工程师的…...

OpenUserJS.org 新手快速上手指南:轻松搭建用户脚本平台
OpenUserJS.org 新手快速上手指南:轻松搭建用户脚本平台 【免费下载链接】OpenUserJS.org The home of FOSS user scripts. 项目地址: https://gitcode.com/gh_mirrors/op/OpenUserJS.org OpenUserJS.org 是一个开源的用户脚本托管平台,为开发者提…...
)
基于双积分滑模控制的双有源桥DAB单移相DC-DC变换器仿真研究(Simulink仿真实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

AGI如何7×24小时守护长江生态?:基于卫星+IoT+多模态大模型的污染溯源实战框架
第一章:AGI驱动的长江生态全天候守护范式 2026奇点智能技术大会(https://ml-summit.org) 传统生态监测依赖人工巡检与离散传感器网络,难以应对长江流域跨省域、多尺度、强动态的水文—生物—人类活动耦合挑战。AGI驱动的守护范式通过具身感知、因果推理…...

互联网大厂 Java 求职面试:音视频场景中的技术挑战
互联网大厂 Java 求职面试:音视频场景中的技术挑战 在一个晴朗的下午,面试官小李正坐在会议室中,等候着候选人燕双非的到来。这位看似轻松的程序员,今天却要面对一系列技术问题。小李微笑着,开始了第一轮提问。第一轮提…...

XML CDATA
XML CDATA 概述 XML(可扩展标记语言)是一种用于存储和传输数据的标记语言。在XML中,CDATA(Character Data)是一种特殊的数据类型,用于包含文本数据,使其不会被XML解析器解释为XML标签或属性。本文将详细介绍XML CDATA的概念、使用方法及其在XML文档中的作用。 CDATA的…...
算法)
别再让照片忽明忽暗了!手把手教你搞定手机/相机里的自动曝光(AE)算法
别再让照片忽明忽暗了!手把手教你搞定手机/相机里的自动曝光(AE)算法 每次拍逆光人像,人脸总是黑得像剪影?夜景照片要么亮如白昼要么漆黑一片?别急着怪设备,可能是你没搞懂相机里那个"聪明…...