MySQL面试题之基础夯实
一、mysql当中的基本数据类型有哪些
MySQL中的基本数据类型包括但不限于以下几大类:
-
数值类型:
- 整数类型:TINYINT、SMALLINT、MEDIUMINT、INT(INTEGER)、BIGINT
- 浮点数类型:FLOAT、DOUBLE、DECIMAL(用于存储精确的小数或货币值)
- 位类型:BIT[(M)],可以存储0和1的二进制值
-
日期和时间类型:
- DATE:存储年-月-日格式的日期
- TIME:存储小时、分钟、秒的时间值
- DATETIME:存储包含日期和时间的完整信息
- TIMESTAMP:类似于DATETIME,但有时区信息,并且在某些情况下会自动更新
- YEAR:存储两位或四位的年份
-
字符串类型:
- CHAR(M):定长字符串,固定长度M,空格也会占用空间
- VARCHAR(M):变长字符串,最大长度M,仅存储实际字符数量所占的空间
- TEXT:可变长度的大文本数据,有TINYTEXT、TEXT、MEDIUMTEXT和LONGTEXT几种子类型
- BLOB:用于存储二进制大对象数据,有TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB几种子类型
- ENUM:枚举类型,预定义的一组可能的值集合
- SET:集合类型,多个预定义的离散值可以作为一组被存储
-
布尔类型:
- MySQL没有直接的BOOLEAN类型,但通常通过TINYINT(1)来模拟,0代表FALSE,非0(通常是1)代表TRUE。
-
其他数据类型:
- JSON:从MySQL 5.7.8开始支持JSON文档类型的列。
- GEOMETRY:用于存储地理空间数据,包括Point, LineString, Polygon等。
注意,随着时间的推移,MySQL数据库的功能和数据类型可能会有所增加或改进。上述内容基于截至2023年的信息。
二、什么是数据库事务?
数据库事务(Transaction)在MySQL中是指作为单个逻辑工作单元执行的一系列操作的集合,这些操作在数据库管理系统中是被捆绑在一起的。事务必须遵循ACID原则:
-
原子性(Atomicity):事务中的所有操作是一个不可分割的整体,要么全部成功提交,要么全部失败回滚,不可能只执行事务中的一部分。
-
一致性(Consistency):事务执行前后,数据库都必须处于一致状态,即任何事务都应该使数据库从一个有效状态转变为另一个有效状态。
-
隔离性(Isolation):并发执行的多个事务之间互不影响,如同单线程串行执行一样。每个事务都好像在独立地处理数据库,即使有其他事务同时在进行。
-
持久性(Durability):一旦事务成功提交,它对数据库的修改就应该是永久性的,即使系统出现故障也不会丢失已提交的更新。
在MySQL中,InnoDB存储引擎支持事务处理,这意味着用户可以定义一组SQL语句作为一个事务来执行,确保数据完整性。如果事务中的任意部分执行失败,整个事务可以通过ROLLBACK命令撤销,返回到事务开始前的状态;若所有操作均成功,则通过COMMIT命令提交事务,使其对数据库的更改永久生效。
三、能说下myisam 和 innodb的区别吗?
当然可以。MySQL中的MyISAM和InnoDB是两种不同的存储引擎,它们在数据处理、索引、事务支持以及其他特性方面有着显著的区别:
-
事务支持:
- MyISAM:不支持事务处理,即无法保证ACID(原子性、一致性、隔离性和持久性)属性。
- InnoDB:支持事务处理,适用于需要复杂事务管理的场景,如银行交易、金融系统等。
-
外键约束:
- MyISAM:不支持外键约束,这意味着表间关系不能通过数据库层面强制执行。
- InnoDB:支持外键约束,能够确保引用完整性,有助于维护数据的一致性。
-
锁机制:
- MyISAM:使用的是表级锁定,当对表进行写操作时,会锁定整个表,阻止其他用户对该表的所有读写操作,这样在并发环境下可能导致性能问题。
- InnoDB:采用行级锁定,只锁定正在处理的数据行,允许其他查询在同一表的不同行上并发读取或修改,提高了并发性能。
-
崩溃恢复与数据安全:
- MyISAM:在系统崩溃或者断电的情况下,如果没有适当的备份和检查点,可能丢失未提交的数据,且修复过程相对复杂。
- InnoDB:提供崩溃恢复功能,并通过重做日志(redo log)和回滚日志(undo log)来保证事务的完整性和一致性,即使在异常情况下也能较好地保护数据。
-
索引类型:
- MyISAM:支持全文索引,适合全文搜索的应用场景;非聚集索引,数据文件和索引文件分开存储。
- InnoDB:从MySQL 5.6版本开始也支持全文索引;采用聚集索引(主键索引),数据行跟主键索引存储在一起,辅助索引则包含指向对应行的指针。
-
空间占用与性能:
- MyISAM:对于只读或者读多写少的应用场景,由于其索引结构简单,有时查询速度更快,但在更新密集型场景下表现不如InnoDB。
- InnoDB:由于其设计上的特点,比如缓存池(Buffer Pool)、预读机制等,在高并发和大量更新插入操作中通常具有更好的性能。
综上所述,MyISAM适用于读密集型、不需要事务支持且对数据一致性要求较低的场景,而InnoDB更适合于频繁写入、有事务需求以及需要支持复杂查询的应用场景。MySQL 5.5以后的版本中,默认的存储引擎已经是InnoDB,这反映了它在现代数据库应用中的广泛适用性。
三、什么是索引?
在MySQL数据库中,索引是一种特殊的物理或逻辑的数据结构,设计用于提高数据检索速度。它为表中的一个或多个列创建有序的值集合,并与这些列对应的行记录相关联。当用户执行查询时,特别是包含WHERE子句的查询,数据库引擎可以利用索引快速定位到符合条件的数据行,而无需对整个表进行线性扫描。
MySQL中适合添加索引的字段通常符合以下条件:
-
经常用于查询条件的字段:如果某个字段频繁出现在
WHERE子句中,特别是当表的数据量非常大时,为这样的字段创建索引可以显著提高数据检索速度。 -
连接操作中的字段(连接键):在进行表连接操作时,两个表之间的连接字段上应建立索引,这样可以加快JOIN操作的速度。
-
排序或分组字段:在
ORDER BY和GROUP BY语句中使用的字段应当考虑创建索引,因为索引可以帮助数据库快速找到排序所需的顺序或者分组依据。 -
具有高选择性的字段:选择性高的字段指的是该字段中唯一值所占的比例较高。这样的字段作为索引能够更有效地过滤记录,减少I/O操作。
-
主键和唯一约束字段:主键(Primary Key)和唯一性约束字段(Unique Key)自然会自动带有索引,因为它们确保了每行数据的唯一性,且值的离散度非常高。
-
固定长度且占用存储空间少的字段:整数类型等固定长度、占用空间小的字段更适合做索引,相比变长类型如字符串,索引效率更高。
-
全文搜索字段:对于需要进行全文本搜索的文本字段,可以创建FULLTEXT索引来优化搜索性能。
需要注意的是,并非所有字段都适合添加索引,尤其是那些更新频繁的字段,因为每次更新都会导致索引重建,可能反而影响写入性能。此外,对于很少用于查询或数据量较小的表,添加索引可能带来的性能提升并不明显,甚至由于维护索引结构而带来额外开销。因此,在决定是否对字段添加索引时,应综合考虑表的大小、查询模式、更新频率以及磁盘空间等因素。
四、索引的优缺点?
优点:
大大加快数据检索的速度。
将随机I/O变成顺序I/O(因为B+树的叶子节点是连接在一起的)
加速表与表之间的连接
缺点:
从空间角度考虑,建立索引需要占用物理空间
从时间角度 考虑,创建和维护索引都需要花费时间,例如对数据进行增删改的时候都需要维护索引。
五、索引的数据结构?
MySQL索引主要使用B+树(B-Tree)数据结构作为其索引的底层实现,尤其是在InnoDB存储引擎中。B+树是一种自平衡的树状数据结构,特别适合于磁盘存储系统。
在B+树中:
- 每个节点可以有多个键和多个指针:相较于二叉查找树,B+树每个节点可以存放更多的元素,这样大大减少了树的高度,从而减少磁盘I/O次数。
- 内部节点不存储数据:非叶子节点仅包含索引键值以及指向子节点的指针,实际的数据只存储在叶子节点上。
- 叶子节点之间通过指针连接成链表:所有叶子节点形成了一个有序链表,便于范围查询时进行高效的遍历。
- 所有叶子节点在同一层:这使得从根节点到任何叶子节点的路径长度相同,且保证了数据检索效率相对稳定。
此外,MySQL还支持其他类型的索引数据结构:
- 哈希索引:用于处理等值查询,适用于那些不需要排序或范围查询的场景。它基于哈希函数快速定位数据,但不支持区间查询。
- 全文索引:主要用于对文本字段进行全文搜索,使用的是倒排索引结构。
- R-Tree索引:在空间数据类型上使用,用于地理空间索引。
综上所述,在MySQL数据库中,尤其是对于关系型数据的检索操作,B+树是最常见的也是最为高效的数据索引结构。
六、Hash索引和B+树的区别?
Hash索引和B+树索引是两种不同的数据库索引结构,它们在数据存储、查找方式以及适用场景上有显著区别:
Hash索引:
- 查找原理:基于哈希函数对键值进行计算,将键直接映射到一个位置。通过哈希函数可以快速定位到特定记录,对于等值查询(如
WHERE key = value)具有非常高的效率。 - 范围查询与排序:不支持范围查询(如
WHERE key BETWEEN value1 AND value2)和排序操作,因为哈希函数会导致键的顺序被打乱,无法按原始顺序遍历。 - 冲突处理:可能出现哈希碰撞,即多个键值映射到相同的位置,需要额外的数据结构(如链表)来解决冲突,这可能会影响性能。
- 空间效率:通常情况下,哈希索引占用的空间比B+树索引更小,因为它只存储键值和指向数据行的指针。
B+树索引:
- 查找原理:B+树是一种平衡多路搜索树,每个节点包含多个键和指针,并且所有叶子节点形成一个有序链表。查询时按照键值大小进行比较和移动,逐步缩小查找范围。
- 范围查询与排序:天然支持范围查询和排序操作,由于叶子节点的键是有序排列的,可以根据键值顺序进行扫描。
- 层级结构:B+树的高度相对较小,通过增加每个节点的扇出数(子节点数量),可以减少磁盘I/O次数,提高检索效率。
- 空间效率:相较于哈希索引,B+树索引通常需要更多的存储空间,因为它不仅保存了键值,还保持了键之间的逻辑顺序关系。
总结来说,哈希索引适用于等值查询频繁且不需要排序或范围查询的场景,而B+树索引则更为通用,尤其适合于涉及范围查询和排序操作的情况,并且能更好地适应磁盘存储环境下的数据库查询优化。MySQL中的InnoDB存储引擎主要使用B+树作为默认的索引类型。
七、索引的类型有哪些?
MySQL中索引的类型主要可以按照不同的分类标准划分为以下几种:
-
根据功能逻辑分类:
- 普通索引(Basic Index):也称为非唯一索引,它不强制字段值必须唯一,主要用于加速查询。
- 唯一索引(Unique Index):索引列中的所有值必须是唯一的,不允许重复。如果试图插入重复值,数据库会抛出错误,除非定义时允许NULL值且一个表中只有一个NULL值。
- 主键索引(Primary Key Index):一种特殊的唯一索引,每个表只能有一个主键,其值必须唯一,并且不允许有NULL值。
- 全文索引(Full-text Index):用于对文本数据进行全文搜索,支持基于自然语言的关键词查找。
-
根据作用字段个数分类:
- 单列索引(Single-column Index):在单个列上创建的索引。
- 联合索引(Composite/Index/Composite Index/Multi-column Index):在一个或多个列上创建的索引,它遵循最左前缀匹配原则,即查询条件中从索引左侧开始连续使用索引列可以获得较好的查询性能。
-
根据物理实现方式分类:
- 聚簇索引(Clustered Index):行数据是按照索引顺序存储的,通常一张表最多只能有一个聚簇索引,InnoDB存储引擎的主键索引默认为聚簇索引,数据和索引存放在一起。
- 非聚簇索引(Non-clustered/Index/Secondary Index):索引与数据分开存储,索引包含指向对应行数据的指针,MyISAM、InnoDB等存储引擎都支持非聚簇索引。
-
根据存储结构分类:
- B-Tree索引:MySQL中最常用的索引结构,适用于全值匹配和范围查询。
- Hash索引:仅支持等值查询,不适合排序和范围查询,例如MEMORY存储引擎默认使用哈希索引。
- R-Tree索引:针对空间数据类型的索引,如地理坐标数据。
- Full-text索引:用于全文本检索,在MySQL 5.6之后版本中InnoDB也开始支持全文索引。
-
其他特殊类型的索引:
- BitMap索引:适合于低基数的列,即字段值种类较少的情况,Oracle数据库中常见。
- 位图索引(可能在特定场景下出现):特别适用于字段值只有有限几个离散值的场景。
请注意,具体的索引类型可能会因为数据库版本的不同以及所使用的存储引擎而有所差异,上述信息以MySQL为主。
八、B树和B+树的区别?
MySQL中B树(B-Tree)和B+树都是数据库索引使用的数据结构,它们都是平衡的多路查找树。虽然两者在很多方面相似,但存在一些关键区别:
B树(B-Tree)的特点:
- 每个节点可以存储多个键(key)以及与每个键相关联的数据。
- 非叶子节点不仅包含键值,还存放了指向子节点的指针,同时也可能直接存储数据记录。
- 查询可以在非叶子节点结束,因为非叶子节点包含了实际的数据项。
- B树的一个特性是它支持在内部节点进行范围查询,但由于数据分布在所有节点中,可能导致磁盘I/O操作增多。
B+树的特点:
- 非叶子节点(内部节点)只存储键值,不存储数据本身,仅起到索引的作用,指向叶子节点。
- 所有的数据都存储在叶子节点上,并且叶子节点是按顺序排列的,每个叶子节点都会包含一个指向下个叶子节点的指针,形成一个有序链表结构。
- 在B+树中,范围查询非常高效,因为它可以直接遍历叶子节点之间的链表来获取连续的一段数据。
- 相对于B树,B+树的叶子节点通常更大,这样可以减少磁盘I/O次数,因为在一次I/O中能够加载更多的数据。
总结来说,B+树相比于B树的优势主要体现在:
- 更少的磁盘I/O次数:B+树通过将所有数据集中到叶子节点并增大节点大小来实现这一点。
- 更好的缓存局部性:由于查询只访问叶子节点,而叶子节点往往连续存储,更利于缓存命中。
- 更优的范围查询性能:B+树的叶子节点之间通过指针连接起来,方便快速进行范围扫描。
因此,在大多数现代数据库系统如MySQL中,尤其是在需要大量磁盘读取的场景下,B+树被广泛用作索引结构。
九、数据库为什么使用B+树而不是B树?
MySQL数据库选择使用B+树作为索引结构而非B树,主要原因如下:
-
顺序访问友好:
- B+树的所有叶子节点形成了一个有序链表,在进行范围查询或全表扫描时,可以按照索引顺序快速地遍历数据。而B树虽然内部节点也包含数据,但在范围查询时无法像B+树那样高效地通过指针连续访问。
-
磁盘读取效率高:
- 数据库系统通常将数据存储在磁盘上,由于I/O操作相对昂贵(尤其是随机I/O),B+树相较于B树具有更优的磁盘访问性能。
- B+树的内部节点(非叶子节点)只存储键值和指向子节点的指针,不存放实际的数据项,使得每个节点能容纳更多的键值对,这样可以降低树的高度,减少磁盘I/O次数。
- B+树叶子节点较大,能够更好地利用磁盘块的大小,一次磁盘I/O可能加载更多相关数据。
-
空间利用率:
- B+树中非叶子节点不存储数据,因此单个节点可以存储更多的索引信息,从而提高索引的空间利用率。
-
查询性能稳定:
- 在B+树中,任何检索都要查找到叶子节点才命中数据,所以查询性能更为稳定且预测性好,不会因为数据分布在不同层级而导致查询时间复杂度有显著差异。
综上所述,B+树更适合于大规模数据存储和检索的场景,特别是当数据量远大于内存容量,需要频繁与磁盘交互时,其优势更加明显。这就是为什么MySQL等关系型数据库管理系统倾向于采用B+树作为索引结构的原因。
十、什么是聚簇索引,什么是非聚簇索引?
聚簇索引(Clustered Index)和非聚簇索引(Non-clustered Index)是数据库中两种不同的索引类型,它们在数据存储结构和查询效率上有所区别。
聚簇索引(Clustered Index):
- 聚簇索引决定了表中数据行的物理存储顺序。创建聚簇索引时,表中的实际数据行会按照索引键值进行排序并存储在一起。
- 表只能有一个聚簇索引,通常建立在主键列上,但也可以在其他唯一且不重复的列上创建。
- 在InnoDB存储引擎中,表默认具有一个隐藏的聚簇索引,如果用户未显式定义主键,则会选择一个唯一的非空索引作为聚簇索引,否则系统自动生成一个隐藏的ROWID作为聚簇索引。
- 聚簇索引的叶子节点直接包含行数据,这意味着通过索引可以直接访问到所需的数据,无需再经过额外的寻址步骤。
非聚簇索引(Non-clustered Index):
- 非聚簇索引不影响表中数据的物理存储顺序。它与数据行分开存储,每个非聚簇索引都有自己的索引结构。
- 一个表可以有多个非聚簇索引,这些索引根据指定的列创建,并且其叶子节点并不直接存储行数据,而是存储指向对应数据行的指针(通常是行标识符或聚集键)。
- 当执行查询时,通过非聚簇索引找到对应的行需要两次查找:首先从非聚簇索引中找到行的位置信息,然后根据位置信息回表查询实际数据,这个过程称为“回表”。
总结来说,聚簇索引优化了数据行的物理组织,对于基于主键的查询以及范围扫描非常高效;而非聚簇索引提供了对非主键字段快速定位的能力,但涉及到实际数据读取时需要额外的I/O操作。
十一、非聚簇索引一定会进行回表查询吗?
非聚簇索引并不一定总会进行回表查询。是否需要回表查询取决于查询语句的需求和索引覆盖情况。
-
如果查询只需要从非聚簇索引中获取的数据(即,查询的所有列都包含在该非聚簇索引中),则不需要回表查询。这种情况下,索引包含了查询所需要的所有信息,被称为“索引覆盖查询”。
-
但如果查询的列包括了非聚簇索引中未存储的列,则数据库系统必须通过非聚簇索引找到对应的主键值或行指针,然后根据这个主键值去聚簇索引中查找完整的行数据,这就涉及到了回表查询。
例如,在一个学生表中,假设有一个非聚簇索引是基于age字段创建的,且索引只包含了年龄和主键ID。若查询仅要求学生的年龄,则可以直接使用非聚簇索引来完成查询;但如果查询还要求学生的姓名等其他不在索引中的信息,则需要先通过非聚簇索引找到主键ID,再通过主键ID在聚簇索引中找到完整的行记录,这就是一次回表查询的过程。
十二、索引的使用场景有哪些?
索引在数据库中的使用场景主要包括以下几个方面:
-
大型表查询:
- 当表中数据量非常大时,直接进行全表扫描效率极低。通过在频繁查询的列上创建索引,可以快速定位到满足条件的数据行,显著提高查询速度。
-
连接操作(JOIN):
- 在多个表进行JOIN操作时,如果连接条件对应的字段有索引,数据库可以利用索引快速找到匹配记录,减少JOIN操作所需的时间。
-
排序和分组(ORDER BY 和 GROUP BY):
- 当SQL语句中包含ORDER BY或GROUP BY子句,并且排序或分组依据的字段上有索引时,数据库可以直接利用索引来完成排序或分组操作,避免了临时文件排序带来的开销。
-
多列查询与复合索引:
- 如果查询条件涉及多个列,可以创建复合索引来加速查询。例如,当经常需要根据
last_name, first_name同时查询用户时,可以在这两个列上创建一个复合索引。
- 如果查询条件涉及多个列,可以创建复合索引来加速查询。例如,当经常需要根据
-
唯一性约束:
- 主键(PRIMARY KEY)和唯一键(UNIQUE KEY)自动创建索引,确保了表中这些字段值的唯一性,并优化了基于这些字段的查找性能。
-
高并发读取场景:
- 在高并发的读取操作中,索引可以帮助数据库系统更快地响应请求,降低锁竞争,提升整体系统的吞吐量。
-
频繁搜索和范围查询:
- 对于那些频繁作为搜索条件或者执行范围查询的列,建立索引有助于加快查询速度。
然而,需要注意的是,虽然索引能提高查询性能,但它们也会占用存储空间,增加写入操作(如INSERT、UPDATE和DELETE)的复杂性和时间成本,因为每次修改数据时都需要维护索引结构。因此,在决定是否为某个字段创建索引时,应权衡查询性能和更新性能之间的平衡,并结合实际业务需求及数据分布特点来确定最优的索引策略。
十三、索引的设计原则?
数据库索引设计原则是一系列指导方针,用于帮助数据库管理员和开发人员创建高效、适用的索引结构。以下是索引设计时需要考虑的一些关键原则:
-
数据访问模式分析:
- 分析应用的查询语句(尤其是频繁执行的SQL)以及表的更新模式。
- 为经常出现在WHERE子句、JOIN条件、ORDER BY、GROUP BY、DISTINCT操作中的字段创建索引。
-
唯一性:
- 对于具有唯一性的列,如主键或业务上要求唯一的字段,应建立唯一索引(UNIQUE INDEX),可以快速定位记录且确保数据一致性。
-
选择合适的列组合:
- 创建复合索引时,按照查询中使用频率高到低的顺序排列列,并遵循最左前缀匹配原则。
-
避免过度索引:
- 不要无目的地在所有可能用作查询条件的列上都创建索引,这会增加存储空间消耗并降低插入、更新和删除操作的效率。
- 定期审查和调整索引,移除不再有效或者利用率低的索引。
-
考虑索引大小:
- 避免在非常大的列(如长文本或BLOB类型)上创建索引,除非有明确的必要性和实际效果。
- 对于大文本列,可以考虑部分索引(前缀索引)来减少索引空间占用。
-
考虑数据分布和选择度:
- 索引对高度重复的数据价值较小,对于区分度高的列,索引的效果更好。
- 对于范围查询较多的场景,考虑是否有必要创建覆盖索引以避免回表查询。
-
索引维护成本:
- 考虑索引在数据修改(INSERT、UPDATE、DELETE)时的维护成本,特别是对于频繁更新的大表。
-
聚簇索引与非聚簇索引的选择:
- 考虑表的物理存储布局,选择合适的列作为聚簇索引,它会影响数据读取性能和磁盘I/O。
-
根据实际需求选择索引类型:
- 根据不同查询需求,可以选择B-Tree索引、哈希索引、全文索引等不同的索引类型。
总之,在设计索引时需综合考虑业务逻辑、查询性能、存储开销及维护成本等因素,做到有针对性地创建和优化索引结构,从而提高数据库整体性能。
十四、如何对索引进行优化?
MySQL索引优化主要包括以下几个方面:
-
分析查询语句:
- 使用
EXPLAIN命令来查看SQL查询的执行计划,了解MySQL如何使用索引、表扫描方式以及哪些操作可能导致全表扫描。 - 分析查询条件和JOIN语句,确保在最常被用作过滤条件或连接条件的列上创建了索引。
- 使用
-
选择合适的索引类型:
- 根据查询需求选择B-Tree(默认)、哈希、全文本等不同类型的索引。例如,对于点查询和范围查询,通常选择B-Tree索引;对于精确匹配且数据量小的情况,可能考虑哈希索引。
-
创建复合索引与覆盖索引:
- 对于多条件查询,创建复合索引,并遵循最左前缀原则。
- 创建覆盖索引,即索引中包含所有需要查询的字段,避免回表查询,可以极大地提高查询效率。
-
索引维护:
- 定期检查并清理不再使用的索引,减少存储开销和维护成本。
- 针对频繁插入、删除、更新的表,评估索引重建策略以减小碎片。
-
主键和唯一索引的选择:
- 主键应当选择具有高唯一性且不经常变更的字段作为基础,尽量避免自增ID以外的大整数作为外键关联的主键,以防JOIN时影响性能。
- 在业务逻辑上要求唯一的字段上建立唯一索引,不仅可以加速查找,还可以保证数据完整性。
-
索引长度优化:
- 对于文本类型的列,考虑只对常用的部分前缀建立索引,而非整个列,以减少索引大小。
-
避免过度索引:
- 不要为所有可能涉及查询的列都创建索引,这会增加写入操作的成本,并占用额外的存储空间。
-
监控与调整:
- 使用数据库监控工具观察实际生产环境中的查询性能,根据查询负载动态调整索引策略。
-
分区表策略:
- 对于特别大的表,可以考虑使用分区表,通过合理的分区策略,将大表划分为多个物理上的小块,有助于分散I/O压力,提高查询性能。
-
适应数据分布:
- 根据数据的实际分布情况,特别是当存在大量重复值时,应谨慎设计索引,有时甚至可能需要考虑函数索引或其他特殊的索引策略。
综上所述,MySQL索引优化是一个持续的过程,需要结合具体的应用场景、查询模式和数据特征进行深入分析和实践。
十五、如何创建/删除索引?
在MySQL中创建和删除索引的语法如下:
创建索引:
方法一:使用CREATE INDEX语句
CREATE [UNIQUE|FULLTEXT] INDEX index_name ON table_name (column1, column2,...);
UNIQUE关键字表示创建唯一索引,确保索引列的数据是唯一的。FULLTEXT关键字用于创建全文索引,适用于文本搜索。index_name是要创建的索引名称。table_name是指定要为其添加索引的表名。(column1, column2,...)是你想要建立索引的列列表。
例如:
CREATE INDEX idx_employee_name ON employees (first_name, last_name);
CREATE UNIQUE INDEX uq_user_email ON users (email);
CREATE FULLTEXT INDEX ft_article_content ON articles (content);
方法二:使用ALTER TABLE语句
ALTER TABLE table_name ADD [UNIQUE|FULLTEXT] INDEX index_name (column1, column2,...);
同样可以使用ALTER TABLE命令来为已存在的表添加索引。
例如:
ALTER TABLE employees ADD INDEX idx_emp_dept (department_id);
ALTER TABLE users ADD UNIQUE INDEX uq_username (username);
删除索引:
使用DROP INDEX语句
DROP INDEX index_name ON table_name;
或者结合ALTER TABLE语句:
ALTER TABLE table_name DROP INDEX index_name;
例如:
DROP INDEX idx_employee_name ON employees;
ALTER TABLE employees DROP INDEX idx_emp_dept;
请注意,在删除索引之前,请确保确认索引名称及其作用,以避免意外影响查询性能。
十六、使用索引查询时性能一定会提升吗?
使用索引查询时性能不一定会提升,这取决于多种因素:
-
查询条件与索引匹配度:
- 如果查询条件完全或部分匹配到索引(例如,对于复合索引遵循最左前缀原则),则查询性能通常会提高。
- 若查询条件不涉及索引列或者虽然涉及但不是按照索引顺序进行的,索引可能无法被有效利用。
-
索引的选择性:
- 索引的选择性是指索引列中唯一值的比例。选择性高的索引能够更精确地定位数据,因此查询性能较好。反之,如果索引列包含大量重复值,则索引效果不佳。
-
查询类型:
- 索引主要用于加速等值查询、范围查询和排序操作。但对于哈希索引,只支持等值查询;对于全文索引,用于全文本搜索。
- 对于复杂的查询,如涉及到多个表JOIN、OR条件、LIKE模糊查询(非前缀匹配)等情况,即使有索引也可能导致全表扫描或无法充分利用索引。
-
索引维护成本:
- 插入、更新和删除数据时需要维护索引结构,频繁的DML操作可能导致索引优化带来的性能增益在写操作上被抵消。
-
数据量大小:
- 当数据量非常小的时候,全表扫描可能比使用索引更快。而当数据量达到一定程度时,索引的优势才得以体现。
-
查询结果集大小:
- 如果查询返回的结果集占了表中的大部分或全部记录,数据库引擎可能会选择放弃使用索引并执行全表扫描。
综上所述,在决定是否使用索引以及如何设计索引时,应综合考虑上述因素,并结合实际业务场景及SQL查询语句来评估索引对查询性能的影响。
十七、什么是前缀索引?
前缀索引是一种特殊的数据库索引,它不是对整个列进行索引,而是只对列的前几个字符创建索引。在MySQL等关系型数据库中,当一个字段值很长(如文本或字符串类型)时,为了节省存储空间和提高查询效率,可以为该字段的前n个字符创建索引。
例如,在一个包含产品描述的表中,如果description字段非常大且每个描述的开头部分差异较大,那么可以为description字段的前100个字符创建前缀索引:
CREATE INDEX idx_description_prefix ON products (SUBSTRING(description, 1, 100));
通过这种方式,数据库只需要存储每个记录描述的前100个字符作为索引的一部分,而不是整个描述字段,从而减小了索引文件的大小。然而,前缀索引也存在一定的局限性:
- 它可能无法覆盖所有查询条件,因为只索引了部分数据。
- 对于包含在索引后部的数据无法有效查找,所以对于涉及索引未覆盖部分的范围查询性能不理想。
- 前缀索引的选择性可能会低于全列索引,这意味着可能存在更多的索引项重复,降低索引效果。
因此,在决定是否使用前缀索引时,需要权衡存储成本、查询效率以及业务需求之间的关系。
十八、什么是最左匹配原则?
最左匹配原则是MySQL数据库中针对复合索引(也称为联合索引)的一种使用规则。在MySQL的InnoDB存储引擎以及其他支持该原则的数据库系统中,当创建了一个包含多个列的复合索引时,查询优化器在利用该索引进行查询时遵循以下原则:
- 查询条件必须从复合索引的最左边开始,并按照索引定义中的顺序依次匹配后面的列。
- 如果查询语句仅使用了索引中最左侧连续的一部分列作为查询条件,则可以利用这部分索引来加速检索过程。
- 当查询条件涉及到索引中间某个列之后的其他列时,但未包含中间列,则索引无法被有效利用。
- 若查询中有范围查询操作符(如
>、<、BETWEEN、LIKE且非前缀匹配等)应用于复合索引的某一列,则后续的列将无法使用索引进行搜索。
例如,假设有一个复合索引为 (col1, col2, col3):
- 查询
WHERE col1 = 'value1' AND col2 = 'value2' AND col3 = 'value3'可以完全利用索引。 - 查询
WHERE col1 = 'value1' AND col3 = 'value3'则只能利用到索引的第一部分,即对col1的索引。 - 查询
WHERE col2 = 'value2'不能利用此复合索引,因为没有从最左边的col1开始。 - 查询
WHERE col1 = 'value1' AND col2 > 'value2'虽然能利用到col1的索引,但col2后面的部分由于涉及范围查询,所以col3的索引将不会被使用。
因此,在设计和使用复合索引时,应当根据实际业务场景及查询需求来确定索引列的顺序,以便最大程度地发挥索引的作用。
十九、索引在什么情况下会失效?
索引在MySQL中可能会失效或无法被优化器有效利用的情况有以下几种:
-
使用不等于(!=、<>)操作符:当查询条件包含不等于操作符时,MySQL可能不会使用索引。
-
使用
OR连接条件:如果WHERE子句中的条件是多个通过OR连接的表达式,并且不是所有条件都涉及到索引列,MySQL通常会选择全表扫描而不是使用索引。除非所有的OR条件都能独立地利用索引,或者某些存储引擎支持所谓的“覆盖索引”查询。 -
对索引列进行函数运算或表达式计算:如
SELECT * FROM table WHERE TRIM(column) = 'value'或column + 1 = value,由于索引仅存储原始值,对索引列应用函数或表达式后,数据库无法直接从索引中找到匹配的数据。 -
类型转换导致数据类型不匹配:例如,索引列是整型,但在查询时使用字符串比较,这可能导致MySQL放弃使用索引。
-
前缀索引使用不当:如果为某个字段创建了前缀索引,而查询条件不是基于这个前缀的,则该索引将无法发挥作用。
-
LIKE查询以通配符开头:对于文本类型的索引,如果使用
LIKE关键字并以%开头,如LIKE '%value%',则MySQL无法使用索引进行高效查找。 -
未使用到复合索引的第一列:对于多列索引(复合索引),如果查询没有按照索引列的顺序开始,尤其是没有用到第一列,则后面的列即使出现在查询条件中,也无法利用索引。
-
排序规则不匹配:如果查询中的排序规则与索引所使用的排序规则不一致,也可能导致索引无法被正确使用。
-
范围查询后的其他列:在复合索引中,如果一个范围查询(如
BETWEEN、>、<等)应用于索引的前面部分,那么索引对于范围查询之后的列将不再生效。 -
数据分布过于分散或重复过多:索引的选择性太低(即索引列中唯一值比例很小),使得索引无法有效区分记录,此时优化器可能会选择全表扫描。
为了确保索引的有效使用,应根据实际业务场景和SQL查询特点来设计和维护索引结构,并定期审查查询性能,优化索引策略。同时,了解数据库查询优化器的工作原理有助于更好地理解何时会采用索引以及何时可能会选择全表扫描。
二十、解释MySQL中的JOIN操作。
MySQL中的JOIN操作是用来合并来自两个或更多表的数据行,基于这些表之间某个(或多个)列的共同值。JOIN操作允许在查询中根据指定的关联条件将不同表中的数据进行匹配,并将结果集以一种新的格式呈现出来。
以下是MySQL中最常见的JOIN类型:
-
INNER JOIN(内连接)
SELECT * FROM table1 INNER JOIN table2 ON table1.column = table2.column;内连接返回的是两个表中满足连接条件的记录的交集。只有当“table1”和“table2”的“column”列匹配时,才会出现在结果集中。
-
LEFT JOIN(左连接)
SELECT * FROM table1 LEFT JOIN table2 ON table1.column = table2.column;左连接返回“table1”所有记录以及与之匹配的“table2”记录。如果“table2”中没有与“table1”某条记录相匹配的数据,则结果中“table2”的部分填充为NULL。
-
RIGHT JOIN(右连接)
SELECT * FROM table1 RIGHT JOIN table2 ON table1.column = table2.column;右连接是左连接的对称形式,它返回“table2”所有记录以及与之匹配的“table1”记录。如果“table1”中没有与“table2”某条记录相匹配的数据,则结果中“table1”的部分填充为NULL。
-
FULL OUTER JOIN(全外连接)
MySQL不直接支持全外连接,但可以通过UNION ALL左连接和右连接的结果来模拟:(SELECT * FROM table1LEFT JOIN table2 ON table1.column = table2.column) UNION ALL (SELECT * FROM table1RIGHT JOIN table2 ON table1.column = table2.column WHERE table1.column IS NULL);全外连接会返回两个表中所有记录的并集,无论它们是否匹配。对于没有匹配项的记录,另一表的部分用NULL填充。
-
CROSS JOIN(交叉连接)
SELECT * FROM table1 CROSS JOIN table2;交叉连接返回的是两表的所有可能的组合,即笛卡尔积。它不使用ON子句来定义连接条件。
通过JOIN操作,可以灵活地从多个相关表中检索和整合数据,这对于构建复杂的多表查询至关重要。
二十一、如何优化MySQL查询?
优化MySQL查询性能是一个系统性的工程,涉及多个层面的考量和调整。以下是一些关键的优化策略:
-
索引优化:
- 合理选择列创建索引:在WHERE、JOIN、ORDER BY或GROUP BY语句中频繁使用的列上创建索引,可以显著提高查询速度。
- 避免过度索引:虽然索引有助于快速定位数据,但过多的索引会增加写操作的开销(如INSERT、UPDATE和DELETE),并占用额外的磁盘空间。
- 使用组合索引:对于多列查询条件,使用包含所有相关列的组合索引可能比单个列的索引更有效。
- 索引顺序:组合索引中的列顺序对效率有直接影响,通常应将最能区分数据的列放在前面。
-
查询优化:
- 避免全表扫描:尽可能编写能够利用索引的查询语句,避免无谓的全表扫描。
- 减少查询复杂性:尽量简化查询逻辑,减少嵌套查询的数量,考虑使用连接查询代替子查询,并合并多个相关的查询为一个复合查询。
- 避免不必要的函数和类型转换:在WHERE子句中避免对索引字段进行函数操作或类型转换,这可能导致无法使用索引。
-
SQL语句优化:
- 利用覆盖索引:如果查询仅需要从索引中获取数据而无需访问表本身,则可使用覆盖索引以减少I/O开销。
- 尽量使用等值查询和范围查询:这些类型的查询更容易利用索引。
- 不要在索引列上使用通配符查询的开头部分:如LIKE 'abc%'是有效的,但LIKE '%abc’会导致全表扫描。
-
数据库设计与存储引擎选择:
- 根据应用需求选择合适的存储引擎,例如InnoDB支持事务和行级锁定,适合高并发环境;MyISAM不支持事务但读取速度快,适用于读密集型场景。
- 数据规范化:合理的设计表结构,通过减少冗余数据和依赖关系来提高查询效率。
-
硬件资源及配置调优:
- 适当增加内存:增大MySQL服务器的可用内存,尤其是InnoDB缓冲池大小,可减少磁盘I/O。
- 调整MySQL配置参数:如innodb_buffer_pool_size、query_cache_size、tmp_table_size等,根据实际负载进行调整。
- 分区表:对于非常大的表,可以根据业务需求进行分区,以提高特定查询的性能。
-
缓存机制:
- MySQL内部的查询缓存,在合适的情况下启用并调整其大小和策略。
- 使用外部缓存如Redis或Memcached,将经常查询的结果暂存起来,减轻数据库的压力。
-
监控与分析:
- 使用
EXPLAIN命令分析查询执行计划,识别未使用索引或全表扫描的情况。 - 开启慢查询日志(slow query log),监控和分析运行较慢的查询,针对性地进行优化。
- 使用
-
定期维护与碎片整理:
- 对于InnoDB存储引擎,定期检查并修复表碎片,优化表空间利用率。
综上所述,优化MySQL查询性能是一个持续的过程,它包括但不限于上述方法,具体优化措施需结合实际情况灵活运用。
二十二、什么是索引,它是如何提高查询性能的?
索引是数据库管理系统中用于提高查询性能的数据结构。它通过预先对表中的一个或多个列的值进行排序,并存储指向数据行的指针,从而使得在执行查询时能够更快地定位到所需的数据。
索引如何提高查询性能:
-
减少数据扫描量:
索引就像书的目录一样,当查找特定信息时,不需要翻遍整本书(全表扫描),而是直接根据索引找到对应的数据页或者行。对于SQL查询,如果WHERE子句中包含索引字段,数据库系统可以直接使用索引来快速定位匹配记录的位置。 -
加速排序和分组操作:
当查询涉及到ORDER BY、GROUP BY等需要排序的操作时,若已存在合适的索引,则可以利用索引本身已排序的特点,避免重新排序大量数据,显著提升效率。 -
支持连接操作:
在多表连接查询时,如果相关联的列上都有索引,数据库可以更高效地匹配连接条件,避免不必要的数据比较和临时表创建。 -
过滤和聚合:
对于满足特定条件的行进行过滤或聚合计算时,索引可以帮助数据库快速跳过不满足条件的记录,只处理符合要求的数据。 -
二分查找和B树/B+树结构:
大多数现代关系型数据库(如MySQL)采用B树(或B+树)作为索引结构。这种数据结构允许在O(log n)时间内完成查找操作,相比于无序列表的线性查找(O(n)时间复杂度),查询速度有了数量级的提升。
总之,索引通过将数据按一定规则组织起来,使得在执行搜索、排序和关联查询时能够更快地定位并获取数据,从而极大地提高了数据库系统的查询性能。但需要注意的是,索引并非总是有利无弊,它们会占用额外的存储空间,且更新索引(如INSERT、UPDATE和DELETE操作)也会增加一定的开销。因此,在设计数据库时,应合理评估业务需求及工作负载特点,选择适合的列创建和维护索引。
二十三、解释MySQL中的主键与唯一键的区别。
MySQL中的主键(Primary Key)和唯一键(Unique Key)都是用来确保表中数据列的唯一性的,但它们之间存在一些关键区别:
-
唯一性约束程度:
- 主键:主键列必须具有唯一且非空的值,即每一行的主键值在整个表中都是独一无二的,并且主键字段不允许有NULL值。
- 唯一键:唯一键列也要求其值在表中是唯一的,但与主键不同的是,唯一键列可以包含一个NULL值,而且一个表中可以有多个唯一键列,每个唯一键都可以接受一个NULL值。
-
数量限制:
- 主键:在一个表中只能定义一个主键,由一个或多个列组成。
- 唯一键:一个表中可以定义多个唯一键约束,每个唯一键也可以由一个或多个列组成。
-
索引类型及默认创建情况:
- 主键:主键自动创建一个唯一索引,而且对于InnoDB存储引擎,这个索引是聚簇索引,意味着表的数据按照主键的顺序物理地存储在磁盘上。
- 唯一键:唯一键也会创建一个唯一索引,但是这个索引是非聚集索引,不会影响表数据的物理存储顺序。
-
作为外键引用:
- 主键:主键可以被其他表用作外键(Foreign Key),建立表间关系。
- 唯一键:虽然唯一键也可以被其他表参照以保证关联字段的唯一性,但它通常不作为外键来建立直接的约束关系。然而,在实际应用中,有时会通过唯一键创建间接的参照完整性约束。
-
业务含义和用途:
- 主键:主要用于唯一标识表中的每一条记录,常用于查找、关联和更新操作,它的选择通常非常谨慎,因为它是记录的关键标识符。
- 唯一键:更多是为了满足特定业务逻辑的需求,避免某个字段或者一组字段出现重复值,而不一定是为了唯一标识记录。例如,用户邮箱地址或身份证号等信息可能需要确保唯一,但并不适合作为整个记录的主键。
总结来说,主键不仅是唯一标识符,还规定了表的物理结构,并强制执行严格的唯一性和非空性规则;而唯一键则提供了更为灵活的唯一性约束,允许为空,并且可应用于多列组合以及满足特定业务需求的场景。
二十四、什么是视图,它有什么优点?
在MySQL以及其他关系型数据库管理系统中,视图(View)是一个虚拟表,它基于一个或多个实际表中的数据,但并不存储任何实际数据。视图是由SELECT语句定义的,并且当查询视图时,数据库会动态地执行相应的查询以生成结果集。
视图的主要优点包括:
-
简单性与用户友好:
视图可以简化对复杂查询的理解和使用。通过将复杂的SQL查询封装成视图,用户只需直接查询视图即可获取所需的数据,无需了解底层表结构及关联条件等细节。 -
安全性:
视图可以用来限制用户对数据的访问权限。管理员可以根据需要创建只包含部分列或经过筛选后的行的视图,从而隐藏敏感数据或实现不同级别的授权管理。用户只能看到并操作视图所展现的数据,而不能直接访问底层基础表。 -
逻辑数据独立性:
当数据库表结构发生变化时,可以通过修改视图来适应这些变化,而不影响依赖于视图的应用程序代码。这样,可以在一定程度上保护应用程序不受物理数据库结构调整的影响。 -
定制化与抽象:
视图允许根据业务需求自定义数据呈现方式,例如聚合函数计算、特定字段的组合或转换等。此外,视图还可以作为数据的逻辑分层,使得不同的用户或者部门可以从各自的角度查看同一份数据的不同方面。 -
提高性能与查询优化:
在某些情况下,视图可以帮助简化查询逻辑,减少查询重复计算,数据库系统也可能利用视图进行查询优化,从而提升查询效率。 -
数据一致性:
由于视图是基于实际表创建的,所以只要基础表的数据发生更新,查询视图时得到的结果也会随之自动更新,保持了数据的一致性。
总之,视图提供了一种抽象和隔离机制,不仅有助于简化数据访问和管理,还能在不影响应用的前提下增强数据的安全性和灵活性。
二十五、MySQL中的存储过程是什么?
MySQL中的存储过程(Stored Procedure)是一种预编译的SQL语句集合,它被封装在数据库中作为一个可重复调用的单元。存储过程允许用户定义一组完成特定任务的SQL语句、控制流语句(如条件判断和循环)、变量声明、以及数据处理逻辑,并为这个逻辑块赋予一个名称。通过这个名字,应用程序或脚本可以调用存储过程并执行其中定义的操作。
存储过程的主要特点和优点包括:
- 封装性:将复杂的操作封装在一起,简化客户端代码,提高代码重用性。
- 性能提升:存储过程在服务器端编译后存储,执行时无需每次都解析和编译SQL语句,因此执行效率相对更高。
- 减少网络流量:只需要调用存储过程名及其参数,减少了在网络上传输大量SQL语句所带来的开销。
- 事务管理:存储过程可以包含事务控制,确保一系列数据库操作要么全部成功,要么全部回滚,保证数据的一致性和完整性。
- 安全性增强:通过权限控制来限制对存储过程的访问,可以隐藏底层表结构和实现细节,增加系统的安全性和数据的保护程度。
创建MySQL存储过程通常使用CREATE PROCEDURE语句,其内部可以定义输入参数(IN)、输出参数(OUT)、输入输出参数(INOUT),并且可以返回结果集给调用者。存储过程体内的SQL语句按照一定的顺序执行,并且支持错误处理和流程控制结构。
二十六、Mysql什么是归一化?它有哪些类型?
在MySQL数据库中,归一化(Normalization)通常指的是数据库设计中的规范化过程,它是一种组织和设计数据库表结构的方法,目的是减少数据冗余、提高数据一致性,并简化数据更新操作。归一化是基于关系理论的一系列原则,通过将数据分散到多个相互关联的表中来实现。
归一化的类型主要依据范式(Normal Forms, NF)来划分,常见的有以下几种:
-
第一范式(1NF, First Normal Form):
数据表的每一列都不可再分,即每个属性的值都是原子性的,不能包含其他值的集合或记录。 -
第二范式(2NF, Second Normal Form):
在满足1NF的基础上,消除非主属性对候选键的部分函数依赖。即所有非主属性完全依赖于整个候选键,而不是只依赖于候选键的一部分。 -
第三范式(3NF, Third Normal Form):
在满足2NF的基础上,消除非主属性对候选键的传递函数依赖。即一个非主属性不依赖于另一个非主属性。 -
BCNF(Boyce-Codd Normal Form):
比3NF更严格的范式,要求每一个决定因素必须是一个超键(superkey),以消除任何可能的非平凡的函数依赖问题。 -
第四范式(4NF, Fourth Normal Form):
用于解决多值依赖的问题,确保表中不存在一个非平凡且非函数依赖的多值依赖。 -
第五范式(5NF, Fifth Normal Form):
又称投影-join范式(PJ/NF),它消除了表中存在的连接依赖性,使得表中的每一份信息都可以通过表自身的属性唯一确定。
在实际应用中,根据业务需求和性能考虑,数据库设计时并不总是追求最高的范式级别,而是要在数据冗余与查询效率之间找到平衡点。
另外,您提到的数据归一化(Data normalization)也可能是指数据分析领域的概念,这里指的是数值处理的一种方法,用于将不同规模或单位的数据转换为同一尺度上的表示,便于比较和分析。例如,在机器学习和数据挖掘中常见的两种数据归一化方法是:
- 最小-最大标准化(Min-Max Scaling):将原始数据按比例缩放至[0, 1]或其他指定区间内。
- Z-score标准化(Standardization):也称为标准差标准化,通过减去均值并除以标准差,使数据转换为标准正态分布的形式,其中均值为0,标准差为1。
二十七、解释MySQL中的外键。
在MySQL以及其他关系型数据库中,外键(Foreign Key)是一种用于确保数据完整性和表间关联性的机制。它是一个或一组列,其值来源于另一个表的主键或者唯一键。
具体来说:
-
定义与作用:
外键是指在一个表(称为从表或子表)中的一个字段或多个字段,这些字段的值必须与另一个表(称为主表或父表)的主键或唯一索引列的值相对应。这样设置的目的在于建立两个表之间的引用关系,确保从表中的记录只包含主表中存在的有效值。 -
完整性约束:
- 级联操作:当主表中的数据发生变化时,可以配置外键约束以执行级联操作,如级联删除(CASCADE)、级联更新(UPDATE)等。
- 防止引用不存:外键约束会阻止用户向从表插入违反外键约束的数据,即从表不能插入不在主表中已存在的主键值,从而保证了参照完整性。
-
关系模型:
在关系数据库设计中,外键是实现实体之间关联的重要手段。例如,在“订单”表中,可能会有一个外键字段“客户ID”,该字段的值对应于“客户”表的主键“客户ID”,这样就表明每个订单都属于特定的一个客户。 -
索引与性能:
MySQL中,为了支持外键约束,通常会在外键列上创建索引,以便快速查找和验证关联性。这有助于提升查询性能,特别是在JOIN操作中。 -
使用注意事项:
使用外键约束需要权衡数据一致性与事务处理复杂度以及写入性能的影响。某些情况下,尤其是对于大数据量且高并发场景,可能会选择牺牲外键约束来换取更高的写入速度。
综上所述,MySQL中的外键是一种强大的工具,通过它可以维护不同表之间数据的一致性,并为开发者提供了灵活的方式来构建复杂的、相互关联的数据结构。
二十八、解释MySQL中的事务隔离级别以及它们如何影响并发。
MySQL中的事务隔离级别是数据库管理系统为确保在并发环境中执行多个事务时的数据一致性而设置的不同级别的控制策略。四种主要的事务隔离级别分别是:
-
读未提交(Read Uncommitted)
- 在这个级别,一个事务可以读取到其他事务尚未提交的数据变更,这被称为“脏读”(Dirty Read)。此级别并发控制最弱,可能导致数据不一致。
-
读已提交(Read Committed)
- 一个事务只能看到已经提交的数据,即在同一事务中,即使先前读取过的数据被其他事务修改并提交后,再次读取同一行时会获取到最新的已提交值,这可能会导致不可重复读(Non-Repeatable Read),即在同一个事务内多次读取同一条记录得到的结果不同。
-
可重复读(Repeatable Read)
- 这是MySQL默认的事务隔离级别。在一个事务开始之后,对于该事务内的任何查询,即使有其他事务对数据进行了修改和提交,也始终能看到事务开始时的数据状态,不会出现不可重复读的问题。然而,在这种隔离级别下,如果其他事务插入了新的行(这些新行符合当前事务查询条件),则在当前事务中无法看到这些新增行,这种情况称为幻读(Phantom Read)。
-
串行化(Serializable)
- 最严格的事务隔离级别,强制所有事务按照顺序逐一执行,等效于完全禁止了事务之间的并发操作。它通过额外的锁定机制(如范围锁或表级锁)来避免脏读、不可重复读以及幻读问题,但这也意味着牺牲了系统的并发性能。
不同的事务隔离级别影响并发的主要方式如下:
- 读未提交:并发性较高,但数据安全性较低。
- 读已提交:减少了脏读的发生,但仍允许不可重复读,提高了数据安全性但并发性能有所下降。
- 可重复读:进一步防止了不可重复读,适用于大部分需要保证事务内部读取结果一致性的场景,但并发情况下仍可能出现幻读。
- 串行化:提供了最高程度的数据一致性保障,但并发性能最低,通常只在非常严格的数据一致性要求下使用。在大多数情况下,开发人员会选择适当降低隔离级别以平衡数据一致性与系统性能之间的关系。
二十九、如何在MySQL中使用索引优化查询?
在MySQL中使用索引优化查询性能,主要涉及以下策略和步骤:
-
选择合适的列创建索引:
- 索引应建立在WHERE、JOIN、ORDER BY、GROUP BY语句中频繁使用的列上。
- 对于主键(Primary Key)和唯一约束(UNIQUE)的列,MySQL会自动创建索引。
- 对于经常用于搜索的大表,并且数据分布均匀的列,尤其是作为过滤条件或连接条件的列,应该考虑添加索引。
-
组合索引(复合索引)的使用:
- 如果查询涉及多个列的比较,可以创建一个包含这些列的组合索引。注意,索引列的顺序很重要,应按照最能区分数据的列到最不区分的列排列。
-
覆盖索引(Covering Index):
- 如果查询只需要从索引中获取所有需要的数据,而无需访问实际的数据行,这种索引称为覆盖索引。这可以极大地减少I/O操作并提高查询速度。
-
避免过度索引:
- 尽管索引有助于查询速度提升,但过多的索引也会占用额外的存储空间,并可能导致插入、更新和删除操作变慢,因为每次修改都会同时更新索引。
- 对于大量写入操作的表,要权衡索引对查询性能提升与维护成本之间的关系。
-
考虑查询模式:
- 理解应用程序中的常见查询模式,并根据这些模式创建相应的索引。例如,如果应用中有大量的范围查询,确保索引支持这样的查询类型。
-
B-Tree vs 哈希索引:
- InnoDB默认使用B-Tree索引,适用于大多数查询场景,包括范围查询和等值查询。
- MEMORY存储引擎支持哈希索引,仅适用于等值查询,不适合排序或范围查询。
-
全文索引:
- 对于全文本搜索需求,可为文本列创建全文索引,以提高全文搜索的效率。
-
定期检查和优化索引:
- 使用
EXPLAIN分析SQL查询执行计划,查看是否正确使用了索引。 - 定期监控并清理不再使用的索引,以及调整索引结构以适应变化的查询负载。
- 使用
-
索引维护:
- 针对InnoDB存储引擎,随着时间推移,由于数据插入、删除和更新,可能产生索引碎片,需要通过OPTIMIZE TABLE或者ALTER TABLE … ENGINE=INNODB来优化表和索引。
通过以上策略结合具体应用场景和业务逻辑进行索引设计和管理,可以有效地利用索引来优化MySQL数据库的查询性能。
三十、MySQL中的慢查询日志是什么,如何使用它来优化性能?
MySQL中的慢查询日志(Slow Query Log)是一个记录了执行时间超过特定阈值的SQL语句的日志文件。MySQL服务器通过配置参数long_query_time来设置这个阈值,当一个查询的执行时间超过该设定值时,MySQL会将这个查询的相关信息记录到慢查询日志中。
慢查询日志的内容通常包括执行较慢的SQL语句文本、执行时间、锁等待时间以及客户端信息等,这些信息有助于数据库管理员和开发者定位那些可能影响系统性能的查询。
使用慢查询日志优化MySQL性能的过程主要包括以下几个步骤:
-
开启慢查询日志:
- 在MySQL配置文件(如my.cnf或my.ini)中启用慢查询日志功能,并设置合适的
long_query_time值。
[mysqld] slow_query_log = 1 long_query_time = 1 # 可以根据实际需求调整秒数,默认是10秒 slow_query_log_file = /path/to/slow-query.log # 设置慢查询日志的路径 - 在MySQL配置文件(如my.cnf或my.ini)中启用慢查询日志功能,并设置合适的
-
收集和分析日志:
- MySQL重启后,慢查询日志将开始记录符合条件的查询。需要定期检查和分析慢查询日志文件,可以使用MySQL自带的工具
mysqldumpslow对日志进行统计分析,或者直接用文本编辑器查看。 mysqldumpslow可以帮助按照各种条件过滤并排序日志内容,快速找到最耗时的查询。
- MySQL重启后,慢查询日志将开始记录符合条件的查询。需要定期检查和分析慢查询日志文件,可以使用MySQL自带的工具
-
查询优化:
- 对于发现的慢查询,可以通过以下方式进行优化:
- 使用
EXPLAIN命令分析查询执行计划,检查是否正确使用索引,是否存在全表扫描等问题。 - 优化查询语句结构,比如避免不必要的子查询,尽量利用索引,减少JOIN操作的数据量等。
- 考虑添加适当的索引,特别是对于WHERE、ORDER BY和GROUP BY子句中涉及的列。
- 检查数据冗余和表设计,确保数据模型满足第三范式或适当反范式化以提高查询效率。
- 使用
- 对于发现的慢查询,可以通过以下方式进行优化:
-
监控与持续改进:
- 定期复查慢查询日志,结合应用的变更和负载情况不断优化查询性能。
- 结合其他性能监控工具和指标(如InnoDB状态变量、SHOW STATUS结果),全面了解数据库的运行状况。
总之,慢查询日志为优化MySQL性能提供了一个非常重要的参考依据,通过对日志的分析和处理,我们可以针对性地改进数据库查询性能,提升整个系统的响应速度和稳定性。
三十一、MySQL中如何实现主从复制?
MySQL的主从复制(Master-Slave Replication)是一种数据备份和分布式读取负载均衡的技术,通过将主数据库(master)的更新操作同步到一个或多个从数据库(slave)来实现。以下是在MySQL中实现主从复制的一般步骤:
-
配置主库:
- 确保主库开启了二进制日志(Binary Log),这是复制的基础,记录了所有更改数据库的数据修改语句。在MySQL服务器配置文件(如my.cnf或my.ini)中添加以下配置:
server-id=1 # 为主库分配一个唯一的ID log-bin=mysql-bin # 启用二进制日志,并指定日志文件前缀
- 确保主库开启了二进制日志(Binary Log),这是复制的基础,记录了所有更改数据库的数据修改语句。在MySQL服务器配置文件(如my.cnf或my.ini)中添加以下配置:
-
创建并授权复制用户:
在主库上创建一个专门用于复制的用户,并赋予其从库连接主库时所需的权限。例如:GRANT REPLICATION SLAVE ON *.* TO 'replication_user'@'%' IDENTIFIED BY 'password'; FLUSH PRIVILEGES; # 刷新权限使其生效 -
获取主库状态信息:
获取主库当前二进制日志的位置,以便在从库上设置同步点:SHOW MASTER STATUS;结果会显示
File(二进制日志文件名)和Position(下一个事件要写入的位置)。 -
配置从库:
- 修改从库的配置文件,同样为其分配一个唯一的ID,并设置主库的信息:
server-id=2 # 为从库分配一个与主库不同的唯一ID relay-log=mysql-relay-bin # 指定中继日志文件前缀 change-master-to master_host='主库IP地址', master_user='replication_user', master_password='password', master_log_file='File', master_log_pos=Position; # 设置主库连接参数和同步点
- 修改从库的配置文件,同样为其分配一个唯一的ID,并设置主库的信息:
-
启动从库复制:
在从库上启动复制服务:START SLAVE;可以通过
SHOW SLAVE STATUS\G来检查从库的复制状态,确保已经成功连接到主库并开始接收和执行更新。 -
监控与维护:
定期检查主从之间的复制延迟情况,以及复制是否正常运行。当主库发生变更时,如新增表、修改结构等,可能需要在从库上手动执行相同的操作,或者使用mysqlbinlog工具分析并应用相应的二进制日志事件。
请注意,在实际环境中,上述步骤可能会因MySQL版本和具体配置而有所差异。同时,为了保证数据一致性及高可用性,建议采用一主多从或多主多从架构,并考虑启用半同步复制、GTID(全局事务标识符)等功能进行更高级别的管理和优化。
三十二、解释MySQL中的分区表,它如何提高性能?
MySQL中的分区表(Partitioned Tables)是将一个大表逻辑上分割成多个较小的部分,每个部分称为一个分区。虽然从用户视角来看,分区表仍然是一个完整的表,但实际上它由多个物理子表组成,每个子表都存储了原始表的一部分数据。
分区表如何提高性能:
-
查询优化:
- 分区允许数据库系统仅扫描与查询条件匹配的分区,而不是整个大表。例如,基于日期范围分区时,如果只查询某个月的数据,则只需要访问该月对应的分区,从而显著减少磁盘I/O和CPU处理时间。
-
索引效率:
- 对于大型表,全表扫描和索引维护的成本较高。通过分区,可以更有效地管理和维护索引,尤其是对于那些具有大量行但热点数据集相对较小的情况。
-
并行处理:
- 在某些情况下,MySQL能够同时对不同的分区执行操作,如独立地对各个分区进行排序、合并或删除,这在一定程度上实现了并行化处理,提高了大规模操作的执行速度。
-
快速数据管理:
- 当需要删除过期数据或者根据特定条件批量更新数据时,可以通过删除或修改相关的分区来快速完成操作,比直接在大表上执行要高效得多。
-
备份与恢复:
- 大表的备份和恢复通常很耗时。而分区表可以按需备份和恢复单个分区,这对于维护活动数据和归档历史数据非常有用。
-
负载均衡:
- 如果不同分区被分布到不同的物理存储设备上,可以分散I/O压力,改善存储系统的整体性能。
需要注意的是,并非所有的查询都能从分区中受益,而且创建和维护分区表也需要一定的开销。正确设计和使用分区策略至关重要,比如按照数据访问模式、业务需求以及数据分布特点选择合适的分区键和分区方法。此外,针对InnoDB存储引擎,MySQL支持的分区类型包括RANGE、LIST、HASH和KEY等,每种类型的分区都有其适用场景和优缺点。
三十三、在MySQL中,如何处理死锁?
在MySQL中,死锁是指两个或多个事务在执行过程中,由于资源争用而造成的一种循环等待现象,每个事务都在等待其他事务释放它需要的资源,从而导致所有事务都无法继续执行。
处理MySQL中的死锁通常包括预防和解决两部分:
预防死锁:
-
事务设计优化:
- 尽量减少事务的持续时间,尽快提交或回滚事务。
- 对于涉及多表更新的操作,按照相同的顺序访问表,以避免交叉锁定资源时产生死锁。
- 减少锁定范围:只锁定必要的行,而不是整个表或者大量数据。
-
设置合理的隔离级别:
- 虽然较低的隔离级别(如读已提交)会降低发生死锁的可能性,但也可能引入其他并发问题。因此,应根据业务需求合理选择隔离级别,并考虑使用更高级别的并发控制机制。
-
资源申请顺序一致:
- 在应用层面确保同一事务对多个资源的获取有固定的顺序,可以有效减少死锁概率。
-
死锁检测与超时设置:
- MySQL InnoDB存储引擎默认开启了死锁检测功能,如果检测到死锁,系统会选择其中一个事务进行回滚来打破死锁链。
- 可以通过
innodb_lock_wait_timeout参数设置事务等待锁定资源的时间,超过该时间后,事务将自动回滚并返回错误,有助于防止长时间的死锁僵持。
解决死锁:
-
自动检测与回滚:
- 如前所述,InnoDB引擎可以通过等待图(wait-for graph)算法自动检测死锁,并自动回滚一个或多个事务以解除死锁状态。
-
手动干预:
- 当发现数据库出现死锁时,可以使用
SHOW ENGINE INNODB STATUS;命令查看当前系统的InnoDB状态信息,其中包含了最近的死锁详细信息。 - 如果有必要,管理员可以直接通过
KILL命令终止特定的事务ID来解决死锁,但这种方法需谨慎操作,以免影响正常业务。
- 当发现数据库出现死锁时,可以使用
-
应用层重试策略:
- 在应用程序中实现事务失败后的重试逻辑,当遇到死锁相关的错误时,重新发起事务请求,可能会在下一次尝试时成功,因为之前引起死锁的事务可能已经被系统自动回滚。
总之,处理MySQL中的死锁是一个结合了SQL语句编写规范、数据库配置调整以及应用程序逻辑设计的过程。通过细致的设计和良好的管理实践,可以最大限度地减少死锁的发生,并在出现死锁时能够快速有效地处理。
三十四、MySQL如何执行子查询,以及它们的性能影响是什么?
MySQL执行子查询的过程可以描述为:
-
子查询的解析与优化:
当遇到一个包含子查询的SQL语句时,MySQL首先会对整个查询进行解析,并将子查询视为内部查询或嵌套查询。MySQL会分析子查询中的逻辑和所涉及的表结构。 -
子查询执行:
MySQL会先执行子查询,生成一个临时的结果集。这个结果集通常被称为“派生表”(Derived Table)或者“内表”(Inner Table)。对于IN、EXISTS等类型的子查询,MySQL会执行子查询直至得到所有满足条件的行。 -
主查询与子查询结合:
子查询执行完毕后,MySQL会将临时结果集与外部查询结合起来进一步处理。例如,如果是SELECT * FROM table1 WHERE column IN (SELECT column FROM table2)这样的查询,MySQL会先执行子查询找出table2中符合条件的所有column值,然后在table1中查找匹配这些值的行。 -
性能影响:
- 资源消耗:子查询需要额外的计算资源来生成临时结果集,尤其是当子查询返回大量数据时,这可能会消耗更多内存和CPU时间。
- 索引利用:如果子查询能够有效利用索引,那么其性能可能较好;反之,若子查询无法利用索引或导致全表扫描,则可能导致性能下降。
- 连接操作替代:在某些情况下,MySQL优化器会选择将子查询转换成等价的JOIN操作,这种转换有时可以提高性能,因为JOIN操作可以直接在数据库层面关联两个表的数据,避免了生成和使用临时结果集。
- 锁定行为:在并发环境中,子查询可能会影响锁定行为,特别是当它涉及写操作或长时间持有锁时,其他事务可能会被阻塞,从而影响系统整体性能。
为了提升子查询的性能,开发者应确保子查询:
- 结果集尽可能小。
- 使用有效的索引以减少全表扫描。
- 如果可能,尽量改写为JOIN操作或使用半连接(如LEFT JOIN + WHERE IS NULL)。
- 考虑设置合适的
optimizer_switch参数,允许MySQL灵活选择最优执行计划。
同时,定期检查并分析EXPLAIN输出,了解MySQL如何执行子查询,以及是否有效地利用了索引,也是优化子查询性能的重要步骤。
三十五、解释MySQL的GROUP BY和HAVING子句
MySQL中的GROUP BY和HAVING子句在执行聚合查询时起到关键作用,用于对数据进行分组并基于这些组应用条件过滤。
GROUP BY 子句
GROUP BY语句用于将表中的行按一个或多个列的值进行分组。当你想要计算每个分类的总和、平均值、最大值、最小值或其他聚合函数时,这个子句是必需的。基本语法如下:
SELECT column1, column2, aggregate_function(column3)
FROM table_name
GROUP BY column1, column2;
在这个例子中:
- MySQL会首先根据
column1和column2的值对表中的行进行分组。 aggregate_function(column3)指的是可以应用于每组的聚合函数,例如COUNT(), SUM(), AVG(), MAX(), 或 MIN()等。
HAVING 子句
HAVING子句与WHERE子句类似,但它是在GROUP BY之后使用的,用于筛选满足特定条件的分组,而不是单个行。HAVING允许你在聚合级别上应用条件,而WHERE不能直接作用于聚合函数的结果。
SELECT column1, column2, aggregate_function(column3)
FROM table_name
GROUP BY column1, column2
HAVING condition;
这里的condition通常涉及聚合函数的结果,例如:
HAVING COUNT(column3) > 5; -- 只返回那些在column3上有超过5条记录的组
HAVING SUM(column4) > 100; -- 只返回那些column4之和大于100的组
总结一下:
GROUP BY用于将数据分割成多个逻辑组,每个组由指定列的一个唯一组合标识。HAVING则进一步筛选这些分组,只返回满足给定条件的组。
在没有使用GROUP BY的情况下直接使用HAVING是没有意义的,因为HAVING针对的是分组后的结果集。同时,在WHERE子句中无法直接使用聚合函数来筛选数据,这时就需要HAVING子句来进行此类操作。
三十六、 如何在MySQL中创建和使用触发器?
MySQL中的触发器(Trigger)是一种特殊的数据库对象,它会在特定的数据库操作(如INSERT、UPDATE或DELETE)执行前后自动调用并执行预定义的一组SQL语句。触发器与特定的表相关联,并在满足指定条件时响应数据的变化。
当触发事件发生时,例如向一个表中插入一行新记录,相应的触发器就会被激活并执行其内含的操作。这些操作可以包括但不限于:
- 更新其他表的数据
- 插入新的记录到其他表
- 检查数据一致性或完整性
- 记录审计信息到日志表
- 实现复杂的业务逻辑
触发器的作用是保证数据库中数据的完整性和一致性,并能够自动完成一些常规性的任务,减轻应用程序对数据库操作后的处理负担。
在MySQL中创建和使用触发器的基本步骤如下:
创建触发器
-
语法:
CREATE TRIGGER trigger_name trigger_time trigger_event ON table_name [FOR EACH ROW] BEGIN-- 触发器操作的SQL语句 END;trigger_name:为触发器指定一个唯一的名字。trigger_time:触发器执行的时间点,可以是BEFORE或AFTER,表示在事件发生前或发生后执行触发器中的逻辑。trigger_event:触发器被激活的数据库操作,可以是INSERT、UPDATE或DELETE。table_name:触发器关联到的表名。FOR EACH ROW(可选):如果指定了这个选项,那么对于受影响的每一行都会执行触发器内的SQL语句。
-
示例:
假设有一个orders表,并希望在每次插入新订单时自动更新库存表inventory。CREATE TRIGGER update_inventory_after_insert_order AFTER INSERT ON orders FOR EACH ROW BEGINUPDATE inventory SET quantity = quantity - NEW.quantity WHERE product_id = NEW.product_id; END;上述触发器会在
orders表中插入新行后执行,将对应商品的库存数量减少新订单的数量。
使用触发器
-
一旦触发器创建完毕,它会自动根据定义的条件运行。无需在应用程序代码中显式调用触发器,只要执行了触发该触发器的操作(如INSERT、UPDATE或DELETE),触发器就会自动执行其内部定义的SQL语句。
-
若要查看已创建的触发器,可以使用以下查询:
SHOW TRIGGERS LIKE 'trigger_name'; -
若要禁用或删除触发器:
- 禁用触发器(MySQL 8.0以上版本支持):
ALTER TABLE table_name DISABLE TRIGGER trigger_name; - 删除触发器:
DROP TRIGGER trigger_name;
- 禁用触发器(MySQL 8.0以上版本支持):
请注意,触发器会影响数据库的行为,应谨慎使用以确保不会引入意外的数据一致性问题或性能瓶颈。同时,在设计触发器时,要充分考虑事务处理、死锁以及数据完整性的问题。
三十七、什么是MySQL的二进制日志(binlog)?它有什么作用?
MySQL的二进制日志(Binary Log)是MySQL服务器用于记录所有更改数据库数据的逻辑操作的一个持久化日志文件。在MySQL中,每当发生对数据的修改操作,如INSERT、UPDATE、DELETE或DDL语句(如CREATE TABLE、ALTER TABLE等),都会将这些操作以事件的形式记录到二进制日志中。
二进制日志的作用主要包括:
-
主从复制(Replication)
二进制日志是MySQL实现主从复制的关键组件。在主从架构中,主库产生的二进制日志会被传输给从库,并在从库上按顺序重新执行,从而保持主从数据库间的数据一致性。 -
数据恢复与审计
- 数据恢复:如果主数据库发生故障,可以通过应用二进制日志中的事件来恢复丢失的数据变更。
- 审计:二进制日志可以作为数据库活动的历史记录,用于监控和追踪数据库的变更历史,为安全性和合规性审计提供依据。
-
增量备份
在进行增量备份时,可以根据二进制日志记录自上次全备以来的所有数据库更新,便于快速生成差异备份。 -
基于时间点的数据恢复
如果需要将数据库还原到特定的时间点,可以使用二进制日志配合mysqlbinlog工具找到对应时间点前的日志事件,然后停止在该点之前的事务,从而实现数据恢复。
总之,MySQL的二进制日志提供了数据库状态变化的完整历史记录,对于维护数据一致性和保障系统可用性至关重要。
三十八、解释MySQL中的索引覆盖扫描是什么?
MySQL中的索引覆盖扫描(Index Covering Scan)是指在执行SQL查询时,MySQL能够直接从索引中获取到满足查询所需的所有列数据,而无需再访问表的数据行。这意味着数据库服务器不需要进行回表操作(即根据索引检索到的行指针回到主键或聚集索引去查找对应行的完整数据),它完全通过读取索引就可以得到查询结果。
索引覆盖扫描的优点包括:
- 减少I/O:由于索引通常比数据行小得多,因此仅读取索引所需的磁盘I/O和内存使用量会显著降低。
- 提高性能:避免了对大量数据行的随机访问,特别是对于范围查询或者按照索引顺序进行的查询,可以更有效地利用存储引擎的缓存机制。
- 加速查询:因为MySQL可以直接从索引中获取所有需要的信息,整个查询过程可以更快地完成。
为了实现索引覆盖扫描,查询语句必须设计得能利用一个包含所有所需列的索引,无论是单列索引还是复合索引。此外,在创建索引时,应当考虑到实际的查询需求以及数据选择性等因素来优化索引结构。
三十九、如何在MySQL中使用EXPLAIN命令?
在MySQL中,`EXPLAIN`命令用于分析SQL查询的执行计划,帮助我们理解MySQL如何处理SELECT语句,包括它如何访问表、使用哪些索引以及查询的执行顺序等。以下是使用`EXPLAIN`命令的基本步骤:```sql
EXPLAIN [EXTENDED | FORMAT = {TRADITIONAL | JSON}] SELECT ...;
-
基本用法:
- 将
EXPLAIN关键字放在要分析的SELECT语句前。
EXPLAIN SELECT * FROM your_table WHERE some_column = 'some_value'; - 将
-
结果解读:
EXPLAIN输出的结果列通常包括:id,select_type,table,type,possible_keys,key,key_len,ref,rows,filtered,Extra等字段。- 这些字段分别代表了查询优化器对查询操作的排序(执行顺序)、所使用的查询类型、涉及的表、访问方法、可能使用的索引、实际选择的索引、索引长度、关联字段、预计扫描行数、过滤条件的预估效率以及额外信息等。
-
扩展用法:
- 使用
EXPLAIN EXTENDED可以获取更多的执行计划信息,比如临时表和文件排序的信息。 - MySQL 8.0版本开始支持JSON格式的输出,可以通过
FORMAT=JSON选项来获取JSON形式的执行计划。
EXPLAIN EXTENDED SELECT * FROM your_table WHERE some_column = 'some_value'; SHOW WARNINGS; -- 查看额外的解释信息EXPLAIN FORMAT=JSON SELECT * FROM your_table WHERE some_column = 'some_value'; - 使用
通过分析EXPLAIN命令返回的信息,我们可以识别出是否正确使用了索引,是否存在全表扫描,表之间的连接方式,以及优化查询性能的方向。例如,如果看到type为ALL表示全表扫描,那么可能是缺少合适的索引;若key列为空,说明没有使用到任何索引等。根据这些信息,我们可以针对性地优化SQL查询或数据库结构。
四十、MySQL中的锁定粒度是什么意思?
MySQL中的锁定粒度(Lock Granularity)指的是数据库系统在执行事务处理时,锁定数据资源的最小单位。不同的存储引擎支持不同级别的锁定粒度,主要包括以下几种:
-
表级锁(Table-level Locking):
- 在这种粒度下,整个数据表被锁定以防止并发访问。当一个事务对表进行写操作(如UPDATE、DELETE或INSERT)时,其他所有事务都无法同时对该表进行读写操作。MyISAM存储引擎主要使用的就是表级锁定。
-
行级锁(Row-level Locking):
- 行级锁允许在同一时刻多个事务分别锁定不同行的数据进行操作,而不影响其他行的并发访问。InnoDB存储引擎支持行级锁定,这可以极大地提高并发性能,因为只锁定需要修改的行而不是整个表。
-
页级锁(Page-level Locking):
- 介于表级和行级之间的锁定粒度,锁定的是数据库中一页内的所有记录。例如,在Berkeley DB(BDB)存储引擎中曾经支持页级锁定,但MySQL 8.0及更高版本已不再支持该存储引擎。
锁定粒度越细,系统的并发能力通常会越高,因为可以减少事务间的等待时间;但与此同时,更细粒度的锁定管理也意味着更高的开销。因此,选择合适的锁定粒度是优化数据库并发性能的重要策略之一。
四十一、在MySQL中,UTF-8和UTF8MB4的区别是什么?
在MySQL中,UTF-8和UTF8MB4都是用于存储Unicode字符集的编码方式,但它们之间存在一个关键区别:
UTF-8(MySQL中的实现):
- MySQL早期版本对UTF-8的支持是不完整的,它将UTF-8最多限制为3个字节的编码,这意味着它只能覆盖到基本多文种平面(BMP, Basic Multilingual Plane),即Unicode范围U+0000至U+FFFF之间的字符。
- 这意味着MySQL的UTF-8编码无法存储包含4字节编码的Unicode字符,例如表情符号(Emoji)、一些辅助平面汉字或其他特殊字符。
UTF8MB4:
- 为了支持4字节的Unicode字符,MySQL从5.5.3版本开始引入了UTF8MB4编码格式。
- UTF8MB4完全兼容标准的UTF-8编码,并且能够存储包括基本多文种平面之外的其他字符,比如那些需要4字节编码的字符,如许多表情符号、部分少数民族字符等。
- 使用UTF8MB4编码可以确保数据库能完整地存储所有Unicode字符,而不会出现因超出3字节限制而导致的数据插入失败等问题。
因此,若应用程序可能涉及到处理4字节的Unicode字符,应使用UTF8MB4作为字符集以确保数据完整性。同时,由于UTF8MB4与UTF-8向下兼容,对于大部分只包含基本多文种平面内的字符的数据,两者并无实质差异。
四十二、MySQL如何处理大型事务?
MySQL处理大型事务时,需要考虑到事务的大小、执行时间以及对系统资源(如内存、CPU和磁盘I/O)的影响。以下是一些处理大型事务的关键策略:
-
优化事务设计:
- 减小事务的粒度:将大事务拆分为多个小事务,并确保每个小事务都是原子且独立的,这样可以减少单个事务锁定资源的时间,降低锁冲突。
- 避免长事务:尽量减少事务的持续时间,避免长时间持有锁,从而降低死锁概率和资源争用。
-
合理使用锁:
- 选择正确的隔离级别:在并发环境下,适当降低隔离级别(如从可重复读到读已提交),可能有助于减轻锁竞争,但要注意这可能会引入不可重复读或幻读问题。
- 使用行级锁定:InnoDB存储引擎默认支持行级锁定,对于涉及大量数据更新的操作,应尽量确保只锁定需要修改的数据行,而不是整个表或索引。
-
批量操作:
- 对于大批量的数据插入、更新或删除操作,可以采用分批处理的方式,每一批次提交一次事务,以减少一次性占用的资源量。
- 对于大型INSERT操作,可以考虑使用LOAD DATA INFILE或者批量INSERT语句,它们通常比逐条插入更高效。
-
资源监控与调优:
- 监控服务器资源使用情况,包括InnoDB缓冲池、线程缓存等关键参数,根据实际负载调整相关配置,保证有足够的资源来处理大型事务。
- 如果事务涉及到大量的临时表创建或排序,应当检查tmp_table_size和max_heap_table_size参数设置,必要时增大这些值以避免在内存中创建临时表时转换为磁盘上的MyISAM表。
-
事务日志管理:
- 确保innodb_log_file_size足够大,能够容纳大型事务产生的日志内容,否则频繁的日志切换会导致性能下降。
- 在事务执行前检查InnoDB redo log空间是否充足,并确保有合理的redo log刷盘策略(innodb_flush_log_at_trx_commit配置)。
-
硬件优化:
- 根据事务规模和数据库负载情况,提升服务器的硬件配置,例如增加内存、提高磁盘I/O速度等。
-
备份与恢复策略:
- 大型事务期间,可能会影响全备和增量备份的执行效率,因此要制定相应的备份策略,确保在不影响业务的前提下完成备份工作。
-
测试与模拟:
- 在生产环境实施大型事务之前,在开发或测试环境中进行充分的模拟和压力测试,以识别并解决潜在的问题。
通过以上策略结合具体应用场景,可以有效地管理和优化MySQL中的大型事务处理过程。
四十三、MySQL优化器是什么,它是如何工作的?
MySQL优化器是MySQL数据库管理系统中的一个关键组件,其主要职责是在执行SQL查询之前,根据表的统计信息、索引结构以及其他内部因素,决定如何最有效地执行给定的SQL语句。优化器的目标是选择一个成本最低(或者说效率最高)的执行计划,这个计划描述了MySQL应如何遍历数据和执行操作来生成查询结果。
MySQL优化器的工作流程通常包括以下几个步骤:
-
解析SQL语句:
首先,优化器会分析SQL语法以确保它是合法的,并将其转换为可理解的内部表示形式。 -
收集统计信息:
优化器从系统表中获取关于表大小、索引分布以及列值的统计信息,这些信息对于评估不同执行策略的成本至关重要。 -
生成可能的执行计划:
根据SQL语句的内容和所涉及的表及索引,优化器会产生多个潜在的执行计划。每个计划都描述了一种不同的数据访问路径和处理方式,例如使用哪个索引、是否全表扫描、连接顺序和类型等。 -
成本估算:
对于每一个可能的执行计划,优化器都会计算一个“成本”值,这个成本通常是基于磁盘I/O、内存访问次数和其他资源消耗的估计值。通过成本估算模型,优化器可以比较不同执行计划的成本,并选择成本最低的那个。 -
选择最优执行计划:
优化器最终会选择成本估算最小的执行计划,并将该计划传递给存储引擎进行实际的数据读取和处理。
在实际运行过程中,MySQL优化器可能会遇到各种复杂的查询条件、多种类型的索引以及JOIN操作,它需要综合考虑所有因素,才能制定出最高效的执行计划。然而,有时候优化器并不一定能选择出最佳方案,这时就需要DBA或者开发人员通过调整查询语句、优化索引设计、提供提示等方式来帮助优化器更好地做出决策。
四十四、什么是MySQL中的全文索引,它是如何工作的?
MySQL中的全文索引(Full-Text Index)是一种特殊的索引类型,设计用于对文本数据进行全文搜索,特别适合于在大量文本数据中快速查找包含特定词汇或短语的记录。全文索引不是基于精确值匹配,而是通过识别和索引文档中的单词或词组来实现快速的模糊查询和基于相似度的搜索。
全文索引的工作原理主要包括以下步骤:
-
分词(Tokenization):
全文索引首先会对存储在指定列(通常是CHAR、VARCHAR或TEXT类型的列)中的文本进行分词处理,将文本拆分成单个词语或短语(根据语言的不同,分词规则也不同)。MySQL支持不同的分词器,并且可以自定义分词字典和停用词列表。 -
创建倒排索引(Inverted Index):
在分词的基础上,全文索引会建立一个倒排索引结构。倒排索引是一种以关键词为索引项,记录了每个关键词出现在哪些文档以及它们在文档中的位置信息的数据结构。这样,当用户搜索某个关键词时,数据库可以直接从倒排索引中找到包含该关键词的所有文档记录,而无需逐行扫描整个表。 -
搜索与排名:
当执行全文查询时,MySQL会使用全文检索语法(如MATCH AGAINST)来查找含有特定词汇的记录。同时,MySQL还可以计算每个结果的相关性得分(relevance score),这个得分通常基于关键词出现的频率、位置和其他因素来确定,从而可以根据相关性对搜索结果进行排序。 -
MySQL版本与引擎支持:
- MySQL 5.6及以后的版本中,InnoDB存储引擎也开始支持全文索引。
- 在早期版本中,只有MyISAM存储引擎支持全文索引。
- 对于中文、日文和韩文等多字节字符集,在某些MySQL版本中需要特殊配置才能正确支持全文索引。
总的来说,全文索引极大地提高了在大文本字段中进行关键字搜索的速度和效率,尤其适用于内容管理系统、博客平台、文档存储库等需要频繁进行全文内容搜索的应用场景。
四十五、什么是MySQL中的全文索引,它是如何工作的?
MySQL的ACID属性是关系型数据库管理系统(如MySQL)保证事务处理正确性的四个基本要素,它们分别是:
-
原子性(Atomicity)
一个事务中的所有操作被看作是一个不可分割的工作单元。这意味着要么整个事务全部成功执行,要么全部不执行。如果在事务执行过程中出现任何错误或中断,系统会通过回滚机制确保事务中已执行的操作不会对数据库造成影响,即事务会被完全撤销到开始前的状态。 -
一致性(Consistency)
在事务开始和结束时,数据库必须处于一致状态。一致性确保了任何事务都将数据库从一个有效状态转换为另一个有效状态,遵循数据库的所有完整性约束。例如,在转账操作中,无论事务是否成功,最终账户余额之和必须保持不变。 -
隔离性(Isolation)
多个并发事务之间互不影响,好像每个事务都在独立地、连续地执行。MySQL通过不同的隔离级别来实现不同程度的隔离效果,避免脏读(Read Dirty)、不可重复读(Non-repeatable Read)、幻读(Phantom Read)等问题的发生。 -
持久性(Durability)
当事务提交后,对数据库所做的更改是永久性的,即使在系统崩溃或其他故障发生后也能持久存在。MySQL通过将事务日志写入磁盘并在必要时恢复未完成的事务来保证数据的持久性。
总之,MySQL通过支持ACID属性来确保事务的安全性和可靠性,这对于构建高可用、强一致性的企业级应用至关重要。
四十六、MySQL如何处理子查询优化?
MySQL在处理子查询时,通过优化器分析和选择最佳执行计划以提高性能。以下是MySQL对子查询进行优化的一些策略:
-
转换为JOIN操作:
MySQL的优化器有时候会选择将某些类型的子查询转换为等价的JOIN操作,因为JOIN通常能更有效地利用索引,尤其是在连接条件中使用了索引列的情况下。 -
物化子查询结果:
对于一些特定情况下的子查询,特别是出现在IN或EXISTS子句中的子查询,MySQL可能会选择提前计算子查询的结果并将其存储在一个临时表中(称为物化子查询)。这样,在主查询执行时可以直接从临时表中查找数据,从而避免反复执行子查询。 -
半连接转换:
MySQL可以将某些类型的子查询转换为半连接操作,例如将NOT EXISTS子查询转换为LEFT JOIN然后应用WHERE条件来过滤出不匹配的数据行。 -
合并查询:
如果多个查询能够被合并成一个查询执行,MySQL可能尝试合并这些查询以减少数据库交互次数。 -
使用索引:
为了加速子查询的执行,确保相关联的列上有合适的索引至关重要。这包括在子查询本身涉及的列上创建索引,以及在外层查询中用于关联的列上创建索引。 -
简化子查询:
减少子查询返回的数据量,比如使用LIMIT限制结果集大小,或者改进子查询逻辑使其更快地返回结果。 -
优化器提示与强制执行计划:
在某些情况下,可以通过SQL Hint来指导优化器如何处理子查询,或者直接强制执行某个已知高效的执行计划。 -
检查统计信息:
确保表的统计信息是最新的,以便优化器准确估计查询成本并选择最优的执行路径。
为了优化子查询,DBA和开发者应该:
- 定期分析和审查慢查询日志。
- 使用
EXPLAIN分析查询计划,了解MySQL是如何处理子查询的。 - 根据实际情况调整查询结构、添加适当的索引,并合理设置MySQL服务器参数。
- 监控系统资源和性能指标,根据需要调整数据库配置或优化查询语句。
四十七、在MySQL中,如何确保数据备份的完整性和一致性?
在MySQL中确保数据备份的完整性和一致性,可以采用以下策略和方法:
-
使用逻辑备份工具:
- 使用
mysqldump命令进行全量或增量备份。这是一个非常常用且功能强大的工具,它能够生成包含数据库结构和数据的SQL脚本文件。在执行备份时,可以通过添加--single-transaction选项来保证事务的一致性,这样在备份过程中其他会话对数据库的更改将不会影响备份结果。
- 使用
-
利用二进制日志(binlog):
- 开启MySQL的二进制日志功能,配合逻辑备份可实现基于时间点的数据恢复。通过应用备份后产生的所有二进制日志事件,可以同步备份完成后发生的变更,以确保数据的一致性。
-
物理备份:
- 使用诸如Percona Xtrabackup等工具进行物理备份,这些工具可以直接复制InnoDB存储引擎的数据文件并记录相关的日志信息,从而支持在线热备份,并确保备份时数据库处于一致状态。
-
锁定数据库:
- 对于非常重要的、不能容忍任何数据不一致性的场景,可以在备份前对整个数据库或特定表进行锁定(例如,设置全局读锁
FLUSH TABLES WITH READ LOCK;),阻止写入操作,然后执行备份。完成备份后再释放锁,但这种方式会导致在备份期间数据库无法进行写操作,影响业务连续性。
- 对于非常重要的、不能容忍任何数据不一致性的场景,可以在备份前对整个数据库或特定表进行锁定(例如,设置全局读锁
-
定期备份与维护:
- 制定合理的备份计划,包括全备和增量备份,以减少备份窗口的同时保持数据的可恢复性。
- 定期检查备份文件的完整性,并进行恢复演练以验证备份的有效性。
-
配置主从复制:
- 在主从复制架构中,可以从只读从库上进行备份,从而避免对主库性能的影响,同时也能保证备份时刻的数据一致性。
-
GTID(Global Transaction Identifier):
- 如果使用了GTID复制,可以更精确地追踪和应用备份之后的事务,进一步提高数据恢复时的一致性。
总之,在MySQL中确保数据备份的完整性和一致性需要结合多种技术手段和管理措施,根据实际业务需求制定合适的备份策略,并定期验证备份的有效性。
四十八、如何在MySQL中设置和使用存储过程的参数?
在MySQL中设置和使用存储过程的参数涉及创建带有参数的存储过程以及在调用该存储过程时传递相应的值。以下是关于如何定义、使用及调用存储过程参数的详细步骤:
定义存储过程并声明参数
DELIMITER //
CREATE PROCEDURE procedure_name (IN param1_type param1_name, OUT param2_type param2_name, INOUT param3_type param3_name)
BEGIN-- 存储过程主体,可以包含SQL语句和其他逻辑-- 使用已声明的参数,例如:SET param2 = '初始值'; -- 对于OUT或INOUT参数,可以在过程中赋值SET param3 = param3 + 1; -- 对于INOUT参数,可以修改其值-- 示例操作:假设我们有一个更新操作,其中param1用于WHERE条件,param2接收结果UPDATE some_tableSET some_column = 'value'WHERE id = param1;SELECT another_column INTO param2 FROM other_table WHERE condition;END //
DELIMITER ;
IN参数是输入参数,仅允许调用者向存储过程传递值。OUT参数是输出参数,调用时不需要提供值,但在存储过程执行后会将结果返回给调用者。INOUT参数既可以作为输入也可以作为输出,调用时需要提供初始值,存储过程可以修改这个值,并在结束时将新值返回。
调用存储过程并传入参数
-- 假设存储过程已经创建好
-- 定义变量来接收OUT或INOUT参数的结果
DECLARE @result_var VARCHAR(50);CALL procedure_name('input_value', @result_var, @another_var);-- 调用结束后,@result_var 和 @another_var 将含有从存储过程传出的新值
SELECT @result_var, @another_var;
注意,在实际调用时,对于IN参数,可以直接提供常量或变量的值;对于OUT和INOUT参数,则需要先声明一个变量(以@符号开头的用户变量),然后在CALL语句中使用这个变量名代替。
请确保在MySQL服务器上启用了存储过程功能,并且根据实际情况调整数据类型和过程体内容。
四十九、如何在MySQL中设置和使用存储过程的参数?
在MySQL中,触发器(Trigger)根据其执行的时间点可以分为两种类型:
-
BEFORE触发器:
- BEFORE触发器会在指定的数据库操作(INSERT、UPDATE或DELETE)实际发生之前执行。
- 在此类型的触发器中,可以查看并修改即将被插入、更新或删除的数据。例如,在向表中插入新记录前验证数据的有效性,或者在更新记录前自动填充某些字段。
CREATE TRIGGER before_trigger_name BEFORE INSERT ON table_name FOR EACH ROW BEGIN-- 在这里编写要在INSERT之前执行的SQL语句-- 使用 "NEW.column_name" 来引用将要插入的新行的值 END; -
AFTER触发器:
- AFTER触发器则在相应的数据库操作完成后执行。
- 对于INSERT和UPDATE操作,可以在操作完成之后访问已更改的数据;对于DELETE操作,则可以在记录从表中实际删除后进行后续处理。
- 通常用于记录审计信息、执行清理任务或维护其他与主表相关联的数据一致性。
CREATE TRIGGER after_trigger_name AFTER UPDATE ON table_name FOR EACH ROW BEGIN-- 在这里编写要在UPDATE之后执行的SQL语句-- 使用 "NEW.column_name" 来引用更新后的最新值,"OLD.column_name" 来引用更新前的旧值 END;
注意:FOR EACH ROW子句表示该触发器将在受影响的每一行上分别执行,这对于处理多行操作时非常有用。此外,触发器是基于特定表定义的,并且不能直接调用,它们会由数据库系统自动触发执行。
五十、 在MySQL中如何管理并调整缓冲池的大小?
在MySQL中,InnoDB存储引擎使用缓冲池(Buffer Pool)来缓存表数据和索引,以提高查询性能。调整InnoDB缓冲池的大小是一个常见的优化操作,可以按照以下步骤进行:
-
查看当前缓冲池大小:
使用如下SQL语句查看当前的InnoDB缓冲池大小:SHOW VARIABLES LIKE 'innodb_buffer_pool_size'; -
调整缓冲池大小:
调整缓冲池大小通常需要修改MySQL服务器的配置文件(如my.cnf或my.ini),具体位置取决于你的操作系统和MySQL安装方式。在配置文件中的
[mysqld]部分添加或修改以下行(假设你打算将缓冲池大小设置为8GB):[mysqld] innodb_buffer_pool_size = 8G注意:确保指定的大小不要超过系统物理内存的大部分,因为MySQL还需要为其他进程、操作系统以及其他数据库组件留出足够的内存空间。
-
重启MySQL服务:
修改配置文件后,需要重启MySQL服务才能使新的缓冲池大小生效。重启命令取决于你的操作系统,例如在Linux上可能需要执行:sudo systemctl restart mysql或者直接运行MySQL的服务管理脚本:
sudo service mysql restart -
验证新设置是否生效:
重启MySQL服务后,再次运行SHOW VARIABLES LIKE 'innodb_buffer_pool_size';来确认新的缓冲池大小已成功应用。
从MySQL 5.7.5开始,InnoDB支持在线更改缓冲池大小(对于某些情况下的扩大操作),但缩小缓冲池大小通常仍然需要重启MySQL服务。请查阅官方文档以了解最新版本中关于在线更改缓冲池大小的支持和限制。
五十一、 MySQL如何处理大量的并发连接?
MySQL处理大量并发连接主要依赖于以下策略和技术:
-
配置参数调整:
max_connections:MySQL服务器允许的最大并发连接数,默认值较小,可根据服务器硬件资源进行适当增加。thread_cache_size:线程缓存大小,用于缓存空闲的线程以供后续请求重用,减少创建新线程的开销。
-
连接池(Connection Pooling):
应用程序层可以使用数据库连接池技术来管理并发连接。通过复用已建立的连接,避免频繁地建立和销毁连接,从而降低系统开销并提高性能。 -
查询优化:
优化SQL查询语句,减少长事务和锁定时间,确保快速响应并发请求。例如,使用索引、减少全表扫描、合理设计查询结构等。 -
内存管理与硬件提升:
提高服务器的内存容量,增大InnoDB缓冲池大小,以加快数据读取速度,并减少磁盘I/O。同时,升级CPU和网络设备以应对更高的并发请求压力。 -
负载均衡:
在分布式架构中,可以采用负载均衡器将并发请求分发到多个MySQL服务器上,减轻单个服务器的压力。 -
分区与分库分表:
对大型表进行水平或垂直分区,或者根据业务逻辑将数据分布到多个数据库或表中,这样不仅可以分散访问压力,还能减少锁竞争,提高并发性能。 -
并发控制与死锁检测:
适当设置事务隔离级别,有效利用行级锁定以及MySQL内置的死锁检测机制,及时处理可能发生的死锁情况。 -
监控与调优:
使用诸如SHOW PROCESSLIST命令实时查看当前活动的连接和其执行状态,定期检查慢查询日志,分析并优化导致资源瓶颈的SQL语句。 -
操作系统层面优化:
调整操作系统的TCP/IP参数,如最大文件描述符数量(ulimit)、内核参数(如somaxconn)等,以适应更高并发需求。
通过以上综合手段,MySQL可以更好地处理大量并发连接,并在实际生产环境中保持高效稳定的服务能力。
五十二、 如何在MySQL中优化COUNT()查询?
在MySQL中优化COUNT()查询,可以考虑以下策略:
-
避免对全表进行COUNT(*):
如果只需要统计表中的行数,并且不关心具体数据,尽量使用主键索引或唯一索引的COUNT()查询,因为InnoDB存储引擎会为每个表维护一个行计数器。SELECT COUNT(*) FROM table WHERE PRIMARY_KEY IS NOT NULL; -
利用覆盖索引(Covering Index):
如果查询中包含了WHERE子句和JOIN操作,确保有适当的索引包含所有需要筛选和计数的字段。这样MySQL可以从索引中直接获取结果而无需访问实际的数据行,这称为“覆盖索引”。CREATE INDEX idx_cover ON table (column1, column2); SELECT COUNT(*) FROM table WHERE column1 = 'value' AND column2 = 'value'; -
减少JOIN操作:
当COUNT()查询涉及到多个表时,尽可能减少不必要的JOIN操作,或者通过预计算JOIN结果并存储在一个汇总表中来提高效率。 -
分页查询中的COUNT()优化:
在处理带有LIMIT和OFFSET的分页查询时,同时获取总数和分页数据可能会导致性能问题。一种解决方案是分别执行两个查询:一个用于获取总数,另一个用于获取当前页数据。 -
缓存计数:
对于经常请求且变化不频繁的计数,可以考虑在应用程序层缓存计数值,定期更新缓存而不是每次请求都去数据库查询。 -
合理设置innodb_buffer_pool_size:
确保缓冲池足够大,能容纳大部分经常访问的表的索引,以便快速完成COUNT()查询。 -
MySQL 8.0的新特性:
MySQL 8.0引入了名为INFORMATION_SCHEMA.TABLE_STATISTICS的新视图,它提供了关于表中行数的近似值,可用于不需要精确计数的场景,以提高性能。 -
分区表:
如果表非常大并且支持分区,可以根据业务需求将表分为多个分区。对于只针对某个分区的COUNT()查询,其速度通常比在整个大表上执行要快得多。 -
避免无谓的排序与临时表创建:
如果COUNT()查询与ORDER BY、GROUP BY一起使用,并导致排序或临时表创建,尝试重新组织查询以避免这种情况发生。 -
使用SQL_CALC_FOUND_ROWS替代COUNT查询:
虽然不是最优方案,但在某些特定场景下,当需要同时获取分页数据及总记录数时,可以考虑使用SELECT SQL_CALC_FOUND_ROWS ... LIMIT ...,但需要注意此方法也有其局限性和额外开销,应根据实际情况权衡使用。
五十三、解释MySQL中的聚集索引和非聚集索引的区别。
MySQL中的聚集索引(Clustered Index)和非聚集索引(Non-Clustered Index)在结构和数据存储方式上有显著区别:
聚集索引(Clustered Index):
- 定义:
聚集索引决定了表中行的物理存储顺序。每个表最多只能有一个聚集索引。 - 结构:
表的数据行是按照索引键值的逻辑顺序进行物理排序存储的,也就是说,数据行本身就在索引的叶子节点上,直接包含了行的所有列信息。 - 特点:
- 查询性能高,尤其对于范围查询或连续键值的检索操作。
- 主键通常默认作为聚集索引,如果没有显式指定,则InnoDB会创建一个隐藏的主键作为聚集索引。
- 插入、删除和更新操作可能会对性能产生影响,因为为了维持索引的有序性,可能需要重新排列物理记录。
非聚集索引(Non-Clustered Index):
- 定义:
非聚集索引独立于数据行的物理存储顺序,它具有独立的索引结构。 - 结构:
非聚集索引包含了指向实际数据行的指针(在InnoDB引擎中称为“ROWID”),而非直接存储数据行的内容。 - 特点:
- 可以有多个非聚集索引,用于不同的查询需求。
- 对于非聚集索引的查找,数据库系统首先找到索引项,然后通过索引项中存储的指针定位到对应的行数据。
- 对于覆盖索引(Covering Index),如果索引包含了查询所需的所有列,那么可以直接从索引中获取数据而无需回表,从而提高查询性能。
总结来说,聚集索引和非聚集索引的主要区别在于它们与表中行数据的关系以及查询时是否需要额外步骤来定位数据行。聚集索引确保了数据按特定字段排序存储,而非聚集索引则提供了指向数据行的间接访问路径。
五十四、在MySQL中,什么是预处理语句,它有什么优点?
在MySQL中,预处理语句(Prepared Statements)是一种SQL语句的处理机制,它允许应用程序先发送SQL语句模板到数据库服务器进行编译和优化,然后多次执行该语句,但每次执行时可以使用不同的参数。预处理语句通常包含占位符(例如 “?”),这些占位符将在后续步骤中被实际的数据值替换。
预处理语句的优点主要包括:
-
性能提升:
- 通过将SQL语句结构一次性解析和编译,避免了对同一查询结构反复解析、编译和优化带来的开销,特别适用于需要重复执行大量相同结构但参数不同的SQL语句的情况。
- 对于复杂查询尤其有利,因为数据库只需要对查询计划进行一次计算,之后可以复用。
-
减少网络传输量:
- 当多次执行时,只需传输参数数据而无需整个SQL字符串,减少了网络传输的数据量。
-
防止SQL注入:
- 预处理语句中的参数是独立绑定并自动转义的,因此,如果正确地使用参数化查询,可以有效地防止SQL注入攻击,确保应用安全。
-
增强代码可读性与维护性:
- 参数化的预处理语句可以使SQL逻辑更清晰,有助于提高代码质量。
在实际编程中,预处理语句可以通过各种数据库接口(如PDO或mysqli扩展)在PHP、Java、C#等语言中使用MySQL实现。例如,在PHP中,可以使用PDO::prepare()方法创建预处理语句,并通过PDOStatement::bindParam()或PDOStatement::execute()传入具体参数来执行。
五十五、MySQL中的FOREIGN KEY约束是什么?
在MySQL以及其他支持关系型数据库管理系统(RDBMS)中,FOREIGN KEY(外键)约束是一种用于确保两个表之间数据引用完整性的机制。它定义了一个表中的列或列集合与另一个表的主键(PRIMARY KEY)之间的关联关系。
具体来说,FOREIGN KEY约束有以下特点和作用:
-
参照完整性:
- 确保在一个表(子表或从表)中的记录引用了另一个表(父表或主表)中存在的记录。
- 当尝试在子表中插入、更新或删除一条记录时,数据库会检查该操作是否违反了与父表之间的外键关联规则。
-
防止非法数据插入:
- 外键列上的值必须是其关联的主键列中已存在的有效值,不能插入一个在主键表中找不到对应项的值。
-
级联操作:
- 可以设置ON DELETE和ON UPDATE规则,当主表中的相关记录发生变化时,自动触发对从表中相关记录的相应操作,例如级联删除(CASCADE)、级联更新(CASCADE)、设置为NULL或RESTRICT(阻止主表中的更改如果将导致从表中违反外键约束)等。
-
数据一致性:
- 通过外键约束可以维护数据库中多个表间数据的一致性和依赖性,使得整个数据模型更加可靠和准确。
在SQL语法上,创建带有FOREIGN KEY约束的表结构通常如下所示:
CREATE TABLE Orders (O_Id int PRIMARY KEY,OrderNo int NOT NULL,P_Id int,FOREIGN KEY (P_Id) REFERENCES Persons(P_Id)ON DELETE CASCADEON UPDATE CASCADE
);
在这个例子中,Orders表中的P_Id列是一个外键,它引用了Persons表的P_Id主键列。这意味着在Orders表中每条记录的P_Id都必须是Persons表中存在的P_Id值,并且根据所设定的级联规则,在Persons表中对应的记录被删除或更新时,Orders表中的相关记录也会自动执行相应的删除或更新操作。
五十六、如何在MySQL中进行性能剖析?
在MySQL中进行性能剖析是一个系统性的过程,涉及到多个步骤和工具的使用。以下是一些关键的步骤和方法来分析和优化MySQL数据库的性能:
-
监控与收集数据:
- 使用
SHOW STATUS或INFORMATION_SCHEMA表获取服务器运行时的状态信息。 - 监控系统资源,如CPU、内存、磁盘I/O以及网络流量。
- 启用并检查MySQL错误日志(
error.log)和慢查询日志(slow_query.log),以识别出执行缓慢或有问题的查询。
- 使用
-
分析查询性能:
- 使用
EXPLAIN或EXPLAIN ANALYZE命令分析单个SELECT语句,了解查询如何执行,包括索引使用情况、表扫描方式等。 - 对于慢查询,查看其执行计划,并尝试通过添加或修改索引来优化查询。
- 使用
-
配置调整:
- 调整MySQL服务器参数,如
innodb_buffer_pool_size(InnoDB缓冲池大小)、query_cache_size(查询缓存大小,已弃用于MySQL 8.0)以及其他与并发处理、连接管理相关的参数。 - 根据业务需求和硬件资源合理设置事务隔离级别、锁定机制等。
- 调整MySQL服务器参数,如
-
统计信息收集与更新:
- 确保MySQL自动更新表的统计信息,或者定期手动执行
ANALYZE TABLE,以便优化器能基于准确的数据分布做出决策。
- 确保MySQL自动更新表的统计信息,或者定期手动执行
-
索引优化:
- 分析查询模式并为高频查询创建适当的索引。
- 避免冗余和不必要的索引,对大表适当考虑分区策略。
-
架构审查:
- 检查应用程序架构,确保SQL语句编写得当,避免全表扫描、N+1查询等问题。
- 考虑是否需要引入读写分离、分库分表等分布式解决方案。
-
性能基准测试:
- 使用专门的基准测试工具(例如mysqlslap、sysbench等)模拟真实场景的压力测试,量化性能改进效果。
-
实时分析工具:
- 使用诸如Percona Toolkit、pt-query-digest等第三方工具分析慢查询日志,找出热点问题。
- 利用MySQL Performance Schema或Oracle MySQL Enterprise Monitor等内置或商业性能监控工具获取更详细的内部操作信息。
-
长期性能监控:
- 设置性能监视系统,持续跟踪关键性能指标,以便及时发现并解决问题。
通过以上步骤可以深入到MySQL数据库的各个层面进行性能剖析,并采取针对性的调优措施。性能调优是一个迭代的过程,可能需要多次循环上述步骤才能达到理想的性能水平。
五十七、什么是MySQL的查询缓存,它是如何工作的?
MySQL的查询缓存是一种数据库性能优化机制,它能够在内存中存储SELECT语句的结果集。当一个查询被执行时,MySQL服务器首先检查查询缓存看是否之前执行过完全相同的SQL查询且结果仍然有效。如果存在匹配的查询和其结果,则直接从缓存中返回结果,而无需再次解析、优化或执行SQL查询以及访问实际的数据表。
查询缓存的工作流程如下:
-
缓存键生成:
- MySQL对每个查询进行哈希运算,生成一个唯一的哈希键。
- 哈希键不仅基于查询的文本内容,还考虑了诸如数据库名、当前会话的SQL模式等因素以确保准确匹配。
-
缓存命中判断:
- 服务器在接收到查询请求后,首先查找该查询对应的哈希键是否存在于查询缓存中。
- 如果找到匹配的哈希键,则进一步验证相关的查询条件(例如用户权限)是否一致,以及数据是否有更新导致缓存失效。
-
缓存结果获取:
- 若缓存命中,MySQL直接从缓存中提取结果,并将其返回给客户端,避免了对数据库的I/O操作和计算资源消耗。
-
缓存结果存储:
- 对于未命中的查询,MySQL将执行查询并获取结果,然后将结果集连同查询本身放入查询缓存中,供后续相同查询使用。
-
缓存失效策略:
- 当对表进行任何写操作(如INSERT、UPDATE、DELETE等)时,MySQL会清除所有依赖于该表的查询缓存结果,这是因为写操作可能改变已缓存查询结果的准确性。
- 查询结果中包含不确定函数(如NOW()、RAND()等)的查询不会被缓存。
-
配置与管理:
- 查询缓存的大小可以通过
query_cache_size系统变量来设置,超过此大小则需要对缓存进行LRU(最近最少使用)替换。 - 开启或关闭查询缓存功能,可以修改全局系统变量
query_cache_type。
- 查询缓存的大小可以通过
需要注意的是,MySQL 8.0版本已经废弃了查询缓存功能,官方推荐通过其他手段优化查询性能,如使用更高效的索引、改进查询语句设计、调整InnoDB缓冲池大小等。在MySQL较早版本中,虽然查询缓存能带来潜在的性能提升,但它并不是总是适用的,尤其在高并发读写场景下可能会导致额外的开销和一致性问题。
五十八、解释MySQL的表分区以及它的优势。
MySQL的表分区是一种将大表物理分割为多个更小、更易管理的部分的技术,这些部分在逻辑上仍然表现为一个完整的表。根据预定义的规则,数据被划分到不同的“分区”中,每个分区实际上是一个独立的存储区域,并且可以有自己的索引和其他属性。
MySQL支持多种类型的表分区,包括但不限于以下几种:
- RANGE分区:基于列值的范围进行分区,例如按照时间(年份或月份)区间划分日志表。
- LIST分区:类似于RANGE分区,但使用的是列值匹配的一个离散列表。
- HASH分区:通过哈希函数对指定列的值计算结果来决定数据行所在的分区。
- KEY分区:与HASH分区类似,不过只针对整数列,并且MySQL内部会自动处理哈希计算。
MySQL表分区的优势主要包括:
- 提高查询性能:对于包含分区条件的查询,数据库仅需扫描相关的分区而不是整个大表,从而加快检索速度。
- 数据维护便捷:可以通过删除整个分区快速移除大量数据,也方便添加新分区以容纳新增的数据,而且可以独立优化、检查和修复单个分区。
- 可用性和容错性提升:若某个分区发生故障,其他分区的数据仍可正常访问,提高了系统的整体可用性。
- I/O负载均衡:可以根据需要将不同分区映射到不同的物理设备上,分散I/O压力,优化系统资源利用。
- 大表管理:允许单个表存储超过单个文件大小限制的数据,更适合大数据量的场景。
因此,表分区特别适用于那些包含大量历史数据、需要频繁插入和删除操作以及存在特定查询模式的大规模数据库表。
相关文章:

MySQL面试题之基础夯实
一、mysql当中的基本数据类型有哪些 MySQL中的基本数据类型包括但不限于以下几大类: 数值类型: 整数类型:TINYINT、SMALLINT、MEDIUMINT、INT(INTEGER)、BIGINT浮点数类型:FLOAT、DOUBLE、DECIMAL…...

feign请求添加拦截器
FeignClient 的 configuration 属性: Feign 注解 FeignClient 的 configuration 属性,可以对 feign 的请求进行配置。 包括配置Feign的Encoder、Decoder、 Interceptor 等。 feign 请求添加拦截器,也可以通过这个 configuration 属性 来指…...

蓝桥杯之简单数论冲刺
文章目录 取模快速幂 取模 这道题目有两个注意点: 1.当你的取模之后刚好等于0的话,后面就不用进行后面的计算 2.if sum detail[i] > q: 这个语句的等号也很重要 import os import sys# 请在此输入您的代码a,b,n map(int,input().split())week a*5 …...

Http的缓存有哪些
HTTP 缓存可以通过多种 HTTP 头部字段来控制,主要包括以下几种: 1.Expires:这个字段定义了响应的过期时间。如果当前时间小于 Expires 的时间,那么就可以直接使用缓存。 2.Cache-Control:这个字段是一个指令ÿ…...
 认知)
Linux 网络虚拟化 Macvlan(基于物理网络接口虚拟网络接口) 认知
写在前面 博文内容涉及 Macvlan 的简单认知,以及一个Demo博文内容根据《 Kubernetes 网络权威指南:基础、原理与实践》 整理理解不足小伙伴帮忙指正 不必太纠结于当下,也不必太忧虑未来,当你经历过一些事情的时候,眼前…...
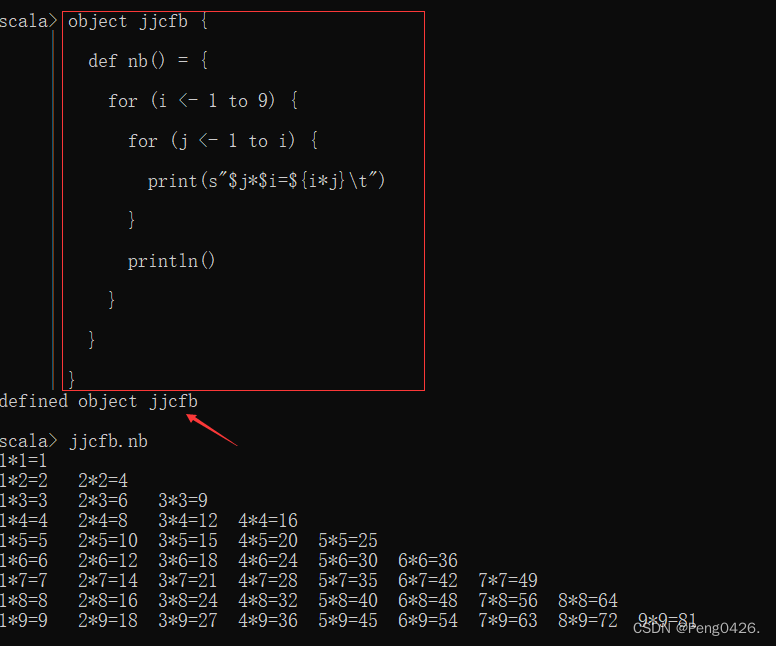
Spark-Scala语言实战(1)
在之前的文章中,我们学习了如何在Linux安装Spark以及Scala,想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。 Spark及Scala的安装https:/…...
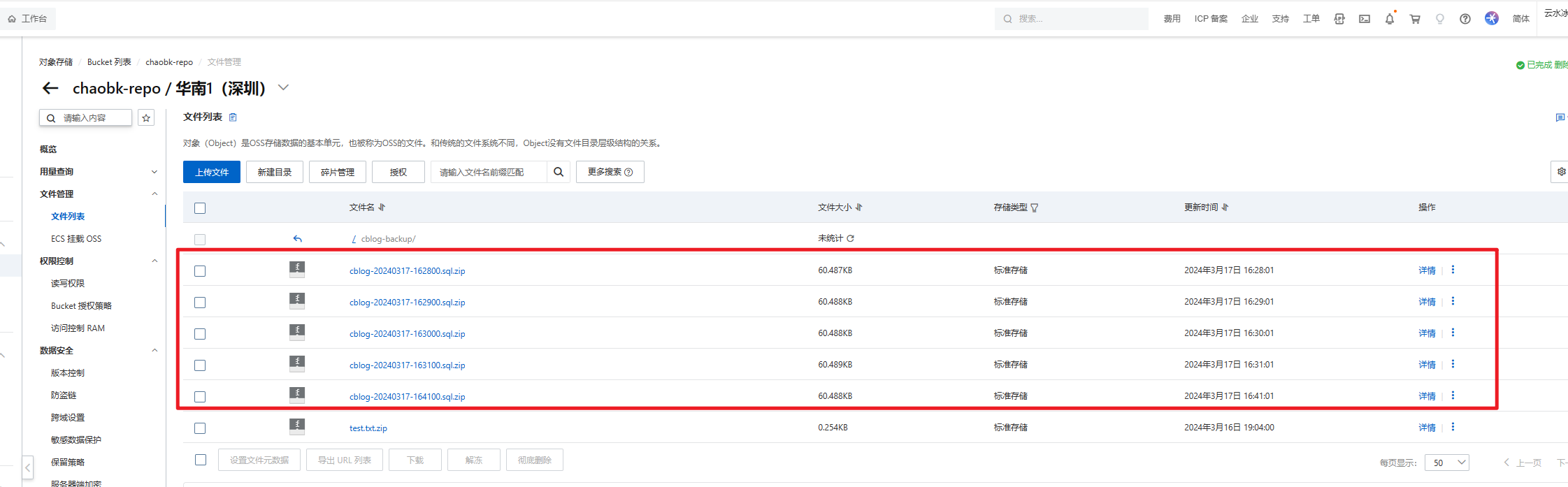
NBlog Java定时任务-备份MySQL数据
NBlog部署维护流程记录(持续更新):https://blog.csdn.net/qq_43349112/article/details/136129806 为了避免服务器被攻击,给博客添加了一个MySQL数据备份功能。 此功能是配合博客写的,有些方法直接用的已有的…...

微信小程序项目实战遇到的问题
我们以学生成绩平台来作为例子。这是我们想得到的效果。 以下是完整代码: index.js // index.js Page({//页面的初始数据data: {hello: 欢迎进入微信小程序的编程世界,score: 80,userArray: [{name: 张三,score: [66, 77, 86, 70, 90]},{name: 李四,score: [88, 7…...
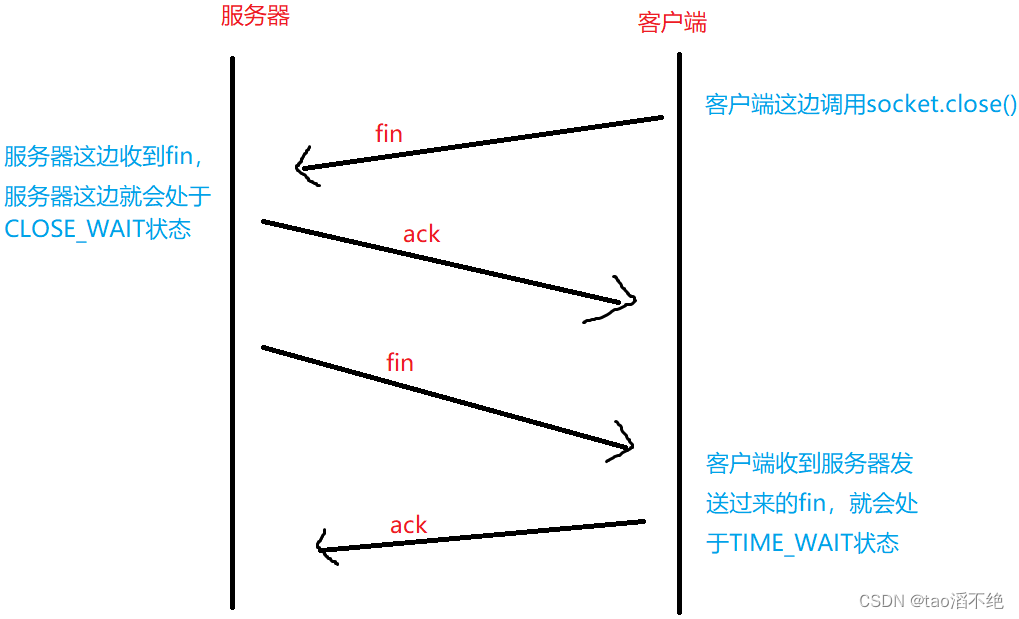
网络原理(3)——TCP协议
目录 一、连接管理 二、三次握手 1、何为三次握手? 2、三次握手有何意义? 三、四次挥手 三次握手和四次挥手的相似之处和不同之处 (1)相似之处 (2)不同之处 四、TCP的状态 建立连接: 断开…...

nginx多级代理配置获取客户端真实ip
流量路径 #mermaid-svg-NX785p8k6RVBngHY {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-NX785p8k6RVBngHY .error-icon{fill:#552222;}#mermaid-svg-NX785p8k6RVBngHY .error-text{fill:#552222;stroke:#552222;}#…...

Django框架的全面指南:从入门到高级【第128篇—Django框架】
👽发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【点击进入巨牛的人工智能学习网站】。 Django框架的全面指南:从入门到高级 Django是一个高效、功能强大的Python Web框…...
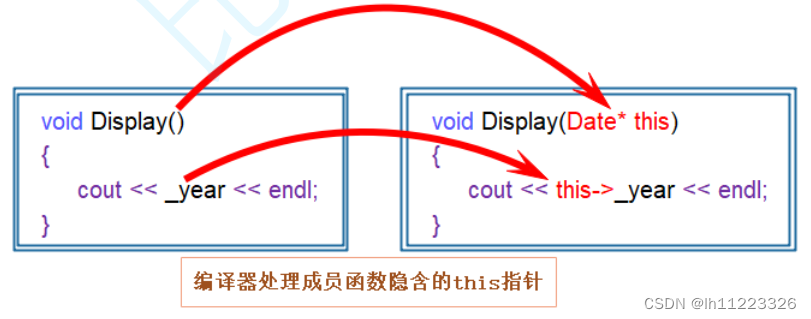
C++类和对象基础
目录 类的认识 访问限定符:public(公有),protected(保护),private(私有)。 类的两种定义方式: 类的实例化: 封装: 类的对象大小的计算: 类成员函数的this指针: C语言是面向过程的语言&am…...
消息队列常见的两种消费模式
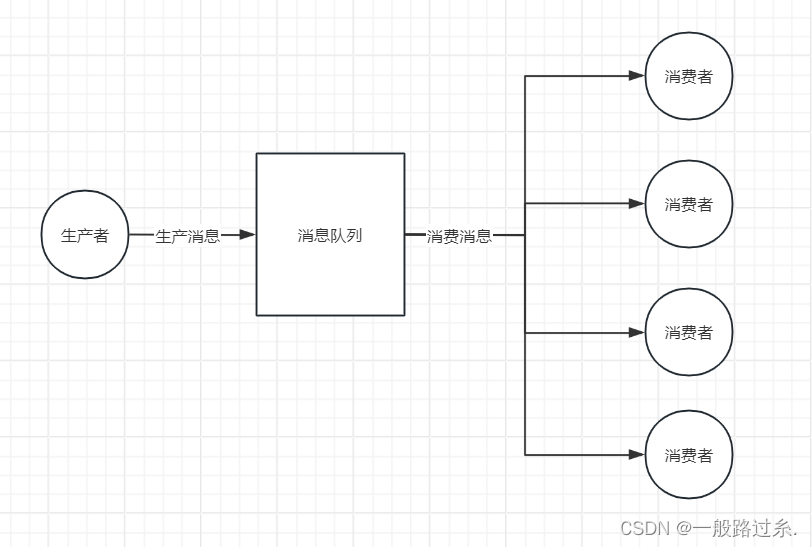
一、点对点模式 点对点模式:生产者发送消息到消息队列,消费者从消息队列中接收、处理消息,消息被消费后,就不在消息队列中了。每个消息只能由一个消费者接收和处理。如果有多个消费者监听同一个队列,消息将被发送到其…...

php的伪协议详解
在 PHP 中,伪协议(pseudo-protocols)是一种特殊的语法,用于访问各种资源,如文件、网络、输入/输出流等。伪协议实际上并不是真正的协议,而是一种简便的语法,用于访问不同的资源类型。 以下是一…...
【研发日记】Matlab/Simulink技能解锁(四)——在Simulink Debugger窗口调试
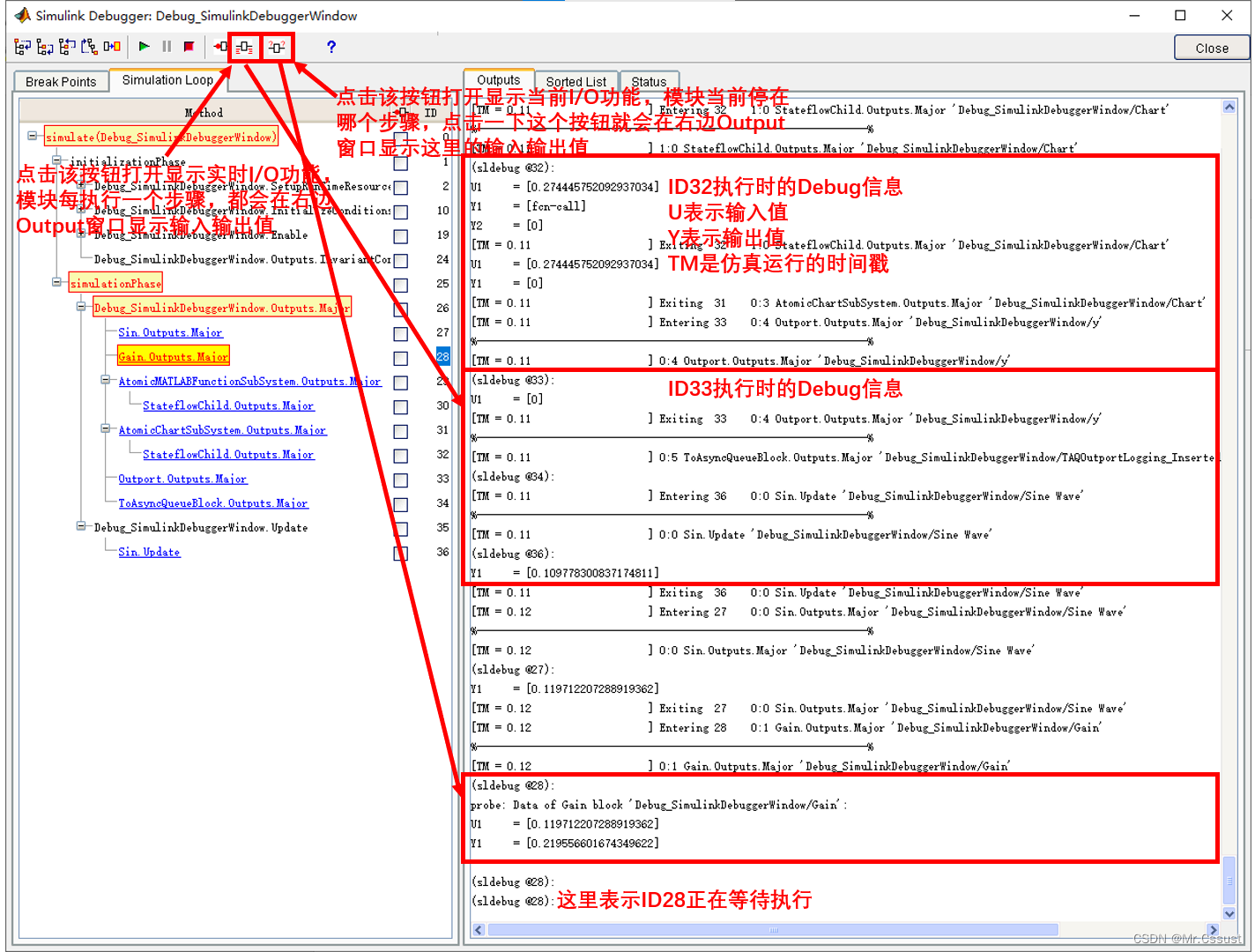
文章目录 前言 Block断点 分解Block步进 Watch Data Value 分析和应用 总结 前言 见《【研发日记】Matlab/Simulink技能解锁(一)——在Simulink编辑窗口Debug》 见《【研发日记】Matlab/Simulink技能解锁(二)——在Function编辑窗口Debug》 见《【研发日记】Matlab/Simul…...

沪深主板打板胜率统计
统计了20100101以来的数据,以中信日K为数据来源。 计算方法: 选出每只股票 (收盘价-开盘价)/开盘价 >0.098的日期,然后往后取3天数据,如果3天内有一天能涨超0.2元,则认为打板成功。 总共打板: 52239次 胜: 43784次…...
)
Python中的列表推导式(List Comprehension)
Python中的列表推导式(List Comprehension)是一种强大且简洁的语法结构,用于快速创建列表。它通过一行代码就能完成原本需要多行代码才能实现的循环迭代与列表添加操作。列表推导式在Python中非常常用,它使得代码更加简洁、易读和…...
MusicHiFi: Fast High-Fidelity Stereo Vocoding
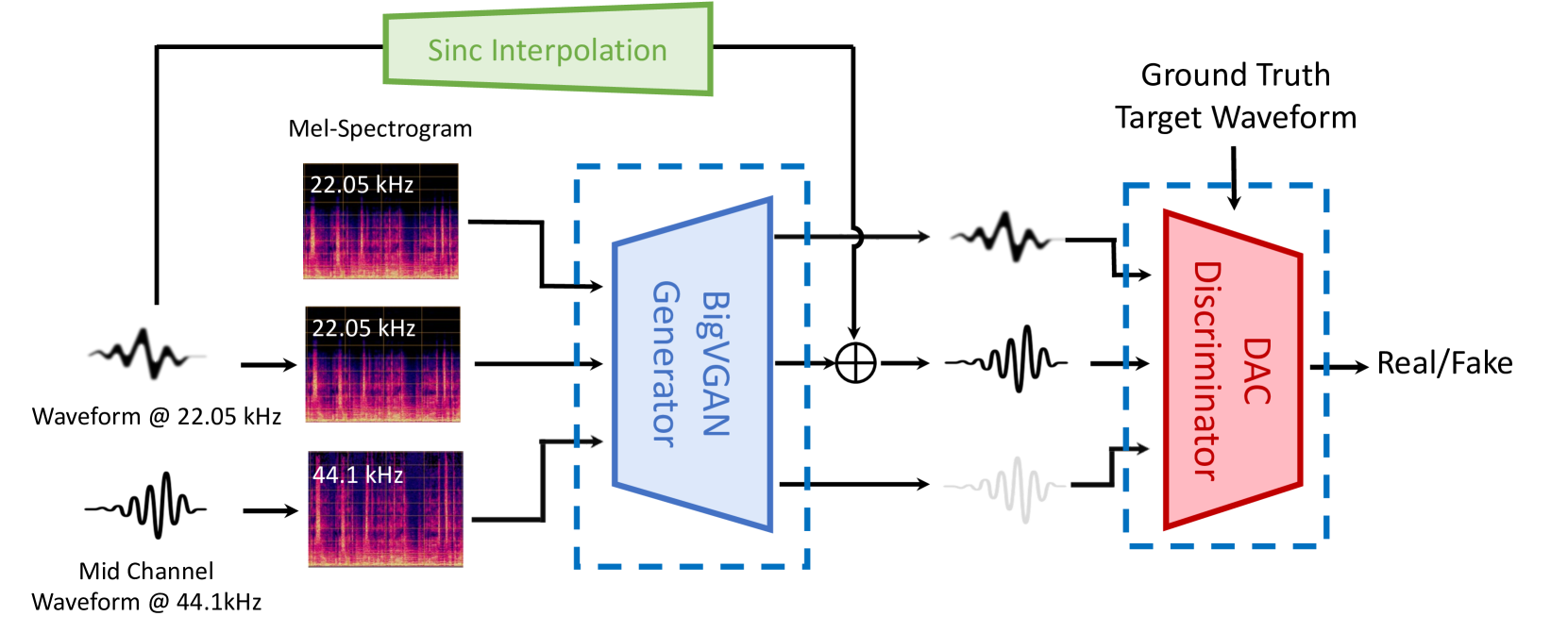
MusicHiFi: Fast High-Fidelity Stereo Vocoding 相关链接:arxiv github 关键字:音乐生成、高保真立体声、立体声编解码器、生成对抗网络、频带扩展 摘要 MusicHiFi是一种高效的高保真立体声编解码器,它通过将低分辨率的mel频谱图转换为音频…...
完美解决 RabbitMQ可视化界面Overview不显示折线图和队列不显示Messages
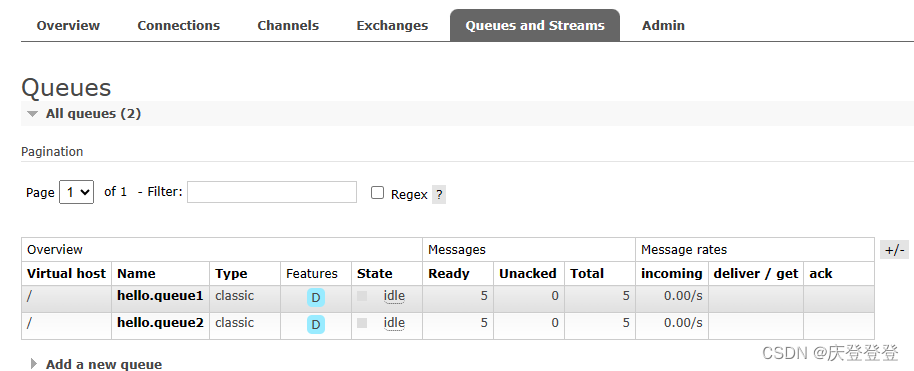
问题场景: 今天使用docker部署了一个RabbitMQ,浏览器打开15672可视化页面发送消息后不显示Overview中的折线图,还有队列中的Messages,因为我要看队列中的消息数量。 解决方案: 进入容器内部 docker exec -it 容器id…...
matlab 混沌系统李雅普洛夫指数谱相图分岔图和庞加莱界面
1、内容简介 略 65-可以交流、咨询、答疑 2、内容说明 matlab 混沌系统李雅普洛夫指数谱相图分岔图和庞加莱界面 混沌系统李雅普洛夫指数谱相图分岔图和庞加莱界面 李雅普洛夫指数谱、相图、分岔图、庞加莱界面 3、仿真分析 略 4、参考论文 略...

GO分层架构【2】使用GIN与GORM
现在大家都使用的的GIN和GORM开发架构是怎么样的?目前在 Go 社区中,基于 Gin 和 GORM 的主流微服务开发架构,最推崇的是 “工程化分层”。它在你的基础上,通过引入 Logic/Service 层 和 Repository 层,彻底解决代码臃肿…...
)
python+Vue实现摄像头视频流服务(支持启停控制)
python+Vue实现摄像头视频流服务(支持启停控制) 在开发视频监控、人脸识别或远程预览应用时,常常需要搭建一个可随时启动/停止的摄像头视频流服务,并同时支持Web浏览器实时预览。本文提供一套完整的解决方案: 后端使用 Flask + OpenCV + Waitress,提供 MJPEG 视频流。 支…...

ABAQUS盾构管片:单环多环精细化建模CAE源文件及录屏讲解教程 ‘一环六块,环宽1.5m...
ABAQUS盾构管片精细化建模cae源文件及录屏讲解教程 包含单环和多环两种 一环6块,环宽1.5m,管片厚度350mm 可以进行计算最近在搞盾构隧道数值模拟,发现管片建模真是个体力活。今天就拿ABAQUS实操经验来说说,怎么快速搞定精细化建模…...

Reference Extractor:如何高效提取Word文档中的Zotero和Mendeley引用?
Reference Extractor:如何高效提取Word文档中的Zotero和Mendeley引用? 【免费下载链接】ref-extractor Reference Extractor - Extract Zotero/Mendeley references from Microsoft Word files 项目地址: https://gitcode.com/gh_mirrors/re/ref-extra…...

Windows多显示器DPI独立控制:绕过系统限制的底层API实践
Windows多显示器DPI独立控制:绕过系统限制的底层API实践 【免费下载链接】SetDPI 项目地址: https://gitcode.com/gh_mirrors/se/SetDPI 在Windows多显示器工作环境中,不同分辨率的显示器需要独立的DPI缩放设置,但系统界面却将这一功…...

从SD卡制作到NFS挂载:手把手教你为ZYNQ7020 Petalinux系统配置完整网络调试环境
ZYNQ7020 Petalinux网络调试全流程实战:从SD卡制作到NFS挂载 当工程师完成Petalinux系统编译后,真正的挑战才刚刚开始——如何将系统部署到硬件并建立高效的网络调试环境?本文将带你跨越从理论到实践的鸿沟,通过七个关键步骤构建完…...

从ICC到Innovus:一个后端工程师的十年工具变迁史与实战避坑心得
从ICC到Innovus:一个后端工程师的十年工具变迁史与实战避坑心得 十年前,当我第一次接触ICC时,FinFET工艺还只是实验室里的概念。如今站在Innovus的界面前,回顾这段工具演进史,恍如隔世。这篇文章不是枯燥的技术对比&am…...
)
从面试官视角拆解:什么样的科研项目陈述能让导师眼前一亮?(附遥感/GIS/地信案例)
科研项目陈述的艺术:如何让导师在面试中记住你的研究价值 当二十多位面试者依次完成自我介绍后,导师们往往只对其中两三个人的项目陈述留有印象——这种现象在保研夏令营和考研复试中屡见不鲜。不同于简历上静态的文字描述,面对面的项目陈述是…...

VisionMaster通讯配置避坑指南:从TCP/IP到Modbus,手把手搞定设备连接与数据解析
VisionMaster工业通讯实战:从协议配置到故障排查的全链路指南 工业视觉系统的通讯链路如同神经网络,任何一处信号阻滞都可能导致整个生产线瘫痪。上周在汽车零部件检测项目中,我们遇到PLC与VisionMaster之间频繁断连的问题——产线每运行37分…...

避坑指南:赛元单片机触摸库配置,SOCAPI_SET_TOUCHKEY_CHANNEL和阈值到底怎么设?
赛元单片机触摸库实战:从参数解析到抗干扰配置全指南 第一次接触赛元单片机的电容触摸功能时,面对那一堆十六进制参数和模糊的文档说明,我盯着示波器上跳动的信号波形整整三天没睡好觉。电机干扰导致的误触发、阈值设置不当引发的响应迟钝、…...