【深度学习】BERT变体—SpanBERT
SpanBERT出自Facebook,就是在BERT的基础上,针对预测spans of text的任务,在预训练阶段做了特定的优化,它可以用于span-based pretraining。这里的Span翻译为“片段”,表示一片连续的单词。SpanBERT最常用于需要预测文本片段的任务。SpanBERT: Improving Pre-training by Representing and Predicting Spans
SpanBERT所做的预训练调整主要是以下三点:1.使用一种span masking来代替BERT的mask;2.加入另外一个新的训练目标:Span Boundary Objective (SBO);3.使用单个句子而非一对句子,并且不使用Next Sentence Prediction任务。这样,SpanBERT使用了两个目标函数:MLM和SBO。
1 Span Masking
给定一个tokens序列 X = ( x1 , x2 , . . . , xn ),每次都会通过采样文本的一个片段(span),得到一个子集 Y ∈ X,直到满足15%的mask。在每次采样过程中,首先,随机选取一个片段长度,然后再随机选取一个起点,这样就可以到一个span进行mask了;span的长度会进行截断,即不超过10,并且实验得到p取0.2效果最好;
另外,span的长度是指word的长度,而不是subword,这也意味着采样的单位是word而非subword,并且随取的起点必须是一个word的开头。
与BERT一样,mask机制仍然为:80%替换为[MASK],10%保持不变,10%用随机的token替换。但不用的是,span masking是span级别的,即同一个span里的所有tokens会是同一种mask。
举例说明:
在SpanBERT中,不是对标记进行随机掩码,而是对连续片段进行掩码.

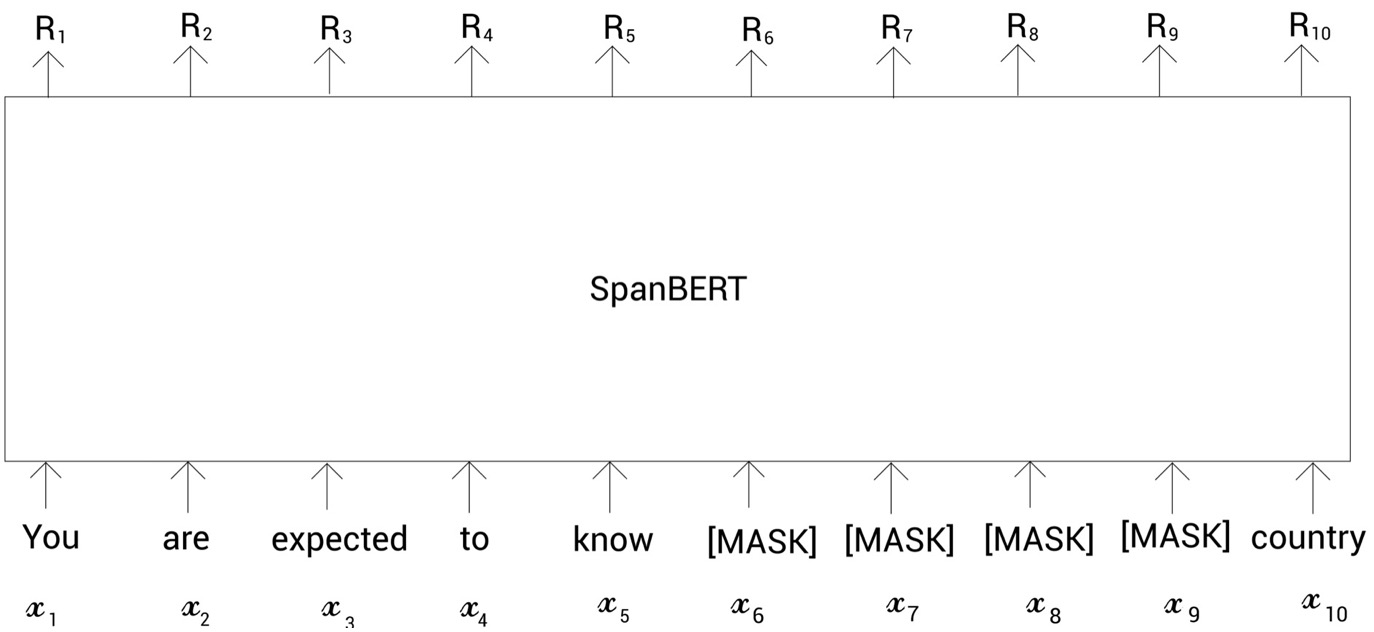
2 Span Boundary Objective
这个新增的预训练任务概括起来其实就是:仅使用span边界的tokens的表征,来预测该span内的这些mask的tokens原来对应哪些tokens,这其实与mlm类似,但它不使用上下文的所有tokens的表征。对masked span中的整体内容进行预测。
如果模型只使用片段边界标记表示来预测任何掩码的标记,那它是如何区分不同的被掩码的标记呢?比如,为了预测掩码的标记,我们的模型只使用片段边界标记表示
和
,然后为了预测掩码的标记
,我们的模型还是使用
和
。那这样的话,模型如何区别不同的掩码标记呢?因此,除了片段边界标记表示,模型还使用掩码标记的位置嵌入信息。这里的位置嵌入代表了掩码标记的相对位置。假设我们要预测掩码标记
。现在,在所有的掩码标记中,我们检查掩码标记
的位置。
如下图所示,掩码标记是所有掩码标记的第二个位置。所以现在,除了使用片段边界标记表示,我们也使用该掩码标记的位置嵌入,即
。通过外边界tokens的表征【R5】、【R10】和
相对位置embedding,用它去预测token
,与BERT中的MLM任务一样。
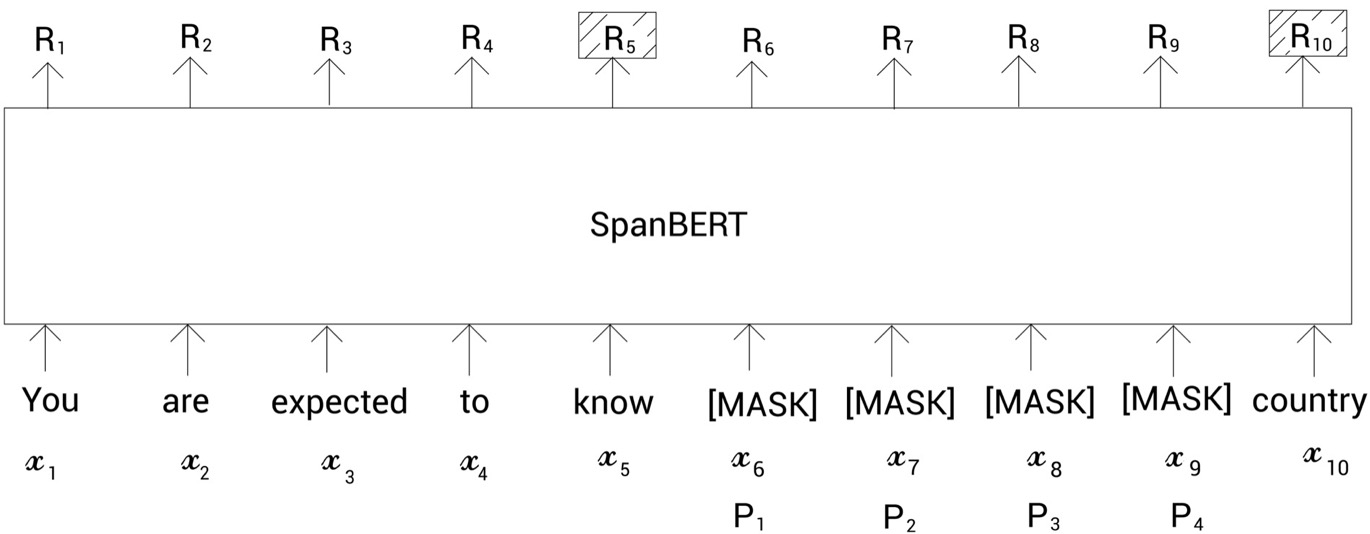
计算公式如下所示:
其中s表示span的起始位置,s-1表示的是span的左侧边界token;e表示的是span的结束位置,e+1表示的是span的右侧边界token,p表示的是位置信息。
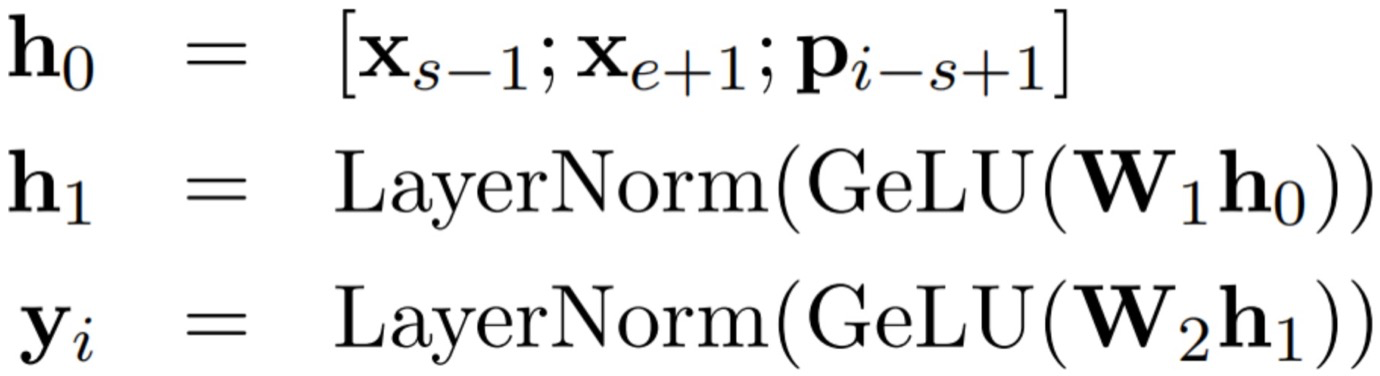
使用预测掩码标记
,训练过程中,将
喂给一个分类器,它返回预测的词表中所有单词的概率分布。
在MLM目标中,为了预测掩码标记,我们只要使用标记标记
即可。将
喂给一个分类器,它返回预测的词表中所有单词的概率分布。
SpanBERT的损失函数是MLM损失和SBO损失的总和。我们通过最小化这个损失函数来训练SpanBERT。在预训练之后,我们可以把预训练的SpanBERT用于任何下游任务。
3 Single-Sequence Training
BERT中包含着一个next sentence prediction的任务,这个任务的input是两个text的序列 , 预测二者是否是上下文。作者通过实验发现,这样的一种设置会比去掉NSP objective而只使用一个sequence的效果要差。因而作者猜测,single-sequence training比bi-sequence training+NSP的效果要好,分析原因如下:
- 模型能够从更长的full-length contexts中受益更多;
- 以从另外一个document中得到的context为条件,往往会给masked language model中添加许多noise。
因此,作者去掉了NSP objective以及two-segment sampling procedure,并仅仅采样出一个单独的continuous segment(这个segment中至多有512个tokens)。
Reference:
https://helloai.blog.csdn.net/article/details/120499194?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-120499194-blog-124881981.pc_relevant_3mothn_strategy_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-120499194-blog-124881981.pc_relevant_3mothn_strategy_recovery&utm_relevant_index=2
https://helloai.blog.csdn.net/article/details/120499194?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-1-120499194-blog-124881981.pc_relevant_3mothn_strategy_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~Rate-1-120499194-blog-124881981.pc_relevant_3mothn_strategy_recovery&utm_relevant_index=2
相关文章:
【深度学习】BERT变体—SpanBERT
SpanBERT出自Facebook,就是在BERT的基础上,针对预测spans of text的任务,在预训练阶段做了特定的优化,它可以用于span-based pretraining。这里的Span翻译为“片段”,表示一片连续的单词。SpanBERT最常用于需要预测文本…...
)
根据身高体重计算某个人的BMI值--课后程序(Python程序开发案例教程-黑马程序员编著-第3章-课后作业)
实例3:根据身高体重计算某个人的BMI值 BMI又称为身体质量指数,它是国际上常用的衡量人体胖瘦程度以及是否健康的一个标准。我国制定的BMI的分类标准如表1所示。 表1 BMI的分类 BMI 分类 <18.5 过轻 18.5 < BMI < 23.9 正常 24 < BM…...

高并发编程JUC之进程与线程高并发编程JUC之进程与线程
1.准备 pom.xml 依赖如下: <properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target&g…...
css基础
1-css引入方式内嵌式style(学习)<style>p {height: 200;}</style>外联式link(实际开发)<link rel"stylesheet" href"./2-my.css">2-选择器2.1标签选择器(标签名相同的都生效&am…...
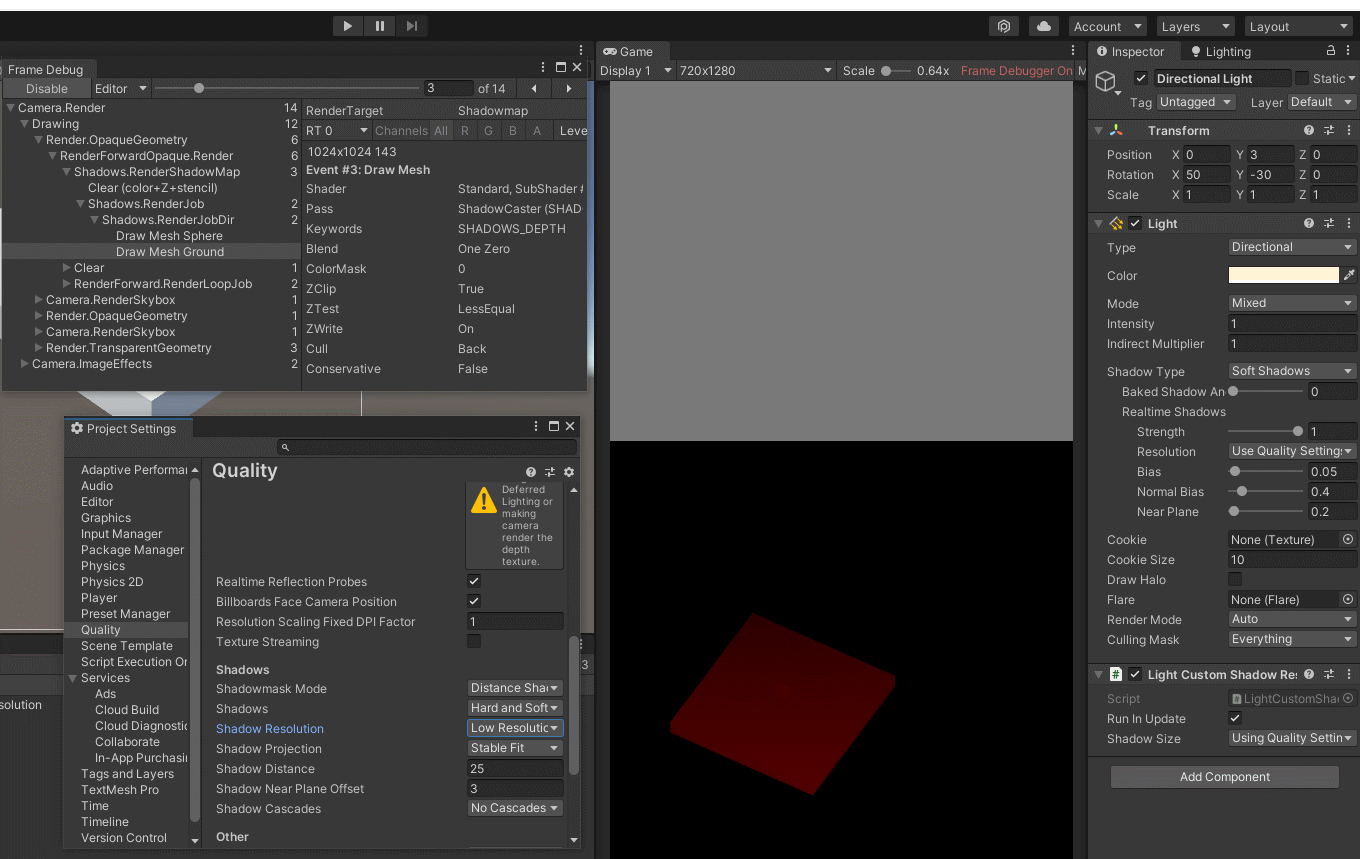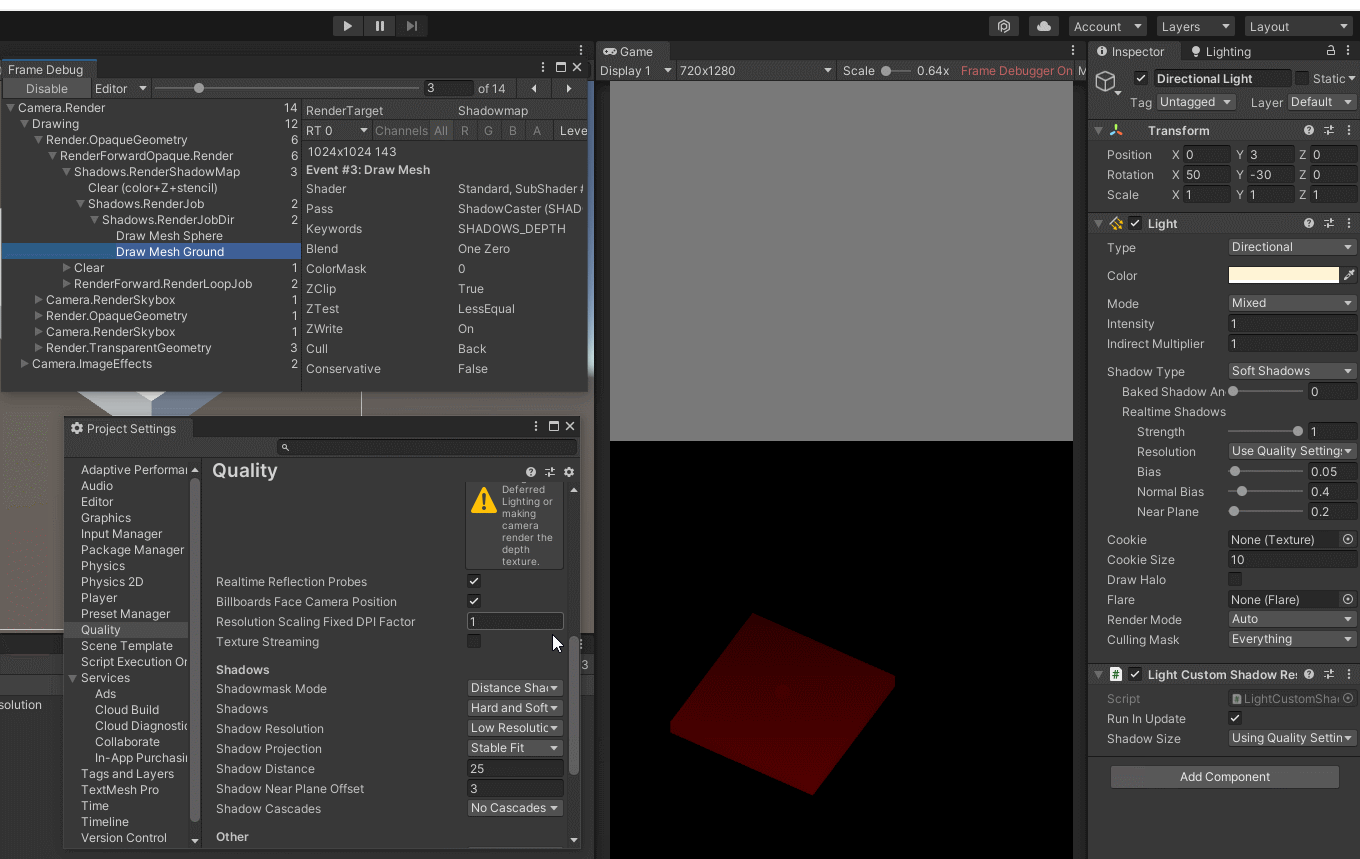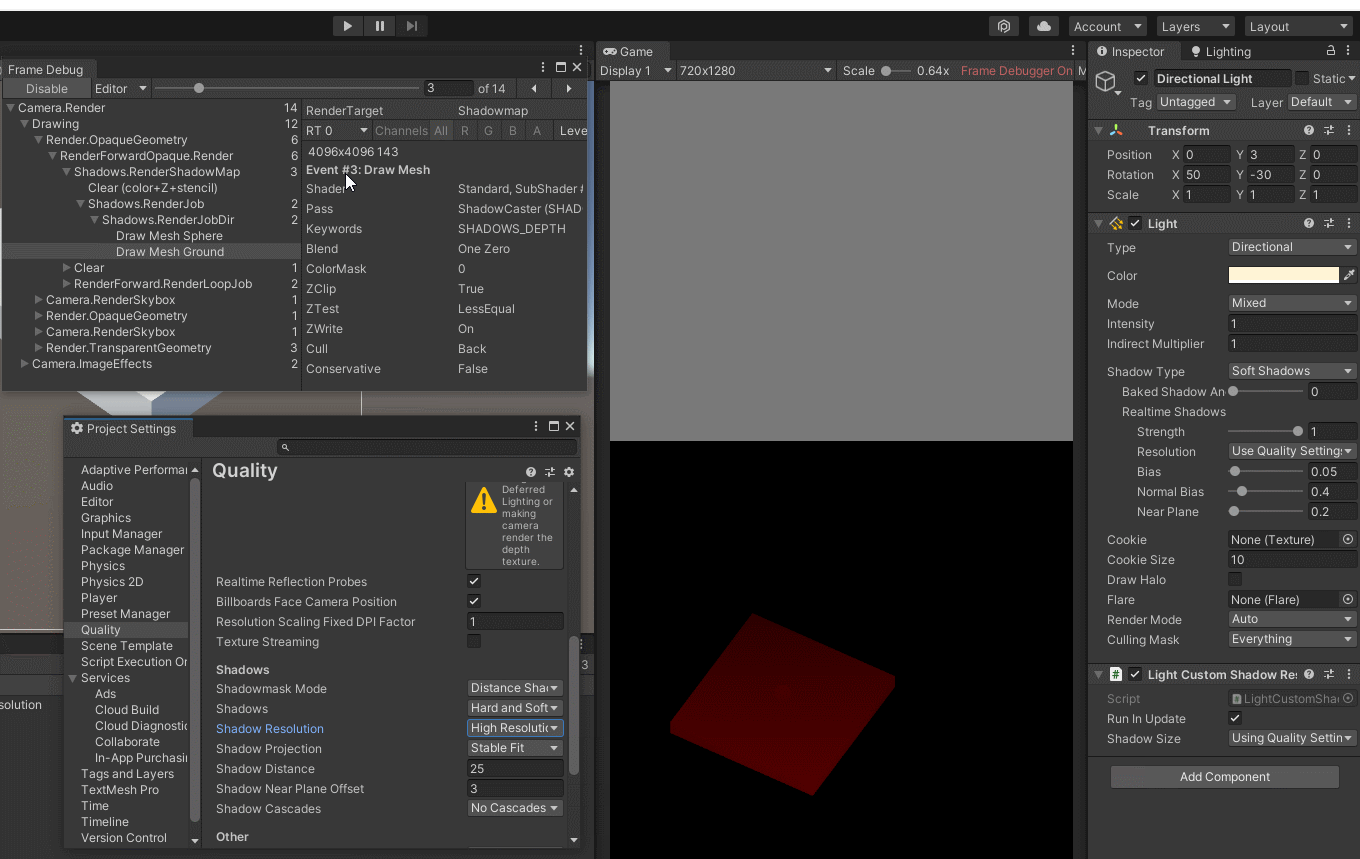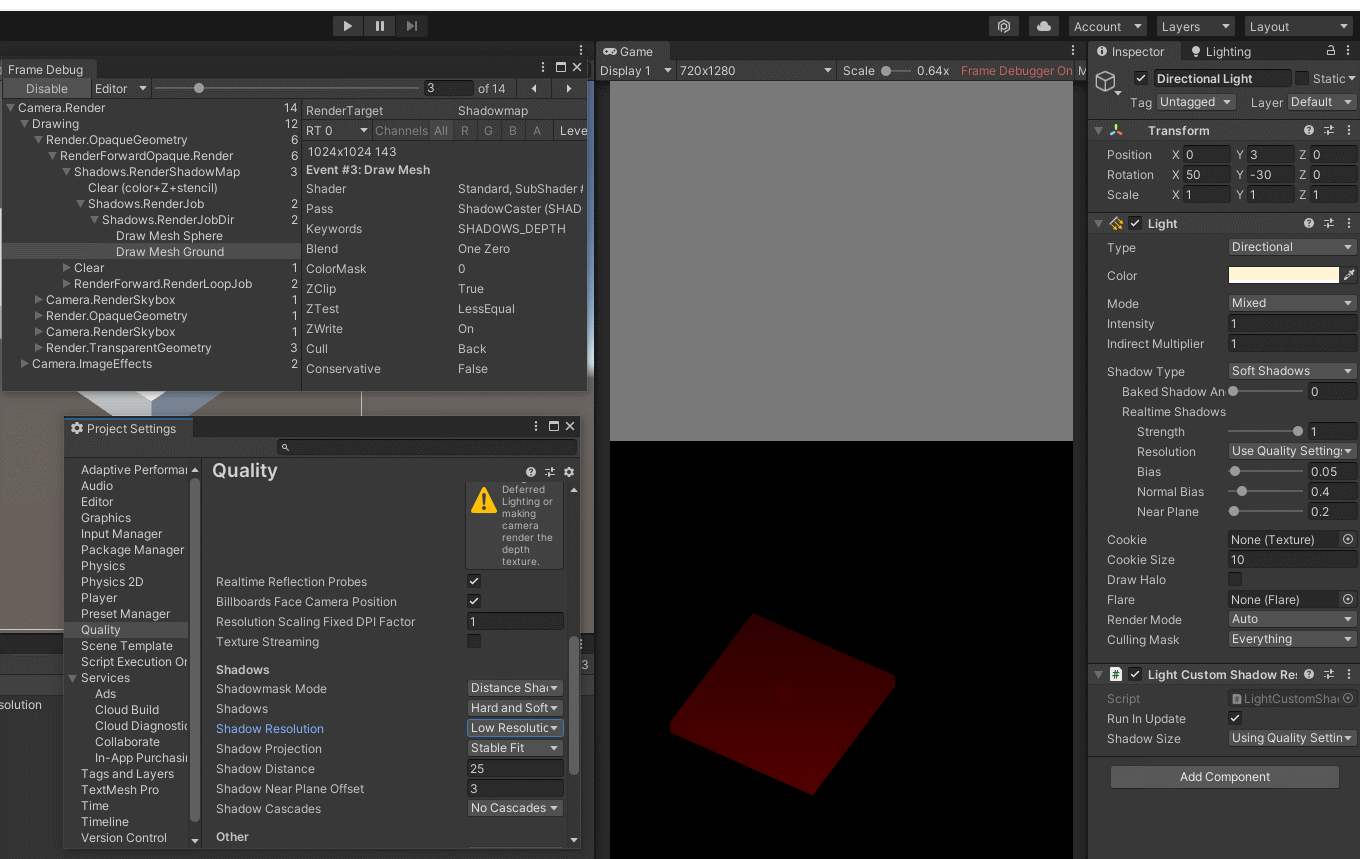
Unity - 搬砖日志 - BRP 管线下的自定义阴影尺寸(脱离ProjectSettings/Quality/ShadowResolution设置)
文章目录环境原因解决CSharp 脚本效果预览 - Light.shadowCustomResolution效果预览 - Using Quality Settings应用ControlLightShadowResolution.cs ComponentTools Batching add the Component to all LightReferences环境 Unity : 2020.3.37f1 Pipeline : BRP 原因 (好久没…...

如何在SSMS中生成和保存估计或实际执行计划
在引擎数据库执行查询时执行的过程的步骤由称为查询计划的一组指令描述。查询计划在SQL Server中也称为SQL Server执行计划,我们可以通过以下步骤来生成和保存估计或实际执行计划。 估计执行计划和实际执行计划是两种执行计划: 实际执行计划:当执行查询时,实际执行计划出…...
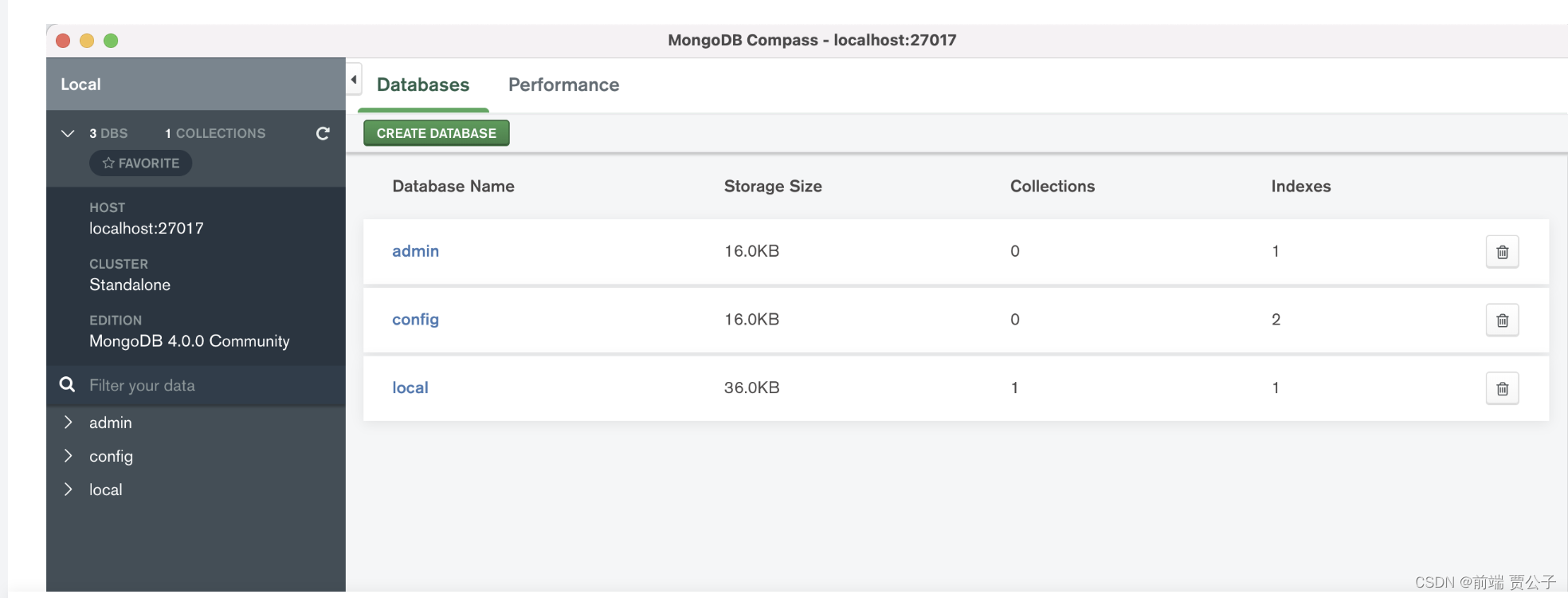
mac 环境下安装MongoDB
目录 一、下载MongoDB数据库并进行安装 二. 解压放在/usr/local目录下 三. 配置环境变量 “无法验证开发者”的解决方法 mongodb可视化工具的安装与使用 一、下载MongoDB数据库并进行安装 下载地址:https://www.mongodb.com/try/download/community 二. 解压…...
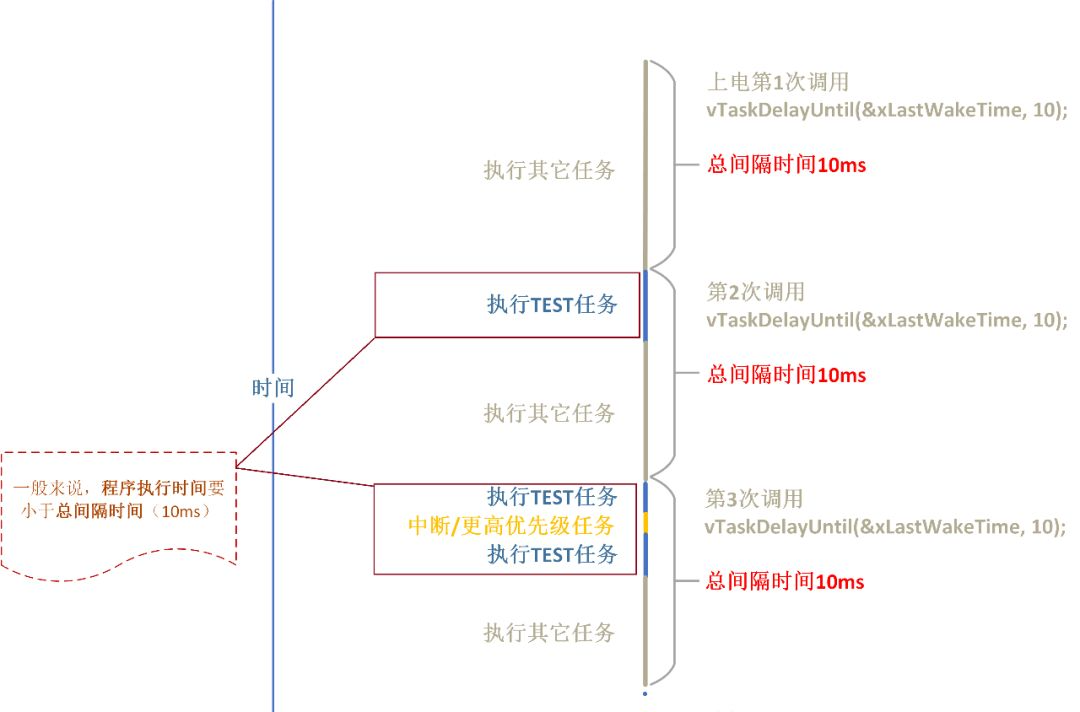
RTOS中相对延时和绝对延时的区别
相信许多朋友都有过这么一个需求:固定一个时间(周期)去处理某一件事情。 比如:固定间隔10ms去采集传感器的数据,然后通过一种算法计算出一个结果,最后通过指令发送出去。 你会通过什么方式解决呢…...

Solon2 项目整合 Nacos 配置中心
网上关于 Nacos 的使用介绍已经很多了,尤其是与 SpringBoot 的整合使用。怎么安装也跳过了,主要就讲 Nacos 在 Solon 里的使用,这个网上几乎是没有的。 1、认识 Solon Solon 一个高效的应用开发框架:更快、更小、更简单…...

Linux 路由表说明
写在前面: 本文章旨在总结备份、方便以后查询,由于是个人总结,如有不对,欢迎指正;另外,内容大部分来自网络、书籍、和各类手册,如若侵权请告知,马上删帖致歉。 目录route 命令字段分…...
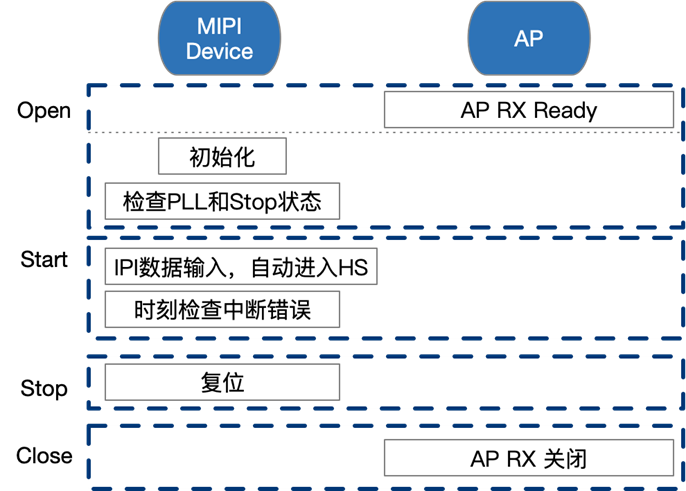
MIPI协议
MIPI调试指南Rev.0.1 June 18, 2019 © 2018 Horizon Robotics. All rights reserved.Revision HistoryThissection tracks the significant documentation changes that occur fromrelease-to-release. The following table lists the technical content changes foreach …...

第十届CCF大数据与计算智能大赛总决赛暨颁奖典礼在苏州吴江顺利举办
2月24日-25日,中国计算机学会(CCF)主办、苏州市吴江区人民政府支持,苏州市吴江区工信局、吴江区东太湖度假区管理办公室、苏州市吴江区科技局、CCF大数据专家委员会、CCF自然语言处理专业委员会、CCF高性能计算专业委员会、CCF计算…...
PMP高分上岸人士的备考心得,分享考试中你还不知道的小秘密
上岸其实也不是什么特别难的事情,考试一共就180道选择题,题目只要答对60.57%就可以通过考试,高分通过没在怕的,加油备考呀朋友们! 这里也提一嘴,大家备考的时候比较顾虑的一个问题就是考试究竟要不要报班…...

ubuntu下编译libpq和libpqxx库
ubuntu下编译libpq和libpqxx库,用于链接人大金仓 上篇文章验证了libpqxx可以链接人大金仓数据库,这篇文章尝试自己编译libpq和libpqxx库。 文章目录ubuntu下编译libpq和libpqxx库,用于链接人大金仓libpq下载libpq库看看有没有libpq库编译lib…...

ESP-C2系列模组开发板简介
C2是一个芯片采用4毫米x 4毫米封装,与272 kB内存。它运行框架,例如ESP-Jumpstart和ESP造雨者,同时它也运行ESP-IDF。ESP-IDF是Espressif面向嵌入式物联网设备的开源实时操作系统,受到了全球用户的信赖。它由支持Espressif以及所有…...
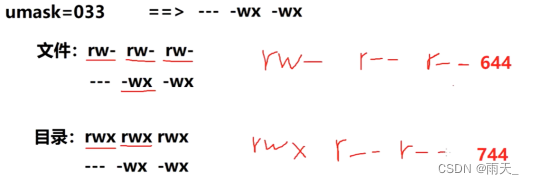
linux权限管理
权限管理 文件的权限针对三类对象进行定义: owner属主,缩写ugroup属组,缩写gother其他,缩写o 1、文件的一般权限 (1)r,w,x的作用及含义: 权限对文件影响对目录影响r(read…...

提高生活质量,增加学生对校园服务的需求,你知道有哪些?
随着电子商务平台利用移动互联网的趋势提高服务质量,越来越多的传统企业开始关注年轻大学生消费者的校园市场。 提高生活质量,增加学生对校园服务的需求 大学生越来越沉迷于用手机解决生活中的“吃、喝、玩、乐”等服务,如“吃、喝”——可…...
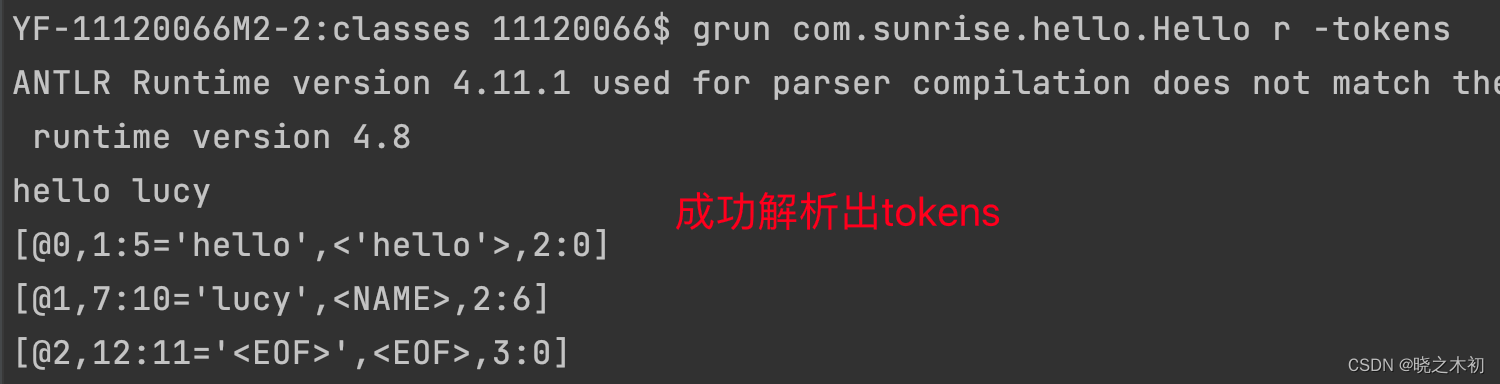
Antlr4:使用grun命令,触发NoClassDefFoundError
1. 意外的发现 在学习使用grun命令时,从未遇到过错误 最近使用grun命令,却遇到了NoClassDefFoundError的错误,使得grun测试工具无法成功启动 错误复现: 使用antlr4命令编译Hello.g4文件,并为指定package(…...

基于rootfs构建Docker镜像
1. 背景 在实际工作中,由于系统本身版本过低,在接受新项目时出现系统版本过低而无法开始工作的问题。 为了解决该问题,使用Docker构建基于ubuntu-18.04的Docker镜像,以解决版本兼容问题。 2. 构建rootfs 2.1. 下载ubuntu-18.0…...

电脑文件软件搬家迁移十大工具
10 大适用于 Windows 的数据迁移软件。 数据迁移至关重要,几乎所有组织都依赖于此。如果您认为数据传输不是一件容易的事,那么数据迁移软件可以帮上忙。 1、奇客电脑迁移 将现有操作系统、软件、文件迁移到 新电脑的最佳方法之一是使用名为奇客电脑迁移…...

多模型 API 聚合如何赋能智能体实现更复杂的决策与调度
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多模型 API 聚合如何赋能智能体实现更复杂的决策与调度 在构建高级智能体系统时,单一的模型提供商往往难以满足所有场景…...

对比直接使用官方 API 体验 Taotoken 聚合接入在配置简化上的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方 API 体验 Taotoken 聚合接入在配置简化上的优势 对于需要调用多种大模型能力的开发者而言,直接与各家…...

OpenAEON:从AI Agent到自主认知引擎的架构解析与实战
1. 项目概述:从“智能助手”到“自主认知引擎”的跃迁 如果你和我一样,在AI Agent领域摸爬滚打了几年,从早期的简单聊天机器人框架,到后来的工具调用(Function Calling)和RAG(检索增强生成&…...

基于Tauri与Rust构建跨平台Claude桌面客户端:架构设计与工程实践
1. 项目概述:一个为Claude设计的“圣杯”级桌面应用 如果你和我一样,在日常开发、写作或信息处理中重度依赖Anthropic的Claude模型,那么你肯定也经历过在浏览器标签页间反复横跳、复制粘贴、以及管理冗长对话历史的烦恼。 CoderLuii/HolyCla…...

AI智能体安全策略引擎:AgentEnforcer框架设计与实战应用
1. 项目概述:一个为AI智能体量身定制的“行为守门员” 最近在折腾AI智能体(Agent)的开发,尤其是在构建那些需要自主执行任务、与外部API交互的复杂系统时,一个核心痛点总是挥之不去: 如何确保智能体的行为…...
)
从DICOM到NIfTI:3D Slicer中医学图像坐标转换的完整避坑指南(附Python代码片段)
从DICOM到NIfTI:3D Slicer中医学图像坐标转换的完整避坑指南(附Python代码片段) 医学影像处理中,数据格式和坐标系的差异常常成为工程师和研究员们的"隐形杀手"。想象一下,你花了三天三夜训练的深度学习模型…...

定制软件开发公司实施方
定制软件开发,为何80%的企业选错实施方?这3个坑你踩过吗?“我们项目预算超了50%,还没上线……”“系统动不动就卡死,用户天天投诉,售后根本找不到人!”“当时说好的功能,现在告诉我实…...
:Agent 的记忆危机与 Mem0 的三阶段管道——为什么 RAG 不够用?)
【Mem0】 源码剖析(一):Agent 的记忆危机与 Mem0 的三阶段管道——为什么 RAG 不够用?
【Mem0】 源码剖析(一):Agent 的记忆危机与 Mem0 的三阶段管道——为什么 RAG 不够用? 写在前面:54K Star,论文被 arXiv 收录,LOCOMO 基准 SOTA——Mem0 是当前 Agent 记忆层的事实标准。它的核…...

AI系统合规性故障模式解析:从公平性、隐私到可解释性的工程实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“AI-Compliance-Failure-Patterns”。光看名字,你大概能猜到它和AI的合规性有关,但具体是做什么的,可能还有点模糊。简单来说,这个项目就像一本针对AI系…...
)
告别X11!在Ubuntu 22.04上从源码编译Wayland+Weston桌面(保姆级避坑指南)
从X11到Wayland:Ubuntu 22.04源码编译Weston全流程实战 如果你已经受够了X11的老旧架构和偶尔的卡顿,现在是时候拥抱Wayland了。作为Linux桌面图形栈的下一代接班人,Wayland不仅在设计上更现代化,还能带来更流畅的图形体验。本文将…...