文本处理基本方法
目录
分词
jieba
词性标注
😆😆😆感谢大家观看😆😆😆
分词
在中文文本中,由于词与词之间没有明显的界限符,如英文中的空格,因此分词是中文自然语言处理的一个基础且重要的步骤。分词的准确性直接影响到后续的语言处理任务,如词性标注、句法分析等。在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符。分词过程就是找到这样分界符的过程。
分词的作用:
词作为语言语义理解的最小单元, 是人类理解文本语言的基础. 因此也是AI解决NLP领域高阶任务, 如自动问答, 机器翻译, 文本生成的重要基础环节。
- 句子:“我爱自然语言处理。”
- 分词结果:“我 / 爱 / 自然语言处理。”
在这个例子中,“自然语言处理”作为一个整体是一个专有名词,应该被识别为一个单独的词语,而不是分开为“自然”、“语言”和“处理”。
- 句子:“中国的首都北京是一个历史悠久的城市。”
- 分词结果:“中国 / 的 / 首都 / 北京 / 是 / 一个 / 历史 / 悠久 / 的 / 城市。”
jieba
jieba库利用一个中文词库来确定汉字之间的关联概率,通过这些概率来组合成词组,从而形成分词结果。除了基本的分词功能,jieba还支持关键词提取、词性标注、词位置查询等高级功能。用户可以向jieba库中添加自定义词组,以提高特定领域文本的分词准确性。jieba库考虑到了性能问题,支持并行分词,提高大规模文本处理的效率。这使得它成为当前Python语言中优秀的中文分词组件之一。
jieba是一个强大的中文分词工具,它具备多种特性,适用于不同的分词需求。三种分词模式
- 精确模式:此模式能够精确地将文本分离开,不会产生冗余的词组。
- 全模式:在全模式下,系统会扫描出文本中所有可能的词语,这可能会包含一些冗余的词汇。
- 搜索引擎模式:这种模式是在精确模式的基础上,对长词进行再次切分,特别适用于搜索引擎中的分词处理。
pip install jieba
import jiebasentence = "我爱自然语言处理"
seg_list = jieba.cut(sentence, cut_all=False)
print("精确模式分词结果:", "/".join(seg_list))中文繁体分词:
import jieba
content = "煩惱即是菩提,我暫且不提"
jieba.lcut(content)
['煩惱', '即', '是', '菩提', ',', '我', '暫且', '不', '提']三种分词模式案例
- 精确模式:使用
jieba.cut()函数,设置参数cut_all=False(默认值)。
import jiebatext = "我爱自然语言处理"
seg_list = jieba.cut(text, cut_all=False)
print("精确模式分词结果:", "/".join(seg_list))
2.全模式:使用jieba.cut()函数,设置参数cut_all=True。
import jiebatext = "我爱自然语言处理"
seg_list = jieba.cut(text, cut_all=True)
print("全模式分词结果:", "/".join(seg_list))
- 3搜索引擎模式:使用
jieba.cut_for_search()函数。
import jiebatext = "我爱自然语言处理"
seg_list = jieba.cut_for_search(text)
print("搜索引擎模式分词结果:", "/".join(seg_list))使用jieba分词时,可以通过添加自定义词典来提高分词的准确性。
- 创建自定义词典文件:首先,创建一个文本文件,将需要添加到词典中的词汇按照每行一个词的格式列出。例如,如果你的专业领域有特殊术语或者你想加入人名、地名等,都可以在这个文件中添加。
- 加载自定义词典:在使用jieba分词时,可以通过
jieba.load_userdict(file_name)函数加载自定义词典。这样,jieba在分词时就会自动识别并使用这些新词。 - 使用自定义词典进行分词:加载了自定义词典后,可以像平常一样使用
jieba.cut函数进行分词,此时jieba会优先考虑自定义词典中的词汇。
import jieba# 加载自定义词典
jieba.load_userdict('my_dict.txt')# 使用自定义词典进行分词
sentence = "这是一个包含专业术语的句子"
seg_list = jieba.cut(sentence, cut_all=False)
print("使用自定义词典后的分词结果:", "/".join(seg_list))命名实体识别
命名实体识别(Named Entity Recognition, NER)是自然语言处理(NLP)中的一项基础任务,它的目标是从文本中识别出具有特定意义的实体,并将这些实体分类到预定义的类别。
命名实体识别包括以下几个关键点:
- 边界识别:确定文本中实体的开始和结束位置。
- 类别识别:将识别出的实体归类到如人名、地名、组织名、时间表达式等类别中。
- 序列标注:命名实体识别属于序列标注任务,需要为文本中的每个词或字分配一个标签,以指示它是否属于某个命名实体以及它的类别。
词性标注
词性: 语言中对词的一种分类方法,以语法特征为主要依据、兼顾词汇意义对词进行划分的结果, 常见的词性有14种, 如: 名词, 动词, 形容词等。
我爱自然语言处理
==>
我/rr, 爱/v, 自然语言/n, 处理/vn
rr: 人称代词
v: 动词
n: 名词
vn: 动名词
词性标注以分词为基础, 是对文本语言的另一个角度的理解, 因此也常常成为AI解决NLP领域高阶任务的重要基础环节 。
要使用jieba进行中文词性标注,可以使用jieba.posseg模块:
import jieba.posseg as pseg# 待分词的文本
text = "我爱自然语言处理"# 使用jieba进行词性标注
words = pseg.cut(text)# 输出每个词语及其词性
for word, flag in words:print(f"{word}({flag})", end=" ")# 我(r) 爱(v) 自然语言处理(nz)其中,"r"表示代词,"v"表示动词,"nz"表示其他专有名词。请注意,jieba的词性标注功能基于其内置的词典和规则,可能无法完全准确地标注所有词汇的词性。
相关文章:

文本处理基本方法
目录 分词 jieba 词性标注 😆😆😆感谢大家观看😆😆😆 分词 在中文文本中,由于词与词之间没有明显的界限符,如英文中的空格,因此分词是中文自然语言处理的一个基础且…...

Java面试题(Spring篇)
💟💟前言 友友们大家好,我是你们的小王同学😗😗 今天给大家打来的是 Java面试题(Spring篇) 希望能给大家带来有用的知识 觉得小王写的不错的话麻烦动动小手 点赞👍 收藏⭐ 评论📄 小王的主页…...
操作系统:malloc与堆区内存管理
malloc是函数而不是系统调用,他的底层是同调调用brk和mmap这两个系统调用实现功能的,具体选择brk还是mmap要看申请的空间大小以及malloc中的阈值(一般是128kb) 注意申请的空间只有使用才会触发缺页中断映射到物理内存 不理解的话先…...

javaSwing推箱子游戏
一、简介 策略性游戏可以锻炼人的思维能力还能缓解人的压力,使人们暂时忘却生活当中的烦恼,增强人们的逻辑思维能力,游戏的艺术美也吸引着越来越多的玩家和厂商,寓教于乐,在放松人们心情的同时还可以活跃双手。在人类…...

JAVA多线程之JMM
文章目录 1. Java内存模型2. 内存交互3. 三大特性3.1 可见性3.1.1 可见性问题3.1.2 原因3.1.3 解决方法 3.2 原子性3.3 有序性 4. 指令重排5. JMM 与 happens-before5.1 happens-before关系定义5.2 happens-before 关系 在继续学习JUC之前,我们现在这里介绍一下Java…...
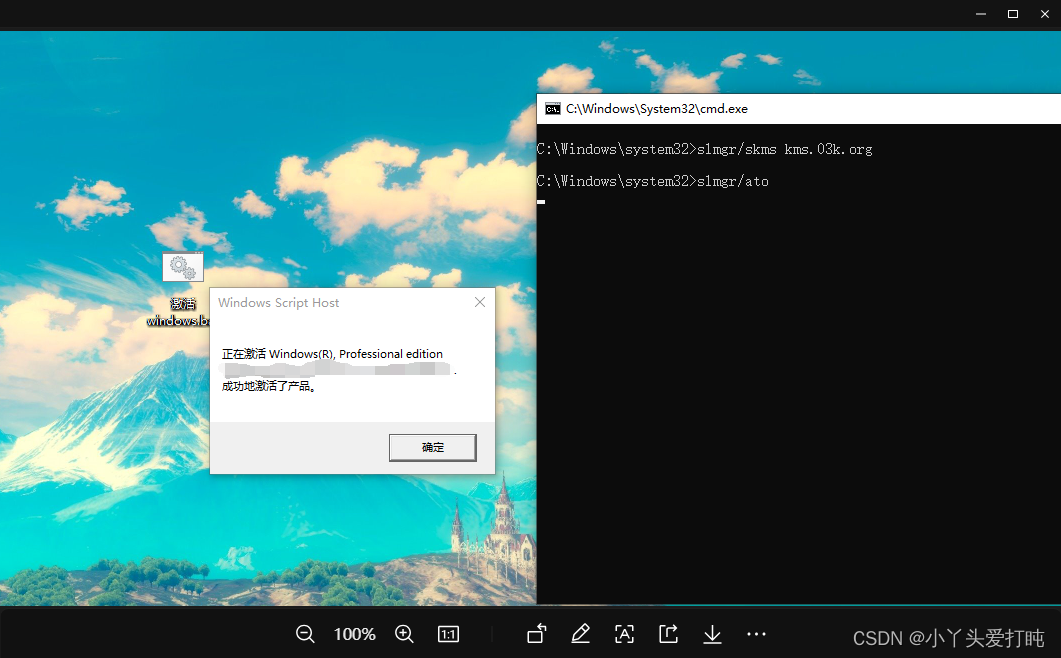
Windows10 专业版 系统激活
Windows10 专业版 系统激活 参考: Windows10系统激活技巧 第一步:在电脑桌面,新建一个文本文档 第二步:打开文本文档,输入以下代码后,直接保存关闭文档 slmgr/skms kms.03k.org slmgr/ato 第三步࿱…...

C#使用LINQ和EF Core
在实际应用中,您可以使用 LINQ 查询 EF Core 来执行各种数据库操作。通过 LINQ,您可以轻松地过滤、排序、分组和连接数据。 要使用LINQ查询EF Core中的数据,您可以按照以下步骤进行操作: 首先,确保您已经安装了 Entit…...
数字人解决方案— SadTalker语音驱动图像生成视频原理与源码部署
简介 随着数字人物概念的兴起和生成技术的不断发展,将照片中的人物与音频输入进行同步变得越来越容易。然而,目前仍存在一些问题,比如头部运动不自然、面部表情扭曲以及图片和视频中人物面部的差异等。为了解决这些问题,来自西安…...

HTML5语法总结
文章目录 一.HTML基本框架二.标题标签三.段落标签四.换行与水平线标签五.文本格式化标签(加粗、倾斜、下划线、删除线)六.图像标签扩展:相对路径,绝对路径与在线网址 七.超链接标签八.音频标签九.视频标签十.列表标签十一.表格标签扩展:表格结构标签合并…...

在github下载的神经网络项目,如何运行?
github网页上可获取的信息 在github上面,有一个requirements.txt文件,该文件说明了项目要求的python解释器的模块。 - 此外,还有一个README.md文件,用来说明项目的运行环境以及其他的信息。例如python解释器的版本是3.7、PyTorc…...
spring boot学习第十四篇:使用AOP编程
一、基本介绍 1,什么是 AOP (1)AOP 为 Aspect Oriented Programming 的缩写,意为:面向切面编程,通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术。 (2)利用 AOP…...
凯特信安云签解决方案
联合解决方案 凯特信安基于《电子签名法》设计“云签服务方案”,应用人脸识别、电子签章签名云服务等技术,支持多个自然人、多个企业等签名,满足各种移动终端签署的应用场景。面向不动产登记、工改系统等社会公众服务系统,针对自然…...

【xr806开发板使用】连接wifi例程实现
##开发环境 win10 WSL ##1、环境配置 参考:https://aijishu.com/a/1060000000287513 首先下载安装wsl 和ubuntu https://docs.microsoft.com/zh-cn/windows/wsl/install (1)安装repo: 创建repo安装目录: mkdir ~/…...
停车管理系统asp.net+sqlserver
停车管理系统asp.netsqlserver 说明文档 运行前附加数据库.mdf(或sql生成数据库) 主要技术: 基于asp.net架构和sql server数据库, 功能模块: 停车管理系统asp.net sqlserver 用户功能有菜单列表 我的停车记录 专…...
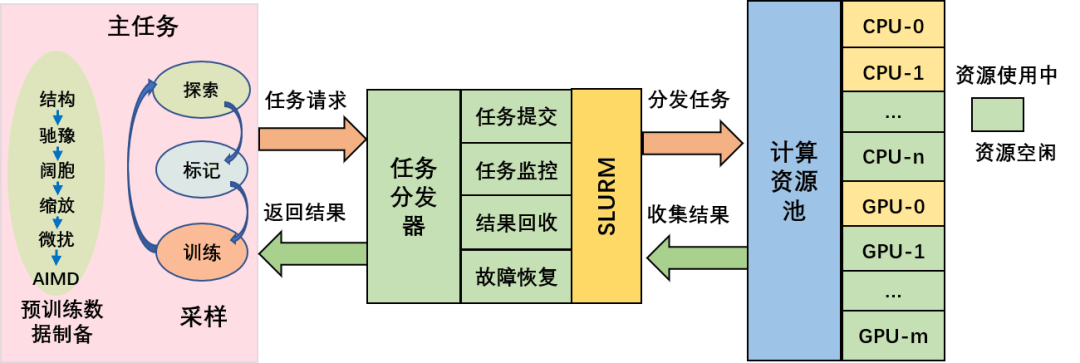
新增多项功能,龙讯旷腾开源机器学习力场PWMLFF 2024.3版本上线
人工智能与传统计算机模拟结合是当今科学计算的一大趋势,机器学习力场作为其中的一个重要方向,能够显著提升分子动力学模拟的精度和效率。PWMLFF是一套由龙讯旷腾团队开发,在 GNU 许可下的开源软件包,用于快速生成媲美从头算分子动力学(AIMD&…...

Docker常用命令练习
文章目录 Docker常用命令练习1.docker 基础命令2.镜像命令3.保存镜像4.加载镜像5.容器命令6.环境变量7. --rm8. --networkhost Docker常用命令练习 1.docker 基础命令 安装docker yum install docker启动docker systemctl start docker关闭docker systemctl stop docker重…...
安全)
Kafka(十)安全
目录 Kafka安全1 安全协议1.1 PALINTEXT1.2 SSL1.2.1 生成服务端证书1.2.2 生成客户端证书1.2.3 修改配置listenersadvertised.listenerslistener.security.protocol.mapinter.broker.listener.namesecurity.inter.broker.protocolcontrol.plane.listener.name 1.3 SASL_PLAINT…...
流畅的 Python 第二版(GPT 重译)(四)
第二部分:函数作为对象 第七章:函数作为一等对象 我从未认为 Python 受到函数式语言的重大影响,无论人们说什么或想什么。我更熟悉命令式语言,如 C 和 Algol 68,尽管我将函数作为一等对象,但我并不认为 Py…...
windows docker
写在前面的废话 最近在学习riscv的软件相关内容,倒是有别人的sg2042机器可以通过ssh使用,但是用起来太不方便了,经常断掉,所以想着在自己的机器上跑一跑riscv的操作系统。最常见的有两种方法吧,第一个就是qemu…...

中国1km分辨率逐月地表太阳辐射均值数据集(1960-2022)
地表太阳辐射是地球系统的主要驱动因子,驱动着地球系统的能量、水和碳循环。它是地表水文、生态、农业等陆表过程模拟的重要驱动数据,也是太阳能利用的重要指标。发展长时间序列、高分辨率的地表太阳辐射数据集,对于地表过程研究、太阳能电厂…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...

3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题
3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题 【免费下载链接】tool the USBToolBox tool 项目地址: https://gitcode.com/gh_mirrors/too/tool 在Hackintosh和跨平台开发领域,USB端口映射一直是个令人头疼的技术难题。US…...

飞书远程控机:OpenClaw配置全攻略
本文详细介绍如何通过 OpenClaw 工具对接飞书开放平台,配置智能机器人实现 Windows 电脑的远程控制。主要内容涵盖文件管理和程序启动等核心功能的实现方法,并提供完整的配置指南与常见问题解决方案。 一、使用前提说明 1. 系统要求 仅适用于 Windows…...

BurpSuite 2025插件开发JDK版本兼容性实战指南
1. 为什么BurpSuite插件开发环境总在JDK版本上翻车?你是不是也经历过:下载好BurpSuite最新版2025.4,兴冲冲打开插件开发文档,照着官方示例写完第一个HelloWorld插件,一编译——java.lang.UnsupportedClassVersionError…...

Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器
Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 还在为复杂的Steam游戏清单下载而头疼吗?想要备份游戏资源却不…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

一次搞懂内存取证:用Volatility3和Cobalt Strike分析工具复现VNCTF‘来一把紧张刺激的CS’
实战内存取证:从Volatility3到Cobalt Strike信标分析全解析 在网络安全事件响应中,内存取证往往是发现高级威胁的最后一道防线。当攻击者使用文件无落地的技术时,传统的磁盘取证可能一无所获,而内存中却保留着攻击行为的完整痕迹。…...

解决Claude Code Token不足问题并享受Taotoken活动价
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code Token不足问题并享受Taotoken活动价 应用场景类,聚焦于使用Claude Code时遇到Token配额紧张的开发者&…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...

pan-baidu-download:百度网盘多线程下载加速器架构解析与性能优化指南
pan-baidu-download:百度网盘多线程下载加速器架构解析与性能优化指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download pan-baidu-download是一款基于Python开发的百度网盘命令行下载…...