数据挖掘|数据集成|基于Python的数据集成关键问题处理
数据挖掘|数据集成|基于Python的数据集成关键问题处理
- 1. 实体识别
- 2. 数据冗余与相关性分析
- 3. 去除重复记录
- 4. 数据值冲突的检测与处理
- 5. 基于Python的数据集成
- 5.1 merge()方法
- 5.2 Concat()方法
数据集成是把来自多个数据库或文件等不同数据源的数据整合成一致的数据存储。其中关键问题有:实体识别、数据冗余与相关性分析、记录重复、数据值冲突的检测与处理。
1. 实体识别
实体识别主要涉及同名异义、异名同义、单位统一以及ID-Mapping等方面。
2. 数据冗余与相关性分析
为了提高数据挖掘的精度和减少数据挖掘使用的时间,对多个数据源进行集成时,减少数据集中的冗余和不一致是十分必要的。
如果一个属性可以由另外一个或一组属性值推导出来,则这个属性可能是冗余的。
冗余是数据集成的一个重要问题,有些冗余可以通过相关性分析检测出来。
对于标称数据,两个属性A和B之间的相关关系可以通过 χ 2 \chi^2 χ2(卡方)检验发现,这里不做详细介绍。
对于数值数据,可以通过计算属性A和B的相关系数(又称 Pearson积矩系数)来分析其相关性。
用Python求相关系数的方法有三种:
- 用numpy模块中的corrcoef()函数计算相关系数矩阵。
- 用pandas模块中DataFrame对象自带相关性计算方法corr(),可以求出所有列之间的相关系数。
- 自己编写Python程序计算相关系数。
对于数值属性,可以使用协方差来评估一个属性值如何随另一个属性值变化。在概率论和统计学中,协方差(Covariance)是用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即为两个变量相同时的协方差。它们都是评估两个属性如何一起变化。
使用Python求协方差示例:
import numpy as np
from sklearn import datasets
iris = datasets.load_iris() #装载鸢尾花数据
A= iris.data[:,0]
B= iris.data[:,1]
result=np.cov(A,B)
print(result)
[[ 0.68569351 -0.042434 ][-0.042434 0.18997942]]
3. 去除重复记录
除了检查属性的冗余之外,还要检测重复的记录,所谓重复记录是指给定唯一的数据实体,存在两个或多个相同的记录。
Python的模块Numpy中unique()函数可以去除一维数组或者列表中的重复元素;对于多维数组,如果指定 axis=0 , 可以把冗余的行去掉,若指定 axis=1 ,可以把冗余的列去掉。
例:去掉多维数组的重复行。
import numpy as np
data=np.array([['S1','张三','女',21],['S4','李四','女',22],['S1','张三','女',21],['S5','王五','男',20]])
print("去除重复前:\n",data)
result=np.unique(data,axis=0)
print("去除重复后:\n",result)
去除重复前:[['S1' '张三' '女' '21']['S4' '李四' '女' '22']['S1' '张三' '女' '21']['S5' '王五' '男' '20']]
去除重复后:[['S1' '张三' '女' '21']['S4' '李四' '女' '22']['S5' '王五' '男' '20']]
4. 数据值冲突的检测与处理
数据集成还涉及数据值冲突的检测与处理,如:
- 对于现实世界的同一实体,来自不同的数据源的属性值可能不同。
- 相同属性的单位可能不同,如公斤和磅;学生成绩有百分制也有五级制等。
- 模式不同,如某大学的学生成绩数据库表中的每一行是成绩类型和相应的成绩,而另一所大学学生成绩数据库表中的每一行是基本课程成绩和平时成绩,还有大学的学生成绩数据库用两个表来存储学生的成绩,第一个表专门存储学生的基本课程成绩,第二个表专门存储学生的平时成绩。
数据值冲突的处理方法是按照一定规则建立起底层关系数据库模式的语义模型,然后利用建立好的语义冲突本体来扩展关系数据库模式的语义,最后再给出基于本体和数据库语义模型解决冲突的具体方法。
5. 基于Python的数据集成
针对可能来自于不同的数据源,可以使用Python对数据子集进行集成处理。Pandas模块中的merge()、concat()方法可以完成数据的集成。
5.1 merge()方法
merge()方法主要是基于两个DataFrame对象的共同列进行连接。
merge()函数常用形式为:
merge(left,right,how=’inner’,on=None,left_on=None,right_on= None, sort=True)
例:merge()函数数据集成示例。
import pandas as pd
S_info=pd.DataFrame({'学号':['S1','S2','S3','S4','S5'],'姓名':['许文','刘德','刘世','于金','周新']})
course=pd.DataFrame({'学号':['S1','S2','S1','S4','S1'],'课程':['C2','C1','C3','C2','C4']})
df=pd.merge(S_info,course)
print(df)
学号 姓名 课程
0 S1 许文 C2
1 S1 许文 C3
2 S1 许文 C4
3 S2 刘德 C1
4 S4 于金 C2
#当遇到两个数据集的关键字不同时,可以分别指定联结关键字:
import pandas as pd
S_info=pd.DataFrame({'学号':['S1','S2','S3','S4','S5'],'姓名':['许文','刘德','刘世','于金','周新']})
course=pd.DataFrame({'编号':['S1','S2','S1','S4','S1'],'课程':['C2','C1','C3','C2','C4']})
df=pd.merge(S_info,course,left_on='学号',right_on='编号')
print("左、右数据子集关键字不同的merge()函数数据集成:\n",df)
左、右数据子集关键字不同的merge()函数数据集成:学号 姓名 编号 课程
0 S1 许文 S1 C2
1 S1 许文 S1 C3
2 S1 许文 S1 C4
3 S2 刘德 S2 C1
4 S4 于金 S4 C2
#当how=’outer’时,函数merge()的数据集成示例。
import pandas as pd
grade1=pd.DataFrame({'学号':['S1','S2','S3','S4','S5'],'姓名':['许文','刘德','刘世','于金','周新'],'高数':[67,92,67,58,78],'英语':[82,88,96,90,87]})
grade2=pd.DataFrame({'学号':['S1','S2','S4','S5','S6'],'数据库技术':[89,34,74,90,83]})
df=pd.merge(grade1,grade2,how='outer')
print(df)
学号 姓名 高数 英语 数据库技术
0 S1 许文 67.0 82.0 89.0
1 S2 刘德 92.0 88.0 34.0
2 S3 刘世 67.0 96.0 NaN
3 S4 于金 58.0 90.0 74.0
4 S5 周新 78.0 87.0 90.0
5 S6 NaN NaN NaN 83.0
# merge()函数通过多个键的数据集成示例。
import pandas as pd
info_s=pd.DataFrame({'学号':['S1','S2','S3','S4','S5'],'姓名':['许文','刘德','刘世','于金','周新'],'性别':['女','男','男','女','女']})
course=pd.DataFrame({'学号':['S1','S2','S1','S3','S5','S2', 'S1'],'姓名':['许文','刘德','许文','刘世','周新','刘德','许文'],'课程':['C1','C1','C3','C2','C2','C3','C4'], '成绩':[78,82,67,92,89,77,68]})
df=pd.merge(info_s,course,on=['学号','姓名'])
print(df)
学号 姓名 性别 课程 成绩
0 S1 许文 女 C1 78
1 S1 许文 女 C3 67
2 S1 许文 女 C4 68
3 S2 刘德 男 C1 82
4 S2 刘德 男 C3 77
5 S3 刘世 男 C2 92
6 S5 周新 女 C2 89
5.2 Concat()方法
Concat()方法是对Series对象或DataFrame对象的数据集进行连接,可以指定按某个轴进行(行或列)连接,也可以指定连接方式:outer和inner。与SQL不同的是concat()不会去重,要达到去重的效果可以使用drop_duplicates()方法。常用形式为:
concat(objs,axis=0,join=’outer’)
参数说明:(1) objs:Series对象、DataFrame对象或list对象。(2) axis:需要连接的轴,axis=0是行连接,axis=1是列连接。(3) join:连接的方式,inner或outer。
#Concat()方法连接示例
import pandas as pd
data1=[['S1','许文','女'],['S2','刘德','男'],['S3','刘世','男'],['S4','于金','女'],['S5','周新','女']]
df1=pd.DataFrame(data1,columns=['学号','姓名','性别'])
data2=[[78,89,80,61],[77,83,78,66],[90,54,68,78],[76,66,80,82]]
df2=pd.DataFrame(data2,columns=['高数','英语','数据库技术','数据挖掘'])
df=pd.concat([df1,df2],axis=1,join='outer')
print(df)
学号 姓名 性别 高数 英语 数据库技术 数据挖掘
0 S1 许文 女 78.0 89.0 80.0 61.0
1 S2 刘德 男 77.0 83.0 78.0 66.0
2 S3 刘世 男 90.0 54.0 68.0 78.0
3 S4 于金 女 76.0 66.0 80.0 82.0
4 S5 周新 女 NaN NaN NaN NaN
相关文章:

数据挖掘|数据集成|基于Python的数据集成关键问题处理
数据挖掘|数据集成|基于Python的数据集成关键问题处理 1. 实体识别2. 数据冗余与相关性分析3. 去除重复记录4. 数据值冲突的检测与处理5. 基于Python的数据集成5.1 merge()方法5.2 Concat()方法 数据集成是把来自多个数据库或文件等不同数据源的数据整合成一致的数据存储。其中…...
Linux-网络层IP协议、链路层以太网协议解析
目录 网络层:IP协议地址管理路由选择 链路层 网络层: 网络层:负责地址管理与路由选择 — IP协议,地址管理,路由选择 IP协议 数据格式: 4位协议版本:4-ipv4协议版本 4位首部长度:以…...

后端开发辅助
maven仓库手动添加jar命令 mvn install:install-file -DfileD:\\spire.xls-4.6.5.jar -DgroupIde-iceblue -DartifactIdspire.xls -Dversion4.6.5 -Dpackagingjaroracle调用存储过程示例 DECLAREPO_ERRCODE VARCHAR2(100);PO_ERRMSG VARCHAR2(100);BEGIN-- Call the procedure…...

插件电阻的工艺结构原理及选型参数总结
🏡《总目录》 目录 1,概述2,工作原理3,结构特点3.1,引脚设计3.2,电阻体3.3,封装4,工艺流程4.1,材料准备4.2,电阻体制作4.3,引脚焊接4.4,绝缘处理4.5,测试与筛选4.6,包装与存储...
视频私有云,HDMI/AV多硬件设备终端接入,SFU/MCU视频会议交互方案。
在视频业务深入的过程中越来越多的硬件设备接入视频交互的视频会议中远程交互,有的是视频采集,有的是医疗影像等资料,都需要在终端承显,这就需要我们的设备终端能多设备,多协议接入,设备接入如下。 1&#…...

mac os 配置两个github账号
1. 清空git全局配置的username和email git config --global --unset user.name git config --global --unset user.emailgit config --list 可以查看是否清空了 2. 定义两个标识符,这两个标识符以后会被用来代替“github.com”来使用。 假设两个账号的邮箱地址分别是a@gmai…...
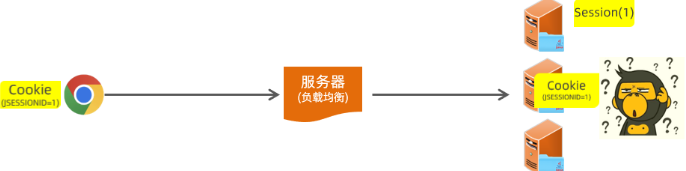
【SpringBoot】登录校验之会话技术、统一拦截技术
真正的登录功能应该是: 登陆后才能访问后端系统页面,不登陆则跳转登陆页面进行登陆。 当我们没有设置登录校验,可以直接通过修改地址栏直接进入管理系统内部,跳过登录页。而后端系统的增删改查功能,没有添加判断用户是…...
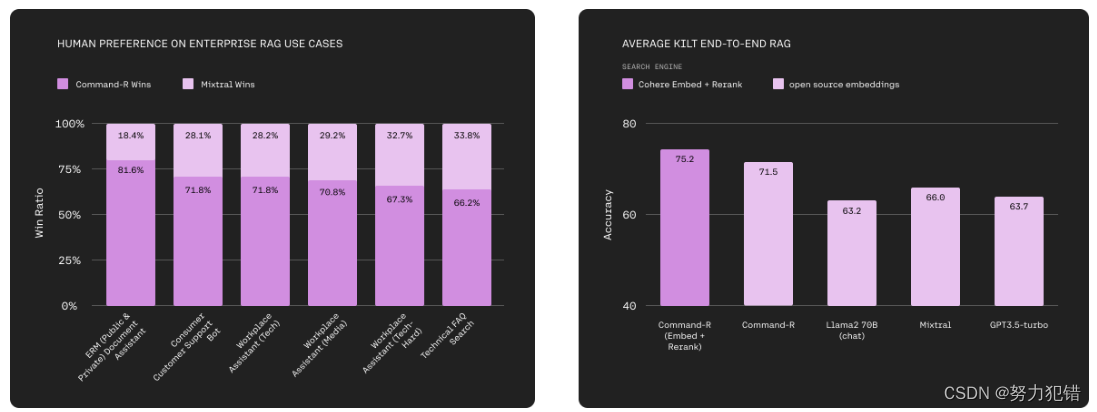
Cohere发布大模型Command-R:35B参数,128K上下文,高性能 RAG 功能,支持中文
引言 随着人工智能技术的快速发展,大型语言模型(LLM)在各行各业的应用日益广泛。Cohere最新发布的Command-R模型,以其35B参数和128K的长上下文能力,为企业级应用带来了前所未有的可能性。本文将深入探讨Command-R的核…...
vue+element 前端实现增删查改+分页,不调用后端
前端实现增删查改分页,不调用后端。 大概就是对数组内的数据进行增删查改分页 没调什么样式,不想写后端,当做练习 <template><div><!-- 查询 --><el-form :inline"true" :model"formQuery">&l…...
浅谈如何自我实现一个消息队列服务器(2)——实现 broker server 服务器
文章目录 一、实现 broker server 服务器1.1 创建一个SpringBoot项目1.2 创建Java类 二、硬盘持久化存储 broker server 里的数据2.1 数据库存储2.1.1 浅谈SQLiteMyBatis 2.1.2 如何使用SQLite 2.2 使用DataBaseManager类封装数据库操作2.3 文件存储消息2.3.1 存储消息时&#…...

html5cssjs代码 039 元素尺寸
html5&css&js代码 039 元素尺寸 一、代码二、解释 使用CSS来定义HTML元素的尺寸,并通过不同的计量单位来设置元素的大小。 一、代码 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><tit…...

Lucene的lukeall工具的下载和使用图解
Lucene的lukeall工具的下载和使用图解-CSDN博客 Releases DmitryKey/luke (github.com) 需要github的用户名和密码,没有是下载不成功的....

【题目】【网络系统管理】2019年全国职业技能大赛高职组计算机网络应用赛项H卷
极安云科专注职业教育技能竞赛培训4年,包含信息安全管理与评估、网络系统管理、网络搭建等多个赛项及各大CTF模块培训学习服务。本团队基于赛项知识点,提供完整全面的系统性理论教学与技能培训,成立至今持续优化教学资源与讲师结构࿰…...
OpenRewrite框架原理解析
目录 1. OpenRewrite处理流程概述 2. OpenRewrite访问者模式的应用 2.1 访问者模式简介 2.2 OpenRewrite框架如何应用访问者模式 2.2.1 抽象访问者&具体访问者 2.2.2 抽象元素&具体元素 3. LST无损语义树构造 4. 配方(Recipe)执行流程 …...

LeetCode_Java_递归系列(题目+思路+代码)
206.反转链表 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。 示例 1: 输入:head [1,2,3,4,5] 输出:[5,4,3,2,1]以此类推,直到反转结束返回头结点 class Solution {public ListNode rever…...

c++ 编译为WebAssembly时,怎么判断是release/debug环境?
我对这块研究不深 我的需求是把cpp代码编译为wasm的形式时,需要知道是debug/release 然而 尝试了一些办法 没有满足我的需求 尝试1: #include <iostream>bool isDebugMode() { #ifdef EMSCRIPTENbool isDebug EM_ASM_INT({return (typeof conso…...
脑电信号分类)
信号处理--基于正则化聚合的共空间模态(CSP)脑电信号分类
目录 理论 工具 方法实现 代码获取 参考文献 理论 传统的通用空间模式 (CSP) 是一种流行的算法,用于对脑电图 (EEG) 信号进行分类。本文主要介绍小样本设置 (SSS) 中 CSP 的正则化和聚合技术。传统的 CSP 基于样本协方差矩阵估计。如果训练样本数量较少,其脑电图分类的…...
 - 11 项目风险管理(高项)》)
【2024年5月备考新增】《软考真题分章练习(含答案解析) - 11 项目风险管理(高项)》
1 题目 1、风险可以从不同角度、根据不同的标准来进行分类。百年不遇的暴雨属于()。 A.不可预测风险 B.可预测风险 C.已知风险 D.技术风险 2、人们对风险事件都有一定的承受能力,当()时,人们愿意承担的风险越大。 A.项目活动投入的越多 B.项目的收益越大 C.个人、组织拥…...
【3GPP】【核心网】【4G】4G手机接入过程,手机附着过程(超详细)
1. 4G手机接入过程,手机附着过程 附着(Attach): 终端在PLMN中注册,从而建立自己的档案,即终端上下文 进行附着的三种情况: ①终端开机后的附着,初始附着 ②终端从覆盖盲区返回到…...

【LeetCode-46.全排列】
题目详情: 给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。 示例 1: 输入:nums [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]示例 2: …...

Allegro等长设置翻车实录:拓扑模板法的3个坑与手工PinPair的救赎
Allegro等长设计避坑指南:从拓扑模板到精准PinPair的实战演进在高速PCB设计中,等长匹配如同精密钟表里的齿轮啮合,差之毫厘便可能导致整个系统时序崩塌。当设计从简单的点对点结构升级到多负载复杂拓扑时,Allegro用户常陷入两种典…...
)
从测速到配置:一套完整的cFosSpeed网络加速保姆级教程(适用于小白)
从零开始掌握cFosSpeed:网络加速全流程实战指南对于经常进行在线游戏、视频会议或大文件传输的用户来说,网络延迟和带宽利用率低下往往是影响体验的关键痛点。cFosSpeed作为一款专业的网络流量优化工具,能够显著改善这些问题,但许…...

Linux服务器被挖矿木马劫持的五步应急处置指南
1. 这不是“中病毒”,是服务器被劫持成了矿机——先别慌,但必须立刻断网“服务器被黑客攻击,用来挖矿!”——这句话在运维圈里一出,比收到OOM告警还让人头皮发紧。它不像网页被挂马、数据库被拖库那样有明显业务影响&a…...

上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷?
更多请点击: https://intelliparadigm.com 第一章:上线前最后一道防线,DeepSeek代码审查如何帮你拦截87%的CVE类缺陷? 在软件交付生命周期末期,传统人工代码审计与通用SAST工具常因误报率高、上下文理解弱而漏检高危漏…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...
)
DeepSeek代码风格检查避坑指南(内部审计报告首次披露:37个被忽略的合规红线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码风格检查的合规性本质与审计背景 DeepSeek代码风格检查并非单纯的技术偏好约束,而是嵌入研发治理链条中的合规性控制节点。其本质是将编程实践与组织级安全策略、行业监管要求&…...

3步快速解密中兴光猫配置:ZET工具终极实战指南
3步快速解密中兴光猫配置:ZET工具终极实战指南 【免费下载链接】ZET-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/ze/ZET-Optical-Network-Terminal-Decoder 中兴光猫配置解密工具是每个网络管理员必备的神器!Z…...

BetterJoy终极指南:3分钟让你的Switch手柄变身PC游戏神器
BetterJoy终极指南:3分钟让你的Switch手柄变身PC游戏神器 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

Git Bash 中无法启动 Claude Code ?
最近需要在 git bash 中跑 Claude Code 。git bash 是随 git for windows 套件安装的,很久没更新了,结果启动 Claude Code 报错:Warning: no stdin data received in 3s, proceeding without it. If piping from a slow command, redirect st…...

天文时序数据分析:机器学习评估、半监督学习与无监督方法实战
1. 项目概述:当机器学习遇见星空 处理海量的天文时序数据,比如来自Kepler、TESS这些“巡天巨眼”的光变曲线,早已不是靠人眼一张张图去翻的时代了。数据量太大,噪声复杂,信号微弱,传统方法常常力不从心。这…...