Linux进程管理:(六)SMP负载均衡
文章说明:
-
Linux内核版本:5.0
-
架构:ARM64
-
参考资料及图片来源:《奔跑吧Linux内核》
-
Linux 5.0内核源码注释仓库地址:
zhangzihengya/LinuxSourceCode_v5.0_study (github.com)
1. 前置知识
1.1 CPU管理位图
内核对CPU的管理是通过位图(bitmap)变量来管理的,并且定义了possible、present、online和active这4种状态:
/* 位图类型变量 */
// 表示系统中有多少个可以运行(现在运行或者将来某个时间点运行)的 CPU 内核
#define cpu_possible_mask ((const struct cpumask *)&__cpu_possible_mask)
// 表示系统中有多少个正处于运行(online)状态的 CPU 内核
#define cpu_online_mask ((const struct cpumask *)&__cpu_online_mask)
// 表示系统中有多少个可处于运行状态的CPU内核,它们不一定都处于运行状态,有的CPU内核可能被热插拔了
#define cpu_present_mask ((const struct cpumask *)&__cpu_present_mask)
// 表示系统中有多少个活跃的 CPU 内核
#define cpu_active_mask ((const struct cpumask *)&__cpu_active_mask)
-
#define DECLARE_BITMAP(name,bits) \unsigned long name[BITS_TO_LONGS(bits)]typedef struct cpumask { DECLARE_BITMAP(bits, NR_CPUS); } cpumask_t;name[]:位图类型变量使用一个长整数类型数组name[],每位代表一个CPU。对于64位处理器来说,一个长整数类型数组成员只能表示64个CPU内核。内核配置中有一个宏CONFIG_NR_CPUS为8,那么只需要一个长整数类型数组成员可。struct cpumask:cpumask数据结构本质上是位图,内核通常使用cpumask的相关接口函数来管理CPU内核数量。
CPU位图的初始化流程如下图所示:

cpu_possible_mask通过查询系统DTS表或者ACPI表获取系统CPU内核数量cpu_present_mask等同于cpu_possible_maskcpu_active_mask是经过使能后的CPU内核数量
1.2 CPU调度域
根据系统的内存和高速缓存的布局,CPU域可分为如下几类:

Linux内核通过数据结构sched_domain_topology_level来描述CPU的层次关系,简称为SDTL:
// 用于描述 CPU 的层级关系
struct sched_domain_topology_level {sched_domain_mask_f mask; // 函数指针,用于指定某个 SDTL 的 cpumask 位图// sd_flags 函数指针里指定了该调度层级的标志位sched_domain_flags_f sd_flags; // 函数指针,用于指定某个 SDTL 的标志位int flags;int numa_level;struct sd_data data;
#ifdef CONFIG_SCHED_DEBUGchar *name;
#endif
};
另外,内核默认定义了一个数组default_topology[]来概括CPU物理域的层次结构:
// CPU 拓扑关系,从下往上
static struct sched_domain_topology_level default_topology[] = {
#ifdef CONFIG_SCHED_SMT // 超线程// cpu_smt_mask() 函数描述了 SMT 层级的 CPU 位图组成方式{ cpu_smt_mask, cpu_smt_flags, SD_INIT_NAME(SMT) },
#endif
#ifdef CONFIG_SCHED_MC // 多核// cpu_coregroup_mask() 函数描述了 MC 层级的 CPU 位图组成方式{ cpu_coregroup_mask, cpu_core_flags, SD_INIT_NAME(MC) },
#endif // 处理器// cpu_cpu_mask() 函数描述了 DIE 层级的 CPU 位图组成方式{ cpu_cpu_mask, SD_INIT_NAME(DIE) },{ NULL, },
};
从default_topology[]数组可知,系统默认支持DIE层级、SMT层级以及MC层级。另外,在调度域里划分调度组,使用sched_group来描述调度组,调度组是负载均衡调度的最小单位,在最低层级的调度域中,通常一个调度组描述一个CPU。
在一个支持NUMA架构的处理器中,假设它支持SMT技术,那么整个系统的调度域和调度组的关系如下图所示(它在默认调度层级中新增一个NUMA层级的调度域):

- DIE表示处理器封装,它是CPU拓扑结构中的一个层级,在多核处理器中,通常有多个物理处理器核心,组成一个封装
在Linux内核中使用sched_domain数据结构来描述调度层级。在超大系统中系统会频繁访问调度域数据结构,为了提升系统的性能和可扩展性,调度域sched_domain数据结构采用Per-CPU变量来构建:
// 描述调度层级
struct sched_domain {// 父调度域指针,顶层调度域必须为 null 终止struct sched_domain *parent;// 子调度域指针,底层调度域必须为 null 终止struct sched_domain *child;// groups 指向该调度域的平衡组链表struct sched_group *groups;// 最小平衡间隔(毫秒)unsigned long min_interval;// 最大平衡间隔(毫秒)unsigned long max_interval;...
};
下面举例来说明CPU调度域的拓扑关系,如下图所示,假设在一个4核处理器中,每个CPU拥有独立L1高速缓存且不支持超线程技术,4个物理CPU被分成两个簇Cluster0和Cluster1,每个簇包含两个物理CPU,簇中的CPU共享L2高速缓存

因为每个CPU内核只有一个运行线程,所以4核处理器没有SMT层级。簇由两个CPU组成,这两个CPU处于MC层级且是兄弟关系。整个处理器可以看作处于DIE层级,因此该处理器只有两个层级,即MC和DIE。根据上述原则,4核处理器的调度域和调度组的拓扑关系如下图所示:

在每个SDTL都为每个CPU分配了对应的调度域和调度组,以CPU0为例:
- 对于DIE层级,CPU0对应的调度域是domain_die_0,该调度域管辖着4个CPU并包含两个调度组,分别为group_die_0和group_die_1
- 调度组group_die_0管辖CPU0和CPU1
- 调度组group_die_1管辖CPU2和CPU3
- 对于MC层级,CPU0对应的调度域是domain_mc_0,该调度域中管辖着CPU0和CPU1并包含两个调度组,分别为group_mc_0和group_mc_1
- 调度组group_mc_0管辖CPU0
- 调度组group_mc_1管辖CPU1
除此以外,4核处理器的调度域和调度组还有两层关系,如下图所示:

综上所述,为了提升系统的性能和可扩展性,sched_domain数据结构采用Per-CPU变量来构建,这样可以减少CPU之间的访问竞争。而sched_group数据结构则是调度域内共享的。
2. LLC调度域
在负载均衡算法中,我们常常需要快速找到系统中最高层级的并且具有高速缓存共享属性的调度域。通常在—个系统,我们把最后一级高速缓存(Last Level Cache,LLC)称为LLC。在调度域标志位中,SD_SHARE_PKG_RESOURCE标志位用于描述高速缓存的共享属性。因此,在调度域层级中,包含LLC的最高一级调度域称为LLC调度域。在Linux内核中实现一组特殊用途的指针,用来指向LLC调度域,这些指针是Per-CPU变量。查找和设置LLC调度域是在update_top_cache_domain()函数中实现的。在select_idle_cpu()等函数中会使用到LLC 调度域。
// 指向 LLC 调度域
DEFINE_PER_CPU(struct sched_domain *, sd_llc);
// LLC 调度域包含多少个 CPU
DEFINE_PER_CPU(int, sd_llc_size);
// LLC 调度域第一个 CPU 的编号
DEFINE_PER_CPU(int, sd_llc_id);
DEFINE_PER_CPU(struct sched_domain_shared *, sd_llc_shared);
DEFINE_PER_CPU(struct sched_domain *, sd_numa);
DEFINE_PER_CPU(struct sched_domain *, sd_asym_packing);
// 指向第一个包含不同 CPU 架构的调度域,主要用于大/小核架构
DEFINE_PER_CPU(struct sched_domain *, sd_asym_cpucapacity);
DEFINE_STATIC_KEY_FALSE(sched_asym_cpucapacity);// 查找和设置 LLC 调度域
static void update_top_cache_domain(int cpu)
{...
}
3. 负载均衡
负载均衡机制从注册软中断开始,每次系统处理调度节拍时会检查当前是否需要处理负载均衡。负载均衡的流程如图所示:

为了使读者有更真切的理解,下文将根据流程图围绕源代码进行讲解这个过程:
load_balance()
// this_cpu 指当前正在运行的 CPU
// this_rq 表示当前就绪队列
// sd 表示当前正在做负载均衡的调度域
// idle 表示当前 CPU 是否处于 IDLE 状态
// continue_balancing 表示当前调度域是否还需要继续做负载均衡
static int load_balance(int this_cpu, struct rq *this_rq,struct sched_domain *sd, enum cpu_idle_type idle,int *continue_balancing)
{...struct lb_env env = {// 当前调度域.sd = sd,// 当前的 CPU,后面可能要把一些繁忙的进程迁移到该 CPU 上.dst_cpu = this_cpu,// 当前 CPU 对应的就绪队列.dst_rq = this_rq,// 当前调度域里的第一个调度组的 CPU 位图.dst_grpmask = sched_group_span(sd->groups),.idle = idle,// 本次最多迁移 32 个进程(sched_nr_migrate_break全局变量的默认值为 32).loop_break = sched_nr_migrate_break,// load_balance_mask 位图.cpus = cpus,.fbq_type = all,.tasks = LIST_HEAD_INIT(env.tasks),};// 把 sd 调度域管辖的 CPU 位图复制到 load_balance_mask 位图里cpumask_and(cpus, sched_domain_span(sd), cpu_active_mask);schedstat_inc(sd->lb_count[idle]);redo:// should_we_balance() 函数判断当前 CPU 是否需要做负载均衡if (!should_we_balance(&env)) {*continue_balancing = 0;goto out_balanced;}// 查找该调度域中最繁忙的调度组group = find_busiest_group(&env);if (!group) {schedstat_inc(sd->lb_nobusyg[idle]);goto out_balanced;}// 在刚才找到的最繁忙的调度组中查找最繁忙的就绪队列busiest = find_busiest_queue(&env, group);if (!busiest) {schedstat_inc(sd->lb_nobusyq[idle]);goto out_balanced;}...// env.src_cpu 指向最繁忙的调度组中最繁忙的就绪队列中的 CPUenv.src_cpu = busiest->cpu;// env.src_rq 指向最繁忙的就绪队列env.src_rq = busiest;ld_moved = 0;if (busiest->nr_running > 1) {...// detach_tasks() 函数遍历最繁忙的就绪队列中所有的进程,找出适合被迁移的进程,然后让这些// 进程退出就绪队列。cur_ld_moved 变量表示已经迁出了多少个进程cur_ld_moved = detach_tasks(&env);...if (cur_ld_moved) {// attach_tasks() 函数把刚才从最繁忙就绪队列中迁出的进程都迁入当前 CPU 的就绪队列中attach_tasks(&env);ld_moved += cur_ld_moved;}...// 由于进程设置了 CPU 亲和性,不能迁移进程到 dst_cpu,因此还有负载没迁移完成,需要换一个新的// dst_cpu 继续做负载迁移if ((env.flags & LBF_DST_PINNED) && env.imbalance > 0) {...goto more_balance;}...}...
}
load_balance()->should_we_balance():
// 判断当前 CPU 是否需要做负载均衡
static int should_we_balance(struct lb_env *env)
{// sg 指向调度域中的第一个调度组struct sched_group *sg = env->sd->groups;...// 查找当前调度组是否有空闲 CPU,如果有空闲 CPU,那么使用变量 balance_cpu 记录该 CPUfor_each_cpu_and(cpu, group_balance_mask(sg), env->cpus) {if (!idle_cpu(cpu))continue;balance_cpu = cpu;break;}// 查找该调度组有哪些 CPU 适合做负载均衡// 若调度组里有空闲 CPU,则优先选择空闲 CPU// 调度组里没有空闲 CPU,则选择调度组的第一个 CPUif (balance_cpu == -1)balance_cpu = group_balance_cpu(sg);// 然后判断适合做负载均衡的 CPU 是否为当前 CPU,若为当前 CPU,则 should_we_balance()函数返回true,表示可以做负载均衡return balance_cpu == env->dst_cpu;
}
load_balance()->find_busiest_group():
// 查找该调度域中最繁忙的调度组
static struct sched_group *find_busiest_group(struct lb_env *env)
{...// 初始化 sd_lb_stats 结构体init_sd_lb_stats(&sds);// 更新该调度域中负载的相关统计信息update_sd_lb_stats(env, &sds);...// 如果没有找到最繁忙的调度组或者最繁忙的组中没有正在运行的进程,那么跳过该调度域if (!sds.busiest || busiest->sum_nr_running == 0)goto out_balanced;// 计算该调度域的平均负载sds.avg_load = (SCHED_CAPACITY_SCALE * sds.total_load)/ sds.total_capacity;// 如果最繁忙的调度组的组类型是 group_imbalanced,那么跳转到 force_balance 标签处if (busiest->group_type == group_imbalanced)goto force_balance;...// 若本地调度组的平均负载比刚才计算出来的最繁忙调度组的平均负载还要大,那么不需要做负载均衡if (local->avg_load >= busiest->avg_load)goto out_balanced;// 若本地调度组的平均负载比整个调度域的平均负载还要大,那么不需要做负载均衡if (local->avg_load >= sds.avg_load)goto out_balanced;// 如果当前 CPU 处于空闲状态,最繁忙的调度组里的空闲 CPU 数量大于本地调度组里的空闲 CPU 数量,说明不需要做负载均衡if (env->idle == CPU_IDLE) {if ((busiest->group_type != group_overloaded) &&(local->idle_cpus <= (busiest->idle_cpus + 1)))goto out_balanced;// 如果当前 CPU 不处于空闲状态,那么比较本地调度组的平均量化负载和最繁忙调度组的平均量化负载,这里使用了 imbalance_pct// 系数,它在 sd_init() 函数中初始化,默认值为125。若本地调度组的平均量化负载大于最繁忙组的平均量化负载,说明该调度组不// 忙,不需要做负载均衡。} else {if (100 * busiest->avg_load <=env->sd->imbalance_pct * local->avg_load)goto out_balanced;}force_balance:env->src_grp_type = busiest->group_type;// 根据最繁忙调度组的平均量化负载、调度域的平均量化负载和本地调度组的平均量化负载来计算该调度域需要迁移的负载不均衡值calculate_imbalance(env, &sds);// 返回最忙的调度组return env->imbalance ? sds.busiest : NULL;out_balanced:env->imbalance = 0;return NULL;
}
load_balance()->find_busiest_queue():
for_each_cpu_and()遍历该调度组里所有的CPU- 通过就绪队列的量化负载(runnable_load_avg)与CFS额定算力(cpu_capacity)的乘积来进行比较。使用
weighted_cpuload()来获取cfs_rq->avg.runnable_load_avg的值,通过capacity_of()来获取cpu_capacity的值。这里要考虑不同处理器架构计算能力的不同对处理器负载的影响。
注意,数据结构rq中的cpu_capacity_orig成员指的是CPU的额定算力,而cpu_capacity成员指的是CFS就绪队列的额定算力,通常CFS额定算力最大能达到CPU额定算力的80%。
load_balance()->detach_tasks():
// detach_tasks() 函数遍历最繁忙的就绪队列中所有的进程,找出适合被迁移的进程,
// 然后让这些进程退出就绪队列。返回值表示已经迁出了多少个进程
static int detach_tasks(struct lb_env *env)
{...// env->imbalance 表示还有多少不均衡的负载需要迁移if (env->imbalance <= 0)return 0;// while 循环遍历最繁忙的就绪队列中所有的进程while (!list_empty(tasks)) {...// 在can_migrate_task()函数中判断哪些进程可以迁移,哪些进程不能迁移。// 不适合迁移的原因:// 一是进程允许运行的CPU位图的限制(cpus_allowed)// 二是当前进程正在运行// 三是热高速缓存(cache-hot)的问题// 四如果进程负载的一半大于要迁移负载总量(env->imbalance),则该进程也不适合迁移if (!can_migrate_task(p, env))goto next;load = task_h_load(p);if (sched_feat(LB_MIN) && load < 16 && !env->sd->nr_balance_failed)goto next;if ((load / 2) > env->imbalance)goto next;// detach_task()函数让进程退出就绪队列,然后设置进程的运行CPU为迁移目的地CPU,并设置p->on_rq为// TASK_ON_RQ_MIGRARINGdetach_task(p, env);// 把要迁移的进程添加到env->tasks链表中list_add(&p->se.group_node, &env->tasks);detached++;// 递减不均衡负载总量 env->imbalanceenv->imbalance -= load;...}return detached;
}
load_balance()->attach_tasks():
// 把detach_tasks()分离出来的进程,重新添加到目标就绪队列中
static void attach_tasks(struct lb_env *env)
{...// 遍历env->tasks链表while (!list_empty(tasks)) {...// 把进程添加到目标CPU的就绪队列中attach_task(env->dst_rq, p);}...
}
相关文章:
Linux进程管理:(六)SMP负载均衡
文章说明: Linux内核版本:5.0 架构:ARM64 参考资料及图片来源:《奔跑吧Linux内核》 Linux 5.0内核源码注释仓库地址: zhangzihengya/LinuxSourceCode_v5.0_study (github.com) 1. 前置知识 1.1 CPU管理位图 内核…...

计算机专业学生的成长之路:超越课堂的自我提升策略
🌟 前言 欢迎来到我的技术小宇宙!🌌 这里不仅是我记录技术点滴的后花园,也是我分享学习心得和项目经验的乐园。📚 无论你是技术小白还是资深大牛,这里总有一些内容能触动你的好奇心。🔍 &#x…...
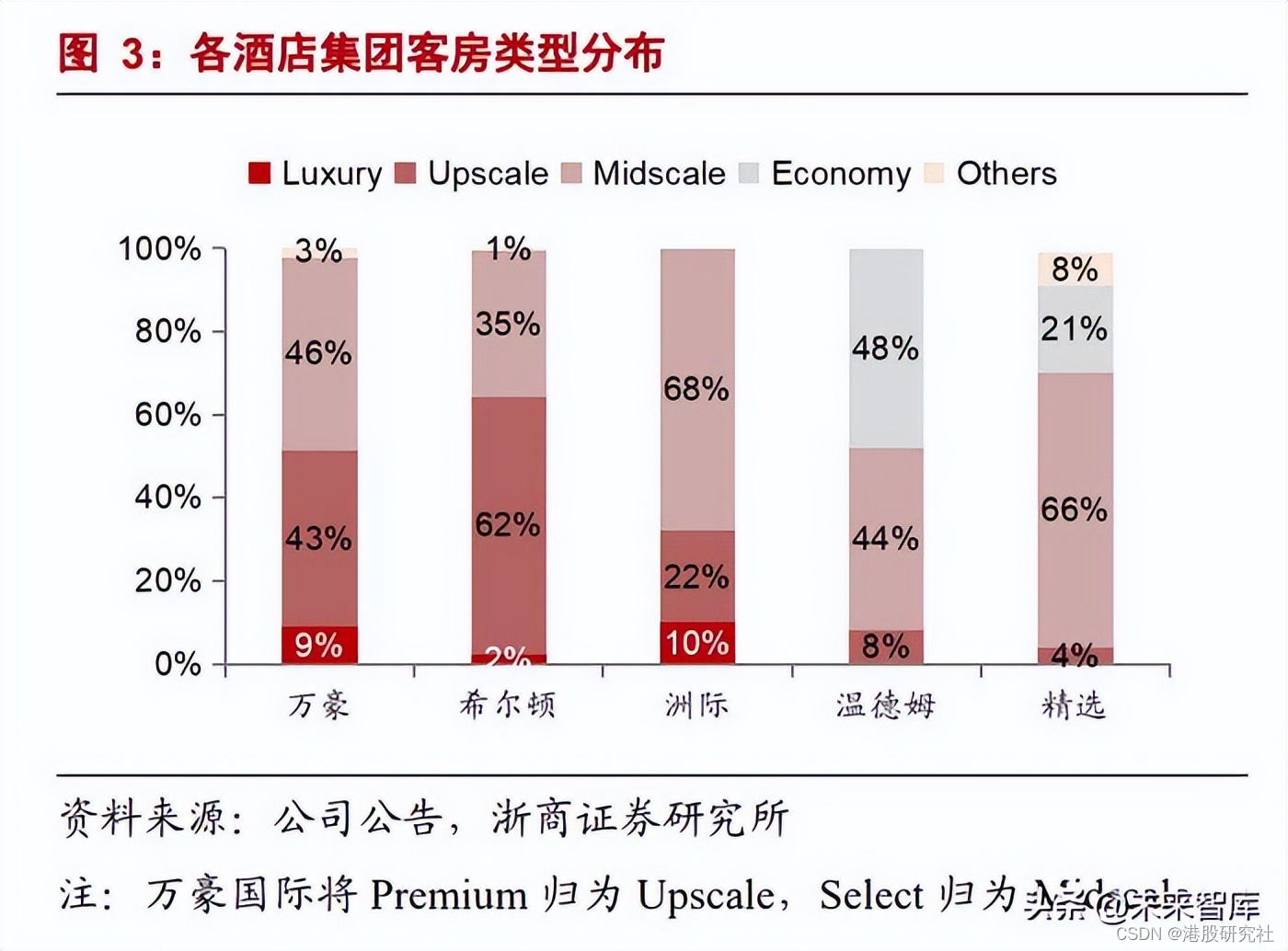
财报解读:“高端化”告一段落,华住开始“全球化”?
2023年旅游业快速复苏,全球酒店业直接受益,总体运营指标大放异彩,多数酒店企业都实现了营收上的明显增长,身为国内龙头的华住也不例外。 3月20日晚,华住集团发布2023年四季度及全年财报。整体实现扭亏为盈,…...

Wifi环境下Unity开发iOS应用启动后HTTPS请求未弹出是否允许无线数据使用数据的弹窗
情况说明 笔者项目在首次启动,登录界面点击登录按钮会先HTTPS请求创建帐号,但是在WIFI网络下,请求后一直提示网络连接失败。但是切换到流量包后,则会弹出"无线数据"使用数据的弹窗,选择允许后则可顺利进入。…...
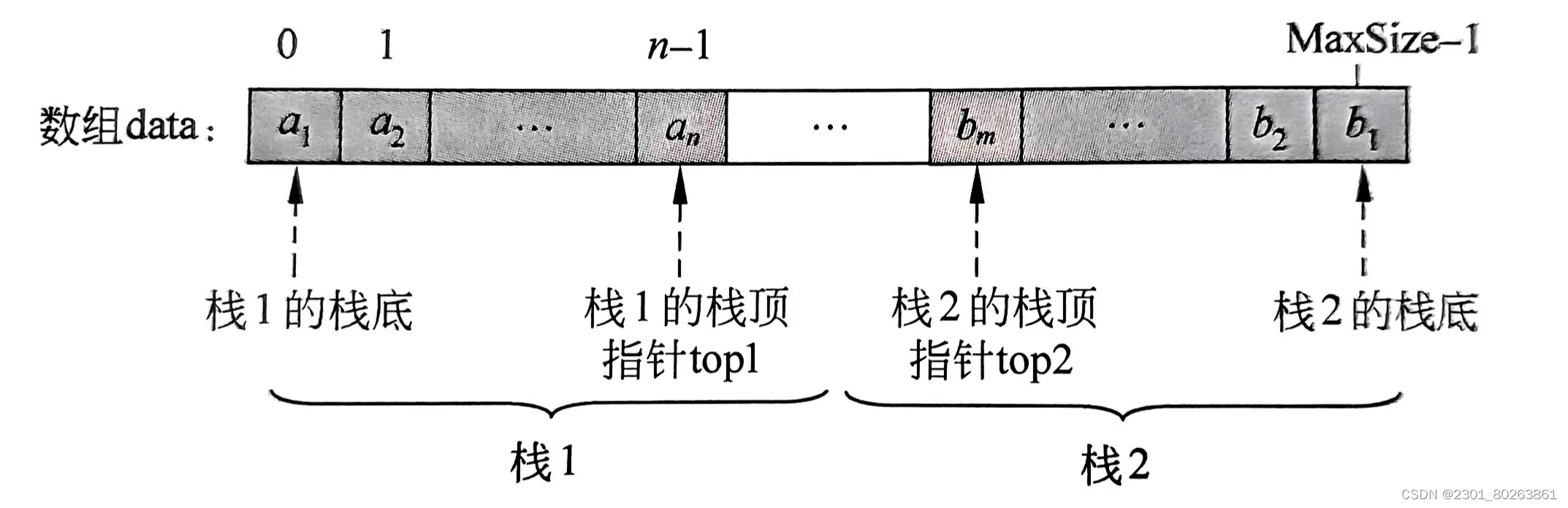
数据结构的概念大合集03(栈)
概念大合集03 1、栈1.1 栈的定义和特点1.2 栈的基础操作1.3 栈的顺序存储1.3.1 顺序栈1.3.2 栈空,栈满,进栈,出栈的基本思想1.3.3 共享栈1.3.3.1 共享栈的4要素 1.4 栈的链式存储1.4.1 链栈的实现1.4.2 链栈的4个要素 1、栈 1.1 栈的定义和特…...
C++ 哈希表
目录 两数之和 面试题 01.02. 判定是否互为字符重排 存在重复元素 存在重复元素 II 字母异位词分组 两数之和 1. 两数之和 思路1:两层for循环 思路2:逐步添加哈希表 思路3:一次填完哈希表 如果一次填完,那么相同元素的值&…...
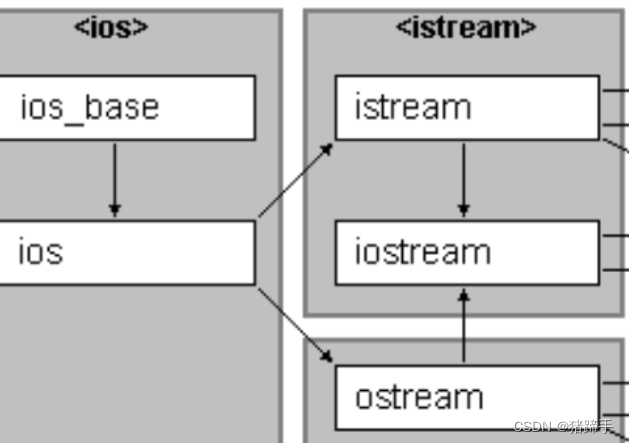
C++之继承详解
一.继承基础知识 继承定义: 继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保 持原有类特性的基础上进行扩展,增加功能,这样产生新的类,称派生类。继承呈现了面向对象 程序设…...

C#装箱和拆箱
一,装箱 装箱是指将值类型转化为引用类型。 代码如下: 装箱的内部过程 当值类型需要被装箱为引用类型时,CLR(Common Language Runtime)会为值类型分配内存,在堆上创建一个新的对象。值类型的数据会被复…...
企业用大模型如何更具「效价比」?百度智能云发布5款大模型新品
服务8万企业用户,累计帮助用户精调1.3万个大模型,帮助用户开发出16万个大模型应用,自2023年12月以来百度智能云千帆大模型平台API日调用量环比增长97%...从一年前国内大模型平台的“开路先锋”到如今的大模型“超级工厂”,百度智能…...
linux 外部GPIO Watchdog驱动适配
前言 文章描述, 利用外部gpio看门狗芯片驱动芯片的复位功能。 芯片:RK3568 平台: Linux ubuntu.lan 4.19.232 #27 SMP Sat Sep 23 13:43:49 CST 2023 aarch64 aarch64 aarch64 GNU/Linux 硬件接线图示 看门狗芯片采用GPIO喂狗,W…...

活动回顾 | 走进华为向深问路,交流数智办公新体验
3月20日下午,“企业数智办公之走进华为”交流活动在华为上海研究所成功举办。此次活动由上海恒驰信息系统有限公司主办,华为云计算技术有限公司和上海利唐信息科技有限公司协办,旨在通过对企业数字差旅和HR数智化解决方案的交流,探…...
【Java】Oracle发布Java22最新版本
甲骨文(ORACLE)已经于2023年3月19日正式发布了最新版本的JDK,版本号:22 根据官方声明,Java 22 (Oracle JDK 22) 在性能、稳定性和安全性方面进行了数千种改进,包括对Java 语言、其API 和性能,以…...

Vue reactive函数的使用
let searchForm reactive({}); let data reactive({ isAdmin: true, isshowAccount: true }); reactive 是什么? reactive 是 Vue 3 Composition API 中的一个函数,用于创建一个包含响应式数据的对象。在 Vue 2.x 中,我们通常使用 data 选项…...

unity自动引用生成
using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Text; using UnityEditor; using UnityEngine; using UnityEngine.UI;/// <summary> /// 模板脚本生成 /// </summary> public class ScriptCreater : EditorW…...

【Linux系统】线程互斥与同步
目录 一.几个概念 二.线程互斥 1.定义并初始化锁 2.加锁 3.解锁 4.销毁锁 三.互斥锁的本质 1.xchg的原子性 2.加锁的过程 3.解锁的过程 四.可重入VS线程安全 五.死锁 1.死锁的概念 2.具体实例 3.死锁产生的四个必要条件 4.解决或避免死锁 六.线程同步 七.…...

武汉星起航引领跨境电商新潮流,深耕亚马逊打造全方位合作新模式
在全球化的浪潮下,跨境电商已成为连接各国市场的重要桥梁,为无数企业带来了前所未有的发展机遇。在这一领域,武汉星起航电子商务有限公司以其独特的战略眼光和实战经验,成为引领行业发展的佼佼者。公司自2017年起便深耕亚马逊平台…...
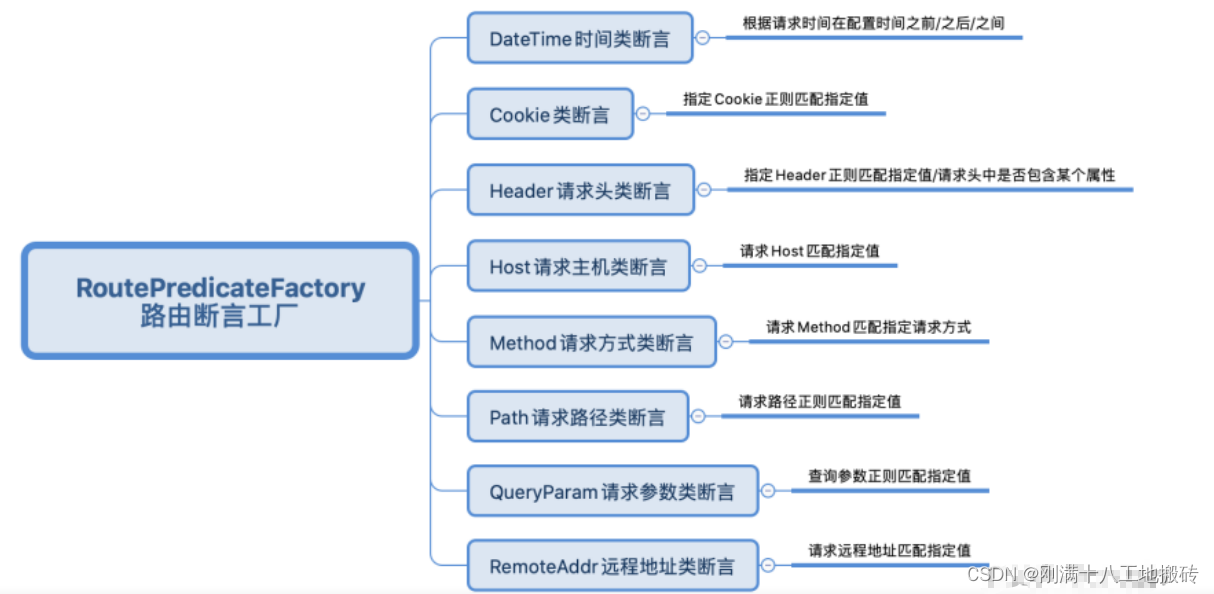
GateWay路由规则
Spring Cloud GateWay 帮我们内置了很多 Predicates功能,实现了各种路由匹配规 则(通过 Header、请求参数等作为条件)匹配到对应的路由 1 时间点后匹配 server:port: 8888 spring:application:name: gateway-servicecloud:nacos:discovery:…...

shell脚本基础改造
一、基础的shell脚本格式 #!/bin/bash 2 #3 #********************************************************************4 #Author: LJH5 #QQ: 2…...

静态综合实验
一,1.搭建拓扑结构并启动。 2.根据题意得该图需要14个网段,根据192.168.1.0/24划分子网段,如下: 划分完如图所示: 二、配置IP地址 R1路由器: 1.进入系统视图并改名. 2.接口配置IP地址:…...
Spring Web MVC入门(6)
应用分层 在开发的过程中, 我们会发现, 程序的代码有时会很"杂乱", 如果后面的项目更大了, 那就会更加地杂乱无章(文件乱, 代码内容乱). 也基于此, 接下来让我们来学习一下应用分层. 也类似于公司的组织架构 公司初创阶段, 一个人身兼数职, 既做财务, 又做人事,还有…...

ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程
ZjDroid命令大全:从DEX内存dump到Lua脚本注入的完整教程 【免费下载链接】ZjDroid Android app dynamic reverse tool based on Xposed framework. 项目地址: https://gitcode.com/gh_mirrors/zj/ZjDroid ZjDroid是一款基于Xposed框架的Android应用动态逆向分…...
两两交换链表中的节点)
力扣HOT100(30)两两交换链表中的节点
链表的交换要注意 “链表不断链”。前驱和后继都要连着迭代法(必学死磕!O (n) 时间,O (1) 空间)1. 为什么必须用虚拟头节点?因为交换后链表的头节点会变! 比如示例 1 中,原来的头是 1࿰…...

基于MaixCam的延时摄影系统:从硬件选型到Python编程全解析
1. 项目概述:用MaixCam打造你的专属延时摄影工坊延时摄影,这个听起来有点专业、甚至带点“魔法”色彩的词,其实离我们并不遥远。想想看,把一朵花从含苞到绽放的几天时间,压缩成十几秒的惊艳绽放;或者把一座…...
)
Mysql:事务管理(中)
在前面的章节中,我们提到了 MVCC(多版本并发控制),它巧妙地通过“版本快照”解决了“读-写”冲突,实现了非阻塞读。但如果两个事务同时执行 UPDATE 操作修改同一行数据,即 写-写(Write-Write&am…...

AI圈内火热的Agent、MCP、Skill、CLI是啥?用装修房子讲透,看完秒懂
本文用装修房子的比喻,详细解释了AI领域的四个核心概念:Agent如同会自主规划任务的私人助理;MCP是AI与外部工具数据的统一接口,类似USB-C;Skill是指导AI按标准操作执行的手册;CLI则是不依赖图形界面的命令行…...

终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理
终极Chrome画中画扩展:如何在浏览器中实现高效视频多任务处理 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension 想要在浏览网页、处理文档的同时继续观看视频内容吗…...

打造XBEE封装BLE112蓝牙模块:硬件设计、射频布局与调试全攻略
1. 项目概述:为什么我们需要一个“XBEE格式”的蓝牙模块?在嵌入式开发和物联网项目中,无线通信模块的选择往往决定了项目的成败。对于很多工程师和创客来说,Silicon Labs(芯科科技)的BLE112/113模块是蓝牙4…...

【审计专栏】【财务领域】 第四十九篇 人在企业中的核心资产和核心利益01
编号 类型 企业 (行业/企业产品/企业利益链/生态位与层级) 业务领域 企业性质 企业中人的角色/岗位/利益矩阵 人在企业中的核心资产/附属资产 资产的业务-财务数学模型及数字/数值 关联知识 1 核心经营性资产(如IP、数据、品牌) 行业:人工智能 产品:工业视觉检…...

GEO优化可以覆盖哪些搜索平台
这是一个非常现实的问题。企业投放资源做GEO,当然希望覆盖面越广越好。那么GEO优化到底能覆盖哪些平台?覆盖到什么程度?不同平台的GEO逻辑有什么差异?GEO平台覆盖的三个层级第一层级:通用大模型AI平台(核心…...

AhMyth位置跟踪:GPS定位与地理围栏技术深度解析
AhMyth位置跟踪:GPS定位与地理围栏技术深度解析 【免费下载链接】AhMyth Cross-Platform Android Remote Administration Tool | The only maintained version of AhMyth on github | A revival of the original repository at https://GitHub.com/AhMyth/AhMyth-An…...