详解llamaindex
什么是LlamaIndex
LlamaIndex是一个用于LLM应用程序的数据框架,用于注入、结构化,并访问私有或特定领域的数据。
入门教程
简单使用
# Linux
export OPENAI_API_KEY=xxxwindows
set OPENAI_API_KEY=xxx# 代码中加入
API_SECRET_KEY = "xxx"
BASE_URL = "xxx"
os.environ["OPENAI_API_KEY"] = API_SECRET_KEY
os.environ["OPENAI_API_BASE"] = BASE_URL
from llama_index_core import VectorStoreIndex, SimpleDirectoryReader#加载数据并构建索引
documnets = SimoleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)#查询数据
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)由于每次运行都需要构建所以比较费时,可以保存第一次的索引
#检查索引是否存在
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):#在这里重新加载数据并构建索引documents = SimpleDirectoryReader("data").load_data()index = VectorStoreIndex.from_documents(documents)index.storage_context.persist(persist_dir=PERSIST_DIR)
else:#从存储中加载索引storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)index = load_index_from_storage(storage_context)#查询数据
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
检索增强生成 (RAG)
原理
LlamaIndex 帮助构建 LLM 驱动的,基于个人或私域数据的应用。RAG(Retrieval Augmented Generation) 是 LlamaIndex 应用的核心概念。
RAG 中,您的数据被加载并准备用于查询或“索引”。用户查询作用于索引,索引将数据筛选到最相关的上下文。然后,此上下文和您的查询会随着提示一起转到 LLM,LLM 会提供响应。

文档分块
from llama_index.core import SettingsSettings.chunk_size = 512from llama_index.core.node_parser import SentenceSplitterindex = VectorStoreIndex.from_documents(documents,transfromations=[SentnceSplitter(chunk_size=512)]
)
不同向量存储
pip install llama_index_vector_stores_chromaimport chromadb
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import StorageContextchroma_client = chromadb.PersistentClient() #建立交互客户端
chroma_collction = chroma_client.create_collection("quickstart") #创建一个集合j
vector_store = ChromaVectorStore(chroma_collection=chroma_collction) #实例化集合
storage_context = StorageContext.from_defaults(vector_store=vector_store) #完成配置存储上下文from llama_index.core import VectorStoreIndex,SimpleDirectoryReaderdocuments = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context
)
query_engine = index.as_query_engine()
response = query_engine.query("what did the author do growing up?")
peint(response)
查询检索上下文
from llama_index_core import VectorStoreIndex, SimpleDirectoryReaderdocumnets = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
#检索器配置为返回前 5 个最相似的文档
query_engine = index.as_query_engine(similarity_top_k=5)
response = query_engine.query("what did the author do growing up?")
peint(response)
使用不同LLM
from llama_index_core import Settings
from llama_index.llms.ollama import OllamaSettings.llm = Ollama(model="mistral", request_timeout=60.0)
index.as_query_engine(llm=Ollama(model="mistral",request_timeout=60.0))不同的响应模式
from llama_index.core import VectorStoreIndex, SimpleDirectoryReaderdocuments = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(response_mode="tree_summarize")
response = query_engine.query("What did the author do growing up?")
print(response)
流式输出响应
from llama_index.core import VectorStoreIndex, SimpleDirectoryReaderdocuments = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(streaming=True)
response = query_engine.query("What did the author do growing up?")
response.print_response_stream()
聊天机器人
from llama_index.core import VectorStoreIndex, SimpleDirectoryReaderdocuments = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_chat_engine()
response = query_engine.chat("What did the author do growing up?")
print(response)response = query_engine.chat("Oh interesting, tell me more.")
print(response)
核心概念
RAG
RAG,也称为检索增强生成,是利用个人或私域数据增强LLM的一种范式,它包含两个阶段:
1.索引
构建知识库
2.查询
从知识库检索相关上下文信息,以辅助LLM回答问题。
索引阶段
LlamaIndex 通过提供 Data connectors(数据连接器) 和 Indexes (索引) 帮助开发者构建知识库。
该阶段会用到如下工具或组件:
- Data connectors
数据连接器。它负责将来自不同数据源的不同格式的数据注入,并转换为LlamaIndex支持的文档(Document)表现形势,其中包含了文本和元数据。
- Documents/Nodes
Document是LlamaIndex中容器的概念,它可以包含任何数据源,包括PDF文档、API响应、数据库的数据。
Node是LlamaIndex中数据的最小单元,代表了一个Document的分块。它还包含了元数据以及与其他Node的关系信息。这使得更精确的检索变为可能。
- Data indexs
LlamaIndex 提供便利的工具,帮助开发者为注入的数据建立索引,使得未来的检索简单而高效。
最常用的索引是向量存储索引 - VectorStoreIndex。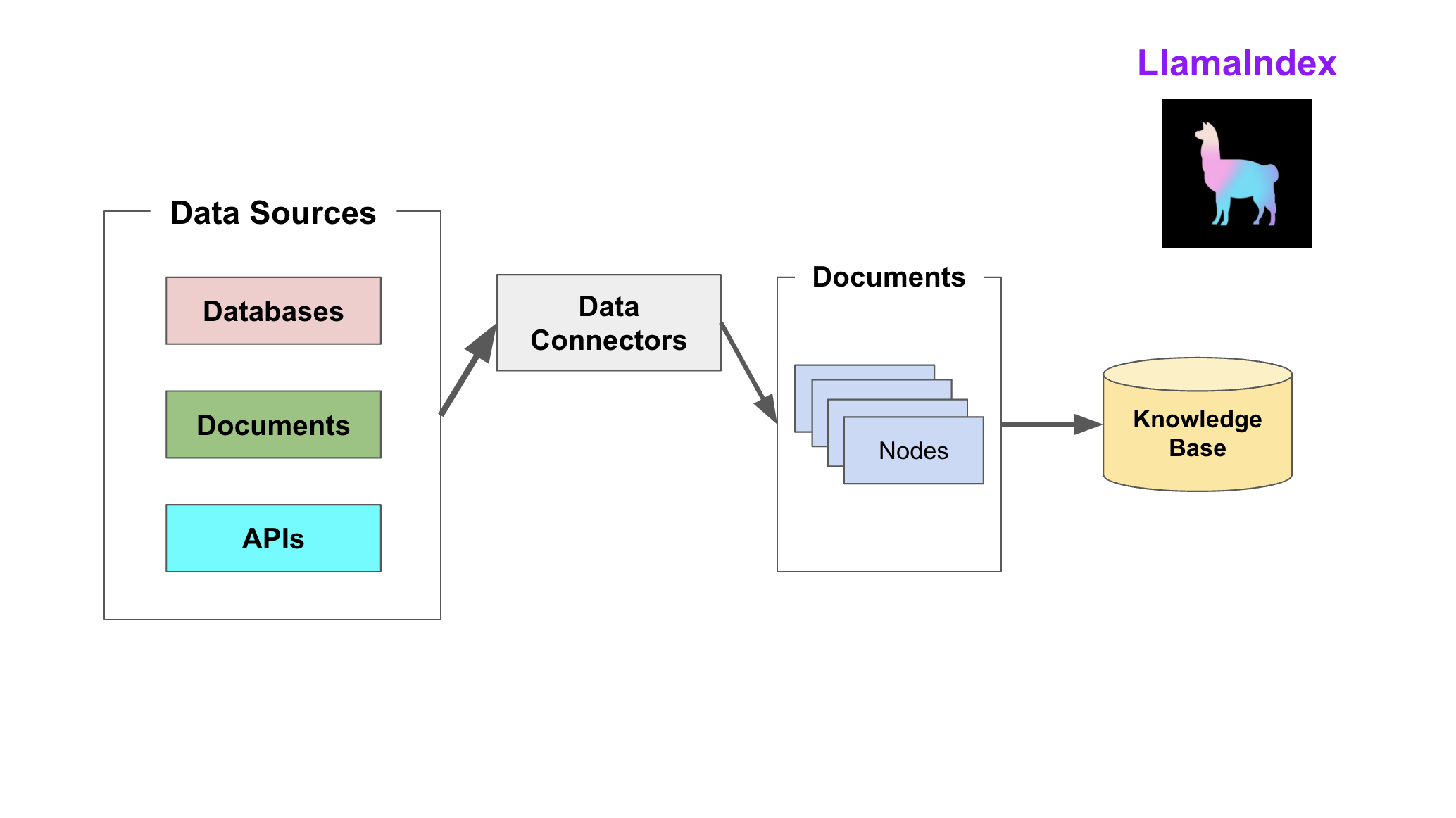
查询阶段
在查询阶段,RAG 管道根据的用户查询,检索最相关的上下文,并将其与查询一起,传递给 LLM,以合成响应。这使 LLM 能够获得不在其原始训练数据中的最新知识,同时也减少了虚构内容。该阶段的关键挑战在于检索、编排和基于知识库的推理。
LlamaIndex 提供可组合的模块,帮助开发者构建和集成 RAG 管道,用于问答、聊天机器人或作为代理的一部分。这些构建块可以根据排名偏好进行定制,并组合起来,以结构化的方式基于多个知识库进行推理。
该阶段的构建块包括:
- Retrievers检索器。它定义如何高效地从知识库,基于查询,检索相关上下文信息。
- Node PostprocessorsNode后处理器。它对一系列文档节点(Node)实施转换,过滤,或排名。
- Response Synthesizers响应合成器。它基于用户的查询,和一组检索到的文本块(形成上下文),利用 LLM 生成响应。
RAG管道包括:
- Query Engines查询引擎 - 端到端的管道,允许用户基于知识库,以自然语言提问,并获得回答,以及相关的上下文。
- Chat Engines聊天引擎 - 端到端的管道,允许用户基于知识库进行对话(多次交互,会话历史)。
- Agents代理。它是一种由 LLM 驱动的自动化决策器。代理可以像查询引擎或聊天引擎一样使用。主要区别在于,代理动态地决定最佳的动作序列,而不是遵循预定的逻辑。这为其提供了处理更复杂任务的额外灵活性。
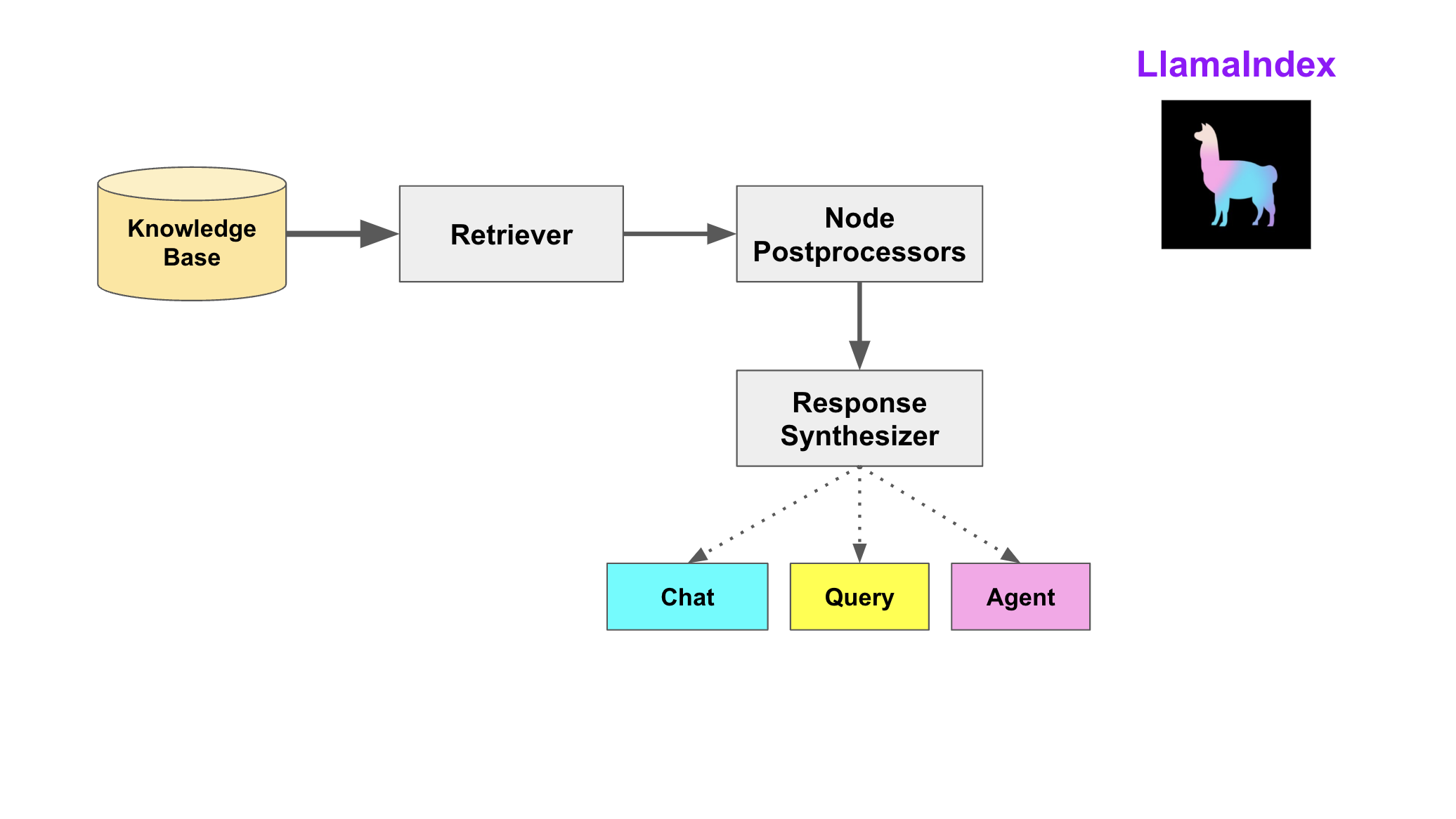
Q&A模式
语义搜索
LlamaIndex 最基本的示例用法是通过语义搜索。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReaderdocuments = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documnets)
query_engine = index.as_query_engine()
response = query_engine.query("what did the author do growing up?")
print(response)
综述
摘要查询需要 LLM 遍历许多(如果不是大多数)文档才能合成答案。 例如,摘要查询可能如下所示:
- “这本文本集的摘要是什么?”
- “给我总结一下X在公司的经历。”
通常,摘要索引适用于此用例。默认情况下,摘要索引会遍历所有数据。
从经验上讲,设置也会导致更好的汇总结果。response_mode=“tree_summarize”
index = SummaryIndex.from_documents(documents)query_engine = index.as_query_engine(response_mode="tree_summarize")
response = query_engine.query("摘要查询")
代码解读
import chromadb
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import StorageContext,SummaryIndex
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.core import Settings
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core import SimpleNodeParser,QueryEngineTool,ToolMetadata,OpenAIAgent,FnRetrieverOpenAIAgent
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core import ObjectIndex, SimpleToolNodeMapping#设置模型
Settings.llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
Settings.embed_model = OpenAIEmbedding()#创建向量存储
chroma_client = chromadb.PersistentClient() # 建立交互客户端
chroma_collction = chroma_client.create_collection("quickstart1") # 创建一个集合
vector_store = ChromaVectorStore(chroma_collection=chroma_collction) # 实例化集合
storage_context = StorageContext.from_defaults(vector_store=vector_store) # 完成配置存储上下文#分块pdf并建立索引
documents = SimpleDirectoryReader("data").load_data()
Settings.chunk_size = 512
index = VectorStoreIndex.from_documents(documents, transfromations=[SentenceSplitter(chunk_size=512)],storage_context=storage_context
)#创建节点解析器
node_parser = SimpleNodeParser.from_defaults(chunk_size=512)
nodes = node_parser.get_nodes_from_documents(documents)#创建摘要索引
summary_index = SummaryIndex(nodes)vector_query_engine = index.as_query_engine()
summary_query_engine = summary_index.as_query_engine()#创建查询引擎工具
query_engine_tools = [QueryEngineTool(query_engine=vector_query_engine,metadata=ToolMetadata(name="vector_tool",description=("这是一个关于电子银行承兑汇票的票据回单"),),),QueryEngineTool(query_engine=summary_query_engine,metadata=ToolMetadata(name="summary_tool",description=("这是一个关于电子银行承兑汇票的票据回单"),),),
]
function_llm = OpenAI(model="gpt-4")
agent = OpenAIAgent.from_tools(query_engine_tools,llm=function_llm,verbose=True,system_prompt=f"""\你是专门为回答有关问题而设计的代理。在回答问题时,您必须使用至少一种工具;不依赖于先验知识。\""",
)all_tools = []
wiki_summary = ("你是专门为回答有关问题而设计的代理。""在回答问题时,您必须使用至少一种工具;不依赖于先验知识。\n"
)
doc_tool = QueryEngineTool(query_engine=agent,metadata=ToolMetadata(name="bank_tool",description=wiki_summary,),
)
all_tools.append(doc_tool)tool_mapping = SimpleToolNodeMapping.from_objects(all_tools)
obj_index = ObjectIndex.from_objects(all_tools,tool_mapping,VectorStoreIndex,
)top_agent = FnRetrieverOpenAIAgent.from_retriever(obj_index.as_retriever(similarity_top_k=3),system_prompt=""" \
你是一个被设计用来回答关于一组给定城市的查询的代理。
请始终使用提供的工具来回答问题。不依赖于先验知识。\
""",verbose=True,
)
# 定义了一个“简单”的RAG管道,它将所有文档转储到单个矢量索引集合中。设置top_k = 4
base_index = VectorStoreIndex(nodes)
base_query_engine = base_index.as_query_engine(similarity_top_k=4)
#对比单个文档的QA /摘要到多个文档的QA /摘要
response = top_agent.query("给我讲讲波士顿的艺术和文化吧")
print(response)
response = base_query_engine.query("给我讲讲波士顿的艺术和文化吧"
)
print(str(response))# 定义了一个“复杂”的RAG管道,它将文档分块并建立索引,然后使用OpenAI模型进行回答。设置top_k = 4
query_engine = index.as_query_engine(response_mode="tree_summarize",agent=agent)
response = query_engine.query("这是一个关于什么的么文件?")
print(response)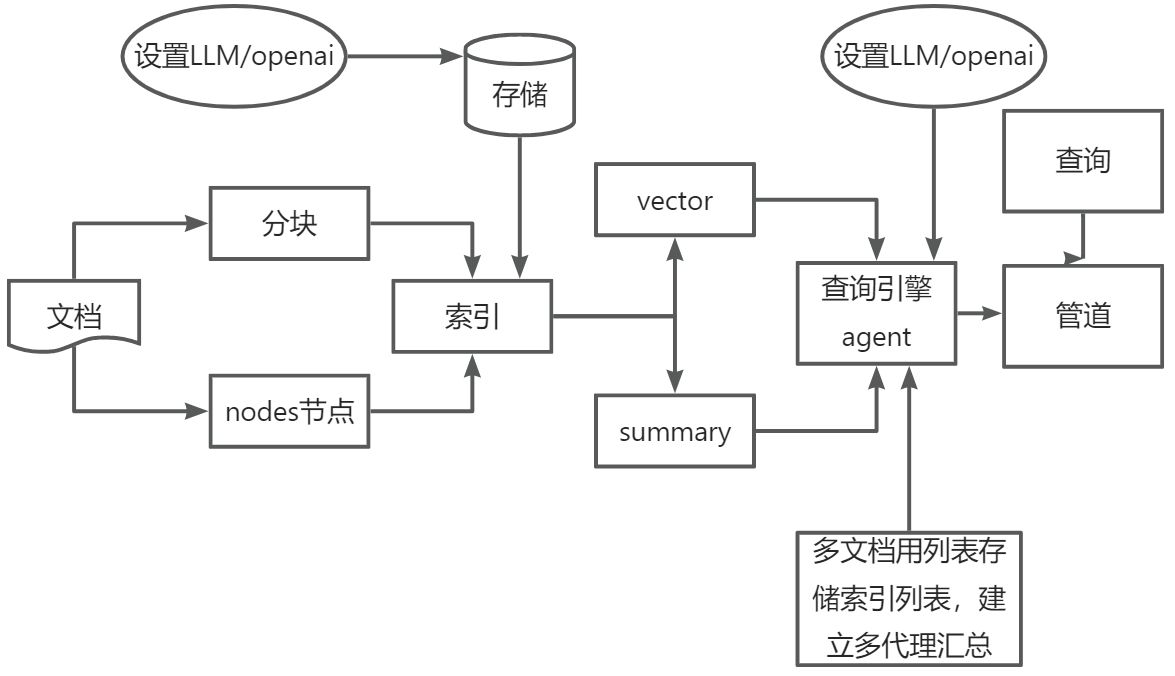
相关文章:
详解llamaindex
什么是LlamaIndex LlamaIndex是一个用于LLM应用程序的数据框架,用于注入、结构化,并访问私有或特定领域的数据。 入门教程 简单使用 # Linux export OPENAI_API_KEYxxxwindows set OPENAI_API_KEYxxx# 代码中加入 API_SECRET_KEY "xxx" B…...

管理类联考–复试–英文面试–问题--规划介绍原因做法--汇总
文章目录 规划介绍原因做法 规划 一、提问方式:问题1:读研的规划;问题2:未来五年的规划;问题3:是否计划读博 常见问法1:Can you talk about your plans in the postgraduate period?…...

成都百洲文化传媒有限公司电商新浪潮的领航者
在当今电商行业风起云涌的时代,成都百洲文化传媒有限公司以其独特的视角和专业的服务,成为了众多商家争相合作的伙伴。今天,就让我们一起走进百洲文化的世界,探索其背后的成功密码。 一、百洲文化的崛起之路 成都百洲文化传媒有限…...
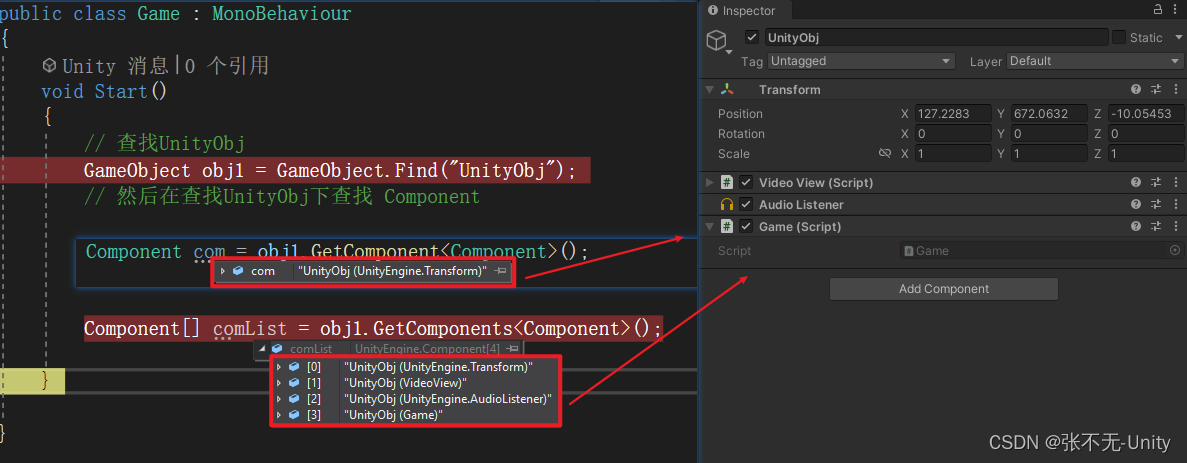
【Unity】获取游戏对象或组件的常用方法
前言 在Unity开发过程中,我们经常需要获取组件,那么在Unity里如何获取组件呢? 一、获取游戏对象 1.GameObject.Find GameObject.Find 是通过物体的名称获取对象的 所以会遍历当前整个场景,效率较低 而且只能获取激活状态的物体…...
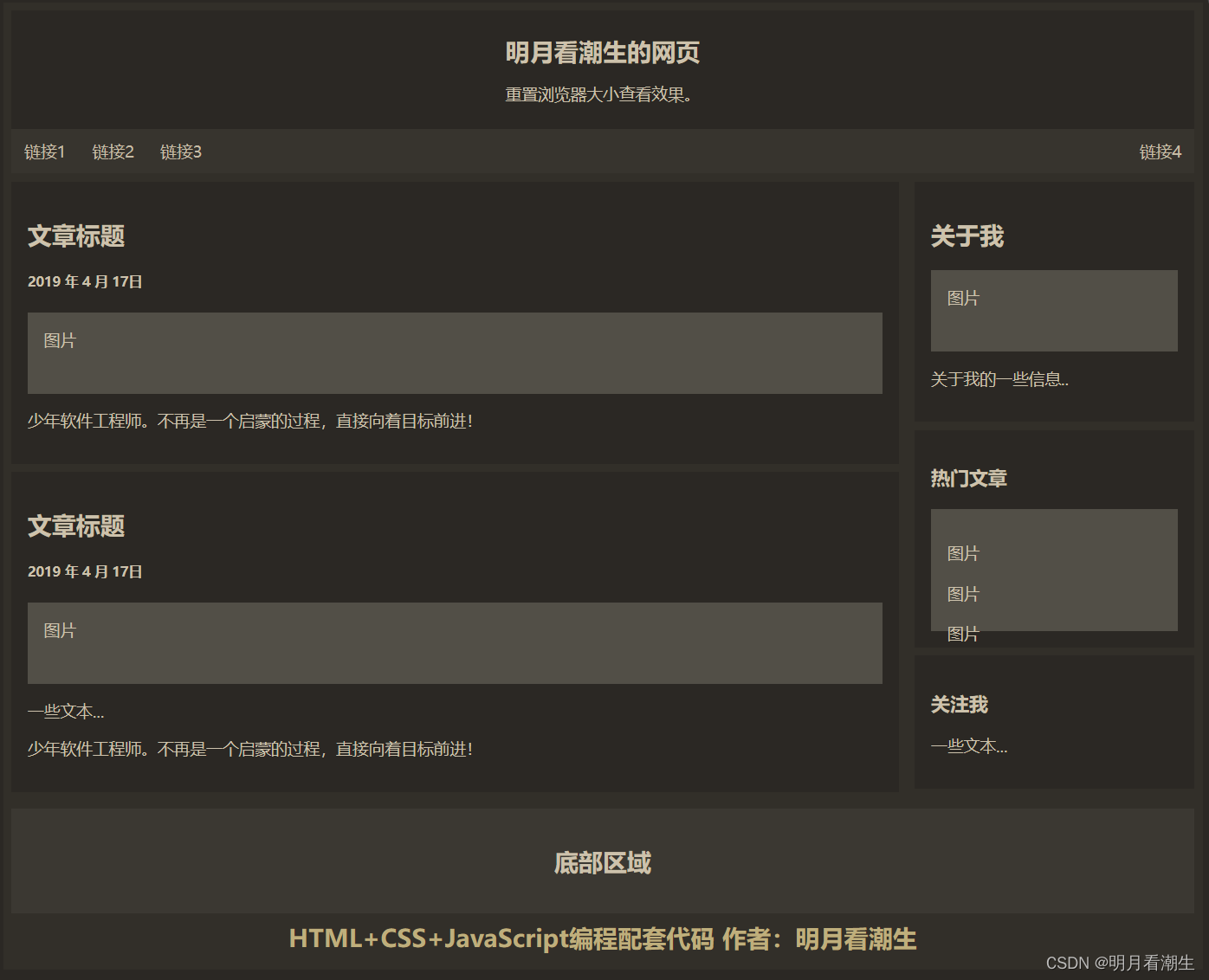
html5cssjs代码 024 响应式布局示例
html5&css&js代码 024 响应式布局示例 一、代码二、解释 该HTML代码重点在于构建一个带有响应式设计的两栏布局网页,包含页头、导航条、主要内容区(左右两列)和底部区域,并运用CSS样式设置页面元素的布局、颜色、字体、间…...

json详解
文章目录 概述JSON 发展史什么是 JSON为什么要使用 JSONJSON 的不足JSON 应该如何存储什么时候会使用 JSON1) 定义接口2) 序列化3) 生成 Token4) 配置文件 Json分类json-lib开源的JacksonGoogle的Gson阿里巴巴的FastJsonJSON.simple JSON 序列化方式有哪些消息队列中传输的数据…...

C语言之---柔性数组
1.1前记 也许你从来没有听说过柔性数组这个概念,但是它是确实存在的。 C99中,结构中的最后一个元素允许是未知大小的数组,这就是柔性数组成员。 例如: struct st_type {int i;int a[0]; }; 有些编译器会报错无法编译可以改为:…...

鸿蒙错误记录
鸿蒙错误代码记录 只是记录学习过程中的错误 只是记录学习过程中的错误 刚开始入手学习鸿蒙,错误记录一下 BussinessError 200 授权没有成功,需要先申请权限 BussinessError 3301200:定位时没有网络,打开网络即可...
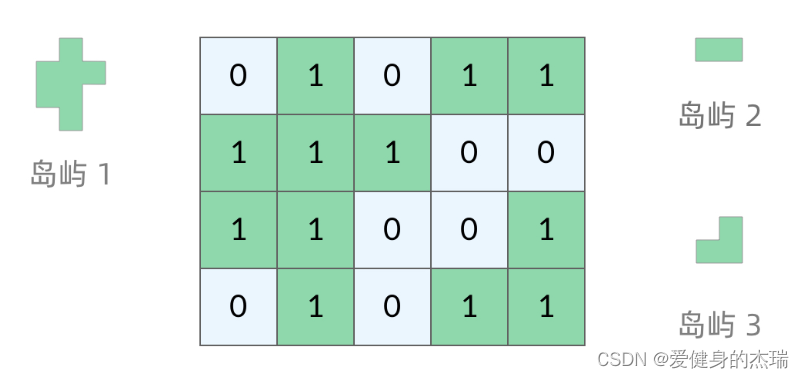
Leetcode热题100:图论
Leetcode 200. 岛屿数量 深度优先搜索法: 对于这道题来说,是一个非常经典的图的问题,我们可以先从宏观上面来看问题,也就是说在不想具体算法的前提下,简单的说出如何找到所有的岛屿呢? 如图中所示&#x…...

刚进公司第一天-电脑环境搭建
写在前面 之前在公司做过一次开发小工具的分享,这两天有个同事找我学习一些小工具开发的知识,但是我发现他的基础是真的差,想学开发知识却连自己本地电脑环境都没弄好,确实,有些人工作了很久,由于自己工作中…...

kubernetes集群报 unable to load bootstrap kubeconfig处置思路
一.现状和问题现象 公司kubernetes集群是通过kubeadm工具安装的,使用1年之后证书到期。在 kubernetes control plane maste节点服务器上运行 kubeadm certs renew all 命令更新证书后,kubelet 无法正常启动,报错日志如下 Failed to run kube…...

MacBook远程桌面Windows使用Microsoft Remote Desktop for Mac_亲测使用
MacBook远程桌面Windows使用Microsoft Remote Desktop for Mac_亲测使用 像Windows上有自带的远程桌面连接软件.MacBook没有自带的远程连接Windows桌面的工具,需要安装软件来实现. 像远程桌面控制软件一般有 TeamViewer、向日葵远程控制, ToDesk, Microsoft Remote Desktop f…...
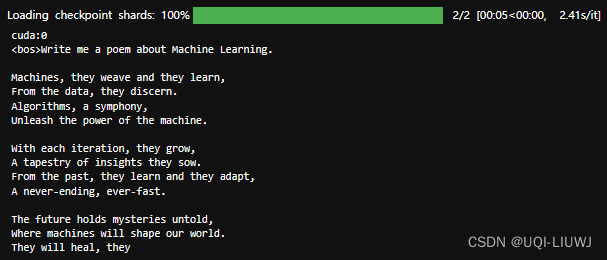
Huggingface 笔记:大模型(Gemma2B,Gemma 7B)部署+基本使用
1 部署 1.1 申请权限 在huggingface的gemma界面,点击“term”以申请gemma访问权限 https://huggingface.co/google/gemma-7b 然后接受条款 1.2 添加hugging对应的token 如果直接用gemma提供的代码,会出现如下问题: from transformers i…...

WebGL 理论基础 01 WebGL 基础概念
WebGL 理论基础 基础概念 WebGL 基础概念 顶点着色器的作用是计算顶点的位置。根据计算出的一系列顶点位置,WebGL可以对点, 线和三角形在内的一些图元进行光栅化处理。当对这些图元进行光栅化处理时需要使用片段着色器方法。 片段着色器的作用是计算…...

Leetcode 28:找出字符串中第一个匹配项的下标
给你两个字符串 haystack 和 needle ,请你在 haystack 字符串中找出 needle 字符串的第一个匹配项的下标(下标从 0 开始)。如果 needle 不是 haystack 的一部分,则返回 -1 。 示例 1: 输入:haystack &q…...

docker opensearch arm64 运行失败解决方案
opensearch版本 2.1.0 docker日志错误信息: Disabling execution of install_demo_configuration.sh for OpenSearch Security Plugin Enabling OpenSearch Security Plugin Killing opensearch process 10 OpenSearch exited with code 143 Performance analyze…...

C#、ASP、ASP.NET、.NET、ASP.NET CORE区别、ASP.NET Core其概念和特点、ASP.NET Core个人心得体会
C#是一种面向对象的编程语言,主要用于开发跨平台的应用程序。它是.NET框架的一部分,并且可以在.NET平台上运行。 ASP(Active Server Pages)是一种用于构建动态Web页面的技术,使用VBScript或JScript作为服务器端脚本语…...
SpringMVC 简介及入门级的快速搭建详细步骤
MVC 回顾 MVC,即Model-View-Controller(模型-视图-控制器)设计模式,是一种广泛应用于软件工程中,特别是Web应用开发中的架构模式。它将应用程序分为三个核心组件: Model(模型)&#…...

Flutter编译卡在Running Gradle task ‘assembleDebug
1、翻墙 2、修改国内镜像源(以下以Flutter 3.19.3版本为例) 找到Flutter SDK目录下的Flutter配置文件resolve_dependencies.gradle 路径:flutter/packages/flutter_tools/gradle/resolve_dependencies.gradle 1)、第一处修改: g…...
基于springboot的牙科就诊管理系统
技术:springbootmysqlvue 一、系统背景 当前社会各行业领域竞争压力非常大,随着当前时代的信息化,科学化发展,让社会各行业领域都争相使用新的信息技术,对行业内的各种相关数据进行科学化,规范化管理。这样…...

ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题
ComfyUI-Manager终极指南:3个核心功能彻底解决AI工作流管理难题 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable vari…...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...

第3篇:系统透视——信息部门如何构建“税务友好型”IT架构
本篇导读:如果你是信息总监或IT负责人,请通读全文,尤其是“系统合规设计的三必须”和“现场检查SOP”;如果你是财税人员,请重点阅读“研产供销全链条的系统对接要求”和“与IT部门的协作要点”;如果你是老板…...

Python合并Excel文档
有若干个Excel文档,每个文档格式一致,及第一行为文件标题,第二行为表格表头(表头不完全一致)。现需要将他们合并。合并规则为:去掉每个文档的第一行,以第二行为表头,将每个文档的第三…...

户外实用|艾迪欧 R6000 测评 —— 户外 / 自驾 / 露营的通讯好搭档
户外出行,通讯工具的核心是稳定、清晰、耐用、续航久、功能全。艾迪欧 R6000 作为一款兼顾专业与户外的 DMR 对讲机,全频段覆盖、双模通讯、自定义功能、长续航,完美适配自驾、露营、登山、越野等户外场景,是户外爱好者的靠谱通讯…...

FairyGUI Unity鼠标悬停与点击对象获取原理与实战
1. 这不是“加个OnMouseEnter就能用”的事:FairyGUI在Unity中处理鼠标交互的真实困境很多人第一次在Unity里集成FairyGUI,想实现“鼠标悬停显示提示”或“点击高亮当前按钮”,下意识就去翻Unity的MonoBehaviour文档,找OnMouseEnte…...

打造XBEE封装BLE112蓝牙模块:硬件设计、射频布局与调试全攻略
1. 项目概述:为什么我们需要一个“XBEE格式”的蓝牙模块?在嵌入式开发和物联网项目中,无线通信模块的选择往往决定了项目的成败。对于很多工程师和创客来说,Silicon Labs(芯科科技)的BLE112/113模块是蓝牙4…...

终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词
终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否厌倦了在听歌时手动搜索歌词…...

通过Taotoken标准OpenAI协议实现分钟级集成现有代码
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken标准OpenAI协议实现分钟级集成现有代码 1. 迁移背景与核心思路 许多开发团队在构建AI应用时,会直接使用O…...

超低功耗电池电压监控电路设计:从LM324到LPV324的硬件方案优化
1. 项目概述与核心需求解析在捣鼓各种电池供电的电子设备时,无论是自己做的无线传感器节点、便携式小工具,还是给孩子改装的玩具,有一个问题总是绕不开:你怎么知道电池快没电了?总不能每次都等到设备彻底罢工ÿ…...