详解机器学习概念、算法
目录
前言
一、常见的机器学习算法
二、监督学习和非监督学习
三、常见的机器学习概念解释
四、深度学习与机器学习的区别
基于Python 和 TensorFlow 深度学习框架实现简单的多层感知机(MLP)神经网络的示例代码:
欢迎三连哦!
前言
机器学习是一种人工智能(AI)的分支,致力于开发算法和技术,使计算机系统能够从数据中学习并改进性能,而无需明确地进行编程。它的核心思想是通过训练模型来识别数据中的模式和规律,然后利用这些模型进行预测和决策。机器学习通常涉及以下几个关键方面:
1. 数据:机器学习的基础是数据。数据可以是结构化的(例如表格数据)或非结构化的(例如文本、图像、音频等)。这些数据用于训练模型。
2. 模型:模型是机器学习算法的核心组成部分。模型通过学习数据中的模式和规律来进行预测或分类。常见的机器学习模型包括线性回归、决策树、支持向量机、神经网络等。
3. 训练:训练模型是指使用已知数据来调整模型的参数,使其能够更好地适应数据中的模式和规律。训练通常包括优化模型的损失函数,以使模型的预测结果尽可能接近实际值。
4. 测试和评估:一旦模型训练完成,就需要对其进行测试和评估,以确保其在未见过的数据上具有良好的泛化能力。这通常涉及将模型应用于测试数据集,并计算模型的性能指标,如准确率、精确率、召回率等。
5. 预测和决策:训练好的模型可以用于进行预测和决策,根据输入数据生成输出结果。这些输出结果可以用于各种应用,如推荐系统、图像识别、自然语言处理、医疗诊断等。
一、常见的机器学习算法
1. 线性回归(Linear Regression):用于建模输入变量与连续输出变量之间的关系。
2. 逻辑回归(Logistic Regression):用于建模输入变量与二元分类输出变量之间的关系。
3. 决策树(Decision Trees):基于树形结构进行决策,可用于分类和回归任务。
4. 随机森林(Random Forests):集成学习方法,通过组合多个决策树来提高预测性能。
5. 支持向量机(Support Vector Machines,SVM):用于分类和回归任务,通过寻找一个最优的超平面来实现分类或回归。
6. K近邻算法(K-Nearest Neighbors,KNN):基于邻近样本的特征进行分类或回归。
7. 朴素贝叶斯(Naive Bayes):基于贝叶斯定理和特征之间的独立假设进行分类。
8. 神经网络(Neural Networks):由多个神经元组成的网络结构,通过多层神经元之间的连接进行学习和预测。
9. 聚类算法(Clustering Algorithms):将数据分成不同的组或簇,常见的算法包括K均值聚类和层次聚类。
10. 主成分分析(Principal Component Analysis,PCA):用于降低数据维度和特征提取。
二、监督学习和非监督学习
监督学习和非监督学习是机器学习中两种主要的学习范式,它们之间的区别在于学习过程中是否有标记的训练数据。
-
监督学习(Supervised Learning):
- 在监督学习中,训练数据包含了输入和对应的输出标签。
- 模型的任务是学习从输入到输出的映射关系,即学习如何从输入数据预测出相应的输出标签。
- 监督学习适用于分类和回归等任务,其中分类任务的输出是离散的类别标签,而回归任务的输出是连续的数值。
- 常见的监督学习算法包括线性回归、逻辑回归、决策树、支持向量机等。
-
非监督学习(Unsupervised Learning):
- 在非监督学习中,训练数据不包含输出标签,模型需要自行发现数据中的模式和结构。
- 模型的任务通常是在没有标签的情况下对数据进行聚类、降维或异常检测等操作。
- 非监督学习适用于对数据进行探索性分析、发现隐藏结构以及理解数据的特点。
- 常见的非监督学习算法包括K均值聚类、层次聚类、主成分分析(PCA)等。
三、常见的机器学习概念解释
常见的机器学习概念:
-
特征(Features):在机器学习中,特征是指描述数据的属性或变量。特征可以是数值型、分类型或者其他类型的数据。
-
标签(Labels):在监督学习中,标签是与输入数据相关联的输出变量或结果。标签通常是需要预测或分类的目标变量。
-
模型(Model):模型是根据训练数据学习到的规律和模式的表示。在预测或分类新数据时,模型根据输入特征生成相应的输出。
-
训练(Training):训练是指使用标记的训练数据来调整模型的参数或权重,以便模型能够从数据中学习并提高性能。
-
测试(Testing):测试是在训练完成后评估模型性能的过程。测试数据与训练数据不同,用于评估模型在未见过的数据上的泛化能力。
-
损失函数(Loss Function):损失函数(Loss Function)是用来衡量模型预测结果与实际标签之间的差异的函数。损失函数是优化算法的核心,其目标是最小化损失函数,从而使模型的预测尽可能接近实际值。选择适当的损失函数取决于问题的性质和所需的模型行为。

-
优化算法(Optimization Algorithm):优化算法用于调整模型的参数以最小化损失函数。常见的优化算法包括梯度下降法、随机梯度下降法等。
-
过拟合(Overfitting):过拟合指模型在训练数据上表现很好,但在未见过的数据上表现较差的现象。过拟合通常发生在模型过于复杂或训练数据量过少时。
-
欠拟合(Underfitting):欠拟合指模型未能在训练数据上学习到足够的模式或规律,导致其在训练和测试数据上表现均不理想的现象。
-
交叉验证(Cross-validation):交叉验证是一种评估模型性能的方法,它将训练数据分成多个子集,然后多次训练和测试模型,最终汇总评估模型的性能。
过拟合(Overfitting):
- 过拟合指模型在训练数据上表现很好,但在未见过的数据上表现较差的现象。
- 过拟合通常发生在模型过于复杂或者训练数据量不足时。
- 过拟合的表现包括模型对训练数据中的噪声过度拟合、模型参数过多、模型复杂度过高等。
- 过拟合可能导致模型在真实世界中的泛化能力差,即在新数据上的表现不佳。
欠拟合(Underfitting):
- 欠拟合指模型未能在训练数据上学习到足够的模式或规律,导致其在训练和测试数据上表现均不理想的现象。
- 欠拟合通常发生在模型过于简单或者数据特征未能充分提取时。
- 欠拟合的表现包括模型无法捕捉数据的复杂关系、模型参数过少、模型复杂度过低等。
- 欠拟合可能导致模型在训练数据和测试数据上的性能都较差,无法有效地进行预测或分类。
解决过拟合和欠拟合问题的方法各有不同:
过拟合的解决方法:
- 增加训练数据量,以更好地反映真实数据的分布。
- 简化模型,减少模型的复杂度,如减少参数数量、减少隐藏层的数量或神经元的数量等。
- 使用正则化方法,如L1正则化(Lasso)或L2正则化(Ridge)来约束模型参数的大小。
- 使用早停法(Early Stopping),在模型在验证集上性能开始下降时停止训练,以防止过度拟合。
欠拟合的解决方法:
- 增加模型复杂度,如增加模型的参数数量、增加模型的隐藏层数量或神经元的数量等。
- 增加特征数量,包括添加新的特征或通过特征工程提取更多的特征。
- 减少正则化程度,如降低正则化参数的值,以允许模型更好地拟合训练数据。
四、深度学习与机器学习的区别
深度学习算法是机器学习算法的一种特殊类型,它们之间的主要区别在于模型的结构和学习方式。
-
模型结构:
- 传统的机器学习算法通常依赖于手工设计的特征提取器和模型结构,例如决策树、支持向量机等。这些算法对特征的选择和提取通常依赖于专家知识或经验。
- 而深度学习算法则通过多层神经网络模型来自动学习数据的表示。这些模型由多个神经元组成的层级结构,可以从原始数据中学习到更加高级和抽象的特征表示。
-
特征表示:
- 传统机器学习算法通常依赖于手工选择和提取的特征,这些特征通常需要领域知识或专业经验来确定。
- 而深度学习算法通过学习数据的表示来自动发现特征,它们可以在原始数据中学习到更加复杂和抽象的特征表示,无需人工干预。
-
学习方式:
- 传统机器学习算法通常使用基于梯度下降等优化算法来最小化损失函数,从而调整模型参数以优化性能。
- 深度学习算法也使用类似的优化算法进行训练,但由于深度神经网络的复杂性,通常需要更大规模的数据和计算资源来训练。
-
应用领域:
- 传统机器学习算法在许多领域都有广泛的应用,包括文本分类、图像识别、推荐系统等。
- 深度学习算法在近年来在许多领域取得了突破性的进展,特别是在计算机视觉、自然语言处理、语音识别等领域。
基于Python 和 TensorFlow 深度学习框架实现简单的多层感知机(MLP)神经网络的示例代码:
# 导入必要的库
import numpy as np
import tensorflow as tf
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split# 生成一些示例数据
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 定义神经网络模型
model = tf.keras.Sequential([tf.keras.layers.Dense(64, activation='relu', input_shape=(20,)),tf.keras.layers.Dense(32, activation='relu'),tf.keras.layers.Dense(1, activation='sigmoid')
])# 编译模型
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32, validation_data=(X_test, y_test))# 在测试集上评估模型
loss, accuracy = model.evaluate(X_test, y_test)
print("测试集上的损失:", loss)
print("测试集上的准确率:", accuracy)
代码使用 TensorFlow 框架来构建、训练和评估一个简单的多层感知机神经网络。首先,我们生成了一些示例数据,然后将数据分为训练集和测试集。接下来,我们定义了一个包含多个密集层的神经网络模型,并编译了该模型。然后,我们使用训练集来训练模型,并在训练过程中使用测试集来验证模型的性能。最后,我们在测试集上评估了模型的损失和准确率。
基于PyTorch 实现数字识别的示例代码,该示例使用了手写数字数据集 MNIST:
# 导入必要的库
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt# 设置随机种子
torch.manual_seed(0)# 定义超参数
batch_size = 100
learning_rate = 0.001
num_epochs = 5# 加载并预处理数据集
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))
])train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
test_dataset = torchvision.datasets.MNIST(root='./data', train=False, transform=transform, download=True)train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)# 定义神经网络模型
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2)self.relu1 = nn.ReLU()self.maxpool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2)self.relu2 = nn.ReLU()self.maxpool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.fc = nn.Linear(7*7*32, 10)def forward(self, x):out = self.conv1(x)out = self.relu1(out)out = self.maxpool1(out)out = self.conv2(out)out = self.relu2(out)out = self.maxpool2(out)out = out.view(out.size(0), -1)out = self.fc(out)return out# 实例化模型和损失函数
model = SimpleCNN()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)# 训练模型
total_step = len(train_loader)
for epoch in range(num_epochs):for i, (images, labels) in enumerate(train_loader):outputs = model(images)loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()if (i+1) % 100 == 0:print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}' .format(epoch+1, num_epochs, i+1, total_step, loss.item()))# 测试模型
model.eval()
with torch.no_grad():correct = 0total = 0for images, labels in test_loader:outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print('在10000张测试集上的准确率为: {} %'.format(100 * correct / total))
使用 PyTorch 构建一个简单的卷积神经网络(CNN)模型来实现手写数字识别。首先,我们加载并预处理了 MNIST 数据集,然后定义了一个简单的 CNN 模型。接着,我们定义了损失函数(交叉熵损失)和优化器(Adam),并利用训练集对模型进行训练。最后,我们使用测试集对模型进行评估,计算了模型在测试集上的准确率。
相关文章:
详解机器学习概念、算法
目录 前言 一、常见的机器学习算法 二、监督学习和非监督学习 三、常见的机器学习概念解释 四、深度学习与机器学习的区别 基于Python 和 TensorFlow 深度学习框架实现简单的多层感知机(MLP)神经网络的示例代码: 欢迎三连哦! 前言…...
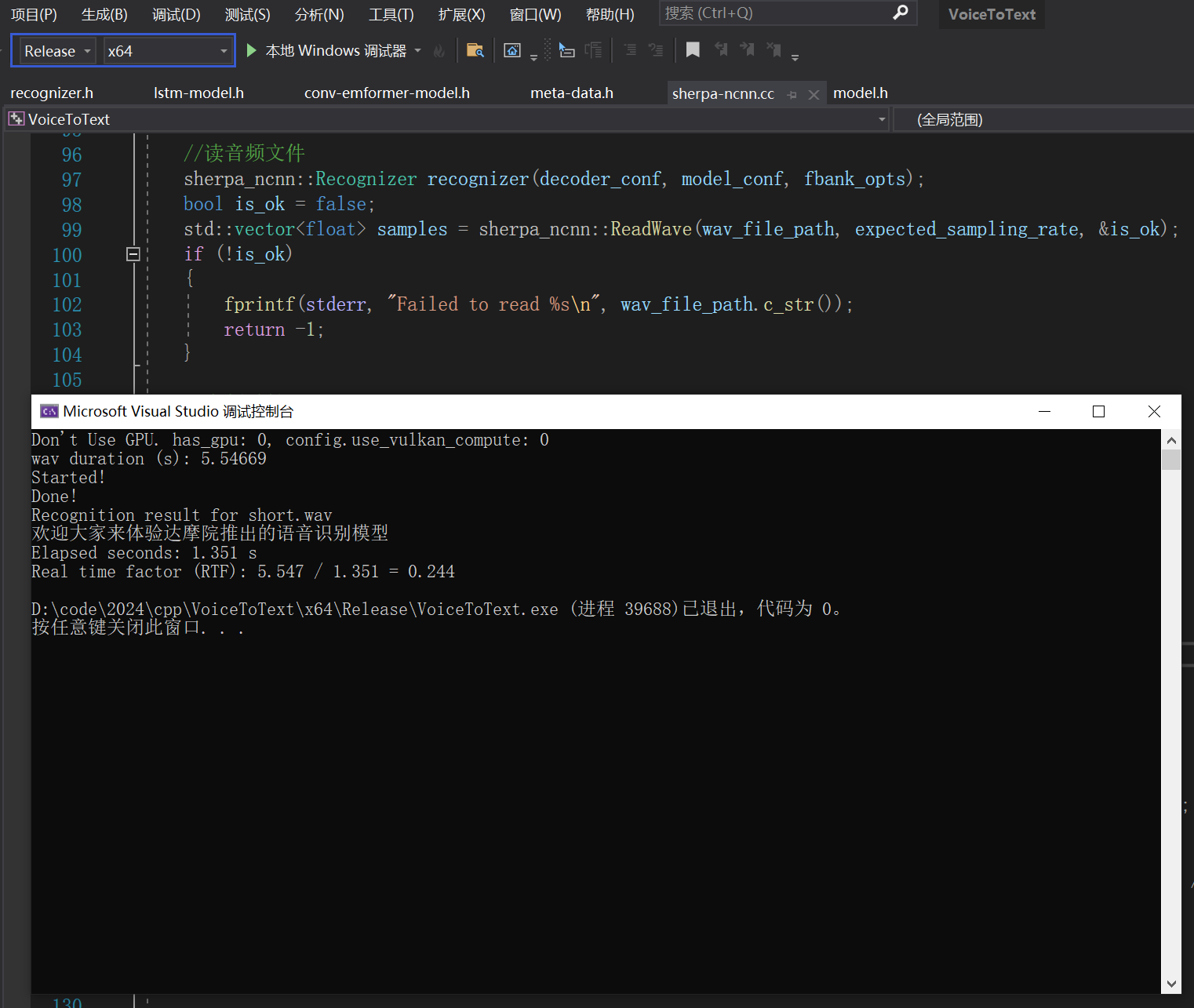
语音转文字——sherpa ncnn语音识别离线部署C++实现
简介 Sherpa是一个中文语音识别的项目,使用了PyTorch 进行语音识别模型的训练,然后训练好的模型导出成 torchscript 格式,以便在 C 环境中进行推理。尽管 PyTorch 在 CPU 和 GPU 上有良好的支持,但它可能对资源的要求较高&#x…...
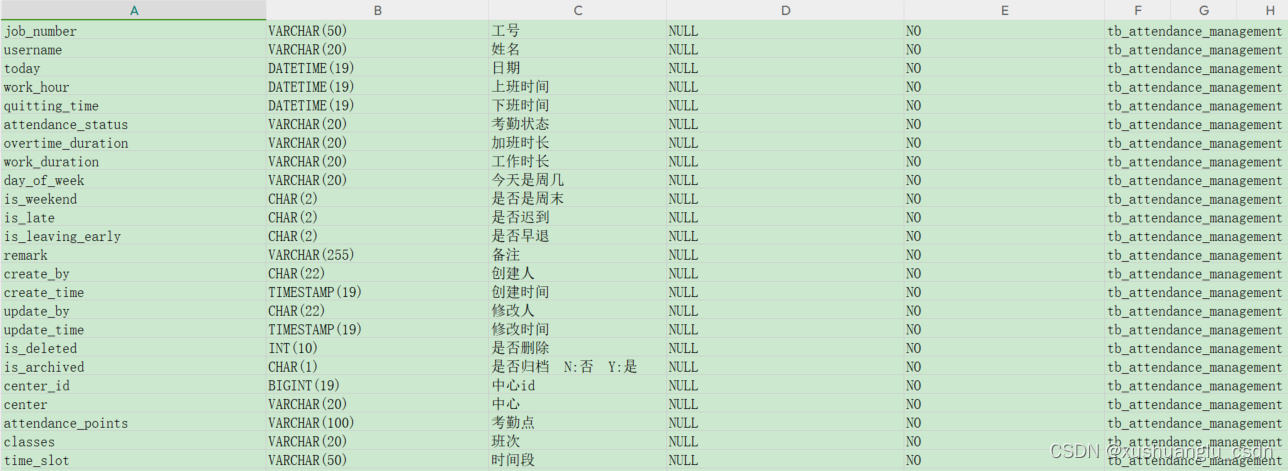
第1篇:Mysql数据库表结构导出字段到Excel(一个sheet中)
package com.xx.util;import org.apache.poi.ss.usermodel.*; import org.apache.poi.xssf.usermodel.XSSFWorkbook;import java.sql.*; import java.io.*;public class DatabaseToExcel {public static void main(String[] args) throws Exception {// 数据库连接配置String u…...

Request请求参数----中文乱码问题
一: GET POST获取请求参数: 在处理为什么会出现中文乱码的情况之前, 首先我们要直到GET 以及 POST两种获取请求参数的不同 1>POST POST获取请求参数是通过输入流getReader来进行获取的, 通过字符输入流来获取响应的请求参数, 并且在解码的时候, 默认的情况是 ISO_885…...

labelImg安装方法
labelImg安装方法(简单方法) - 知乎 (zhihu.com) 1. lableImg下载 git clone https://github.com/tzutalin/labelImg.git 2. 制作lableImg所需的"condapython"环境(conda需要先安装,最好再设置下下载源) 打开Anaconda Prompt对话框 # 创建环境 conda create -n …...
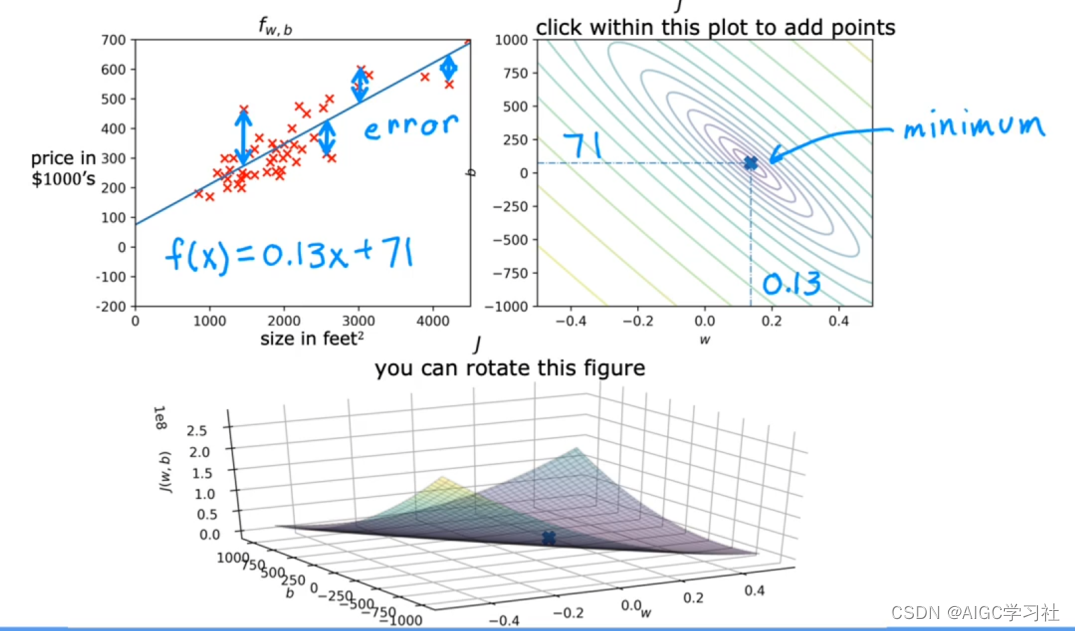
吴恩达2022机器学习专项课程(一) 3.6 可视化样例
问题预览 1.本节课主要讲的是什么? 2.不同的w和b,如何影响线性回归和等高线图? 3.一般用哪种方式,可以找到最佳的w和b? 解读 1.课程内容 设置不同的w和b,观察模型拟合数据,成本函数J的等高线…...

C#入门及进阶教程|Windows窗体属性及方法
1.Windows窗体 窗体本身是一个对象,对应于System.Windows.Forms名称空间的Form类。它有自己的属性、方法和事件,用于控制窗体的外观和行为。窗体又是各种控件的容器,用于容纳各种窗体控件。如果想生成窗体,必须从Form类派生出自己…...
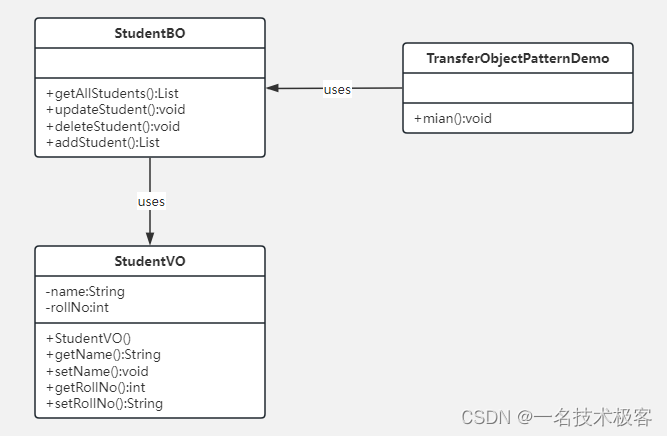
34-Java传输对象模式 ( Transfer Object Pattern )
Java传输对象模式 实现范例 传输对象模式(Transfer Object Pattern)用于从客户端向服务器一次性传递带有多个属性的数据传输对象也被称为数值对象,没有任何行为传输对象是一个具有 getter/setter 方法的简单的 POJO 类,它是可序列…...
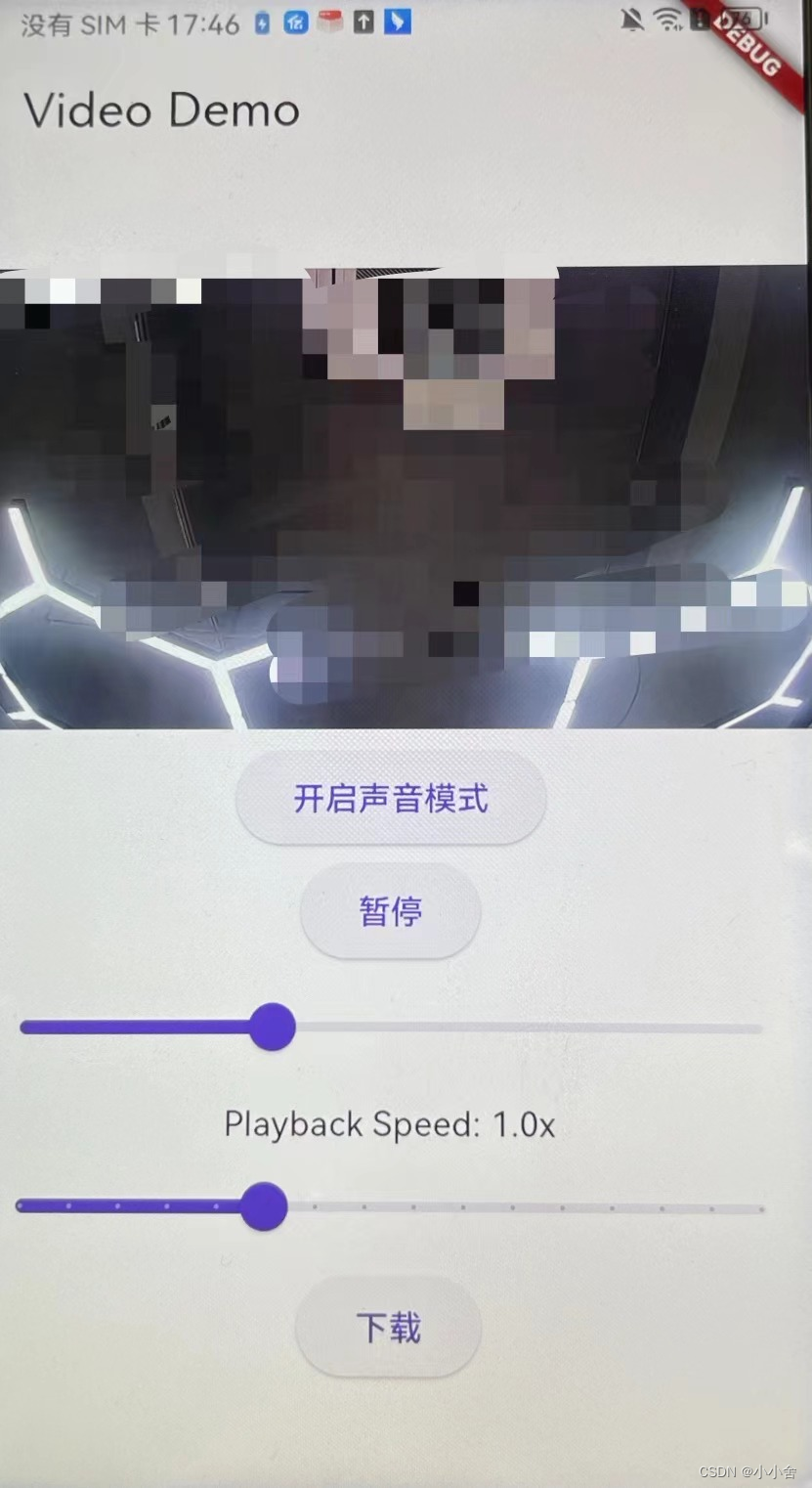
flutter实现视频播放器,可根据指定视频地址播放、设置声音,进度条拖动,下载等
需要装依赖: gallery_saver: ^2.3.2video_player: ^2.8.3 AndroidManifest.xml <uses-permission android:name"android.permission.INTERNET"/> 实现代码 import dart:async; import dart:io;import package:flutter/material.dart; import pa…...

微服务(基础篇-001-介绍、Eureka)
目录 认识微服务(1) 服务架构演变(1.1) 单体架构(1.1.1) 分布式架构(1.1.2) 微服务(1.1.3) 微服务结构 微服务技术对比 企业需求 SpringCloud(1.2) …...
mac 解决随机出现的蓝色框
macbookair为什么打字的时候按空格键会出现蓝色框? - 知乎...

深入理解与使用go之函数与方法--使用
深入理解与使用go之函数与方法–理解与使用 文章目录 引子函数与方法分类函数函数入参普通参数可变参数默认值返回命名不带命名带命名讨论init 函数defer 函数方法值接收指针接收构造函数引子 在 Go 语言中,函数被视为一等公民(First-Class Citizens),这意味着函数可以像其…...

【QT问题】 Qt信号函数如果重名,调用怎么处理
问题描述: 在调用某个类的信号函数的时候,出现信号函数名字相同,参数不同的情况,但是Qt在链接信号槽的时候,又不需要指明信号函数参数,此时就会出现无法分辨的情况。 例如:QComboBox的信号 Q_…...
)
登山小分队(dfs,模拟)
原题链接: 题目描述 Foxity和他的好友们相约去爬山,但是他们每个人都来到了不同的山脚下。整个山的结构类似一棵 "树",有很多的观光节点通过一条条山道连接起来。 在图论中,树是一种无向图,其中任意两个顶…...

Luminar Neo:重塑图像编辑新纪元,Mac与Win双平台畅享创意之旅
在数字时代的浪潮中,图像编辑软件已成为摄影师和设计师们不可或缺的创作工具。Luminar Neo,作为一款专为Mac与Windows双平台打造的图像编辑软件,正以其卓越的性能和创新的编辑功能,引领着图像编辑的新潮流。 Luminar Neo不仅继承…...

计算机二级Python题库深度解析与备考策略
计算机二级Python题库深度解析与备考策略 随着信息技术的飞速发展,Python作为一门简洁、易读且功能强大的编程语言,受到了越来越多人的青睐。计算机二级Python考试作为衡量考生Python编程水平的重要标准,其题库内容涵盖了Python语言的基础知…...
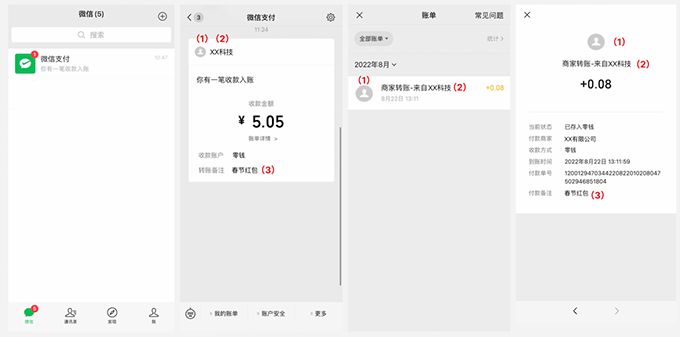
微信商家转账到零钱:实用指南,涵盖开通、使用与常见问题
商家转账到零钱是什么? 商家转账到零钱功能整合了企业付款到零钱和批量转账到零钱,支持批量对外转账,操作便捷。如果你的应用场景是单付款,体验感和企业付款到零钱基本没差别。 商家转账到零钱的使用场景有哪些? 这…...

[精选]Kimi到底是什么,将带来什么?
## 阿里通义千问重磅升级:免费开放1000万字长文档处理功能。 Kimi突然的泼天富贵,大家都想沾一把。短期这一块大概率会继续热一段时间。 作为月之暗面的创始人,杨植麟常把他的AGI梦想形容为“登月计划”,长文本就是这个伟大计划…...

MySQL学习笔记------SQL(2)
ziduanSQL DML 全称为:Data Manipulation Language,用来对数据库中表的数据记录进行增删改操作 插入数据 添加数据(INSERT) 给指定字段添加数据:INSERT INTO 表名(字段名1,字段名2,......…...
【循环神经网络rnn】一篇文章讲透
目录 引言 二、RNN的基本原理 代码事例 三、RNN的优化方法 1 长短期记忆网络(LSTM) 2 门控循环单元(GRU) 四、更多优化方法 1 选择合适的RNN结构 2 使用并行化技术 3 优化超参数 4 使用梯度裁剪 5 使用混合精度训练 …...

MCP Server生产级配置:Playwright与LLM集成的避坑指南
1. 这不是又一个“Playwright入门教程”,而是一份能直接塞进CI流水线的MCP Server生产级配置实录你有没有遇到过这样的场景:团队刚决定用AI驱动自动化测试,技术选型会上大家一致看好Playwright MCP(Model Context Protocol&#…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...

小米MIMO最新邀请码
欢迎使用,各得10元体验金...

别再盲跑了!手把手教你用Arduino Zero在IDE 2.0里设置断点单步调试
告别盲跑时代:Arduino Zero与IDE 2.0的源码级调试实战指南 当你的Arduino项目逻辑越来越复杂,仅靠串口打印调试就像在迷宫里摸黑前行——直到遇见Arduino Zero与IDE 2.0的调试组合。本文将揭示如何用这套工具实现 源码级精准调试 ,即使你手…...

2026年,揭秘那些真正安全的原生态食材厂家你不可不知的秘密
随着人们生活水平的提升以及对健康的日益重视,选择真正安全的原生态食材已经成为许多人购买食物的标准。但市场的繁杂使得甄别真正安全的食材厂家变得愈加困难。今天,我将通过几个关键角度,为大家揭秘那些真正安全的原生态食材厂家的秘密&…...
)
Mysql:事务管理(中)
在前面的章节中,我们提到了 MVCC(多版本并发控制),它巧妙地通过“版本快照”解决了“读-写”冲突,实现了非阻塞读。但如果两个事务同时执行 UPDATE 操作修改同一行数据,即 写-写(Write-Write&am…...

从“DOC/PDF”到“WPS”:细看GJB438C-2021文档格式要求背后的国产化信号与落地指南
从“DOC/PDF”到“WPS”:GJB438C-2021文档格式变革的深度解读与实施策略 当一份国家军用标准在文档格式描述中刻意删除"DOC/PDF"字样,转而明确标注"(WPS)文档处理器"时,这绝非简单的技术参数调整。…...
)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)
告别混乱绑定!在UE5 GAS中优雅管理技能输入(基于GameplayTag)当你的UE5 RPG项目发展到中期,技能数量从十几个膨胀到几十个时,最痛苦的莫过于发现InputAction绑定已经变成一团乱麻。每次新增技能都要修改输入绑定逻辑&a…...

破解材料数据荒:合成数据与随机森林预测聚合物阻燃性能
1. 项目概述与核心挑战在材料研发领域,尤其是涉及公共安全的聚合物阻燃性研究,传统实验方法正面临巨大瓶颈。想象一下,你是一位材料工程师,需要设计一种用于高铁内饰或高层建筑电缆护套的新型聚合物,其阻燃性能必须满足…...
)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战)
告别SVN恐惧症:美术策划也能轻松上手的Unity PlasticSCM极简入门(附团队项目拉取实战) 在游戏开发团队中,版本控制系统是协作的基石,但传统工具如SVN往往让非技术成员望而生畏。当美术资源频繁更新、策划案不断迭代时&…...