数据结构与算法-排序算法
1.顺序查找
def linear_search(iters, val):for i, v in enumerate(iters):if v == val:return ireturn2.二分查找
# 升序的二分查找
def binary_search(iters, val):left = 0right = len(iters)-1while left <= right:mid = (left + right) // 2if iters[mid] == val:return midelif iters[mid] > val:right = mid - 1else:left = mid + 1else:return
lis = [1, 2, 3, 4]
print(binary_search(lis, 2))# 降序的二分查找
def binary_search(iters, val):left = 0right = len(iters)-1while left <= right:mid = (left + right) // 2if iters[mid] == val:return midelif iters[mid] > val:left = mid + 1else:right = mid - 1else:return
lis = [4, 3, 2, 1]
print(binary_search(lis, 2))3.冒泡排序
# 升序冒泡排序
def bubble_sort(li):for i in range(len(li)-1): #第i趟exchange = False # 判断第i趟是否进行了交换for j in range(len(li)-1-i):if li[j] > li[j+1]:li[j], li[j+1] = li[j+1], li[j]exchange = Trueprint(li)if not exchange:return
li = [1, 4, 2, 9, 0]
bubble_sort(li)print("===========================================")# 降序冒泡排序
def bubble_sort(li):for i in range(len(li)-1): #第i趟exchange = False # 判断第i趟是否进行了交换for j in range(len(li)-1-i):if li[j] < li[j+1]:li[j], li[j+1] = li[j+1], li[j]exchange = Trueprint(li)if not exchange:return
li = [1, 4, 2, 9, 0]
bubble_sort(li)4.选择排序
# 升序选择排序: 非原地排序(新增一个变量存储排序后的结果)
def select_sort_sample1(li):li_new = []for i in range(len(li)):min_val = min(li)li_new.append(min_val)li.remove(min_val)return li_new
li = [3, 1, 4, 7, 4, 8]
print(select_sort_sample1(li))print("================================================")# 降序选择排序: 非原地排序(新增一个变量存储排序后的结果)
def select_sort_sample2(li):new_li = []for i in range(len(li)):max_val = max(li)new_li.append(max_val)li.remove(max_val)return new_li
li = [3, 1, 4, 7, 4, 8]
print(select_sort_sample2(li))print("=================================================")# 升序选择排序: 原地排序
def select_sort1(li):for i in range(len(li)-1):min_loc = ifor j in range(i+1, len(li)):if li[j] < li[min_loc]:min_loc = jli[i], li[min_loc] = li[min_loc], li[i]print(li)
li = [1, 4, 2, 8, 5]
select_sort1(li)print("==================================================")# 降序选择排序: 原地排序
def select_sort2(li):for i in range(len(li)-1):max_loc = ifor j in range(i+1, len(li)):if li[j] > li[max_loc]:max_loc = jli[i], li[max_loc] = li[max_loc], li[i]print(li)
li = [1, 4, 2, 8, 5]
select_sort2(li)5.插入排序
# 升序插入排序
def insert_sort1(li):for i in range(1, len(li)): #i表示摸到的牌的下标tmp = li[i] #存放待插入的牌j = i - 1 #j表示手里的牌的下标while j >= 0 and li[j] > tmp:li[j+1] = li[j]j -= 1li[j+1] = tmpprint(li)
li = [1, 4, 2, 8, 5]
insert_sort1(li)print("=======================================")# 降序插入排序
def insert_sort2(li):for i in range(1, len(li)):tmp = li[i]j = i - 1while j >= 0 and li[j] < tmp:li[j+1] = li[j]j -= 1li[j+1] = tmpprint(li)
li = [1, 4, 2, 8, 5]
insert_sort2(li)6.快速排序
# 升序快速排序
def partition1(li, left, right):tmp = li[left] #存放待归位的值while left < right:while left < right and li[right] >= tmp: #从右面找比tmp小的元素right -= 1 #往左走一步li[left] = li[right] #把右边的值写到左边while left < right and li[left] <= tmp: #从左面找比tmp大的元素left += 1 #往右走一步li[right] = li[left] #把左边的值写到右边li[left] = tmpreturn leftdef quick_sort1(li, left, right):if left < right: #至少两个元素mid = partition1(li, left, right)quick_sort1(li, left, mid-1)quick_sort1(li, mid+1, right)li = [4, 3, 5, 5, 8, 7]
quick_sort1(li, 0, len(li)-1)
print(li)print("======================================================")# 降序快速排序
def partition2(li, left, right):tmp = li[left]while left < right:while left < right and li[right] <= tmp:right -= 1li[left] = li[right]while left < right and li[left] >= tmp:left += 1li[right] = li[left]li[left] = tmpreturn leftdef quick_sort2(li, left, right):if left < right:mid = partition2(li, left, right)quick_sort2(li, left, mid-1)quick_sort2(li, mid+1, right)li = [4, 3, 5, 5, 8, 7]
quick_sort2(li, 0, len(li)-1)
print(li)7.堆排序
# 升序堆排序
def shift(li, low, high):# 建大根堆""":param li: 列表:param low: 堆的根节点位置:param high: 堆的最后一个元素位置:return:"""i = low #i最开始指向根节点j = 2 * i + 1 #j开始是左孩子tmp = li[low] #把堆顶存起来while j <= high: # j位置有效if j + 1 <= high and li[j+1] > li[j]: #如果右孩子有且比较大j = j + 1 #j指向右孩子if li[j] > tmp:li[i] = li[j]i = jj = 2 * i + 1else:li[i] = tmpbreakelse:li[i] = tmp # 把tmp放到叶子节点上def heap_sort(li):n = len(li)for i in range((n-2)//2, -1, -1):# (n - 2) // 2表示最后一个有孩子节点的节点的下标# i表示建堆的时候要进行调整的二叉树的根的下标shift(li, i, n-1)# 建堆完成print("大根堆:{}".format(li))for i in range(n-1, -1, -1):# i指向当前堆的最后一个元素li[0], li[i] = li[i], li[0]shift(li, 0, i-1) # i-1是最新的high
import random
li = [i for i in range(10)]
random.shuffle(li)
print("初始列表:{}".format(li))
heap_sort(li)
print("排序列表:{}".format(li))print("============================================")# 降序堆排序
def shift1(li, low, high):# 建小根堆""":param li: 列表:param low: 堆的根节点位置:param high: 堆的最后一个节点的位置:return:"""i = low # 最开始指向根节点j = 2 * i + 1 # 左孩子节点tmp = li[low]while j <= high:if j + 1 <= high and li[j + 1] < li[j]:j = j + 1if li[j] < tmp:li[i] = li[j]i = jj = 2 * i + 1else:li[i] = tmpbreakelse:li[i] = tmpdef heap_sort1(li):n = len(li)for i in range((n-2)//2, -1, -1):shift1(li, i, n-1)print("小根堆:{}".format(li))# 建堆完成for i in range(n-1, -1, -1):li[0], li[i] = li[i], li[0]shift1(li, 0, i - 1)
import random
li = [i for i in range(10)]
random.shuffle(li)
print("初始列表:{}".format(li))
heap_sort1(li)
print("排序列表:{}".format(li))8.归并排序
# 升序归并排序
def merge(li, low, mid, high):# 对两个有序列表进行合并""":param li: 列表:param low::param mid::param high::return:"""i = lowj = mid + 1ltmp = []while i <= mid and j <= high: #只要两边都有数if li[i] < li[j]:ltmp.append(li[i])i += 1else:ltmp.append(li[j])j += 1while i <= mid:ltmp.append(li[i])i += 1while j <= high:ltmp.append(li[j])j += 1li[low:high+1] = ltmpdef merge_sort(li, low, high):if low < high: # 至少有两个元素mid = (low + high) // 2merge_sort(li, low, mid)merge_sort(li, mid + 1, high)merge(li, low, mid, high)import random
li = [i for i in range(10)]
random.shuffle(li)
merge_sort(li, 0, len(li) - 1)
print(li)print("================================================")# 降序归并排序
def merge1(li, low, mid, high):# 对两个有序列表进行合并""":param li: 列表:param low::param mid::param high::return:"""i = lowj = mid + 1ltmp = []while i <= mid and j <= high: #只要两边都有数if li[i] > li[j]:ltmp.append(li[i])i += 1else:ltmp.append(li[j])j += 1while i <= mid:ltmp.append(li[i])i += 1while j <= high:ltmp.append(li[j])j += 1li[low:high+1] = ltmpdef merge_sort1(li, low, high):if low < high: # 至少有两个元素mid = (low + high) // 2merge_sort1(li, low, mid)merge_sort1(li, mid + 1, high)merge1(li, low, mid, high)import random
li = [i for i in range(10)]
random.shuffle(li)
merge_sort1(li, 0, len(li) - 1)
print(li)9.希尔排序
# 升序希尔排序
def insert_sort_gap(li, gap):for i in range(gap, len(li)): #i表示摸到的牌的下标tmp = li[i] #存放待插入的牌j = i - gap #j表示手里的牌的下标while j >= 0 and li[j] > tmp:li[j + gap] = li[j]j -= gapli[j+gap] = tmpdef shell_sort(li):d = len(li) // 2while d >= 1:insert_sort_gap(li, d)d //= 2li = [1, 4, 2, 8, 5]
shell_sort(li)
print(li)10.计数排序
# 升序计数排序
# 限制: 数值有确定的范围
def count_sort(li, max_count=100):count = [0 for _ in range(max_count+1)]for val in li:count[val] += 1li.clear()for ind, val in enumerate(count):for i in range(val):li.append(ind)
import random
li = [random.randint(0, 100) for i in range(1000)]
count_sort(li)
print(li)11.桶排序
# 升序桶排序
def bucket_sort(li, n=100, max_num=10000):buckets = [[] for i in range(n)] # 创建桶for var in li:i = min(var // (max_num // n), n - 1) # i表示var放到第几个桶里buckets[i].append(var) # 把var放桶里for j in range(len(buckets[i]) - 1, 0, -1):if buckets[i][j] < buckets[i][j - 1]:buckets[i][j], buckets[i][j - 1] = buckets[i][j - 1], buckets[i][j]else:breaksorted_li = []for buc in buckets:sorted_li.extend(buc)return sorted_liimport random
li = [random.randint(0, 10000) for i in range(100)]
print(bucket_sort(li))12.基数排序
def redix_sort(li):""":param li: 列表:return:限制于正整数的基数排序"""max_num = max(li)it = 0 # 0 -> 按个位分桶 1 -> 按十位分桶 2 -> 按百位分桶...while 10 ** it <= max_num:buckets = [[] for _ in range(10)]for var in li:digit = (var // 10 ** it) % 10 # it->0 取个位; it->1 取十位; it->2 取百位...(若该数位上没有数字, 取零)buckets[digit].append(var)# 分桶完成li.clear()for buc in buckets:li.extend(buc)# 把数重新写回liit += 1import random
li = [random.randint(0, 10000) for i in range(100)]
redix_sort(li)
print(li)相关文章:

数据结构与算法-排序算法
1.顺序查找 def linear_search(iters, val):for i, v in enumerate(iters):if v val:return ireturn 2.二分查找 # 升序的二分查找 def binary_search(iters, val):left 0right len(iters)-1while left < right:mid (left right) // 2if iters[mid] val:return mid…...
SpringBoot 文件上传(三)
之前讲解了如何接收文件以及如何保存到服务端的本地磁盘中: SpringBoot 文件上传(一)-CSDN博客 SpringBoot 文件上传(二)-CSDN博客 这节讲解如何利用阿里云提供的OSS(Object Storage Service)对象存储服务保存文件。…...

web渗透测试漏洞流程:红队目标信息收集之资产搜索引擎收集
web渗透测试漏洞流程 渗透测试信息收集---域名信息收集1.域名信息的科普1.1 域名的概念1.2 后缀分类1.3 多重域名的关系1.4 域名收集的作用1.5 DNS解析原理1.6 域名解析记录2. 域名信息的收集的方法2.1 基础方法-搜索引擎语法2.1.1 Google搜索引擎2.1.1.1 Google语法的基本使用…...

UI自动化_id 元素定位
## 导包selenium from selenium import webdriver import time1、创建浏览器驱动对象 driver webdriver.Chrome() 2、打开测试网站 driver.get("你公司的平台地址") 3、使浏览器窗口最大化 driver.maximize_window() 4、在用户名输入框中输入admin driver.find_ele…...

华为OD技术面算法题整理
LeetCode原题 简单 题目编号频次409. 最长回文串 - 力扣(LeetCode)3...

vmware虚拟机下ubuntu扩大磁盘容量
1、扩容: 可以直接在ubuntu setting界面里直接扩容,也可通过vmware命令,如下: vmware提供一个命令行工具,vmware-vdiskmanager.exe,位于vmware的安装目录下,比如 C:/Program Files/VMware/VMwar…...
秋招打卡算法题第一天
一年多没有刷过算法题了,已经不打算找计算机类工作了,但是思来想去,还是继续找吧。 1. 字符串最后一个单词的长度 public static void main(String[] args) {Scanner in new Scanner(System.in);while(in.hasNextInt()){String itemin.nextL…...

BC98 序列中删除指定数字
题目 描述 有一个整数序列(可能有重复的整数),现删除指定的某一个整数,输出删除指定数字之后的序列,序列中未被删除数字的前后位置没有发生改变。 数据范围:序列长度和序列中的值都满足 1≤�≤…...
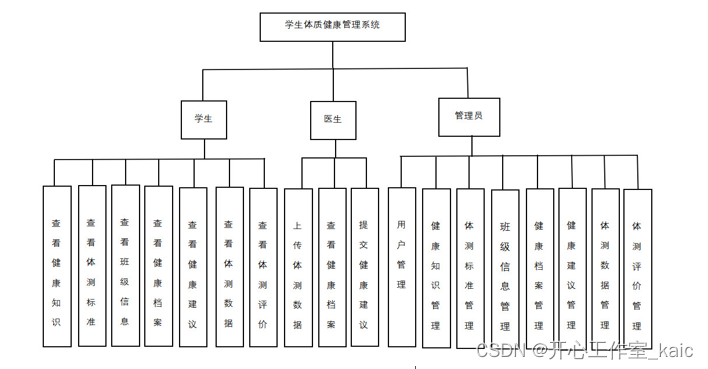
基于Java的学生体质健康管理系统的设计与实现(论文+源码)_kaic
摘 要 随着时代的进步,信息化也在逐渐深入融进我们生活的方方面面。其中也给健康管理带来了新的发展方向。通过对学生体质健康管理的研究与分析发现当下的管理系统还不够全面,系统的性能达不到使用者的要求。因此,本文结合Java的优势和流行性…...

【Linux系统】冯诺依曼与操作系统
什么是冯诺依曼体系结构? 如图即为冯诺依曼大致的体系结构图, 我们知道这些都是由我们的计算机硬件组成 输入设备:键盘, 鼠标, 摄像头, 话筒, 磁盘, 网卡... 输出设备:…...
——form表单的新增特性/h5的新特性)
前端理论总结(html5)——form表单的新增特性/h5的新特性
form表单的新增特性 range:范围 color:取色器 url:对url进行验证 tel:对手机号格式验证 email:对邮箱格式验证 novalidate :提交表单时不验证 form 或 input 域 numbe…...

基于TensorFlow的花卉识别(算能杯)%%%
Anaconda Prompt 激活 TensorFlow CPU版本 conda activate tensorflow_cpu //配合PyCharm环境 直接使用TensorFlow1.数据分析 此次设计的主题为花卉识别,数据为TensorFlow的官方数据集flower_photos,包括5种花卉(雏菊、蒲公英、玫瑰、向日葵…...

Android实现一周时间早中晚排班表
我们要做一个可以动态添加,修改一周早中晚时间排班表,需求图如下: one two 过程具体在这里不描述了,具体查看,https://github.com/yangxiansheng123/WorkingSchedule 上传数据格式: {"friday_plan":"…...
【Java八股面试系列】中间件-Redis
目录 Redis 什么是Redis Redis解决了什么问题 Redis的实现原理 数据结构 String 常用命令 应用场景 List(列表) 常用命令 应用场景 Hash(哈希) 常用命令 应用场景 set(集合) 常见命令编辑 应用场景 Sorted Set(有序集合) 常见命令编辑 应用场景 数据持…...

目前国内体验最佳的AI问答助手:kimi.ai
文章目录 简介图片理解长文档解析 简介 kimi.ai是国内初创AI公司月之暗面推出的一款AI助手,终于不再是四字成语拼凑出来的了。这是一个非常存粹的文本分析和对话工具,没有那些东拼西凑花里胡哨的AIGC功能,实测表明,这种聚焦是对的…...
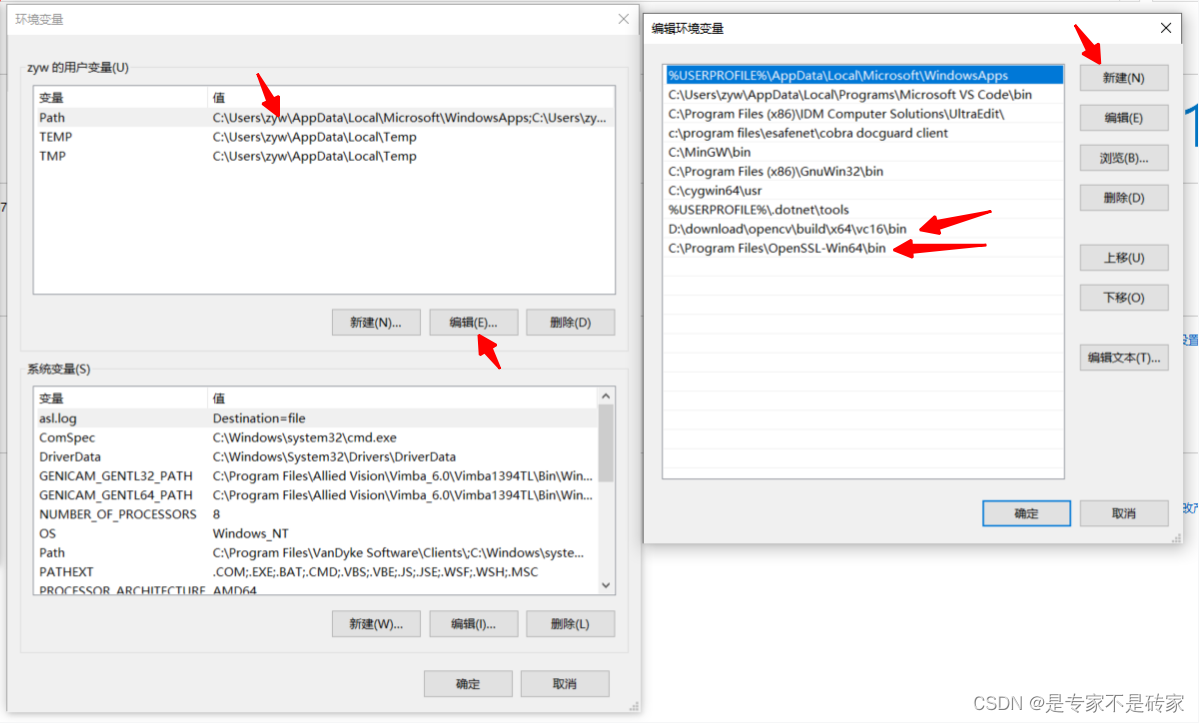
Visual Studio项目编译和运行依赖第三方库的项目
1.创建项目,这里创建的项目是依赖于.sln的项目,非CMake项目 2.添加第三方库依赖的头文件和库文件路劲 3.添加第三方依赖库文件 4.项目配置有2个,一个是Debug,一个是Release,如果你只配置了Debug,编译和运行…...

Rust 语言中 Vec 的元素的删除方法
在 Rust 中,Vec(向量)提供了多种删除元素的方法。以下是一些常用的删除方法: remove: 这是最常用的删除方法,它接受一个索引作为参数,并移除该索引处的元素,同时返回被移除的元素。所有后面的元…...

谈谈我对 AIGC 趋势下软件工程重塑的理解
作者:陈鑫 今天给大家带来的话题是 AIGC 趋势下的软件工程重塑。今天这个话题主要分为以下四大部分。 第一部分是 AI 是否已经成为软件研发的必选项;第二部分是 AI 对于软件研发的挑战及智能化机会,第三部分是企业落地软件研发智能化的策略…...
我在京东做数据分析,一位京东数据分析师的工作日常
有人说:“种下一棵树最好的时间是十年前,其次是现在”。任何时候,我们都应该抓住机遇,说不定就是改变你现状的一个机会。 2020年,我在疫情得到控制后,面试入职京东大数据组,截止目前࿰…...

数字乡村战略实施:科技引领农村经济社会全面发展
随着信息技术的快速发展,数字化已经成为推动经济社会发展的重要力量。在乡村振兴战略的大背景下,数字乡村战略的实施成为了引领农村经济社会全面发展的关键。本文将从数字乡村战略的内涵、实施现状、面临挑战及未来展望等方面,探讨科技如何引…...

Fiddler HTTPS抓包失败原因与证书信任机制详解
1. 为什么HTTPS抓包总在“证书这关”卡死?——不是Fiddler不行,是系统和APP联手设防Fiddler HTTPS抓包避坑指南:从证书安装失败到APP抓包不全的完整解决方案——这个标题里藏着太多人反复踩坑却始终没想通的真相。我带过三届移动测试团队&…...

不用开WPS会员了!这一款电子发票批量打印工具:支持排版 + OCR识别,完全免费!
软件下载 夸克下载:https://pan.quark.cn/s/39d9ed085809 软件介绍 今天给大家带来的是Office的代替品,LibreOffice不用激活、完全免费,非常好用! 软件支持Windows、macOS、Linux。它包括包含 Writer(文字处理&…...

2026免费在线去水印保姆级教程!不用下载,3秒去除,一看就会
你是不是也遇到过这种抓狂时刻?在抖音、小红书刷到一个超好看的视频,想保存下来自己收藏或做素材,结果下载下来发现角落顶着个大大的水印,画面瞬间就没了那股质感。更气的是,找了一堆号称“免费去水印”的软件…...

[开源] 病历自举报系统:面向临床质控的电子病历智能预审工具,用大模型扮演质疑者角色发现逻辑矛盾与缺项问题
本项目是一个专为中文电子病历(EMR)设计的轻量级质控辅助工具,核心目标是让医生在提交病历前,就能快速识别出文本中潜藏的逻辑矛盾、信息缺项、时间线错乱、数值异常和主观夸大等典型质量问题。我们不替代人工质控,也不…...

为什么你的Gemini总生成错误JOIN?深度拆解语义理解断层、外键缺失与上下文截断三大黑洞
更多请点击: https://intelliparadigm.com 第一章:为什么你的Gemini总生成错误JOIN?深度拆解语义理解断层、外键缺失与上下文截断三大黑洞 当Gemini面对多表SQL生成任务时,频繁输出逻辑错误的JOIN语句——例如对无关联字段的表强…...

MySQL 全文索引实战:搜索功能的正确打开方式
开场白 做搜索功能的时候,很多人第一反应是 LIKE ‘%关键词%’,数据量小的时候没问题,数据一大直接全表扫描。我之前有个项目,商品表的 LIKE 搜索在 50 万条数据时就要 3 秒以上,根本没法用。后来上了全文索引&#x…...

5分钟免费上手:AI换脸终极指南,用roop-unleashed创作专业级视频
5分钟免费上手:AI换脸终极指南,用roop-unleashed创作专业级视频 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 想要零基础制作电影…...

混沌系统预测方法全景评测:从线性回归到神经ODE的实战指南
1. 项目概述:混沌系统预测的“兵器谱”与实战评测在动力系统建模和时间序列预测这个行当里混了十几年,我见过太多同行面对混沌系统时那种“既爱又恨”的复杂心情。爱的是它背后深刻的物理内涵和广泛的应用前景,从大气湍流到金融市场ÿ…...

从岭回归到Lasso:正则化原理、稀疏性与ADMM算法实践
1. 项目概述:从岭回归到Lasso的深度解析在机器学习和统计建模的实践中,我们常常面临一个核心矛盾:模型在训练数据上表现优异,但在未见过的数据上却一塌糊涂,这就是所谓的“过拟合”。想象一下,你为了记住一…...

LSLib:游戏资源逆向工程的架构级解决方案
LSLib:游戏资源逆向工程的架构级解决方案 【免费下载链接】lslib Tools for manipulating Divinity Original Sin and Baldurs Gate 3 files 项目地址: https://gitcode.com/gh_mirrors/ls/lslib 面对《神界:原罪》和《博德之门3》等CRPG游戏复杂…...