冒泡排序 快速排序 归并排序 其他排序
书接上回..
目录
2.3 交换排序
2.3.1冒泡排序
2.3.2 快速排序
快速排序的优化:
快速排序非递归
2.4 归并排序
基本思想
归并排序非递归
海量数据的排序问题
排序算法时间空间复杂度和稳定性总结
四. 其他非基于比较排序 (了解)
2.3 交换排序
基本思想:所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置,交换排序的特
点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
2.3.1冒泡排序
遍历数组, 将最大值移动到最后, 再次遍历, 将第二大值移动到倒数第二个位置, 以此类推
思路:
代码:
- 一共需要遍历arr.length-1趟, 才能将所有的元素变有序
- 第1趟在遍历时, 需要交换arr.length-1次, 第2趟在编历时, 需要交换arr.length-1-1次...
- 我们可以优化一下代码, 即只需要交换arr.length-1-i次即可, i从0开始
- 进一步优化, 如果一趟遍历下来, .没有任何的交换进行, 则说明数组已经有序, 则不需再遍历, 直接return即可
public static void bubbleSort(int[] arr){for (int i = 0; i < arr.length-1; i++) {int flag = 0;for (int j = 0; j < arr.length-1-i; j++) {if(arr[j]>arr[j+1]){swap(arr,j,j+1);flag = 1;}}if(flag == 0){return;}}}
【冒泡排序的特性总结】
- 冒泡排序是一种非常容易理解的排序
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:稳定
2.3.2 快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
思路:
- 对[left,right]区间进行排序
- partition()方法的作用: 找到一个基准值pivot, 并将小于基准值的数都放在其左边, 大于基准值的数都放在其右边, 即将划分成以pivot边界的[left,pivot-1],[pivot+1,right]两部分
- 递归基准值的左边, 即[left,pivot-1]再次进行partition, 直到left>= right
- 递归基准值的右边, 即[pivot+1,right]再次进行partition, 直到left>= right
- 全部完成后数组就会变有序
代码:(非最终)
public static void quickSort(int[] arr){quick(arr,0,arr.length-1);}private static void quick(int[] arr,int left,int right){if(left >= right){return ;}int pivot = partition(arr,left,right);quick(arr,left,pivot-1);quick(arr,pivot+1,right);}
将区间按照基准值划分为左右两半部分的常见方式有:
1. Hoare法
假设数组的第一个数就是基准值, 运用交换的思想
思路:
- 将left赋给pivot, 创建变量i = left; j = right,用来遍历数组
- i从前面遍历, 找到比arr[pivot]大的数, 停下来, j从后面遍历,找到比arr[pivot]小的数, 停下来, 交换这两个下标的值, 这样就把比arr[pivot]小的数放前面, 比arr[pivot]大的数放后面
- 继续遍历, 直到i>=j, 停止
- 此时交换i和pivot的值,返回i下标, 即基准值的下标
代码:
private static int partition(int[] arr,int left,int right){int i = left;int j = right;int pivot = left;while(i < j){while(i < j && arr[j] >= arr[pivot]){j--;}while(i < j && arr[i] <= arr[pivot]){i++;}swap(arr,i,j);}swap(arr,i,pivot);return i;}
思考:
1. 上述里层while循环, 判断条件一定是>= <= 吗?不取等行不行?
答案: 不行, 因为如果不加等号, 左右两边都是相同的数字时, 进不去里层循环, 外层循环死循环
2. 以左边作为基准时, 为什么一定要从右边先开始找, 而不是左边?
答案: 如果从左边开始找, 那么左右相遇的地方可能是比基准值大的数字, 那么进行交换后, 就不满足基准值左边的数都小于右边, 反之, 如果从右边开始找, 那么左右相遇的地方一定是比基准值小的数字, 这时与左边的基准值进行交换, 小的数换到左边, 满足基准值左边的数都小于右边
2. 挖坑法
假设数组的第一个数就是基准值, 运用覆盖的思想
思路:
- 将数组第一个下标的值存起来给pivot,挖坑pivot的位置, 创建变量i = left; j = right,用来遍历数组
- i从前面遍历, 找到比arr[pivot]大的数, 停下来, 将arr[j]放在arr[i]的位置, 此时i = 0, 在arr[j]的位置挖坑,j从后面遍历,找到比arr[pivot]小的数, 停下来,将arr[i]放在arr[j]的位置,在arr[i]的位置挖坑
- 继续遍历, 直到i >= j, 停止
- 最后放pivot的值放在arr[i]这个坑中即可, 返回基准值所在的下标i
代码:
private static int partition(int[] arr,int left,int right){int i = left;int j = right;int pivot = arr[left];while(i < j){while(i<j && arr[j] >= pivot){j--;}arr[i] = arr[j];while(i<j && arr[i] <= pivot){i++;}arr[j] = arr[i];}arr[i] = pivot;return i;}
3. 前后指针(了解)
private static int partition(int[] array, int left, int right) {
int prev = left ;
int cur = left+1;
while (cur <= right) {
if(array[cur] < array[left] && array[++prev] != array[cur]) {
swap(array,cur,prev);
}
cur++;
}
swap(array,prev,left);
return prev;
}快速排序的优化:
1. 三数取中法选key
拿到left = 0, right = arr.length-1, 和mid为中间下标, 可以表示为mid = left + ((right-left)>>1), 比较这三个数的大小, 将中间大小的数字作为基准值, 这样可以保证基准值的左右两边都有数据, 减小时间复杂度
private static int middleNum(int[] arr,int left,int right){int mid = left + ((right-left)>>1);if (arr[left] < arr[right]){if(arr[mid] < arr[left]){return left;}else if(arr[mid] > arr[right]){return right;}else{return mid;}}else{if(arr[mid] < arr[right]){return right;}else if(arr[mid] > arr[left]){return left;}else{return mid;}}}private static void quick(int[] arr,int left,int right){if(left >= right){return ;}//优化1int index = middleNum(arr,left,right);swap(arr,index,left);int pivot = partition(arr,left,right);quick(arr,left,pivot-1);quick(arr,pivot+1,right);}2. 递归到小的子区间时,可以考虑使用插入排序
当区间变小时, 再使用递归的方法进行排序, 会浪费时间, 所以当区间小于一个数(假设10)时, 就采用直接插入排序, 提高效率
private static void quick(int[] arr,int left,int right){if(left >= right){return ;}//优化1int index = middleNum(arr,left,right);swap(arr,index,left);//优化2if(right-left+1 <= 10 ){insertSort2(arr,left,right);return;}int pivot = partition(arr,left,right);quick(arr,left,pivot-1);quick(arr,pivot+1,right);}public static void insertSort2(int[] arr,int left,int right){for (int i = 1 + left; i <=right ; i++) {int tmp = arr[i];int j = i-1;for ( ; j >= 0; j--) {if(arr[j] > tmp){arr[j+1] = arr[j];}else{//arr[j+1] = tmp;break;}}arr[j+1] = tmp;}}快速排序非递归
思路:
- 使用partition方法找到基准值的下标
- 判断如果基准值的左边不止有一个数据, 即pivot-1 > left, 则需要继续划分, 则将这一划分的左右坐标分别压入栈中, 注意在出栈时先右后左
代码:
public static void quickSortNorR(int[] arr){int left = 0;int right = arr.length-1;int pivot = partition(arr,left,right);Stack<Integer> stack = new Stack<>();if(pivot - 1 > left){stack.push(left);stack.push(pivot - 1);}if(pivot + 1 < right){stack.push(pivot+1);stack.push(right);}while(!stack.isEmpty()){right = stack.pop();left = stack.pop();pivot = partition(arr,left,right);if(pivot - 1 > left){stack.push(left);stack.push(pivot - 1);}if(pivot + 1 < right){stack.push(pivot+1);stack.push(right);}}}
快速排序总结
- 时间复杂度:O(N*logN)
- 空间复杂度:O(logN)
- 稳定性:不稳定
- 快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序
2.4 归并排序
基本思想
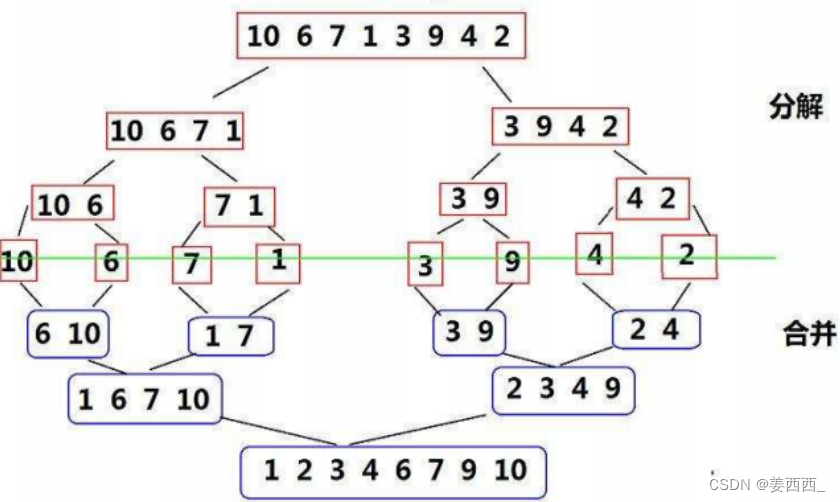
思路:
- 归并排序分为两部分, 分解和合并, 分解我们运用到的思路是递归, 合并我运用到的思路是用新数组存储有序序列, 再赋值给原数组
- 分解: 找到数组的中间下标mid, 左下标left, 右下标right, 将数组分解成[left, mid] 和[mid+1,right], 递归分解, 直到只剩下一个元素
- 合并:将两组数据的头和尾分别定义成s1e1 和s2e2, s1和s2依次进行比较, 小的就存放在新数组里, 并++,直到有一个数组的s1 > s2, 结束比较, 直接将另一组数据剩下的加到新数组的后面, 最后将新数组赋值给原数组, 注意: 新数组和原数组的对应关系是:arr[i+left] = tmpArr[i]
代码:public static void mergeSort(int[] arr){mergeFunc(arr,0,arr.length-1);}private static void mergeFunc(int[] arr,int left,int right){if(left >= right){return ;}int mid = left+((right-left)>>1);mergeFunc(arr,left,mid);mergeFunc(arr,mid+1,right);merge(arr,left,mid,right);}private static void merge(int[] arr, int left,int mid,int right){int s1 = left;int s2 = mid +1;int e1 = mid;int e2 = right;int[] tmpArr = new int[right-left+1];int k = 0;while(s1 <= e1 && s2 <= e2){if(arr[s1] > arr[s2]){tmpArr[k++] = arr[s2++];}else{tmpArr[k++] = arr[s1++];}}while(s1 <= e1){tmpArr[k++] = arr[s1++];}while(s2 <= e2){tmpArr[k++] = arr[s2++];}for (int i = 0; i < k; i++) {arr[i+left] = tmpArr[i];}}
归并排序非递归
思路:
- 设gap, 表示几个元素为一半, 归并是将一组分成两半进行比较的,比较的事交给merge方法, 我们只需要知道怎么分组, 并找好下一组的位置, 每次gap*=2, 当gap >arr.length时, 说明已经全部有序了
- 用 i 来遍历数组找位置, i=0 时, 那么第一组的left就是0, mid就是left+gap-1, right就是mid+gap, 注意:为了防止mid和right越界, 当mid right>= arr.length时, 说明超过了数组的大小, 只需将他们设置成最后一个元素即可
- i在找下一组时, i应该等于i+2*gap, 因为一组的长度为2*gap
代码:
public static void mergeSortNorR(int[] arr){int gap = 1;while(gap < arr.length){for (int i = 0; i < arr.length; i=i+2*gap) {int left = i;int mid = left + gap -1;if(mid >= arr.length){mid = arr.length-1;}int right = mid +gap;if(right >= arr.length){right = arr.length-1;}merge(arr,left,mid,right);}gap *= 2;}}
归并排序总结
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
- 稳定性:稳定
海量数据的排序问题
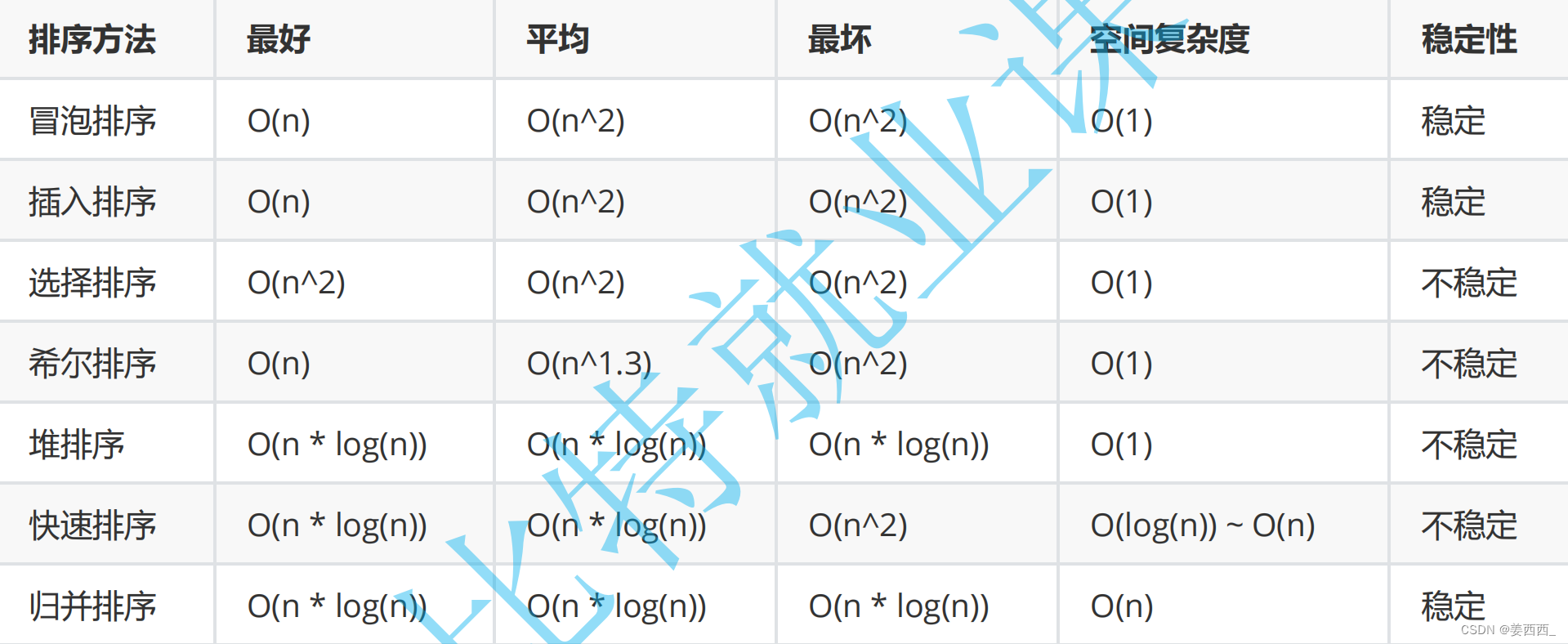
排序算法时间空间复杂度和稳定性总结
四. 其他非基于比较排序 (了解)
1. 计数排序
- 统计相同元素出现次数
- 根据统计的结果将序列回收到原来的序列中

- 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
- 时间复杂度:O(MAX(N,范围))
- 空间复杂度:O(范围)
- 稳定性:稳定
2. 基数排序
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。
步骤:
- 先比较个位数字, 依次放在有顺序的10个队列中, 分别代表数字0~9, 然后从第一个队列开始出队
- 再按照十位数字比较, 继续放入, 再出队, 循环最大数字的位数次结束
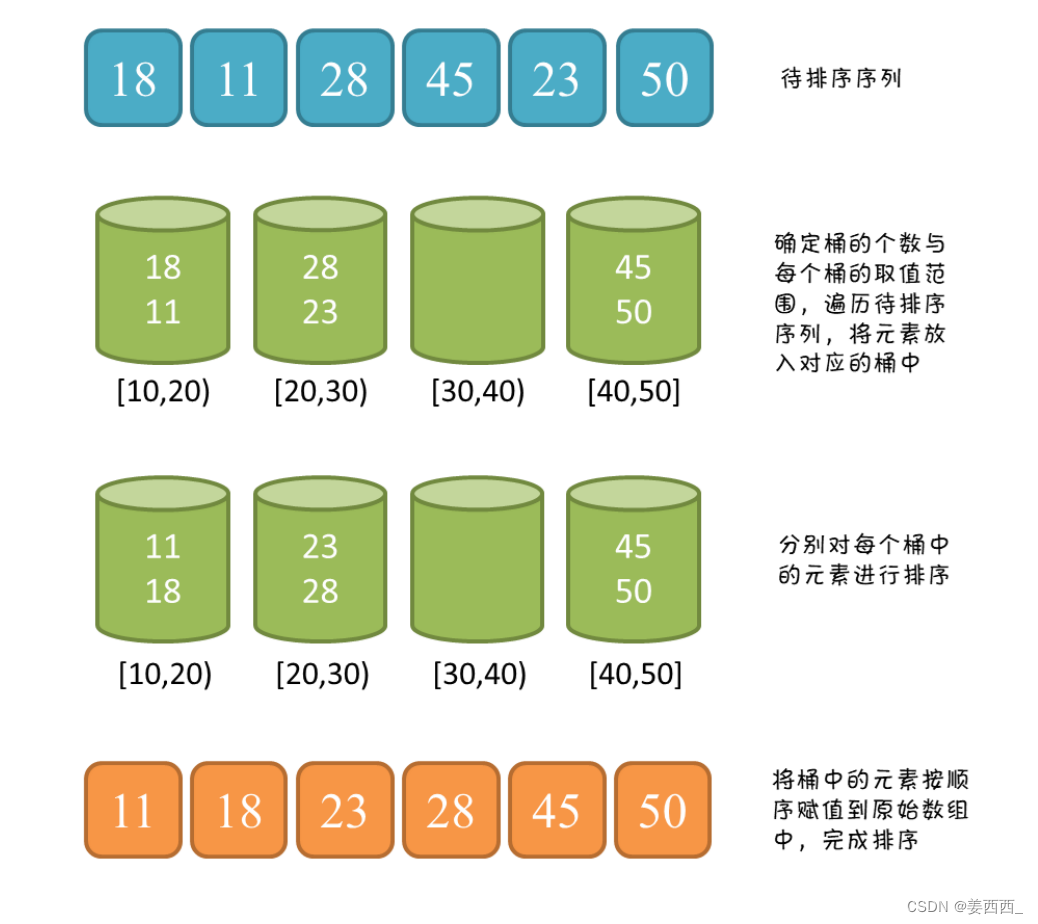
3. 桶排序
思想:划分多个范围相同的区间,每个子区间自排序,最后合并。
相关文章:
冒泡排序 快速排序 归并排序 其他排序
书接上回.. 目录 2.3 交换排序 2.3.1冒泡排序 2.3.2 快速排序 快速排序的优化: 快速排序非递归 2.4 归并排序 基本思想 归并排序非递归 海量数据的排序问题 排序算法时间空间复杂度和稳定性总结 四. 其他非基于比较排序 (了解) 2.3 交换排序 基本思想:…...

阿里云服务器安装MySQL(宝塔面板)
只写关键步骤 1. 创建一个云服务器实例 2 修改密码,登录服务器 3. 安装宝塔面板 进入https://www.bt.cn/new/index.html 进入宝塔面板地址 4. 安装Mysql 5. 创建数据库(可导入数据库) 6. 测试连接数据库 打开Navicat(或其他数据…...
)
设计模式|发布-订阅模式(Publish-Subscribe Pattern)
文章目录 初识发布-订阅模式发布-订阅模式的关键概念发布订阅模式的优缺点示例代码(使用 Java 实现)有哪些知名框架使用了发布-订阅模式常见面试题 初识发布-订阅模式 发布-订阅模式(Publish-Subscribe Pattern)是一种软件架构设…...

根据疾病名生成病例prompt
prompt 请根据疾病名:" disease_name " 为我生成一份病历。下面是病历内容的要求:病例应严格包含如下几项: 性别,年龄,疾病名(必须是" disease_name "),主诉ÿ…...

HarmonyOS网格布局:List组件和Grid组件的使用
简介 在我们常用的手机应用中,经常会见到一些数据列表,如设置页面、通讯录、商品列表等。下图中两个页面都包含列表,“首页”页面中包含两个网格布局,“商城”页面中包含一个商品列表。 上图中的列表中都包含一系列相同宽度的列表…...
NASA数据集—— 1984-2019年湖泊生长季绿色表面反射率趋势数据集
ABoVE: Lake Growing Season Green Surface Reflectance Trends, AK and Canada, 1984-2019 简介 该数据集提供了1984年至2019年期间ABoVE扩展研究域内472,890个湖泊的大地遥感卫星绿色表面反射率年度时间序列和衍生的年度生长季节(6月和7月)趋势。反射…...
DMA知识
提示:文章 文章目录 前言一、背景二、 2.1 2.2 总结 前言 前期疑问: 本文目标: 一、背景 2024年3月26日23:32:43 今天看了DMA存储器到存储器的DMA传输和存储器到外设的DMA实验,在keil仿真可以看到效果。还没有在protues和开发…...

Linux 系统 docker快速搭建PHP环境
PHP安装 ############################################################################# 1、直接拉取官方镜像 查找Docker Hub上的php镜像 docker search php 直接拉取官方镜像 docker run --name myphp --restartalways --network lnmp -d php:7.1-fpm 2、创建php容…...

逻辑设计问题 -- 设计一个函数
文章目录 设计一个函数函数接口规格说明运算符或者非运算符自由或成员运算符虚函数或非虚函数纯虚函数或者非纯虚函数静态或者非静态成员函数const 成员函数或者非const成员函数公共的、保护的或者私有的成员函数通过值、引用或者指针返回返回const 或者非const可选参数或者必要…...

RHCE 补充:判断服务状态
内容补充:判断服务状态 systemctl 命令 系统控制管理命令工具 常用指令 1、启动 systemctl start 程序名 若要启动多个程序名,使用空格隔开,下同 2、重启:类似主机先断电再启动的一个状态 systemctl restart 程序名 3、停…...

计算机网络:物理层 - 编码与调制
计算机网络:物理层 - 编码与调制 基本概念编码不归零制编码归零制编码曼彻斯特编码差分曼彻斯特编码 调制调幅调频调相混合调制 基本概念 在计算机网络中,计算机需要处理和传输用户的文字、图片、音频和视频,他们可以统称为消息数据…...

《量子计算:揭开未来科技新篇章》
随着科技的不断发展,量子计算作为一项颠覆性的技术逐渐走进人们的视野,引发了广泛的关注和探讨。本文将围绕量子计算的技术进展、技术原理、行业应用案例、未来趋势预测以及学习路线等方向,深入探讨这一领域的前沿动态和未来发展趋势。 量子…...

机器人机械手加装SycoTec 4060 ER-S电主轴高精密铣削加工
随着科技的不断发展,机器人技术正逐渐渗透到各个领域,展现出前所未有的潜力和应用价值。作为机器人技术的核心组成部分之一,机器人机械手以其高精度、高效率和高稳定性的优势,在机械加工、装配、检测等领域中发挥着举足轻重的作用…...

docker 共享内存不足问题
在启动容器时增加共享内存大小: 您可以通过在docker run命令中添加--shm-size参数来指定更大的共享内存大小。例如,如果您需要32GB的共享内存,可以这样做: docker run --shm-size32g -it your-docker-image 这里的your-docker-im…...

英语口语 3.27
keep It straight :竖着放 turn it to the side:横过来放 i get my shit done:shit(everything)任何事情 我都会去做的 that‘s what’s up 可以的可以的 thats cool zodiac sign :生肖 座 i sense that :我感受到了 talent”艺人 influencer:有影响力的人 …...
pytest之统一接口请求封装
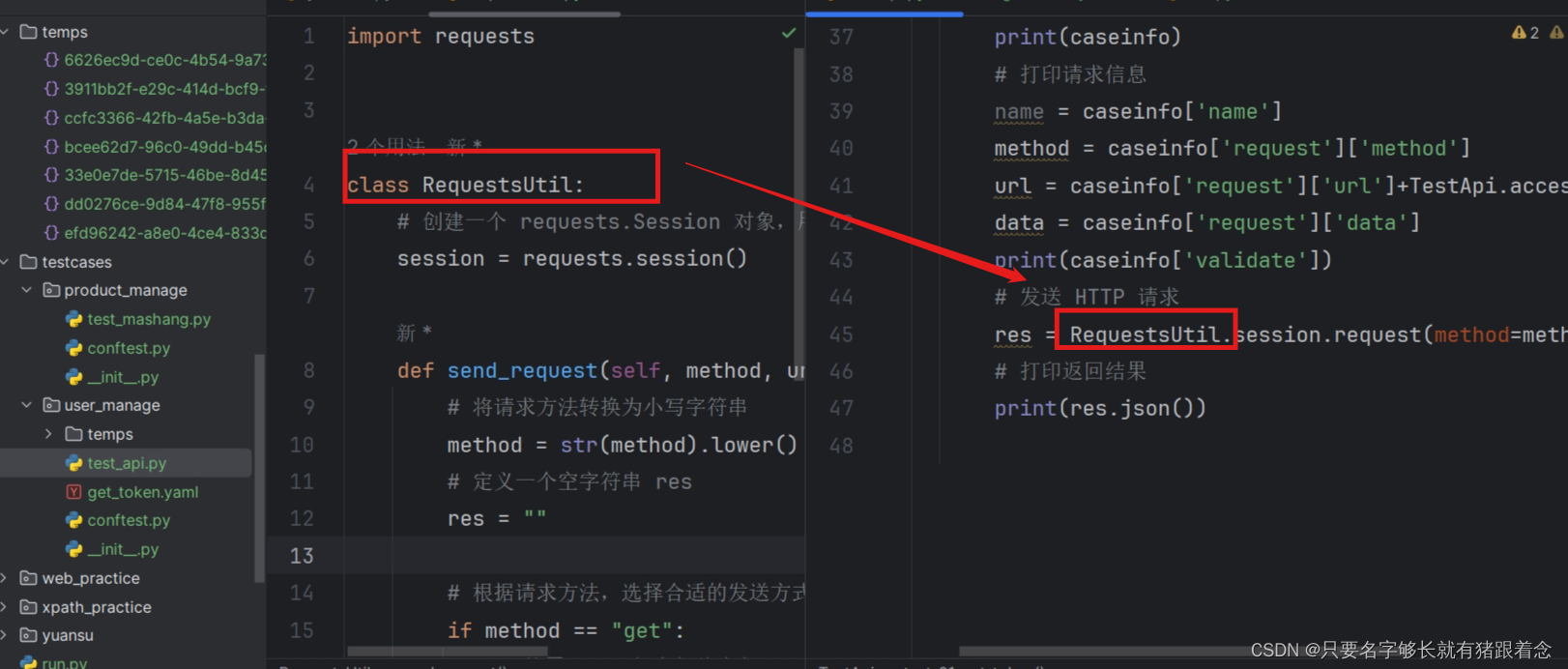
pytest之统一接口请求封装 pytest的requests_util.pyrequests_util.py 接口自动化测试框架的封装yaml文件如何实现接口关联封装yaml文件如何实现动态参数的处理yaml文件如何实现文件上传有参数化时候,怎么实现断言yaml的数据量大怎么处理接口自动化框架的扩展&#…...
使用npm仓库的优先级以及.npmrc配置文件的使用
使用npm仓库的优先级以及.npmrc配置文件的使用 概念如何设置 registry(包管理仓库)1. 设置项目配置文件2. 设置用户配置文件3. 设置全局配置文件4. .npmrc文件可以配置的常见选项 概念 npm(Node Package Manager)是一个Node.js的…...

Netty源码剖析——ChannelHandlerContext 篇(三十七)
ChannelHandlerContext 作用及设计 ChannelHandlerContext 继承了出站方法调用接口和入站方法调用接口 ChannelOutboundInvoker 和 ChannelInboundInvoker 部分源码 这两个invoker就是针对入站或出站方法来的,就是在入站或出站 handler 的外层再包装一层,…...

5.92 BCC工具之bitesize.py解读
一,工具简介 bitesize工具按进程名称显示请求块大小的I/O分布。 它通过监视磁盘上的读取和写入操作,记录每个操作的大小。再将跟踪到的 I/O 操作按照大小分组,通常是以 2 的幂次方(如 4K、8K、16K 等)进行划分,并统计每个大小范围内的 I/O 操作数量。 二,代码示例 #…...
jupyter notebook导出含中文的pdf(LaTex安装和Pandoc、MiKTex安装)
用jupyter notebook导出pdf时,因为报错信息,需要用到Tex nbconvert failed: xelatex not found on PATH, if you have not installed xelatex you may need to do so. Find further instructions at https://nbconvert.readthedocs.io/en/latest/install…...

可视化跨平台Node.js管理:如何告别命令行依赖,实现高效多版本切换
可视化跨平台Node.js管理:如何告别命令行依赖,实现高效多版本切换 【免费下载链接】nvm-desktop Node Version Manager Desktop - A desktop application to manage multiple active node.js versions. 项目地址: https://gitcode.com/gh_mirrors/nv/n…...

三步搞定Windows和Office永久激活:KMS智能激活终极指南
三步搞定Windows和Office永久激活:KMS智能激活终极指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然变成只…...

RAID5瘫痪抢救实录:硬盘物理故障下的数据恢复实战
1. 这不是数据丢失预警,而是RAID5信任危机的现场直播“凌晨三点,监控告警邮件炸了——/dev/md0状态DEGRADED,紧接着是两块盘离线。”这是我上个月在值班日志里写下的第一行字。没有夸张,没有铺垫,就是这么一句干巴巴的…...

终极指南:3步解锁网易云音乐NCM格式的完整Windows解决方案
终极指南:3步解锁网易云音乐NCM格式的完整Windows解决方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的歌曲&…...

别再手动改Hex了!用Vector HexView的/remap命令,5分钟搞定固件地址重映射
嵌入式开发革命:Vector HexView自动化重映射技术实战指南 在汽车电子和物联网设备开发中,固件地址调整如同家常便饭。每当内存布局变更、Bootloader升级或外设地址重新分配时,嵌入式工程师们就不得不面对一项枯燥且容易出错的任务——手动修改…...

使用C#代码在 PowerPoint 中组合或取消组合形状
在 PowerPoint 中,对形状进行组合和取消组合是两个非常实用的功能。通过组合,您可以将多个形状整合为一个整体,从而像操作单个对象一样同时移动、设置格式、调整大小或旋转这些形状。而取消组合则可以解除这些形状之间的关联,使您…...

海光3330E工控机实战:工业边缘计算与国产x86平台部署指南
1. 项目概述:当工业智能化遇见“中国芯”最近在为一个工业视觉检测的项目选型硬件平台,客户的要求很明确:稳定、可靠、能长时间在产线恶劣环境下跑,还得有足够的算力处理实时图像分析。在对比了市面上常见的几款基于x86或ARM架构的…...
)
手把手教你修复‘MsBuild.exe不是内部或外部命令’(附Win10/Win11环境变量配置详解)
手把手教你解决‘MsBuild.exe不是内部或外部命令’问题 第一次在命令行里敲下msbuild却看到系统报错"不是内部或外部命令"时,那种挫败感我至今记忆犹新。作为.NET开发者必备的核心工具,MSBuild的配置问题困扰过无数新手。本文将用最直观的方式…...

如何高效下载QQ音乐资源:5个简单步骤掌握res-downloader嗅探技术
如何高效下载QQ音乐资源:5个简单步骤掌握res-downloader嗅探技术 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...

Keil µVision TAB显示异常问题分析与解决方案
1. 问题现象与背景分析在Keil Vision集成开发环境中,部分用户遇到了编辑器界面显示异常的问题。具体表现为:当代码中包含TAB字符(制表符)时,屏幕上会出现奇怪的显示错乱,原本应该显示为空白缩进的区域&…...