【C++】list的使用和基本迭代器框架的实现 vs和g++下string结构的说明
真正的成熟应该并不是追求完美,而是直面自己的缺憾,这才是生活的本质。

文章目录
- 一、初见list
- 1.list的迭代器失效和基本使用
- 2.list的operations操作接口(看起来挺不错的接口,但可惜不怎么实用)
- 3.vector和list的排序性能对比(list的sort接口不常用的原因:list的排序效率不高)
- 二、list迭代器的基本框架(结构体指针无法满足需求,类封装+运算符重载让迭代器的行为像指针一样)
- 三、vs和g++下string结构的说明
- 1.vs下的string结构
- 2.g++下的string结构
一、初见list
1.list的迭代器失效和基本使用
1.
list的底层是由带头双向循环链表实现的,与vector和string不同的是,list的遍历要通过迭代器来实现,就算我们不知道list迭代器的底层实现机制,但并不影响我们使用迭代器,这就是迭代器对于所有容器带来的好处,无论你是什么容器,都有统一的遍历方式,那就是迭代器。
2.
范围for的实现,本质就是通过迭代器,范围for可以遍历容器的迭代器,对迭代器进行解引用,然后依次拷贝给元素e,所以C++11的范围for没有什么新花样,本质上使用的还是迭代器实现的。在编译器编译代码的时候,会傻瓜式的将范围for替换为迭代器的代码,然后进行编译运行。
3.
数据结构初阶阶段所使用的尾插尾删,头插头删,对于list依旧可以正常使用。
void test_list1()
{list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);list<int>::iterator it = lt.begin();//迭代器属于类的内嵌类型while (it != lt.end()){cout << *it << " ";++it;}cout << endl;lt.push_front(10);lt.push_front(20); lt.push_front(30);lt.push_front(40);for (int e : lt){cout << e << " ";}cout << endl;lt.pop_back();lt.pop_back();lt.pop_front();lt.pop_front();for (int e : lt){cout << e << " ";}cout << endl;
}
4.
对于list来说,和vector一样,我们可以用迭代器区间配合find进行元素对应的某一个节点的查找,并返回该节点对应的迭代器位置。
5.
在list这个容器中,只要对某一个节点进行操作,就离不开迭代器,迭代器就是list的唯一,因为像链表这样的数据结构他是无法支持随机访问的,所以通过下标随机访问的方式是不可行的,那么我们就只能通过STL提供的迭代器来对某一节点进行操作。
6.
对于list来说,insert不会导致迭代器失效,vector存在迭代器失效是因为在扩容时reserve采取异地扩容的方式,这就导致原有迭代器指向了已经被释放的空间。
但list并不存在扩容这样的操作,list直接按需申请空间,你要插入多少个节点,那我就申请多少个节点,然后将所有的节点链接到头结点后面就好了,所以insert之后迭代器依旧可以继续使用,因为他对应的节点空间不会被销毁,依旧好好的存在着。
7.
而对于erase来说就不一样了,erase会释放迭代器对应节点的空间,自然erase之后迭代器就会失效,如果想要继续使用迭代器,则可以利用erase的返回值,erase会返回被删除节点的下一个节点的迭代器,我们可以用erase的返回值来更新迭代器。
void test_list2()
{list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);list<int>::iterator pos = find(lt.begin(), lt.end(), 3);if (pos != lt.end()){lt.insert(pos, 30);//insert之后,pos迭代器肯定不会失效。}cout << *pos << endl;(*pos)++;for (int e : lt){cout << e << " ";}cout << endl;lt.erase(pos);//erase之后,迭代器会失效,因为节点空间被释放了cout << *pos << endl;for (int e : lt){cout << e << " ";}cout << endl;
}
2.list的operations操作接口(看起来挺不错的接口,但可惜不怎么实用)
1.
resize用于调整链表的空间,如果是调整大一些,那就是一个一个的申请节点,尾插到链表上面去。
如果是调整小一些,那也需要一个个的释放节点,相当于尾删节点。
但这个接口list不喜欢用。
2.
clear用于释放除头结点之外的所有节点,调用clear之后,链表的size大小也就变为了0,但需要和析构函数区分开来,析构函数会将头结点的空间也给释放掉,而clear仅仅只是将存储有效数据的所有节点释放掉。后面list模拟实现之后,就会有一个更深层次的理解。

3.
下面的operations的操作接口用的非常少,就是看起来确实挺有用的感觉挺不错,但在实际应用的时候就不怎么常用了,这也就是库的设计者在想的时候,想的很好,但是在程序员实际使用的时候并没有那么的实用。
这就是在做计划的时候,设计的很好,但等到实际使用的时候,发现没啥用,价值不大。
4.
remove相当于find+erase,可用于链表中某个具体节点的删除,如果删除的数据不存在,则什么也不会发生,并不会报错。
5.
链表单独提供了一个排序接口sort,而没有用算法库里面的sort,这其实就涉及到迭代器的类型问题。
迭代器从功能上来说,可以分为三类:只能++的单向迭代器(单链表、哈希表),既能++也能 - - 的双向迭代器(list带头双向循环链表),既能++也能 - - 还能±某个具体的数的随机迭代器(string、vector)。
6.
算法库的sort底层用的是快速排序,为了key值选的合适,快排会进行三数取中,所以会进行迭代器的作差,而list的双向迭代器肯定不支持做差,所以调用算法库的sort就会报错。
如果想要排序链表,那就只能调用list类的成员函数sort来进行排序,list的sort底层用的是归并排序。


7.
unique可以对链表进行去重,但去重必须建立在排序的基础之上,如果不排序就去重,则去重的结果会发生问题。
挨着的相同数字会被去重,如果不挨着,unique调用后的结果就会出错,这一点有点像去除数组中重复元素那个题,快慢指针法进行去重,那个我记得也是建立在有序的情况下进行重复元素的删除的,这里的unique的道理和快慢指针相同。
8.
merge可以合并两个链表,reverse用于逆置链表,splice可以转移一个链表的节点或某一区间的节点或所有节点,到另一个链表上面去。
//operations操作接口:有用,但用处不大,和我们做的时间规划表一样,想的挺好,但在实际用的时候,并没有那么常用。
void test_list3()
{list<int> lt;lt.push_back(1);lt.push_back(9);lt.push_back(5);lt.push_back(2);lt.push_back(5);lt.push_back(2);for (int e : lt){cout << e << " ";}cout << endl;lt.remove(3);//remove=find+eraselt.remove(30);//如果删除的元素不存在,则什么也不会发生for (int e : lt){cout << e << " ";}cout << endl;lt.sort();//链表单独提供一个排序,没有用算法库里面的//sort(lt.begin(), lt.end());//这样进行链表排序是不行的//迭代器功能分类://1.单向迭代器 ++ 单链表//2.双向迭代器 ++ -- list//3.随机迭代器 ++ -- + - vector&&stringfor (int e : lt){cout << e << " ";}cout << endl;//必须先排序,再去重lt.unique();//去重算法是建立在有序的基础上。去重有点像快慢指针删除数组重复元素,所以如果重复数字不挨着,unique就会出现错误。for (int e : lt){cout << e << " ";}cout << endl;lt.reverse();逆置lt.merge();归并lt.splice();拼接转移
}
3.vector和list的排序性能对比(list的sort接口不常用的原因:list的排序效率不高)
1.
测试排序性能,建议在release版本下面进行测试,debug版本下会由于编译器版本的差异产生不同的现象,对于性能的测试release版本下面更加准确,debug底层会由于某些优化等等导致产生的结果不够精确。
2.
在数据量大概是十万左右的情况下,vector的排序性能大概是list排序性能的二倍左右,所以说list的排序性能很低了,相对于vector。
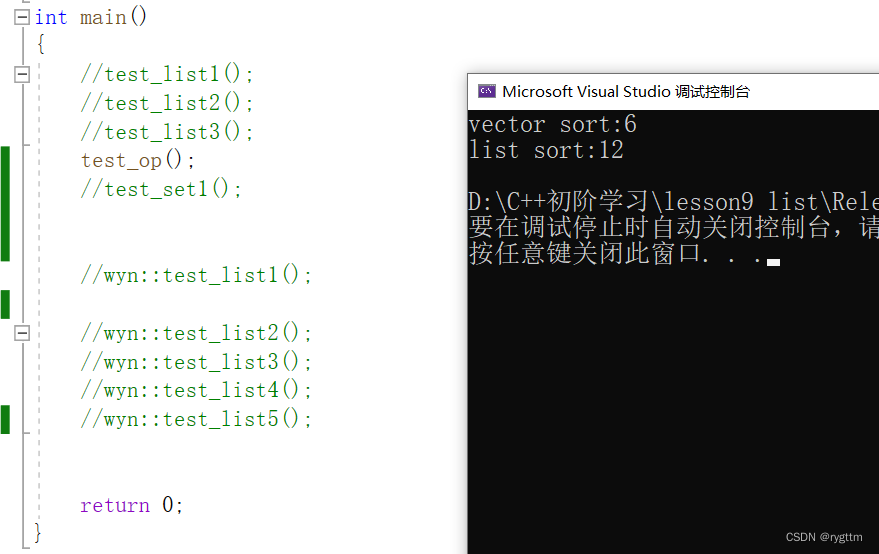
3.
有人做过比喻,如果你要排序list,倒不如先将list的数据拷贝到vector进行排序,等排完序再将数据拷贝回list里面去,就算这样的排序的性能都是要比直接用list进行排序的性能要高不少。从结果可以看到,vector的排序性能明显要高于list。
当然如果数据量很小的话,vector和list的差别就没有那么大了,那时候的排序时间就相差无几了。
4.
所以,如果在数据量很大的情况下,排序不会选择list的sort,其实主要是list的空间不连续,在访问不连续的空间时,消耗时间还是蛮大的。而连续的vector空间在访问时,消耗就比较小,CPU高速缓存的命中率也高,这也正是vector数据结构独有的优势。
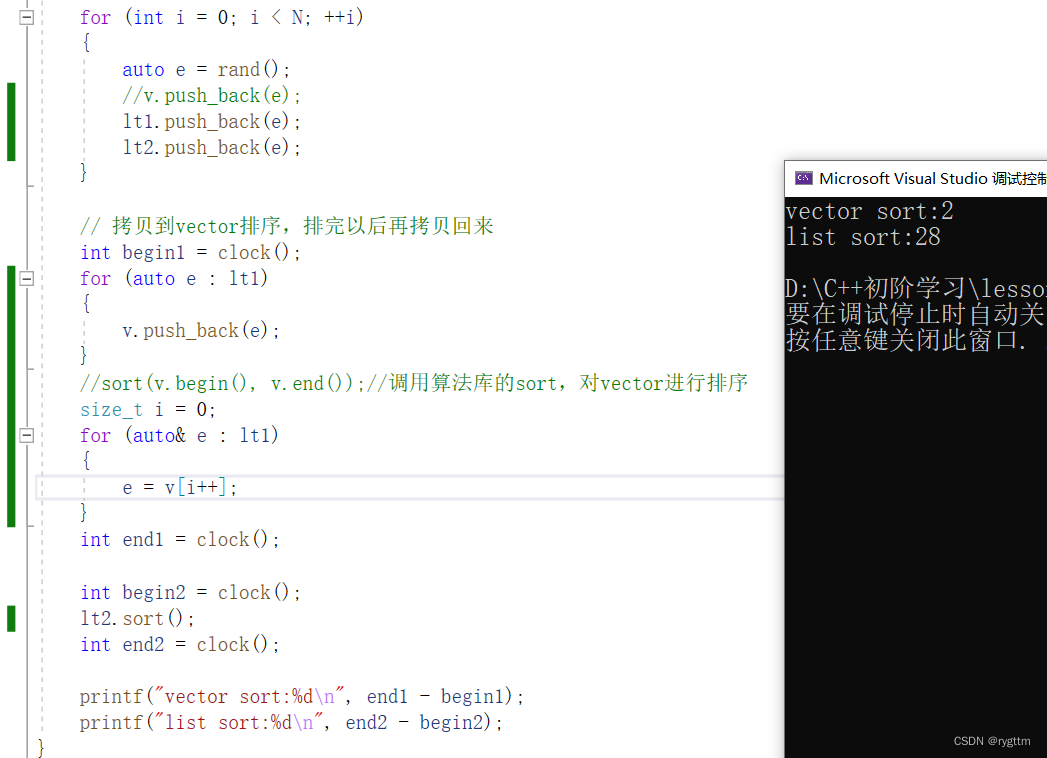
5.
如果不头插头删,vector就比较好,如果频繁头插或中间插入删除等,list的结构优势就体现出来了,因为vector是连续的空间,list是一个一个的节点,一个需要挪动数据,一个不需要挪动数据。
//1.vector排序和链表排序的性能对比,所以如果你要排序,就不要将数据放到链表里面去,这也正是链表的sort接口不常用的原因。
//2.N个数据需要排序,vector+ 算法sort list+ sort
void test_op()//优化这部分直接看release版本即可,debug版本对于不同的结构在底层优化达到的效果都不太一样。主要看release即可。
{srand(time(NULL));const int N = 100000;vector<int> v;v.reserve(N);list<int> lt1;list<int> lt2;for (int i = 0; i < N; ++i){auto e = rand();v.push_back(e);lt1.push_back(e);//lt2.push_back(e);}// 拷贝到vector排序,排完以后再拷贝回来int begin1 = clock();//for (auto e : lt1)//{// v.push_back(e);//}sort(v.begin(), v.end());//调用算法库的sort对vector进行排序//size_t i = 0;//for (auto& e : lt1)//{// e = v[i++];//}int end1 = clock();int begin2 = clock();lt1.sort();int end2 = clock();printf("vector sort:%d\n", end1 - begin1);printf("list sort:%d\n", end2 - begin2);
}
二、list迭代器的基本框架(结构体指针无法满足需求,类封装+运算符重载让迭代器的行为像指针一样)
1.
C++为了能够支持泛型编程,搞出来内置类型的构造,实则编译器会在这里进行特殊处理,区分开泛型和内置类型,使用时,可以用类型的构造函数来进行初始化,内置类型一般初始化为0等值,自定义类型会调用该类的默认构造。

2.
迭代器是类的内嵌类型,行为像指针一样,可以解引用和++或 - - 。
vector和string的迭代器都是由原生指针实现的,那是因为他们的底层是一个动态的顺序表,内存是连续的,解引用迭代器就是解引用原生指针,那自然就可以拿到对应数组位置的内容,而list的迭代器对应的是一个结构体,是一个自定义类型,并非原生指针的内置类型,所以解引用迭代器我们拿到的是结构体对象,而并非是数据内容,这就不符合迭代器的特征,因为迭代器的本意就是要解引用拿到数据,而我们拿到的是一个结构体对象,这就有问题了。
所以这个时候我们就需要类封装和运算符重载来实现list的迭代器了,以便于他的迭代器能够解引用和++或 - - ,只要用运算符重载,当然就离不开类,解引用迭代器能够获得对应结构体数据,则迭代器就不简单是一个原生指针了,他应该是一个对象,这个对象的类成员函数可以实现解引用++ - - 等功能。
3.
这就好比年月日不支持++ - - 等操作,那我们就封装一个日期类,在日期类里面实现日期的++ - - 等操作。这里的迭代器也是这个意思,你普通的结构体指针node *不是不支持解引用拿到数据,++ - - 等操作吗?那我就封装一个类,在这个类里面利用运算符重载,让你的结构体指针node *支持迭代器操作,这不就好了吗?
4.
用一个结点的指针就可以作为list迭代器的成员变量了,迭代器本质就是一个对象,这个对象的成员变量是结构体指针,通过迭代器类和迭代器对象我们才能让list的迭代器实现解引用加加减减等操作。
5.
为了支持泛型,可以看到STL库在参数设计上采用模板的形式,在实现部分将内置类型也看作了自定义类型,C++让内置类型也支持构造,赋值,拷贝构造等成员函数,就是为了在泛型编程下,无论是自定义类型还是内置类型都能够统一用模板参数来处理,等到具体使用的时候在根据模板参数类型的不同实例化出不同的模板,这样在编程时可大大提升代码的可维护性,泛型编程可以省去很多不必要的代码。
namespace wyn
{template<class T>struct list_node{list_node* _next;//指向下一个结点的结构体指针list_node* _prev;//指向前一个结点的结构体指针T _data;//数据类型是泛型,可能是内置类型,也有可能是自定义类型list_node(const T& x)//new结点的时候会调用构造函数,但编译器默认生成的无参构造函数无法满足我们的要求//所以我们需要自己写一个带参数的构造函数,因为new结点时需要将数据作为参数传递,无参不符合要求。:_next(nullptr),_prev(nullptr),_data(x){}};template<class T>struct __list_iterator{typedef list_node<T> node;node* _pnode;//迭代器类的成员就是一个结构体指针_pnode__list_iterator(node* p):_pnode(p){}T& operator*()//返回_data的引用,则解引用迭代器可以修改结点对应的数据{return _pnode->_data;}__list_iterator<T>& operator++(){_pnode = _pnode->_next;return *this;}bool operator!=(const __list_iterator<T>& it)//比较两个迭代器是否相等,就是比较结点指针相不相等{return _pnode != it._pnode;}};template<class T>class list{typedef list_node<T> node;//将实例化后的类模板list_node<T>类型重定义为nodepublic:typedef __list_iterator<T> iterator;//将实例化后的类模板__list_iterator<T>类型重定义为iteratoriterator begin(){//iterator it(_head->_next);//return it;//上下这两种写法是等价的。return iterator(_head->_next);//返回迭代器类的匿名对象,参数传结构体指针,迭代器类的成员变量只有一个结构体指针。//匿名对象可以省下我们自己定义出对象然后再返回,这样比较麻烦。}iterator end()//迭代器对象出了作用域被析构掉,所以用传值返回,不能用传引用返回{return iterator(_head);//end()返回的是最后一个元素的下一个位置的迭代器,所以我们返回的是哨兵卫结点的迭代器对象。}void empty_initialize() {_head = new node(T());//node实现的构造函数是带参数的,调用T类型的默认构造初始化//new一个结点,new会自动调用node类的带参构造函数,我们给构造函数传一个泛型的匿名对象,//保证结点存储的数据类型是泛型,既有可能是内置类型也有可能是自定义类型,所以传匿名对象。//如果是自定义类型,会调用其类的无参构造函数,如果是内置类型,基本是0或NULL等初始值,//我们可以认为内置类型也有构造函数,这样的写法实际是为了支持C++的泛型编程所搞出来的,//如果是内置类型,编译器会做特殊处理。_head->_next = _head;_head->_prev = _head;}list(){empty_initialize();}void push_back(const T& x){node* newnode = new node(x);//这里所传x的类型是不确定的,他的类型取决于调用方给模板参数所传的值。//如果T是自定义类型,那x就是对象,如果T是内置类型,x就是变量。node* tail = _head->_prev;tail->_next = newnode;newnode->_prev = tail;newnode->_next = _head;_head->_prev = newnode;//insert(end(), x);}private:node* _head;};
}void test_list1(){list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);lt.push_back(4);//内嵌类型 -- 迭代器需要能够1.解引用能够取到结点的数据 2.并且可以++或--进行移动//string和vector的iterator原生指针能够使用,是因为数组结构正好支持迭代器行为。//list如果用原生指针,它的数组结构无法支持迭代器行为,因为list的空间是不连续的。//为了支持list的迭代器,我们用类的封装和运算符重载进行支持。list<int>::iterator it = lt.begin();//由于迭代器对象的拷贝构造没有实现,所以用编译器默认生成的浅拷贝。while (it != lt.end())//vector和string可以用<来进行判断,但list这里只能用!=,这里会调用it对应类的运算符重载{//it.operator*(){} --- 转换为调用自定义类型对应类内的运算符重载函数//it.operator++(){}cout << *it << " ";//*it是自定义类型iterator的运算符重载,iterator是进行封装的类型++it;//++it也是自定义类型iterator的运算符重载。//(*it)++; --- it.operator*()函数的引用返回值进行自增,返回值可能是自定义类型或内置类型。}cout << endl;for (auto e : lt)//范围for就是傻瓜式的替换迭代器的代码,begin()end(),迭代器支持解引用++--等操作,范围for就能用{cout << e << " ";}cout << endl;}
三、vs和g++下string结构的说明
1.vs下的string结构
1.
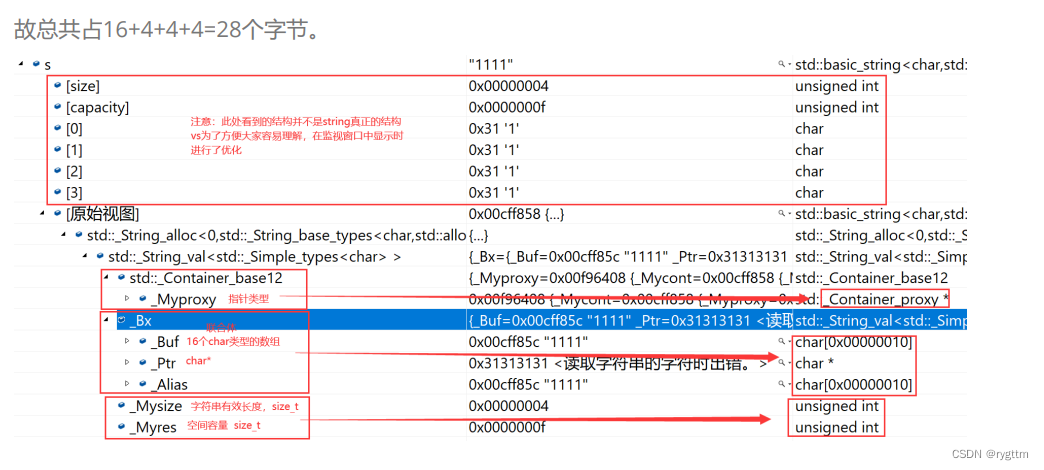
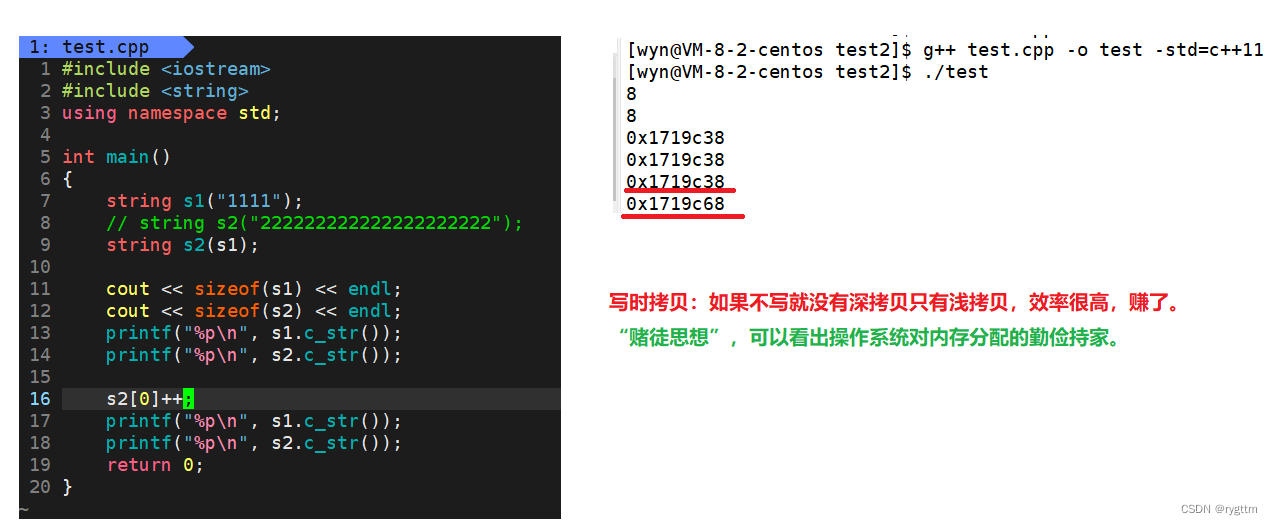
下面所说的默认环境是32位平台,指针为4字节。从打印结果我们可以得到两个信息,一个是s1和s2的所占字节大小一样,另一个是两者所占字节大小为28字节。
首先,两者一样的原因是因为,对象的大小和存储的数据无关,因为数据是在堆区上动态开辟的,分析对象大小时,我们只看对象成员变量所占大小,所以这就能解释为什么对象s1和对象s2的大小是一样的了。
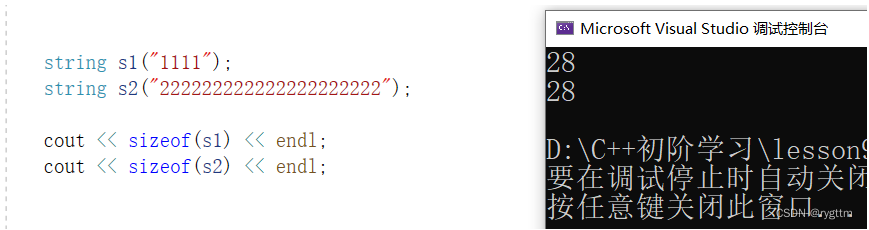
2.
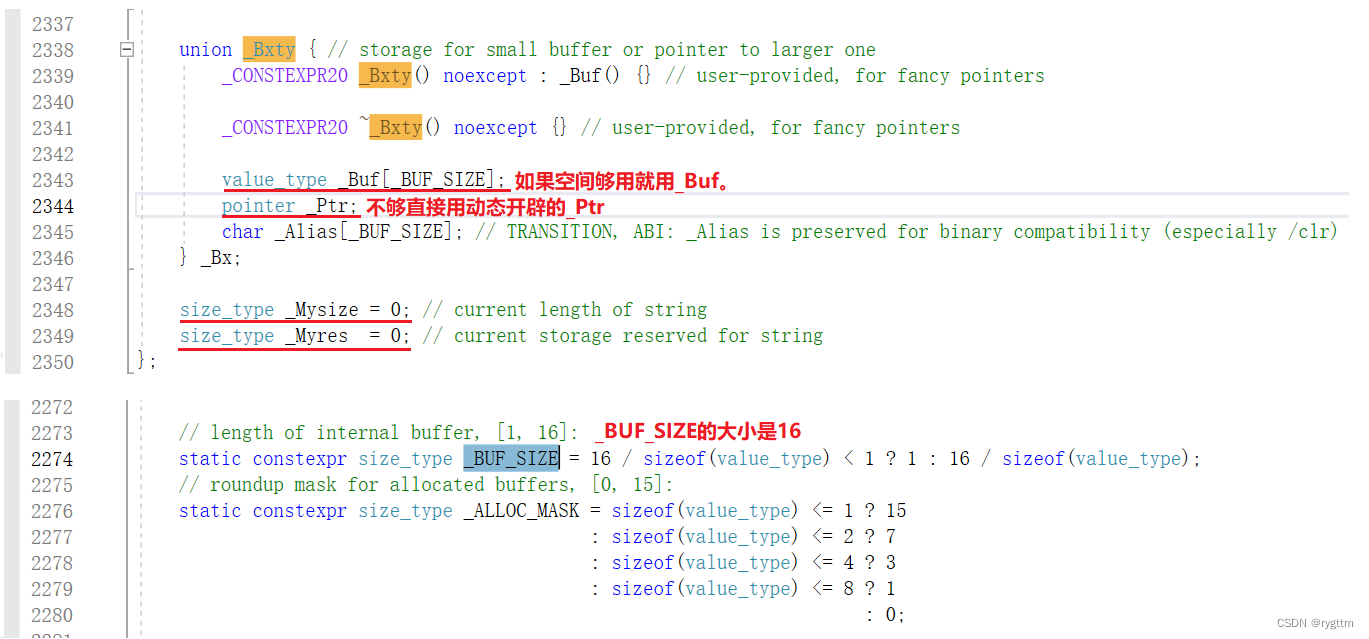
至于为什么是28字节,而不是12字节,这就和vs下string的结构有关系了,我们实现的string有三个成员变量分别是_ptr、_size和_capacity按照内存对齐的原则应该是12字节。但我们实现的并不标准,仅仅能够完成string的大部分功能而已。
vsPJ版本的STL源码中string总共占28个字节,内部结构稍微复杂一点,先是有一个联合体,联合体用来定义string中字符串的存储空间:当字符串长度小于16时,使用内部固定的字符数组_buf来存放,当字符长度大于等于16时,从堆上开辟空间,不在使用_buf数组进行存放。
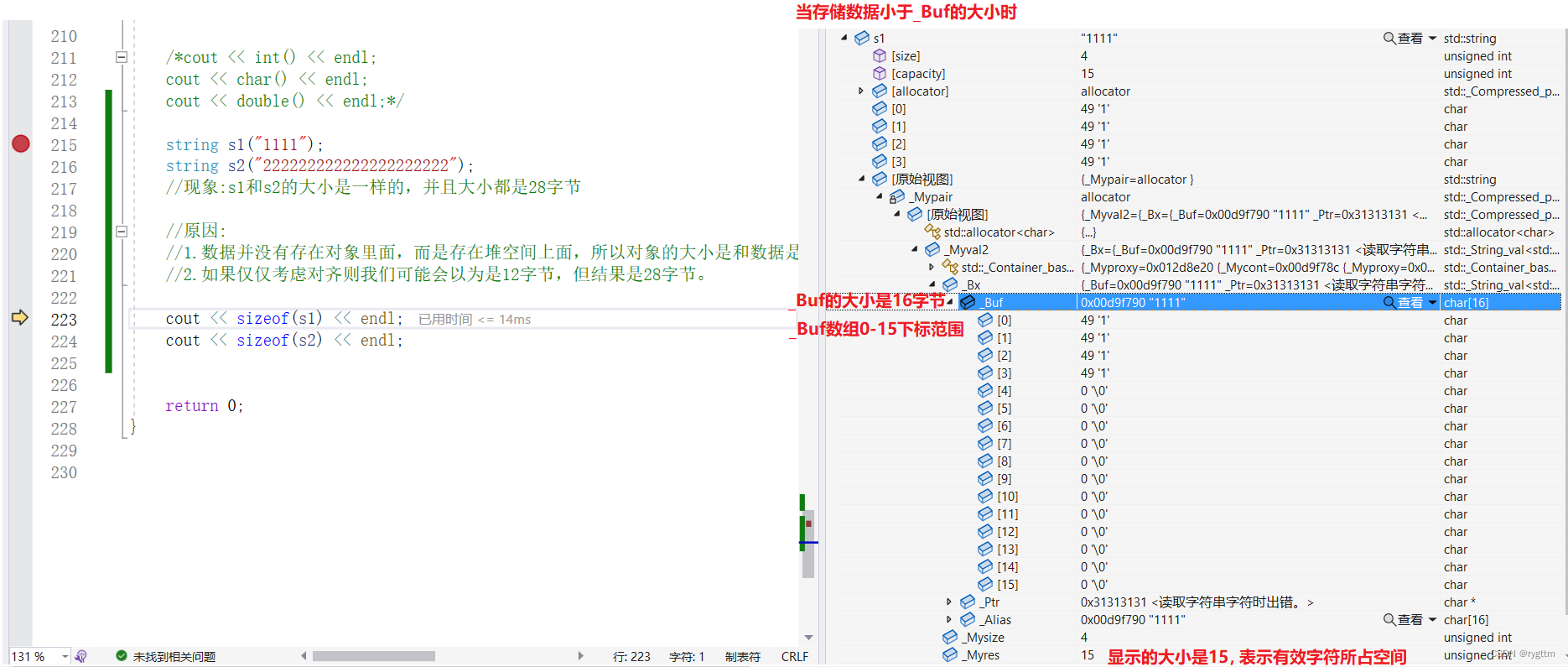
3.
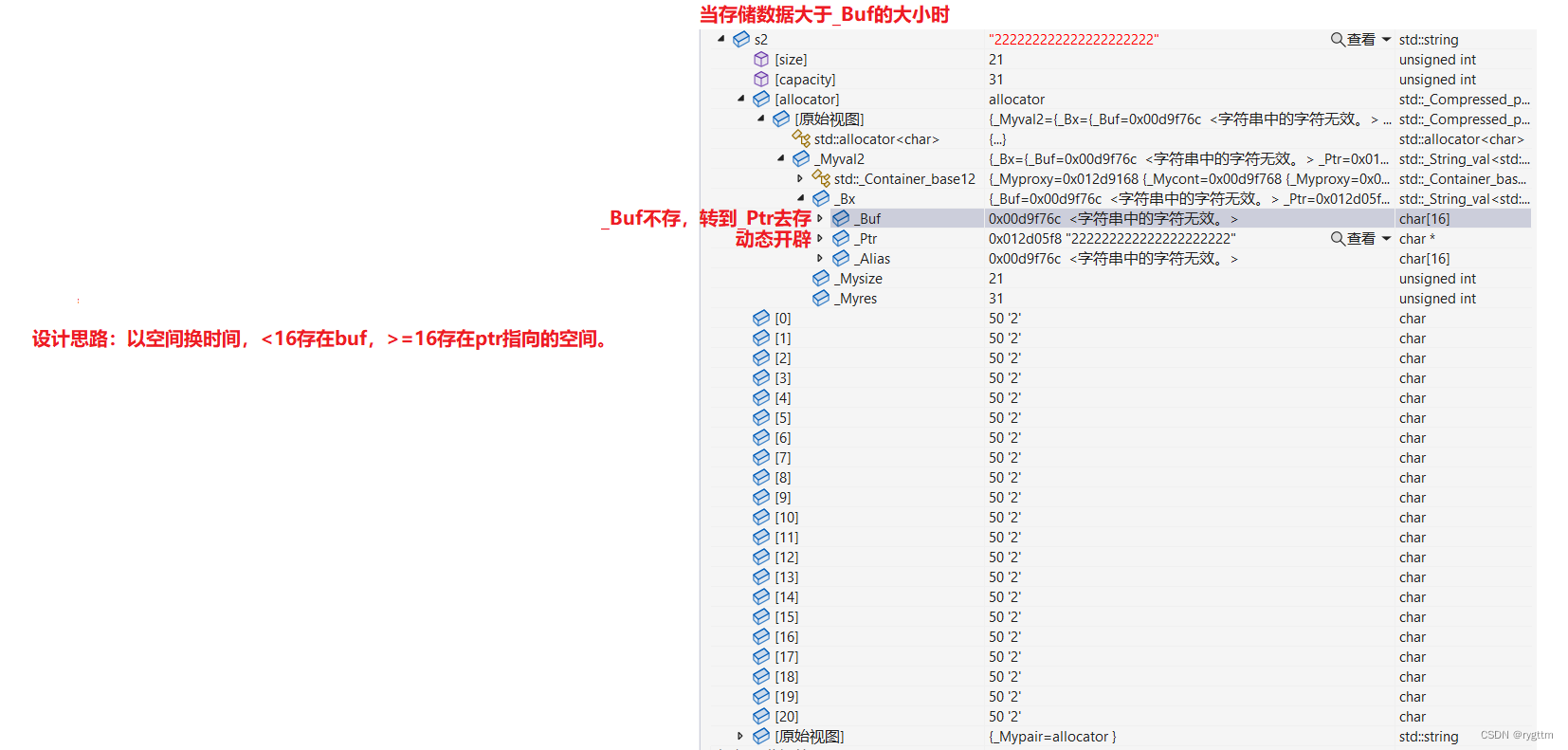
从调试窗口可以看到,当存储数据小于16时,数据内容被存放到了_Buf数组里面,而_Ptr并没有指向具有有效字符的空间。当存储数据大于等于16时,数据内容被存放到了_Ptr指向的动态开辟的空间里面,而_Buf里面什么都没有存。
4.
vs对于string的设计思想主要还是用空间换时间,增大string对象的大小,如果数据量比较小,那就用提前开好的_Buf数组进行存储,节省自己动态开辟空间的消耗。
2.g++下的string结构
1.
g++下,string是通过写时拷贝实现的,string对象总共占4个字节,内部只包含了一个指针,该指针将来指向一块堆空间,内部包含了如下字段:共分为4个部分,空间总大小,字符串有效长度,引用计数,指向堆空间的指针,用来存储字符串。
2.但是显示出来的string对象大小是8字节,因为默认使用的环境是64位,指针大小为8字节。
x86_64是64位平台,指针大小为8字节

3.
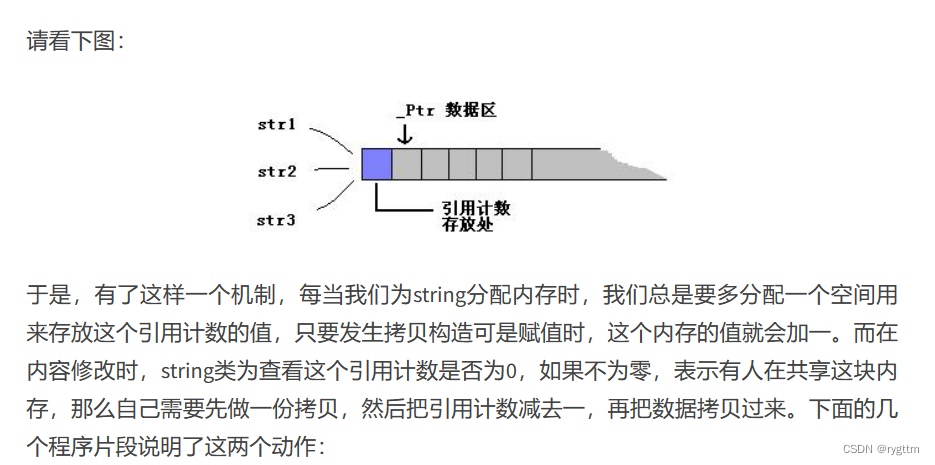
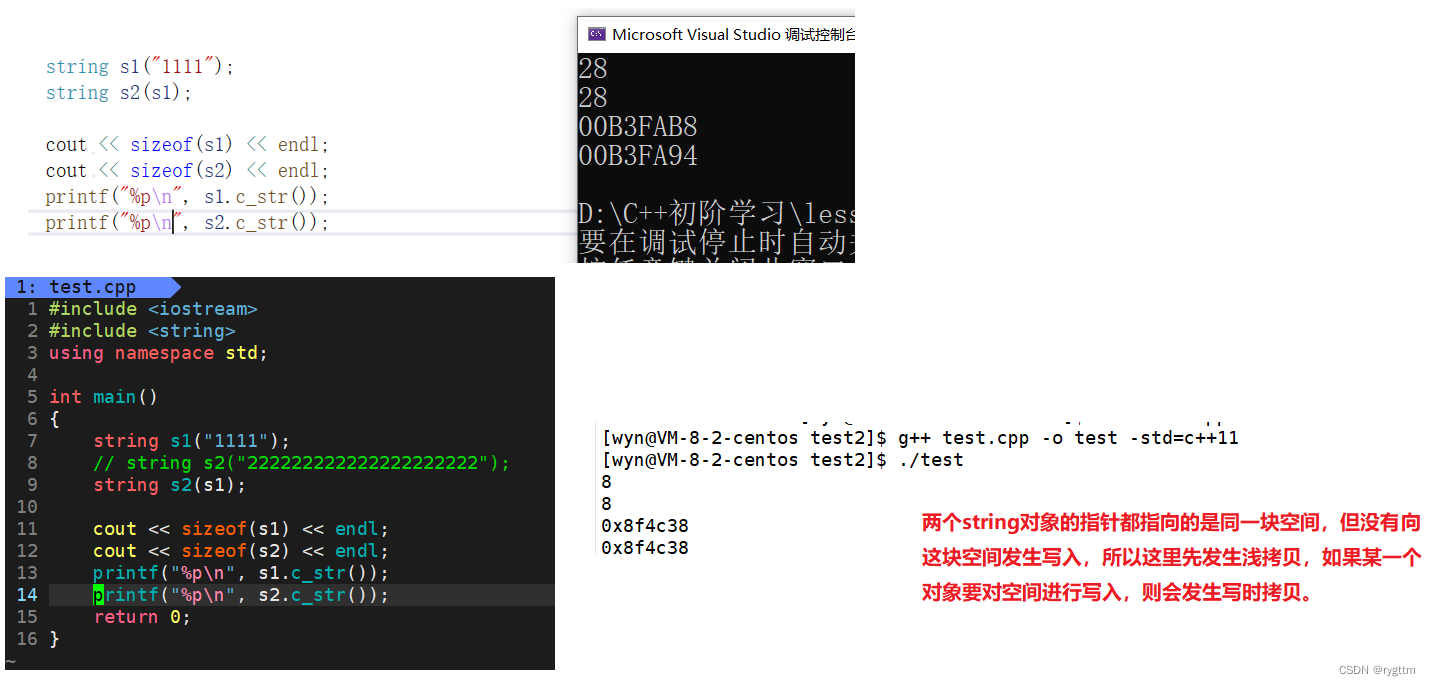
在没有向对象中指针指向空间发生数据的写入的时候,g++下面会先发生浅拷贝,先不开空间,下面代码的第三张图片中我们对空间进行了写入,这个时候就会发生写时拷贝,重新进行空间的深拷贝。
相关文章:
【C++】list的使用和基本迭代器框架的实现 vs和g++下string结构的说明
真正的成熟应该并不是追求完美,而是直面自己的缺憾,这才是生活的本质。 文章目录一、初见list1.list的迭代器失效和基本使用2.list的operations操作接口(看起来挺不错的接口,但可惜不怎么实用)3.vector和list的排序性能…...
基于深度学习的轴承寿命预测实践,开发CNN、融合LSTM/GRU/ATTENTION
关于轴承相关的项目之前做的大都是故障识别诊断类型的,少有涉及回归预测的,周末的时候宅家发现一个轴承寿命加速实验的数据集就想着拿来做一下寿命预测。首先看下数据集如下:直接百度即可搜到,这里就不再赘述了。Learning_set为训…...
redis进阶:mysql,redis双写一致性,数据库更新后再删除缓存就够了吗?
0. 引言 最近线上的一个状态修改功能出现了问题,一开始是运营找了过来,运营告知某条数据的状态已经开启了的,但是实际使用起来还是没有生效,于是拿到这个问题后,首先就去数据库查了这条数据,发现确实如他所…...
RTOS中互斥量的原理以及应用
互斥量的原理 RTOS中的互斥量是一种同步机制,用于保护共享资源,防止多个任务同时访问该资源,从而避免数据竞争和不一致性。 互斥量的原理是通过对共享资源进行加锁和解锁操作来实现的。 在RTOS中,互斥量通常是一个数据结构&…...
数据分析:基于随机森林(RFC)对酒店预订分析预测
数据分析:基于随机森林(RFC)对酒店预订分析预测 作者:AOAIYI 作者简介:Python领域新星作者、多项比赛获奖者:AOAIYI首页 😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞…...
【python】序列(列表、元组)、字典、集合的初步认识
一、序列 序列类型(sequence):一组有序的数据集,特点是数据之间存在先后关系,通过序号访问 序列包含以下三种类型: 1.字符串(str)不可修改 2.列表(list)可修改 3.元组(t…...

周赛335(模拟、质因子分解、分组背包)
题解:0x3f https://leetcode.cn/problems/number-of-ways-to-earn-points/solution/fen-zu-bei-bao-pythonjavacgo-by-endlessc-ludl/ 文章目录周赛335[6307. 递枕头](https://leetcode.cn/problems/pass-the-pillow/)模拟[6308. 二叉树中的第 K 大层和](https://le…...

【极致简洁】Python tkinter 实现下载工具,你想要的一键获取
嗨害大家好鸭!我是小熊猫~开发环境本次项目案例步骤成品效果【咱追求的就是一个简洁】界面如何开始?1.导入模块2.创建窗口【这步很重要】功能按键1.创建一个下拉列表2.设置下拉列表的值3.设置其在界面中出现的位置 column代表列 row 代表行4.设置下拉列表…...
npm i 安装报错
npm WARN EBADENGINE Unsupported engine { npm WARN… npm WARN deprecated stable0.1.8: Modern JS… 诸如此类的报错。大部分都是因为 node 版本问题!比如node版本无法满足,对应项目里需要的那些模块和依赖所需要的条件。 有些模块对node版本是有要…...
原腾讯QQ空间负责人,T13专家,黄希彤被爆近期被裁员,裁员原因令人唏嘘。。...
点击上方“码农突围”,马上关注这里是码农充电第一站,回复“666”,获取一份专属大礼包真爱,请设置“星标”或点个“在看这是【码农突围】的第 431 篇原创分享作者 l 突围的鱼来源 l 码农突围(ID:smartyuge&…...
【C++】BloomFilter——布隆过滤器
文章目录一、布隆过滤器概念二、布隆过滤器应用三、布隆过滤器实现1.插入2.查找3.删除四、布隆过滤器优缺五、结语一、布隆过滤器概念 布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是…...

【Spring】资源操作管理:Resource、ResourceLoader、ResourceLoaderAware;
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ 资源操作:Spring Resources一、Res…...

【System Verilog基础】automatic自动存储--用堆栈区存储局部变量
文章目录一、C语言的内存分配:BSS、Data、Text、Heap(堆)、Stack(栈)1、1、静态内存分配:BSS、Data1、2、程序执行代码:Text1、3、动态内存分配:Heap(堆)、St…...

看板组件:Bryntum Task Board JS 5.3.0 Crack
一个超级灵活的看板组件,Bryntum Task Board 是一个灵活的看板 Web 组件,可帮助您可视化和管理您的工作。 功能丰富 任务板非常灵活,允许您完全自定义卡片、列和泳道的渲染和样式。借助丰富的 API,您甚至可以在运行时打开或关闭功…...

45 个 Git 经典操作场景,专治不会合代码
git对于大家应该都不太陌生,熟练使用git已经成为程序员的一项基本技能,尽管在工作中有诸如 Sourcetree这样牛X的客户端工具,使得合并代码变的很方便。但找工作面试和一些需彰显个人实力的场景,仍然需要我们掌握足够多的git命令。下…...

MyBatis之动态SQL
目录 一、<if>标签 二、<trim>标签 三、<where>标签 四、<set>标签 五、<foreach>标签 一、<if>标签 当我们在某个平台提交某些信息时,可能都会遇到这样的问题,有些信息是必填信息,有些信息是非必…...
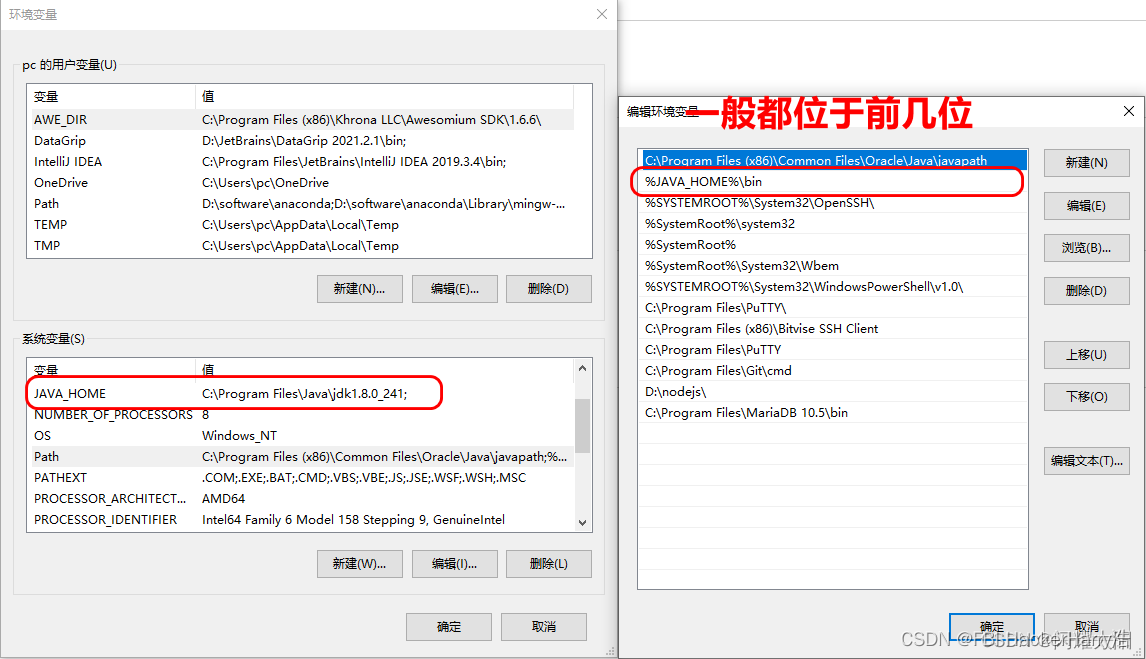
SpringBoot(Tedu)—DAY01——环境搭建
SpringBoot(Tedu)—DAY01——环境搭建 目录SpringBoot(Tedu)—DAY01——环境搭建零、今日目标一、IDEA2021项目环境搭建1.1 通过 ctrl鼠标滚轮 实现字体大小缩放1.2 自动提示设置 去除大小写匹配1.3 设置参数方法自动提示1.4 设定字符集 要求都使用UTF-8编码1.5 设置自动编译二…...
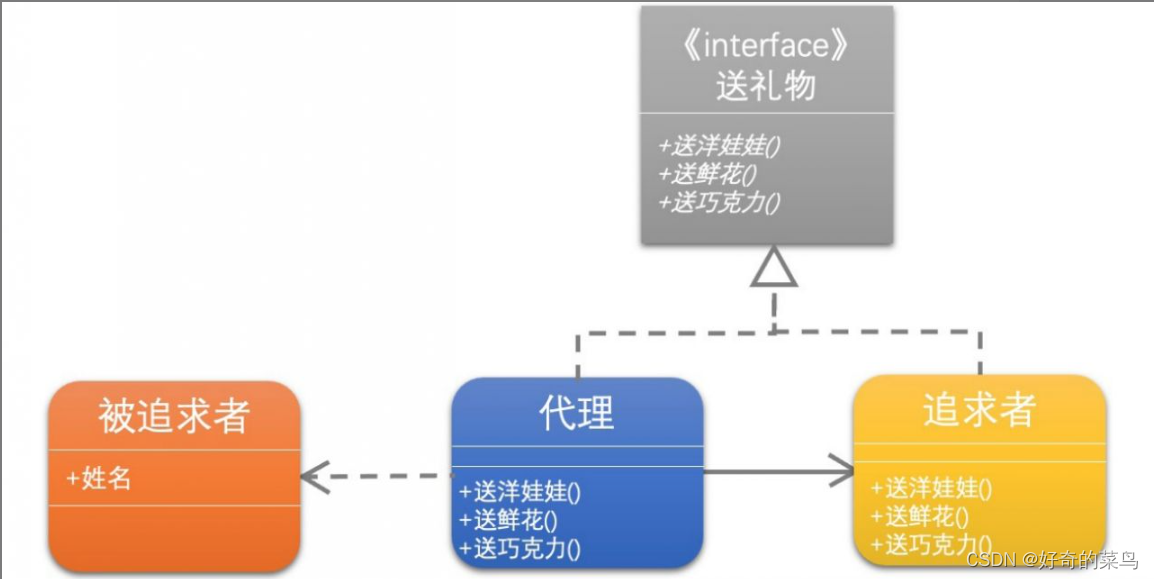
代理模式-大话设计模式
一、定义 代理模式的定义:为其他对象提供一种代理以控制对这个对象的访问。在某些情况下,一个对象不适合或者不能直接引用另一个对象,而代理对象可以在客户端和目标对象之间起到中介的作用。 著名的代理模式例子为引用计数(英语…...

STM32定时器的编码器接口模式
MCU为STM32L431,通用定时器框图: 编码器接口模式一共有三种,通过TIMx_SMCR寄存器的SMS[3:0]位来选择。模式1计数器仅在TI1FP1的边沿根据TI2FP2的电平来判断向上/下计数;模式2计数器仅在TI2FP2的边沿根据TI1FP1的电平来判断向上/下…...
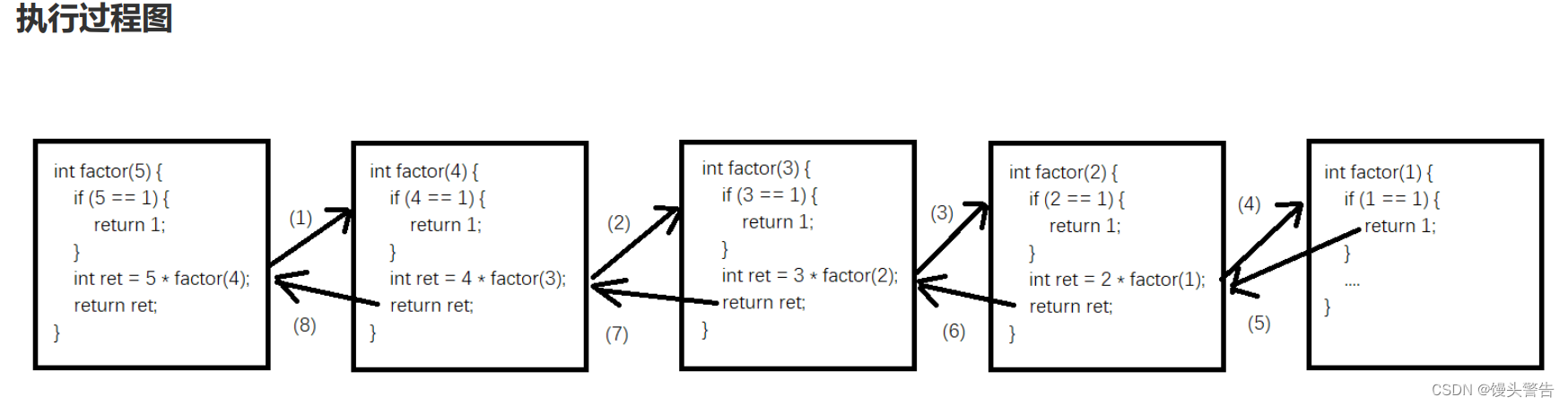
Java方法的使用
目录 一、方法的概念及使用 1、什么是方法(method) 2、方法定义 3、方法调用的执行过程 4、实参和形参的关系 二、方法重载 1、为什么需要方法重载 2、方法重载概念 3、方法签名 三、递归 1、递归的概念 2、递归执行过程分析 一、方法的概念及使用 1、什么是方法(met…...

追踪Elsevier审稿进度:开源工具如何提升学术投稿效率
追踪Elsevier审稿进度:开源工具如何提升学术投稿效率 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 学术出版流程中,审稿进度的不确定性常给研究者带来困扰。Elsevier作为全球领先的学术出版…...

基于COMSOL 5.5的精确非局部损伤模型:模拟脆性材料压缩、摩擦和剪切条件下的破坏行为研究
开发了一种基于COMSOL 5.5的损伤模型,专门用于模拟脆性材料在压缩、摩擦和剪切条件下的破坏行为。 该模型采用非局部本构关系,通过考虑材料内部微观结构的影响,精确捕捉脆性材料在受力过程中的应力分布和破坏机理。脆性材料的破坏模拟一直是工…...

AI辅助开发中的Codec VAD优化实践:从算法原理到工程落地
在实时音视频应用里,语音活动检测(VAD)就像个“守门员”,负责精准判断当前有没有人在说话。这个判断准不准、快不快,直接关系到后续的编码、传输乃至降噪、唤醒等一系列流程的效率。尤其在AI辅助开发的框架下ÿ…...

RVC 技术指南:从问题解决到效率提升
RVC 技术指南:从问题解决到效率提升 【免费下载链接】rvc RVC is a Linux console UI for vSphere, built on the RbVmomi bindings to the vSphere API. 项目地址: https://gitcode.com/gh_mirrors/rvc/rvc 问题场景→核心原理→分步方案→进阶技巧 一、环…...

深入解析服务器License管理:从基础命令到实战应用
1. 服务器License管理:为什么它比你想的更重要 如果你管理过服务器,尤其是那些运行着像CAD、EDA、仿真分析这类专业软件的服务器,那你肯定对“License”这个词不陌生。它就像软件的“通行证”,没有它,再强大的硬件也只…...

C++ 无原生 JSON 支持?一文实现通用序列化与反序列化封装方案
前言 在现代软件开发中,JSON(JavaScript Object Notation)因其轻量级和易读性成为数据交换的主流格式。C虽无原生JSON支持,但通过封装第三方库(如nlohmann/json),可高效实现序列化(…...

Qt新手必看:MinGW和MSVC构建套件到底怎么选?保姆级对比指南
Qt构建套件选择指南:MinGW与MSVC深度对比与实战决策 刚接触Qt开发的初学者,往往在配置开发环境的第一步就陷入选择困难——面对MinGW和MSVC这两个构建套件选项,究竟该如何抉择?这个看似简单的选择背后,实则关系到后续开…...

CentOS 7下PHP7.4编译安装全攻略:从依赖解决到常见报错处理
CentOS 7下PHP7.4编译安装全攻略:从依赖解决到常见报错处理 在Linux服务器环境中,PHP作为最流行的服务器端脚本语言之一,其安装方式通常有yum安装和编译安装两种选择。对于追求性能优化和功能定制的开发者来说,编译安装PHP7.4无疑…...

async-http-client原生镜像大小优化:GraalVM裁剪终极指南 [特殊字符]
async-http-client原生镜像大小优化:GraalVM裁剪终极指南 🚀 【免费下载链接】async-http-client Asynchronous Http and WebSocket Client library for Java 项目地址: https://gitcode.com/gh_mirrors/as/async-http-client 在当今云原生和微服…...

终极指南:如何用org-roam保护敏感笔记的安全与隐私
终极指南:如何用org-roam保护敏感笔记的安全与隐私 【免费下载链接】org-roam Rudimentary Roam replica with Org-mode 项目地址: https://gitcode.com/gh_mirrors/or/org-roam org-roam是一款基于Org-mode的强大知识管理工具,它允许用户创建和管…...