【NLP笔记】大模型prompt推理(提问)技巧
文章目录
- prompt概述
- 推理(提问)技巧
- 基础prompt构造技巧
- 进阶优化技巧
- prompt自动优化
参考链接:
- Pre-train, Prompt, and Predict: A Systematic Survey of
Prompting Methods in Natural Language Processing - 预训练、提示和预测:NLP中提示的系统综述
随着LLM时代的到来,通过prompt直接对话语言模型,得到预期结果,解析后用于实际应用的模式也随之推广。那么什么是prompt,如何用好prompt去激发语言模型的潜力,成为了预训练语言模型底座+prmpt-tuning范式的重要议题。
prompt概述
prompt通俗来说就是通过设计自然语言提示词,让预训练的语言模型“回忆”预测出学习到的内容,并对提示词的问题做出解答,具体步骤如下:
- 设计模版:设计一个自然语言模版,该模版中一个位置用于存放输入文本[X],一个位置用于存放输出文本[Z];根据模版构造问答样本,如设计模版为"[X] The movie is [Z]“,输入内容[X]为"I love this movie.”,预测结果的位置为[Z]存放的位置,通过这样的模式去构造样本;
- 中间位置的为完形填空prompt,还有前缀、后缀的prompt形式;
- prompt并非局限于自然语言,也可以是向量化后的token;
- [X] 和 [Z] 槽位数量可以根据任务需要灵活调整;

- 搜索回答:这一步主要经大模型推理预测找到得分最高的结果 z ˆ zˆ zˆ。通过预训练的大模型可能会有一组允许的 Z Z Z(生成任务可以是任意文本,分类任务可以是一组单词)被预测出来,函数 f f i l l ( x ′ , z ) f_{fill}(x', z) ffill(x′,z)( x ′ x' x′为根据模版构造的未填充结果的文本)表示用潜在回答 z z z填充提示 x ′ x' x′中的位置 [Z],得到的结果一般被称为 filled prompt,如果填充的是正确回答,则被称为 answered prompt,具体表现为,通过使用预训练的大模型计算会从相应filled prompt 从可能的回答集合 Z Z Z中找出概率最大的结果 z ˆ zˆ zˆ,得到answered prompt;

- 映射回答:最后,基于得分最高的回答 z ˆ zˆ zˆ 到得分最高的输出 y ˆ yˆ yˆ,尤其是在分类任务中需要进行这样的结果映射(比如excellent、fabulous、wonderful 等近义词可以映射到某一情感类别);
推理(提问)技巧
prompt采用完形填空、前缀还是后缀的形式,是预训练底座或者微调时需要考虑的,当前就总结基于大模型完成推理(提问)时,该如何设计prompt以及使用什么样的技巧才能更好地激发大模型的潜能。
基础prompt构造技巧
当提问的方式与大模型的语料库更接近时,模型的预测效果可能会更好,不过大多数大模型的语料库都是非公开的,好在都是采用类似的模版设计,因此能够总结出一定的规律。
想要在推理时得到较理想的预测结果,结合很多prompt经验来看,一个合理的架构就包含了构造prompt所需的技巧,下面介绍一个ChatGPT3官方提出的prompt构造模版CRISPE(Capacity and Role、Insight、Statement、Personality、Experiment),具体为:
| 构造步骤 | 技巧描述 | 示例 |
|---|---|---|
| Capacity and Role | 指定角色和能力 | “假设你是一个机器学习架构开发专家,并且还是一个资深博客作家。” |
| Insight | 给定一些背景信息 | “博客的受众是有兴趣了解机器学习最新进展的技术专业人士。” |
| Statement | 说明任务目标 | “全面概述最流行的机器学习框架,包括它们的优点和缺点。包括现实生活中的例子和案例研究,以说明这些框架如何在各个行业中成功使用。” |
| Personality | 控制输出格式与风格 | “在回复时,请使用 Andrej Karpathy、Francois Chollet、Jeremy Howard 和 Yann LeCun 的混合写作风格。” |
| Experiment | 指定输出结果的要求,如单输出/多输出 | “给出多个输出示例” |
上述模版包含了很多构造prompt的技巧,不同的模版侧重的技巧可能有差异,但是都是可以用来尝试的范式,其他更多的模版可以参考:9个prompt构造模版范式;
还有很多prompt的设计技巧,避免模型出现幻觉等,更好地得到目标输出结果,比较基础简单的技巧如:
- 提供更多的细节/背景信息;
- 描述更清晰,避免模糊的表达;
- 多尝试不同的prompt构造范式,选取最适合任务的一种提问方式;
- 采用效果好的prompt范式,多次调用模型,选出投票结果(self-consistency);
- 把单个问题拆分成多个子问题,一步一步地得到最终结果(least to most);
- 知识增强,通过检索引入外部知识,构造prompt,提升效果(RAG,Retrieval Augmented Generation);
- 把问题拆分成不同的问题后,逐步进行提问(self-ask)等;
# 采用langchain生成self-ask示例
# pip install langchain
# pip install openai
# pip install google-search-resultsimport os
os.environ['OPENAI_API_KEY'] = str("xxxxxxxxxxxxxxxxxxxx")
os.environ["SERPAPI_API_KEY"] = str("xxxxxxxxxxxxxxxxxxxx")from langchain import OpenAI, SerpAPIWrapper
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentTypellm = OpenAI(temperature=0)
search = SerpAPIWrapper()
tools = [Tool(name="Intermediate Answer",func=search.run,description="useful for when you need to ask with search",)
]self_ask_with_search = initialize_agent(tools, llm, agent=AgentType.SELF_ASK_WITH_SEARCH, verbose=True
)
self_ask_with_search.run("What is the hometown of the reigning men's U.S. Open champion?"
)
# 输出self-ask示例
#> Entering new AgentExecutor chain...
# Yes.
# Follow up: Who is the reigning men's U.S. Open champion?
# Intermediate answer: Carlos Alcaraz
# Follow up: Where is Carlos Alcaraz from?
# Intermediate answer: El Palmar, Spain
# So the final answer is: El Palmar, Spain
# > Finished chain.
# El Palmar, Spain
更多技巧可以参考以下内容:
- OpenAI官方技巧教程
- Reasoning with Language Model Prompting: A Survey
- Awesome-Prompt-Engineering
- 12 Prompt Engineering Techniques
如果模型的参数是可以通过入口传递的,也可以通过参数设置调整模型的预测结果:
- 温度系数(Temperature):控制模型输出随机性的参数。它影响模型在选择下一个词时的确定性,越接近1时模型的输出越随机;
- 多样性(top p):采样策略,模型仅从累计概率超过指定阈值p的最可能的词中进行选择。设置 top-p 为0.9,模型将从概率最高的一小部分词中选择,这些词的累计概率加起来接近0.9。;
- 重复惩罚(penalty):控制模型重复内容的输出,在长篇回答或生成文章时,使用重复惩罚可以帮助减少冗余和重复。
进阶优化技巧
上面提到的链接里有很多更细节/高阶的优化技巧,下面主要是从两种现在应用比较广泛的范式出发来介绍进阶的优化技巧,能更好地解决模型产生幻觉的问题。
把问题拆分成一步一步的小问题,并逐步进行解答,直到得到最终的目标结果。中间过程结合RAG,就能够产出更稳定、准确性更高的模型预测结果;
现在又很多AI-Agent(如:LangChain)集成了这些大模型推理优化技巧,还包含很多底层数据处理和检索等能力,可以协助使用者更好地进行大模型应用,提升模型的预测效果;
- CoT
论文链接:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
是一种引导大模型进行任务分解的提问方法,作法是给出任务分解的少量示例,利用大模型的上下文学习能力(in-context learning)引导模型进行任务拆解,并得到目标结果,如图所示:

- ReAct(Reason+Act)
论文链接:React: Synergizing Reasoning and Acting in
Language Models
引导大模型将问题进行更细致的拆分,在不同的子问题阶段拆分出Thought、Act和Observation三步,分步骤去检索/LLM推理并解答每个子步骤的问题,把各个问题的流程拼接成大模型的最终输入,让模型更有规划地去解决目标问题;

- ReWOO(Reasoning WithOut Observation)
论文链接:ReWOO: Decoupling Reasoning from Observations
for Efficient Augmented Language Models
去掉了ReAct处理手段中的Observation阶段,并且把Thought、Act转换成Planner、Worker和Solver三个阶段,把问题拆分成不同的子问题(Planner),根据子问题去检索/LLM推理对应的结果(Worker),拼接各个子问题的问答,输入给大模型得到目标问题的预测结果;

- ToT(Tree of Thought)
论文链接:Tree of Thoughts: Deliberate Problem Solving
with Large Language Models
ToT是结合了多种优化技巧的一种优化方案,在解决复杂问题时具有更大的优势。CoT是基于问题将问题划分成多个子步骤,并通过检索或者向大模型提问的方式得到各个步骤的结果,而CoT则是在会基于初始问题拆分出多个一级问题,每个问题会通过检索/LLM推理的方式解决,以此类推,就可以得到一颗树结构,最终的结果通过广度优先搜素、深度优先搜索等方式来拼接每一步的内容,最终输入给大模型得到目标答案;

- GoT(Graph of Thought)
论文链接:Graph of Thoughts: Solving Elaborate Problems with Large Language Models
在ToT的基础上引入了循环refine的结构,特定节点上可以想循环神经网络一样不断更新结果,使得整个过程的调整空间更大;

prompt自动优化
还有一些转为优化prompt设计的架构,可以帮你优化提问的文本内容:
- AutoPrompt:Eliciting Knowledge from Language Models with Automatically Generated Prompts
- PromptAgent: Strategic Planning with
Language Models Enables Expert-Level
Prompt Optimization - Guiding Large Language Models via Directional Stimulus Prompting
- Synthetic Prompting: Generating Chain-of-Thought Demonstrations for Large Language Models
相关文章:
【NLP笔记】大模型prompt推理(提问)技巧
文章目录 prompt概述推理(提问)技巧基础prompt构造技巧进阶优化技巧prompt自动优化 参考链接: Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing预训练、提示和预测:NL…...

【目标检测】西红柿成熟度数据集三类标签原始数据集280张
文末有分享链接 标签名称names: - unripe - semi-ripe - fully-ripe D00399-西红柿成熟度数据集三类标签原始数据集280张...
)
Java File类(文件操作类)
背景: 在Java编程语言中,操作文件和目录是一项常见的任务。而File类,则是java.io包中的重要类,它是唯一代表磁盘文件本身的对象。通过File类提供的方法,我们可以轻松地创建、删除、重命名文件和目录等操作。 构造方法&…...

正则表达式 vs. 字符串处理:解析优势与劣势
title: 正则表达式 vs. 字符串处理:解析优势与劣势 date: 2024/3/27 15:58:40 updated: 2024/3/27 15:58:40 tags: 正则起源正则原理模式匹配优劣分析文本处理性能比较编程应用 1. 正则表达式起源与演变 正则表达式(Regular Expression)最早…...
1、goreplay流量回放
目的 在实际项目中,会有大量的回归测试工作,通常会使用自动化代码的手段来实现回归,但是对于一个庞大的系统来说,通过自动化脚本的方式来实现回归测试,又显得很费时费力。并且如果有定期将线上数据同步到测试环境的需求…...
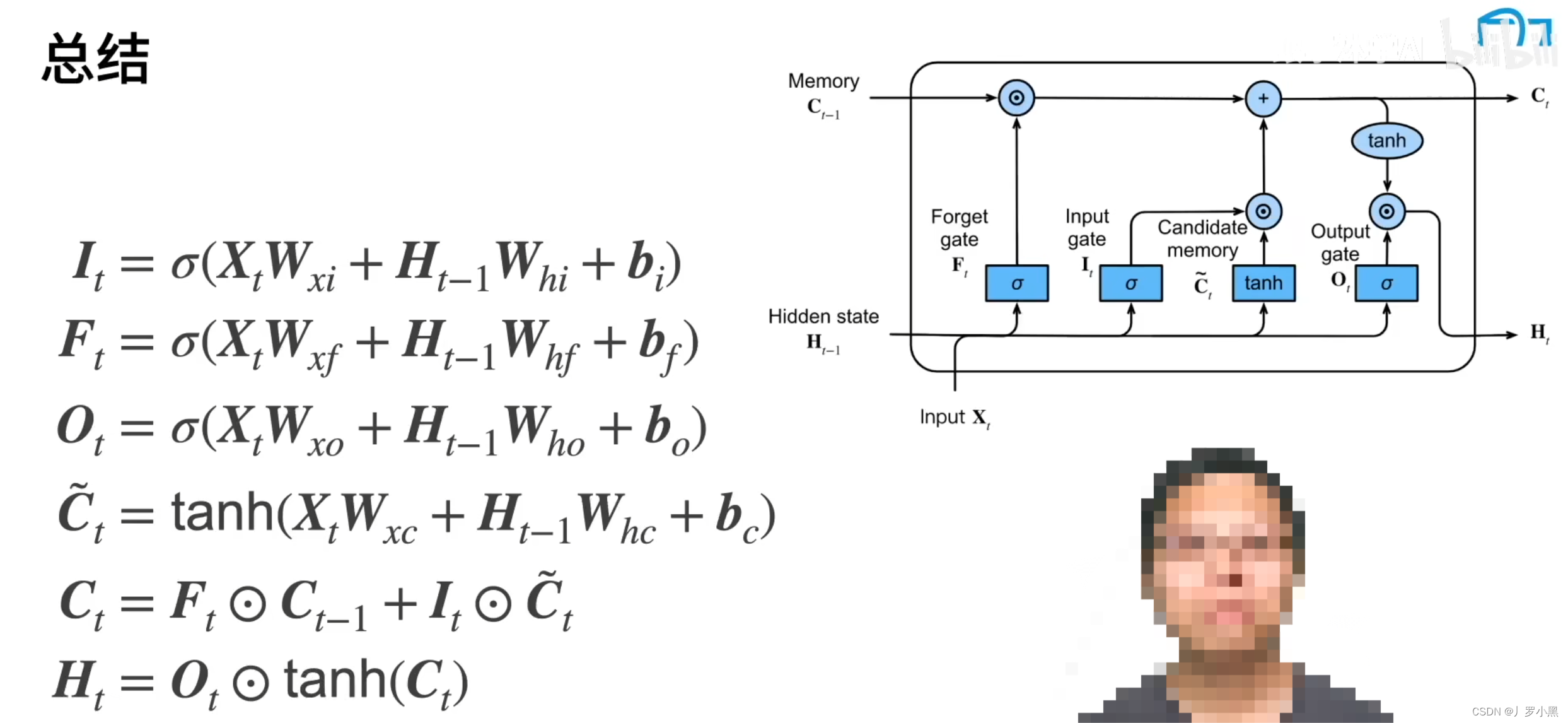
Transformer的前世今生 day06(Self-Attention和RNN、LSTM的区别)
Self-Attention和RNN、LSTM的区别 RNN的缺点:无法做长序列,当输入很长时,最后面的输出很难参考前面的输入,即长序列会缺失上文信息,如下: 可能一段话超过50个字,输出效果就会很差了 LSTM通过忘…...
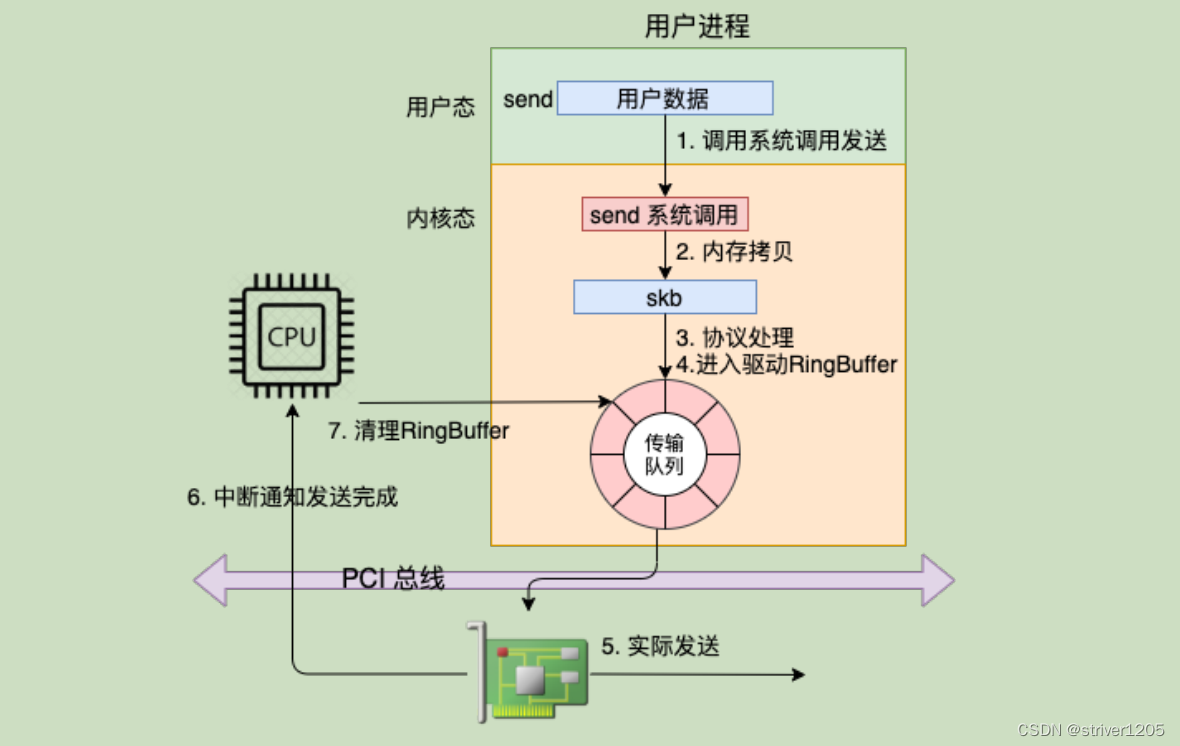
UDP send 出现大量“Resource temporarily unavailable”
背景 最近排查用户现场环境,查看日志出现大量的“send: Resource temporarily unavailable”错误,UDP设置NO_BLOCK模式,send又发生在进程上下文,并且还设置了SO_SNDBUF 为8M,在此情况下为什么还会出现发送队列满的情况…...

怎么拆解台式电脑风扇CPU风扇的拆卸步骤-怎么挑
今天我就跟大家分享一下如何选购电脑风扇的知识。 我也会解释一下机箱散热风扇一般用多少转。 如果它恰好解决了您现在面临的问题,请不要忘记关注本站并立即开始! 文章目录列表:大家一般机箱散热风扇都用多少转? 机箱散热风扇选择…...
Windows安装Odoo结合内网穿透实现公网访问本地企业管理系统
文章目录 前言1. 下载安装Odoo:2. 实现公网访问Odoo本地系统:3. 固定域名访问Odoo本地系统 前言 Odoo是全球流行的开源企业管理套件,是一个一站式全功能ERP及电商平台。 开源性质:Odoo是一个开源的ERP软件,这意味着企…...
Portainer的替代Dockge?又一个Docker Compose管理器?
Dockge:让Docker Compose管理触手可及,一图胜千言,轻松构建与管控您的容器服务栈!- 精选真开源,释放新价值。 概览 Docker,这一开放源代码的创新平台,旨在实现应用程序部署、扩展与运维的自动化…...

Midjourney AI绘图工具介绍及使用
介绍 Midjourney是一款目前被誉为最强的AI绘图工具。只要输入想到的文字,就能通过人工智能产出相对应的图片。 官网只是宣传和登录入口,提供个人主页、订阅管理等功能,Midjourney实际的绘画功能,是在另外一个叫discord的产品中实…...

clang-query 的编译安装与使用示例
1,clang query 概述 作用: 检查一个程序源码的抽象语法树,测试 AST 匹配器; 帮助检查哪些 AST 节点与指定的 AST 匹配器相匹配; 2,clang-query 安装 准备: git clone --recursive https://git…...

echarts数据下钻如何配置
官方范例:https://echarts.apache.org/examples/zh/editor.html?cbar-multi-drilldown 看了一眼范例直接晕了,你这,一堆数据直接写死,这怎么用啊! 一般来说,实现步骤是: 1)后台&a…...

git 提交空目录
git 提交空目录 1. git 无法感应空目录2. git 提交空目录References 1. git 无法感应空目录 Git FAQ https://archive.kernel.org/oldwiki/git.wiki.kernel.org/index.php/GitFaq.html Currently the design of the Git index (staging area) only permits files to be liste…...

【优化方案】Java 将字符串中的星号替换为0-9中的数字,并返回所有可能的替换结果
需求 将输入的字符串中的星号替换为0-9中的数字,并返回所有可能的替换结果,允许存在多个*号。 分析: 在每个星号位置,我们需要进行 0-9 的循环遍历,因此每个星号位置都有 10 种可能性。如果字符数组中有k个星号&#x…...

C语言复习-链表
链表: 特点: 通过 next 指针 把内存上不连续 的几段数据 联系起来 set nu -- 打印行号 概念: 一种数据结构 -- 数据存放的思想 比如 -- 数组 -- 内存连续的一段空间,存放相同类型的一堆数据 缺点 -- 增删元素很 难 -- 不灵活 --> 引入链表 next指针的初步认识…...
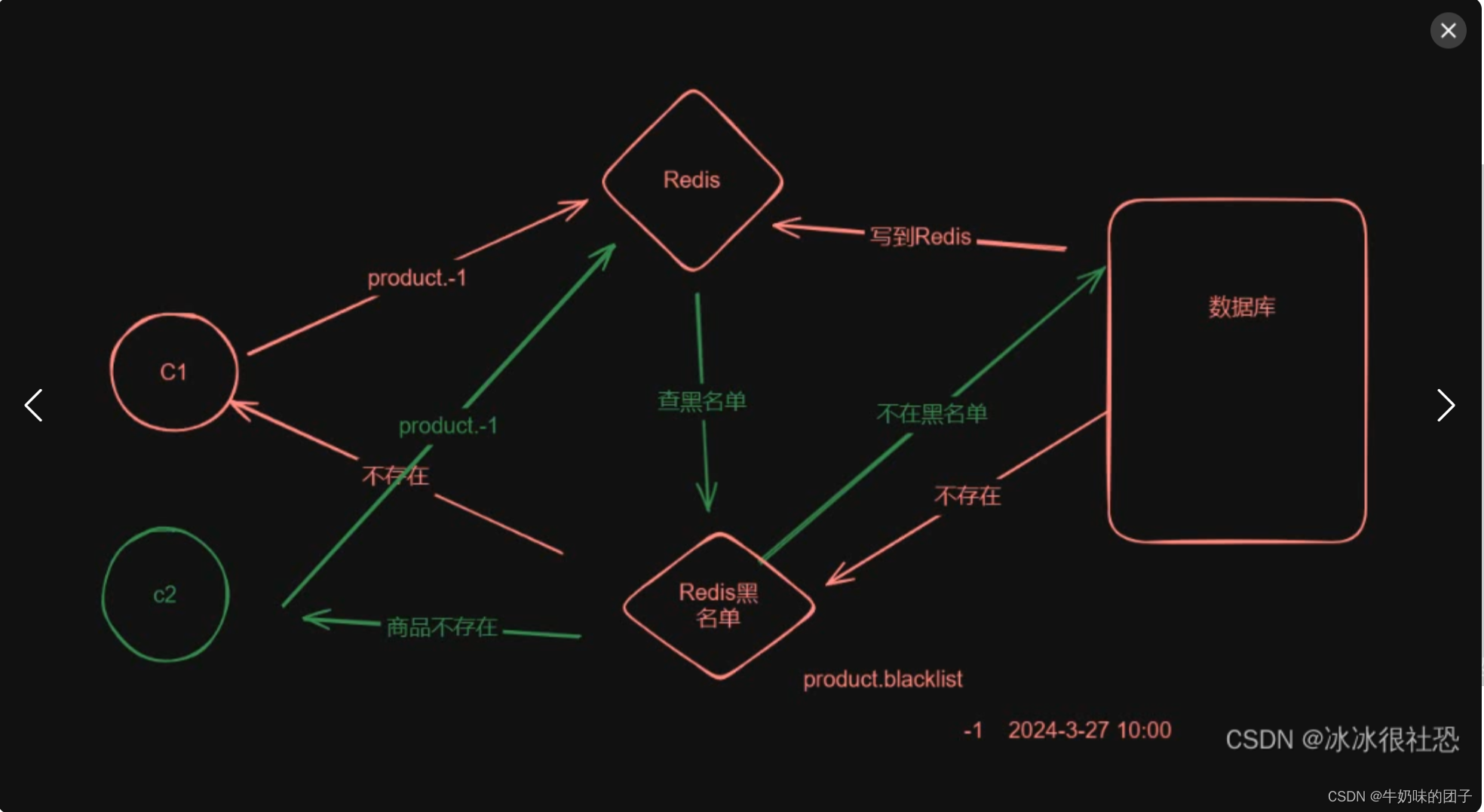
Redis面试题-缓存雪崩、缓存穿透、缓存击穿问题
1 穿透: 两边都不存在(皇帝的新装) (黑名单) (布隆过滤器) 2 击穿:一个热点的key失效了,这时大量的并发请求直接到达数据库. (提前预热) 3 雪崩:…...
【Node.js】npx
概述 npx 可以使用户在不安装全局包的情况下,运行已安装在本地项目中的包或者远程仓库中的包。 高版本npm会自带npx命令。 它可以直接运行 node_modules/.bin 下的 exe 可执行文件。而不像之前,我们需要在 scripts 里面配置,然后 npm run …...

hive授予指定用户特定权限及beeline使用
背景:因业务需要,需要使用beeline对hive数据进行查询,但是又不希望该用户可以查询所有的数据,希望有一个新用户bb给他指定的库表权限。 解决方案: 1.赋权语句,使用hive管理员用户在终端输入hive进入命令控…...
Vmware虚拟机无法用root直连说明
Vmware虚拟机无法用root直连说明 背景目的SSH服务介绍无法连接检查配置 背景 今天在VM上新装了一套Centos-stream-9系统,网络适配器的连接方式采用的是桥接,安装好虚拟机后,在本地用ssh工具进行远程连接,ip、用户、密码均是成功的…...

4个维度解析Steam Achievement Manager:开源工具如何重塑游戏成就管理体验
4个维度解析Steam Achievement Manager:开源工具如何重塑游戏成就管理体验 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager 一、困境诊断&#…...

致翔智慧校园招生迎新系统正式上线!一键解锁「零跑腿」入学新体验!
告别排长队、告别填不完的纸质表、告别来回跑、告别信息反复核对!致翔智慧校园招生迎新管理系统重磅上线啦!从招生报名到迎新报到,全流程数字化、一站式智能化,轻松搞定所有环节!✨ 告别繁琐,新生入学超丝滑…...

效率提升秘籍:用快马AI一键生成nt动漫角色管理模块代码
最近在开发一个nt动漫相关的项目,其中角色管理模块是必不可少的部分。这个模块需要实现角色列表展示、详情查看、新增、编辑和删除等功能。传统开发方式下,光是搭建这些基础功能就要花费不少时间。不过我发现用InsCode(快马)平台可以快速生成这些重复性高…...

GCN在推荐系统中的应用:如何用图神经网络提升电商个性化推荐效果
GCN在电商推荐系统中的实战指南:从二部图构建到A/B测试全流程 当你在电商平台浏览商品时,那些"猜你喜欢"的推荐背后,可能正运行着一套基于图神经网络(GCN)的复杂算法系统。与传统的协同过滤不同,GCN能够捕捉用户-商品交…...

2026硬核对比:Claude 4.6官网双版本解析与Gemini 3.1 Pro镜像如何选
对于追求极致编码质量与深度推理的开发者与技术决策者,2026年Anthropic推出的Claude 4.6系列(含旗舰Opus与高性价比Sonnet)在智能体(Agent)能力与长上下文处理上树立了新标杆。 若想在国内网络环境下零成本深度对比其…...

3分钟掌握哔哩下载姬:零安装B站视频下载神器使用指南
3分钟掌握哔哩下载姬:零安装B站视频下载神器使用指南 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&#x…...

KingbaseES V008R006C008B0014物理备份实战:sys_rman从配置到自动化的完整避坑指南
KingbaseES物理备份实战:从sys_rman配置到自动化运维的深度解析 凌晨三点,数据库告警铃声突然响起——某核心业务系统的KingbaseES实例因磁盘故障导致数据丢失。此时,一个配置得当的sys_rman物理备份系统将成为最后的救命稻草。不同于简单的操…...

RevokeMsgPatcher 2.1:实用高效的微信QQ防撤回完整解决方案
RevokeMsgPatcher 2.1:实用高效的微信QQ防撤回完整解决方案 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitco…...

256K上下文颠覆智能编程:Qwen3-Coder重构全栈开发效率范式
256K上下文颠覆智能编程:Qwen3-Coder重构全栈开发效率范式 【免费下载链接】Qwen3-Coder-30B-A3B-Instruct 项目地址: https://ai.gitcode.com/hf_mirrors/unsloth/Qwen3-Coder-30B-A3B-Instruct 问题发现:传统AI编程助手的三大痛点 2025年Stac…...

PHP-JWT:PHP 中 JSON Web Tokens 的完整实现指南
PHP-JWT:PHP 中 JSON Web Tokens 的完整实现指南 【免费下载链接】php-jwt 项目地址: https://gitcode.com/gh_mirrors/ph/php-jwt Firebase PHP-JWT 是一个遵循 RFC 7519 标准的 PHP JSON Web Tokens 实现库,提供安全、高效的 JWT 编码和解码功…...