Apache Hive的基本使用语法(二)
Hive SQL操作
7、修改表
- 表重命名
alter table score4 rename to score5;
- 修改表属性值
# 修改内外表属性
ALTER TABLE table_name SET TBLPROPERTIES("EXTERNAL"="TRUE");
# 修改表注释
ALTER TABLE table_name SET TBLPROPERTIES ('comment' = new_comment);
- 其余属性可参见
点此官网链接查看 - 添加分区
ALTER TABLE tablename ADD PARTITION (month='201101');
- 修改分区值
ALTER TABLE tablename PARTITION (month='202005') RENAME TO PARTITION (month='201105');
- 删除分区
ALTER TABLE tablename DROP PARTITION (month='201105');
- 添加列
ALTER TABLE table_name ADD COLUMNS (v1 int, v2 string);
- 修改列名
ALTER TABLE test_change CHANGE v1 v1new INT;
- 清空表(只可以清空内部表)
TRUNCATE TABLE tablename;
- 删除表
DROP TABLE tablename;
8、数组类型(array)
- 如下数据文件,有2个列,locations列包含多个城市:
说明:name与locations之间制表符分隔,locations中元素之间逗号分隔

可以使用array数组类型,存储locations的数据
建表语句:
create table myhive.test_array(name string, work_locations array<string>)
row format delimited fields terminated by '\t'
COLLECTION ITEMS TERMINATED BY ',';

- 常用查询语句
# 查询所有数据
select * from myhive.test_array;
# 查询loction数组中第一个元素
select name, work_locations[0] location from myhive.test_array;
# 查询location数组中元素的个数
select name, size(work_locations) location from myhive.test_array;
# 查询location数组中包含tianjin的信息
select * from myhive.test_array where array_contains(work_locations,'tianjin');
9、映射类型(map)
- map类型其实就是简单的指代:Key-Value型数据格式。 有如下数据文件,其中members字段是key-value型数据
字段与字段分隔符: “,”;需要map字段之间的分隔符:“#”;map内部k-v分隔符:“:”

- 建表语句
create table myhive.test_map(
id int, name string, members map<string,string>, age int
)
row format delimited
fields terminated by ','
COLLECTION ITEMS TERMINATED BY '#'
MAP KEYS TERMINATED BY ':';

- 常用查询语句
# 查询全部
select * from myhive.test_map;
# 查询father、mother这两个map的key
select id, name, members['father'] father, members['mother'] mother, age from myhive.test_map;
# 查询全部map的key,使用map_keys函数,结果是array类型
select id, name, map_keys(members) as relation from myhive.test_map;
# 查询全部map的value,使用map_values函数,结果是array类型
select id, name, map_values(members) as relation from myhive.test_map;
# 查询map类型的KV对数量
select id,name,size(members) num from myhive.test_map;
# 查询map的key中有brother的数据
select * from myhive.test_map where array_contains(map_keys(members), 'brother');
10、结构类型(struct)
- struct类型是一个复合类型,可以在一个列中存入多个子列,每个子列允许设置类型和名称
有如下数据文件,说明:字段之间#分割,struct之间冒号分割

- 建表语句
create table myhive.test_struct(
id string, info struct<name:string, age:int>
)
row format delimited
fields terminated by '#'
COLLECTION ITEMS TERMINATED BY ':';
- 常用查询
select * from hive_struct;
# 直接使用列名.子列名 即可从struct中取出子列查询
select ip, info.name from hive_struct;
11、数据查询
- 查询语句基本语法如下(跟普通数据库sql查询基本一样):
SELECT [ALL | DISTINCT]select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BYcol_list] [HAVING where_condition] [ORDER BYcol_list] [CLUSTER BYcol_list | [DISTRIBUTE BY col_list] [SORT BY col_list] ] [LIMIT number]
# 排序查询
SELECT * FROM orders WHERE useraddress like '%广东%' ORDER BY totalmoney DESC LIMIT 1;
# 分组查询
SELECT userid, AVG(totalmoney) AS avg_money FROM itheima.orders GROUP BY userid HAVING avg_money > 10000;
# Join连接查询
SELECT o.orderid, o.userid, u.username, o.totalmoney, o.useraddress, o.paytime FROM itheima.orders o LEFT JOIN itheima.users u ON o.userid = u.userid;
# RLIKE查询(支持正则)
SELECT * FROM itheima.orders WHERE useraddress RLIKE '.*广东.*';
SELECT * FROM itheima.orders WHERE userphone RLIKEE '188\\S{4}0\\S{3}';
# UNION查询
SELECT t_id FROM itheima.course WHERE t_id = '周杰轮'UNION ALLSELECT t_id FROM itheima.course WHERE t_id = '王力鸿'
12、数据抽样
- 基于随机分桶抽样语法:
SELECT ... FROM tbl TABLESAMPLE(BUCKET x OUT OF y ON(colname | rand()))
SELECT * FROM orders TABLESAMPLE(BUCKET 1 OUT OF 10 ON rand());
- 基于数据块抽样语法(每一次抽样的结果都一致):
SELECT ... FROM tbl TABLESAMPLE(num ROWS | num PERCENT | num(K|M|G));
- num ROWS 表示抽样num条数据
- num PERCENT 表示抽样num百分百比例的数据
- num(K|M|G) 表示抽取num大小的数据,单位可以是K、M、G表示KB、MB、GB
SELECT * FROM orders TABLESAMPLE(num rows);
13、虚拟列
- 虚拟列是Hive内置的可以在查询语句中使用的特殊标记,可以查询数据本身的详细参数。
- Hive目前可用3个虚拟列:
- INPUT__FILE__NAME,显示数据行所在的具体文件
- BLOCK__OFFSET__INSIDE__FILE,显示数据行所在文件的偏移量
- ROW__OFFSET__INSIDE__BLOCK,显示数据所在HDFS块的偏移量
注:此虚拟列需要设置:SET hive.exec.rowoffset=true 才可使用
SELECT *, INPUT__FILE__NAME, BLOCK__OFFSET__INSIDE__FILE, ROW__OFFSET__INSIDE__BLOCK FROM course;
Hive函数
- Hive的函数分为两大类:内置函数(Built-in Functions)、用户定义函数UDF(User-Defined Functions):

Hive函数官方文档,点此查看 - Hive内置函数(举例说明)
# 查看当下可用的所有函数
show functions
# 查看函数的使用方式
describe function extended funcname
- 数学函数
# 取整函数: round 返回double类型的整数值部分 (遵循四舍五入)
select round(3.1415926);
# 指定精度取整函数: round(double a, int d) 返回指定精度d的double类型
select round(3.1415926,4);
# 取随机数函数: rand 每次执行都不一样 返回一个0到1范围内的随机数
select rand();
# 指定种子取随机数函数: rand(int seed) 得到一个稳定的随机数序列
select rand(3);
# 求数字的绝对值
select abs(-3);
# 得到pi值(小数点后15位精度)
select pi();
- 集合函数

- 类型转换函数

- 日期函数
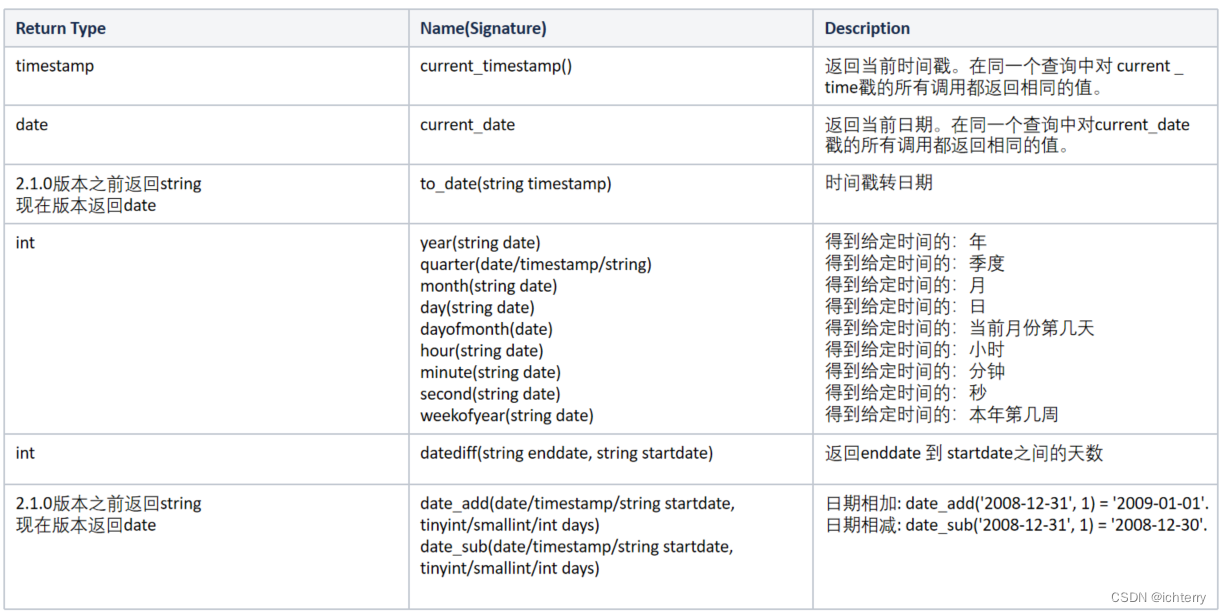
- 条件函数

- 数据脱敏函数

- 字符串函数
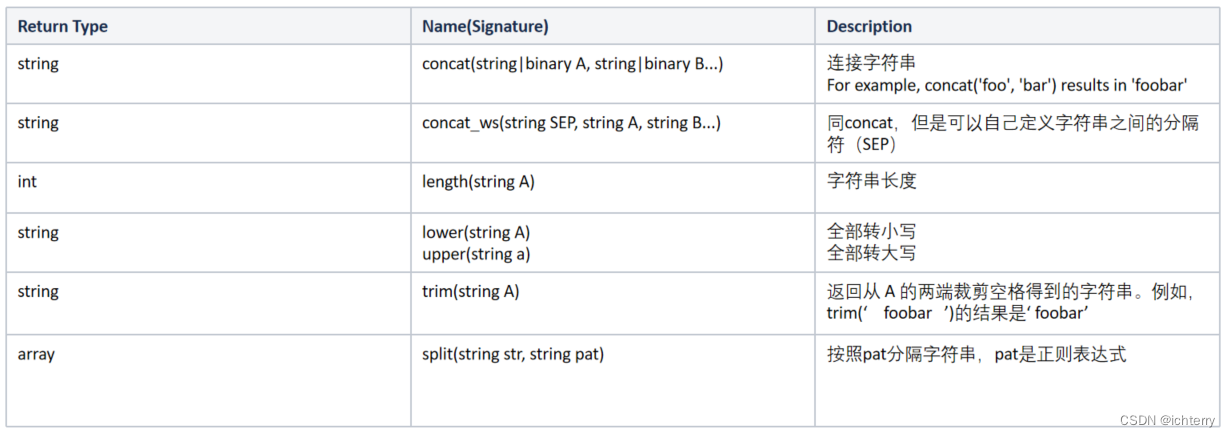
- 其他函数

至此,Apache Hive的基本使用语法分享结束!!!
相关文章:
Apache Hive的基本使用语法(二)
Hive SQL操作 7、修改表 表重命名 alter table score4 rename to score5;修改表属性值 # 修改内外表属性 ALTER TABLE table_name SET TBLPROPERTIES("EXTERNAL""TRUE"); # 修改表注释 ALTER TABLE table_name SET TBLPROPERTIES (comment new_commen…...

基于单片机16位智能抢答器设计
**单片机设计介绍,基于单片机16位智能抢答器设计 文章目录 一 概要二、功能设计设计思路 三、 软件设计原理图 五、 程序六、 文章目录 一 概要 基于单片机16位智能抢答器设计是一个结合了单片机技术、显示技术、按键输入技术以及声音提示技术的综合性项目。其设计…...

idea默认代码生成脚本修改
修改了下idea自带的代码生成脚本,增加了脚本代码的注释,生成了controller,service,impl,mapper,里面都是空的,具体可以根据自己的代码习惯增加 代码生成脚本的使用可以看下使用 idea 生成实体类…...
StarRocks实战——多点大数据数仓构建
目录 前言 一、背景介绍 二、原有架构的痛点 2.1 技术成本 2.2 开发成本 2.2.1 离线 T1 更新的分析场景 2.2.2 实时更新分析场景 2.2.3 固定维度分析场景 2.2.4 运维成本 三、选择StarRocks的原因 3.1 引擎收敛 3.2 “大宽表”模型替换 3.3 简化Lambda架构 3.4 模…...
jmeter总结之:Regular Expression Extractor元件
Regular Expression Extractor是一个后处理器元件,使用正则从服务器的响应中提取数据,并将这些数据保存到JMeter变量中,以便在后续的请求或断言中使用。在处理动态数据或验证响应中的特定信息时很有用。 添加Regular Expression Extractor元…...

快速上手Spring Cloud 七:事件驱动架构与Spring Cloud
快速上手Spring Cloud 一:Spring Cloud 简介 快速上手Spring Cloud 二:核心组件解析 快速上手Spring Cloud 三:API网关深入探索与实战应用 快速上手Spring Cloud 四:微服务治理与安全 快速上手Spring Cloud 五:Spring …...

leetcode 1997.访问完所有房间的第一天
思路:动态规划前缀和 这道题还是很难的,因为你如果需要推出状态方程是很难想的。 在题中我们其实可以发现,这里在访问nextVisit数组的过程中,其实就是对于当前访问的房子之前的房子进行了回访。 怎么说呢?比如你现在…...
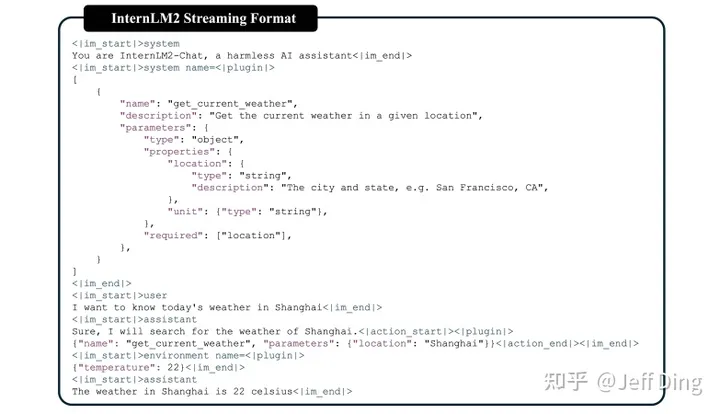
【InternLM 实战营第二期笔记】书生·浦语大模型全链路开源体系及InternLM2技术报告笔记
大模型 大模型成为发展通用人工智能的重要途径 专用模型:针对特定任务,一个模型解决一个问题 通用大模型:一个模型应对多种任务、多种模态 书生浦语大模型开源历程 2023.6.7:InternLM千亿参数语言大模型发布 2023.7.6&#…...
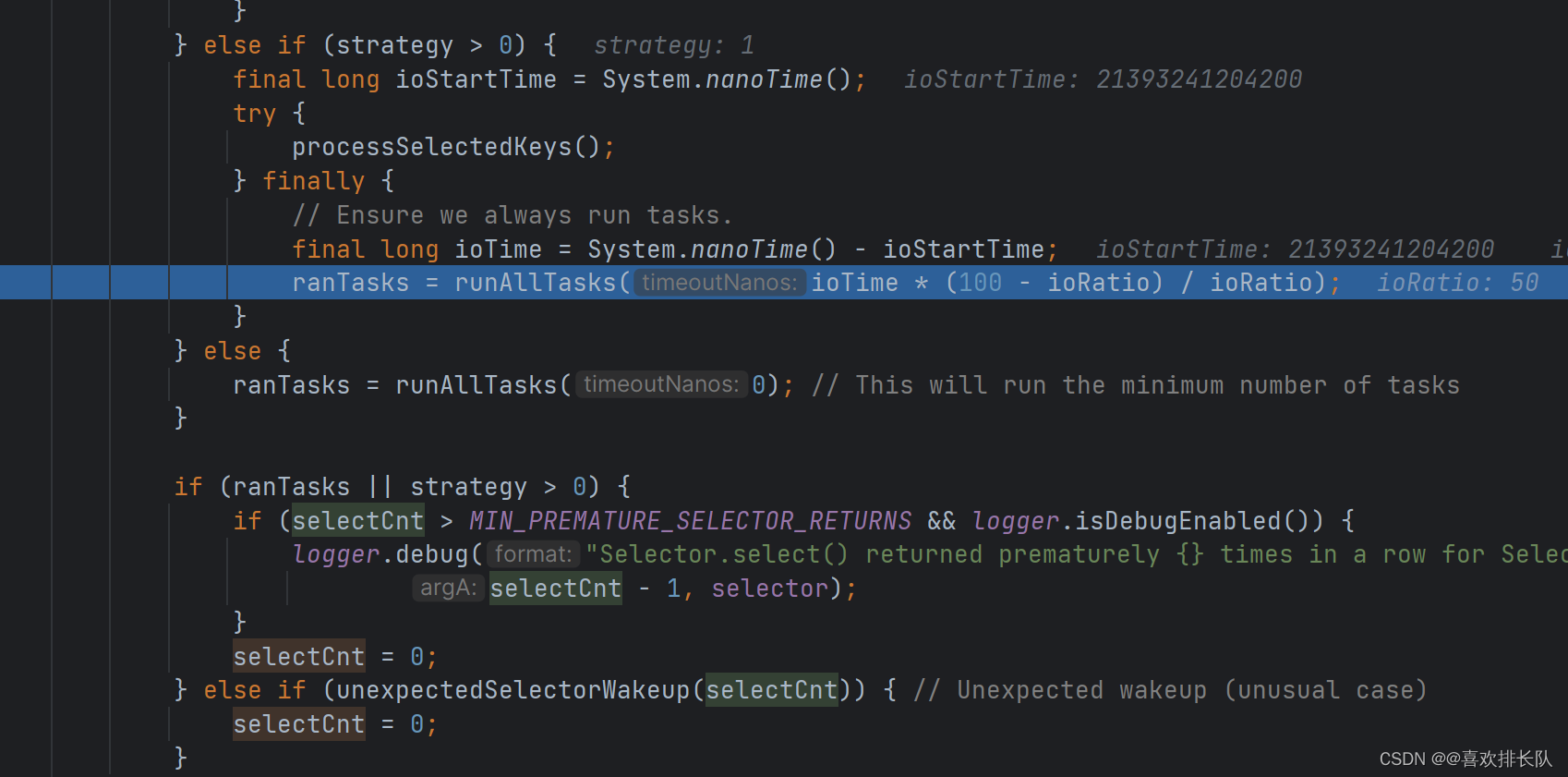
Netty对Channel事件的处理以及空轮询Bug的解决
继续上一篇Netty文章,这篇文章主要分析Netty对Channel事件的处理以及空轮询Bug的解决 当Netty中采用循环处理事件和提交的任务时 由于此时我在客户端建立连接,此时服务端没有提交任何任务 此时select方法让Selector进入无休止的阻塞等待 此时selectCnt进…...

【PostgreSQL】- 1.1 在 Debian 12 上安装 PostgreSQL 15
官方说明参考 (原文 PostgreSQL:Linux 下载 (Debian)) 默认情况下,PostgreSQL 在所有 Debian 版本中都可用。但是, Debians 的稳定版本“快照”了特定版本的 PostgreSQL 然后在该 Debian 版本的…...

第4章.精通标准提示,引领ChatGPT精准输出
标准提示 标准提示,是引导ChatGPT输出的一个简单方法,它提供了一个具体的任务让模型完成。 如果你要生成一篇新闻摘要。你只要发送指示词:汇总这篇新闻 : …… 提示公式:生成[任务] 生成新闻文章的摘要: 任务&#x…...
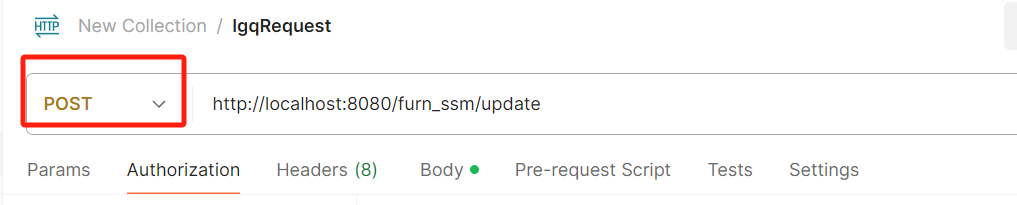
HTTP状态 405 - 方法不允许
方法有问题。 用Post发的请求,然后用Put接收的。 大家也可以看看是不是有这种问题 <body><h1>HTTP状态 405 - 方法不允许</h1><hr class"line" /><p><b>类型</b> 状态报告</p><p><b>消息…...

题目 2898: 二维数组回形遍历
题目描述: 给定一个row行col列的整数数组array,要求从array[0][0]元素开始,按回形从外向内顺时针顺序遍历整个数组。如图所示: 代码: package lanqiao;import java.math.BigInteger; import java.util.*;public class Main {public static …...
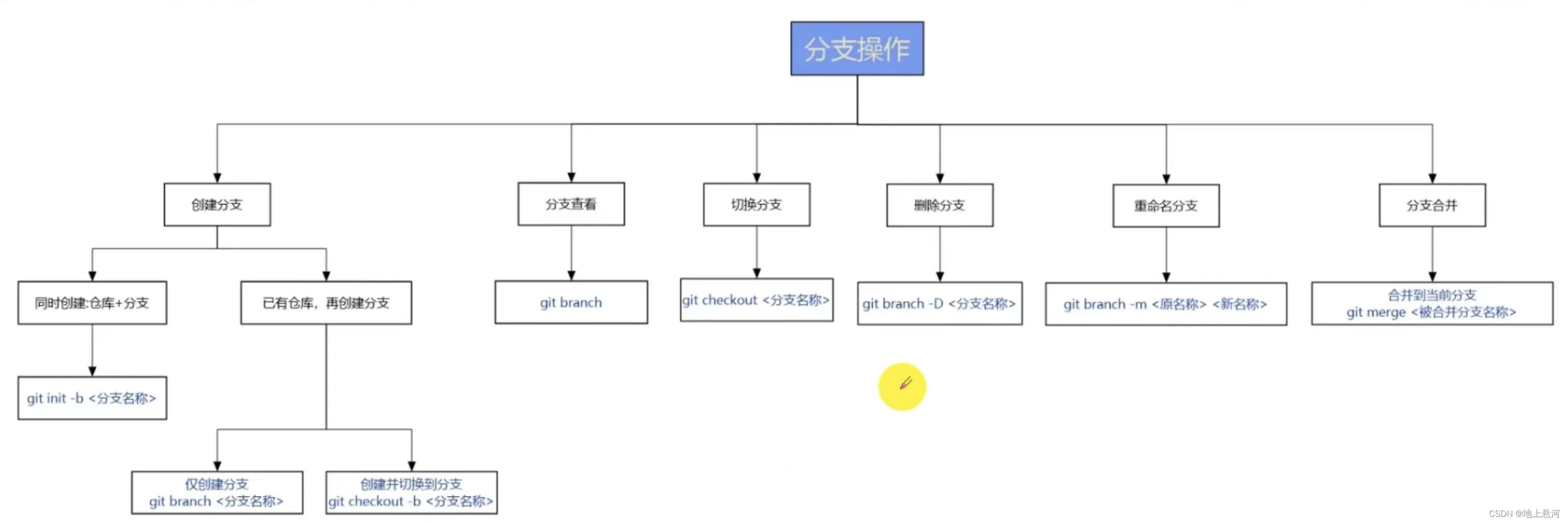
Git命令上传本地项目至github
记录如何创建个人仓库并上传已有代码至github in MacOS环境 0. 首先下载git 方法很多 这里就不介绍了 1. Github Create a new repository 先在github上创建一个空仓库,用于一会儿链接项目文件,按照自己的需求设置name和是否private 2.push an exis…...

机器学习之决策树现成的模型使用
目录 须知 DecisionTreeClassifier sklearn.tree.plot_tree cost_complexity_pruning_path(X_train, y_train) CART分类树算法 基尼指数 分类树的构建思想 对于离散的数据 对于连续值 剪枝策略 剪枝是什么 剪枝的分类 预剪枝 后剪枝 后剪枝策略体现之威斯康辛州乳…...
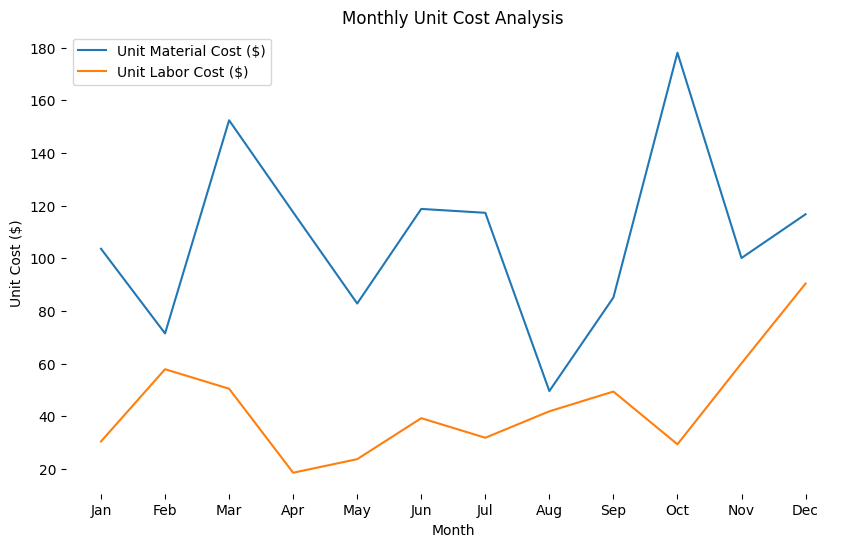
【python分析实战】成本:揭示电商平台月度开支与成本结构占比 - 过于详细 【收藏】
重点关注本文思路,用python分析,方便大家实验复现,代码每次都用全量的,其他工具自行选择。 全文3000字,阅读10min,操作1小时 企业案例实战欢迎关注专栏 每日更新:https://blog.csdn.net/cciehl/…...

新网站收录时间是多久,新建网站多久被百度收录
对于新建的网站而言,被搜索引擎收录是非常重要的一步,它标志着网站的正式上线和对外开放。然而,新网站被搜索引擎收录需要一定的时间,而且时间长短受多种因素影响。本文将探讨新网站收录需要多长时间,以及新建网站多久…...
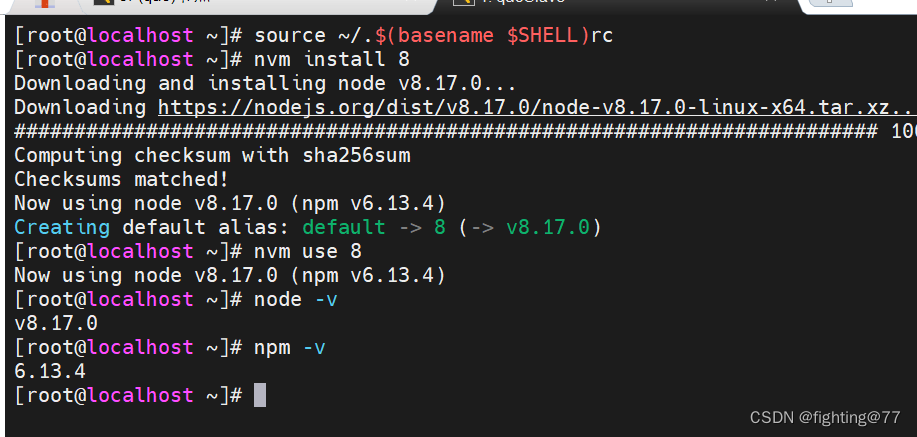
通过Caliper进行压力测试程序,且汇总压力测试问题解决
环境要求 第一步. 配置基本环境 部署Caliper的计算机需要有外网权限;操作系统版本需要满足以下要求:Ubuntu >= 16.04、CentOS >= 7或MacOS >= 10.14;部署Caliper的计算机需要安装有以下软件:python 2.7、make、g++(gcc-c++)、gcc及git。第二步. 安装NodeJS # …...

LabVIEW比例流量阀自动测试系统
LabVIEW比例流量阀自动测试系统 开发了一套基于LabVIEW编程和PLC控制的比例流量阀自动测试系统。通过引入改进的FCMAC算法至测试回路的压力控制系统,有效提升了压力控制效果,展现了系统的设计理念和实现方法。 项目背景: 比例流量阀在液压…...

安卓U3D逆向从Assembly-CSharp到il2cpp
随着unity技术的发展及厂商对于脚本源码的保护,很大一部分U3D应用的scripting backend已经由mono转为了il2cpp,本文从unity简单应用的制作讲起,介绍U3D应用脚本的Assembly-CSharp.dll的逆向及il2cpp.so的逆向分析。 目录如下: 0…...

中文大语言模型智能路由:统一接口调度多模型,实现降本增效
1. 项目概述:一个中文大语言模型路由器的诞生最近在折腾大语言模型应用开发的朋友,估计都遇到过这个头疼的问题:手头有好几个模型,比如智谱的GLM、百度的文心、阿里的通义,还有一堆开源的,每个模型都有自己…...

翻转电饼铛生产厂家:高性价比背后的运营策略深度解析
翻转电饼铛生产厂家:高性价比背后的运营策略深度解析“高性价比不是低价竞争,而是让设备价值与企业需求精准匹配”——这是优质翻转电饼铛生产厂家的核心运营逻辑。很多食品企业在选购翻转电饼铛时,既担心高价设备增加成本,又怕低…...

告别纯前端‘假识别’:UniApp+微信小程序如何实现真·人脸检测与姿态校验
告别纯前端‘假识别’:UniApp微信小程序如何实现真人脸检测与姿态校验 在移动应用开发中,人脸识别功能已经从单纯的"拍照上传"进化到了需要实时验证用户真实性的阶段。许多开发者可能遇到过这样的尴尬:用户上传的照片明明不符合要求…...

Chrome网页批量替换神器:3分钟掌握高效文本编辑技巧
Chrome网页批量替换神器:3分钟掌握高效文本编辑技巧 【免费下载链接】chrome-extensions-searchReplace 项目地址: https://gitcode.com/gh_mirrors/ch/chrome-extensions-searchReplace 你是否曾为网页上重复的文本修改而烦恼?面对需要批量替换…...

耳机选购指南:从音质佩戴到无线降噪,构建你的场景化耳机衣橱
1. 耳机选购的底层逻辑:从“听个响”到“场景化生存”我家里有个抽屉,专门用来放耳机,数了数,不下十几副。从最早那副压箱底的Koss头戴式,到如今几乎长在耳朵上的AirPods Pro,每一副都对应着我生活里一个特…...

douyin-downloader技术架构革新:混合策略下载引擎与智能任务调度系统深度解析
douyin-downloader技术架构革新:混合策略下载引擎与智能任务调度系统深度解析 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and …...

Termux SSH服务从安装到外网访问全攻略:用手机IP和ngrok实现随时随地远程控制
Termux SSH服务外网访问实战:手机变身24小时远程服务器的完整方案 在咖啡馆修改代码时突然需要调用家里手机存储的某个配置文件,出差途中想检查一下家中树莓派设备的运行状态,或是深夜突发灵感想启动卧室智能设备的某个自动化流程——这些场景…...

船载AIS的Class A、Class B和接收器到底怎么选?一篇讲清休闲帆船、渔船和小货船的设备配置指南
船载AIS设备选购全指南:从合规到实战的智能决策 清晨的港口,一艘30英尺的休闲帆船正在做最后的出海准备。船长盯着仪表盘上闪烁的AIS接收器信号,思考着是否该升级为收发一体的Class B设备——这个决定可能关系到未来航行中能否被大型商船及时…...

GPT宏系统开发指南:从提示词模板到RAG知识库的自动化实践
1. 项目概述:一个让GPT“记住”并“执行”的自动化利器如果你经常和GPT打交道,无论是ChatGPT的Web界面,还是通过API调用,肯定都遇到过这样的烦恼:每次对话,你都得把那些重复的、固定的指令或背景信息再敲一…...

特征工程:从数据到特征
特征工程:从数据到特征 1. 技术分析 1.1 特征工程流程 特征工程是机器学习的核心环节: 特征工程流程数据理解 → 特征提取 → 特征选择 → 特征转换 → 特征验证1.2 特征类型 类型描述处理方法数值型连续数值归一化、标准化分类型类别标签独热编码、…...