MySQL索引18连问,谁能顶住
前言
过完这个节,就要进入金银季,准备了 18 道 MySQL 索引题,一定用得上。
- 作者:
- 感谢每一个支持: github
1. 索引是什么
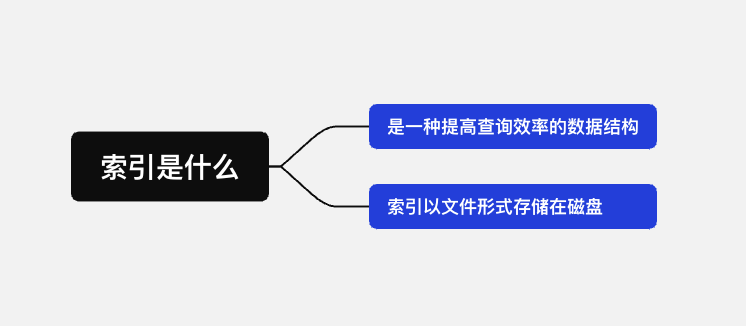
- 索引是一种数据结构,用来帮助提升查询和检索数据速度。可以理解为一本书的目录,帮助定位数据位置。
- 索引是一个文件,它要占用物理空间。
2. MySQL索引有哪些类型
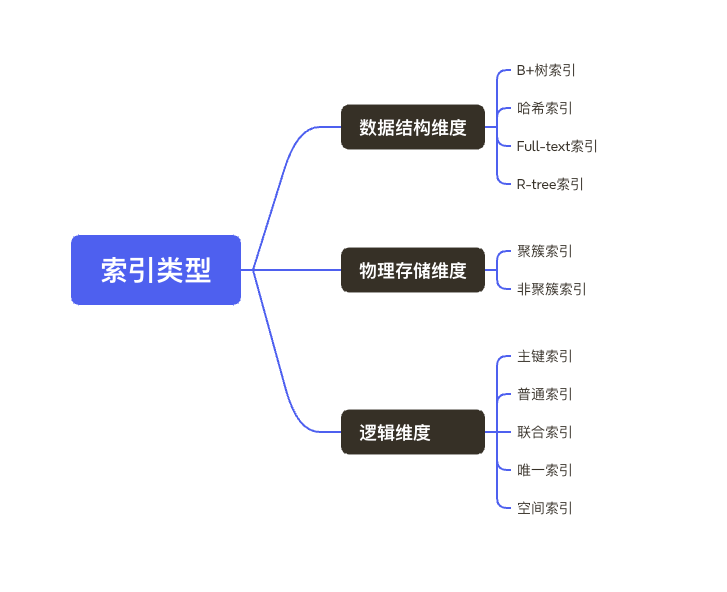
数据结构维度
- B+tree 索引: B+树是最常用的索引类型,所有数据都会存储在叶子节点上,时间复杂度是
O(logn),擅长范围查询。 - Hash 索引: 哈希索引就是采用哈希算法,将键值换算成新的哈希值,映射到对应槽位,然后存储到哈希表中,擅长做对等比较(=,in)。
- Full-text 索引: 全文索引是一种建立倒排索引,实现信息检索。在 MySQL 不同版本中支持程度不同。
R-Tree索引: 属于地理空间数据类型查询,通常使用较少。
物理存储维度
簇 cù
-
聚簇索引:
InnoDB 引擎要求必须有聚簇索引,也就是在主键字段建立聚簇索引。 -
非聚簇索引: 非聚簇索引就是以非主键创建的索引,在叶子节点存储的是表主键和索引列。
InnoDB 引擎
逻辑维度
-
主键索引: 主键索引是一种特殊的唯一索引,不允许值重复或者值为空。
-
普通索引: 普通索引是 MySQL 中最基本的索引类型,允许在定义索引的列中插入重复值和空值。
-
联合索引: 联合索引指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用联合索引时遵循最左前缀集合。
-
唯一索引: 唯一索引列的值必须唯一,允许有空值。
-
空间索引: 空间索引是一种针对空间数据类型(如点、线、多边形等)建立的特殊索引,用于加速地理空间数据的查询和检索操作。
3. 主键索引和唯一索引有什么区别
- 数量限制: 唯一索引有多个,但是主键索引一张表只能有一个。
- 本质区别: 被唯一索引约束的健可以为空,主键索引不可以。
- 外键引用: 主键可以被其他表作为外键,从而建立表之间的关系。而唯一索引则不能被其他表用作外键。
4. 什么是聚簇索引和非聚簇索引?它们在InnoDB存储引擎中是如何工作的?
聚簇索引是将表的数据按照索引顺序存储在磁盘上,聚簇索引的叶子节点直接存储了实际的数据行,而不是指向数据的指针。所以在查询的时候减少了磁盘的随机读取,无需进行多次磁盘I/O效率很高。
非聚簇索引是一种基于指针的索引,有时也叫它二级索引。非聚簇索引不直接存储实际的数据,seelec 语句在执行查询时,会先根据二级索引定位到数据所在的磁盘位置,然后再进行一次磁盘I/O操作,读取实际的数据行。
5. 复合索引和单列索引有何区别?
-
顾名思义,单列索引就是在一个列上创建的索引,复合索引就是多个列上创建的索引。
-
当只涉及到一个字段查询,单列是非常快速的。当涉及到多个字段查询,WHERE 子句引用了符合索引的所有列或者前导列时,查询速度会非常快。
-
在复合索引中,列的顺序非常重要。MySQL会按照索引中列的顺序从左到右进行匹配。例如,对于复合索引(a, b, c),它可以支持a、a,b和a,b,c三种组合的查询,但不支持b,c进行查询。因此,在创建复合索引时,应把最常被访问和选择性较高的列放在前面。
当然具体如何选择需要看查询需求、数据分布和性能要求。如果你有开发需要欢迎在 JavaPub 下留言讨论。
6. Hash 索引和 B+ 树索引区别是什么?如何选择?
哈希索引:
- 工作原理:通过哈希算法将被索引的列的值存储到一个固定长度的桶(Bucket)。使得在查询特定值的时候非常高效,因为可以直接计算出存储位置,快速定位到数据。
- 查询效率:在等值查询下,哈希查询效率极高,可以在常数时间复杂度内定位到目标数据。但是范围查询和排序操作时,哈希索引的效率较低,因为哈希算法会导致数据随机分布,无法保持原有的顺序。
- 磁盘存储:hash 索引的存储是随机的,可能导致磁盘的随机访问,从而降低磁盘的利用效率和查询效率。
- 插入和删除操作:Hash 索引在插入和删除操作方面相对简单,只需要通过哈希函数确定存储位置即可。
B+树白话详解_下载
B+树索引
- 工作原理:B+树索引使用平衡树,将索引健的值按照顺序保存在树节点中,根据键值的大小关系,并通过节点之间的指针进行查找,快速定位存储了数据的叶子节点。
- 查询效率:B+树擅长范围查询和排序操作,因为他是按照顺序存储数据,可以高效的支持范围查询和排序操作。
- 磁盘存储:B+树索引的节点是有序存储的,有利于磁盘的顺序访问,从而减少磁盘的IO次数,提高查询效率。
- 插入和删除操作:B+树在索引删除和插入操作时,需要维护树的平衡,可能进行节点的拆分和合并,相对哈希索引来说操作更复杂。
所以在选择上:
- 查询维度:如果查询主要是等值查询,且对性能要求较高,Hash 索引可能是一个好的选择。然而,如果查询涉及到范围查询、排序操作或模糊查询,B+ 树索引则更为合适。
- 数据维度:如果索引列具有大量重复值,Hash索引的效率可能会下降,因为哈希碰撞会导致性能下降。在这种情况下,B+ 树索引可能更为稳定。
- 磁盘存储和I/O维度:由于 Hash 索引可能导致磁盘的随机访问,如果磁盘 IO 是性能瓶颈,那么 B+ 树索引可能更适合,因为它更有利于磁盘的顺序访问。
从这三个维度可以很好的应用在你的开发工作中,如果是小数据量的 web 网站查询、直接用 B+ 树就可以了。对于数据量的大小评估,后面单开一篇讲解。
7. 索引是否越多越好?为什么?
不是。索引是建立在原数据上的数据结构,所以不论在查询还是更新维护、一定会带来开销。
比如一本书有 100 页,我构建了 50 页的目录,你觉查询起来还会方便吗?
- 数据量小的表不需要建立索引,建立索引反而会增加额外开销。
- 数据变更后索引也需要更新,更多的索引意味着更多的维护成本。
- 索引是放在磁盘的,更能的索引也意味着更多的存储空间。
- 数据重复且分布平均的字短没必要建立索引(比如:性别)
索引并非银弹,正确使用才能发挥奇效。
8. 索引什么时候会失效?
慢 SQL 是数据库使用中最长遇见的问题,当遇到慢 SQL 时,首先我们就要去看是不是索引失效。一般会有以下几种常见的情况:
- Where 条件中包含 OR: 当查询条件中包含 OR,即使其中某些条件带有索引,也会全表扫描。下例中 username 没有索引,就算 id 走了索引也需要全表扫描,所以引擎大概率不会走索引。
失效索引: id 有索引, username 没有索引。
explain select * from t_user where id = 2 or username = 'javapub';
- 多列索引没有最左匹配: 对于复合索引,如果查询条件没有从索引的第一部分匹配,则不会使用索引。也就是我们在使用联合索引时,要正确使用最左匹配。
例如,如果你有一个(id, name)的多列索引,但查询条件只使用了name,那么索引不会被使用。
-
LIKE 查询以%开头: 当使用LIKE操作符进行模糊查询,并且模式以%开头时,索引将不会生效。这是因为以%开头的模式匹配意味着匹配的字符串可以在任何位置,这使得索引无法有效定位数据。
-
索引列参与计算: 当我们在查询条件中对索引列进行表达式计算,也是无法走索引的。比如:
select * from t_user where id > age;
- 类型不匹配导致隐式转换: 当表里存的是 varchar 类型的字段时,用 int 类型去查询,导致全表扫描。如下例子中:
explain select * from t_user where id_no = 1002;
表里的 id_no 是 varchar 类型。
出了这几种情况还有一些导致索引失效。 例如:
-
全表扫描效率更优:在某些情况下,MySQL 优 化器可能认为全表扫描比使用索引更快。
-
数据分布不均:如果索引列的数据分布非常不均匀,MySQL 可能不会选择使用索引。
-
索引列包含 NULL 值:如果索引列包含 NULL 值,MySQL可 能不会使用索引,因为 NULL 值的比较有特殊性。因为NULL值无法与其他值进行比较或匹配,所以无法使用索引。
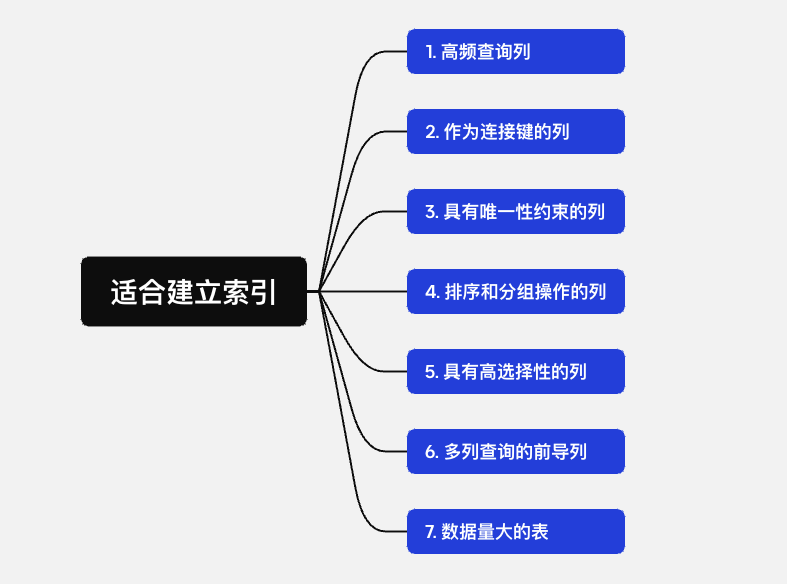
9. 哪些情况下适合建立索引?
-
高频查询列: 对于经常出现在查询条件中的列,建立索引可以加快查询速度。例如,经常根据username或email字段查询的用户表。
-
作为连接键的列: 在执行表连接操作时,用于连接的列(通常在ON子句中指定)应该建立索引,以加快连接操作的速度。
-
具有唯一性约束的列: 对于需要保证唯一性的列,如主键或具有唯一约束的列,建立索引是必要的,因为索引可以帮助快速检查重复的数据。
-
排序和分组操作的列: 在ORDER BY、GROUP BY或DISTINCT操作中使用的列,通过建立索引可以加快排序和分组的处理速度。
-
具有高选择性的列: 选择性是指不同值的数量与总行数的比率。具有高选择性的列(即列中的值分布广泛)适合建立索引,因为这样的索引可以更有效地缩小搜索范围。
-
多列查询的前导列: 如果你经常执行涉及多个列的查询,可以在这些列上建立组合索引,其中最常用作查询条件的列应该放在索引的最前面。
-
数据量大的表: 对于数据量较大的表,合理地建立索引可以大幅提高查询效率。但是,对于数据量小的表,由于数据量本身就少,索引可能不会带来太大的性能提升,反而可能增加插入、更新和删除操作的开销。
在考虑建立索引时,也需要考虑以下因素:
-
更新频率:频繁更新的列可能不适合建立索引,因为每次更新都可能导致索引的重新构建,增加开销。
-
索引的维护成本:索引不仅占用存储空间,还会增加数据插入、删除和更新操作的维护成本。
-
查询类型:需要分析查询类型,确保索引能够被有效利用。例如,对于只读或几乎只读的表,建立索引可能没有太大必要。
10. 为什么要用 B+ 树,而不用二叉树?
-
查询性能稳定: B+树通过多层索引结构,使得查询性能更加稳定。在最坏的情况下,B+树的查询时间复杂度仍然是对数级别(O(log n)),而二叉树在最坏情况下(退化成链表)的时间复杂度为线性(O(n))。这意味着即使数据分布极不均匀,B+树也能保持较高的查询效率。
-
空间局部性: B+树的叶子节点包含了所有数据记录,并且通过指针相互连接,形成了一个有序链表。这种结构使得范围查询和顺序访问更加高效,因为相邻的数据在物理存储上也是相邻的。而二叉树不具备这种空间局部性,数据的物理存储位置可能分散。
-
磁盘I/O优化: 数据库操作经常涉及磁盘I/O,B+树的设计更适合减少磁盘访问次数。由于B+树的非叶子节点不存储实际数据,可以使得每个节点包含更多的键值,从而降低树的高度。这样,在一次磁盘I/O操作中可以读取更多的索引信息,减少了I/O次数。
-
高效的范围查询和排序: B+树的有序链表结构使得它在执行范围查询和排序操作时非常高效。而二叉树需要进行中序遍历才能得到有序的结果,效率较低。
-
节点分裂和合并的开销: 在二叉树中,插入和删除操作可能导致频繁的节点分裂和合并,增加了操作的复杂性。B+树通过减少节点分裂和合并的次数,降低了维护开销。
-
非叶子节点的简洁性: B+树的非叶子节点仅用于索引,不存储实际数据,这样可以使得每个节点包含更多的键值对,进一步降低树的高度。
-
更新操作的效率: 由于B+树的高度通常较低,更新操作(插入、删除)时需要遍历的节点数量较少,从而提高了更新操作的效率。
总的来说,B+树在数据库索引中提供了更稳定的查询性能、优化的磁盘I/O操作、高效的范围查询和排序,以及较低的维护成本。
11. 什么是回表?如何减少回表?
回表定义: MySQL回表查询是指在使用索引进行查询时,MySQL数据库引擎在通过索引定位到数据行后,发现需要访问表中的其他列数据,而不是直接通过索引就能获取到所需的数据。这种情况下,MySQL需要再次访问表中的数据行,这个过程就称为回表查询(Referring to the table)。
-
覆盖索引: 覆盖索引是指一个查询可以完全通过索引来得到结果,而不需要访问数据表的行。如果查询只需要索引中包含的字段,那么就无需回表。设计良好的覆盖索引可以显著减少回表操作。
-
**避免SELECT ***: 在编写查询时,尽量指定需要的列,而不是使用SELECT *来选择所有列。这样可以减少不必要的数据访问,从而减少回表。
-
索引包含所需列: 确保查询中涉及的列都被包含在索引中。如果索引包含了所有需要的列,那么查询可能不需要回表。
-
使用复合索引: 如果查询经常根据多个列进行过滤,可以考虑创建一个包含这些列的复合索引。这样可以在一个索引中完成查询,减少回表。
-
优化查询逻辑: 分析查询逻辑,尽量减少不必要的回表操作。例如,如果查询中的某些条件不太可能同时满足,可以考虑将它们分开处理,或者使用临时表来存储中间结果。
-
使用物化视图或汇总表: 对于频繁执行的复杂查询,可以考虑使用物化视图或汇总表来存储查询结果。这样,当需要这些数据时,可以直接从物化视图或汇总表中获取,而无需进行回表操作。
当然,不是所有情况都不允许回表,有时候,适当的回表是必要的,因为索引的设计需要平衡查询性能和存储空间的利用。
12. 能否解释什么是位图索引,以及它在MySQL中的使用场景?
位图索引是一种将数据列的所有可能值映射到二进制位上的索引。每个位表示某个值是否存在于该列中,从而帮助我们快速定位符合某个条件的行。与其他类型的索引相比,位图索引通常在低基数列(即列中有限的不同值)上表现更好。
可以参考 bitmap 数据结构来理解
例子:
在该示例中,我们为 age 和 country 列分别创建了位图索引。由于使用了位图索引,查询性能将大大提高。
CREATE TABLE users (id INT PRIMARY KEY,name VARCHAR(50),age INT,country VARCHAR(50)
);CREATE BITMAP INDEX idx_age ON users(age);
CREATE BITMAP INDEX idx_country ON users(country);SELECT * FROM users WHERE age = 20 AND country = 'China';
13. 如何查看MySQL表中已有的索引?
两种方式:
- 使用 SHOW INDEX,也是最常用的。
SHOW INDEX FROM your_table_name;
- 查询 information_schema 数据库,information_schema 是 MySQL 中包含元数据的特殊数据库。我可以查询其中的 TABLES 和 STATISTICS 表来获取索引信息。
SELECT TABLE_SCHEMA, TABLE_NAME, NON_UNIQUE, INDEX_NAME, INDEX_TYPE, INDEX_COMMENT, SEQ_IN_INDEX, COLUMN_NAME, CARDINALITY, SUB_PART, PACKED, NULLABLE, INDEX_DIR, INDEX_DISC
FROM information_schema.STATISTICS
WHERE TABLE_SCHEMA = 'your_database_name' AND TABLE_NAME = 'your_table_name';
14. 如何在MySQL中创建全文索引,并说明全文索引的使用场景?
正例:
CREATE TABLE articles (id INT NOT NULL AUTO_INCREMENT,title VARCHAR(255) NOT NULL,content TEXT NOT NULL,PRIMARY KEY (id),FULLTEXT INDEX (title, content) -- 创建联合全文索引
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
当已经建好表结构,使用 ALTER TABLE 创建:
ALTER TABLE articles
ADD FULLTEXT INDEX ft_index (title, content);
全文索引一般用于内容管理平台(CMS),问答社区等检索场景,然而,全文索引也有一些限制,比如它只能用于MyISAM或InnoDB存储引擎(在MySQL 5.6及以上版本中),并且全文索引的列不能是NULL值。
实际应用中其实很少会使用到,现在多数使用 ElasticSearch 来搭建全文搜索引擎。
15. 当表中的数据量非常大时,如何有效地维护和管理索引,以确保查询性能?
索引主要是为了优化查询性能而设计的。如果一个字段的查询频率远低于更新频率,那么为该字段创建索引可能不会带来预期的性能提升,反而可能因为维护索引而降低整体性能。
-
性能开销: 索引的维护需要额外的计算和存储资源。当对一个字段进行大量的更新操作时,数据库系统不仅需要更新数据本身,还需要更新所有相关的索引。这会导致性能开销增加,尤其是在高并发的写操作环境中。
-
存储空间: 索引本身占用存储空间。对于经常更新的字段,如果创建了索引,那么每次数据更新都可能导致索引的页面分裂,进而需要更多的存储空间来维护索引结构。
-
索引失效: 频繁的更新操作可能导致索引的页变得碎片化,从而降低索引的效率。索引页的碎片化意味着索引中的数据不再按照顺序存储,这会增加数据库在执行查询操作时的磁盘I/O次数,因为数据库可能需要读取多个不连续的页面来满足查询条件。
-
更新锁竞争: 在高并发的更新操作中,索引可能会成为锁竞争的瓶颈。当多个事务尝试更新同一索引页时,可能会发生锁等待,这会降低并发性能。
16. 假设你有一个包含大量数据的表,并且经常需要根据某个字段进行排序。你应如何优化这个字段的索引以提高排序操作的性能?
当你尝试为一个已经存在大量数据的表添加索引时,可能会遇到什么问题?如何解决这些问题?
首先:
如果是亿级大表,在建表时就要添加必要的索引,否则存入过多数据可能会出现加不成功的现象。
垂直拆分
按照业务维度拆分。
水平拆分
按照不同的行进行分片,分散到不同的物理表中。
创建索引
分区
根据实际情况进行数据分区,但是要注意分区后可能影响写入性能。
优化查询语句
分布式数据库
17. 如何优化索引
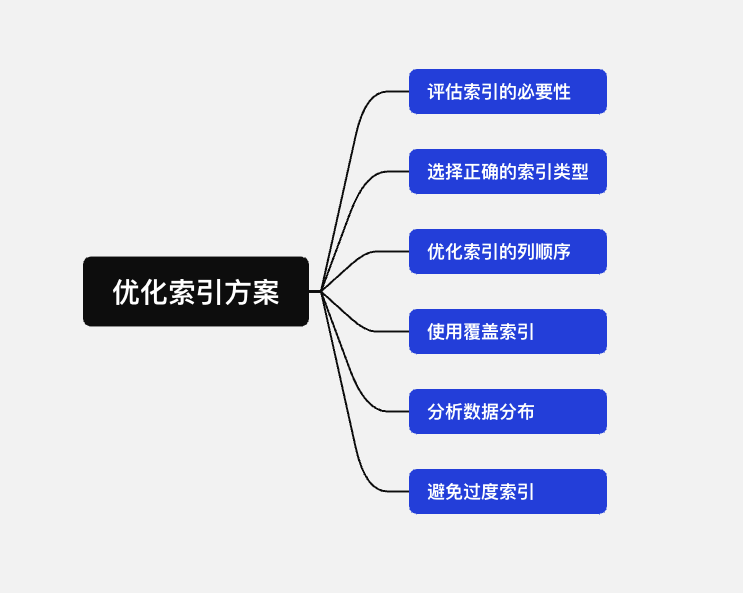
当你遇到查询性能问题时,如何分析和优化索引的使用?开放性问题。
- 评估索引的必要性,不是所有字段都要走索引。
- 选择正确的索引类型,例如,B-tree索引适合范围查询和排序操作,Hash索引适合等值查询,Bitmap索引适合低基数(不同值的数量较少)的列。
- 优化索引的列顺序:在创建多列索引时,考虑列的访问模式和查询类型。通常,将最常用作查询条件的列放在索引的前面,因为数据库可以更有效地使用这些列来过滤数据。
- 使用覆盖索引:如果查询只访问索引中包含的列,使用覆盖索引可以避免访问数据行本身,从而提高查询性能。
- 分析数据分布:对于列的值分布进行分析,避免在高度重复的列上创建索引,因为这样的索引可能不会带来显著的性能提升。
- 避免过度索引:过多的索引会增加数据库的维护成本,尤其是在数据插入、更新和删除时。确保每个索引都有其明确的用途,并定期审查和清理不再需要的索引。
18. 请谈谈你对 MySQL 索引碎片化的理解,并说明如何检测和修复索引碎片化。
**如何检测索引碎片化?**两个方法
-
使用SHOW TABLE STATUS命令: 通过执行
SHOW TABLE STATUS LIKE 'table_name';可以获取表的状态信息,其中包括 Data_free 字段,它表示表中未使用的空间百分比。如果这个值相对较高,可能表明表存在碎片化问题。 -
使用 INFORMATION_SCHEMA.TABLES 表: 查询
INFORMATION_SCHEMA.TABLES可以获取表的碎片化信息。例如:
SELECT table_name, table_schema, Data_free / Data_length * 100 AS碎片化百分比
FROM information_schema.TABLES
WHERE table_schema = 'your_database_name' AND Data_free > 0;
如何修复索引碎片化?
- 优化表的存储引擎:
对于 MyISAM 存储引擎,可以使用 OPTIMIZE TABLE 命令来重新组织表的数据,减少碎片化。对于 InnoDB 存储引擎,这个命令也会尝试优化表,但效果可能不如 MyISAM 明显。
OPTIMIZE TABLE table_name;
- 重建索引:
对于 InnoDB 存储引擎,可以通过 ALTER TABLE 命令来重建表的索引,这通常比 OPTIMIZE TABLE 更有效。
ALTER TABLE table_name ENGINE=InnoDB;
- 定期维护:
定期执行 OPTIMIZE TABLE 或 ALTER TABLE 命令可以帮助维持索引的健康状况,减少碎片化。
需要注意的是,优化表的操作可能会消耗大量的系统资源,并且可能需要较长的时间来完成,特别是对于大型表。因此,在执行这些操作之前,最好在测试环境中进行评估,并在业务低峰时段进行。此外,确保在执行优化操作之前备份数据,以防万一出现问题。
相关文章:
MySQL索引18连问,谁能顶住
前言 过完这个节,就要进入金银季,准备了 18 道 MySQL 索引题,一定用得上。 作者:感谢每一个支持: github 1. 索引是什么 索引是一种数据结构,用来帮助提升查询和检索数据速度。可以理解为一本书的目录&…...
[flink 实时流基础系列]揭开flink的什么面纱基础一
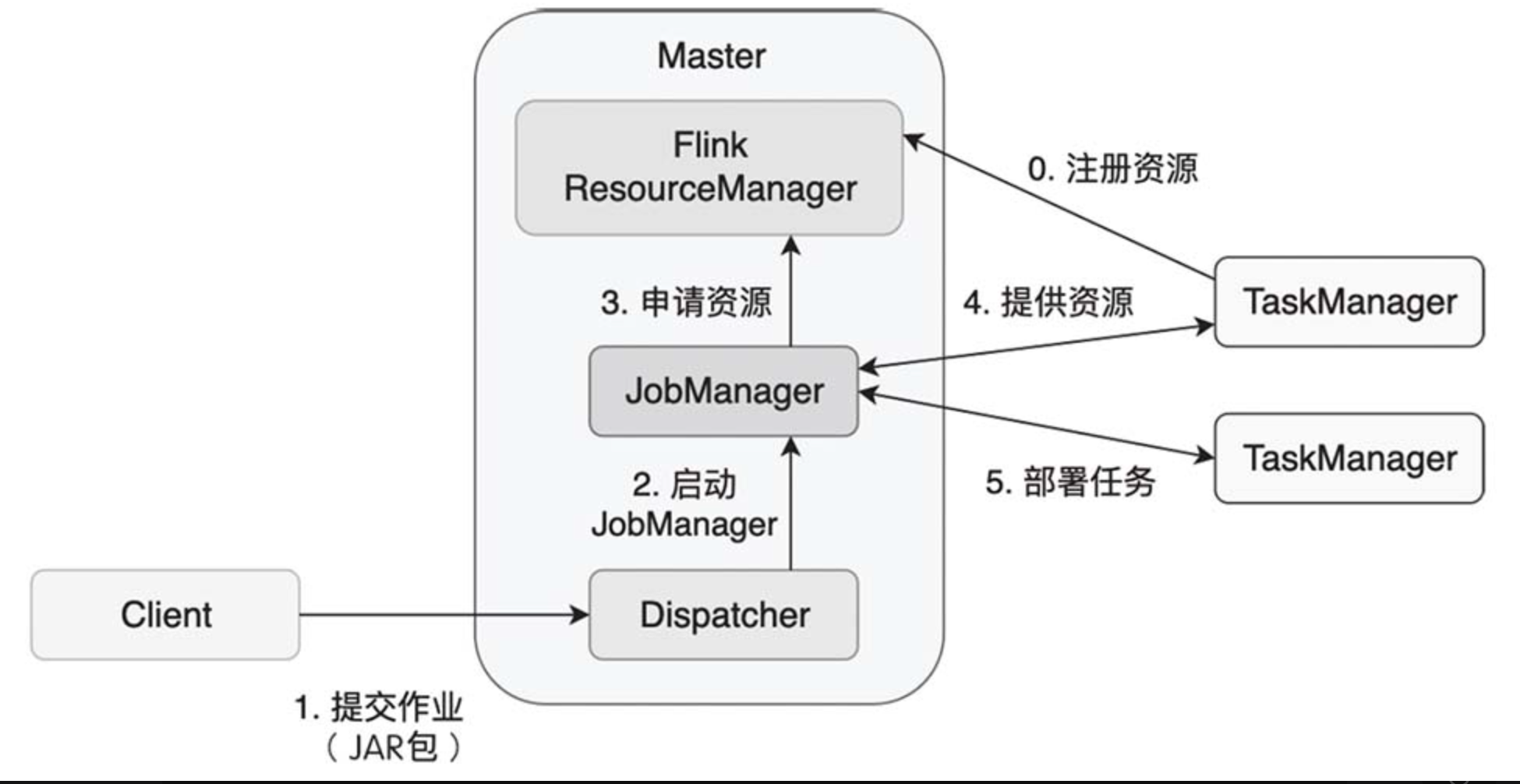
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。 文章目录 0. 处理无界和有界数据无界流有界流 1. Flink程序和数据流图2. 为什么一定要…...
开放平台 - 互动玩法演进之路
本期作者 1. 背景 随着直播业务和用户规模日益壮大,如何丰富直播间内容、增强直播间内用户互动效果,提升营收数据变得更加关键。为此,直播互动玩法应运而生。通过弹幕、礼物、点赞、大航海等方式,用户可以参与主播的直播内容。B站…...
Linux之进程控制进程终止进程等待进程的程序替换替换函数实现简易shell
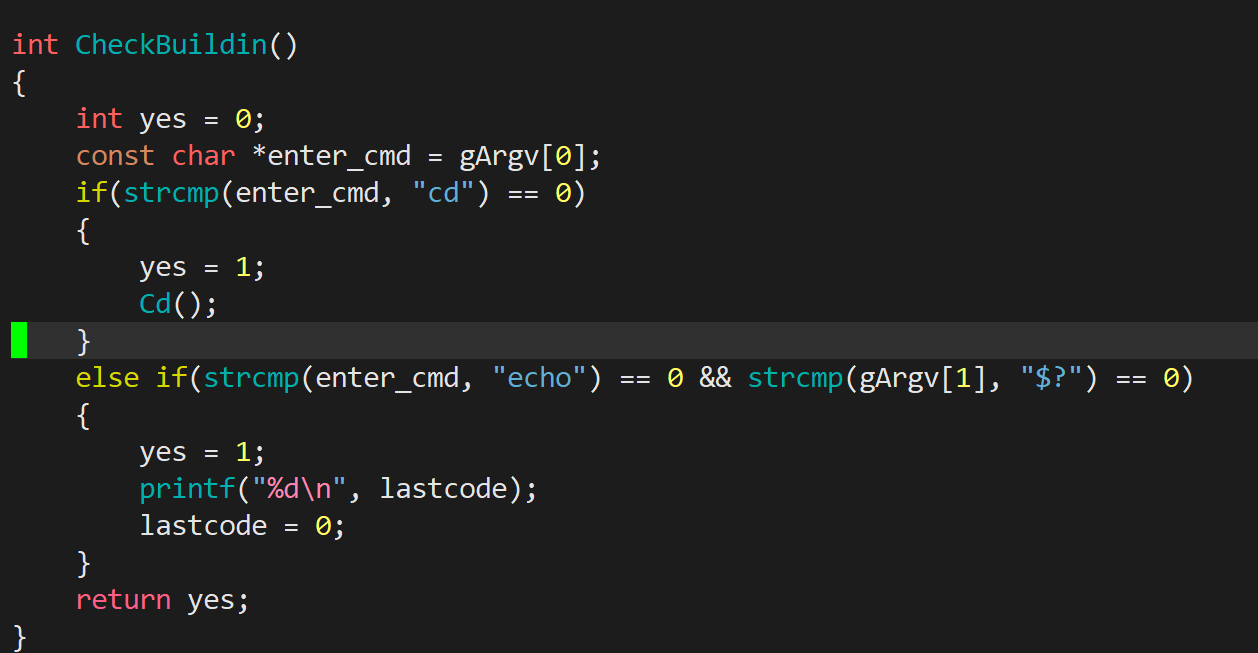
文章目录 一、进程创建1.1 fork的使用 二、进程终止2.1 终止是在做什么?2.2 终止的3种情况&&退出码的理解2.3 进程常见退出方法 三、进程等待3.1 为什么要进行进程等待?3.2 取子进程退出信息status3.3 宏WIFEXITED和WEXITSTATUS(获取…...

RegSeg 学习笔记(待完善)
论文阅读 解决的问题 引用别的论文的内容 可以用 controlf 寻找想要的内容 PPM 空间金字塔池化改进 SPP / SPPF / SimSPPF / ASPP / RFB / SPPCSPC / SPPFCSPC / SPPELAN  ASPP STDC:short-term dense concatenate module 和 DDRNet SE-ResNeXt …...

Qt中常用宏定义
Qt中常用宏定义 一、Q_DECLARE_PRIVATE(Class)二、Q_DECLARE_PRIVATE_D(Dptr, Class)三、Q_DECLARE_PUBLIC(Class)四、Q_D(Class) 和 Q_Q(Class) 一、Q_DECLARE_PRIVATE(Class) #define Q_DECLARE_PRIVATE(Class) inline Class##Private* d_func() { # 此处的 d_ptr 是属于QOb…...

【计算机网络】第 9 问:四种信道划分介质访问控制?
目录 正文什么是信道划分介质访问控制?什么是多路复用技术?四种信道划分介质访问控制1. 频分多路复用 FDM2. 时分多路复用 TDM3. 波分多路复用 WDM4. 码分多路复用 CDM 正文 什么是信道划分介质访问控制? 信道划分介质访问控制(…...
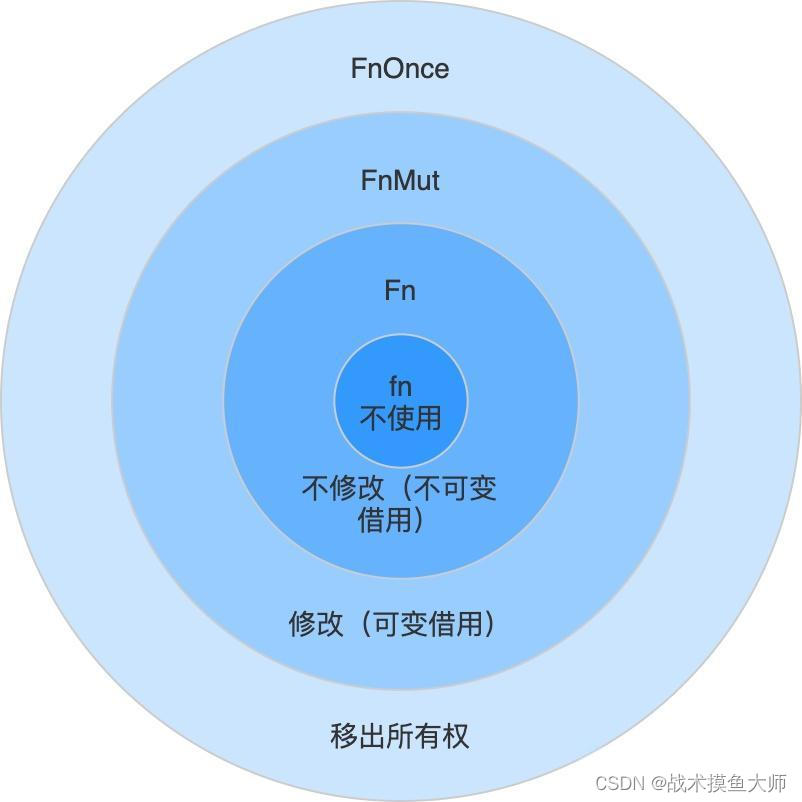
Rust编程(五)终章:查漏补缺
闭包 & 迭代器 闭包(Closure)通常是指词法闭包,是一个持有外部环境变量的函数。外部环境是指闭包定义时所在的词法作用域。外部环境变量,在函数式编程范式中也被称为自由变量,是指并不是在闭包内定义的变量。将自…...

LLM漫谈(五)| 从q star视角解密OpenAI 2027年实现AGI计划
最近,网上疯传OpenAI2027年关于AGI的计划。在本文,我们将针对部分细节以第一人称进行分享。 摘要:OpenAI于2022年8月开始训练一个125万亿参数的多模态模型。第一个阶段是Arrakis,也叫Q*,该模型于2023年12月完成训练&…...

【echart】数据可视化+vue+vite遇到问题
1、vue3使用echars图表报错:"Initialize failed:invalid dom" 原因是因为:Dom没有完成加载时,echarts.init() 就已经开始执行了,获取不到Dom,无法进行操作 解决:加个延时 onMounted(async () …...

mac m1安装和使用nvm的问题
mac m1安装和使用nvm的问题 使用nvm管理多版本node 每个项目可能用的node版本不同,所以需要多个版本node来回切换 但是最近遇到安装v14.19.0时一直安装失败的问题。 首先说明一下,用的电脑是mac M1芯片 Downloading and installing node v14.19.0... …...

git泄露
git泄露 CTFHub技能树-Web-信息泄露-备份文件下载 当前大量开发人员使用git进行版本控制,对站点自动部署。如果配置不当,可能会将.git文件夹直接部署到线上环境。这就引起了git泄露漏洞。 工具GitHack使用:python2 GitHack.py URL地址/.git/ git命令…...
Java项目:78 springboot学生宿舍管理系统的设计与开发
作者主页:源码空间codegym 简介:Java领域优质创作者、Java项目、学习资料、技术互助 文中获取源码 项目介绍 系统的角色:管理员、宿管、学生 管理员管理宿管员,管理学生,修改密码,维护个人信息。 宿管员…...

ArcGis Pro Python工具箱教程 03 工具箱中工具自定义
ArcGis Pro Python工具箱教程 03 工具箱中工具自定义 用于定义工作工具类的方法 工具方法必选或可选描述__ init __必需项right-aligned 初始化工具类。getParameterInfo可选定义工具的参数。isLicensed可选返回工具是否获得执行许可。updateParameters可选在用户每次在工具对…...
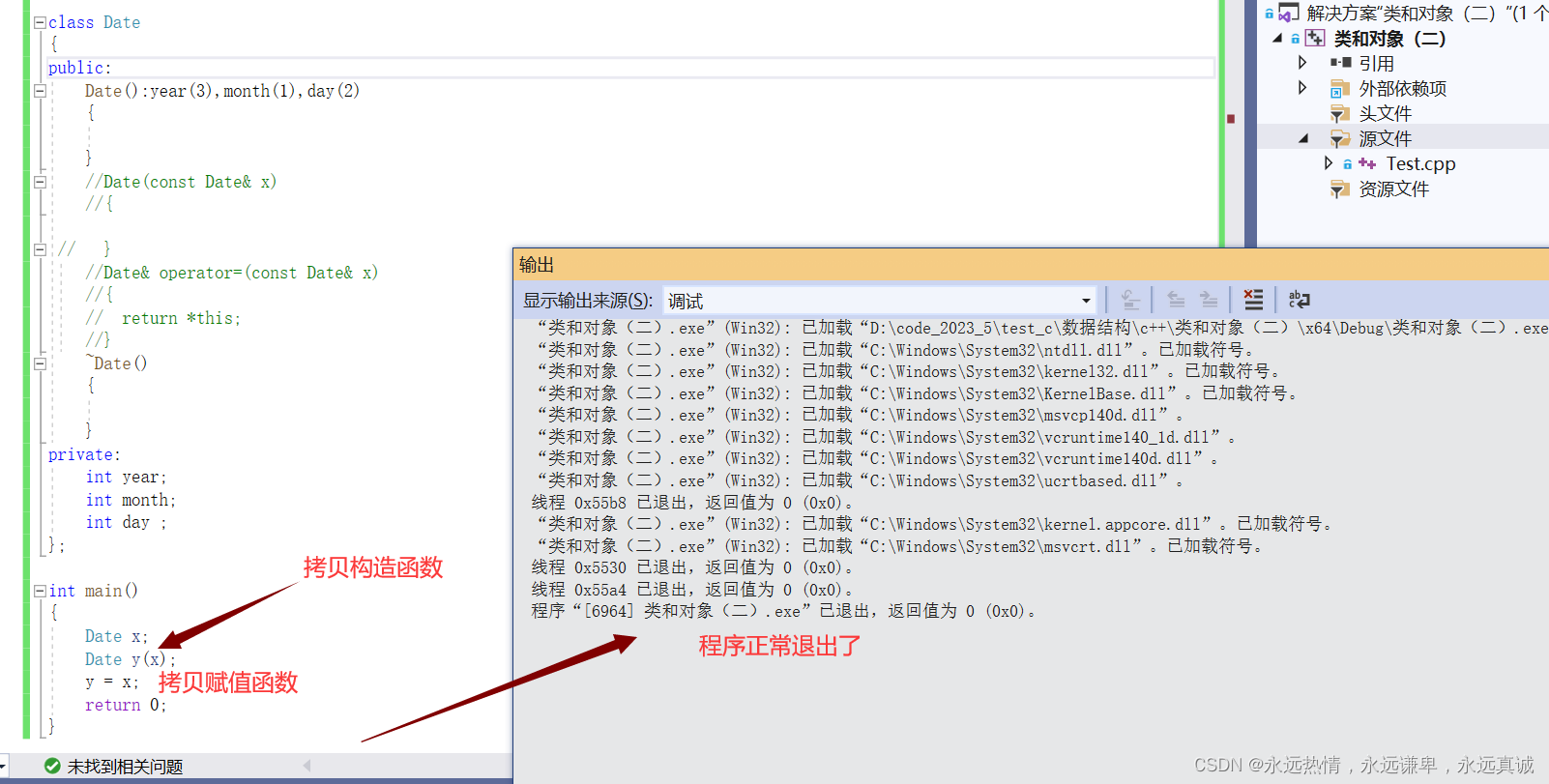
【C++初阶】之类和对象(中)
【C初阶】之类和对象(中) ✍ 类的六个默认成员函数✍ 构造函数🏄 为什么需要构造函数🏄 默认构造函数🏄 为什么编译器能自动调用默认构造函数🏄 自己写的构造函数🏄 构造函数的特性 ✍ 拷贝构造…...

Vue2(十一):脚手架配置代理、github案例、插槽
一、脚手架配置代理 1.回顾常用的ajax发送方式: (1)xhr 比较麻烦,不常用 (2)jQuery 核心是封装dom操作,所以也不常用 (3)axios 优势:体积小、是promis…...
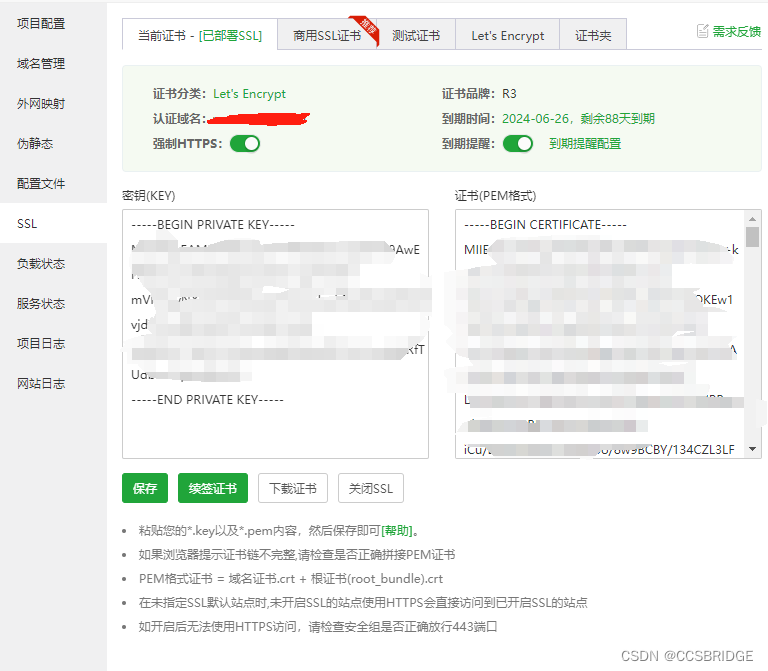
在宝塔面板中,为自己的云服务器安装SSL证书,为所搭建的网站启用https(主要部分攻略)
前提条件 My HTTP website is running Nginx on Debian 10(或者11) 时间:2024-3-28 16:25:52 你的网站部署在Debain 10(或者11)的 Nginx上 安装单域名证书(默认)(非泛域名…...

学习JavaEE的日子 Day32 线程池
Day32 线程池 1.引入 一个线程完成一项任务所需时间为: 创建线程时间 - Time1线程中执行任务的时间 - Time2销毁线程时间 - Time3 2.为什么需要线程池(重要) 线程池技术正是关注如何缩短或调整Time1和Time3的时间,从而提高程序的性能。项目中可以把Time…...
@Transactional 注解使用的注意事项
事务管理 事务管理在系统开发中是不可缺少的一部分,Spring提供了很好的事务管理机制,主要分为编程式事务和声明式事务两种。 编程式事务: 是指在代码中手动的管理事务的提交、回滚等操作,代码侵入比较强。 声明式事务ÿ…...

电商系列之库存
> 插:AI时代,程序员或多或少要了解些人工智能,前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 坚持不懈,越努力越幸运,大家…...

SPIRAN ART SUMMONER优化指南:如何调整参数让生成的图片更符合预期
SPIRAN ART SUMMONER优化指南:如何调整参数让生成的图片更符合预期 1. 理解SPIRAN ART SUMMONER的核心参数 SPIRAN ART SUMMONER作为一款基于Flux.1-Dev模型的图像生成工具,其参数设置直接影响最终输出效果。与普通AI绘画工具不同,它融入了…...

如何选择可靠的第三方软件测试机构,构建全生命周期的软件安全防线
在数字化转型的浪潮中,软件已成为企业运营的核心。然而,伴随其重要性一同增长的,是日益严峻的安全威胁。传统软件开发流程中,安全测试往往被置于交付前的独立环节,这种“事后补丁”的模式导致安全漏洞发现晚、修复成本…...

Go语言的context.WithCancel取消信号传播与资源清理在分布式系统中的协调
Go语言的context.WithCancel取消信号传播与资源清理在分布式系统中的协调 在分布式系统中,任务的取消与资源清理是确保系统稳定性和高效性的关键挑战。Go语言通过context包提供了优雅的解决方案,尤其是context.WithCancel机制,能够实现跨组件…...

从拼图游戏到自动驾驶:点云配准技术的跨领域进化史
从拼图游戏到自动驾驶:点云配准技术的跨领域进化史 1. 三维世界的数字拼图师 1987年,当Paul Besl和Neil McKay在实验室里尝试将两组扫描数据对齐时,他们可能不会想到,这项被称为迭代最近点(ICP)的技术会成为…...

Antares ESP MQTT库:ESP32/ESP8266接入Antares物联网平台指南
1. 项目概述Antares ESP MQTT 是一款专为 ESP32 和 ESP8266 平台设计的轻量级 Arduino 库,旨在大幅降低接入 Telkom Indonesia 运营的 Antares IoT 平台的开发门槛。其核心价值不在于实现 MQTT 协议栈(该职责由 PubSubClient 承担)࿰…...

Anthropic 经济指数报告:学习曲线
引言 Anthropic 经济指数利用隐私保护数据分析系统,追踪 Claude 在整个经济领域中的应用情况。这是Anthropic 努力的一部分,旨在尽早理解 AI 对经济的影响,以便研究人员和政策制定者有充足的时间做好准备。 在最新一期的报告中,首先观察到了与先前报告相比使用情况的变化…...

基于Python的律师事务所案件管理系统毕业设计
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在开发一套基于Python的律师事务所案件管理系统,以满足现代法律事务处理的高效性和智能化需求。具体研究目的如下: 首先…...

Go 协程池设计与调度实现
Go 协程池设计与调度实现 在并发编程中,Go 语言的协程(goroutine)以其轻量级和高性能著称。无限制地创建协程可能导致资源耗尽,影响系统稳定性。为此,协程池的设计与调度成为优化高并发场景的重要手段。本文将深入探讨…...

VirtualBox虚拟机磁盘空间分配技巧:如何用动态分配40G空间玩转Debian 12
VirtualBox磁盘空间动态分配实战:以Debian 12为例的40GB高效配置指南 在虚拟化技术日益普及的今天,VirtualBox作为一款开源免费的虚拟化工具,凭借其跨平台特性和易用性,成为众多开发者和技术爱好者的首选。然而,许多用…...
)
告别龟速滚屏!Ubuntu 20.04下用imwheel调鼠标滚轮速度(附开机自启保姆级教程)
Ubuntu 20.04终极鼠标滚轮优化指南:从基础配置到系统级调优 每次在Ubuntu上浏览长网页或翻阅代码时,那个慢如蜗牛的滚动速度是否让你抓狂?作为从Windows或macOS迁移过来的用户,这种体验落差尤为明显。鼠标滚轮响应迟缓不仅影响工作…...