《VMamba》论文笔记
原文链接:
[2401.10166] VMamba: Visual State Space Model (arxiv.org)
原文笔记:
What:
VMamba: Visual State Space Model
Why:
多年以来CNN和VIT作为视觉特征提取的主流框架
CNN具有模型简单,共享权重,计算效率高(线性复杂度)的优点,缺点是不具备全局感受野,能力不足VIT,不擅长处理多模态数据,并且模型已经比较老了,多种模型变体已经使卷积网络接近能力的上限
VIT基于Transformer,具有架构简单,全局感受野,动态权重(当提到"动态权重"时,通常是指注意力机制中用于分配不同输入元素之间关联度的权重。这些权重是根据输入数据的不同情况动态计算得出的。)的优点,缺点是计算效率不如卷积神经网络。(二次复杂度)
作者从最近很火的基于SSM模型的Mamba中获取灵感,集合了CNNs与VIT的优点提出了视觉状态空间模型VMamba该模型在不牺牲全局感受野的情况下实现了线性复杂度
Challenge:
1、作者想让这个视觉backbone在线性复杂度的情况下实现全局感受野,这是本研究的主要目的
2、如何将1D的SSM模型融合到2D的Vision任务当中作者将这一难题概括为
方向敏感问题:(然而,由于视觉数据的非因果性质,直接将这种策略应用于打成patch和拉伸后的图像不可避免地会导致感受野受限,因为无法估计与未扫描patch块的关系。我们将此问题称为“方向敏感”问题)
Idea:
为解决方向敏感问题作者提出交叉扫描模块(CSM)
(详见原文翻译部分)
Model:
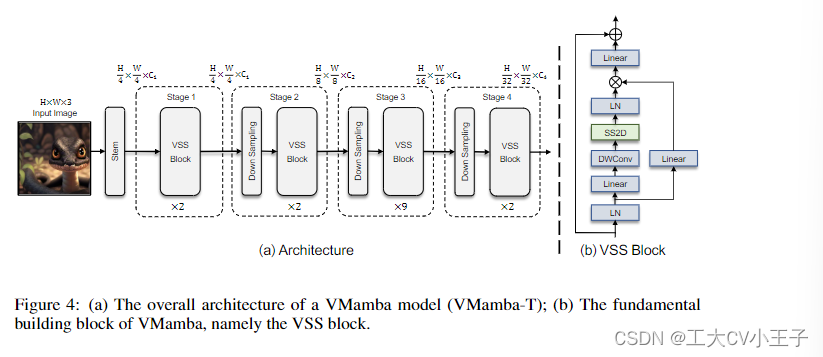
(ps:时间有点紧,这篇整理的略显匆忙,但是这些基于Mamba的模型大差不差,连行文逻辑都很相似,将Mamba用作Vision领域的主要有两个工作一个是Vim一个就是本文VMamba,他们主要的区别都是在1D转2D这个操作上的区别,我将专门基于它们的区别写一篇)
原文翻译:
Abstract
卷积神经网络(CNNs)和Visual Transformer(ViTs)是视觉表示学习的两个最流行的基础模型。虽然 CNN 以线性复杂度在图像分辨率方面表现出显着的可扩展性,但 ViT 在拟合能力方面超过了它们,尽管它具有二次复杂度。仔细检查表明,ViTs通过结合全局感受野和动态权重实现了卓越的视觉建模性能。这一观察促使我们提出了一种新颖的架构,该架构继承了这些组件,同时提高了计算效率。为此,我们从最近引入的状态空间模型中获得灵感,提出了视觉状态空间模型(VMamba),该模型在不牺牲全局接受域的情况下实现了线性复杂度。为了解决遇到的方向敏感问题,我们引入了交叉扫描模块(CSM)遍历空间域,并将任何非因果视觉图像转换为顺序补丁序列。大量的实验结果表明,随着图像分辨率的增加,VMamba不仅在各种视觉任务中表现出有希望的能力,而且在已建立的基准上也表现出更明显的优势。源代码可在 https://github.com/MzeroMiko/VMamba 获得。
1 Introduction
视觉表示学习是计算机视觉中最基本的研究课题之一,自深度学习时代开始以来,取得了重大突破。深度基础模型的两个主要类别,即卷积神经网络(CNNs)[38,19,22,29,42]和视觉变形器(ViTs)[10,28,45,56],已广泛应用于各种视觉任务。虽然两者都在计算表达视觉表示方面取得了显着成功,但与 CNN 相比,ViTs 通常表现出卓越的性能,这可以归因于注意力机制促进的全局感受野和动态权重。
然而,注意机制在图像大小方面要求二次复杂度,导致在处理下游密集预测任务(如目标检测、语义分割等)时产生昂贵的计算开销。为了解决这个问题,通过限制计算窗口的大小或跨步来提高注意力的效率已经付出了大量的努力[43],尽管这是以限制接受域的规模为代价的。这促使我们设计一种新的具有线性复杂性的视觉基础模型,同时仍然保留与全局接受域和动态权重相关的优势。
从最近提出的状态空间模型[12,34,47]中汲取灵感,我们引入了用于高效视觉表示学习的视觉状态空间模型(表示为VMamba)。VMamba在有效降低注意力复杂性方面的成功背后的关键概念继承自选择性扫描空间状态序列模型(S6)[12],该模型最初是为解决自然语言处理(NLP)任务而设计的。与传统的注意力计算方法相比,S6使一维数组中的每个元素(例如文本序列)通过压缩的隐藏状态与先前扫描的任何样本交互,有效地将二次复杂度降低到线性。
然而,由于视觉数据的非因果性质,直接将这种策略应用于打成patch和拉伸后的图像不可避免地会导致感受野受限,因为无法估计与未扫描patch块的关系。我们将此问题称为“方向敏感”问题,并提出通过新引入的 Cross-Scan 模块 (CSM) 对其进行解决。CSM 不是以单向模式(按列或逐行)遍历图像特征图的空间域,而是采用四向扫描策略,即从特征图中的所有四个角到相反的位置(见图 2(b))。该策略确保特征图中的每个元素都集成了来自不同方向所有其他位置的信息,在不增加线性计算复杂度的情况下呈现全局感受野。
在不同的视觉任务上进行了大量的实验来验证VMamba的有效性。如图1所示,与Resnet[19]、ViT[10]和Swin[28]等基准视觉模型相比,VMamba模型在ImageNet-1K上表现出优越或至少具有竞争力的性能。我们还报告了下游密集预测任务的结果。例如,vambatiny /Small/Base(分别具有22/44/75 M参数)使用MaskRCNN检测器(1倍训练计划)在COCO上实现46.5%/48.2%/48.5% mAP,使用512 × 512输入的UperNet在ADE20K上实现47.3%/49.5%/50.0% mIoU,显示其作为强大基础模型的潜力。此外,当使用更大的图像作为输入时,ViT的FLOPs增长速度明显快于CNN模型,尽管通常仍然表现出优越的性能。然而,令人感兴趣的是VMamba本质上是基于Transformer体系结构的基础模型,它能够在FLOPs稳步增加的情况下获得与ViT相当的性能。

我们总结了本文的主要贡献:
- 我们提出了一个具有全局接受域和动态权值的视觉状态空间模型vamba,用于视觉表征学习。VMamba为视觉基础模型提供了一种新的选择,超越了cnn和vit的现有选择。
- 引入了交叉扫描模块(CSM),以弥合一维阵列扫描和二维平面遍历之间的差距,促进S6扩展到视觉数据而不影响接收域。
- 我们展示了vamba在各种视觉任务(包括图像分类、对象检测和语义分割)上取得了令人满意的结果。这些发现强调了vamba作为一个强大的视觉基础模型的潜力。
2 Related Work
深度神经网络极大地促进了机器视觉感知的研究。视觉基础模型主要有两种,cnn[23,38,41,19,42]和vit[10,28,48,9,6,56]。最近,状态空间模型 (SSM) [12, 34, 47]。说明了它们在高效的长序列建模中的有效性,这在 NLP 和 CV 社区中引起了广泛的关注。我们的研究坚持这一工作路线,并提出了VMamba,这是一种基于SSM的架构,用于视觉领域的数据建模。VMamba和CNN以及VIT同时作为计算机视觉领域的可供替代的基础模型。
卷积神经网络(cnn)是视觉感知史上具有里程碑意义的模型。早期基于cnn的模型[25,23]是为基本任务而设计的,例如识别手写数字[24]和分类字符类别[55]。cnn的独特特征被封装在卷积核中,卷积核利用接收野从图像中捕获感兴趣的视觉信息。在强大的计算设备(GPU)和大规模数据集[7]的帮助下,越来越深入的[38,41,19,22]和高效的模型[20,42,52,36]被提出,以提高跨视觉任务的性能。除了这些努力之外,在提出更先进的卷积算子[4,21,53,5]或更高效的网络架构[59,3,51,20]方面也取得了进展。
Vision Transformers(ViTs)是NLP社区的产物,展示了一种有效的视觉任务感知模型,并迅速发展成为最有前途的视觉基础模型之一。早期基于vit的模型通常需要大规模的数据测试[10],并以朴素的配置出现[54,58,1,31]。后来,DeiT[45]采用训练技术来解决优化过程中遇到的挑战,随后的研究倾向于将视觉感知的归纳偏差纳入网络设计中。例如,社区提出分层vit[28, 9, 48, 31, 56, 44, 6, 8, 57],以逐步降低整个主干的特征分辨率。此外,也有研究提出利用CNN的优势,如引入卷积运算[49,6,46],结合CNN和ViT模块设计混合架构[6,40,31]等。
状态空间模型(ssm)是最近提出的模型,作为状态空间转换引入深度学习[16,15,39]。受控制系统中的连续状态空间模型的启发,结合HiPPO[13]初始化,LSSL[16]展示了处理远程依赖问题的潜力。然而,由于状态表示对计算量和内存的要求过高,LSSL在实际应用中并不可行。为了解决这个问题,S4[15]提出将参数归一化为对角结构。此后,不同结构的结构状态空间模型层出不穷,如复杂对角结构[17,14]、多输入多输出支持[39]、对角分解加低秩运算[18]、选择机制[12]等。然后将这些模型集成到大型表示模型中[34,33,11]。
这些模型主要关注的是如何将状态空间模型应用于语言和语音等远程和随机数据,如语言理解[33,34]、基于内容的推理[12]、像素级一维图像分类[15]等,然而这些模型很少关注视觉识别方面。与我们最相似的工作是S4ND[35]。S4ND是第一个将状态空间机制应用到视觉任务中的工作,并显示了其性能可能与ViT竞争的潜力[10]。然而,S4ND对S4模型进行了简单的扩展,无法以依赖输入的方式有效地捕获图像信息。我们证明了通过mamba[12]引入的选择性扫描机制,所提出的VMamba能够匹配现有流行的视觉基础模型,如ResNet[19]、ViT[10]、swin[27]和convnext[29],显示了VMamba作为强大基础模型的潜力。
3 Method
在本节中,我们首先介绍与VMamba相关的初步概念,包括状态空间模型、离散化过程和选择性扫描机制。然后,我们提供了作为VMamba核心元素的二维状态空间模型的详细规范。最后,我们对整个VMamba体系结构进行了全面的讨论。
3.1 Preliminaries
状态空间模型。状态空间模型(SSMs)通常被认为是将刺激x(t)∈R^L映射到响应y(t)∈R^L的线性时不变系统。在数学上,这些模型通常被表述为线性常微分方程(ode) (Eq. 1),其中参数包括A∈C^N ×N, B, C∈C^N,状态大小为N,跳跃连接D∈C^1。

离散化。状态空间模型(ssm)作为连续时间模型,在与深度学习算法集成时面临着很大的挑战。为了克服这一障碍,离散化过程变得势在必行。离散化的主要目标是将ODE转化为离散函数。这种转换对于使模型与输入数据中隐含的底层信号的采样率保持一致至关重要,从而实现高效的计算操作[16]。考虑输入Xk∈R^L×D,在长度伟L的信号流内的采样向量如下[17],常微分方程(Eq. 1)可以使用零阶保持规则离散如下:
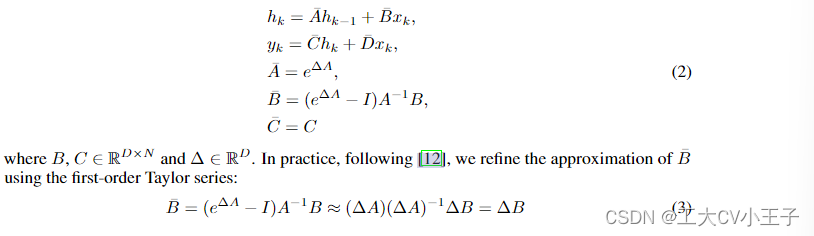
选择性扫描机制。与主要关注线性时不变(LTI) SSM的流行方法不同,所提出的VMamba通过将选择性扫描机制(S6)[12]作为核心SSM算子而使自己与众不同。在S6中,矩阵B∈RB×L×N,C∈RB×L×N,∆∈RB×L×D由输入数据x∈RB×L×D导出。这意味着S6知道嵌入在输入中的上下文信息,从而确保该机制中的权重的动态性。
3.2 2D Selective Scan
尽管S6具有鲜明的特点,但它对输入数据进行因果处理,因此只能捕获数据扫描部分内的信息。这自然使S6与涉及时间数据的NLP任务保持一致,但在适应非因果数据(如图像、图形、集合等)时提出了重大挑战。这个问题的一个直接解决方案是沿着两个不同的方向(即向前和向后)扫描数据,允许它们在不增加计算复杂性的情况下补偿彼此的接受域。
尽管具有非因果性,但图像与文本的不同之处在于它们包含二维空间信息(例如局部纹理和全局结构)。为了解决这个问题,S4ND[35]建议用卷积重新表述SSM,并通过外积直接将核从一维扩展到二维。然而,这种修改阻止了权重的动态性(即,与输入无关),从而导致了基于上下文的数据建模能力的丧失。因此,我们选择通过坚持选择性扫描方法[12]来保持动态权重,不幸的是,这种方法不允许我们遵循[35]集成卷积操作。
为了解决这个问题,我们提出了如图2所示的交叉扫描模块(CSM)。我们选择将图像patch块沿着行和列展开成序列(扫描展开),然后沿着四个不同的方向进行扫描:左上到右下,右下到左上,右上到左下,左下到右上。这样,任何像素(如图2中的中心像素)都可以集成来自不同方向的所有其他像素的信息。然后,我们将每个序列重塑为单个图像,并将所有序列合并为一个新的序列,如图3所示(扫描合并)。

S6与CSM的集成称为S6块,它是构建可视状态空间(VSS)块的核心元素,VSS块构成了VMamba的基本构建块(下一小节将进一步详细介绍)。我们强调,S6块继承了选择性扫描机制的线性复杂性,同时保留了全局接受野,这与我们构建这种视觉模型的动机是一致的。
3.3 VMamba Model
3.3.1 Overall Architecture
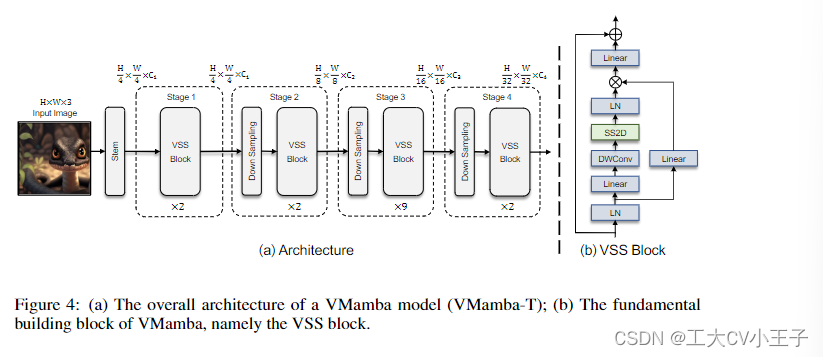
vamba - tiny的架构概述如图4 (a)所示。vamba通过使用类似于ViTs的干模块将输入图像划分为patch开始该过程,但没有进一步将补丁平坦化为1-D序列。这种修改保留了图像的二维结构,得到尺寸为H/4 × W/4 × C1的特征图。
然后vamba将几个VSS块堆叠在特征图上,保持相同的维度,构成“阶段1”。vamba中的分层表示是通过patch merge操作对“Stage 1”中的feature map进行降采样来构建的[27]。随后,更多的VSS块参与,导致输出分辨率为H/8 × W/8,形成“第二阶段”。重复此过程以创建分辨率分别为H/16 × W/16和H/32 × W/32的“阶段3”和“阶段4”。所有这些阶段共同构建了类似于流行的CNN模型[19,22,41,29,42]和一些vit[27, 48, 6, 56]的分层表示。所得到的体系结构可以作为具有类似需求的实际应用中其他视觉模型的通用替代品。
我们开发了三种不同的vamba,即vamba - tiny, vamba - small和vamba - ase(分别称为vamba - t, vamba - s和vamba - b)。表1概述了详细的体系结构规范。所有模型的FLOPs都使用224 × 224的输入尺寸进行评估。在未来的更新中将引入其他架构,例如大型模型。

3.3.2 VSS Block
VSS块的结构如图4 (b)所示。输入经过初始线性嵌入层,输出分成两个信息流。在进入核心SS2D模块之前,一个流通过一个3 × 3深度卷积层,然后是一个Silu激活函数[37]。SS2D的输出经过一个层规范化层,然后加入到另一个信息流的输出中,这个信息流经过了一个Silu激活。这种组合产生了VSS块的最终输出。与VisionTransformer不同,由于其因果性,我们避免在VMamba中使用位置嵌入偏差。我们的设计不同于典型的视觉转换器结构,它在一个块中采用了如下的操作顺序:Norm → attention → Norm → MLP,然后丢弃MLP操作,因此VSS块比VIT块更浅,这是我们能够以相似的总模型深度预算堆叠更多块。
4 Experiment
略
相关文章:
《VMamba》论文笔记
原文链接: [2401.10166] VMamba: Visual State Space Model (arxiv.org) 原文笔记: What: VMamba: Visual State Space Model Why: 多年以来CNN和VIT作为视觉特征提取的主流框架 CNN具有模型简单,共享权重&…...

手机真机连接USB调试adb不识别不显示和TCPIP连接问题
手机真机连接USB调试adb devices不显示设备和TCPIP连接 本文手机型号为NOVA 7 ,其他型号手机在开发人员模式打开等方式可能略有不同,需根据自己的手机型号修改。 文章目录 1. 打开和关闭开发者模式2. 真机USB连接调试adb不显示设备问题的若干解决方法3…...

MySQL分表后,如何做分页查询?
参考: https://blog.csdn.net/qq_44732146/article/details/127616258 user.sql 完整的执行一遍,可以做到分表和分页 数据是实时的,往一张子表里插入之后,all表就能立刻查询到 在这里实现分页查询的是MyIsam引擎,这个引擎不支持…...

【Deep Learning 11】Graph Neural Network
🌞欢迎来到图神经网络的世界 🌈博客主页:卿云阁 💌欢迎关注🎉点赞👍收藏⭐️留言📝 🌟本文由卿云阁原创! 📆首发时间:🌹2024年3月20日…...
http和https的工作原理是什么?
HTTP(HyperText Transfer Protocol)和HTTPS(HyperText Transfer Protocol Secure)是两种用于在互联网上传输数据的主要协议,它们均用于在客户端(通常是Web浏览器)与服务器之间交换信息。尽管它们…...

STL中容器、算法、迭代器
STL标准模板库封装了常用的数据结构和算法,让程序员无需太关心真实的数据结构实现。 容器 容器:用来存放数据的。 STL容器就是将运用最广泛的的一些数据结构实现出来。 常用的数据结构有:数组、链表、树、栈、队列、集合、映射表。 这些…...

深入并广泛了解Redis常见的缓存使用问题
Redis 作为一门主流技术,缓存应用场景非常多,很多大中小厂的项目中都会使用redis作为缓存层使用。 但是Redis作为缓存,也会面临各种使用问题,比如数据一致性,缓存穿透,缓存击穿,缓存雪崩&#…...
nginx界面管理工具之nginxWebUI 搭建与使用
nginx界面管理工具之nginxWebUI 搭建与使用 一、nginxWebUI 1.nginx网页配置工具 官网地址: http://www.nginxwebui.cn 源码地址:https://git.chihiro.org.cn/chihiro/nginxWebUI 2.功能说明 本项目可以使用WebUI配置nginx的各项功能, 包括http协议转发, tcp协议…...

linux下 罗技鼠标睡眠唤醒问题的解决
sudo dmesg | grep Logitech | grep -o -P "usb.?\s" 得到3-2,用上面这条命令得到哪个usb口。 下面这条命令禁用罗技鼠标睡眠唤醒系统(3-2改成你自己电脑上得到的usb口) sudo sh -c "echo disabled > /sys/bus/usb/devic…...

架构师之路--Docker的技术学习路径
Docker 的技术学习路径 一、引言 Docker 是一个开源的应用容器引擎,它可以让开发者将应用程序及其依赖包打包成一个可移植的容器,然后在任何支持 Docker 的操作系统上运行。Docker 具有轻量级、快速部署、可移植性强等优点,因此在现代软件开…...

【动手学深度学习-pytorch】 9.4 双向循环神经网络
在序列学习中,我们以往假设的目标是: 在给定观测的情况下 (例如,在时间序列的上下文中或在语言模型的上下文中), 对下一个输出进行建模。 虽然这是一个典型情景,但不是唯一的。 还可能发生什么其…...

网际协议 - IP
文章目录 目录 文章目录 前言 1 . 网际协议IP 1.1 网络层和数据链路层的关系 2. IP基础知识 2.1 什么是IP地址? 2.2 路由控制 3. IP地址基础知识 3.1 IP地址定义 3.2 IP地址组成 3.3 IP地址分类 3.4 子网掩码 IP地址分类导致浪费? 子网与子网掩码 3.5 CIDR与…...
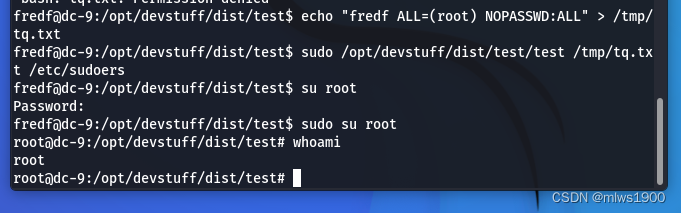
DC-9靶场
一.环境搭建 1.下载地址 靶机下载地址:https://download.vulnhub.com/dc/DC-9.zip 2.虚拟机配置 设置虚拟机为nat,遇到错误点重试和是 开启虚拟机如下图所示 二.开始渗透 1. 信息收集 查找靶机的ip地址 arp-scan -l 发现靶机的ip地址为192.168.11…...
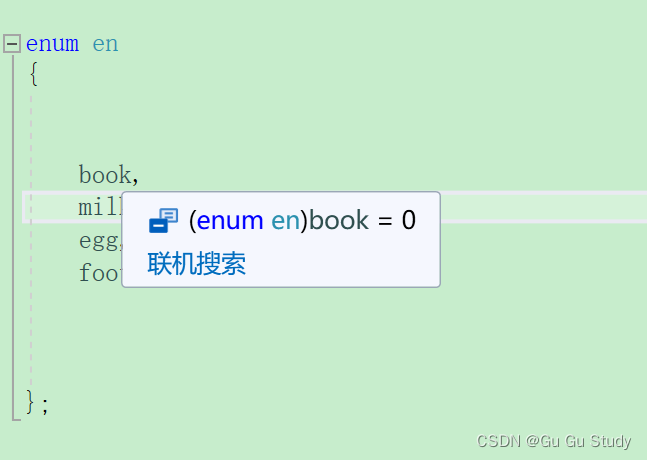
自定义类型(二)结构体位段,联合体,枚举
这周一时兴起,想写两篇文章来拿个卷吧,今天也是又来写一篇博客了,也是该结束自定义类型的学习与巩固了。 常常会回顾努力的自己,所以要给自己的努力留下足迹。 为今天努力的自己打个卡,留个痕迹吧 2024.03.30 小闭…...

MySQL5.7源码分析--解析
select语句会走的case COM_QUERY判断 具体流程如下: 1.获取网络包数据,拿到查询语句,放入thd->query alloc_query(thd, packet, packet_length) 2.先查询缓存,缓存命中直接返回结果,未命中则解析 功能集中在mys…...
windows10搭建reactnative,运行android全过程
环境描述 win10,react-native-cli是0.73,nodeJS是20,jdk17。这都是完全根据官网文档配置的。react-native环境搭建windows。当然官网文档会更新,得完全按照配置来安装,避免遇到环境不兼容情况。 安装nodeJS并配置 这里文档有详…...

小迪学习笔记(内网安全)(常见概念和信息收集)
小迪学习笔记(内网安全)(一) 内网分布图内网基本概念工作组和域环境的优缺点内网常用命令域的分类单域父域和子域域数和域森林 Linux域渗透问题内网安全流程小迪演示环境信息收集mimikatzLazagne(all)凭据信息政集操作演示探针主机…...

Python自动连接SSH
Python自动连接SSH 在 Python 中,可以使用 paramiko 模块来编写脚本自动执行 SSH 命令。paramiko 是一个用于 SSHv2 的 Python 实现,可以帮助你在脚本中进行远程执行命令。 首先,确保安装了 paramiko: pip install paramiko然后…...

机器学习实验------AGNES层次聚类方法
机器学习 — AGNES层次聚类方法 第1关:距离的计算 任务描述 本关任务:根据本关所学知识,完成calc_min_dist函数,calc_max_dist函数以及calc_avg_dist函数分别实现计算两个簇之间的最短距离、最远距离和平均距离。 import numpy as np def calc_min_dist(cluster1, clus…...

HBase常用的Filter过滤器操作
HBase过滤器种类很多,我们选择8种常用的过滤器进行介绍。为了获得更好的示例效果,先利用HBase Shell新建students表格,并往表格中进行写入多行数据。 一、数据准备工作 (1)在默认命名空间中新建表格students…...
)
VSCode界面突然变英文了?别慌,一分钟教你切回中文(附快捷键和常见问题解决)
VSCode界面突然变英文了?别慌,一分钟教你切回中文(附快捷键和常见问题解决) 早上打开VSCode准备写代码,突然发现所有菜单和按钮都变成了英文?这种突如其来的"国际化"体验确实让人措手不及。别担…...

从CelebA数据集到落地应用:一份给新手的MTCNN训练数据制作与模型训练全指南
从CelebA数据集到落地应用:MTCNN训练数据制作与模型训练全指南 人脸检测作为计算机视觉的基础任务,其精度直接影响后续的人脸识别、表情分析等应用效果。MTCNN(Multi-task Cascaded Convolutional Networks)作为经典的多任务级联人…...
)
Watercolor风格在MJ中被严重低估的3个底层能力:纸基模拟、颜料扩散建模、干湿叠加逻辑(Adobe资深插画师联合验证)
更多请点击: https://intelliparadigm.com 第一章:Watercolor风格在MJ中被严重低估的3个底层能力:纸基模拟、颜料扩散建模、干湿叠加逻辑(Adobe资深插画师联合验证) 纸基模拟:不只是纹理,而是…...

从噪声中捕捉节拍:基于PLL的CDR电路如何重塑光通信数据流
1. 当光信号遇上噪声:CDR电路为何成为关键救星 想象一下你正在嘈杂的菜市场里试图听清朋友说话——周围此起彼伏的叫卖声就像光通信中的噪声,而朋友说话的节奏就是需要提取的时钟信号。这就是光接收机面临的真实困境:传输过来的NRZ信号往往带…...
)
告别手敲!手把手教你给STM32CubeIDE 1.3.0装上Keil同款代码补全插件(附成品包)
5分钟极速配置:为STM32CubeIDE注入Keil级代码补全能力 从Keil切换到STM32CubeIDE的开发者,最不适应的莫过于代码补全功能的缺失。每次输入变量名时手动敲击完整字符的体验,让开发效率大打折扣。本文将分享一种无需Java基础、无需手动编译的插…...

InjectFix实战:除了修Bug,如何在Unity里用它安全地‘新增’功能与属性?
InjectFix实战:突破Bug修复边界,安全扩展Unity功能 在Unity开发中,InjectFix作为热修复方案早已被开发者熟知,但大多数教程仅停留在修复Bug的基础用法上。当线上版本需要临时增加活动界面属性或工具函数时,重新打包发布…...

如何在无GPU群晖设备上开启完整AI相册功能:Synology Photos面部识别终极指南
如何在无GPU群晖设备上开启完整AI相册功能:Synology Photos面部识别终极指南 【免费下载链接】Synology_Photos_Face_Patch Synology Photos Facial Recognition Patch 项目地址: https://gitcode.com/gh_mirrors/sy/Synology_Photos_Face_Patch 还在为DS918…...

终极智能修复:VisualCppRedist AIO一键解决Windows软件兼容性问题 [特殊字符]
终极智能修复:VisualCppRedist AIO一键解决Windows软件兼容性问题 😊 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 还在为软件打不开、…...

宇树GO2机器人ROS2控制:从零到自主导航的完整指南
宇树GO2机器人ROS2控制:从零到自主导航的完整指南 【免费下载链接】go2_ros2_sdk Unofficial ROS2 SDK support for Unitree GO2 AIR/PRO/EDU 项目地址: https://gitcode.com/gh_mirrors/go/go2_ros2_sdk Unitree GO2 ROS2 SDK是一个专门为宇树科技GO2系列机…...

脉冲微波信号高速采集与实时测频模块设计【附程序】
✨ 本团队擅长数据搜集与处理、建模仿真、程序设计、仿真代码、EI、SCI写作与指导,毕业论文、期刊论文经验交流。 ✅ 专业定制毕设、代码 ✅如需沟通交流,点击《获取方式》 (1)多相并行FFT与二次曲线拟合测频方案: 针…...