你了解HashMap吗?
一、前言:
面试过的人都知道,HashMap是Java程序员在面试中最最最经常被问到的一个点,可以说,不了解HashMap都不好意思说自己是做Java开发的。基本上你去面试十家公司,有七八家都会问到你HashMap。那么今天,就带着大家从源码的角度去分析一下,HashMap具体是怎么实现的。
二、HashMap的构造方法
1.HashMap构造方法
我们先来看HashMap的四个构造方法
```java
//initialCapacity给定的初始化容量,loadFactor扩容因子publicHashMap(int initialCapacity ,float loadFactor){if(initialCapacity <0)thrownewIllegalArgumentException("Illegal initial capacity: "+initialCapacity);if(initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if(loadFactor <=0||Float.isNaN(loadFactor))thrownewIllegalArgumentException("Illegal load factor: "+loadFactor);this.loadFactor = loadFactor;this.threshold =tableSizeFor(initialCapacity);}publicHashMap(int initialCapacity){//内部调用了上边的构造方法this(initialCapacity, DEFAULT_LOAD_FACTOR);}publicHashMap(){//空参构造this.loadFactor = DEFAULT_LOAD_FACTOR;// all other fields defaulted}publicHashMap(Map<?extendsK,?extendsV> m){//构造传入一个map,将map中的值放到hashmap中this.loadFactor = DEFAULT_LOAD_FACTOR;putMapEntries(m,false);}
```2.构造方法里的putMapEntries方法
刚才构造方法中提到了putMapEntries这个方法,接下来就让我们一起看一下
//该函数用于将一个map赋值给新的HashMapfinalvoidputMapEntries(Map<?extendsK,?extendsV> m,boolean evict){//定义变量接收旧hashmap的size int s = m.size();//判断s的容量是否大于0if(s >0){//判断当前数组有没有初始化if(table ==null){// pre-size求出以 旧hashmap数组容量为阈值 的数组容量赋值给ftfloat ft =((float)s / loadFactor)+1.0F;//判断是不是大于最大容量,如果是,赋值为最大容量,否则将ft赋值给tint t =((ft <(float)MAXIMUM_CAPACITY)?(int)ft : MAXIMUM_CAPACITY);//判断t是否大于threshold(数组扩容阈值)if(t > threshold)//通过tablesizefor方法求出大于等于t的最小2的次幂值赋值给threshold(数组扩容阈值)threshold =tableSizeFor(t);}//如果数组长度大于扩容阈值,进行resize扩容操作 elseif(s > threshold)resize();//循环遍历取出旧hashmap的值放入当前hashmapfor(Map.Entry<?extendsK,?extendsV> e : m.entrySet()){K key = e.getKey();V value = e.getValue();putVal(hash(key), key, value,false, evict);}}}/* if (table == null)分支,是判断当前数组是否初始化,因为在jdk1.8之后,只有当你第一次放值时,才会帮你创建16位的数组。float ft = ((float)s / loadFactor) + 1.0F经过除运算再加上1.0F是为了向上取整if (t > threshold)注意一个细节,做判断的的时候,数组还没有初始化,这里的threshold的值还是给定的数组长度的值,也就是capacity的值else if (s > threshold)说明传入的map集合大于当前的扩容阈值,需要进行resize扩容操作
*/
```tableSizeFor方法
刚才putMapEntries方法中,调用了tableSizeFor方法,接下来我们看一下这个tableSizeFor方法。
作用:创建hashMap对象时调用有参构造,传入初始容量,需要保证hashMap的初始长度为2的n次幂。
tableSizeFor方法用来计算大于等于并离传入值最近的2的n次幂的数值,比如传入15,算出结果为16,传入17,算出结果为32。
通过二进制的位移,第一次右移一位,第二次右移两位,第三次右移四位。。。通过五次位移,将范围内所有的位数都变为1,高位补0,最后得出来的结果再加上1,最后算出来的结果一定是2的n次幂。
//这个方法的作用是找到大于等于给定容量的最小2的次幂值//>>>表示无符号右移,也叫逻辑右移,即若该数为正,则高位补0,而若该数为负数,则右移后高位同样补07--》816--》16staticfinalinttableSizeFor(int cap){//先将数组长度减1,之所以在开始移位前先将容量-1,是为了避免给定容量已经是8,16这样2的幂时,不减一 直接移位会导致得到的结果比预期大。比如预期16得到应该是16,直接移位的话会得到32。int n = cap -1;//右移一位,在进行或运算,这个时候最高位和次高位就已经都是1,此时是2个1n |= n >>>1;//右移两位,在进行或运算,这个时候由上次运算得出的两个1,变成了四个1n |= n >>>2;//右移四位n |= n >>>4;//右移八位n |= n >>>8;//右移十六位,这个时候所有的位数都变为了1n |= n >>>16;//n+1操作,是为了进1,这个时候算出来的数值就一点是 2的n次幂return(n <0)?1:(n >= MAXIMUM_CAPACITY)? MAXIMUM_CAPACITY : n +1;}
```移位的思想
2的整数幂用二进制表示都是最高有效位为1,其余全是0。
对任意十进制数转换为2的整数幂,结果是这个数本身的最高有效位的前一位变成1,最高有效位以及其后的位都变为0。
核心思想是,先将最高有效位以及其后的位都变为1,最后再+1,就进位到前一位变成1,其后所有的满2变0。所以关键是如何将最高有效位后面都变为1。
先移位,再或运算。
> 右移一位,再或运算,就有两位变为1;
>
> 右移两位,再或运算,就有四位变为1,,,
>
> 最后右移16位再或运算,保证32位的int类型整数最高有效位之后的位都能变为1。
三、HashMap的底层原理
先来看几个重要的参数:
staticfinalint DEFAULT_INITIAL_CAPACITY =1<<4;// 默认数组初始容量staticfinalint MAXIMUM_CAPACITY =1<<30;//数组最大容量staticfinalfloat DEFAULT_LOAD_FACTOR =0.75f;//默认加载因子staticfinalint TREEIFY_THRESHOLD =8;//树化的阈值staticfinalint UNTREEIFY_THRESHOLD =6;//由树退化到链表的阈值staticfinalint MIN_TREEIFY_CAPACITY =64;//树化最小数组容量//node节点,继承了Map.entry,在Entry原有的K,V的基础上追加了hash和next字段//分别表示key的hash值和下一个节点staticclassNode<K,V>implementsMap.Entry<K,V>{finalint hash;finalK key;V value;Node<K,V> next;}//重写了计算hash的方法//将 Hash 值的高 16 位右移并与原 Hash 值取异或运算(^),混合高 16 位和低 16 位的值//得到一个更加散列的低 16 位的 Hash 值。staticfinalinthash(Object key){int h;return(key ==null)?0:(h = key.hashCode())^(h >>>16);}
```HashMap在JDK1.8之前的实现方式数组+链表,
但是在JDK1.8后对HashMap进行了底层优化,改为了由 **数组+链表或者数值+红黑树**实现,主要的目的是提高查找效率
1. Jdk8数组+链表或者数组+红黑树实现,当链表中的元素大于等于8 个并且数组长度大于等于64以后, 会将链表转换为红黑树,当红黑树节点 小于 等于6 时又会退化为链表。
2. 当new HashMap()时,底层没有创建数组,首次调用put()方法示时,会调用resize方法,底层创建长度为16的数组,jdk8底层的数组是:Node[],而非Entry[],用数组容量大小乘以加载因子得到一个值,一旦数组中存储的元素个数超过该值就会调用resize方法将数组扩容到原来的两倍,在做扩容的时候会生成一个新的数组,原来的所有数据需要重新计算哈希码值重新分配到新的数组,所以扩容的操作非常消耗性能。
默认的负载因子大小为0.75,数组大小为16。也就是说,默认情况下,那么当HashMap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍。
3. 在我们Java中任何对象都有hashcode,hash算法就是通过hashcode与自己进行向右位移16的异或运算。这样做是为了使高位的16位hash也能参与运算,使运算出来的hash值足够随机,足够分散,还有产生的数组下标足够随机。
map.put(k,v)实现原理:
(1)首先将k,v封装到Node对象当中(节点)。
(2)先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的下标。
(3)下标位置上如果没有任何元素,就把Node添加到这个位置上。如果说下标对应的位置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果所有的equals方法返回都是false,那么这个新的节点将被添加到链表的末尾。如其中有一个equals返回了true,那么这个节点的value将会被覆盖。
HashMap中的put()方法
```java
publicVput(K key,V value){returnputVal(hash(key), key, value,false,true);}
```putVal()方法。
finalVputVal(int hash,K key,V value,boolean onlyIfAbsent,boolean evict){Node<K,V>[] tab;Node<K,V> p;int n, i;//判断数组是否未初始化if((tab = table)==null||(n = tab.length)==0)//如果未初始化,调用resize方法 进行初始化n =(tab =resize()).length;//通过 & 运算求出该数据(key)的数组下标并判断该下标位置是否有数据if((p = tab[i =(n -1)& hash])==null)//如果没有,直接将数据放在该下标位置tab[i]=newNode(hash, key, value,null);//该数组下标有数据的情况else{Node<K,V> e;K k;//判断该位置数据的key和新来的数据是否一样if(p.hash == hash &&((k = p.key)== key ||(key !=null&& key.equals(k))))//如果一样,证明为修改操作,该节点的数据赋值给e,后边会用到e = p;//判断是不是红黑树elseif(p instanceofTreeNode)//如果是红黑树的话,进行红黑树的操作e =((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);//新数据和当前数组既不相同,也不是红黑树节点,证明是链表else{//遍历链表for(int binCount =0;;++binCount){//判断next节点,如果为空的话,证明遍历到链表尾部了if((e = p.next)==null){//把新值放入链表尾部p.next =newNode(hash, key, value,null);//因为新插入了一条数据,所以判断链表长度是不是大于等于8if(binCount >= TREEIFY_THRESHOLD -1)// -1 for 1st//如果是,进行转换红黑树操作treeifyBin(tab, hash);break;}//判断链表当中有数据相同的值,如果一样,证明为修改操作if(e.hash == hash &&((k = e.key)== key ||(key !=null&& key.equals(k))))break;//把下一个节点赋值为当前节点p = e;}}//判断e是否为空(e值为修改操作存放原数据的变量)if(e !=null){// existing mapping for key//不为空的话证明是修改操作,取出老值V oldValue = e.value;//一定会执行 onlyIfAbsent传进来的是falseif(!onlyIfAbsent || oldValue ==null)//将新值赋值当前节点e.value = value;afterNodeAccess(e);//返回老值return oldValue;}}//计数器,计算当前节点的修改次数++modCount;//当前数组中的数据数量如果大于扩容阈值if(++size > threshold)//进行扩容操作resize();//空方法afterNodeInsertion(evict);//添加操作时 返回空值returnnull;}
```map中resize方法
//扩容、初始化数组finalNode<K,V>[]resize(){Node<K,V>[] oldTab = table;//如果当前数组为null的时候,把oldCap老数组容量设置为0int oldCap =(oldTab ==null)?0: oldTab.length;//老的扩容阈值int oldThr = threshold;int newCap, newThr =0;//判断数组容量是否大于0,大于0说明数组已经初始化if(oldCap >0){//判断当前数组长度是否大于最大数组长度if(oldCap >= MAXIMUM_CAPACITY){//如果是,将扩容阈值直接设置为int类型的最大数值并直接返回threshold =Integer.MAX_VALUE;return oldTab;}//如果在最大长度范围内,则需要扩容 OldCap << 1等价于oldCap*2//运算过后判断是不是最大值并且oldCap需要大于16elseif((newCap = oldCap <<1)< MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)newThr = oldThr <<1;// double threshold 等价于oldThr*2}//如果oldCap<0,但是已经初始化了,像把元素删除完之后的情况,那么它的临界值肯定还存在, 如果是首次初始化,它的临界值则为0elseif(oldThr >0)// initial capacity was placed in thresholdnewCap = oldThr;//数组未初始化的情况,将阈值和扩容因子都设置为默认值else{// zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr =(int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}//初始化容量小于16的时候,扩容阈值是没有赋值的if(newThr ==0){//创建阈值float ft =(float)newCap * loadFactor;//判断新容量和新阈值是否大于最大容量newThr =(newCap < MAXIMUM_CAPACITY && ft <(float)MAXIMUM_CAPACITY ?(int)ft :Integer.MAX_VALUE);}//计算出来的阈值赋值threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})//根据上边计算得出的容量 创建新的数组 Node<K,V>[] newTab =(Node<K,V>[])newNode[newCap];//赋值table = newTab;//扩容操作,判断不为空证明不是初始化数组if(oldTab !=null){//遍历数组for(int j =0; j < oldCap;++j){Node<K,V> e;//判断当前下标为j的数组如果不为空的话赋值个e,进行下一步操作if((e = oldTab[j])!=null){//将数组位置置空oldTab[j]=null;//判断是否有下个节点if(e.next ==null)//如果没有,就重新计算在新数组中的下标并放进去newTab[e.hash &(newCap -1)]= e;//有下个节点的情况,并且判断是否已经树化elseif(e instanceofTreeNode)//进行红黑树的操作((TreeNode<K,V>)e).split(this, newTab, j, oldCap);//有下个节点的情况,并且没有树化(链表形式)else{//比如老数组容量是16,那下标就为0-15//扩容操作*2,容量就变为32,下标为0-31//低位:0-15,高位16-31//定义了四个变量// 低位头 低位尾Node<K,V> loHead =null, loTail =null;// 高位头 高位尾Node<K,V> hiHead =null, hiTail =null;//下个节点Node<K,V> next;//循环遍历do{//取出next节点next = e.next;//通过 与操作 计算得出结果为0if((e.hash & oldCap)==0){//如果低位尾为null,证明当前数组位置为空,没有任何数据if(loTail ==null)//将e值放入低位头loHead = e;//低位尾不为null,证明已经有数据了else//将数据放入next节点loTail.next = e;//记录低位尾数据loTail = e;}//通过 与操作 计算得出结果不为0else{//如果高位尾为null,证明当前数组位置为空,没有任何数据if(hiTail ==null)//将e值放入高位头hiHead = e;//高位尾不为null,证明已经有数据了else//将数据放入next节点hiTail.next = e;//记录高位尾数据hiTail = e;}//如果e不为空,证明没有到链表尾部,继续执行循环}while((e = next)!=null);//低位尾如果记录的有数据,是链表if(loTail !=null){//将下一个元素置空loTail.next =null;//将低位头放入新数组的原下标位置newTab[j]= loHead;}//高位尾如果记录的有数据,是链表if(hiTail !=null){//将下一个元素置空hiTail.next =null;//将高位头放入新数组的(原下标+原数组容量)位置newTab[j + oldCap]= hiHead;}}}}}//返回新的数组对象return newTab;}
```map.get(k)实现原理
(1)、先调用k的hashCode()方法得出哈希值,并通过哈希算法转换成数组的下标。
(2)、在通过数组下标快速定位到某个位置上。重点理解如果这个位置上什么都没有,则返回null。如果这个位置上有单向链表,那么它就会拿着参数K和单向链表上的每一个节点的K进行equals,如果所有equals方法都返回false,则get方法返回null。如果其中一个节点的K和参数K进行equals返回true,那么此时该节点的value就是我们要找的value了,get方法最终返回这个要找的value。
HashMap中的get()方法
publicVget(Object key){Node<K,V> e;return(e =getNode(hash(key), key))==null?null: e.value;}
```getNode()方法
finalNode<K,V>getNode(int hash,Object key){Node<K,V>[] tab;Node<K,V> first, e;int n;K k;//判断数组不为null并且长度大于0,并且通过hash算出来的数组下标的位置不为空,证明有数据if((tab = table)!=null&&(n = tab.length)>0&&(first = tab[(n -1)& hash])!=null){//判断数组的位置的key的hash和内容是否等同与要查询的数据if(first.hash == hash &&// always check first node((k = first.key)== key ||(key !=null&& key.equals(k))))//相等的话直接返回return first;//判断是否有下个节点if((e = first.next)!=null){//判断是否为为红黑树if(first instanceofTreeNode)//进行红黑树查询操作return((TreeNode<K,V>)first).getTreeNode(hash, key);//链表查询操作do{//循环链表,逐一判断if(e.hash == hash &&((k = e.key)== key ||(key !=null&& key.equals(k))))//发现key的话就返回return e;}while((e = e.next)!=null);}}//没有查询到返回nullreturnnull;}四、HashMap常见面试题分析
为何HashMap的数组长度一定是2的次幂?
首先,HashMap的初始化的数组长度一定是2的n次的,每次扩容仍是原来的2倍的话,就不会破坏这个规律,每次扩容后,原数据都会进行数据迁移,根据二进制的计算,扩容后数据要么在原来位置,要么在【原来位置+扩容长度】,这样就不需要重新hash,效率上更高。
HashMap中,如果想存入数据,首先它需要根据key的哈希值去定位落入哪个桶中
HashMap的做法,我总结的是,三步:>>>无符号右移、^异或、&与
具体是:拿着key的哈希值,先“>>>”无符号右移16位,然后“^”异或上key的哈希值,得到一个值,再拿着这个值去“&”上数组长度减一
最后得出一个数(如果数组长度是15的话,那这个数就是一个0-15之间的一个数),这个数就是得出的数组脚标位置,也就是存入的桶的位置。
由上边可以知道,定位桶的位置最后需要做一个 “&” 与运算,&完了得出一个数,就是桶的位置
知道了这些以后,再来说为什么HashMap的长度之所以一定是2的次幂?
至少有以下**两个原因**:
1、HashMap的长度是2的次幂的话,可以让**数据更散列更均匀的分布**,更充分的利用数组的空间
怎么理解呢?下面举例子说一下如果不是2的次幂的数的话假设数组长度是一个奇数,那参与最后的&运算的肯定就是偶数,那偶数的话,它二进制的最后一个低位肯定是0,0做完&运算得到的肯定也是0,那意味着&完后得到的数的最低位一定是0最低位一定是0的话,那说明一定是一个偶数,换句话说就是:&完得到的数一定是一个偶数,所以&完获取到的脚标永远是偶数位,那意味着奇数位的脚标永远都没值,**有一半的空间是浪费的**奇数说完了,来说一下偶数,假设数组长度是一个偶数,比如6,那参与&运算的就是55的二进制 00000000 00000000 00000000 00000101发现任何一个数&上5,倒数第二低位永远是0,那就意味着&完以后,最起码肯定得不出2或者3(这点刚开始不好理解,但是好好想一下就能明白)意味着第二和第三脚标位肯定不会有值。
虽然偶数的话,不会像奇数那么夸张会有一半的脚标位得不到,但是也总会有一些脚标位得不到的。**所以不是2的次幂的话,不管是奇数还是偶数,就肯定注定了某些脚标位永远是没有值的,而某些脚标位永远是没有值的,就意味着浪费空间,会让数据散列的不充分,这对HashMap来说绝对是个灾难!**
2、HashMap的长度一定是2的次幂,还有另外一个原因,那就是在扩容迁移的时候不需要再重新通过哈希定位新的位置了。扩容后,元素新的位置,要么在原脚标位,要么在原脚标位+扩容长度这么一个位置。
比如扩容前长度是8,扩容后长度是16第一种情况:扩容前:00000000000000000000000000000101&000000000000000000000000000001118-1=7-------------------------------------101=====5 原来脚标位是5扩容后:00000000000000000000000000000101&0000000000000000000000000000111116-1=15-------------------------------------101=====5 扩容后脚标位是5(原脚标位)第二种情况:扩容前:00000000000000000000000000001101&000000000000000000000000000001118-1=7-------------------------------------101=====5 原来脚标位是5扩容后:00000000000000000000000000001101&0000000000000000000000000000111116-1=15-------------------------------------1101=====13 扩容后脚标位是13(原脚标位+扩容长度)```扩容后到底是在原来位置还是在原脚标位+扩容长度的位置,主要是看新扩容最左边一个1对应的上方数字是0还是1如果是0则扩容后在原来位置,如果是1则扩容后在原脚标位+扩容长度的位置HashMap源码里扩容也是这么做的。
总结来说,就是hash&(n-1)这个计算有关。如果不为n不为2的n次方的话,那转换为二进制情况下,n-1就会有某一位为0,那与hash做了&运算后,该位置永远为0,那么计算出来的数组位置就永远会有某个下标的数组位置是空的,也就是这个位置永远不会有值。
JDK1.8中HashMap的性能优化
JDK1.8在1.7的基础上对一些操作进行了优化。
| 不同 | JDK1.7 | JDK1.8 |
| ------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
| 存储结构 | 数组+链表 | 数组+链表+红黑树 |
| 初始化方式 | 单独函数inflateTable() | 集成至扩容方法resize() |
| hash值计算方式 | 扰动处理=9次扰动=4次位运算+5次异或运算 | 扰动处理=2次扰动=1次位运算+1次异或运算 |
| 存放数据规则 | 无冲突时,存放数组;冲突时存放链表 | 无冲突时,存放数组;冲突&链表长度<8:c存放单链表;冲突&链表长度 >8:树化并存放红黑树 |
| 插入数据方式 | 头插法(将原位置的数据移动到后一位,再插入数据到该位置) | 尾插法 (直接插入链表尾部/红黑树) |
| 扩容后存储位置的计算方式 | 全部按照原来的方法进行运算(hashCode()->>扰动函数->>(h&length-1)) | 按照扩容后的规则计算(即扩容后位置=原位置或原位置+旧容量) |
注意:JDK1.8里转换为红黑树的时候,数组长度必须大于64,如果数组长度小于64,链表长度达到8的话,会进行resize扩容操作。
五、总结
看到这里,我们已经HashMap的源码和实现有了清晰的理解,并且对它的构造方法再到它的一个put数据和get数据的一个源码解析,还有一些它里边比较精妙和重要的一些方法也都探索清楚了,希望这些知识点可以在大家以后的面试中也能够帮助到大家,斩获一个心仪的offer。
相关文章:

你了解HashMap吗?
一、前言:面试过的人都知道,HashMap是Java程序员在面试中最最最经常被问到的一个点,可以说,不了解HashMap都不好意思说自己是做Java开发的。基本上你去面试十家公司,有七八家都会问到你HashMap。那么今天,就…...

我一个女孩子居然做了十年硬件……
2011年,一个三本大学的电子信息专业的大三女学生跟2个通信专业的大二男生组成了一组代表学校参加2011年“瑞萨杯”全国大学生电子设计大赛,很意外的获得了湖北赛区省三等奖,虽然很意外,但还是挺高兴的,毕竟第一次为喜欢…...

【Linux】编译器gcc g++和调试器gdb的使用
文章目录1.编译器gcc/g1.1C语言程序的翻译过程1.预处理2.编译3.汇编4. 链接1.2 链接方式与函数库1.动态链接与静态链接2.动态库与静态库1.3 gcc与g的使用2.调试器gdb2.1debug和release2.2gdb的安装2.3gdb的使用2.4gdb的常用指令3.总结1.编译器gcc/g 1.1C语言程序的翻译过程 1…...

高效能自动化港口数字化码头智慧港航,中国人工智能企业CIMCAI世界港航人工智能领军者,成熟港口码头人工智能产品中国人工智能企业
打造高效能自动化港口数字化码头智慧港航,中国人工智能企业CIMCAI中集飞瞳世界港航人工智能领军者,成熟港口码头人工智能产品全球顶尖AI科技CIMCAI成熟AI产品全球前三船公司及港口落地,包括全球港口/堆场智能闸口验箱,全球港口岸边…...
)
HTTP协议(一)
HTTP协议(一) 什么是HTTP协议 客户端连上web服务器后,如果想要获得web服务器中的某个web资源,需要遵守一定的通讯格式,HTTP协议用于定义客户端与web服务器之间通讯的格式;基于TCP连接的传输协议ÿ…...
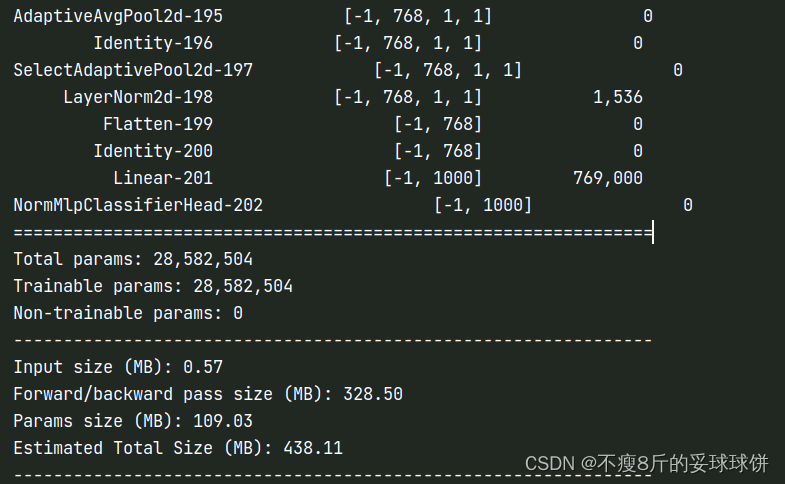
计算神经网络参数量Params、计算量FLOPs(亲测有效的3种方法)
1.stat(cpu统计) pip install torchstat from torchstat import statstat(model, (3, 32, 32)) #统计模型的参数量和FLOPs,(3,32,32)是输入图像的size 结果: 问题:当网络中有自定义参数时&am…...

sizeof与一维数组和二维数组
🍕博客主页:️自信不孤单 🍬文章专栏:C语言 🍚代码仓库:破浪晓梦 🍭欢迎关注:欢迎大家点赞收藏关注 sizeof与一维数组和二维数组 文章目录sizeof与一维数组和二维数组前言1. sizeof与…...
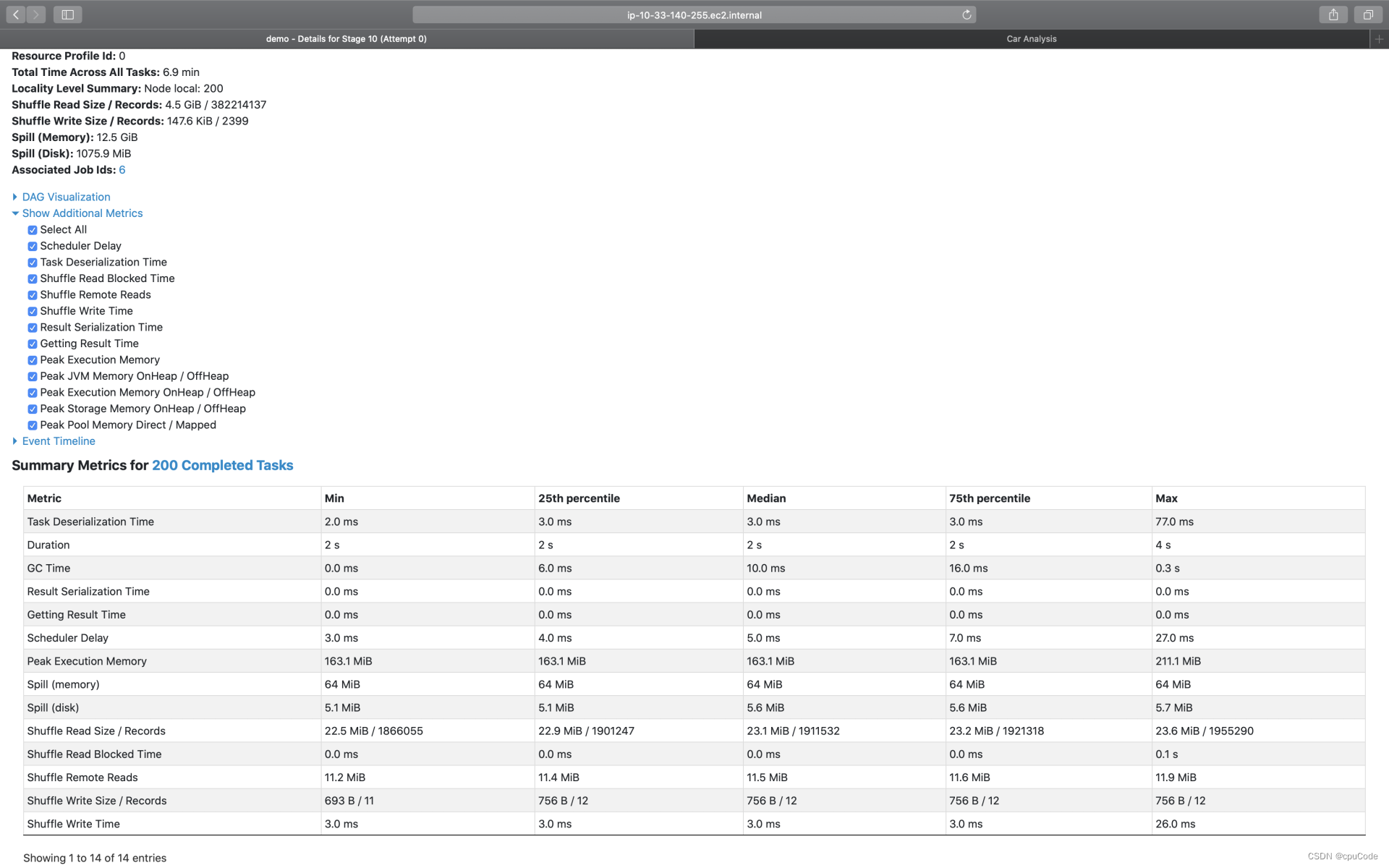
Spark UI
Spark UIExecutorsEnvironmentStorageSQLExchangeSortAggregateJobsStagesStage DAGEvent TimelineTask MetricsSummary MetricsTasks展示 Spark UI ,需要设置配置项并启动 History Server # SPARK_HOME表示Spark安装目录 ${SPAK_HOME}/sbin/start-history-server…...
MFC基础到实战(2))
windows应用(vc++2022)MFC基础到实战(2)
目录向导和资源编辑器使用 MFC 应用程序向导创建 MFC 应用程序使用类视图管理类和 Windows 消息使用资源编辑器创建和编辑资源生成 MFC 应用程序的操作1.创建一个主干应用程序。2.了解即使在不添加你自己的任何一行代码的情况下,框架和 MFC 应用程序向导也能提供的内…...

记一次反射型XSS
记一次反射型XSS1.反射型XSS1.1.前言1.2.测试过程1.3.实战演示1.3.1.输入框1.3.2.插入代码1.3.3.跳转链接2.总结1.反射型XSS 1.1.前言 关于这个反射型XSS,利用的方式除了钓鱼,可能更多的就是自娱自乐,那都说是自娱自乐了,并且对系…...

BUUCTF-[羊城杯 2020]Bytecode
题目下载:下载 这道题是一个关于python字节码的。 补充一下相关知识:https://shliang.blog.csdn.net/article/details/119676978dis --- Python 字节码反汇编器 — Python 3.7.13 文档 手工还原参考:[原创]死磕python字节码-手工还原python源码-软件逆…...

《Uniapp入门指南:从安装到打包的全流程》
Uniapp是一款基于Vue.js的跨平台开发框架,可以快速构建出同时支持多个移动端平台和Web端的应用程序。本文将介绍Uniapp的基础知识和开发流程,帮助读者快速入门Uniapp开发。一、Uniapp的基础知识1.Uniapp的优势Uniapp的最大优势是可以快速开发同时支持多个…...

机器学习算法集成系统
版权所有:CSDN——川川菜鸟 本系统并不作为本专栏要求,这一篇自愿学习。 文章目录 本系统设计背景设计思路完整代码本系统设计背景 随着人工智能技术的不断发展,机器学习成为了人工智能领域的重要组成部分。机器学习算法能够从大量数据中发现模式、规律,并利用这些规律对新…...

scratch绘制雷达 电子学会图形化编程scratch等级考试三级真题和答案解析2022年9月
目录 scratch绘制雷达 一、题目要求 1、准备工作 2、功能实现 二、案例分析...

VRRP主备备份
1、VRRP专业术语 VRRP备份组框架图如图14-1所示: 图14-1:VRRP备份组框架图 VRRP路由器(VRRP Router):运行VRRP协议的设备,它可能属于一个或多个虚拟路由器,如SwitchA和SwitchB。虚拟路由器(Virtual Router):又称VRR…...

【软件逆向】软件破解?病毒木马?游戏外挂?
文章目录课前闲聊认识CTF什么是CTFCTF解题模式什么是逆向定义应用领域CTF中的逆向现状推荐书籍学习要点逆向工程学习基础常规逆向流程阶段一:信息收集阶段二:过保护后静态调试阶段三:结合动态调试阶段四:写解题脚本逆向例题概览1-控制台程序解题过程2-Crackme3-游戏4-移动安全C…...

curl请求常用参数和返回码
curl是一个用于传输数据的工具,支持各种协议,如HTTP、FTP、SMTP等。以下是一些常用的curl请求参数及其作用: -X, --request:指定HTTP请求方法,常见的有GET、POST、PUT、DELETE等。 -H, --header:设置HTTP请…...
:抢占式优先级和响应式优先级(NVIC_PriorityGroupConfig))
【STM32】进阶(一):抢占式优先级和响应式优先级(NVIC_PriorityGroupConfig)
1、简介 STM32(Cortex-M3)中每个中断源都有两级优先级:抢占式优先级(pre-emption priority)和子优先级(subpriority),子优先级也叫响应式优先级。 1.1 抢占式优先级 望文知义,就是优先级高的…...

LogCompilation后JIT输出文件格式解析
https://wiki.openjdk.org/display/HotSpot/LogCompilationoverview https://spotcodereviews.com/articles/optimization/2020/12/23/why-does-the-jit-continually-recompile-the-same-method.html task_queued count表示总共执行次数,iicount表示解释器执行次数…...

Linux学习第二十四节-Podman容器
一、容器的概念 容器是由一个或多个与系统其余部分隔离的进程组成的集合。我们可以理解为“集装箱”。 集装箱是打包和装运货物的标准方式。它作为一个箱子进行标记、装载、卸载,以及从一个 位置运输到另一个位置。该容器的内容与其他容器的内容隔离,…...

Cookie AutoDelete技术架构解析:深入理解Redux驱动的浏览器扩展实现
Cookie AutoDelete技术架构解析:深入理解Redux驱动的浏览器扩展实现 【免费下载链接】Cookie-AutoDelete Firefox and Chrome WebExtension that deletes cookies and other browsing site data as soon as the tab closes, domain changes, browser restarts, or a…...

FanControl终极指南:Windows风扇智能控制完全手册
FanControl终极指南:Windows风扇智能控制完全手册 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/Fan…...

为Cursor AI Agent构建专用HTTP客户端:扩展智能体联网能力实战
1. 项目概述:一个为Cursor AI Agent定制的HTTP客户端 如果你和我一样,深度使用Cursor作为日常开发的主力工具,那你肯定对它的“Agent”功能又爱又恨。爱的是,它能理解你的意图,帮你生成代码、重构函数、甚至写测试&…...

AI辅助故事创作:从工具链构建到人机协同写作实践
1. 项目概述:当AI成为你的专属故事创作伙伴最近在折腾一个挺有意思的项目,我把它叫做“盐的故事”(Salt-Story)。这名字听起来有点玄乎,其实内核很简单:一个专门用来辅助故事创作的AI工具链。我自己是个业余…...

别再傻傻分不清了!VB、VBS、VBA到底该学哪个?给新手的选型指南
VB、VBS与VBA终极选型指南:从零开始做出明智选择 每次打开Excel想要自动化处理数据时,是否对着宏录制按钮犹豫不决?当需要批量重命名几百个文件时,是否在批处理和VBS之间举棋不定?本文将带您深入理解这三种"VB系…...

OpenClaw赚钱实录:从“养龙虾“到可持续变现的实践指南——OpenClaw一人公司-[一人公司的终极技术栈,从0到变现的完整光谱]
【限时99元】专栏原价299元,在专栏未完结的持续更新期间享受99元早鸟价,现在订阅同享后续专栏所有文章! 【专栏介绍】《OpenClaw赚钱实录:从“养龙虾“到可持续变现的实践指南》专栏介绍 有任何疑问均可联系博主微信(微信号:NeumannAI),作者将亲自解答并持续优化文章内…...

第四章 数字孪生制作完整流程
4.1 项目需求分析、场景规划、页面布局设计数字孪生项目开发前期必须进行需求分析,明确项目用途、使用人群、展示内容以及功能模块,避免盲目开发造成资源浪费。需求分析是整个项目开发的逻辑起点,决定项目最终呈现效果。4.1.1 需求分析开发者…...
RT-DTER最新创新改进系列:(购买资料的粉丝反馈涨点的TOP1模块)我们将BiFPN的加权双向融合之力,注入RT-DETR的端到端Transformer架构,创新与涨点的双丰收!!!!!!
RT-DTER最新创新改进系列:(购买资料的粉丝反馈涨点的TOP1模块)我们将BiFPN的加权双向融合之力,注入RT-DETR的端到端Transformer架构,创新与涨点的双丰收!! 购买相关资料后畅享一对一答疑&#…...

英雄联盟智能辅助工具Seraphine:三步快速上手的终极指南
英雄联盟智能辅助工具Seraphine:三步快速上手的终极指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 你是否厌倦了在英雄联盟排位赛中手忙脚乱地查询对手战绩?是否希望有一个智能助…...

别再用示波器死磕了!用Python+RC积分电路,5分钟搞定充放电曲线模拟与可视化
别再用示波器死磕了!用PythonRC积分电路,5分钟搞定充放电曲线模拟与可视化 在电子工程实践中,RC积分电路的充放电特性分析是基础中的基础。传统方法往往依赖示波器观测,不仅耗时耗力,还受限于硬件条件。今天ÿ…...