生成式语言模型预训练阶段验证方式与微调阶段验证方式
生成式语言模型,如GPT-3、BERT等,在预训练和微调阶段都需要进行验证以确保模型性能。下面分别介绍这两个阶段的验证方式:
预训练阶段的验证:
预训练阶段通常使用大量未标注的文本数据来训练模型,以学习语言的一般特性。在这个阶段,验证的主要目的是监控模型的学习进度和泛化能力。常见的验证方式包括:
- 困惑度(Perplexity):困惑度是衡量语言模型性能的常用指标,它衡量的是模型对语言数据的预测准确性。较低的困惑度意味着模型对数据的预测更加准确。
- 似然性(Likelihood):似然性评估的是模型生成给定数据的概率,高的似然性表明模型能够很好地拟合训练数据。
- 样本生成质量:通过人工评估模型生成的文本样本的质量,检查样本的语言流畅性、语义连贯性和主题相关性。
困惑度
困惑度(Perplexity)是评估语言模型性能的一个重要指标,尤其是在模型预训练阶段。它衡量的是模型对给定测试集的预测准确性。具体来说,困惑度是交叉熵损失函数的指数形式,可以用来衡量模型对每个词的预测不确定性。
困惑度的计算公式如下:
P P ( W ) = P ( w 1 , w 2 , . . . , w N ) − 1 N = 1 P ( w 1 , w 2 , . . . , w N ) N PP(W) = P(w_1, w_2, ..., w_N)^{-\frac{1}{N}} = \sqrt[N]{\frac{1}{P(w_1, w_2, ..., w_N)}} PP(W)=P(w1,w2,...,wN)−N1=NP(w1,w2,...,wN)1
其中,(PP(W)) 表示困惑度,(P(w_1, w_2, …, w_N)) 表示模型对整个序列 (w_1, w_2, …, w_N) 的联合概率。N 是序列中词的数量。
困惑度的直观含义是,模型预测下一个词时平均有多少种可能性。因此,困惑度越低,模型的不确定性越小,对数据的预测越准确。理想情况下,困惑度接近于 1,这意味着模型总是能够完美地预测下一个词。
在实际应用中,降低困惑度是提高语言模型性能的一个重要目标。通过优化模型结构、训练策略和数据集,可以降低困惑度,从而提高模型在各项任务上的表现。
似然性(Likelihood)
在统计建模和机器学习领域,似然性(Likelihood)是一个衡量模型对给定数据集拟合程度的指标。具体来说,似然性是指模型生成观测数据的概率,即模型参数在给定数据下的概率密度。
对于语言模型,似然性通常是通过计算模型对训练数据中每个词的概率乘积来估计的。这个乘积给出了在模型参数和训练数据固定的情况下,模型生成整个数据集的概率。我们希望这个概率尽可能高,因为这表示模型能够很好地捕捉数据的统计特性。
似然性的计算公式可以表示为:
L ( θ ∣ D ) = ∏ i = 1 N P ( w i ∣ w 1 , w 2 , . . . , w i − 1 , θ ) L(\theta | D) = \prod_{i=1}^{N} P(w_i | w_1, w_2, ..., w_{i-1}, \theta) L(θ∣D)=i=1∏NP(wi∣w1,w2,...,wi−1,θ)
其中,(L(\theta | D)) 是似然函数,(\theta) 是模型参数,(D = {w_1, w_2, …, w_N}) 是训练数据集,(P(w_i | w_1, w_2, …, w_{i-1}, \theta)) 是在给定前 (i-1) 个词和模型参数的情况下,模型对第 (i) 个词的概率估计。
在实际应用中,由于直接计算似然性可能会遇到数值下溢的问题(因为连乘很多小于 1 的数),我们通常使用对数似然性(Log-Likelihood)来简化计算:
log L ( θ ∣ D ) = ∑ i = 1 N log P ( w i ∣ w 1 , w 2 , . . . , w i − 1 , θ ) \log L(\theta | D) = \sum_{i=1}^{N} \log P(w_i | w_1, w_2, ..., w_{i-1}, \theta) logL(θ∣D)=i=1∑NlogP(wi∣w1,w2,...,wi−1,θ)
对数似然性的值越高,表示模型对数据的拟合越好。在训练过程中,我们通常通过最大化对数似然性来找到最佳的模型参数。这种方法被称为最大似然估计(Maximum Likelihood Estimation, MLE)。
需要注意的是,尽管高似然性表明模型能够很好地拟合训练数据,但这并不保证模型具有良好的泛化能力。因此,在评估模型时,我们还需要考虑验证集和测试集上的性能,以避免过拟合。
样本生成质量
在生成式语言模型的训练和评估过程中,样本生成质量是一个非常重要的指标。尤其是在预训练阶段,由于没有具体的任务目标,评估模型的泛化能力和语言理解能力变得更加重要。以下是评估样本生成质量时通常会考虑的几个方面:
- 语言流畅性:生成的文本应该符合语言的语法规则,包括正确的拼写、标点和句子结构。流畅的语言表达是衡量模型是否能够生成自然语言的基本标准。
- 语义连贯性:文本中的词汇、短语和句子应该逻辑上一致,表达清晰的意思。语义连贯性反映了模型对语言深层含义的理解能力。
- 主题相关性:生成的文本应该与给定的主题或上下文相关。模型应该能够生成与输入信息相关的内容,而不是无关的信息。
- 多样性和创造性:除了上述基本要求外,高质量的文本还应该展现出一定的多样性和创造性。模型不应该只能够生成刻板的回答,而应该能够创造出新颖的内容。
- 事实准确性:在某些应用场景中,如问答系统或知识获取,生成文本的事实准确性也非常重要。模型生成的信息应该真实可靠。
人工评估样本生成质量通常是通过让一组评估者根据上述标准对生成的文本进行评分来完成的。这种方法虽然耗时且成本较高,但能够提供关于模型性能的综合和直观的理解。此外,随着技术的发展,也有一些自动化的评估工具和方法被开发出来,如使用预训练的语言模型来评估生成文本的质量,但这些方法通常无法完全替代人工评估。
微调阶段的验证:
微调阶段使用特定任务的有标注数据对预训练模型进行进一步训练,以适应特定应用场景。在这个阶段,验证的目的是评估模型在特定任务上的性能。常见的验证方式包括:
- 开发集(Development Set):使用专门划分的开发集来评估模型性能,通过计算各种任务特定的评价指标(如准确率、F1分数、精确率、召回率等)来监控模型表现。
- 交叉验证(Cross-Validation):当数据量有限时,可以使用交叉验证来更有效地利用数据,同时减少评估结果的方差。
- 超参数调整:在微调阶段,可能需要调整一些超参数以优化模型性能。验证集可以帮助确定最佳的超参数设置。
在验证过程中,重要的是要确保验证集或开发集能够代表实际应用场景的数据分布,以便模型在验证集上的表现能够真实反映其在实际应用中的性能。此外,为了避免过拟合验证集,通常需要严格划分训练集、验证集和测试集,并确保模型在验证集上的表现能够泛化到未见过的新数据上。
相关文章:

生成式语言模型预训练阶段验证方式与微调阶段验证方式
生成式语言模型,如GPT-3、BERT等,在预训练和微调阶段都需要进行验证以确保模型性能。下面分别介绍这两个阶段的验证方式: 预训练阶段的验证: 预训练阶段通常使用大量未标注的文本数据来训练模型,以学习语言的一般特性。…...
flink on yarn
前言 Apache Flink,作为大数据处理领域的璀璨明星,以其独特的流处理和批处理一体化模型,成为众多企业和开发者的首选。它不仅能够在处理无界数据流时展现出卓越的实时性能,还能在有界数据批处理上达到高效稳定的效果。本文将简要…...

用TOMCAT部署web项目教程
文章目录 引言I 使用webapps文件夹II 利用server.xmlIII 自定义配置文件IV 预备知识4.1项目的一般结构4.2 contex标签4.3 IDE部署4.4 配置Tomcat服务引言 在开发阶段,一般使用IDE如MyEclipse来部署web项目,不要忘记手动部署的三种方式。 I 使用webapps文件夹 将项目文件夹…...

bash例子-source进程替换、alias不生效处理
#1. source 例子, 进程替换source <(echo alias zls"ls") #上一行 中 echo替换为cat,则得到如下行, 好处是 cat不用处理引号转义问题,而echo则必须处理引号转义问题#写一段复杂脚本,且 不处理引号转义问题 &#x…...
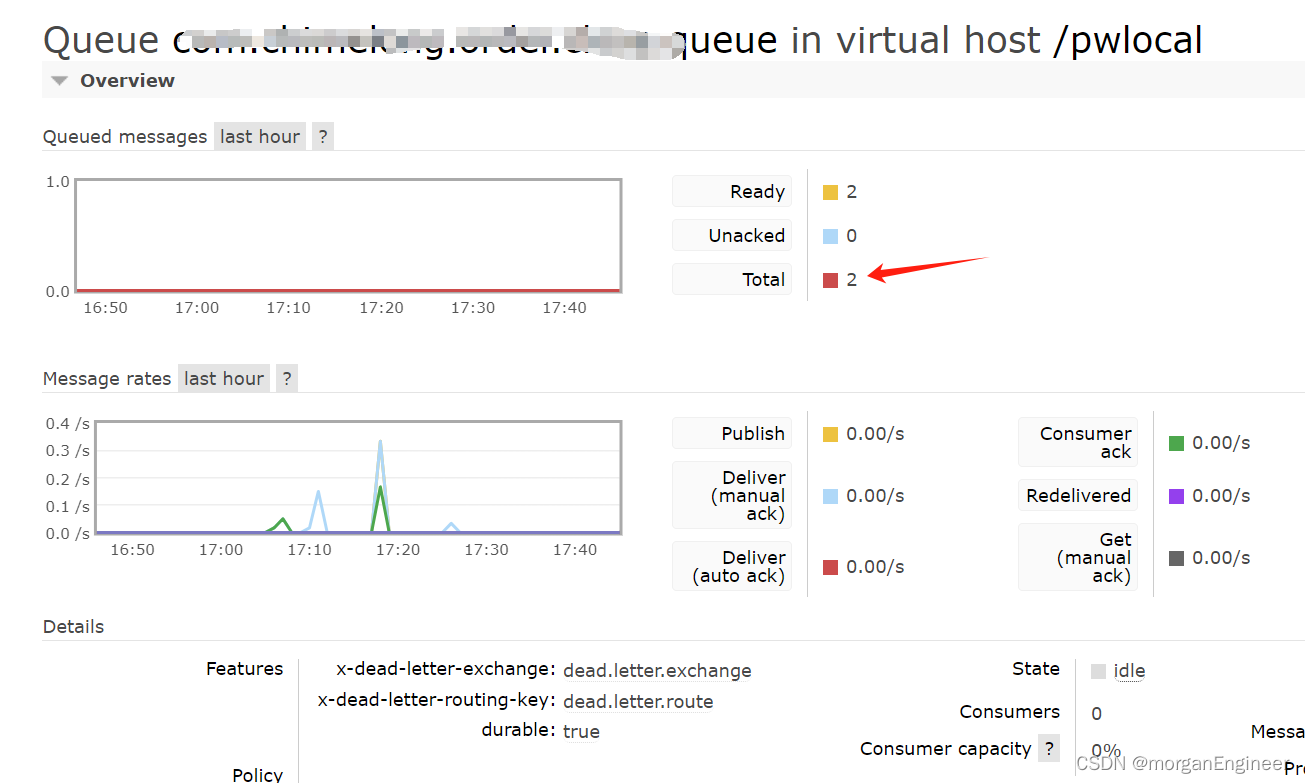
rabbitmq死信交换机,死信队列使用
背景 对于核心业务需要保证消息必须正常消费,就必须考虑消费失败的场景,rabbitmq提供了以下三种消费失败处理机制 直接reject,丢弃消息(默认)返回nack,消息重新入队列将失败消息投递到指定的交换机 对于核…...

gitlab备份与恢复
1.1.1 查看系统版本和软件版本 cat /etc/debian_version cat /opt/gitlab/embedded/service/gitlab-rails/VERSION 1.1.2 数据备份 打开/etc/gitlab/gitlab.rb配置文件,查看一个和备份相关的配置项 sudo vim /etc/gitlab/gitlab.rb gitlab_rails[backup_path] &q…...
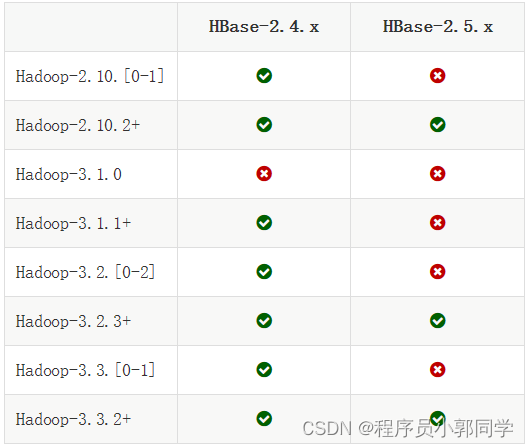
HBase详解(1)
HBase 简介 概述 HBase是Yahoo!公司开发的后来贡献给了Apache的一套开源的、分布式的、可扩展的、基于Hadoop的非关系型数据库(Non-Relational Database),因此HBase并不支持SQL(几乎所有的非关系型数据库都不支持SQL),而是提供了一套单独的命令和API操…...

深入理解数据结构第二弹——二叉树(2)——堆排序及其时间复杂度
看这篇前请先把我上一篇了解一下:深入理解数据结构第一弹——二叉树(1)——堆-CSDN博客 前言: 相信很多学习数据结构的人,都会遇到一种情况,就是明明最一开始学习就学习了时间复杂度,但是在后期…...

视频汇聚/安防监控/EasyCVR平台播放器EasyPlayer更新:新增【性能面板】
视频汇聚/安防监控/视频存储平台EasyCVR基于云边端架构,可以在复杂的网络环境中快速、灵活部署,平台视频能力丰富,可以提供实时远程视频监控、视频录像、录像回放与存储、告警、语音对讲、云台控制、平台级联、磁盘阵列存储、视频集中存储、云…...

【教程】Flutter 应用混淆
在移动应用开发中,保护应用代码安全至关重要。Flutter 提供了简单易用的混淆工具,帮助开发者在构建 release 版本应用时有效保护代码。本文将介绍如何在 Flutter 应用中使用混淆,并提供了相关的操作步骤和注意事项。 📝 摘要 本…...

STM32中C编程引入C++程序
C具备类的创建思想很实用于实际场景多相似性的框架搭建;同种类型或相似类型的C的优势明显因此进行相互嵌套使用 需要在C中使用C类的话,你可以通过C的“extern "C"”语法来实现。这允许你在C代码中使用C的链接方式,而在C代码中使用…...

MySQL DBA 需要了解一下 InnoDB Online DDL 算法更新
在 MySQL 8.0.12 中,我们引入了一种新的 DDL 算法,该算法在更改表的定义时不会阻塞表。第一个即时操作是在表格末尾添加一列,这是来自腾讯游戏的贡献。 然后在 MySQL 8.0.29 中,我们添加了在表中任意位置添加(或删除&…...

多态--下
文章目录 概念多态如何实现的指向谁调谁?例子分析 含有虚函数类的大小是多少?虚函数地址虚表地址多继承的子类的大小怎么计算?练习题虚函数和虚继承 概念 优先使用组合、而不是继承; 继承会破坏父类的封装、因为子类也可以调用到父类的函数;…...
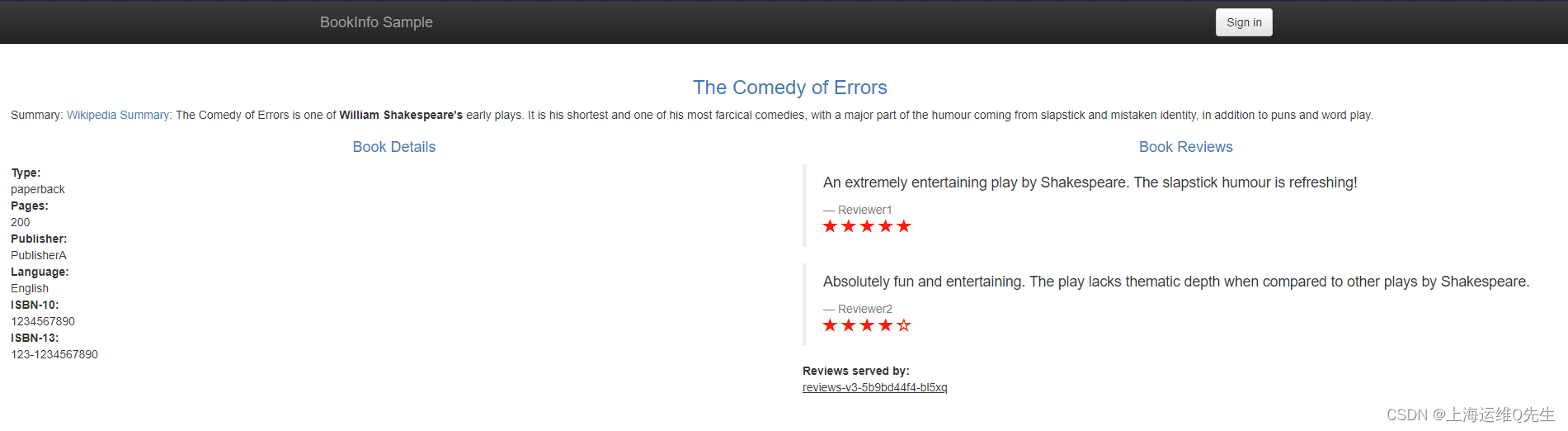
备考ICA----Istio实验16---HTTP流量授权
备考ICA----Istio实验16—HTTP流量授权 1. 环境准备 kubectl apply -f istio/samples/bookinfo/platform/kube/bookinfo.yaml kubectl apply -f istio/samples/bookinfo/networking/bookinfo-gateway.yaml访问测试 curl -I http://192.168.126.220/productpage2. 开启mtls …...
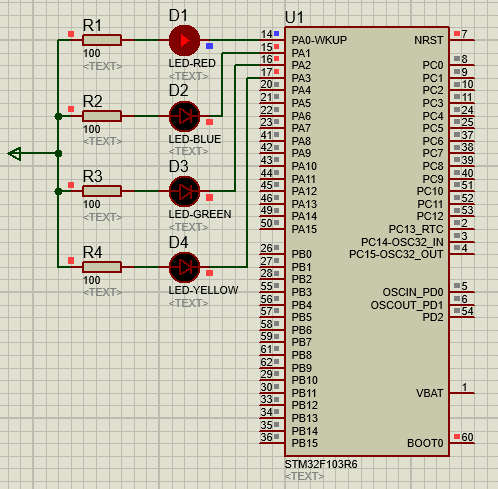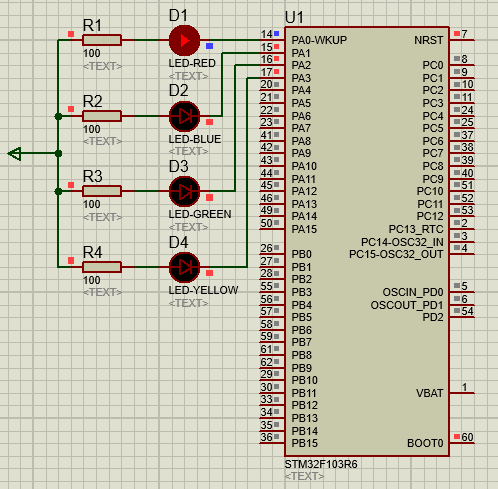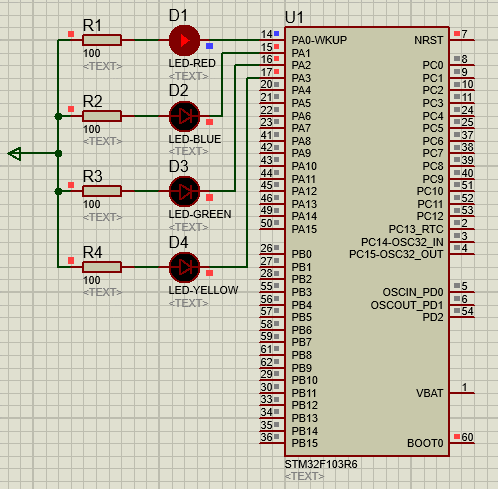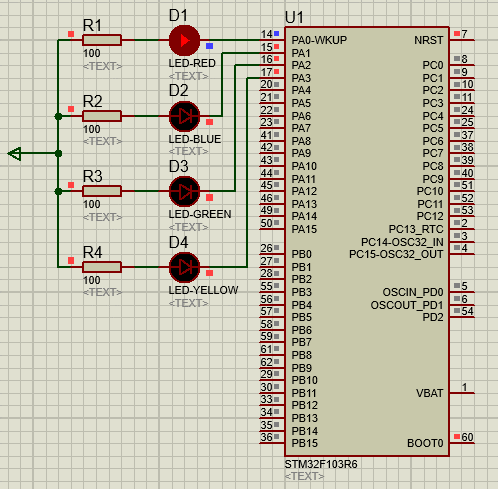
STM32-02基于HAL库(CubeMX+MDK+Proteus)GPIO输出案例(LED流水灯)
文章目录 一、功能需求分析二、Proteus绘制电路原理图三、STMCubeMX 配置引脚及模式,生成代码四、MDK打开生成项目,编写HAL库的GPIO输出代码五、运行仿真程序,调试代码 一、功能需求分析 在完成开发环境搭建之后,开始使用STM32GP…...
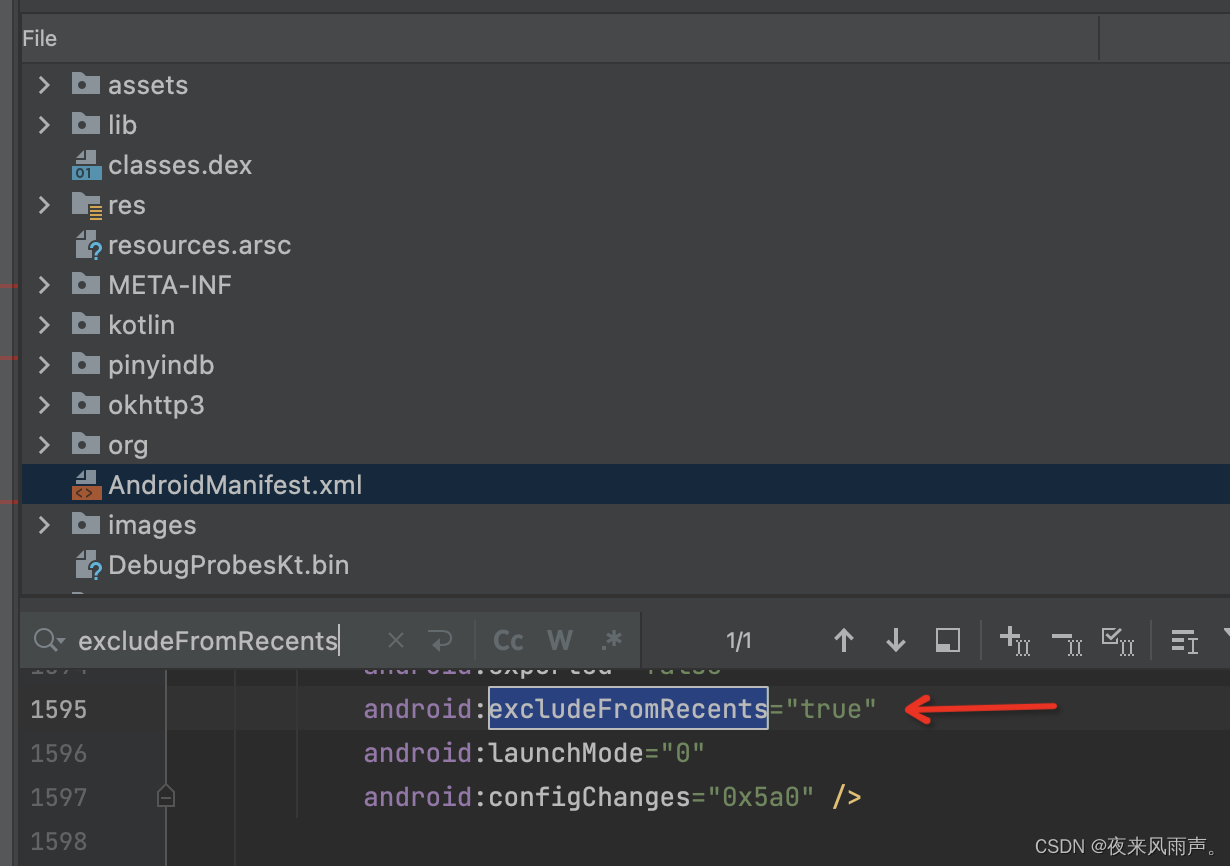
华为审核被拒提示: 您的应用存在(最近任务列表隐藏风险活动)的行为,不符合华为应用市场审核标准
应用审核意见: 您的应用存在(最近任务列表隐藏风险活动)的行为,不符合华为应用市场审核标准。 修改建议:请参考测试结果进行修改。 请参考《审核指南》第2.19相关审核要求:https://developer.huawei.com/c…...
数论与线性代数——整除分块【数论分块】的【运用】【思考】【讲解】【证明(作者自己证的QWQ)】
文章目录 整除分块的思考与运用整除分块的时间复杂度证明 & 分块数量整除分块的公式 & 公式证明公式证明 代码code↓ 整除分块的思考与运用 整除分块是为了解决一个整数求和问题 题目的问题为: ∑ i 1 n ⌊ n i ⌋ \sum_{i1}^{n} \left \lfloor \frac{n}{…...
Linux系统下安装jdk与tomcat【linux】
一、yum介绍 linux下的jdk安装以及环境配置,有两种常用方法: 1.使用yum一键安装。 2.手动安装,在Oracle官网下载好需要的jdk版本,上传解压并配置环境。 这里介绍第一种方法,在此之前简单了解下yum。 yum 介绍 yum&…...
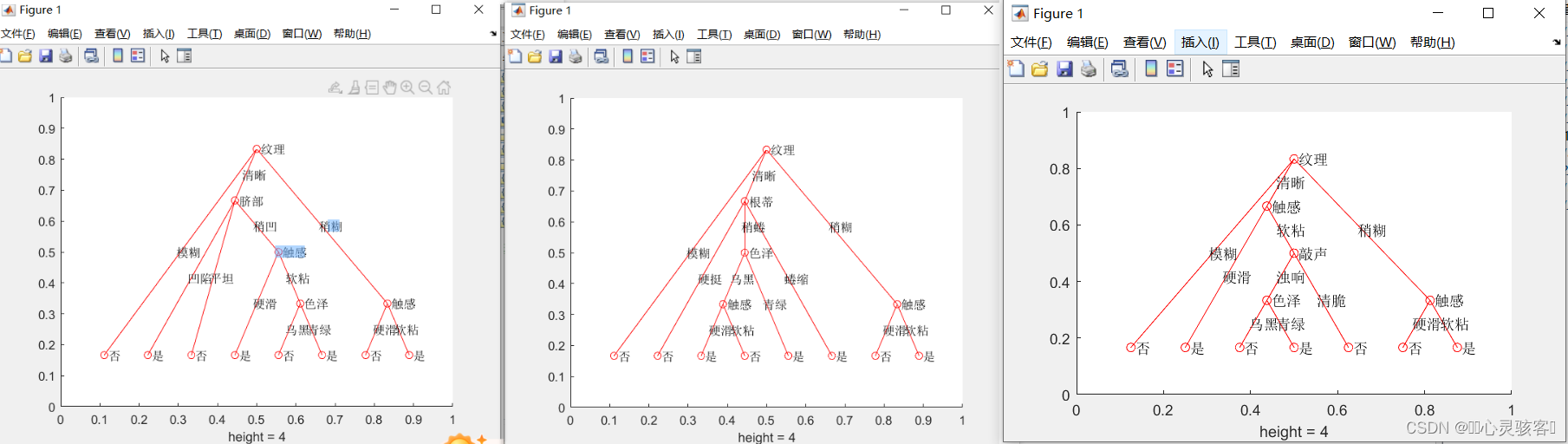
matlab实现决策树可视化——信息增益、C4.5、基尼指数
代码:https://download.csdn.net/download/boyas/89074326...

如何使用Python进行网络编程和套接字通信?
如何使用Python进行网络编程和套接字通信? Python作为一种通用编程语言,具有强大的网络编程能力。它提供了丰富的库和工具,使得开发者可以轻松地实现网络编程和套接字通信。下面将详细介绍如何使用Python进行网络编程和套接字通信。 一、网…...

MagiskBoot:Android启动镜像解构与重构引擎深度解析
MagiskBoot:Android启动镜像解构与重构引擎深度解析 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk MagiskBoot作为Magisk生态系统的核心组件,专门负责Android启动镜像的多格式解…...

告别龟速下载!实测对比Axel、Aria2、mwget三大神器,教你选对多线程工具
三大命令行下载神器深度横评:Axel、Aria2与mwget的性能对决 当你在终端里反复输入wget或curl命令,盯着缓慢增长的进度条时,是否想过还有更高效的解决方案?本文将带你深入探索Axel、Aria2和mwget这三款命令行下载加速工具ÿ…...

LaMa图像修复:基于傅里叶卷积的大掩码鲁棒修复方法
1. 项目概述:这不是又一个“修图工具”,而是一次对图像修复底层逻辑的重新定义LaMa——全称Large Mask Inpainting,直译是“大区域掩码图像修复”,但它的实际能力远超字面。我第一次在CVPR 2022论文里看到它时,第一反应…...

LVGL图片资源全解析:从C数组到图标字体的高效集成方案
1. LVGL图片资源方案概述 在嵌入式GUI开发中,图片资源的管理直接影响产品性能和开发效率。LVGL作为轻量级图形库,提供了三种主流的图片集成方案:内部C数组、外部文件系统图片和图标字体。每种方案都有其独特的适用场景和实现方式,…...

AI赋能医院物流:基于PDCA循环的智能供应链韧性提升实践
1. 项目概述:当医院物流遇上AI与PDCA医院物流,听起来可能有点“幕后”,但它绝对是现代医疗体系顺畅运转的“大动脉”。从高值耗材、药品、检验试剂,到被服布草、医疗废物,甚至是一日三餐,这条链条上任何一个…...

基于MCP协议与向量数据库构建AI编程助手私有记忆系统
1. 项目概述:为你的AI编程助手打造一个“记忆宫殿”如果你和我一样,重度依赖Cursor这类AI编程助手,那你肯定遇到过这个痛点:昨天刚和它深入讨论过一个复杂的业务逻辑实现,今天想参考一下,却发现在浩如烟海的…...
:无监督拓扑保持的高维数据可视化与聚类)
自组织映射(SOM):无监督拓扑保持的高维数据可视化与聚类
1. 什么是自组织映射(SOM)?它到底能帮你解决什么实际问题?我第一次在客户现场看到SOM落地,是在一家做工业设备预测性维护的公司。他们有上百台传感器,每台每秒产生十几维的振动、温度、电流数据,…...

三步搞定:iPaaS系统集成自动化配置实战
2025年,全球集成平台即服务(iPaaS)市场规模达到156.3亿美元,预计到2034年将增长至1087.6亿美元,年复合增长率高达24.20%。(数据来源:Fortune Business Insights,2026年2月࿰…...

想转行AI?大模型4大热门方向深度解构!小白也能收藏的进阶指南
AI大模型领域岗位需求激增,人才缺口超500万。本文深度解析大模型4大热门方向:算法研发与模型预训练(门槛高,偏研究)、模型对齐与后训练优化(岗位增长快,数据驱动)、推理工程与模型部…...
版本:UEFI-OC095-)
Hyper-V下安装macOS(引导文件macOS.Monterey.14.x.UEFI.vhdx)版本:UEFI-OC095-
用于windows自带hyper-v虚拟机安装macos14时使用的虚拟磁盘,具体如何安装请参考文章...