机器学习的模型校准
背景知识
之前一直没了解过模型校准是什么东西,最近上班业务需要看了一下:
模型校准是指对分类模型进行修正以提高其概率预测的准确性。在分类模型中,预测结果通常以类别标签形式呈现(例如,0或1),但有时我们更关注的是预测的概率。
当使用某些分类模型(例如支持向量机(SVM)或随机森林)时,其预测的概率并不一定与真实标签的概率分布相匹配。这意味着,即使预测概率较高的类别出现的频率更高,模型的预测概率也可能偏离真实情况。这可能导致对模型的概率输出有误解,或者在需要高度依赖概率预测的任务(例如风险评估或阈值选择)中出现问题。
通过校准分类模型,我们可以将模型的预测概率调整为更准确地反映真实情况。`CalibratedClassifierCV`是Scikit-learn库中提供的用于校准分类器的类。它根据指定的校准方法(`method`),通过拟合后的分类器(`model`)和交叉验证拟合(`cv='prefit'`)来创建一个经过校准的分类器(`calibrated_model`)。
在代码中,使用`calibrated_model.fit(X_train, y_train)`通过使用交叉验证拟合来训练、校准模型。之后,使用`calibrated_model.predict(X_test)`对测试集进行预测,并使用`classification_report`输出校准模型的分类性能报告。
通过校准分类模型,我们可以使得模型的概率预测更为准确,从而提高在概率判断和相关任务中的性能和可靠性。
代码实现
模型校准主要是针对分类模型的,我之前都是做回归,难怪没怎么接触过。也没空找真实数据了,直接模拟数据来实现一下。
导入包和制作数据集
import numpy as np
import pandas as pd
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
from sklearn.calibration import calibration_curve
from sklearn.ensemble import RandomForestClassifierimport matplotlib.pyplot as plt# 生成二分类数据集
X, y = make_classification(n_samples=10000, n_features=40, n_classes=2, weights=[0.9, 0.1], random_state=2, flip_y=0.3)查看分布:
pd.Series(y).value_counts()
不平衡样本。
标准化,划分训练集测试集
# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y,stratify=y, test_size=0.2, random_state=2)训练,然后评价,这里就弄了个随机森林模型试试
# 模型训练
model =RandomForestClassifier()
model.fit(X_train, y_train)# 模型评价
y_pred = model.predict(X_test)
print("Classification Report:")
print(classification_report(y_test, y_pred))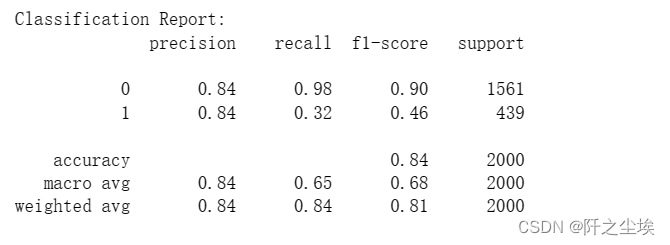
画校准曲线。
# 计算校准曲线
prob_true, prob_pred = calibration_curve(y_test, model.predict_proba(X_test)[:, 1], n_bins=10)# 绘制校准曲线
plt.figure(figsize=(7, 4),dpi=128)
plt.plot(prob_pred, prob_true, marker='o', label='uncalibrated')
plt.plot([0, 1], [0, 1], linestyle='--', color='gray', label='perfectly calibrated')
plt.xlabel('Mean predicted probability')
plt.ylabel('Fraction of positives')
plt.title('Calibration Curve (Uncalibrated)')
plt.legend()
plt.show()
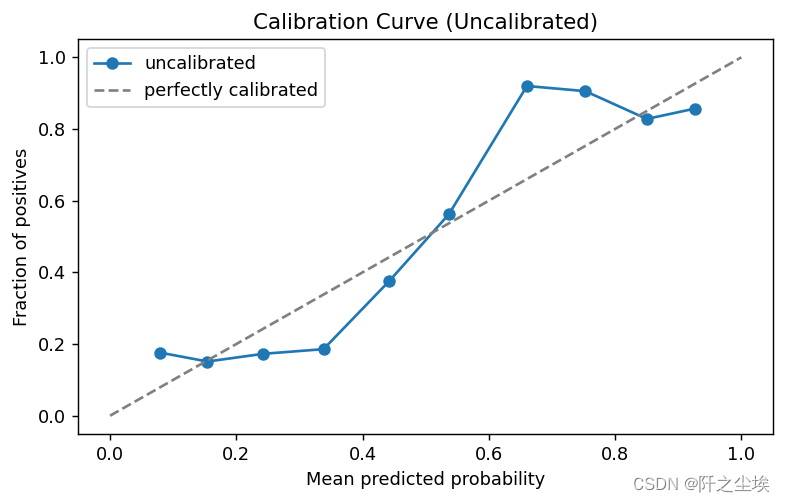
这玩意怎么看,,,我也不太懂,反正就是要单调,并且越靠近对角线越好。这个明显在0.1-0.2区间不单调,还有0.7-0.9也在下降。
来校准一下:
模型校准
模型校准很多方法,目前这个是用了 method='sigmoid',这个方法,好像叫做什么p系数校准。
from sklearn.calibration import CalibratedClassifierCV
calibrated_model = CalibratedClassifierCV(model, method='sigmoid', cv='prefit')
calibrated_model.fit(X_train, y_train)# 模型评价(校准后)
y_pred_calibrated = calibrated_model.predict(X_test)
print("Classification Report (Calibrated Model):")
print(classification_report(y_test, y_pred_calibrated))
emmm,效果好像没有明显提升。
method='isotonic',这个是什么保序回归方法校准。
calibrated_model2 = CalibratedClassifierCV(model, method='isotonic', cv='prefit')
calibrated_model2.fit(X_train, y_train)# 模型评价(校准后)
y_pred_calibrated2 = calibrated_model2.predict(X_test)
print("Classification Report (Calibrated Model):")
print(classification_report(y_test, y_pred_calibrated2))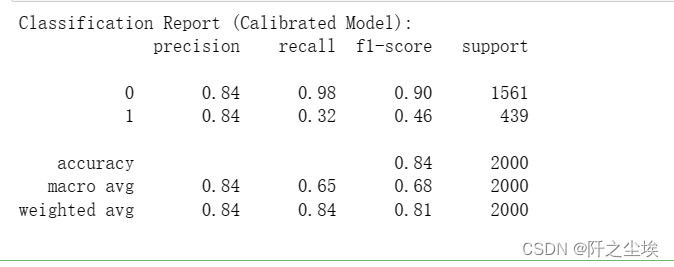
效果也差不多。
画出校准曲线的对比图:
# 计算校准后的校准曲线
prob_true_calibrated, prob_pred_calibrated = calibration_curve(y_pred_calibrated,calibrated_model.predict_proba(X_test)[:, 1], n_bins=10)
prob_true_calibrated2, prob_pred_calibrated2 = calibration_curve(y_pred_calibrated2,calibrated_model2.predict_proba(X_test)[:, 1], n_bins=10)
# 绘制校准后的校准曲线
plt.figure(figsize=(7, 4),dpi=128)
plt.plot(prob_pred, prob_true, marker='o', label='uncalibrated')
plt.plot(prob_pred_calibrated, prob_true_calibrated, marker='o', label='sigmoid calibrated')
plt.plot(prob_pred_calibrated2, prob_true_calibrated2, marker='o', label='isotonic calibrated')
plt.plot([0, 1], [0, 1], linestyle='--', color='gray', label='perfectly calibrated')
plt.xlabel('Mean predicted probability')
plt.ylabel('Fraction of positives')
plt.title('Calibration Curve (Calibrated)')
plt.legend()
plt.show()
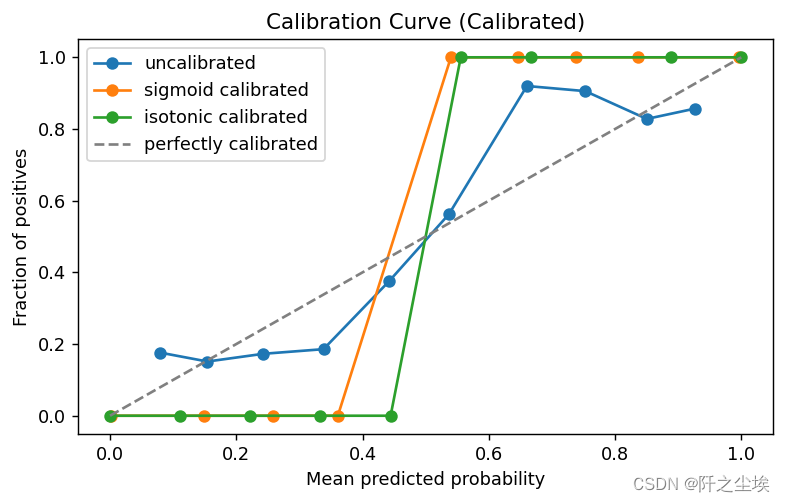
可以看到模型校准之后这个线都是单调上升的了。但是都很奇怪,而且预测效果也没太多改善,可能是我这个数据集是随便造的原因。
校准曲线的单调性在模型校准中确实非常重要。校准曲线的单调性指的是在横轴表示预测概率的均值,纵轴表示实际观测到的正例比例时,曲线应该是单调递增的,即预测概率越高,观测到的正例比例也应该越高。
校准曲线的单调性反映了模型输出的概率与实际观测之间的一致性。如果校准曲线的单调性较差,意味着模型的输出概率与实际观测之间存在较大的偏差,可能会导致模型在实际应用中表现不稳定或不可靠。因此,单调的校准曲线通常被认为是一个良好校准的指标之一。
在实际应用中,如果模型的校准曲线不单调,可能需要进一步考虑以下问题:
模型的输出概率是否准确反映了样本的真实概率:如果模型输出的概率存在系统性的偏差,可能需要对模型进行校准,使其输出更加准确地反映样本的真实概率。
模型是否过度自信或不足自信:校准曲线的不单调性可能反映了模型在某些概率范围内过度自信或不足自信的问题。对于过度自信的模型,可能需要降低其输出概率;对于不足自信的模型,可能需要提高其输出概率。
模型的可靠性:校准曲线的单调性也反映了模型的可靠性。单调递增的校准曲线意味着模型的输出概率与实际观测之间的一致性较好,通常更可靠。
因此,校准曲线的单调性对于评估模型的校准效果和可靠性具有重要意义,在模型校准过程中应该注意观察和优化校准曲线的单调性。
嗯,都是gpt的话,看看了解一下就行。
相关文章:
机器学习的模型校准
背景知识 之前一直没了解过模型校准是什么东西,最近上班业务需要看了一下: 模型校准是指对分类模型进行修正以提高其概率预测的准确性。在分类模型中,预测结果通常以类别标签形式呈现(例如,0或1)…...

0.17元的4位数码管驱动芯片AiP650,支持键盘,还是无锡国家集成电路设计中心某公司的
推荐原因:便宜的4位数码管驱动芯片 只要0.17元,香吗?X背景的哦。 2 线串口共阴极 8 段 4 位 LED 驱动控制/7*4 位键盘扫描专用电路 AIP650参考电路图 AIP650引脚定义...

【C++】编程规范之内存规则
在高质量编程中,内存管理是一个至关重要的方面。主要有以下原则: 内存分配后需要检查是否成功:内存分配可能会失败,特别是在内存紧张的情况下。因此,在分配内存后,应该检查分配是否成功。 int* ptr new …...
并发编程之线程池的应用以及一些小细节的详细解析
线程池在实际中的使用 实际开发中,最常用主要还是利用ThreadPoolExecutor自定义线程池,可以给出一些关键的参数来自定义。 在下面的代码中可以看到,该线程池的最大并行线程数是5,线程等候区(阻塞队列)是3,即…...
基于JSP的农产品供销服务系统
背景 互联网的迅猛扩张彻底革新了全球各类组织的运营模式。自20世纪90年代起,中国的政府机关和各类企业便开始探索利用网络系统来处理管理事务。然而,早期的网络覆盖范围有限、用户接受度不高、互联网相关法律法规不完善以及技术开发不够成熟等因素&…...
redis之主从复制、哨兵模式
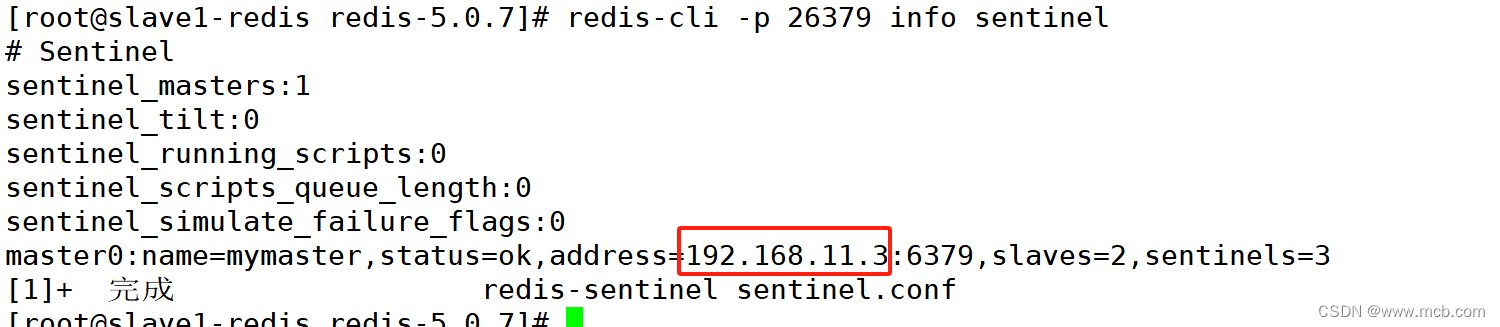
一 redis群集有三种模式 主从复制: 主从复制是高可用Redis的基础,哨兵和集群都是在主从复制基础上实现高可用的。 主从复制主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复。 缺陷: 故障恢复无法自动化&…...

【随笔】Git 基础篇 -- 分支与合并 git rebase(十)
💌 所属专栏:【Git】 😀 作 者:我是夜阑的狗🐶 🚀 个人简介:一个正在努力学技术的CV工程师,专注基础和实战分享 ,欢迎咨询! 💖 欢迎大…...

图像识别技术在体育领域的应用
图像识别技术在体育领域的应用是一个充满创新和挑战的研究方向。随着计算机视觉和人工智能技术的快速发展,图像识别技术已经在体育领域展现出广泛的应用潜力和实际价值。以下是一些图像识别技术在体育领域的具体应用: 运动员表现分析: 图像识…...

【项目新功能开发篇】开发编码
作者介绍:本人笔名姑苏老陈,从事JAVA开发工作十多年了,带过大学刚毕业的实习生,也带过技术团队。最近有个朋友的表弟,马上要大学毕业了,想从事JAVA开发工作,但不知道从何处入手。于是࿰…...

软件设计原则:开闭原则
定义 开闭原则(Open-Closed Principle, OCP)是面向对象设计的基本原则之一,由 Bertrand Meyer 提出。它指出软件实体(类、模块、函数等)应该对扩展开放,对修改封闭。这意味着软件应该设计成在不修改现有代…...

Python如何下载视频
大家好,今天我将为大家介绍如何使用Python来下载视频。Python作为一门强大的编程语言,不仅可以用于数据分析、机器学习等领域,还能用于网络爬虫和视频下载等任务。下面我将详细介绍如何使用Python来下载视频。 首先,我们需要明确…...
使用虚拟引擎为AR体验提供动力
Powering AR Experiences with Unreal Engine 目录 1. 虚拟引擎概述 2. 虚拟引擎如何为AR体验提供动力 3. 虚拟引擎中AR体验的组成部分是什么? 4. 使用虚拟引擎创建AR体验 5. 虚拟引擎中AR的优化提示 6. 将互动性融入AR与虚拟引擎 7. 在AR中…...

Kafka入门到实战-第五弹
Kafka入门到实战 Kafka常见操作官网地址Kafka概述Kafka的基础操作更新计划 Kafka常见操作 官网地址 声明: 由于操作系统, 版本更新等原因, 文章所列内容不一定100%复现, 还要以官方信息为准 https://kafka.apache.org/Kafka概述 Apache Kafka 是一个开源的分布式事件流平台&…...

Ideal Holidays
题目链接 AtCoder Beginner Contest 347 C - Ideal Holidays 思路: 一周有 A B AB AB 天,前 A A A 天放假,问能不能把所有工作放进节假日里。 先看简单的,两个。其实我们并不是很在乎它们中间隔了多少天,我们只…...
Raven:一款功能强大的CICD安全分析工具
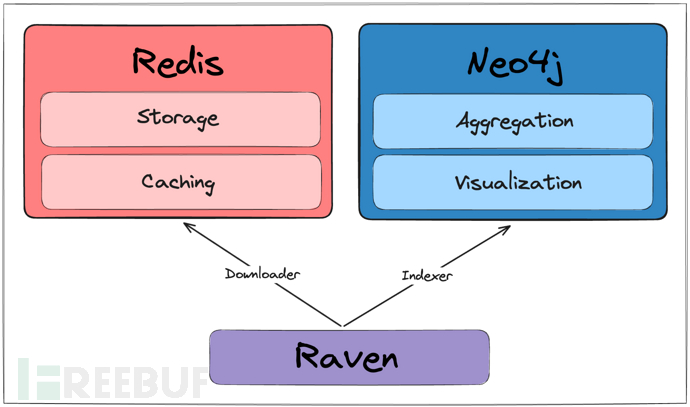
关于Raven Raven是一款功能强大的CI/CD安全分析工具,该工具旨在帮助广大研究人员对GitHub Actions CI工作流执行大规模安全扫描,并将发现的数据解析并存储到Neo4j数据库中。 Raven,全称为Risk Analysis and Vulnerability Enumeration for C…...

【苹果MAC】苹果电脑 LOGI罗技鼠标设置左右切换全屏页面快捷键
首先键盘设置->键盘快捷键 调度中心 设置 f1 f2 为移动一个空间(就可以快捷移动了) 想要鼠标直接控制,就需要下载官方驱动,来设置按键快捷键,触发 F1 F2 安装 LOGI OPTIONS Logi Options 是一款功能强大且便于使用…...
IDE/VS2015和VS2017帮助文档MSDN安装和使用
文章目录 概述VS2015MSDN离线安装离线MSDN的下载离线MSDN安装 MSDN使用方法从VS内F1启动直接启动帮助程序跳转到了Qt的帮助网页 VS2017在线安装MSDN有些函数在本地MSDN没有帮助?切换中英文在线帮助文档 概述 本文主要介绍了VS集成开发环境中,帮助文档MS…...
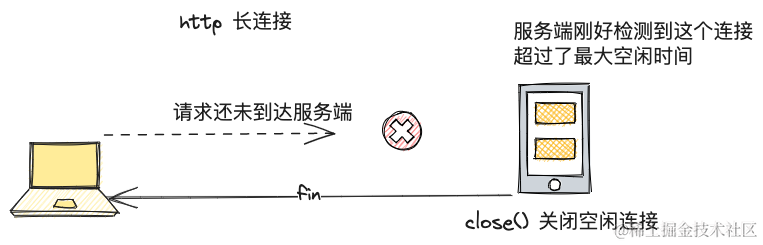
开启 Keep-Alive 可能会导致http 请求偶发失败
大家好,我是蓝胖子,说起提高http的传输效率,很多人会开启http的Keep-Alive选项,这会http请求能够复用tcp连接,节省了握手的开销。但开启Keep-Alive真的没有问题吗?我们来细细分析下。 最大空闲时间造成请求…...
)
【leetcode面试经典150题】4.删除有序数组中的重复项 II(C++)
【leetcode面试经典150题】专栏系列将为准备暑期实习生以及秋招的同学们提高在面试时的经典面试算法题的思路和想法。本专栏将以一题多解和精简算法思路为主,题解使用C语言。(若有使用其他语言的同学也可了解题解思路,本质上语法内容一致&…...

【LeetCode热题100】【普通数组】合并区间
题目链接:56. 合并区间 - 力扣(LeetCode) 先排序,按左区排序,装第一个区间进入答案容器,判断答案容器钟最后一个区间的右区是否小于区间的左区,是则不能合并是新区间,否则可以合并 …...

光伏并网系统谐波抑制控制策略【附程序】
✨ 长期致力于锁相环、谐波电流检测、二阶广义积分器、LMS滤波器研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于双二阶广义积分器-锁频环的自适应…...
)
扫雷外挂逆向笔记:我是如何找到那个0x8F代表地雷的(含OD动态调试技巧)
扫雷外挂逆向笔记:从内存数据到游戏逻辑的侦探之旅 逆向工程最迷人的地方在于,它像一场精心设计的侦探游戏。当你面对一堆看似毫无规律的十六进制数值时,如何抽丝剥茧,找出它们与游戏逻辑之间的映射关系?本文将分享我在…...

Tiny AI Client:零依赖、轻量化的AI API调用库设计与实战
1. 项目概述与核心价值最近在折腾AI应用本地化部署和轻量化客户端时,发现了一个挺有意思的项目——piEsposito/tiny-ai-client。这名字起得就很直白,“tiny”意味着小巧,“ai-client”点明了它是一个AI客户端。乍一看,你可能会觉得…...

ComfyUI-Impact-Pack完整安装指南:解决AI图像增强插件功能缺失问题
ComfyUI-Impact-Pack完整安装指南:解决AI图像增强插件功能缺失问题 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地…...
)
告别一堆转换头!一个自研小工具搞定USB、网口、485、232、TTL全互连(附配置软件)
极简主义工程师的终极武器:全协议互连调试工具实战指南 每次出差调试设备,我的背包里总塞满了各种转换头——USB转串口、网口转485、232电平转换器...直到上个月在客户现场,当我蹲在机柜旁手忙脚乱切换第五个转换器时,螺丝刀不小心…...

Neovim涂抹光标插件:提升编码体验的动态轨迹设计
1. 项目概述:一个为Neovim设计的“涂抹光标”插件 如果你和我一样,是个重度Neovim用户,每天有超过8小时的时间泡在终端和代码编辑器里,那你肯定对光标的“存在感”有要求。默认的方块或下划线光标,在长时间编码后&…...

上网行为怎么监控?教你五个简单实用的上网行为监控方法,建议收藏
在数字化办公时代,企业管理面临着新的挑战:一方面需要网络提供资讯和工具,另一方面,无节制的非工作上网行为正在侵蚀企业的生产力。如何科学、合理地监控上网行为?以下为您介绍五个监控方法,涵盖了从硬件到…...

仅限首批Beta开发者访问的Gemini Calendar高级API权限池即将关闭——现在掌握这6个私有端点将决定你团队的2025排期话语权
更多请点击: https://intelliparadigm.com 第一章:Gemini Google Calendar智能安排 Gemini 与 Google Calendar 的深度集成正在重塑日程管理范式。通过 Google Workspace 的授权 API 与 Gemini 的自然语言理解能力协同,用户可直接用日常语句…...

VLSI时代下74系列离散逻辑芯片的现代应用与设计实践
1. 从“胶水逻辑”到“系统粘合剂”:离散逻辑芯片的现代生存法则 在今天的数字电路设计领域,提起“7400系列”或者“74HC04”,很多年轻工程师的第一反应可能是博物馆里的古董,或者教科书上的历史章节。主流叙事已经被SoC、FPGA和高…...

如何快速掌握ComfyUI图像修复插件:终极完整使用指南
如何快速掌握ComfyUI图像修复插件:终极完整使用指南 【免费下载链接】comfyui-inpaint-nodes Nodes for better inpainting with ComfyUI: Fooocus inpaint model for SDXL, LaMa, MAT, and various other tools for pre-filling inpaint & outpaint areas. 项…...