Redis 做延迟消息队列
背景
看到消息队列,我们肯定会想到各种MQ,比如:RabbitMQ,acivityMQ、RocketMQ、Kafka等。
但是,当我们需要使用消息中间件的时候,并非每次都需要非常专业的消息中间件,假如我们只有一个消息队列,只有一个消费者,那就没有必要去使用上面这些专业的消息中间件,这种情况我们可以考虑使用 Redis 来做消息队列。
延迟消息队列使用场景
- 我们打车,在规定时间内,没有车主接单,那么平台就会推送消息给你,提示暂时没有车主接单。
- 网上支付场景,下单了,如果没有在规定时间付款,平台通常会发消息提示订单在有效期内没有支付完成,此订单自动取消之类的信息。
- 我们买东西,如果在一定时间内,没有对该订单进行评分,这时候平台会给一个默认分数给此订单。
.....
Redis如何实现消息队列?
大家都知道,Redis的五种数据类型,其中有一种类型是list。并且提供了相应的进入list的命令lpush和rpush ,以及弹出list的命令lpop和rpop。
这里我们就可以把List理解为一个消息队列,并且lpush和rpush操作称之为进入队列,同时,lpop和rpop称之为消息出队列。
命令
lpush
- 将一个或多个值 value 插入到列表 key 的表头
- 如果有多个 value 值,那么各个 value 值按从左到右的顺序依次插入到表头:比如说,对空列表 mylist 执行命令 LPUSH mylist a b c ,列表的值将是 c b a ,
- 这等同于原子性地执行 LPUSH mylist a 、 LPUSH mylist b 和 LPUSH mylist c 三个命令。
- 如果 key 不存在,一个空列表会被创建并执行 LPUSH 操作。
- 当 key 存在但不是列表类型时,返回一个错误。
使用案例:
rpush
- 将一个或多个值 value 插入到列表 key 的表尾(最右边)。
- 如果有多个 value 值,那么各个 value 值按从左到右的顺序依次插入到表尾:比如对一个空列表 mylist 执行 RPUSH mylist a b c ,得出的结果列表为 a b c ,等同于执行命令 RPUSH mylist a 、 RPUSH mylist b 、 RPUSH mylist c 。
- 如果 key 不存在,一个空列表会被创建并执行 RPUSH操作。
- 当 key 存在但不是列表类型时,返回一个错误。
使用案例:
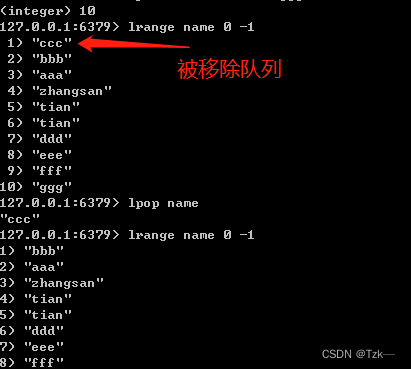
lpop
使用方式:lpop key。移除并返回列表 key 的头元素。如果key不存在,返回nil。
使用案例:
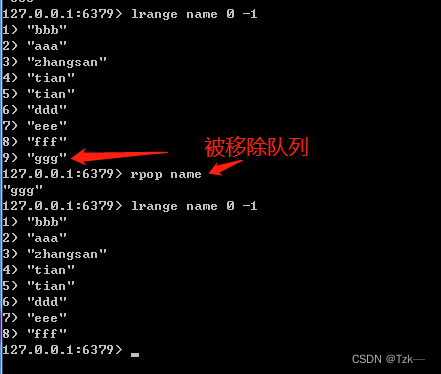
rpop
使用方式:rpop key,移除并返回列表 key 的尾元素。当 key 不存在时,返回 nil 。
使用案例:
以上四个命令是不是相当的简单呢,这里说一下lrange命令。
lrange
- 返回列表 key 中指定区间内的元素,区间以偏移量 start 和 stop 指定。
- 下标(index)参数 start 和 stop 都以 0 为底,也就是说,以 0 表示列表的第一个元素,以 1 表示列表的第二个元素,以此类推。
- 你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。
Redis实现消息队列
使用Spring Boot+Redis实现:
添加application.properties内容:
# Redis数据库索引(默认为0)
spring.redis.database=0
# Redis服务器地址
spring.redis.host=127.0.0.1
# Redis服务器连接端口
spring.redis.port=6379
# Redis服务器连接密码(默认为空)
spring.redis.password=
# 连接池最大连接数(使用负值表示没有限制)
spring.redis.jedis.pool.max-active=20
# 连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.jedis.pool.max-wait=-1
# 连接池中的最大空闲连接
spring.redis.jedis.pool.max-idle=10
# 连接池中的最小空闲连接
spring.redis.jedis.pool.min-idle=0
# 连接超时时间(毫秒)
spring.redis.timeout=1000
pom.xml中添加:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency>
创建一个RedisConfig类,对RedisTemplate做一些序列化的设置:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;@Configuration
public class RedisConfig {@Autowiredprivate RedisConnectionFactory redisConnectionFactory;@Beanpublic RedisTemplate<String, Object> redisTemplate() {RedisTemplate<String, Object> template = new RedisTemplate<String, Object>();template.setConnectionFactory(redisConnectionFactory);template.setKeySerializer(new StringRedisSerializer());template.setValueSerializer(new StringRedisSerializer());template.afterPropertiesSet();return template;}
}
创建RedisMQServicehe RedisMQServiceImpl
public interface RedisMQService {void produce(String string);void consume();
}
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;import javax.annotation.Resource;@Service
public class RedisMQServiceImpl implements RedisMQService {private static Logger log = LoggerFactory.getLogger(RedisMQServiceImpl.class);private static final String MESSAGE_KEY = "message:queue";@Resourceprivate RedisTemplate redisTemplate;@Overridepublic void produce(String string) {//生产者把消息丢到消息队列中redisTemplate.opsForList().leftPush(MESSAGE_KEY, string);}@Overridepublic void consume() {String string = (String) redisTemplate.opsForList().rightPop(MESSAGE_KEY);//消费方拿到消息后进行业务处理log.info("consume : {}", string);}
}
创建一个ccontroller
import com.tian.user.mq.RedisMQService;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RestController;import javax.annotation.Resource;@RestController
public class RedisMQController {@Resourceprivate RedisMQService redisMQService;@PostMapping("/produce")public String produce() {String[] names = {"java后端技术全栈", "老田", "面试专栏"};for (String name : names) {redisMQService.produce(name);}return "ok";}@PostMapping("/consume")public void consume() {int i = 0;while (i < 3) {redisMQService.consume();i++;}}
}
启动项目,访问:http://localhost:8080/produce生产者把三个消息丢到消息队列中。
在访问:http://localhost:8080/consume从消息队列中取出消息,然后就可以拿着消息继续做相关业务了。
后台输出:
到此,使用Redis实现消息队列就成功了。
但是,搞了半天只是使用Redis实现 了消息队列,那延迟呢?
上面并没有提到延迟队列的实现方式,下面我们来看看Redis中是如何实现此功能的。
Redis实现延迟消息队列的相关命令
延迟队列可以通过 zset 来实现,因为 zset 中有一个 score,我们可以把时间作为 score,将 value 存到 redis 中,然后通过轮询的方式,去不断的读取消息出来
整体思路
1.消息体设置有效期,设置好score,然后放入zset中
2.通过排名拉取消息
3.有效期到了,就把当前消息从zset中移除
我们来看看,zset有哪些命令:

可以通过网址:http://doc.redisfans.com/set/index.html 获取中文版Redis命令。
其实Redis实现延迟队列,只需要zset的三个命令即可。下面先来熟悉这三个命令。
zadd命令
使用方式:ZADD key score member [[score member][score member] ...]
- 将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
- 如果某个 member 已经是有序集的成员,那么更新这个 member 的 score 值,并通过重新插入这个 member 元素,来保证该 member 在正确的位置上。
- score 值可以是整数值或双精度浮点数。
- 如果 key 不存在,则创建一个空的有序集并执行 ZADD 操作。
- 当 key 存在但不是有序集类型时,返回一个错误。
- 在 Redis 2.4 版本以前, ZADD 每次只能添加一个元素。
使用案例:
ZRANGEBYSCORE命令
使用方式:ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
1.返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
2.具有相同 score 值的成员按字典序(lexicographical order)来排列(该属性是有序集提供的,不需要额外的计算)。
3.可选的 LIMIT 参数指定返回结果的数量及区间(就像SQL中的 SELECT LIMIT offset, count ),注意当 offset 很大时,定位 offset 的操作可能需要遍历整个有序集,此过程最坏复杂度为 O(N) 时间。
4.可选的 WITHSCORES 参数决定结果集是单单返回有序集的成员,还是将有序集成员及其 score 值一起返回。
注意:该选项自 Redis 2.0 版本起可用。
区间及无限
min 和 max 可以是 -inf 和 +inf ,这样一来,你就可以在不知道有序集的最低和最高 score 值的情况下,使用 ZRANGEBYSCORE这类命令。
默认情况下,区间的取值使用闭区间(小于等于或大于等于),你也可以通过给参数前增加 ( 符号来使用可选的开区间 (小于或大于)。
举个例子:
ZRANGEBYSCORE zset (1 5
返回所有符合条件 1 < score <= 5 的成员,而
ZRANGEBYSCORE zset (5 (10
则返回所有符合条件 5 < score < 10 的成员。
使用案例
ZREM命令
使用方式:ZREM key member [member ...]
移除有序集 key 中的一个或多个成员,不存在的成员将被忽略。
当 key 存在但不是有序集类型时,返回一个错误。
使用案例:
延迟队列可以通过Zset(有序列表实现),Zset类似于java中SortedSet和HashMap的结合体,它是一个Set结构,保证了内部value值的唯一,同时他还可以给每个value设置一个score作为排序权重,Redis会根据score自动排序,我们每次拿到的就是最先需要被消费的消息,利用这个特性我们可以很好实现延迟队列。
java代码实现
创建一个消息实体类:
import java.time.LocalDateTime;public class Message {/*** 消息唯一标识*/private String id;/*** 消息渠道 如 订单 支付 代表不同业务类型* 为消费时不同类去处理*/private String channel;/*** 具体消息 json*/private String body;/*** 延时时间 被消费时间 取当前时间戳+延迟时间*/private Long delayTime;/*** 创建时间*/private LocalDateTime createTime;// set get 省略
}
生产者方代码:
import com.tian.user.dto.Message;
import org.springframework.stereotype.Component;import javax.annotation.Resource;
import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
import java.util.UUID;@Component
public class MessageProvider {@Resourceprivate DelayingQueueService delayingQueueService;private static String USER_CHANNEL = "USER_CHANNEL";/*** 发送消息** @param messageContent*/public void sendMessage(String messageContent, long delay) {try {if (messageContent != null) {String seqId = UUID.randomUUID().toString();Message message = new Message();//时间戳默认为毫秒 延迟5s即为 5*1000long time = System.currentTimeMillis();LocalDateTime dateTime = Instant.ofEpochMilli(time).atZone(ZoneOffset.ofHours(8)).toLocalDateTime();message.setDelayTime(time + (delay * 1000));message.setCreateTime(dateTime);message.setBody(messageContent);message.setId(seqId);message.setChannel(USER_CHANNEL);delayingQueueService.push(message);}} catch (Exception e) {e.printStackTrace();}}
}
消费方代码:
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.tian.user.dto.Message;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.http.converter.json.Jackson2ObjectMapperBuilder;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;import javax.annotation.Resource;
import java.time.LocalDateTime;
import java.util.List;@Component
public class MessageConsumer {private static ObjectMapper mapper = Jackson2ObjectMapperBuilder.json().build();@Resourceprivate DelayingQueueService delayingQueueService;private Logger log = LoggerFactory.getLogger(this.getClass());/*** 定时消费队列中的数据* zset会对score进行排序 让最早消费的数据位于最前* 拿最前的数据跟当前时间比较 时间到了则消费*/@Scheduled(cron = "*/1 * * * * *")public void consumer() throws JsonProcessingException {List<Message> msgList = delayingQueueService.pull();if (null != msgList) {long current = System.currentTimeMillis();msgList.stream().forEach(msg -> {// 已超时的消息拿出来消费if (current >= msg.getDelayTime()) {try {log.info("消费消息:{}:消息创建时间:{},消费时间:{}", mapper.writeValueAsString(msg), msg.getCreateTime(), LocalDateTime.now());} catch (JsonProcessingException e) {e.printStackTrace();}//移除消息try {delayingQueueService.remove(msg);} catch (JsonProcessingException e) {e.printStackTrace();}}});}}
}
controller中的代码(或自写一个test类):
@RestController
public class RedisMQController { @Resourceprivate MessageProvider messageProvider; @PostMapping("/delay/produce")public String produce() { //延迟20秒messageProvider.sendMessage("同时发送消息1", 20);messageProvider.sendMessage("同时发送消息2", 20);return "ok";}
}
启动项目,访问:http://localhost:8080/delay/produce
后台消费者消费消息:
从输出日志中,可以看出,已经实现了延迟的功能。
自此,Redis实现延迟队列的功能就完成了。
实现延迟队列的其他方案
「RabbitMQ」 :利用 RabbitMQ 做延时队列是比较常见的一种方式,而实际上RabbitMQ自身并没有直接支持提供延迟队列功能,而是通过 RabbitMQ 消息队列的 TTL和 DXL这两个属性间接实现的。
「RocketMQ」 :RocketMQ 发送延时消息时先把消息按照延迟时间段发送到指定的队列中(rocketmq把每种延迟时间段的消息都存放到同一个队列中),然后通过一个定时器进行轮训这些队列,查看消息是否到期,如果到期就把这个消息发送到指定topic的队列中。
「Kafka」 :Kafka支持延时生产、延时拉取、延时删除等,其基于时间轮和 JDK 的 DelayQueue 实现 。
「ActiveMQ」 :需要延迟的消息会先存储在JobStore中,通过异步线程任务JobScheduler将到达投递时间的消息投递到相应队列上 。
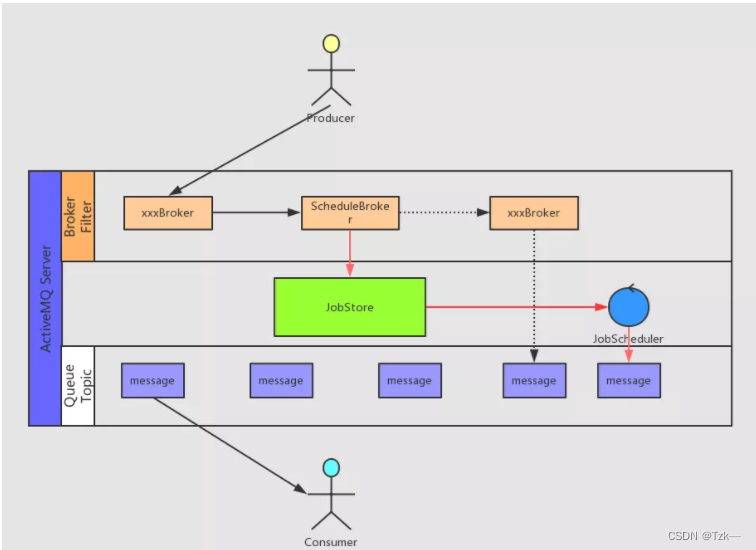
消息队列对比
总结
如果项目中仅仅是使用个别不是很重要的业务功能,可以使用Redis来做消息队列。但如果对消息可靠性有高度要求的话 ,建议从上面的其他方案中选一个相对合适的来实现。
相关文章:
Redis 做延迟消息队列
背景 看到消息队列,我们肯定会想到各种MQ,比如:RabbitMQ,acivityMQ、RocketMQ、Kafka等。 但是,当我们需要使用消息中间件的时候,并非每次都需要非常专业的消息中间件,假如我们只有一个消息队…...

刚果金FERI证书模板
FERI办理流程介(一)申请资料1:FERI APPLICATION FORM申请表格;2:草本海运提单(DRAFT B/L COPY);三:已盖章的商业发飘和箱单扫描件 (Commercial Invoice&Packing list)…...
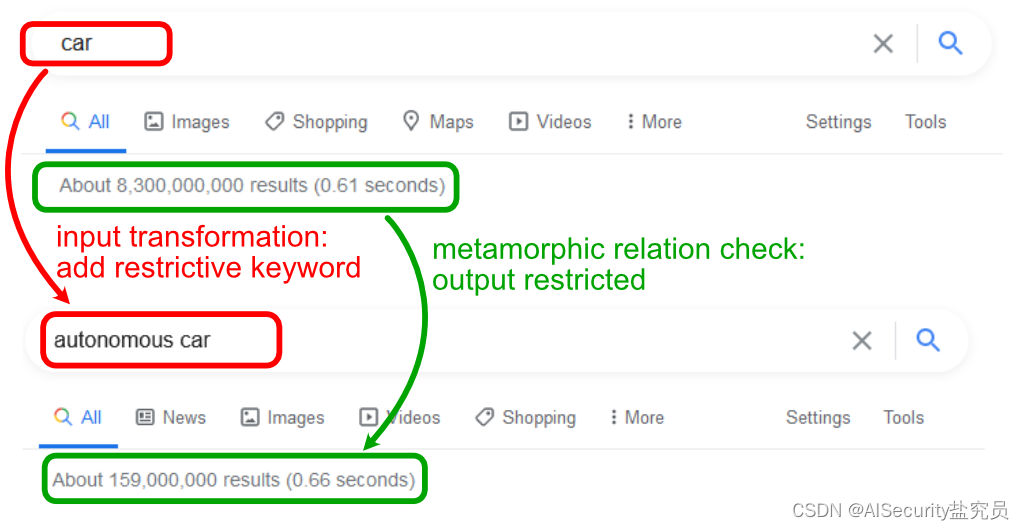
什么是蜕变测试?
文章目录1.传统测试2.蜕变测试2.1.蜕变测试的理解2.2.蜕变测试的步骤2.2.1.生成蜕变关系2.2.2.生成蜕变用例2.2.3.执行蜕变用例2.2.4.校验蜕变关系参考文献1.传统测试 在没有蜕变测试的时代,传统软件测试的原理是:给定输入,观察被测软件的输…...

74. ‘pip‘不是内部或外部命令,也不是可运行的程序-解决办法
74. pip’不是内部或外部命令,也不是可运行的程序-解决办法 文章目录74. pip不是内部或外部命令,也不是可运行的程序-解决办法1. 课题导入2. 手动配置环境变量1. 准备工作2. 配置步骤3. 命令行安装1. 课题导入 有的同学在使用pip安装第三方库时…...
- 初始化和控制MIL应用程序的执行环境)
MIL图像处理那些事:应用程序模块(Mapp)- 初始化和控制MIL应用程序的执行环境
提示:本系列文章通过示例详细介绍MIL图像处理的基础知识及相关操作,让给你快速学会使用MIL进行图像处理 文章目录 前言初始化Mil环境MappAllocMappAllocDefault计时MappTimer异常处理打开和关闭 Mil 异常提示C# try...catch回调函数MappHookFunction查询MappInquire文件操作Ma…...

Pytorch基础语法学习2——argparse模块
一、基本介绍 argparse 模块是 Python 内置的用于命令行参数解析的模块,可以通过少数代码中变量或者参数的改变以实现对整个代码项目的操控。对于大型代码项目(如代码超过1000行),十分便捷 argparse 模块可以让人轻松编写用户友好的命令行接口…...
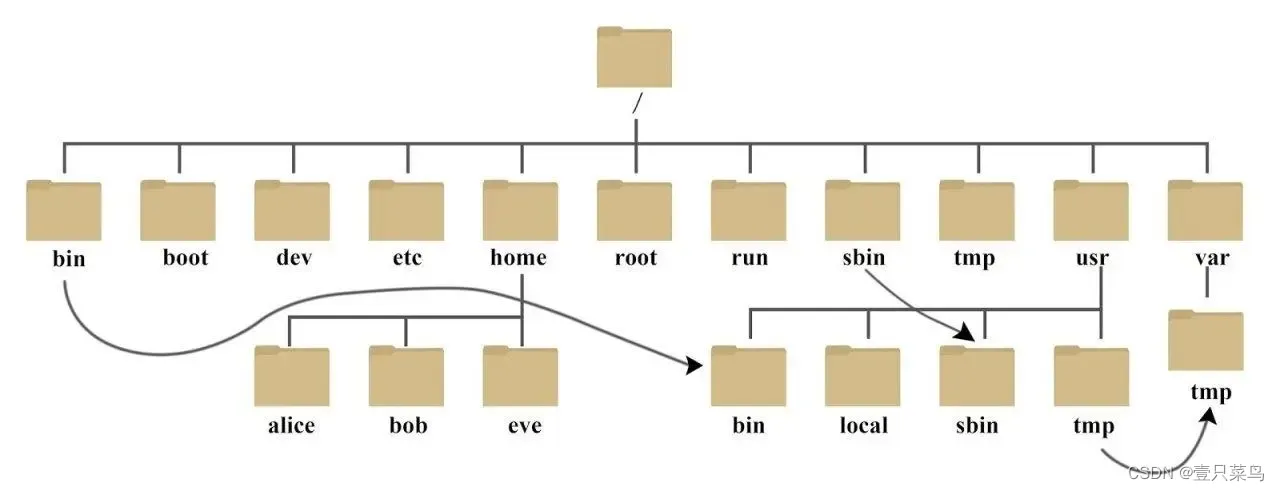
CHAPTER 2 目录及文件
目录及文件1 目录1.1 目录结构1.2 核心目录2 文件2.1 /etc/中的文件2.1.1 修改主机名(/etc/hostname)2.1.2 网卡配置文件2.1.3 开机自启动配置文件(/etc/rc.local)2.1.4 /etc/motd和/etc/issue2.2 /var/中的文件2.3 /proc/中的文件2.3.1 CPU信息(lscpu)3 文件类型3.1 类型说明3…...
 T1最终测试)
2021牛客OI赛前集训营-提高组(第四场) T1最终测试
2021牛客OI赛前集训营-提高组(第四场) 题目大意 有nnn个选手参加比赛,比赛有两道题。 对于第一题,第iii个选手有50%50\%50%的可能拿到ai,1a_{i,1}ai,1分,有50%50\%50%的可能拿到000分。 对于第二题,第…...

【华为OD机试2023】租车骑绿岛 C++ Java Python
【华为OD机试2023】租车骑绿岛 C++ Java Python 前言 如果您在准备华为的面试,期间有想了解的可以私信我,我会尽可能帮您解答,也可以给您一些建议! 本文解法非最优解(即非性能最优),不能保证通过率。 Tips1:机试为ACM 模式 你的代码需要处理输入输出,input/cin接收输入…...

05-路由中的Hook
hook中使用 this.props中的路由 类组件中我们通过 this.props 获取到的关于路由的相关方法和数据,在函数组件中还是可以继续通过参数 props 来获取使用: export default function Login(prosp) {return (<button onClick{() > {props.history.pu…...

Ubuntu20.04 源码编译安装SRS-6流媒体服务器,开启GB28181支持
1. 下载SRS源码 直接从仓库clone git clone -b develop https://gitee.com/ossrs/srs.git 2. 编译源码 此处通过 --gb28181on 开启GB28181支持,默认是不开启的 cd srs/trunk && ./configure --gb28181on && make -j4 3. 编译过程中遇到的问题 …...
Web前端学习:六 -- 练习小总结
1、背景颜色透明度写法: background:rgba(R,G,B,Alpha透明度) 透明度范围:0–1,1完全不透明,0完全透明 2、伪类 hovar: 当鼠标接触该元素是,显示另一种样…...
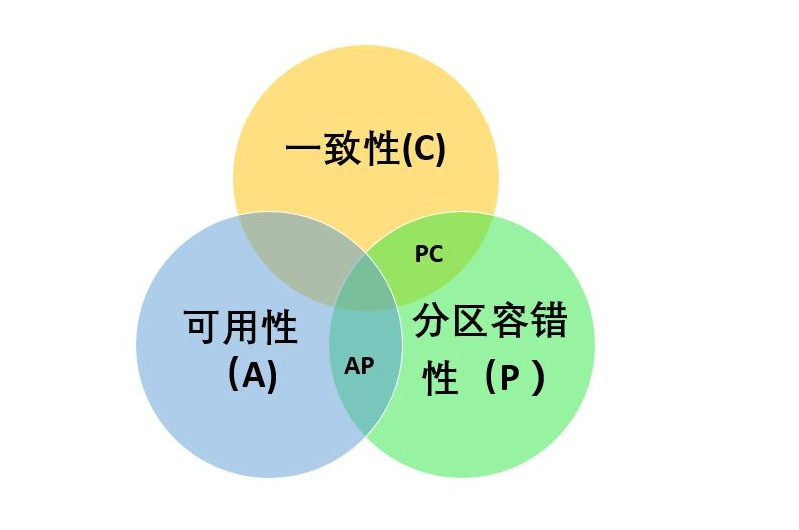
微服务之 CAP原则
文章目录微服务CAP原则AC 可用性 一致性CP 一致性 分区容错性AP 可用性 分区容错性提示:以下是本篇文章正文内容,SpringCloud系列学习将会持续更新 微服务CAP原则 经过前面的学习,我们对 SpringCloud Netflix 以及 SpringCloud 官方整个生…...
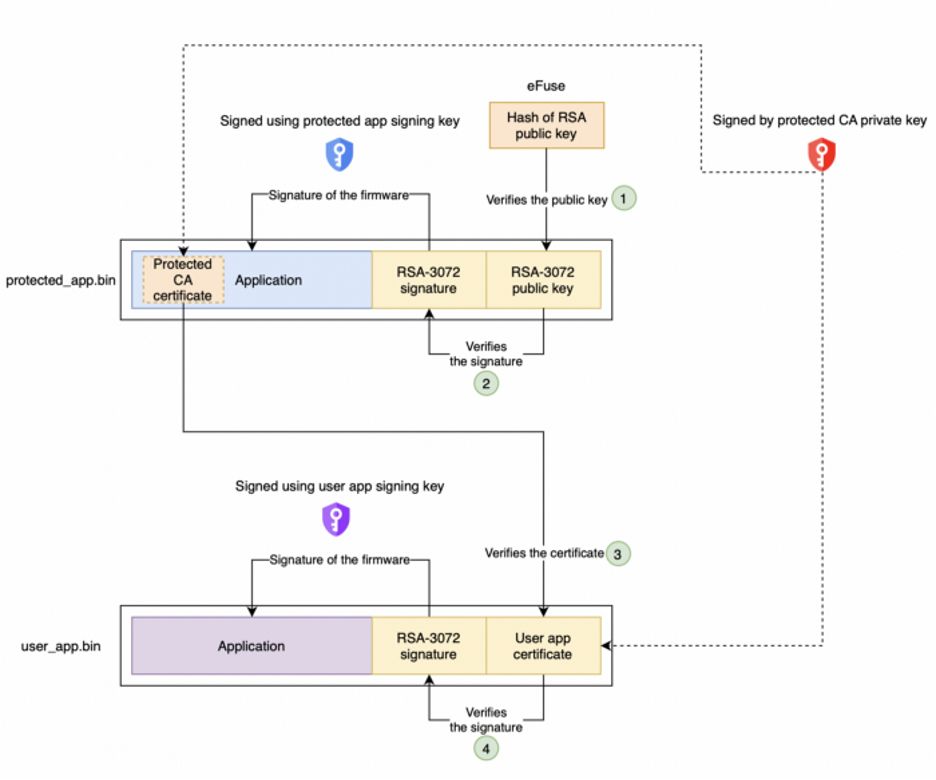
乐鑫特权隔离机制 #4 | 用户应用程序的安全启动
乐鑫特权隔离机制 系列文章 #4 目录 安全启动 (Secure boot) 受保护应用程序的安全启动 (Secure boot for protected app ) 用户应用程序的安全启动 (Secure boot for user app) 基于证书的验证方案 (Certificate-based verification scheme) 必要条件验证过程…...
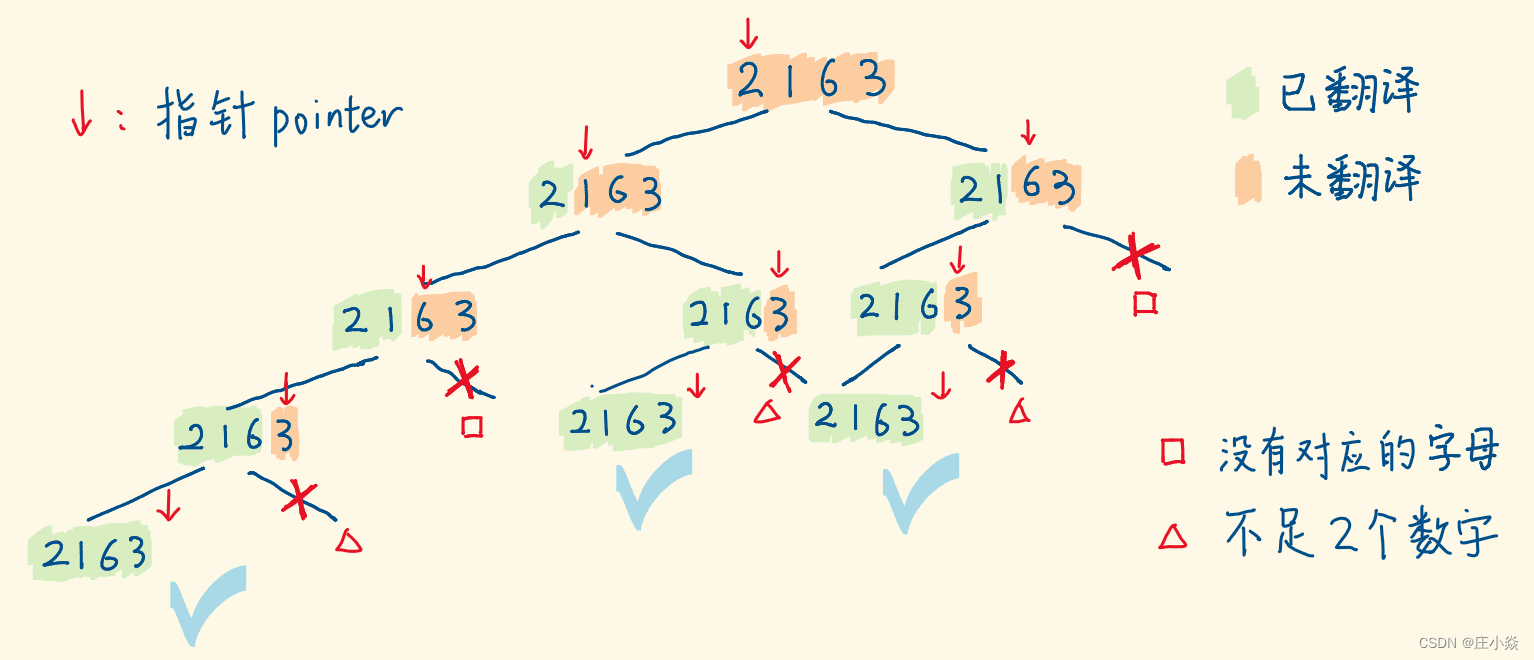
剑指 Offer 46. 把数字翻译成字符串
摘要 剑指 Offer 46. 把数字翻译成字符串 一、递归算法解析 给定一个数字,我们按照如下规则把它翻译为字符串:0 翻译成 “a” ,1 翻译成 “b”,……,11 翻译成 “l”,……,25 翻译成 “z”。…...

tar命令——归档/压缩和解压缩文件
tar命令的功能是将一个或多个文件归档成一个文件,同时可结合gzip、bzip2和xz等压缩命令实现文件的压缩和解压缩。 tar 命令的语法格式如下: tar [选项] 文件或目录 常用选项如下: 选项作用/含义-c建立归档文件-x从归档文件中解出文件-z通…...

Softing smartLink网关——推进过程工业数字化转型
虽然在过程工业中各工厂所投入的运营时间千差万别,但仍需按照新标准来进行有效控制和管理,而这就需要使用一种能够聚合其异构数据的数字通信架构。对此,Softing提供了两种网关解决方案,可用于将过程工业通信架构集成到现有以太网系…...

Spark的常用算子
Spark的常用算子 目录内容Spark的常用算子一、转换算子(Transformation)二、行动算子(Action)三、键值对算子(PairRDDFunctions)四、文件系统算子(File System)Spark 内置算子是指 S…...
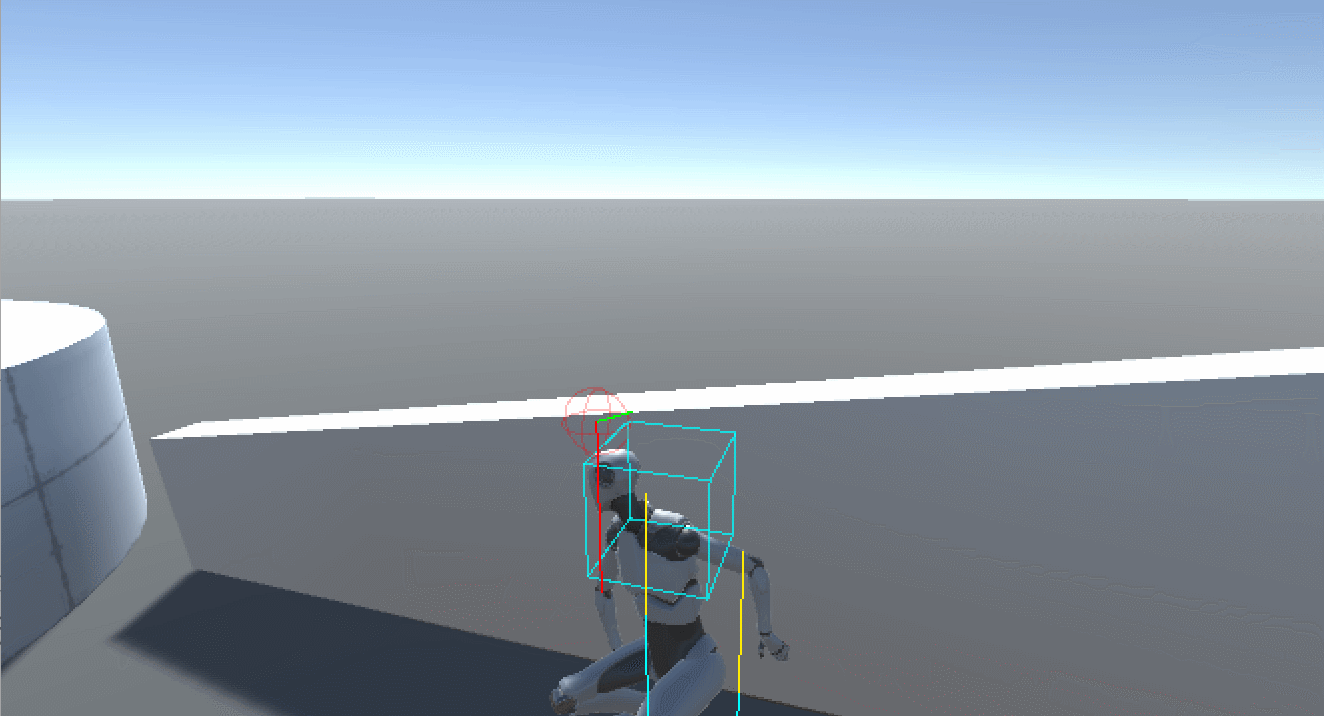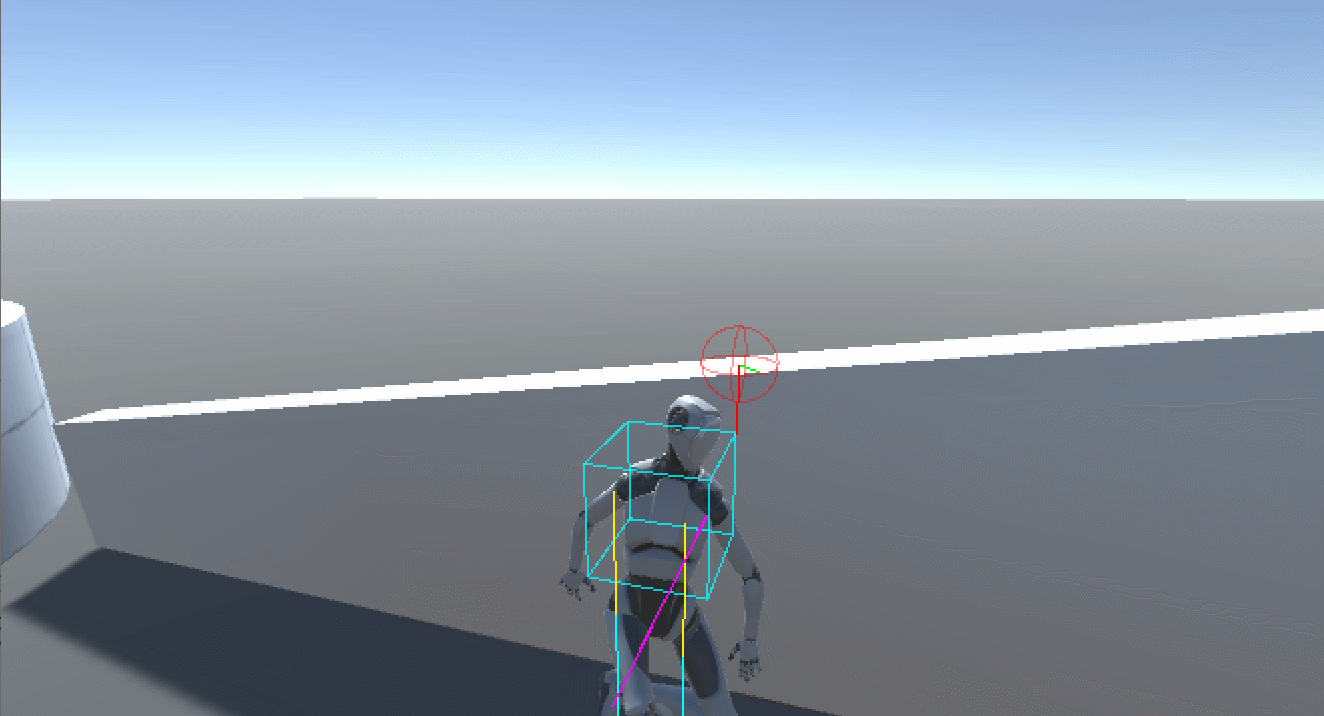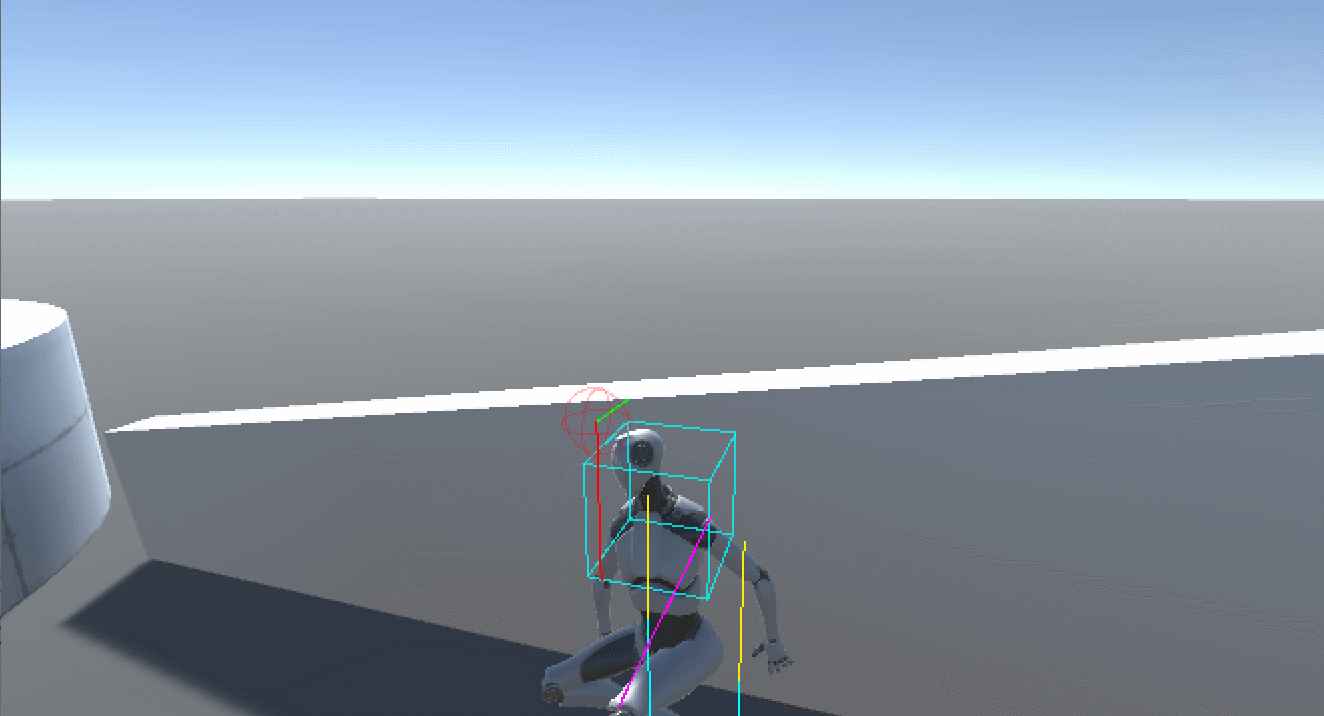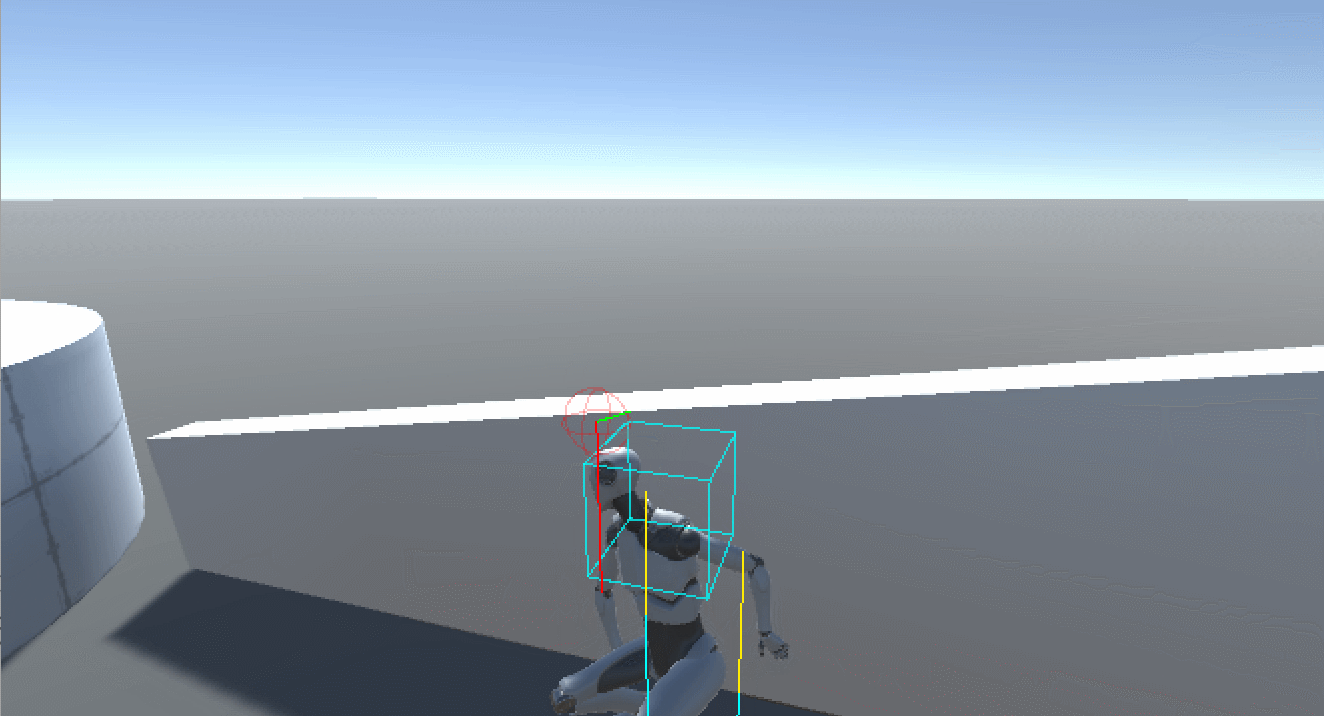
Unity Avatar Cover System - 如何实现一个Avatar角色的智能掩体系统
文章目录简介变量说明实现动画准备动画状态机State 状态NoneStand To CoverIs CoveringCover To Stand高度适配高度检测脚部IK简介 本文介绍如何在Unity中实现一个Avatar角色的智能掩体系统,效果如图所示: 初版1.0.0代码已上传至SKFramework框架Package…...

steam/csgo搬砖项目到底真的假的?
搬砖是从国外steam市场置办游戏装备回来,在国内网易buff售卖,低买高卖,产生利润的一个项目。 但我真正上手后,才知道steam是面向全球的游戏平台,用户真的大的夸张!!市场非常巨大,一…...

STM32模拟I2C驱动PCF8591避坑指南:为什么你的AD/DA数据总在跳?
STM32模拟I2C驱动PCF8591避坑指南:为什么你的AD/DA数据总在跳? 调试STM32与PCF8591的模拟I2C通信时,AD/DA数据跳动是开发者最常遇到的棘手问题。本文将深入分析数据不稳定的根源,并提供一套完整的解决方案。不同于基础教程&#x…...

3步解锁游戏窗口任意分辨率:SRWE终极使用指南
3步解锁游戏窗口任意分辨率:SRWE终极使用指南 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾经遇到过这样的情况:想用游戏截图制作精美的壁纸,却发现游戏内置的分辨…...

为什么Windows用户需要APK安装器?三大场景解决你的跨平台痛点
为什么Windows用户需要APK安装器?三大场景解决你的跨平台痛点 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经遇到过这样的困境:在电…...

3分钟掌握微信聊天记录永久保存:从数据备份到智能分析完全攻略
3分钟掌握微信聊天记录永久保存:从数据备份到智能分析完全攻略 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/…...
,让开源检索进入“所想即所得”时代)
别再Ctrl+F GitHub了!Perplexity高级提示词工程(含18个已验证模板),让开源检索进入“所想即所得”时代
更多请点击: https://intelliparadigm.com 第一章:Perplexity GitHub资源检索的范式革命 从关键词匹配到语义理解的跃迁 传统 GitHub 搜索依赖精确的仓库名、文件路径或正则表达式,而 Perplexity 引入的 LLM 驱动检索将自然语言查询&#x…...

Nevis‘22基准:评估持续学习模型的计算效率与知识迁移能力
1. 项目概述:为什么我们需要一个全新的终身学习基准?在计算机视觉乃至整个机器学习领域,我们正面临一个日益尖锐的矛盾:一方面,我们希望模型能够像人类一样,在漫长的时间里持续学习新知识,不断进…...
)
不止于建模:用COMSOL几何操作优化你的仿真效率(分隔、二维轴对称实战)
不止于建模:用COMSOL几何操作优化你的仿真效率 在工程仿真领域,几何建模往往被视为前期准备工作,但真正的高手知道:建模阶段的每一个决策都会在后续网格划分和求解过程中产生指数级影响。我们曾对比过两个相似的电机散热模型——一…...

Jellyfin.Plugin.MetaShark配置详解:10个关键设置优化你的元数据刮削体验
Jellyfin.Plugin.MetaShark配置详解:10个关键设置优化你的元数据刮削体验 【免费下载链接】jellyfin-plugin-metashark jellyfin电影元数据插件 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-plugin-metashark 想要让你的Jellyfin媒体库拥有丰富的…...
)
物联网项目实战:在Ubuntu 20.04上快速部署Mosquitto MQTT Broker(含客户端测试)
物联网开发实战:Ubuntu 20.04下Mosquitto MQTT Broker的高效部署与全链路测试 在智能家居和工业物联网项目中,设备间的实时通信往往面临网络不稳定、硬件资源有限等挑战。MQTT协议凭借其轻量级和发布/订阅模式,成为连接传感器与云端的最优解。…...

ExifToolGUI:如何轻松批量管理照片元数据的完整指南
ExifToolGUI:如何轻松批量管理照片元数据的完整指南 【免费下载链接】ExifToolGui A GUI for ExifTool 项目地址: https://gitcode.com/gh_mirrors/ex/ExifToolGui 你是否曾经面对成百上千张照片,想要批量修改拍摄时间、添加版权信息或调整GPS坐标…...