Python爬取公众号封面图(零基础也能看懂)
📚博客主页:knighthood2001
✨公众号:认知up吧 (目前正在带领大家一起提升认知,感兴趣可以来围观一下)
🎃知识星球:【认知up吧|成长|副业】介绍
❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更新的动力❤️
🙏笔者水平有限,欢迎各位大佬指点,相互学习进步!
需求:平时一些公众号文章封面图比较好,想获取一下。因此写了这个脚本。
前言
打开一篇公众号,右键,查看网页源代码

其中,你可以通过ctrl+F进行关键字搜索。
msg_cdn_url对应的链接就是微信公众号封面图,比如

cdn_url_1_1对应的链接就是没有裁剪的公众号封面图,比如

可以发现cdn_url_1_1对应的链接图片资源完整一些。
因此我选择爬取这个图片,也就是找cdn_url_1_1所对应的网址。
爬取思路
- 首先,图片是以网址形式给出,因此需要从网址中把图片保存为本地文件。
- 其次,我需要从网页源代码中筛选出该网址,可以使用
re正则表达式进行该操作。
预备知识
可以先看一下我写的这两篇文章,因为代码都是逐渐往上加内容,才实现最终功能的,你可以理解为搭积木。
Python爬取网页源代码(自用)
Python下载爬取到的图片链接
Python获取当前时间戳
通过正则表达式筛选内容
除了以上内容,下面代码是今天要学的,其功能就是正则表达式获取公众号封面图所在的网址,通过查找网页源代码,cdn_url_1_1只出现了一次,因此可以直接通过re模块进行筛选。
import requests
import re
# 定义目标网页的URL
url = 'https://mp.weixin.qq.com/s/d7DUHB-hT8DExjpxsEncQw'# 发送GET请求获取网页内容
response = requests.get(url)# 检查响应状态码,200表示请求成功
if response.status_code == 200:# 输出网页源代码print(response.text)# 定义包含目标网址的字符串source_code = response.text# 使用正则表达式提取网址# url_pattern = re.compile(r'cdn_url_1_1\s*=\s*"(.*?)"')url_pattern = re.compile(r'cdn_url_1_1 = "(.*?)"')matches = url_pattern.findall(source_code)# 输出提取到的网址if matches:print(matches[0])else:print("No URL found.")
matches返回的是一个列表,因此需要添加[0],表示取第一个。运行结果如下,返回的就是公众号封面的图片网址。
https://mmbiz.qpic.cn/sz_mmbiz_jpg/n3WJwMGdIpnGSMHew0kcnsEk8Y9icBG8EBh8ib6qBBZmJR8DgkZookgGWVuibTgsUrIPiatfiafNI8N1dR4uhI086UA/0?wx_fmt=jpeg
本文正则表达式的解释
此外,对于这个正则表达式 cdn_url_1_1\s*=\s*"(.*?)" 可以分为几个部分来解释:
cdn_url_1_1:匹配字符串中的cdn_url_1_1,它是要匹配的目标字符串的一部分。\s*:匹配零个或多个空白字符,包括空格、制表符、换行符等。=:匹配一个等号字符。\s*:再次匹配零个或多个空白字符。":匹配一个双引号字符。双引号是开始网址的标记。(.*?):这是一个捕获组,用于捕获双引号内的内容。.*?匹配任意字符(除换行符外)零次或多次,非贪婪模式,即匹配到第一个双引号结束。":再次匹配一个双引号字符。双引号是结束网址的标记。
因此,整个正则表达式的作用是匹配形如 cdn_url_1_1 = "..." 这样的字符串,并捕获其中双引号内的网址部分。
为了更加简单,你也可以写成cdn_url_1_1 = "(.*?)"。
全文代码
通过搭积木的方式,将以上代码整合起来,具体代码如下:
import requests
import re
import os
#TODO 使用时间戳当作文件名称
def get_time():import timetimestamp = int(time.time())return timestamp
#TODO 实现从网页图片保存到本地,输入为图片网址和保存路径
def image_save(image_url, path):if not os.path.exists(path): # 如果文件夹不存在,则创建os.makedirs(path)# 发送 GET 请求获取图片数据response = requests.get(image_url)# 确保请求成功if response.status_code == 200:image_name = get_time()image_name = "{}.jpg".format(image_name)# 指定图片保存路径save_path = os.path.join(path, image_name) # 这里将图片保存在名为 images 的文件夹中# 将图片数据写入文件with open(save_path, 'wb') as f:f.write(response.content)print(f'图片已保存为: {save_path}')else:print(f'下载图片失败,状态码: {response.status_code}')# 定义目标网页的URL
url = 'https://mp.weixin.qq.com/s/d7DUHB-hT8DExjpxsEncQw'# 发送GET请求获取网页内容
response = requests.get(url)# 检查响应状态码,200表示请求成功
if response.status_code == 200:# 输出网页源代码print(response.text)# 定义包含目标网址的字符串source_code = response.text# 使用正则表达式提取网址# url_pattern = re.compile(r'cdn_url_1_1\s*=\s*"(.*?)"')url_pattern = re.compile(r'cdn_url_1_1 = "(.*?)"')matches = url_pattern.findall(source_code)# 输出提取到的网址if matches:print(matches[0])image_save(matches[0], "images")else:print("No URL found.")else:# 如果请求失败,打印错误信息print('Failed to retrieve webpage:', response.status_code)
最后,可以将其封装为函数,方便调用。
import requests
import re
import os
#TODO 使用时间戳当作文件名称
def get_time():import timetimestamp = int(time.time())return timestamp
#TODO 实现从网页图片保存到本地,输入为图片网址和保存路径
def image_save(image_url, path):if not os.path.exists(path): # 如果文件夹不存在,则创建os.makedirs(path)# 发送 GET 请求获取图片数据response = requests.get(image_url)# 确保请求成功if response.status_code == 200:image_name = get_time()image_name = "{}.jpg".format(image_name)# 指定图片保存路径save_path = os.path.join(path, image_name) # 这里将图片保存在名为 images 的文件夹中# 将图片数据写入文件with open(save_path, 'wb') as f:f.write(response.content)print(f'图片已保存为: {save_path}')else:print(f'下载图片失败,状态码: {response.status_code}')# 定义目标网页的URL
url = 'https://mp.weixin.qq.com/s/d7DUHB-hT8DExjpxsEncQw'
# TODO 微信公众号获取封面并保存,输入网址
def get_image(wechat_url):response = requests.get(wechat_url)# 检查响应状态码,200表示请求成功if response.status_code == 200:# 定义包含目标网址的字符串source_code = response.text# 使用正则表达式提取网址url_pattern = re.compile(r'cdn_url_1_1 = "(.*?)"')matches = url_pattern.findall(source_code)# 输出提取到的网址if matches:print(matches[0])image_save(matches[0], "images")else:print("No URL found.")else:# 如果请求失败,打印错误信息print('Failed to retrieve webpage:', response.status_code)get_image(url)
最后结果如下:

相关文章:
Python爬取公众号封面图(零基础也能看懂)
📚博客主页:knighthood2001 ✨公众号:认知up吧 (目前正在带领大家一起提升认知,感兴趣可以来围观一下) 🎃知识星球:【认知up吧|成长|副业】介绍 ❤️感谢大家点赞👍&…...

2024.4.6学习笔记
今日学习韩顺平java0200_韩顺平Java_对象机制练习_哔哩哔哩_bilibili 今日学习p315-p328 动态绑定机制 当调用方法对象的时候,该方法会和该对象的内存地址/运行类型绑定 当调用对象属性时,没有动态绑定机制,哪里声明,哪里使用 …...
)
2024年华为OD机试真题-查找一个有向网络的头节点和尾节点-Java-OD统一考试(C卷)
题目描述: 给定一个有向图,图中可能包含有环,图使用二维矩阵表示,每一行的第一列表示起始节点,第二列表示终止节点,如[0, 1]表示从0到1的路径。每个节点用正整数表示。求这个数据的首节点与尾节点,题目给的用例会是一个首节点,但可能存在多个尾节点。同时,图中可能含有…...
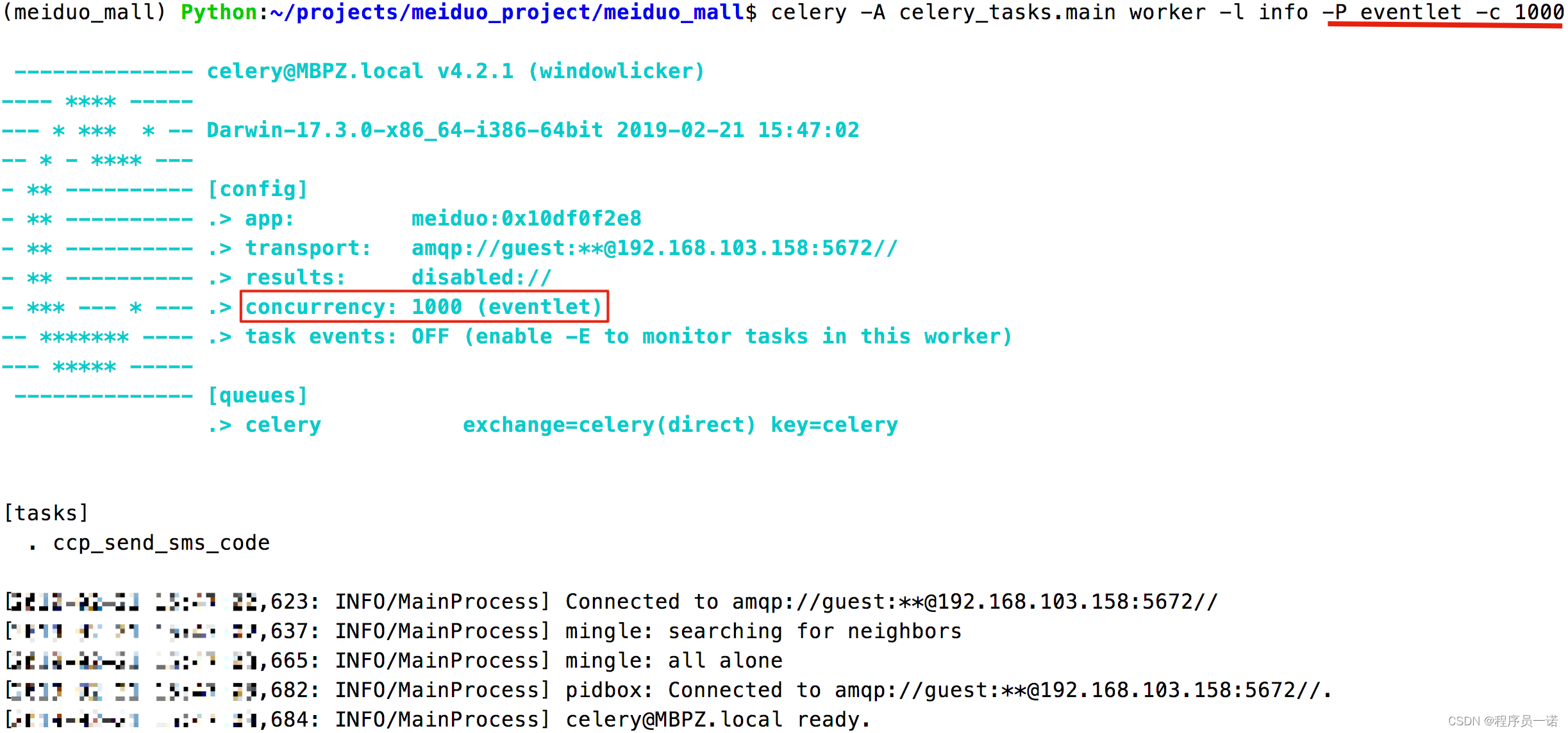
【Django开发】0到1美多商城项目md教程第5篇:短信验证码,1. 避免频繁发送短信验证码逻辑分析【附代码文档】
美多商城完整教程(附代码资料)主要内容讲述:欢迎来到美多商城!,项目准备。展示用户注册页面,创建用户模块子应用。用户注册业务实现,用户注册前端逻辑。图形验证码,图形验证码接口设…...
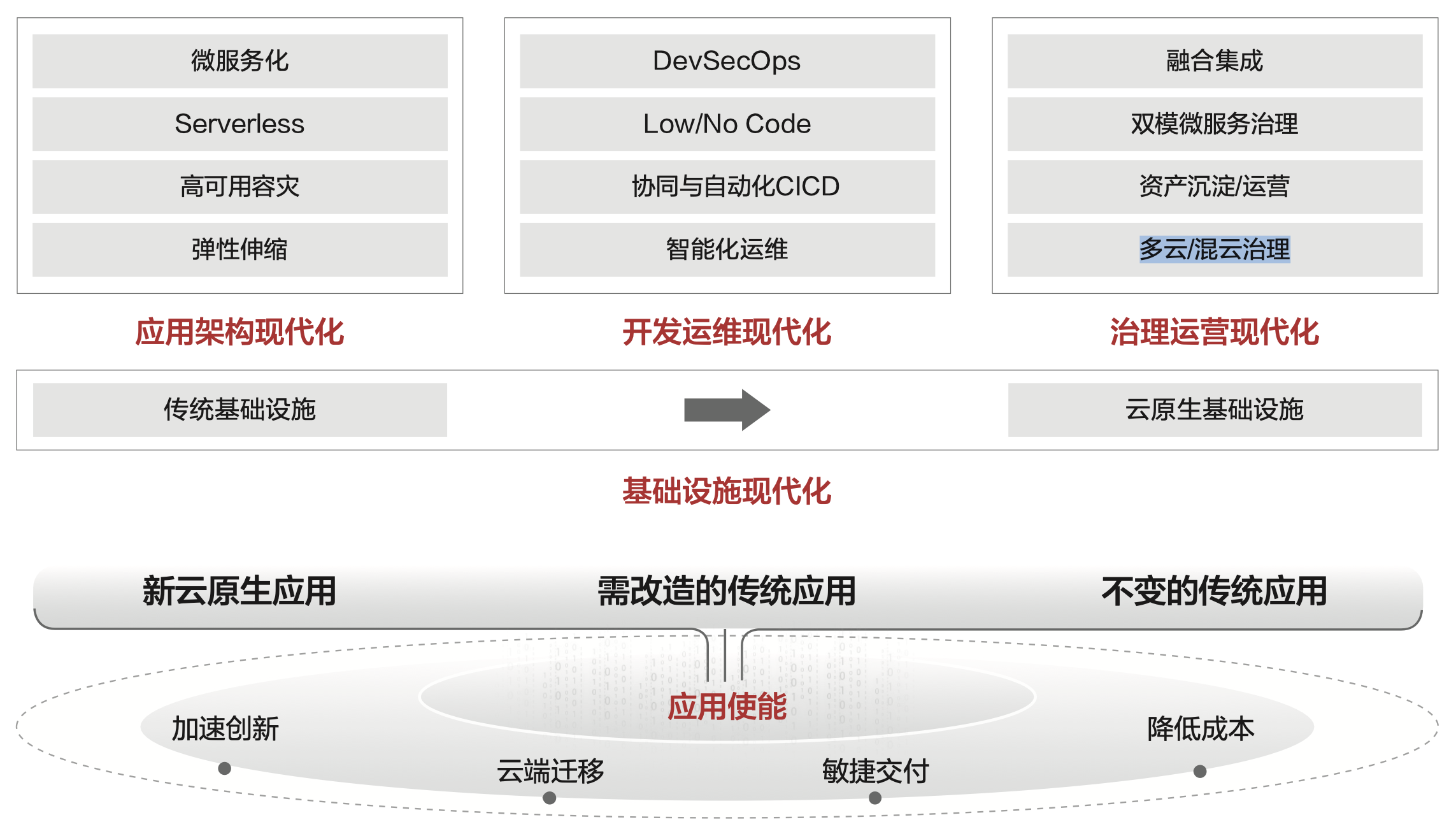
云原生:应用敏捷,华为视角下的应用现代化
Gartner 也提出,到 2023 年,新应用新服务的数量将达到 5 亿,也即是说:“每个企业都正在成为软件企业”。据IDC 预测,到 2025 年三分之二的企业将成为多产的“软件企业”,每天都会发布软件版本。越来越多的企…...
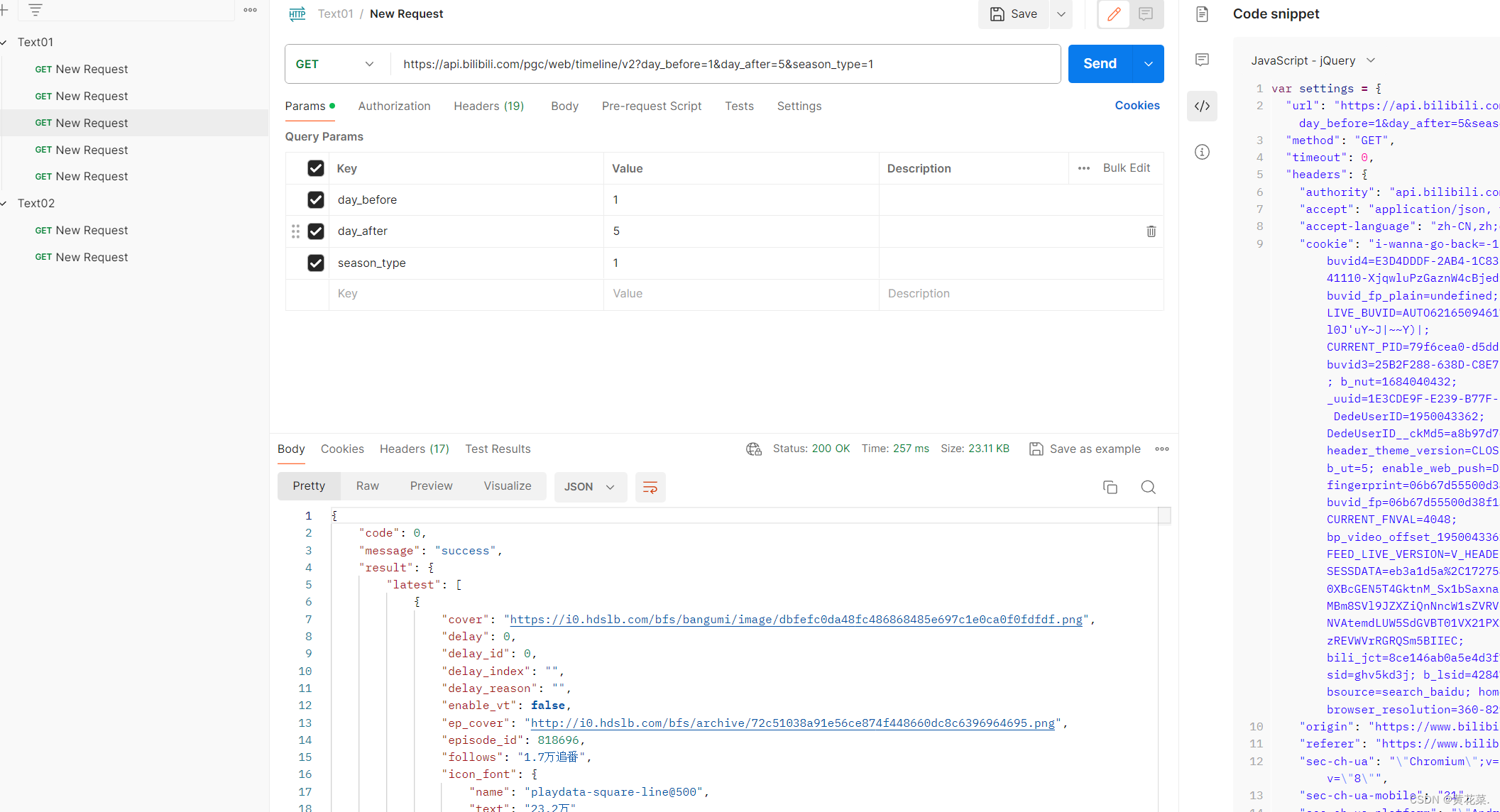
【测试篇】接口测试
接口测试,可以用可视化工具 postman。 如何做接口测试?? 我们可以先在浏览器中随机进入一个网页,打开开发者工具(F12)。 随便找一个接口Copy–>Copy as cURL(bash) 打开postman 复制地址 进行发送。 …...
突破校园网限速:使用 iKuai 多拨分流负载均衡 + Clash 代理(内网带宽限制通用)
文章目录 1. 简介2. iKuai 部署2.1 安装 VMware2.2 安装 iKuai(1) 下载固件(2) 安装 iKuai 虚拟机(3) 配置 iKuai 虚拟机(4) 配置 iKuai(5) 配置多拨分流 2.3 测试速度 3. Clash 部署(1) 配置磁盘分区(2) 安装 Docker(3) 安装 Clash(4) 设置代理 4. 热点:一起瓜分互…...

03-JAVA设计模式-工厂模式详解
工厂模式 工厂设计模式是一种创建型设计模式,它提供了一种封装对象创建过程的机制,将对象的创建与使用分离。 这种设计模式允许我们在不修改客户端代码的情况下引入新的对象类型。 在Java中,工厂设计模式主要有三种形式:简单工厂…...

百度文心大模型推理成本降至1% / 马斯克起诉OpenAI |魔法半周报
我有魔法✨为你劈开信息大海❗ 高效获取AIGC的热门事件🔥,更新AIGC的最新动态,生成相应的魔法简报,节省阅读时间👻 🔥资讯预览 百度文心大模型推理成本降至1%,与三星、荣耀等企业达成合作 马斯…...
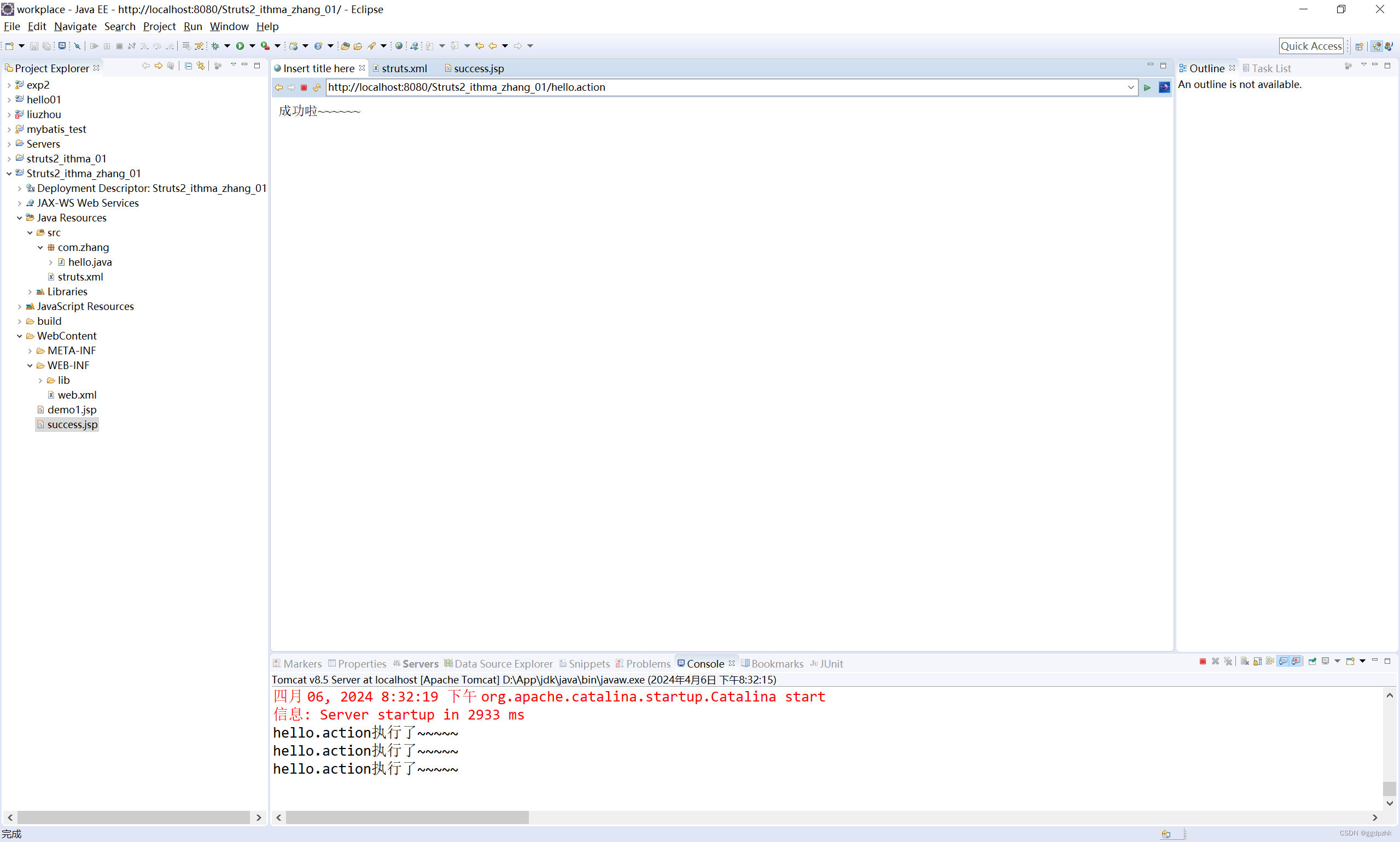
Struts2的入门:新建项目——》导入jar包——》jsp,action,struts.xml,web.xml——》在项目运行
文章目录 配置环境tomcat 新建项目导入jar包新建jsp界面新建action类新建struts.xml,用来配置action文件配置Struts2的核心过滤器:web.xml 启动测试给一个返回界面在struts.xml中配置以实现页面的跳转:result再写个success.jsp最后在项目运行 配置环境 …...

git 标签功能操作以及回退
Git 标签功能允许开发者为特定的提交打上标签,以便后续能够方便地引用这些提交。标签通常用于标记重要的版本或里程碑,例如软件发布的版本号。与分支不同,标签指向的是固定的提交,一旦设置,就不能轻易更改。下面是一些…...

利用python实现文字转语音
代码如下: import pathlib import tkinter as tk import tkinter.ttk as ttk import tkinter.filedialog as filedialog import tkinter.messagebox as msgbox import pyttsx3class Application(tk.Tk):def __init__(self):super().__init__()self.title("文本…...

拾光坞N3 ARM 虚拟主机 i茅台项目
拾光坞N3 在Dcoker部署i茅台案例 OS:Ubuntu 22.04.1 LTS aarch64 cpu:RK3566 ram:2G 部署流程——》mysql——》java8——》redis——》nginx mysql # 依赖 apt update apt install -y net-tools apt install -y libaio* # 下载mysql wg…...
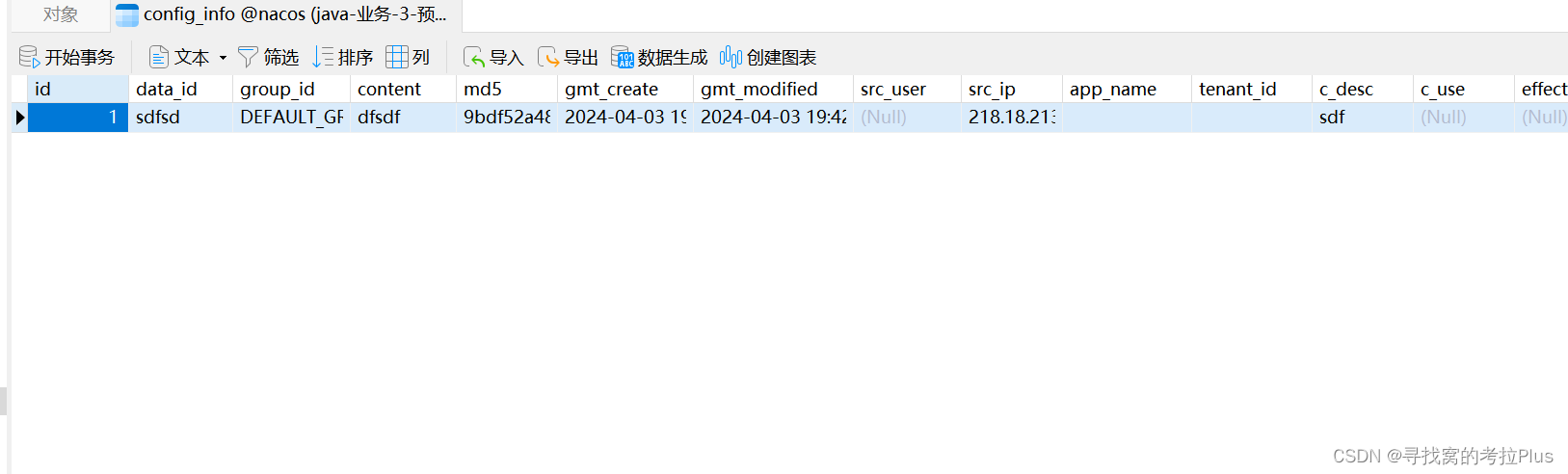
docker安装nacos,单例模式(standalone),使用mysql数据库
文章目录 前言安装创建文件夹"假装"安装一下nacos拷贝文件夹删除“假装”安装的nacos容器生成nacos所需的mysql表获取mysql-schema.sql文件创建一个mysql的schema 重新生成新的nacos容器 制作docker-compose.yaml文件查看网站 前言 此处有本人写得简易版本安装&…...
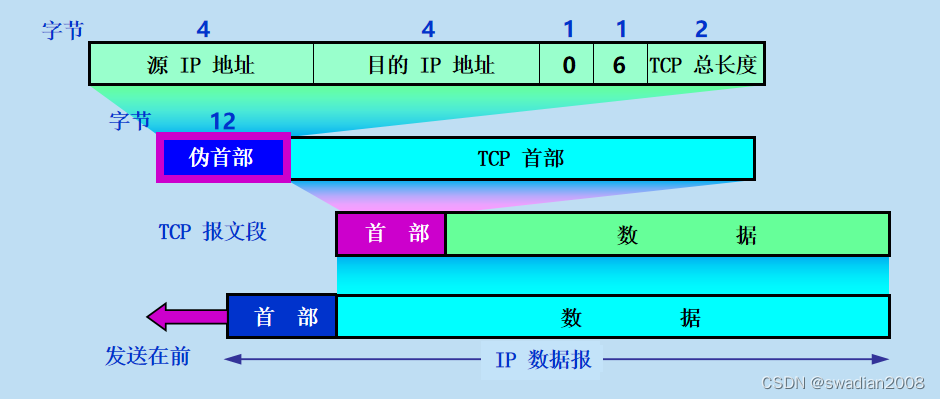
【运输层】传输控制协议 TCP
目录 1、传输控制协议 TCP 概述 (1)TCP 的特点 (2)TCP 连接中的套接字概念 2、可靠传输的工作原理 (1)停止等待协议 (2)连续ARQ协议 3、TCP 报文段的首部格式 1、传输控制协议…...

深入浅出 -- 系统架构之Keepalived搭建双机热备
Keepalived重启脚本双机热备搭建 ①首先创建一个对应的目录并下载keepalived安装包(提取码:s6aq)到Linux中并解压: [rootlocalhost]# mkdir /soft/keepalived && cd /soft/keepalived [rootlocalhost]# wget https://www.keepalived.…...

如何做好产业园运营?树莓集团:响应政府号召,规划,注重大局观
随着经济的发展和产业结构的调整,产业园区的建设和发展已经成为推动地方经济的重要力量。如何做好产业园运营,提高行业竞争力,现已成为了一个亟待解决的问题。树莓集团作为一家有着丰富产业园运营经验的企业,积极响应政府号召&…...

NIO与BIO
当谈到 Java 网络编程时,经常会听到两个重要的概念:BIO(Blocking I/O,阻塞 I/O)和 NIO(Non-blocking I/O,非阻塞 I/O)。它们都是 Java 中用于处理 I/O 操作的不同编程模型。 一、介…...
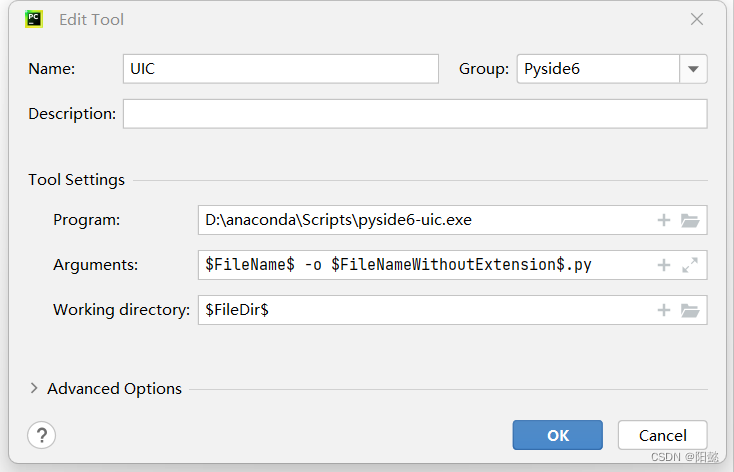
YOLOv5实战记录05 Pyside6可视化界面
个人打卡,慎看。 指路大佬:【手把手带你实战YOLOv5-入门篇】YOLOv5 Pyside6可视化界面_哔哩哔哩_bilibili 零、虚拟环境迁移路径后pip报错解决 yolov5-master文件夹我换位置后,无法pip install了。解决如下: activate.bat中修改…...
HTML5.Canvas简介
1. Canvas.getContext getContext(“2d”)是Canvas元素的方法,用于获取一个用于绘制2D图形的绘图上下文对象。在给定的代码中,首先通过getElementById方法获取id为"myCanvas"的Canvas元素,然后使用getContext(“2d”)方法获取该Ca…...
)
别再只写assign了!用三种Verilog建模风格重构你的三人表决器(行为级/数据流/门级)
别再只写assign了!用三种Verilog建模风格重构你的三人表决器 三人表决器是数字电路设计中的经典案例,它能直观展示不同抽象层次的Verilog建模风格如何影响代码质量与硬件实现。很多工程师习惯性地使用assign语句完成所有设计,却忽略了Verilo…...

联想笔记本BIOS隐藏设置解锁工具:专业指南与深度解析
联想笔记本BIOS隐藏设置解锁工具:专业指南与深度解析 【免费下载链接】LEGION_Y7000Series_Insyde_Advanced_Settings_Tools 支持一键修改 Insyde BIOS 隐藏选项的小工具,例如关闭CFG LOCK、修改DVMT等等 项目地址: https://gitcode.com/gh_mirrors/le…...

51单片机电子秤的语音播报怎么选?JQ8400模块 vs OTP芯片,实测成本与易用性对比
51单片机电子秤语音方案实战选型:JQ8400模块与OTP芯片的深度拆解 在智能硬件开发中,语音交互功能正从锦上添花的附加项逐渐变为核心用户体验的关键组成部分。以51单片机电子秤为例,语音播报功能不仅能提升产品的无障碍使用体验,还…...

3行代码实现语音检索:用FunASR从10万段音频中精准定位关键信息
3行代码实现语音检索:用FunASR从10万段音频中精准定位关键信息 【免费下载链接】FunASR A Fundamental End-to-End Speech Recognition Toolkit and Open Source SOTA Pretrained Models, Supporting Speech Recognition, Voice Activity Detection, Text Post-proc…...

电流互感器选型与设计全攻略:励磁电感、匝数比及误差控制实战
摘要: 电流互感器(CT)作为电力监测、过流保护、计量反馈的核心元件,其选型直接影响系统的测量精度与可靠性。工程师常因忽视励磁电感与二次侧负载的匹配导致角差超差,或未考虑暂态饱和特性造成保护误动。本文从CT工作原…...

VSCode里Code Runner跑Python总报9009?别慌,检查一下你的setting.json文件
VSCode中Code Runner执行Python报错9009的终极排查指南 当你第一次在VSCode中用Code Runner插件运行Python脚本,满心期待看到输出结果时,终端却弹出"Process exited with code 9009"的红色错误提示——这种挫败感我深有体会。这个看似神秘的错…...
)
保姆级教程:用YOLOv5 v6.0训练自己的数据集(从环境配置到模型导出)
从零构建工业级YOLOv5 v6.0检测系统:环境配置到模型部署全流程实战 在工业质检、安防监控等场景中,快速构建高精度目标检测系统已成为工程师的核心竞争力。YOLOv5以其卓越的平衡性——兼顾速度与精度、完善的工程化支持,成为落地首选。本文将…...

20+终极Obsidian模板:简单快速构建你的卡片盒笔记系统
20终极Obsidian模板:简单快速构建你的卡片盒笔记系统 【免费下载链接】Obsidian-Templates A repository containing templates and scripts for #Obsidian to support the #Zettelkasten method for note-taking. 项目地址: https://gitcode.com/gh_mirrors/ob/O…...

[STM32U3] 【STM32U385RG 测评】PWM调节屏幕亮度
在评测计划中有使用pwm来实现调节屏幕亮度,因此本篇为如何使用HMI实现对屏的亮度调节。实现原理为,使用TouchGFX Designer添加一个滑动控件,通过滑动来修改pwm的占空比,实现ST7789的BLK的电压实现。 本次工程在上一篇试用的基础上…...

脉冲神经网络:低功耗AI计算的生物启发革命
1. 脉冲神经网络:生物启发的低功耗计算革命2014年,IBM发布TrueNorth芯片时,其每平方厘米功耗仅20毫瓦的性能震惊了整个AI界。这款基于脉冲神经网络(SNN)的芯片,能耗仅为传统CPU的万分之一,却能够实时处理视频流中的复杂…...