单链表专题
文章目录
- 目录
- 1. 链表的概念及结构
- 2. 实现单链表
- 2.1 链表的打印
- 2.2 链表的尾插
- 2.3 链表的头插
- 2.4 链表的尾删
- 2.5 链表的头删
- 2.6 查找
- 2.7 在指定位置之前插入数据
- 2.8 在指定位置之后插入数据
- 2.9 删除pos节点
- 2.10 删除pos之后的节点
- 2.11 销毁链表
- 3. 链表的分类
目录
- 链表的概念及结构
- 实现单链表
- 链表的分类
1. 链表的概念及结构
概念:
链表是⼀种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的(链表在逻辑上是连续的,在物理结构上不一定连续) 。

链表是由一个一个节点(结点)组成的,一个节点由两个部分组成:要存储的数据 + 指针(结构体指针)
因此,只要定义节点的结构,就等于定义了链表:
typedef int SLTDataType;//链表是由节点组成
typedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SLTNode;
2. 实现单链表
2.1 链表的打印
void SLTPrint(SLTNode* phead)
{SLTNode* pcur = phead;while (pcur){printf("%d->", pcur->data);pcur = pcur->next;}printf("NULL\n");
}
2.2 链表的尾插
void SLTPushBack(SLTNode* phead, SLTDataType x)
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));newnode->data = x;newnode->next = NULL;//链表为空,新节点作为pheadif (NULL == phead){phead = newnode;return;}//链表不为空,找尾节点SLTNode* ptail = phead;while (ptail->next){ptail = ptail->next;}//ptail就是尾节点ptail->next = newnode;
}
这样写是错误的!当一开始链表为空时,尾插的节点就变成了第一个节点,因此要把phead中的NULL改为第一个节点的地址,所以要传phead的地址,而不是传值。
应该这样写:
//因为头插、尾插、指定位置插入都需要申请新节点,所以单独封装成一个函数
SLTNode* SLTBuyNode(SLTDataType x)
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (NULL == newnode){perror("malloc fail!");exit(1);}newnode->data = x;newnode->next = NULL;return newnode;
}void SLTPushBack(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newnode = SLTBuyNode(x);//链表为空,新节点作为pheadif (NULL == *pphead){*pphead = newnode;return;}//链表不为空,找尾节点SLTNode* ptail = *pphead;while (ptail->next){ptail = ptail->next;}//ptail就是尾节点ptail->next = newnode;
}
2.3 链表的头插
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newnode = SLTBuyNode(x);newnode->next = *pphead;*pphead = newnode;
}
2.4 链表的尾删
void SLTPopBack(SLTNode** pphead)
{assert(pphead);//链表不能为空assert(*pphead);//链表不为空//链表只有一个节点,有多个节点if (NULL == (*pphead)->next){free(*pphead);*pphead = NULL;return;}SLTNode* ptail = *pphead;SLTNode* prev = NULL;while (ptail->next){prev = ptail;ptail = ptail->next;}prev->next = NULL;//销毁尾节点free(ptail);ptail = NULL;
}
2.5 链表的头删
void SLTPopFront(SLTNode** pphead)
{assert(pphead);//链表不能为空assert(*pphead);//让第二个节点成为新的头//把旧的头节点释放掉SLTNode* next = (*pphead)->next;//->的优先级高于*free(*pphead);*pphead = next;
}
2.6 查找
SLTNode* SLTFind(SLTNode** pphead, SLTDataType x)
{assert(pphead);//遍历链表SLTNode* pcur = *pphead;while (pcur) //等价于pcur != NULL{if (pcur->data == x){return pcur;}pcur = pcur->next;}//没有找到return NULL;
}
2.7 在指定位置之前插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{assert(pphead);assert(pos);//要加上链表不能为空assert(*pphead);SLTNode* newnode = SLTBuyNode(x);//pos刚好是头节点if (pos == *pphead){//头插SLTPushFront(pphead, x);return;}//pos不是头节点的情况SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}//prev -> newnode -> posprev->next = newnode;newnode->next = pos;
}
2.8 在指定位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{assert(pos);SLTNode* newnode = SLTBuyNode(x);newnode->next = pos->next;pos->next = newnode;
}
2.9 删除pos节点
void SLTErase(SLTNode** pphead, SLTNode* pos)
{assert(pphead);assert(*pphead);assert(pos);//pos刚好是第一个节点,没有前驱节点,执行头删if (*pphead == pos){//头删SLTPopFront(pphead);return;}SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);pos = NULL;
}
2.10 删除pos之后的节点
void SLTEraseAfter(SLTNode* pos)
{assert(pos);//pos->next不能为空assert(pos->next);SLTNode* del = pos->next;pos->next = pos->next->next;free(del);del = NULL;
}
2.11 销毁链表
void SListDesTroy(SLTNode** pphead)
{assert(pphead);assert(*pphead);SLTNode* pcur = *pphead;while (pcur){SLTNode* next = pcur->next;free(pcur);pcur = next;}*pphead = NULL;
}
完整代码:
//SList.h#include <stdio.h>
#include <stdlib.h>
#include <assert.h>typedef int SLTDataType;//链表是由节点组成
typedef struct SListNode
{SLTDataType data;struct SListNode* next;
}SLTNode;void SLTPrint(SLTNode* phead);//链表的头插、尾插
//void SLTPushBack(SLTNode* phead, SLTDataType x);//err
void SLTPushBack(SLTNode** pphead, SLTDataType x);
void SLTPushFront(SLTNode** pphead, SLTDataType x);//链表的头删、尾删
void SLTPopBack(SLTNode** pphead);
void SLTPopFront(SLTNode** pphead);//查找
SLTNode* SLTFind(SLTNode** pphead, SLTDataType x);//在指定位置之前插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);//在指定位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x);//删除pos节点
void SLTErase(SLTNode** pphead, SLTNode* pos);//删除pos之后的节点
void SLTEraseAfter(SLTNode* pos);//销毁链表
void SListDesTroy(SLTNode** pphead);
//SList.c#include "SList.h"void SLTPrint(SLTNode* phead)
{SLTNode* pcur = phead;while (pcur){printf("%d->", pcur->data);pcur = pcur->next;}printf("NULL\n");
}//因为头插、尾插、指定位置插入都需要申请新节点,所以单独封装成一个函数
SLTNode* SLTBuyNode(SLTDataType x)
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (NULL == newnode){perror("malloc fail!");exit(1);}newnode->data = x;newnode->next = NULL;return newnode;
}void SLTPushBack(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newnode = SLTBuyNode(x);//链表为空,新节点作为pheadif (NULL == *pphead){*pphead = newnode;return;}//链表不为空,找尾节点SLTNode* ptail = *pphead;while (ptail->next){ptail = ptail->next;}//ptail就是尾节点ptail->next = newnode;
}void SLTPushFront(SLTNode** pphead, SLTDataType x)
{assert(pphead);SLTNode* newnode = SLTBuyNode(x);newnode->next = *pphead;*pphead = newnode;
}void SLTPopBack(SLTNode** pphead)
{assert(pphead);//链表不能为空assert(*pphead);//链表不为空//链表只有一个节点,有多个节点if (NULL == (*pphead)->next){free(*pphead);*pphead = NULL;return;}SLTNode* ptail = *pphead;SLTNode* prev = NULL;while (ptail->next){prev = ptail;ptail = ptail->next;}prev->next = NULL;//销毁尾节点free(ptail);ptail = NULL;
}void SLTPopFront(SLTNode** pphead)
{assert(pphead);//链表不能为空assert(*pphead);//让第二个节点成为新的头//把旧的头节点释放掉SLTNode* next = (*pphead)->next;//->的优先级高于*free(*pphead);*pphead = next;
}//查找
SLTNode* SLTFind(SLTNode** pphead, SLTDataType x)
{assert(pphead);//遍历链表SLTNode* pcur = *pphead;while (pcur) //等价于pcur != NULL{if (pcur->data == x){return pcur;}pcur = pcur->next;}//没有找到return NULL;
}//在指定位置之前插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{assert(pphead);assert(pos);//要加上链表不能为空assert(*pphead);SLTNode* newnode = SLTBuyNode(x);//pos刚好是头节点if (pos == *pphead){//头插SLTPushFront(pphead, x);return;}//pos不是头节点的情况SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}//prev -> newnode -> posprev->next = newnode;newnode->next = pos;
}//在指定位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{assert(pos);SLTNode* newnode = SLTBuyNode(x);newnode->next = pos->next;pos->next = newnode;
}//删除pos节点
void SLTErase(SLTNode** pphead, SLTNode* pos)
{assert(pphead);assert(*pphead);assert(pos);//pos刚好是第一个节点,没有前驱节点,执行头删if (*pphead == pos){//头删SLTPopFront(pphead);return;}SLTNode* prev = *pphead;while (prev->next != pos){prev = prev->next;}prev->next = pos->next;free(pos);pos = NULL;
}//删除pos之后的节点
void SLTEraseAfter(SLTNode* pos)
{assert(pos);//pos->next不能为空assert(pos->next);SLTNode* del = pos->next;pos->next = pos->next->next;free(del);del = NULL;
}//销毁链表
void SListDesTroy(SLTNode** pphead)
{assert(pphead);assert(*pphead);SLTNode* pcur = *pphead;while (pcur){SLTNode* next = pcur->next;free(pcur);pcur = next;}*pphead = NULL;
}
//Test.c//int removeElement(int* nums, int numsSize, int val)
//{
// //定义两个变量
// int src = 0, dst = 0;
//
// while (src < numsSize)
// {
// //nums[src] == val,src++
// //否则赋值,src和dst都++
// if (nums[src] == val)
// {
// src++;
// }
// else
// {
// //说明src指向位置的值不等于val
// nums[dst] = nums[src];
// dst++;
// src++;
// }
// }
//
// //此时dst的值刚好是数组的新长度
// return dst;
//}//void merge(int* nums1, int nums1Size, int m, int* nums2, int nums2Size, int n)
//{
// int l1 = m - 1;
// int l2 = n - 1;
// int l3 = m + n - 1;
//
// while (l1 >= 0 && l2 >= 0)
// {
// //从后往前比大小
// if (nums1[l1] > nums2[l2])
// {
// nums1[l3--] = nums1[l1--];
// }
// else
// {
// nums1[l3--] = nums2[l2--];
// }
// }
//
// //要么是l1 < 0,要么是l2 < 0
// while (l2 >= 0)
// {
// nums1[l3--] = nums2[l2--];
// }
//}#include "SList.h"void SListTest01()
{//一般不会这样去创建链表,这里只是为了给大家展示链表的打印SLTNode* node1 = (SLTNode*)malloc(sizeof(SLTNode));node1->data = 1;SLTNode* node2 = (SLTNode*)malloc(sizeof(SLTNode));node2->data = 2;SLTNode* node3 = (SLTNode*)malloc(sizeof(SLTNode));node3->data = 3;SLTNode* node4 = (SLTNode*)malloc(sizeof(SLTNode));node4->data = 4;node1->next = node2;node2->next = node3;node3->next = node4;node4->next = NULL;SLTNode* plist = node1;SLTPrint(plist);
}void SListTest02()
{SLTNode* plist = NULL;SLTPushBack(&plist, 1);SLTPushBack(&plist, 2);SLTPushBack(&plist, 3);SLTPushBack(&plist, 4);SLTPrint(plist);//SLTPushBack(NULL, 5);//SLTPushFront(&plist, 5);//SLTPrint(plist);//SLTPushFront(&plist, 6);//SLTPrint(plist);//SLTPushFront(&plist, 7);//SLTPrint(plist);SLTPopBack(&plist);SLTPrint(plist);SLTPopBack(&plist);SLTPrint(plist);SLTPopBack(&plist);SLTPrint(plist);SLTPopBack(&plist);SLTPrint(plist);//SLTPopBack(&plist);//SLTPrint(plist);
}void SListTest03()
{SLTNode* plist = NULL;SLTPushBack(&plist, 1);SLTPushBack(&plist, 2);SLTPushBack(&plist, 3);SLTPushBack(&plist, 4);SLTPrint(plist);//头删//SLTPopFront(&plist);//SLTPrint(plist);//SLTPopFront(&plist);//SLTPrint(plist);//SLTPopFront(&plist);//SLTPrint(plist);//SLTPopFront(&plist);//SLTPrint(plist);SLTPopFront(&plist);SLTPrint(plist);//SLTNode* FindRet = SLTFind(&plist, 3);if (FindRet){ printf("找到了!\n");}else{ printf("未找到!\n");}SLTInsert(&plist, FindRet, 100);SLTPrint(plist);SLTInsertAfter(FindRet, 100);SLTPrint(plist);删除指定位置的节点//SLTErase(&plist, FindRet);//SLTPrint(plist);SListDesTroy(&plist);
}int main()
{//SListTest01();//SListTest02();SListTest03();return 0;
}
3. 链表的分类
链表的结构非常多样,以下情况组合起来就有8种(2 x 2 x 2)链表结构:
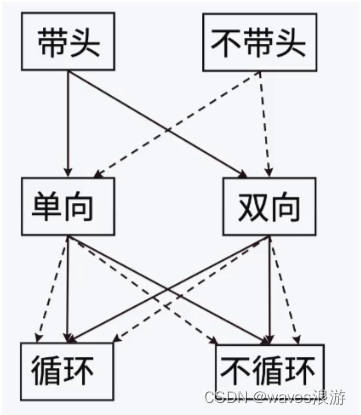
链表说明:
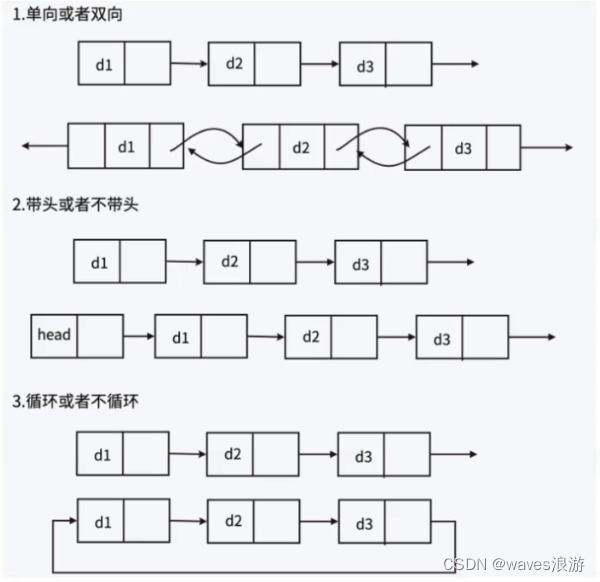
注:
- 之前代码里写的 SList 意思是 single linked list --> 单链表(不带头单向不循环链表)
- 刚才在单链表中提到的“头节点”指的是第一个有效的节点;“带头”链表里的“头”指的是无效的节点
- “带头”中的“头”:放哨的;头节点:哨兵位(不保存任何有效的数据)
虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:单链表和双向带头循环链表。
- 无头单向非循环链表:结构简单,⼀般不会单独用来存数据,实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等;另外这种结构在笔试面试中出现很多。
- 带头双向循环链表:结构最复杂,⼀般用在单独存储数据,实际中使用的链表数据结构,都是带头双向循环链表;另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了。
相关文章:
单链表专题
文章目录 目录1. 链表的概念及结构2. 实现单链表2.1 链表的打印2.2 链表的尾插2.3 链表的头插2.4 链表的尾删2.5 链表的头删2.6 查找2.7 在指定位置之前插入数据2.8 在指定位置之后插入数据2.9 删除pos节点2.10 删除pos之后的节点2.11 销毁链表 3. 链表的分类 目录 链表的概念…...

js把数组中的某一项移动到第一位
在JavaScript中,如果你要将数组中的某一项移动到第一位,你可以使用以下几种方法。 假设我们有一个数组arr,并且想要将位于索引index的项移动到数组的第一个位置: let arr [1, 2, 3, 4, 5]; let index 2; // 假设我们想将3&…...

MyBatis如何实现分页
文章目录 MyBatis分页方式对比使用数据库厂商提供的分页查询语句通过自定义 SQL 实现分页逻辑1. 使用 RowBounds 实现分页2. 使用 PageHelper 实现分页 数组分页使用 MyBatis-Plus 进行分页MyBatis物理分页和逻辑分页MyBatis 手写一个 拦截器分页 在 MyBatis 中实现分页通常有两…...

在 Python 编程中,面向对象编程的核心概念包括哪些部分?
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 在 Python 编程中,面向对象编程(Object-Oriented Programming,OOP)的核心概念主要包括类(Class)、对象(Object&#x…...

elementui树形组件自定义高亮颜色
1、需求描述:点击按钮切换树形的章节,同时高亮 2、代码实现 1)style样式添加 <style> .el-tree--highlight-current .el-tree-node.is-current > .el-tree-node__content {background-color: #81d3f8 !important; //高亮颜色colo…...

富格林:技巧抵抗曝光虚假套路
富格林悉知,黄金具备独特的优势吸引着众多投资者的目光,在现货黄金市场也被认为是一条潜力无限的盈利之道。但我们要明白风险与盈利是相辅相成的,因此在这复杂的市场中我们必须利用技巧来抵抗曝光的虚假套路。下面富格林将给大家分享一些正确…...
24年权威数学建模报名通知汇总(含妈妈杯、国赛、美赛、电工杯、数维杯、五一数模、深圳杯......)
1、MathorCup比赛 报名时间:2024年4月11日中午12点(周四) 比赛开始时间:2024年4月12日上午8时(周五) 比赛结束时间:2024年4月16日上午9时(周二) 报名费用:…...
【C语言自定义类型之----结构体,联合体和枚举】
一.结构体 1.结构体类型的声明 srruct tag {nemer-list;//成员列表 }varible-list;//变量列表结构体在声明的时候,可以不完全声明。 例如:描述一个学生 struct stu {char name[20];//名字int age;//年龄char sex[20];//性别 };//分号不能省略2.结构体…...
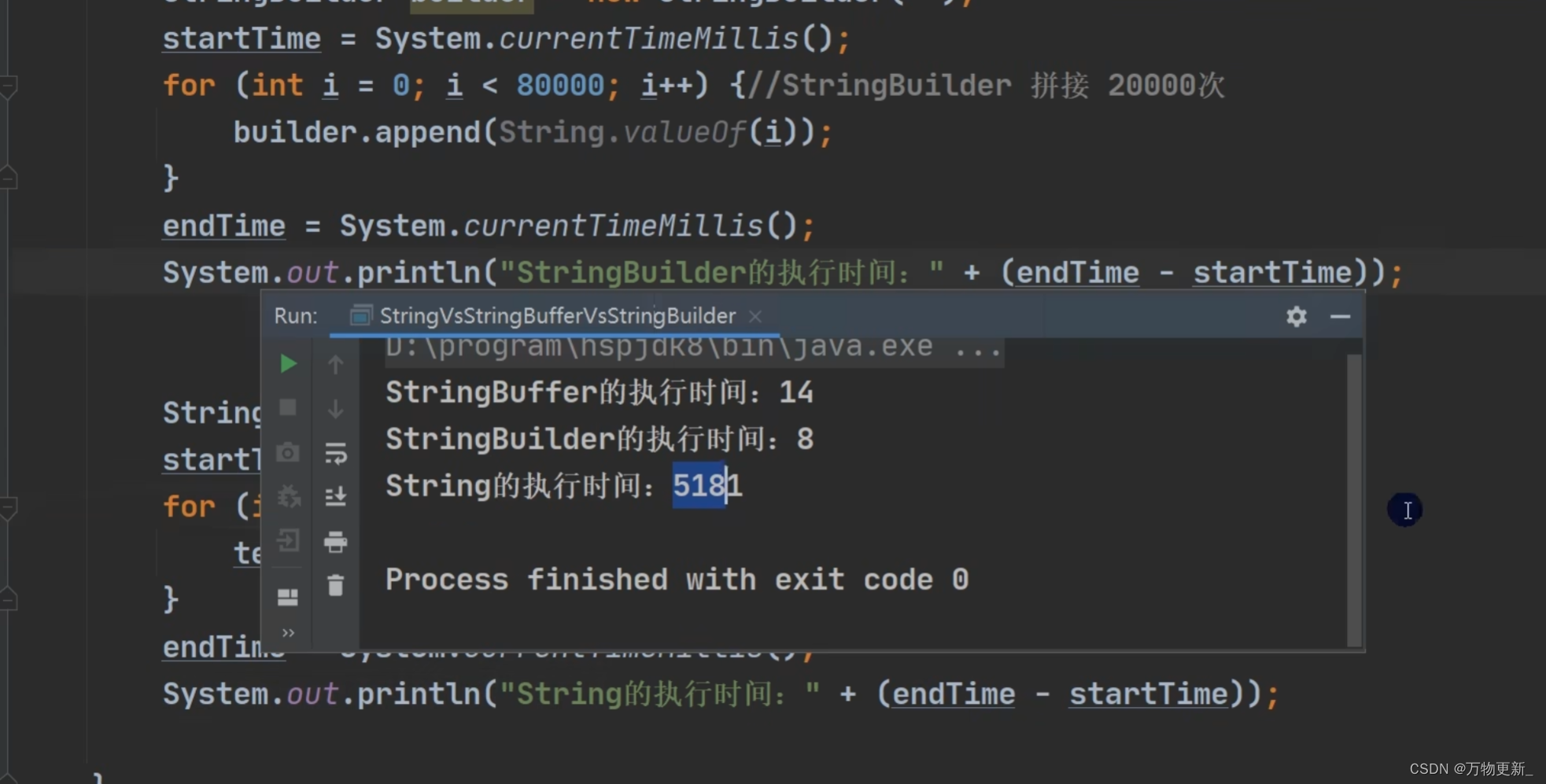
[Java基础揉碎]StringBuffer类 StringBuild类
目录 StringBuffer类 介绍 继承图 String VS StringBuffer StringBuffer的构造器 String和StringBuffer的转换 StringBuffer类常见方法 测试题 StringBuild类 基本介绍 继承图 String、StringBuffer 和StringBuilder的比较 通过字符串拼接循环测试可以看到各自的性…...
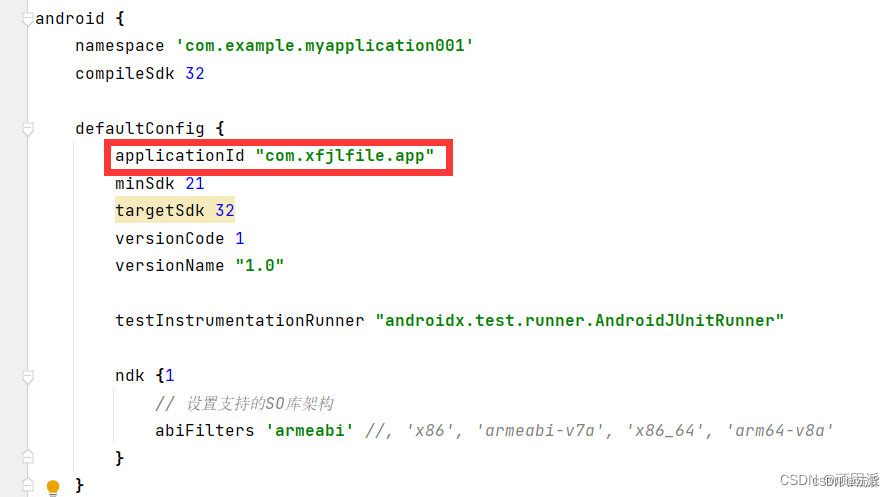
Android Studio修改项目包名
1.第一步,项目结构是这样的,3个包名合在了一起,我们需要把每个包名单独展示出来 2.我们点击这个 取消选中后的包名结构是这样的,可以看到,包名的每个文件夹已经展示分开了,现在我们可以单独对每个包名文件夹…...

c++语言增强的地方
目录 1.对全局变量的检测能力 2.struct类型增强 3.c中所有变量和函数都必须有类型 4.c中新增的bool类型 5.三目运算符的加强 6.const的增强 7.对枚举的增强 1.对全局变量的检测能力 C语言中同时定义两个相同的全局变量编译器并不会报错,而c中就会报重定义错…...

评论发布完整篇(react版)
此篇文章阐述评论的最新、最热之间的tab标签切换(包括当前所在tab标签的高亮显示问题);当前评论的删除;除此之外还延伸了用户的评论实时发布功能。其中最新tab标签所展示的内容是根据当前评论点赞数来进行排序,点赞数量…...

前端window.open的简单使用
JavaScript 中的 Window.open() 用法详解-CSDN博客 window.open("https://www.baidu.com/?tn49055317_12_hao_pg", _blank);...

基于开源软件构建存储解决方案的思考
近来看了一些IBM的存储产品的资料,有一些收获。 依据存储软件和搭配硬件,IBM存储产品的组合,大致分类如下: 自研存储软件,搭配自研专有硬件自研存储软件,搭配通用服务器硬件,比如IBM Storage S…...

【leetcode】动态规划::前缀和(二)
标题:【leetcode】前缀和(二) 水墨不写bug 正文开始: (一) 和为K的子数组 给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。 子数组是数组中元素的连续…...

SpringBoot自动装配原理之@Import注解解析
文章目录 1. 概述2. 使用2.1 导入普通Bean2.2 导入配置类2.3 导入 ImportSelector 实现类2.4 导入 ImportBeanDefinitionRegistrar 实现类 3. 区别 1. 概述 当谈及现代Java开发领域中的框架选择时,SpringBoot无疑是无与伦比的热门之选。其简化了开发流程࿰…...
49 样式迁移【李沐动手学深度学习v2课程笔记】
1. 样式迁移(Style Transfer) 计算机视觉的应用之一,将样式图片中的样式(比如油画风格等)迁移到内容图片(比如实拍的图片)上,得到合成图片 可以理解成为一个滤镜,但相对于滤镜来讲…...

Linux的学习之路:4、权限
一、Linux权限的概念 权限我们都熟悉,最常见的就是在看电视时需要vip这个就是权限,然后在Linux就是有两个权限,就是管理员也就是超级用户和普通的用户 命令:su [用户名] 功能:切换用户。 例如,要从root用户…...

自定义类型—结构体
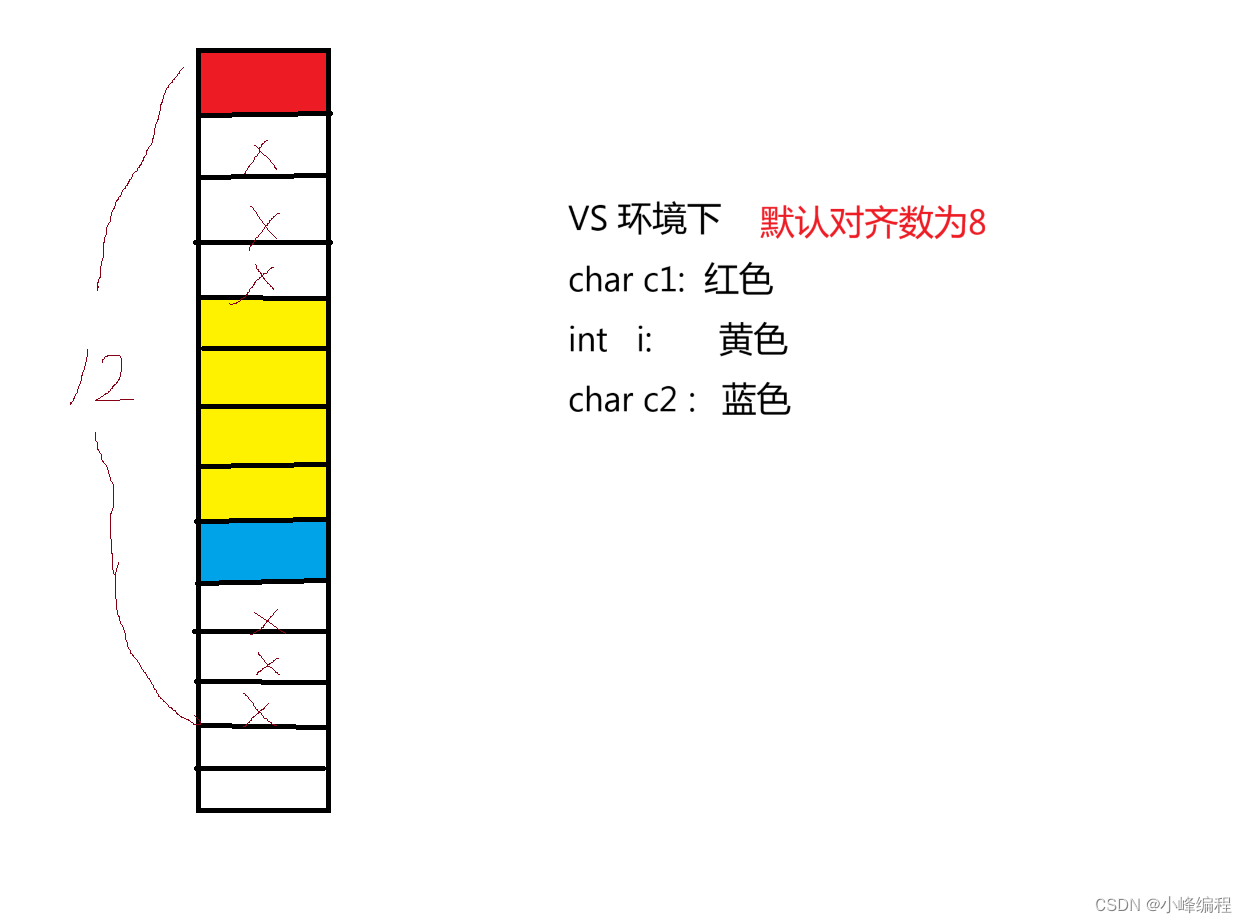
目录 1 . 结构体类型的声明 1.1 结构的声明 1.2 结构体变量的创建与初始化 1.3 结构体的特殊声明 1.4 结构体的自引用 2. 结构体内存对齐 2.1 对齐规则 2.2 为什么存在内存对齐 2.3 修改默认对齐数 3. 结构体传参 4.结构体实现位段 4.1 位段的内存分配 4.3 位段的…...

【JavaWeb】Jsp基本教程
目录 JSP概述作用一个简单的案例:使用JSP页面输出当前日期 JSP处理过程JSP 生命周期编译阶段初始化阶段执行阶段销毁阶段案例 JSP页面的元素JSP指令JSP中的page指令Include指令示例 taglib指令 JSP中的小脚本与表达式JSP中的声明JSP中的注释HTML的注释JSP注释 JSP行…...

GEE入门实战:从云端概念到首个遥感分析
1. 初识Google Earth Engine(GEE) 第一次接触GEE时,我完全被它的云端处理能力震撼到了。想象一下,你不需要在本地安装任何软件,打开浏览器就能调用PB级别的遥感数据,还能直接在上面跑分析——这简直就是遥感…...

免费AI编程助手搭建指南:基于本地大模型与开源工具链
1. 项目概述与核心价值最近在逛GitHub的时候,发现了一个挺有意思的项目,叫“Cursor-Ai-Free”。光看名字,可能很多朋友会以为这又是一个破解或者绕过付费限制的工具。但点进去仔细研究后,我发现它的定位和实现思路,其实…...

FreeRTOS任务通知:轻量级任务通信机制详解与实战应用
1. 项目概述:为什么你需要关注FreeRTOS任务通知?在嵌入式实时操作系统(RTOS)的开发中,任务间的通信与同步是核心课题。如果你用过FreeRTOS,肯定对队列、信号量、事件组这些通信机制不陌生。它们功能强大&am…...

Live Server 5分钟完全指南:如何在VSCode中实现浏览器实时预览?
Live Server 5分钟完全指南:如何在VSCode中实现浏览器实时预览? 【免费下载链接】vscode-live-server Launch a development local Server with live reload feature for static & dynamic pages. 项目地址: https://gitcode.com/gh_mirrors/vs/vs…...

AI商品计划:中国鞋服零售如何用机器学习解决库存与周转难题
过去十年,中国鞋服零售经历了从线下到线上、从粗放铺货到精准运营的剧烈转变。但一个老问题始终没变:该备多少货,备在哪,备什么颜色尺码。备多了,资金压在仓库,季末折扣吞噬利润;备少了…...

macOS微信防撤回终极指南:3步安装WeChatIntercept插件
macOS微信防撤回终极指南:3步安装WeChatIntercept插件 【免费下载链接】WeChatIntercept 微信防撤回插件,一键安装,仅MAC可用,支持v3.7.0微信 项目地址: https://gitcode.com/gh_mirrors/we/WeChatIntercept 还在为微信消息…...

Java——线程的中断
线程的中断1、取消/关闭的场景2、取消/关闭的机制3、线程对中断的反应3.1、Runnable3.2、Waiting/Timed_Waiting3.3、Blocked3.4、New/Terminate4、如何正确地取消/关闭线程1、取消/关闭的场景 我们知道,通过线程的start方法启动一个线程后,线程开始执行…...

终极B站缓存视频转换指南:快速将m4s无损转换为MP4
终极B站缓存视频转换指南:快速将m4s无损转换为MP4 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经因为B站视频突然下架而感…...
)
【ElevenLabs土耳其语音实战指南】:2024最新Turkish TTS配置全流程(含音色微调+本地化发音校准)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs土耳其语音技术概览与本地化价值 ElevenLabs 作为前沿AI语音合成平台,已正式支持土耳其语(tr-TR)语音克隆与实时TTS生成,其声学模型基于覆盖安…...

解放CPU!用STM32G4的FMAC硬核加速器做实时滤波,代码实测与性能对比
解放CPU!用STM32G4的FMAC硬核加速器做实时滤波,代码实测与性能对比 在嵌入式系统中,实时信号处理一直是工程师面临的挑战之一。无论是电机控制中的电流采样,还是环境监测中的传感器数据采集,滤波算法往往是不可或缺的一…...