循环神经网络简介
卷积神经网络相当于人类的视觉,但是它并没有记忆能力,所以它只能处理一种特定的视觉任务,没办法根据以前的记忆来处理新的任务。比如,在一场电影中推断下一个时间点的场景,这个时候仅依赖于现在的场景还不够,还需要依赖于前面发生的情节。这时候,我们就需要一种具有记忆能力的神经网络,循环神经网络就是这样一种神经网络,它期望网络能够记住前面出现的特征,并依据特征推断后面的结果,而且整体的网络结构不断循环,因此被称为循环神经网络。
循环神经网络通过使用带自反馈的神经元,能够处理任意长度的时序数据。简单循环网络是指只有一个隐藏层的神经网络,在一个两层的前馈神经网络中,连接存在相邻的层与层之间,而循环神经网络增加了从隐藏层到隐藏层的反馈连接。如果我们把每个时刻的状态都看作是前馈神经网络的一层的话,循环神经网络可以看成是时间维度上权值共享的神经网络,如下图所示:
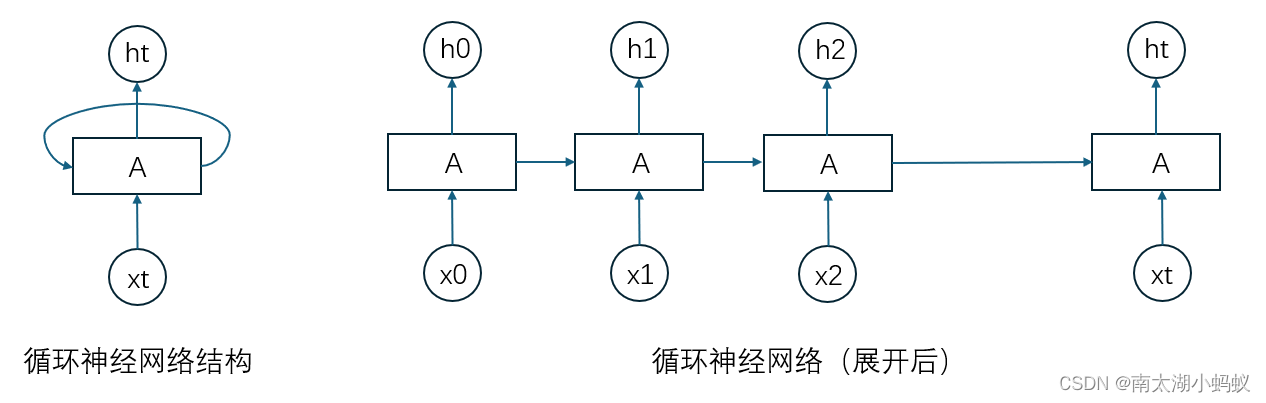
循环神经网络和普通神经网络(多层感知机)最大的差别在于:普通神经网络中,输出是有输入乘以权重加上偏置,再进行非线性运算得到的,也就是y = sigmoid(w*x + b),
而在循环神经网络中,增加了当前节点前面的节点的“记忆”,也就是增加了前面节点的输出乘以权重的值,写成公式就是y = sigmoid(w*x + wh*h + b),其中w是输入x的权重矩阵,wh是隐状态的权重矩阵。
循环神经网络的反向传播算法一般称为“随时间反向传播”算法,该算法的主要思想是通过类似前向神经网络的错误反向传播算法来计算梯度。该算法将循环神经网络看作是一个展开的多层前馈网络,就像上面那个图展开后的样子,其中“每一层”对应循环神经网络中的“每个时刻”,这样,循环神经网络就可以按照前馈网络中的反向传播算法计算梯度。在“展开”的循环神经网络中,所有层的参数是共享的,因此参数的真实梯度是所有“展开层”的参数梯度之和。
循环神经网络可以应用到很多不同类型的机器学习任务。根据这些任务的特点可以分为以下几种模式:序列到类别模式、同步的序列到序列模式、异步的序列到序列模式。
1. 序列到类别模式
基本就相当于输入一个序列数据,输出这个序列数据的类别。典型的就是输入一段话,输出这句话的情感的积极的还是消极的。
2. 同步的序列到序列模式
每一时刻都有输入和输出,且输入和输出长度相同,比如词性标注,每一个单词都需要标注其对应的词性标签。再比如说,DNA序列分析,输入是一段DNA序列,输出也是一段一一对应的DNA序列。

3. 异步的序列到序列模式
异步的序列到序列模式也被称为编码器-解码器模型,输入和输出不需要有严格的对应关系,也不需要保持相同的长度。典型的就是机器翻译,中文翻译成英文,不需要每个单词都一一对应,但是意思是相同的,这就需要先对中文进行解码,然后再对解码结果编码成英文。

下面我们看一个简单的例子,这个例子是从《动手学深度学习》一书中选取的,不过我改用了循环神经网络实现了一下。
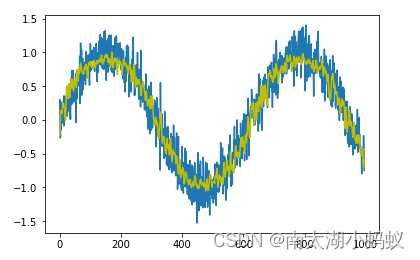
我们先用正弦函数来生成一个有1000个数据的序列:
# 画出sin函数作为序列函数
y = []
for i in range(1000):y.append(np.sin(0.01*i)+np.random.normal(0,0.2)) # 给sin函数增加一个微小的扰动
x = [i for i in range(1000)]plt.plot(x, y)
plt.show()
下面,我们希望用这个序列中的每四个连续的值,去预测下一个值。
total = 1000
tau = 4
features = np.zeros((total-tau, tau))
data = [i for i in range(total)]
for i in range(tau):features[:,i] = y[i:total-tau+i] # 获取到每一列的特征值
print(len(features)) # 样本个数
print(features) # 输出特征值
# 输出 996
[[ 0.16806793 0.14102484 0.01429365 -0.02700145][ 0.14102484 0.01429365 -0.02700145 0.21676487][ 0.01429365 -0.02700145 0.21676487 -0.15535389]...[-0.44295722 -0.4784534 -0.74262601 -0.66540164][-0.4784534 -0.74262601 -0.66540164 -0.40766233][-0.74262601 -0.66540164 -0.40766233 -0.81723738]]可以看到,features是一个996x4的矩阵,我们要做的其实就是用每一行的4个数据去预测下一个值。下面我定义了一个简单的神经网络:
# 构建一个简单的多层感知机来训练
class SimpleNet(nn.Module):def __init__(self) -> None:super().__init__()self.classifier = nn.Sequential(nn.Linear(4, 10), nn.ReLU(), nn.Linear(10, 1))def forward(self, x):x = self.classifier(x)return x下面我将这些数据构造成dataset和dataloader:
# 用前600个数字作为训练集,后400个作为测试集
class myDataset(Dataset):def __init__(self, tau=4, total=600, transform=None):data = [i for i in range(total)]y = []for i in range(total):y.append(np.sin(0.01*i)+np.random.normal(0,0.2)) # 给sin函数增加一个微小的扰动# tau代表用多少个数字来作为输入,默认为4self.features = np.zeros((total-tau, tau)) # 构建了596行4列的输入序列,代表了596个训练样本,每个样本有4个数字构成for i in range(tau):self.features[:,i] = y[i: total-tau+i] # 给特征向量赋值self.data = dataself.transform = transformself.labels = y[tau:]print((self.features))print((self.labels))print(y)def __len__(self):return len(self.labels)def __getitem__(self, idx):return self.features[idx], self.labels[idx]transform = transforms.Compose([transforms.ToTensor()])
trainDataset = myDataset(transform=transform)
train_loader = DataLoader(dataset=trainDataset, batch_size=32, shuffle=False) # 由于序列数据有前后关系,所以不能打乱接下来,对模型进行训练:
def train(epochs=10):net = SimpleNet()net.apply(init_weights)criterion = nn.MSELoss()#criterion = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(net.parameters(), lr=0.001)for epoch in range(epochs):total_loss = 0.0for i, (x, y) in enumerate(train_loader):x = Variable(x)x = x.to(torch.float32)y = Variable(y)y = y.to(torch.float32)optimizer.zero_grad()outputs = net(x)loss = criterion(outputs, y)total_loss += loss.sum() # 因为标签值和输出都是一个张量,所以损失值要求和loss.sum().backward()optimizer.step()print('Epoch {}, Loss: {:.4f}'.format(epoch+1, total_loss/len(trainDataset)))torch.save(net, 'simple.pt')预测并显示预测的结果:
# 预测
net = torch.load('simple.pt')
features = torch.from_numpy(features)
features = features.float()
y_pred = net(features)
# 画出sin函数作为序列函数
y = []
for i in range(996):y.append(np.sin(0.01*i)+np.random.normal(0,0.2)) # 给sin函数增加一个微小的扰动
x = [i for i in range(996)]fig, ax = plt.subplots()
ax.plot(x, y, color="r")
ax.plot(x, y_pred.detach().numpy(), color="g")
plt.show()
可以看到,跟原始数据相比,预测出来的结果也是比较接近的。下面尝试用循环神经网络来实现一下这个简单的功能:
class RNN(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(RNN, self).__init__() self.hidden_size = hidden_size self.rnn = nn.RNN(input_size, hidden_size, batch_first=True) self.fc = nn.Linear(hidden_size, output_size) def forward(self, x): h0 = torch.zeros(1, x.size(0), self.hidden_size).to(x.device)#print("x.shape = ",x.shape)#print("h0.shape = ",h0.shape)out, _ = self.rnn(x, h0)#print("out.shape = ",out.shape)#print("out[:, -1, :].shape = ",out[:, -1, :].shape)out = self.fc(out[:, -1, :])#print("out.shape : ",out.shape)return out注意,这里的out[:,-1,:]代表的是一个三维数组,把第二维最后一个值取出来,看一下代码会比较清晰:
a = [[[1,2,3],[4,5,6],[7,8,9]],[['a','b','c'],['d','e','f'],['h','i','j']]]
t = np.array(a)
print(t[:,-1,:])
# 输出:
[['7' '8' '9']['h' 'i' 'j']]预测结果同样比较准确。
采用循环神经网络其实也可以对图像进行分类,我们以mnist数据集为例,其实只要把mnist数据集看成是28x28的序列数据就行了,一个序列由28个数据组成,每个数据有28个元素构成。
# 超参数
input_size = 28class RNN(nn.Module): def __init__(self, input_size, hidden_size, num_classes): super(RNN, self).__init__() self.hidden_size = hidden_size self.rnn = nn.RNN(input_size, hidden_size, batch_first=True) self.fc = nn.Linear(hidden_size, num_classes) def forward(self, x): h0 = torch.zeros(1, x.size(0), self.hidden_size).to(x.device)out, _ = self.rnn(x, h0)out = self.fc(out[:, -1, :])return out定义一个训练函数
def train(net, data_loader, test_loader, epochs=10):criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(net.parameters(), lr=0.001)for epoch in range(epochs):total_loss = 0.0for i, (images, labels) in enumerate(data_loader):optimizer.zero_grad()# 将图像展平为序列,每个序列的特征数为28images = images.view(-1, 28, input_size)outputs = net(images)loss = criterion(outputs, labels)total_loss += loss.item()loss.backward()optimizer.step()print('Epoch {}, Loss: {:.4f}'.format(epoch+1, total_loss/len(data_loader)))# 测试模型net.eval()with torch.no_grad():correct = 0total = 0for images, labels in test_loader:images = images.view(-1, 28, input_size)outputs = net(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print('Test Accuracy: {:.2f}%'.format(100 * correct / total))passif __name__ == '__main__':model = RNN(input_size=28, hidden_size=64, num_classes=10)# 加载MNIST数据集train_dataset = datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)test_dataset = datasets.MNIST(root='./data', train=False, transform=transforms.ToTensor())# 定义数据加载器train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=8, shuffle=True)test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=8, shuffle=False)train(model, train_loader, test_loader)可以看到测试精度还是比较高的。
Epoch 1, Loss: 0.6863
Epoch 2, Loss: 0.3386
Epoch 3, Loss: 0.3025
Epoch 4, Loss: 0.2789
Epoch 5, Loss: 0.2924
Epoch 6, Loss: 0.2702
Epoch 7, Loss: 0.2620
Epoch 8, Loss: 0.2580
Epoch 9, Loss: 0.2459
Epoch 10, Loss: 0.2680
Test Accuracy: 93.12%下一篇文章,我们来看看循环神经网络的两种变体,LSTM和GRU。
相关文章:
循环神经网络简介
卷积神经网络相当于人类的视觉,但是它并没有记忆能力,所以它只能处理一种特定的视觉任务,没办法根据以前的记忆来处理新的任务。比如,在一场电影中推断下一个时间点的场景,这个时候仅依赖于现在的场景还不够࿰…...
计算机网络 子网掩码与划分子网
一、实验要求与内容 1、需拓扑图和两个主机的IP配置截图。 2、设置网络A内的主机IP地址为“192.168.班内学号.2”,子网掩码为“255.255.255.128”,网关为“192.168.班内学号.1”;设置网络B内的主机IP地址为“192.168.班内学号100.2”&#…...

HUD抬头显示器中如何设计LCD的阳光倒灌实验
关键词:阳光倒灌实验、HUD光照温升测试、LCD光照温升测试、太阳光模拟器 HUD(Head-Up Display,即抬头显示器)是一种将信息直接投影到驾驶员视线中的技术,通常用于飞机、汽车等驾驶舱内。HUD系统中的LCD(Liq…...

Shoplazza闪耀Shoptalk 2024,新零售创新解决方案引领行业新篇章!
在近期举办的全球零售业瞩目盛事——Shoptalk 2024大会上,全球*的零售技术平台-店匠科技(Shoplazza)以其*的创新实力与前瞻的技术理念,成功吸引了与会者的广泛关注。此次盛会于3月17日至20日在拉斯维加斯曼德勒湾隆重举行,汇聚了逾万名行业精英。在这场零售业的盛大聚会上,Shop…...

Linux:sprintf、snprintf、vsprintf、asprintf、vasprintf比较
这些函数都在stdio.h里,不过不同系统不同库,有些函数不一定提供。 1. sprintf 函数原型: int sprintf (char *str, const char *format, ...); extern int sprintf (char *__restrict __s, const char *__restrict __format, ...); 功能是将…...

Github远程仓库改名字之后,本地git如何配置?
文章目录 缘由解决方案 缘由 今天在github创建一个仓库,备份一下本地电脑上的资料。起初随便起一个仓库名字,后来修改之。既然远程仓库改名,那么本地仓库需要更新地址。这里采用SSH格式。 解决方案 如果你的GitHub仓库改名了,你…...
4.10)
Objective-C学习笔记(ARC,分类,延展)4.10
1.自动释放池autoreleasepool:存入到自动释放池的对象,在自动释放池销毁时,会自动调用池内所有对象的release方法。调用autorelease方法将对象放入自动释放池。 Person *p1 [ [ [ Person alloc ] init ] autorelease]; 2.在类方法里写一个…...
02 Git 之IDEA 集成使用 GitHub(Git同时管理本地仓库和远程仓库)
2 .IDEA 集成使用 GitHub(Git同时管理本地仓库和远程仓库) 首先在 IDEA 的设置中绑定 GitHub 的账号 先创建一个 test1.txt 文件,内容为 aaa. 最上一栏 VCS, SHARE ON GitHub,然后选择要发送到远程仓库的文件即可。…...

CSS滚动条样式修改
前言 目前我们可以通过 CSS伪类 来实现滚动条的样式修改,以下为修改滚动条样式用到的CSS伪类: ::-webkit-scrollbar — 整个滚动条 ::-webkit-scrollbar-button — 滚动条上的按钮 (上下箭头) ::-webkit-scrollbar-thumb — 滚动条上的滚动滑块 ::-web…...

《零秒思考》像麦肯锡精英一样思考 - 三余书屋 3ysw.net
零秒思考:像麦肯锡精英一样思考 大家好,今天我们要深入探讨的著作是《零秒思考》。在领导提出问题时,我们常常会陷入沉思,却依然难以有所进展,仿佛原地踏步,但是身边的同事却能够立即给出清晰的回答。这种…...

使用docker制作Android镜像(实操可用)
一、安装包准备 1、准备jdk 下载地址:Java Downloads | Oracle 注意版本!!!!!! 我下载的jdk17,不然后面构建镜像报错,就是版本不对 2、准备安装的工具包 ttps://dev…...

大厂MVP技术JAVA架构师培养
课程介绍 这是一个很强悍的架构师涨薪计划课程,课程由专家级MVP讲师进行教学,分为是一个章节进行分解式面试及讲解,不仅仅是面试,更像是一个专业的架构师研讨会课程。课程内容从数据结构与算法、Spring Framwork、JVM原理、 JUC并…...

uniapp实现文件和图片选择上传功能实现
主要介绍了uni-file-picker文件选择上传,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下 上传一张: <template><view class="container example"><uni-forms ref="baseForm" …...
2024认证杯数学建模C题思路模型代码
目录 2024认证杯数学建模C题思路模型代码:4.11开赛后第一时间更新,获取见文末名片 以下为2023年认证杯C题: 2024年认证杯数学建模C题思路模型代码见此 2024认证杯数学建模C题思路模型代码:4.11开赛后第一时间更新,获…...
springcloud项目中,nacos远程的坑
我将允许重写放在了远程nacos的注册中心,还是无法启动。这个bug,想想确实也可以解决。 解决方案 1.配置到bootstrap.yml或者application.yml中 2.实现EnvironmentPostProcessor并设置值,并在META-INF中注入我们的类 org.springframework.boot…...

南京航空航天大学-考研科目-513测试技术综合 高分整理内容资料-01-单片机原理及应用分层教程-单片机有关常识部分
系列文章目录 高分整理内容资料-01-单片机原理及应用分层教程-单片机有关常识部分 文章目录 系列文章目录前言总结 前言 单片机的基础内容繁杂,有很多同学基础不是很好,对一些细节也没有很好的把握。非常推荐大家去学习一下b站上的哈工大 单片机原理及…...

【python】Flask Web框架
文章目录 WSGI(Web服务器网关接口)示例Web应用程序Web框架Flask框架创建项目安装Flask创建一个基本的 Flask 应用程序调试模式路由添加变量构造URLHTTP方法静态文件模板—— Jinja2模板文件(Template File)<...
Electron+React 搭建桌面应用
创建应用程序 创建 Electron 应用 使用 Webpack 创建新的 Electron 应用程序: npm init electron-applatest my-new-app -- --templatewebpack 启动应用 npm start 设置 Webpack 配置 添加依赖包,确保可以正确使用 JSX 和其他 React 功能ÿ…...
基于Android的记单词App系统的设计与实现
博主介绍:✌IT徐师兄、7年大厂程序员经历。全网粉丝15W、csdn博客专家、掘金/华为云//InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇dz…...
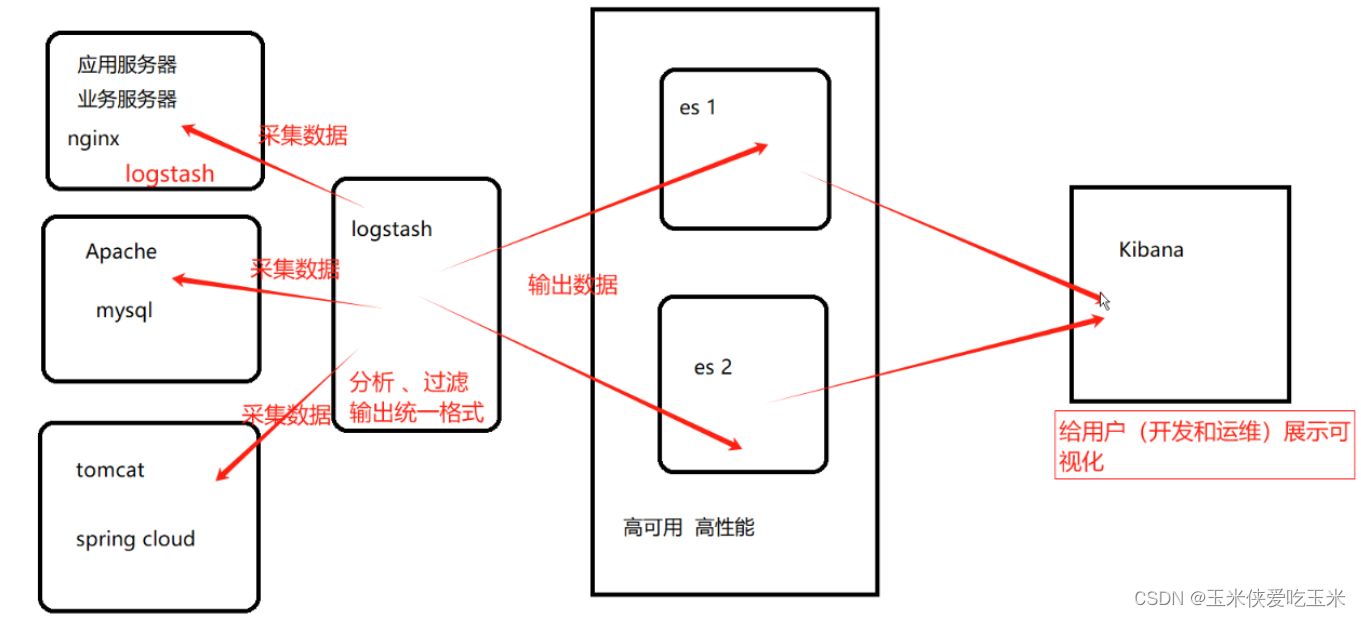
ELK 企业级日志分析系统 简单介绍
目录 一 ELK 简介 1, elk 是什么 2,elk 架构图 3,elk 日志处理步骤 二 Elasticsearch 简介 1, Elasticsearch 是什么 2, Elasticsearch 的核心概念 3, Elasticsearch 的原理 三 Logstas…...

如何通过霞鹜文楷解决中文开源字体在技术项目中的核心挑战
如何通过霞鹜文楷解决中文开源字体在技术项目中的核心挑战 【免费下载链接】LxgwWenKai An unprofessional open-source Chinese font derived from Fontworks Klee One. 一款非专业的开源中文字体,基于 FONTWORKS 出品字体 Klee One 衍生。 项目地址: https://g…...

计算机毕业设计springboot智慧化教学辅助系统 基于SpringBoot的智能化教学管理与评价平台 SpringBoot驱动的数字化教学支持服务平台
计算机毕业设计springboot智慧化教学辅助系统 (配套有源码 程序 mysql数据库 论文) 本套源码可以在文本联xi,先看具体系统功能演示视频领取,可分享源码参考。随着信息技术的迅猛发展和全球教育环境的不断变化,传统教育模式正面临着…...

LangChain + AgentRun 浏览器沙箱极简集成指南
AgentRun Browser Sandbox 介绍 什么是 Browser Sandbox? Browser Sandbox 是 AgentRun 平台提供的云原生无头浏览器沙箱服务,基于阿里云函数计算(FC)构建。它为智能体提供了一个安全隔离的浏览器执行环境,支持通过标准的 Chrome DevTools Protocol (…...

LFM2.5-1.2B-Thinking-GGUF入门必看:轻量模型在离线环境中的安全合规部署
LFM2.5-1.2B-Thinking-GGUF入门必看:轻量模型在离线环境中的安全合规部署 1. 模型概述 LFM2.5-1.2B-Thinking-GGUF是Liquid AI推出的轻量级文本生成模型,专为低资源环境设计。这个1.2B参数的模型采用GGUF格式,能够在各种边缘设备上高效运行…...

DVB-S系统设计:从理论到FPGA实现的完整指南
1. DVB-S系统概述:卫星数字电视的核心技术 DVB-S(Digital Video Broadcasting - Satellite)是卫星数字电视广播的国际标准,它定义了从信号编码、调制到传输的完整技术规范。我第一次接触DVB-S系统是在2015年参与一个卫星接收机项目…...

投资组合优化中的常见陷阱:如何用LINGO和MATLAB避免风险计算错误
投资组合优化中的常见陷阱:如何用LINGO和MATLAB避免风险计算错误 在金融投资领域,优化投资组合是实现收益最大化和风险最小化的关键手段。然而,许多金融分析师和量化投资爱好者在实际操作中常常陷入各种计算陷阱,导致结果偏离预期…...
及新手详细指南)
8款实用AI论文生成工具(包括爱毕业aibiye)及新手详细指南
在学术研究领域,AI技术的应用显著提升了论文写作的效率与质量。以下推荐8款功能强大的智能工具,涵盖文献解析、内容生成、文本优化等关键环节,助力研究者高效完成从资料收集到论文润色的全流程工作。这些创新解决方案能够有效简化研究过程&am…...

、SEATA分布式事务——XA模式
指令替换 项目需求:将加法指令替换为减法 项目目录如下 /MyProject ├── CMakeLists.txt # CMake 配置文件 ├── build/ #构建目录 │ └── test.c #测试编译代码 └── mypass2.cpp # pass 项目代码 一,测试代码示例 test.c // test.c #includ…...

Intv_AI_MK11跨平台开发体验:在Windows WSL2中无缝使用GPU进行模型调试
Intv_AI_MK11跨平台开发体验:在Windows WSL2中无缝使用GPU进行模型调试 1. 为什么选择WSL2进行AI开发 对于习惯Windows系统的开发者来说,直接使用Linux环境进行AI模型开发往往面临诸多不便。WSL2(Windows Subsystem for Linux 2)…...

MatterGen:AI驱动的无机材料生成革命,开启新材料发现新纪元
MatterGen:AI驱动的无机材料生成革命,开启新材料发现新纪元 【免费下载链接】mattergen Official implementation of MatterGen -- a generative model for inorganic materials design across the periodic table that can be fine-tuned to steer the …...