机器学习_XGBoost模型_用C++推理示例Demo
1. 需求
将 python 训练好的 xgboost 模型, 使用C++ 进行加载并进行推理(预测)
2. 代码实现
#include <iostream>
#include <fstream>
#include <sstream>
#include <vector>
#include <string>
#include <xgboost/c_api.h>const char *model_path = "my_xgb.model";// 预测单条数据
void test_xgboost_one_item(std::vector<float> features)
{// load confidence prediction modelBoosterHandle booster;XGBoosterCreate(NULL, 0, &booster);XGBoosterLoadModel(booster, model_path);DMatrixHandle dtest;XGDMatrixCreateFromMat(reinterpret_cast<float*>(&features[0]), 1, features.size(), 0, &dtest);// 进行预测const float *out_result;unsigned long out_len;XGBoosterPredict(booster, dtest, 0, 0, 0, &out_len, &out_result);// 输出预测结果std::cout << "Prediction result: ";for (unsigned long i = 0; i < out_len; ++i) {std::cout << out_result[i] << " ";}std::cout << std::endl;// 释放资源XGDMatrixFree(dtest);XGBoosterFree(booster);}// 预测多条数据(来自文件.txt)
void test_xgboost_from_file(std::string file_name)
{BoosterHandle booster;XGBoosterCreate(NULL, 0, &booster);XGBoosterLoadModel(booster, model_path);// 打开文件std::ifstream datasets_file(file_name);if (!datasets_file.is_open()) {std::cerr << "Failed to open the file: " << file_name << std::endl;}// 读取文件内容并存储到二维vector数组中std::vector<std::vector<float>> test_data_src;std::string line;while (std::getline(datasets_file, line)){std::istringstream iss(line);std::vector<float> row_src;std::string token;//仅读取一行中的前7个数据,举例.for (int i = 0; i < 7; ++i){// 读取每行的前7个元素std::getline(iss, token, ',');float value = std::stof(token);row_src.push_back(value);}test_data_src.push_back(row_src);}// 关闭文件datasets_file.close();std::cout << "====== test_data_src ========" << std::endl;// 输出二维vector数组中的数据(可选)for (const auto& row : test_data_src) {for (const auto& value : row) {std::cout << value << " ";}std::cout << std::endl;}//注意: test data 需要 和训练模型时的数据保持一致, 即经过相同的预处理(若有)//注意: 重要操作, 为了通过第一个数据地址,访问到所有数据.// 将二维vector数组转换为一维的连续内存块std::vector<float> flatData;for (const auto& row : test_data_src) {flatData.insert(flatData.end(), row.begin(), row.end());}// 将测试数据转换为DMatrix格式DMatrixHandle dtest;bst_ulong nrow = test_data_src.size();bst_ulong ncol = test_data_src[0].size();XGDMatrixCreateFromMat(flatData.data(), nrow, ncol, 0, &dtest);// 进行预测const float *out_result;unsigned long out_len;XGBoosterPredict(booster, dtest, 0, 0, 0, &out_len, &out_result);// 输出预测结果std::cout << "Prediction result: " << std::endl;;for (unsigned long i = 0; i < out_len; ++i) {std::cout << out_result[i] << " "<< std::endl;}std::cout << std::endl;// 保存预测结果到文件(可选)std::ofstream file_prediction("predict_result.txt", std::ofstream::trunc);if (!file_prediction.is_open()) {std::cerr << "Failed to open the file." << std::endl;}for (unsigned long i = 0; i < out_len; ++i) {file_prediction << out_result[i] << " "<< std::endl;}// 关闭文件file_prediction.close();// 释放资源XGDMatrixFree(dtest);XGBoosterFree(booster);}
int main(int argc, char **argv) {// 测试1: 仅预测一条数据 (使用7个feture,预测输出一个output数据)std::vector<float> features = {0.562000, 0.739818, 0.917457, 0.943217, 0.055662, 0.994000, 0.995506};test_xgboost_one_item(features);// 测试2: 预测存储在文件中的多条数据 (使用7个feture,预测输出一个output数据)std::string test_data_normalsets = "test_data.txt";// test_data.txt 内容:// 0.562000 0.739818 0.917457 0.943217 0.055662 0.994000 0.995506// 0.548000 0.737632 0.910190 0.943415 0.000000 0.994591 0.997773// 0.544000 0.738136 0.924542 0.944812 0.563753 0.994729 0.996054// 0.556000 0.740211 0.919053 0.945792 0.000000 0.999281 0.990547test_xgboost_from_file(test_data_normalsets);std::cout << "==== Done ====" << std::endl;return 0;
}
3. 注意
注意: test data 需要 和训练模型时的数据保持一致, 即经过相同的预处理(若有)
XGBoosterPredict() / 参数说明:
int XGBoosterPredict ( BoosterHandle handle,DMatrixHandle dmat,int option_mask,unsigned ntree_limit, int training,bst_ulong * out_len,const float ** out_result
)
- handle:句柄
- dmat:数据矩阵
- option_mask:选项的位掩码,用于预测,可能的取值为 0: 正常预测 1: 输出边缘值而不是转换后的值 2: 输出树的叶子索引而不是叶子值,注意,叶子索引在每棵树中是唯一的 4: 输出单个预测的特征贡献
- ntree_limit:限制用于预测的树的数量,这仅适用于提升树,当参数设置为0时,我们将使用所有树 training:预测函数是否用作训练循环的一部分。
- 可以在两种情况下运行预测: 给定数据矩阵 X,从模型中获取预测 y_pred。 获取用于计算梯度的预测。例如,DART 提升器在训练期间执行了 dropout,由于被舍弃的树,预测结果与正常推断步骤获取的结果不同。
- 对于第一个场景,设置 training=false。对于第二个场景,设置 training=true。第二个场景适用于定义自定义目标函数时。
- out_len:用于存储返回结果的长度
- out_result:用于设置指向数组的指针
参考:
-
将基于python训练得到XGBoost模型,用于C++环境推理的示例Demo
-
GitHub - Outliers1106/XGBoost-py2cpp
-
Xgbboost: cpp调用: GitHub - EmbolismSoil/xgboostpp: 将XGBoost c api封装成c++接口
-
-
官方说明文档: Installation Guide — xgboost 2.0.3 documentation
相关文章:

机器学习_XGBoost模型_用C++推理示例Demo
1. 需求 将 python 训练好的 xgboost 模型, 使用C 进行加载并进行推理(预测) 2. 代码实现 #include <iostream> #include <fstream> #include <sstream> #include <vector> #include <string> #include <xgboost/c_api.h>const char *m…...

C语言 | Leetcode C语言题解之第21题合并两个有序链表
题目: 题解: /*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/typedef struct ListNode ListNode; struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {/…...

2024考研调剂须知
----------------------------------------------------------------------------------------------------- 考研复试科研背景提升班 教你快速深入了解掌握考研复试面试中的常见问题以及注意事项,系统的教你如何在短期内快速提升自己的专业知识水平和编程以及英语…...
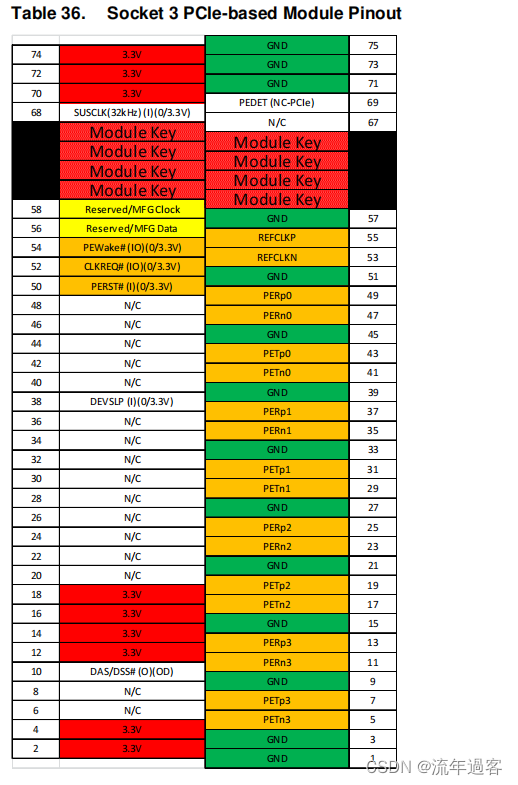
PCIE协议版--M.2接口规范V1.0中文版1——电气规格篇
3.电气规范 3.1 Connectivity Socket 1 系统接口信号 表15适用于Socket 1-SD和Socket 1-DP输出版本。 3.1.1.补充NFC信号 当一个SIM设备被用作安全元素时,NFC解决方案可以与表16中列出的附加信号相结合。 3.1.2.电源和地 PCI Express M.2 Socket 1使用一个3.3 V…...
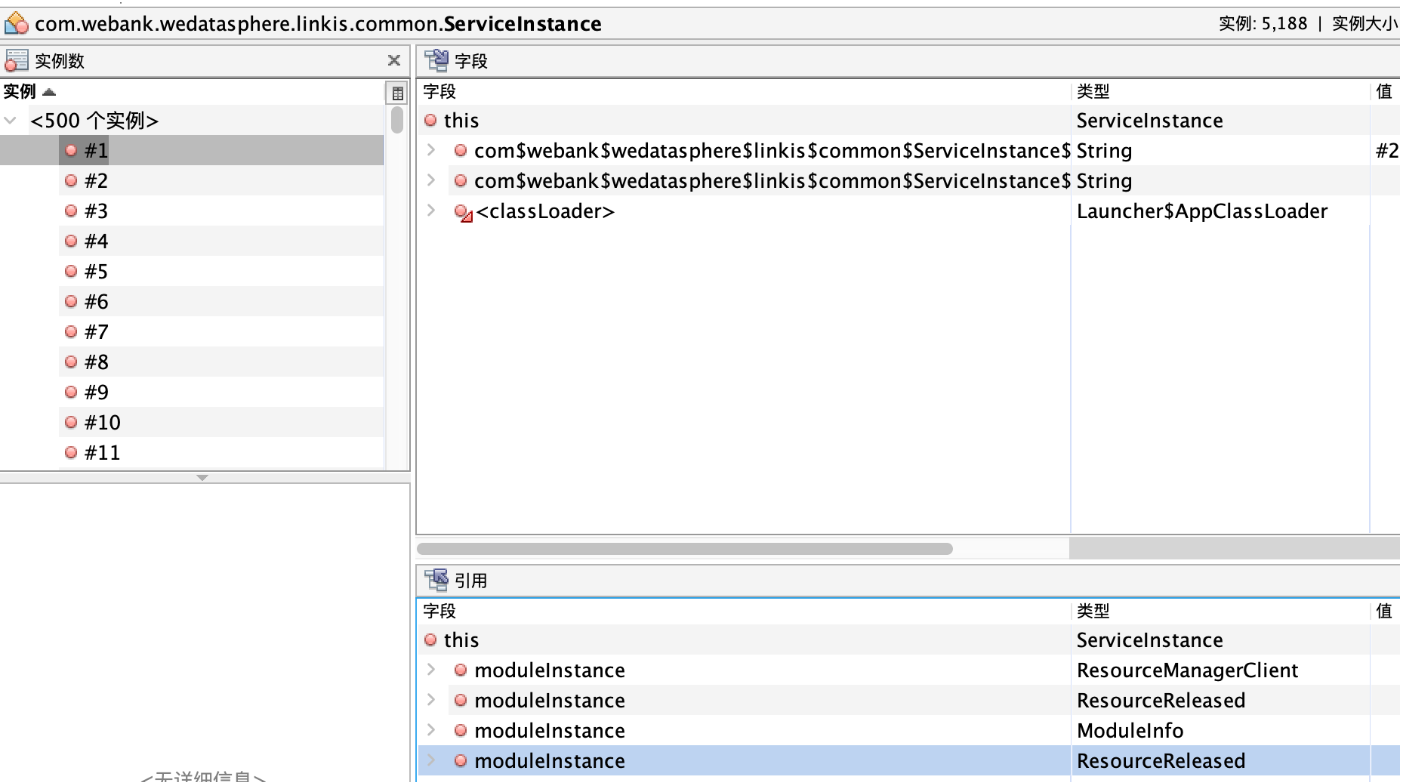
【JVM】JVM堆占用情况分析(频繁创建的对象、内存泄露等问题)、jmap+jhat、jvisualvm工具使用
文章目录 一. 相关命令1. 查看进程堆内存整体使用情况:OOM的可能2. 统计类的对象数量以及内存占用:定位内存泄漏 二. 分析内存占用1. 使用 jhat 排查对象堆占用情况1.1. 排查步骤1.2. 具体分析例子a. 分析频繁创建对象导致的OOM 1.3. OQL查看某一个对象的…...
)
【蓝桥杯每日一题】4.11 更小的数(不用区间DP)
题目来源: 蓝桥杯 2023 省 A]更小的数 - 洛谷 这题只需要用到双指针就OK~ 思路1: 翻转数组的子数组,然后进行比较大小将翻转后的数组存储在字符串 k k k中,然后将字符串 k k k与字符串 a a a进行逐一元素比较(因为…...

【线段树】2276. 统计区间中的整数数目
算法可以发掘本质,如: 一,若干师傅和徒弟互有好感,有好感的师徒可以结对学习。师傅和徒弟都只能参加一个对子。如何让对子最多。 二,有无限多1X2和2X1的骨牌,某个棋盘若干格子坏了,如何在没有坏…...

ChatGPT 写作利器:探索ChatGPT在论文写作中的应用
ChatGPT无限次数:点击直达 ChatGPT 写作利器:探索ChatGPT在论文写作中的应用 引言 ChatGPT是一种强大的自然语言处理工具,能够为我们提供高效、准确的文本生成功能。在论文写作领域,ChatGPT的应用也逐渐受到关注。本文将探讨ChatGPT在论文写…...

从 SQLite 3.4.2 迁移到 3.5.0(二十)
返回:SQLite—系列文章目录 上一篇:SQLite---调试提示(十九) 下一篇:SQLite—系列文章目录 SQLite 版本 3.5.0 (2007-09-04) 引入了一个新的操作系统接口层, 与所有先前版本的 SQLi…...

集群开发学习(一)(安装GO和MySQL,K8S基础概念)
完成gin小任务 参考文档: https://www.kancloud.cn/jiajunxi/ginweb100/1801414 https://github.com/hanjialeOK/going 最终代码地址:https://github.com/qinliangql/gin_mini_test.git 学习 1.安装go wget https://dl.google.com/go/go1.20.2.linu…...

[Kubernetes[K8S]集群:Slaver从节点初始化和Join]:添加到主节点集群内
文章目录 操作流程:上篇主节初始化地址:前置:Docker和K8S安装版本匹配查看0.1:安装指定docker版本 **[1 — 8] ** [ 这些步骤主从节点前置操作一样的 ]一:主节点操作 查看主机域名->编辑域名->域名配置二&#x…...

redis复习笔记08(小滴课堂)
案例实战需求之大数据下的用户画像标签去重 我们就简单的做到了去重了。 案例实战社交应用里面之关注、粉丝、共同好友案例 这就是我们set的一个应用。 案例实战之SortedSet用户积分实时榜单最佳实践 准备积分类对象: 我们加上构造方法和判断相等的equals和hascod…...
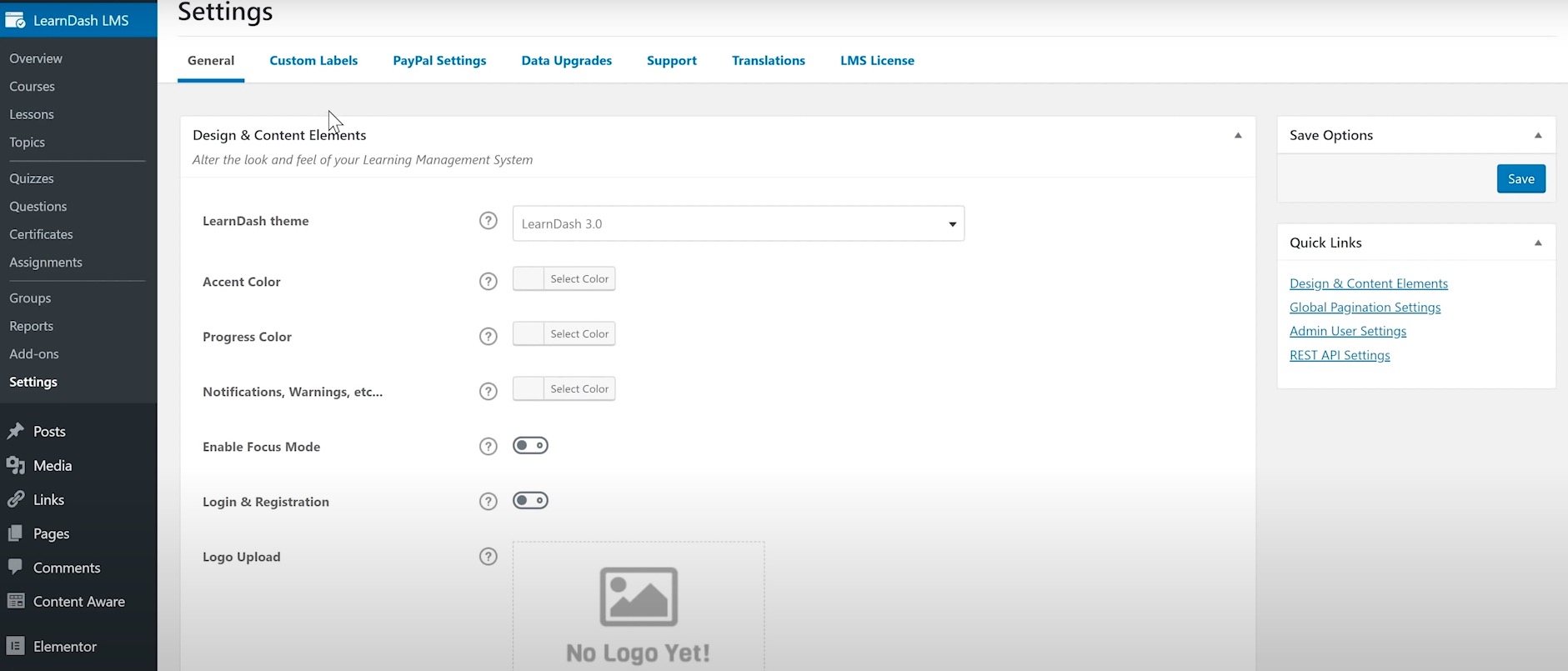
在线课程平台LearnDash评测 – 最佳 WordPress LMS插件
在我的LearnDash评测中,我探索了流行的 WordPress LMS 插件,该插件以其用户友好的拖放课程构建器而闻名。我深入研究了各种功能,包括课程创建、测验、作业、滴灌内容、焦点模式、报告、分析和管理工具。 我的评测还讨论了套餐和定价选项&…...

OpenDDS-3.27构建与用法
一、OpenDDS-3.27构建 ./configure To enable Java bindings, use ./configure --java make 二、运行Messenger Example: source setenv.sh For the C example:cd DevGuideExamples/DCPS/Messenger For the Java example:cd java/tests/mes…...

计算机网络——MAC地址和IP地址
目录 前言 引入 MAC地址与IP地址 IP地址和MAC地址是什么?如何起作用的? MAC地址如何表示与确定网卡在网络中的确定位置? DHCP协议自动帮我们配置 操作系统是如何知道对方的MAC地址的? 前言 本博客是博主用于复习计算机网络…...

Unity构建详解(7)——AssetBundle格式解析
【文件格式】 文件可以分为文本文件、图片文件、音频文件、视频文件等等,我们常见的这些文件都有行业内的标准格式,其意味着按照一定的规则和规范去保存读取文件,可以获取我们想要的数据。 有些软件会有自己的文件格式,会按照其…...
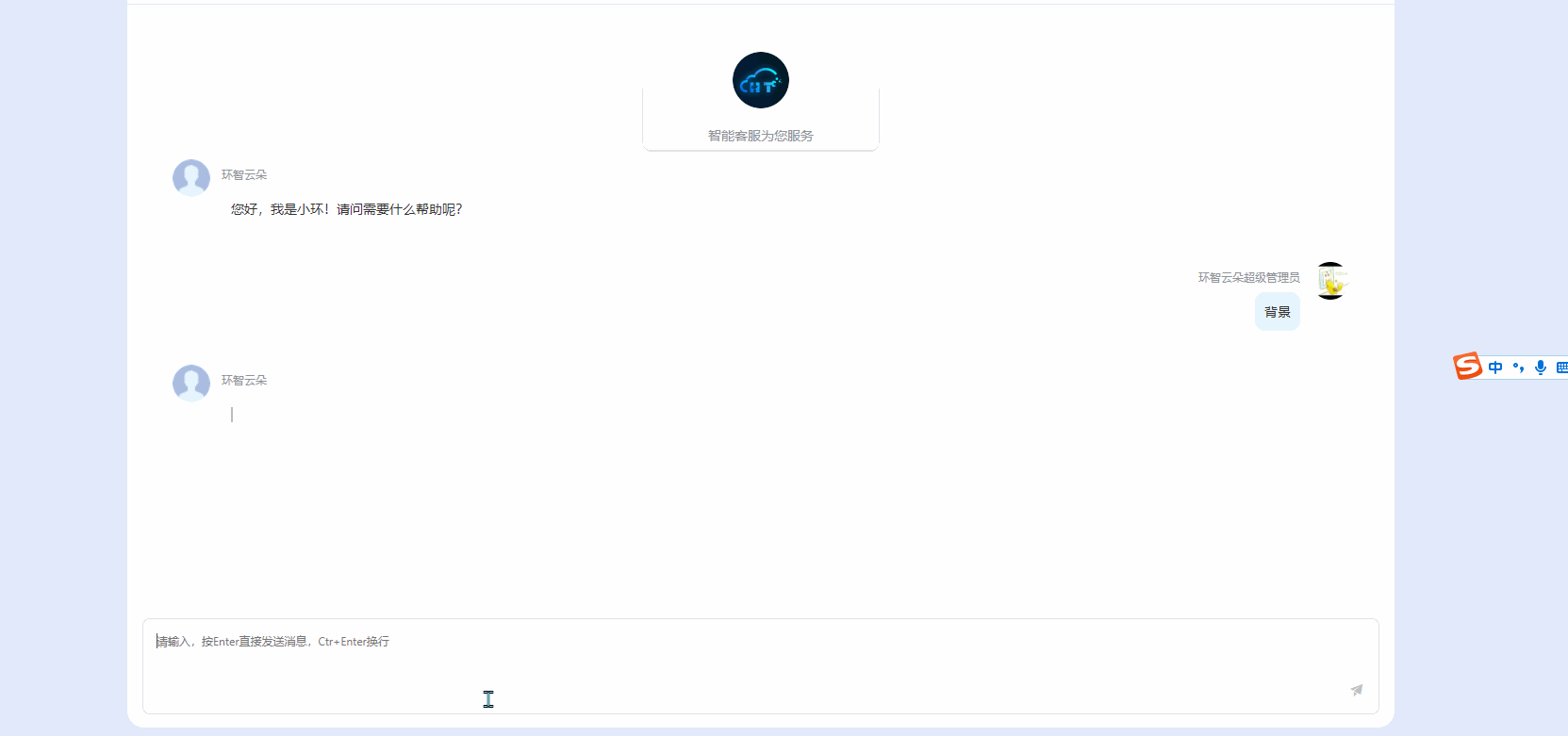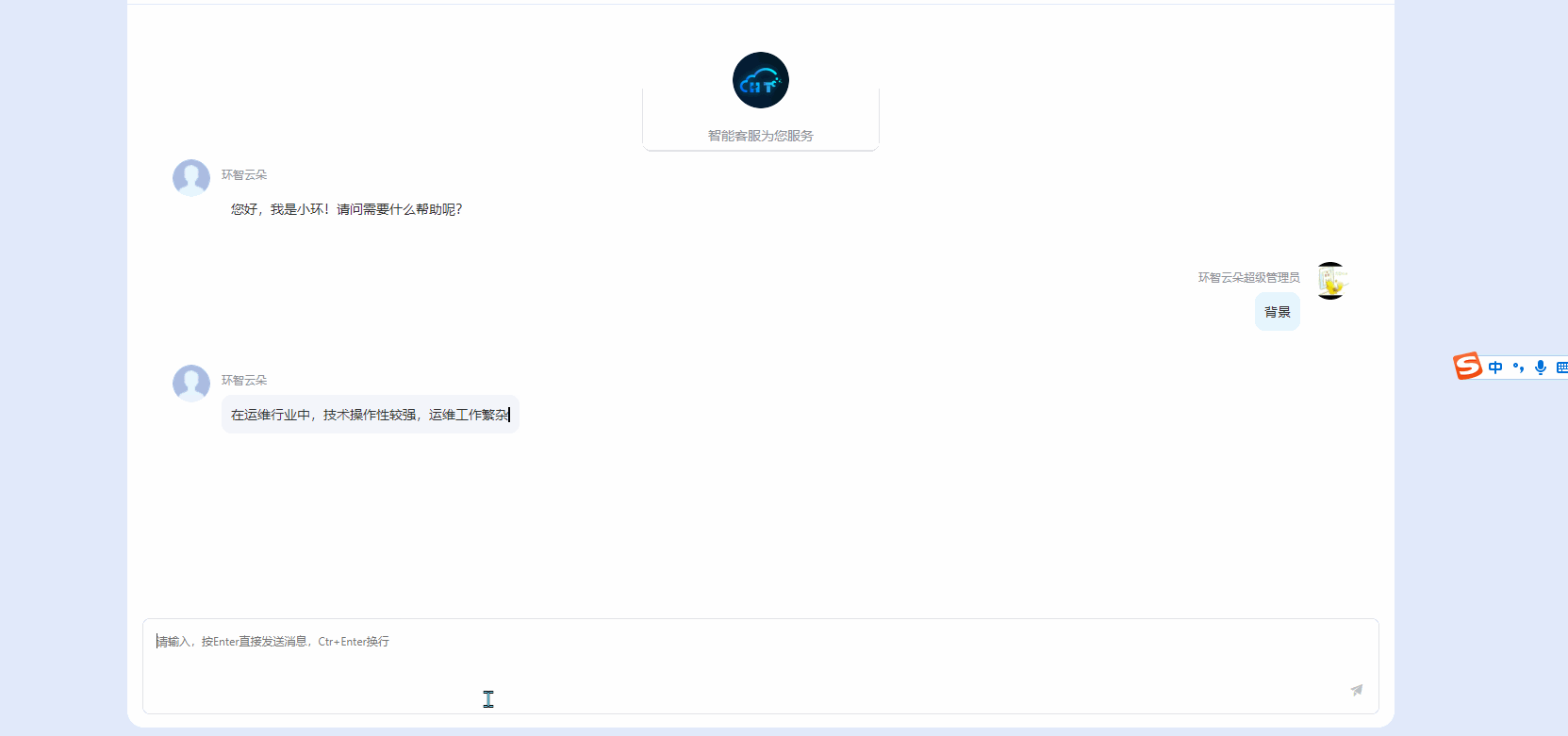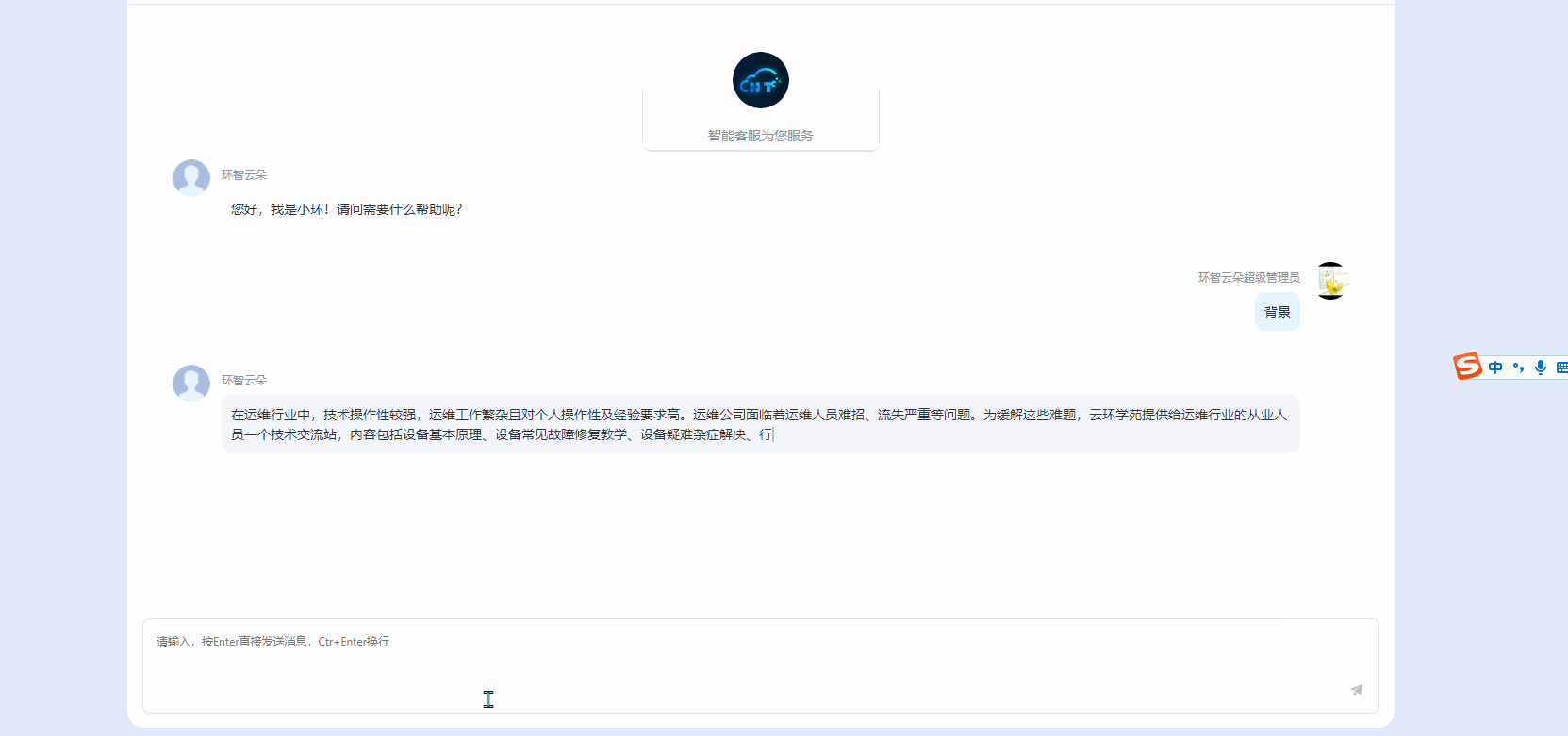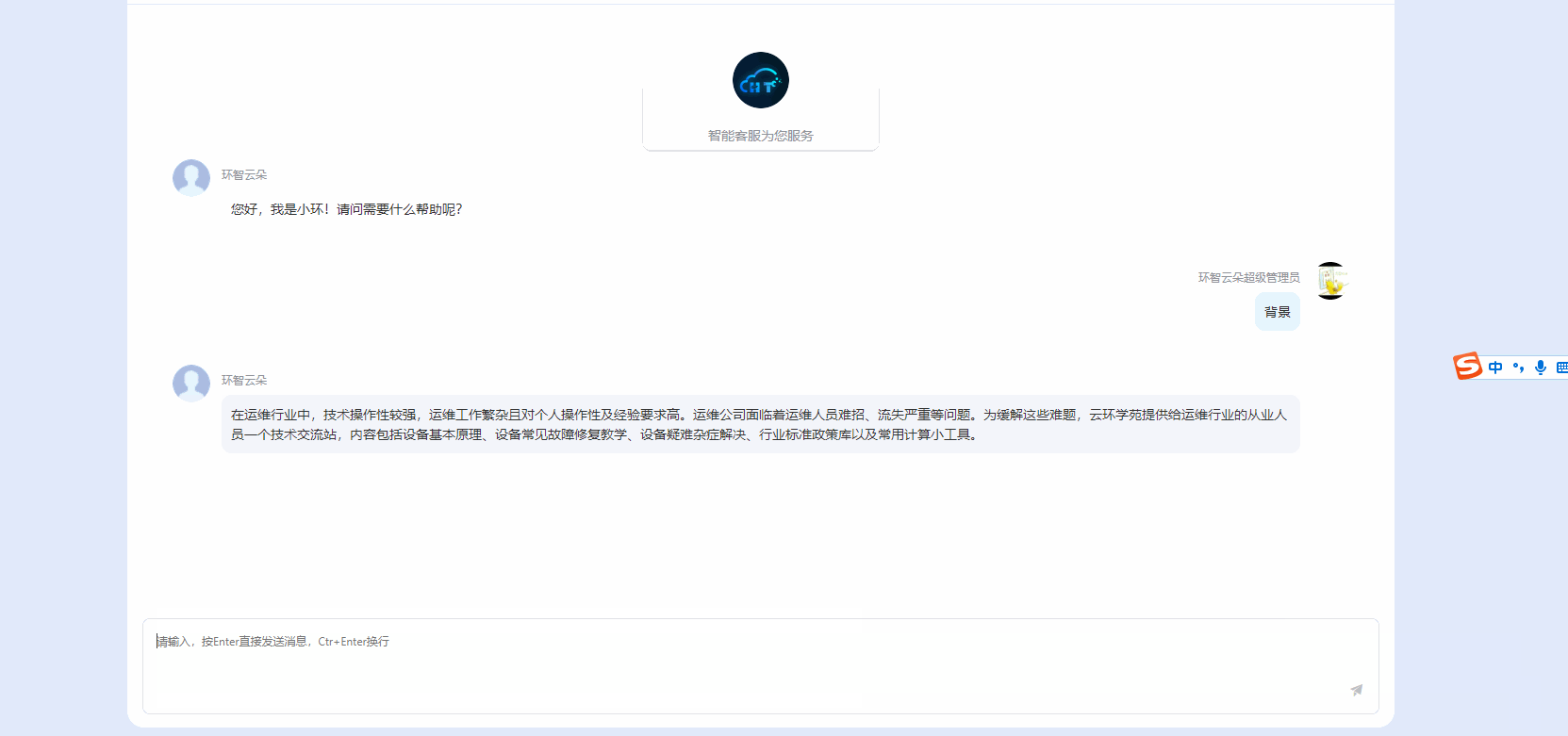
前端对接fastGPT流式数据+打字机效果
首先在对接api时 参数要设置stream: true, const data {chatId: abc,stream: true,//这里true返回流式数据detail: false,variables: {uid: sfdsdf,name: zhaoyunyao,},messages: [{ content: text, role: user }]}; 不要用axios发请求 不然处理不了流式数据 我这里使用fetch …...
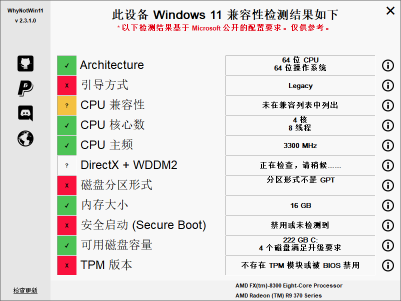
避免使用第三方工具完成电脑环境检测
0. 简介 在之前配置各种深度学习环境的时候经常需要先检测一下电脑的软硬件环境,其实整个过程比较重复和固定,所以我们是否有可能一键检测Python版本、PIP版本、Conda版本、CUDA版本、电脑系统、CPU核数、CPU频率、内存、硬盘等内容这是很多Deepper苦恼…...

vue 中 mixin 的应用场景,原理和合并规则
应用场景 多个组件的相同逻辑可以提出去来一个公共的 mixin 原理 Mixin 的工作原理是将 Mixin 中的选项合并到组件的选项中 合并规则 优先处理 mixinsprops 、method、inject、computed 同名的使用组件内的,不使用mixin 的data 进行合并生命周期和watch 先执行…...

点击按钮(文字)调起elementUI大图预览
时隔一年,我又回来了 ~ 最近在做后台,遇到一个需求,就是点击“查看详情”按钮,调起elementUI的大图预览功能,预览多张图片,如下图: 首先想到的是使用element-ui的el-image组件,但它是…...

手把手教你用OpenMP和CUDA加速ICP配准:从单核到GPU的完整性能对比
手把手教你用OpenMP和CUDA加速ICP配准:从单核到GPU的完整性能对比 ICP(Iterative Closest Point)算法是点云配准领域的经典方法,但在处理大规模点云时常常面临性能瓶颈。本文将深入探讨如何利用OpenMP和CUDA技术对ICP算法进行多线…...

【Proteus仿真】SRF04超声波阈值预警系统设计与LCD1602交互实现
1. SRF04超声波测距原理与硬件连接 SRF04超声波模块是工业测距的经典选择,它通过发射40kHz的声波并计算回波时间差来测量距离。在实际项目中,我发现很多初学者容易忽略声速受温度影响的问题——常温下声速约343m/s,但温度每升高1℃࿰…...

Arm Ethos-U85 NPU架构解析与边缘AI优化实践
1. Arm Ethos-U85 NPU架构解析:边缘AI的算力引擎在嵌入式AI领域,算力与功耗的平衡始终是核心挑战。Arm Ethos-U85 NPU的诞生,为Cortex-M/A系列处理器提供了专用的神经网络加速方案。这款NPU采用独特的微架构设计,支持TOSA标准指令…...

Java 枚举类型:3个经典应用场景与实战案例
Java 枚举类型:3个经典应用场景与实战案例枚举( enum )是 Java 中一种特殊的类,它通过固定的常量集合来表示有限且离散的状态,不仅能提升代码可读性,还能避免魔法值、减少错误,是后端开发中非常…...

OpenFold实战指南:在Linux系统部署蛋白质结构预测模型
1. 从仰望到上手:OpenFold如何让蛋白质结构预测走进寻常实验室去年AlphaFold2横空出世,几乎以一己之力解决了困扰生物学界半个世纪的“蛋白质折叠问题”,其意义不亚于在生命科学领域投下了一颗重磅炸弹。一时间,无论是结构生物学家…...

企业内部分享Taotoken在代码审查与生成场景下的应用实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内部分享Taotoken在代码审查与生成场景下的应用实践 在软件开发团队中,代码审查与代码生成是提升代码质量、保障项…...

3 万粉丝公众号变现实录:技术社区如何做到月入 5 万 +
摘要:从 0 到 3 万 粉丝,3 万 社群成员,一个技术类公众号的完整运营路径。本文拆解内容定位、合作模式、变现策略,全是实操经验,没有虚的。 封面文案:技术公众号变现全攻略 开篇:说实话&…...

API管理平台能力与数据盘点
API管理平台是现代企业IT架构中的核心组件,承担着接口设计、发布、运维、安全管控及生态开放等关键职责。不同平台在功能深度、性能指标和行业实践上各有积累。本文基于公开资料,对五款API管理平台的核心能力与关键数据进行客观梳理,以表格与…...

注意力机制新思路:拆解CoordAttention,看它如何用两个1D全局池搞定“位置+通道”信息
注意力机制新思路:拆解CoordAttention,看它如何用两个1D全局池搞定“位置通道”信息 在计算机视觉领域,注意力机制已经成为提升模型性能的关键组件。传统的通道注意力机制(如SE模块)虽然能有效建模通道间关系ÿ…...

Parabolic视频下载工具:三步完成200+网站视频下载的终极方案
Parabolic视频下载工具:三步完成200网站视频下载的终极方案 【免费下载链接】Parabolic Download web video and audio 项目地址: https://gitcode.com/GitHub_Trending/pa/Parabolic 你是否还在为寻找一款简单易用、功能强大的视频下载工具而烦恼࿱…...