【LeetCode】回溯算法类题目详解
所有题目均来自于LeetCode,刷题代码使用的Python3版本

回溯算法
回溯算法是一种搜索的方法,在二叉树总结当中,经常使用到递归去解决相关的问题,在二叉树的所有路径问题中,我们就使用到了回溯算法来找到所有的路径。
回溯算法本质就是去穷举,性能并不是那么高效。一般为了提高效率,往往回溯算法会跟剪枝操作相结合。
回溯算法通常可以用来解决一些问题,这也是为什么会有回溯算法的原因
- 组合问题
- N个数里面按照一定规则找出k个数的集合。组合不强调元素的顺序
- 切割问题
- 一个字符串按一定规则有几种切割方式
- 分割回文串
- 复原IP地址
- 一个字符串按一定规则有几种切割方式
- 子集问题
- 一个N个数的集合里有多少符合条件的子集
- 排列问题
- N个数按照一定规则全排列,有几种排列方式。排列强调元素的顺序
- 棋盘问题
- N皇后、解数独问题
理解回溯
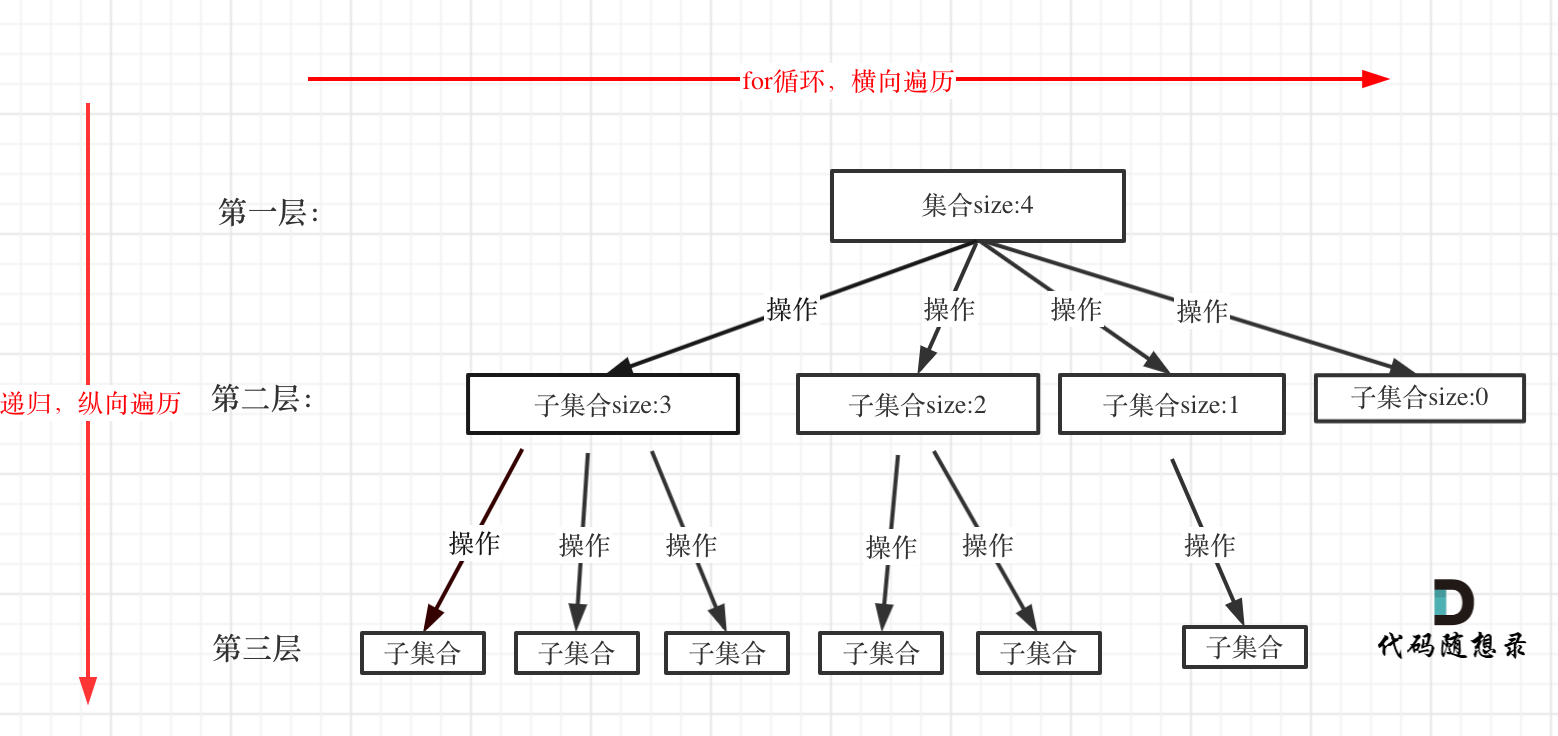
回溯法解决的问题都可以抽象为树形结构,回溯算法解决问题都是在集合中递归查找子集,集合的大小构成了树的宽度,递归的深度构成了树的深度。
递归必须要有终止条件,所以一定是一个高度有限的N叉树。
回溯模板
递归三部曲:
- 返回值及参数
- void backtracking(参数)
- 回溯函数的终止条件
- 回溯搜索的遍历过程
void backtracking(参数) {if (终止条件) {存放结果;return;}for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {处理节点;backtracking(路径,选择列表); // 递归回溯,撤销处理结果}
}
练习题
77、组合
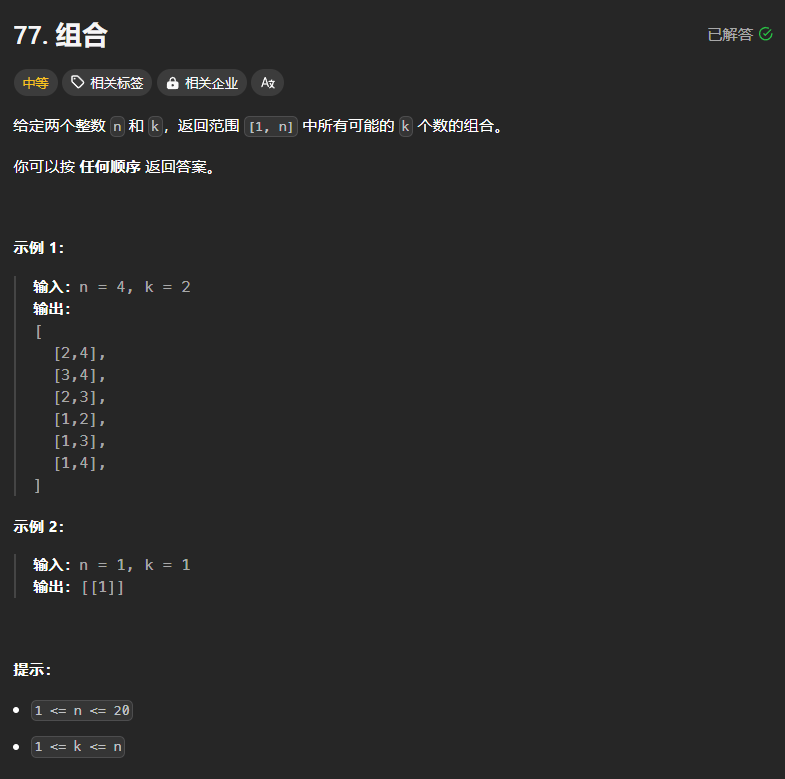
class Solution:def combine(self, n: int, k: int) -> List[List[int]]:def backtracking(n,k,startindex,path):if len(path)==k:# 这里需要注意,因为列表在Python中是可变数据类型,后面的修改会导致path变为[]res.append(path[:])return # 这里的startindex代表的是在单层递归中需要遍历的次数 从startindex一直到n寻找符合条件的数for i in range(startindex, n+1):path.append(i)backtracking(n,k,i+1,path)a = path.pop()res = []backtracking(n,k,1,[])return res
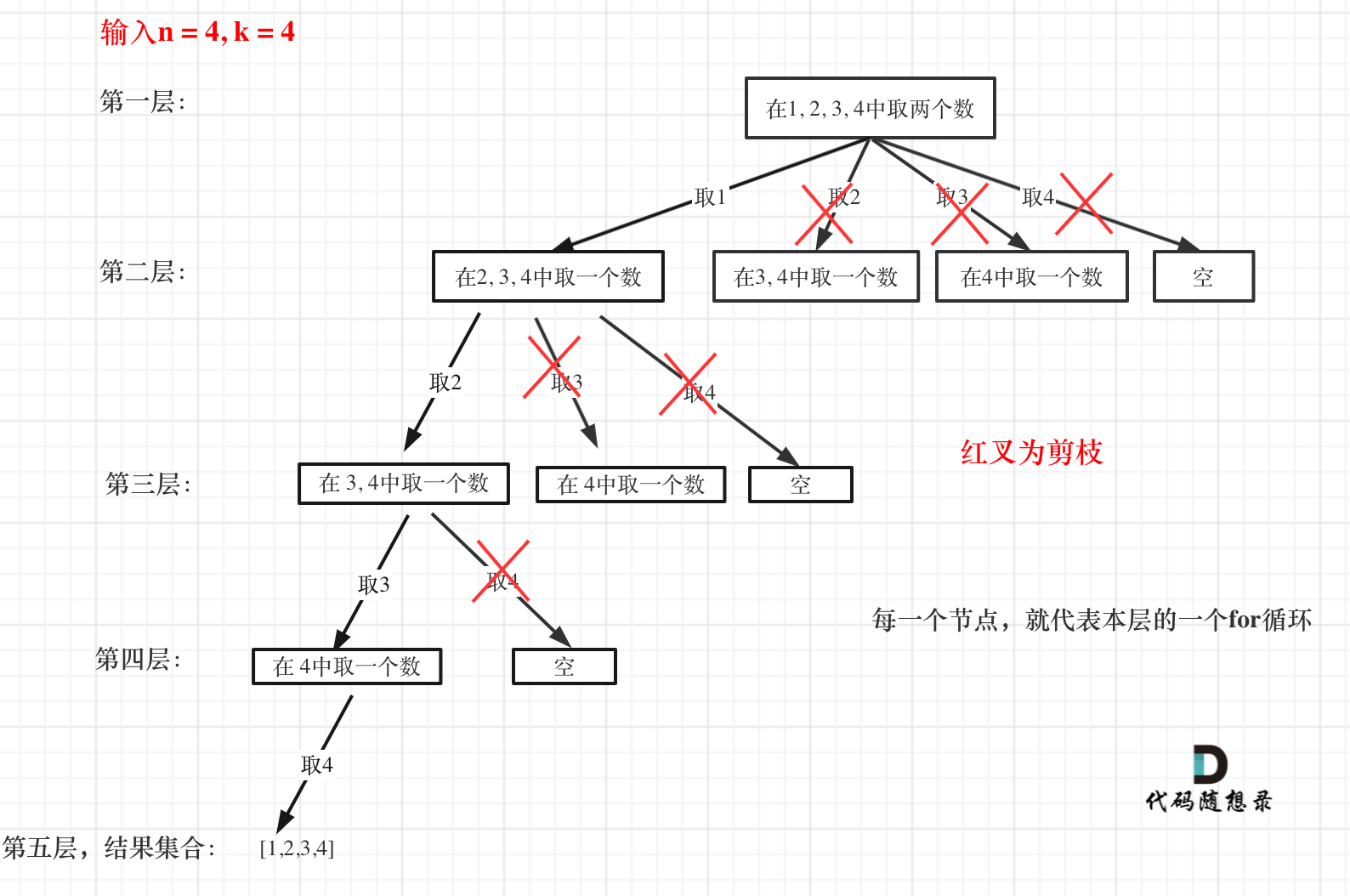
回溯+剪枝
使用剪枝的原理就在于如果剩余的元素个数已经小于k-len(path)的时候,我们就不再往下继续了。
- 已经选择过的元素个数:
len(path) - 还需要选择的个数:
k-len(path) - 在集合中更需要从最多要从下标为
n-(k-len(path))+1开始遍历,在python中因为range循环的时候是左闭右开,所以还需要+1
class Solution:def combine(self, n: int, k: int) -> List[List[int]]:def backtracking(n,k,startindex,path):if len(path)==k:# print(path)# 这里需要注意,因为列表在Python中是可变数据类型,后面的修改会导致path变为[]res.append(path[:])return for i in range(startindex, n-(k-len(path))+1+1):path.append(i)backtracking(n,k,i+1,path)# 回溯 退出上一个元素path.pop()res = []backtracking(n,k,1,[])return res
2024更新代码:【传递的参数不要过多,题目已经给出的参数就不需要再进行传递了】
class Solution:def combine(self, n: int, k: int) -> List[List[int]]:res = []def backtracking(startIndex, path):if len(path) == k:res.append(path[:])returnfor i in range(startIndex, n - (k - len(path)) + 1 + 1):path.append(i)backtracking(i + 1, path)path.pop()backtracking(1, [])return res

216、组合总数III

利用回溯代码模板。其中需要注意的是,如果path列表的和已经超过n,那么可以直接进行剪枝,除此之外,如果剩余的数字长度小于k-len(path)的话,就可以不用继续循环了,这一点也方便我们进行剪枝。
递归的三要素
- 返回值和参数
def backtracking(n,k,startindex,path):pass
- 递归终止条件
if sum(path)>n:return
if len(path)==k and sum(path)==n:res.append(path[:])return
- 递归体部分
for i in range(startindex,9 - (k - len(path)) + 1 + 1):path.append(i)backtracking(n,k,i+1,path)path.pop()
代码
class Solution:def combinationSum3(self, k: int, n: int) -> List[List[int]]:def backtracking(n,k,startindex,path):# 剪枝if sum(path)>n:return if len(path)==k and sum(path)==n:res.append(path[:])returnfor i in range(startindex,9 - (k - len(path))+1+1):path.append(i)backtracking(n,k,i+1,path)path.pop()res = []backtracking(n,k,1,[])return res
17、电话号码的字母组合

思路
本题类似于组合问题,需要根据输入的数字对其能够涵盖的字母进行组合,需要解决下面几个问题:
- 数字和字母如何进行映射
- 采用一个列表,位置0和位置1的地方空出来,从2开始对应号码上的字母,用字符串表示
- 两个字母两个for循环,三个字母三个for循环,多个字母多个for循环
- 输入异常字母如何进行处理?
- 对于空的digits需要返回一个空列表
递归三要素
- 递归的参数
参数是digits和index,其中digits是题目给出的字符串,如“23”,而index是记录当前已经遍历到第几个数字了。【实际可以不用digits】
- 递归结束的条件
如果index的长度和digits长度一样的话,直接return
if index==len(digits):res.append(path) # 这里的path被定义为字符串 而字符串在python中是不可变数据类型,因此可以直接用return
- 递归体部分
需要注意的是,回溯的时候对于字符串要想去掉最后一个字符的方法是直接s=s[:-1]。
# 获取字符串中的数字
mynum = int(digits[index])
# 获取电话号码对应的字符组合
char = myhash[mynum]
for i in range(len(char)):path+=char[i]backtracking(digits, index+1, path)path = path[:-1] # 刨去字符串的最后一个字符
本题是不需要startindex的,因为遍历的不是同一个集合,而是不同的集合。在回溯问题中,如果是遍历同一个集合就需要传递一个参数startindex,用来表示的当前遍历到集合中的第几位。
本题通过index来判断目前遍历到第几个数字,并且index是通过充当函数的参数来实现的。
class Solution:def letterCombinations(self, digits: str) -> List[str]:myhash = ["","","abc","def","ghi","jkl","mno","pqrs","tuv","wxyz"]res = []s = ""def backtracking(digits, index):nonlocal sif index==len(digits):res.append(s)return # digit表示digits中的数字digit = int(digits[index])# letters表示digit所代表的数字对应的字母有哪些letters = myhash[digit]# for循环遍历这些字母 for i in range(len(letters)):s+=letters[i]# 进行回溯backtracking(digits,index+1)s = s[:-1]if len(digits)==0:return resbacktracking(digits,0)return res
本题有一个需要特殊处理的地方,如果digits为空字符串的话,直接返回空列表,不需要在进行递归回溯了。
class Solution:def letterCombinations(self, digits: str) -> List[str]:if len(digits)==0:return []numList = ["", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"]res = []s = ""def backtracking(index):nonlocal sif len(digits) == len(s):res.append(s)returndigit = int(digits[index])chars = numList[digit]for i in range(len(chars)):s+=chars[i]backtracking(index+1)s = s[:-1]backtracking(0)return res
39、组合总数


本题中说了candidates中的同一个数字可以无限制重复被选取,所以我们在进行递归的时候,传递的startindex就是i。
这里需要注意的是:每次需要传入startIndex的原因是可以避免选取之前已经取过的数字
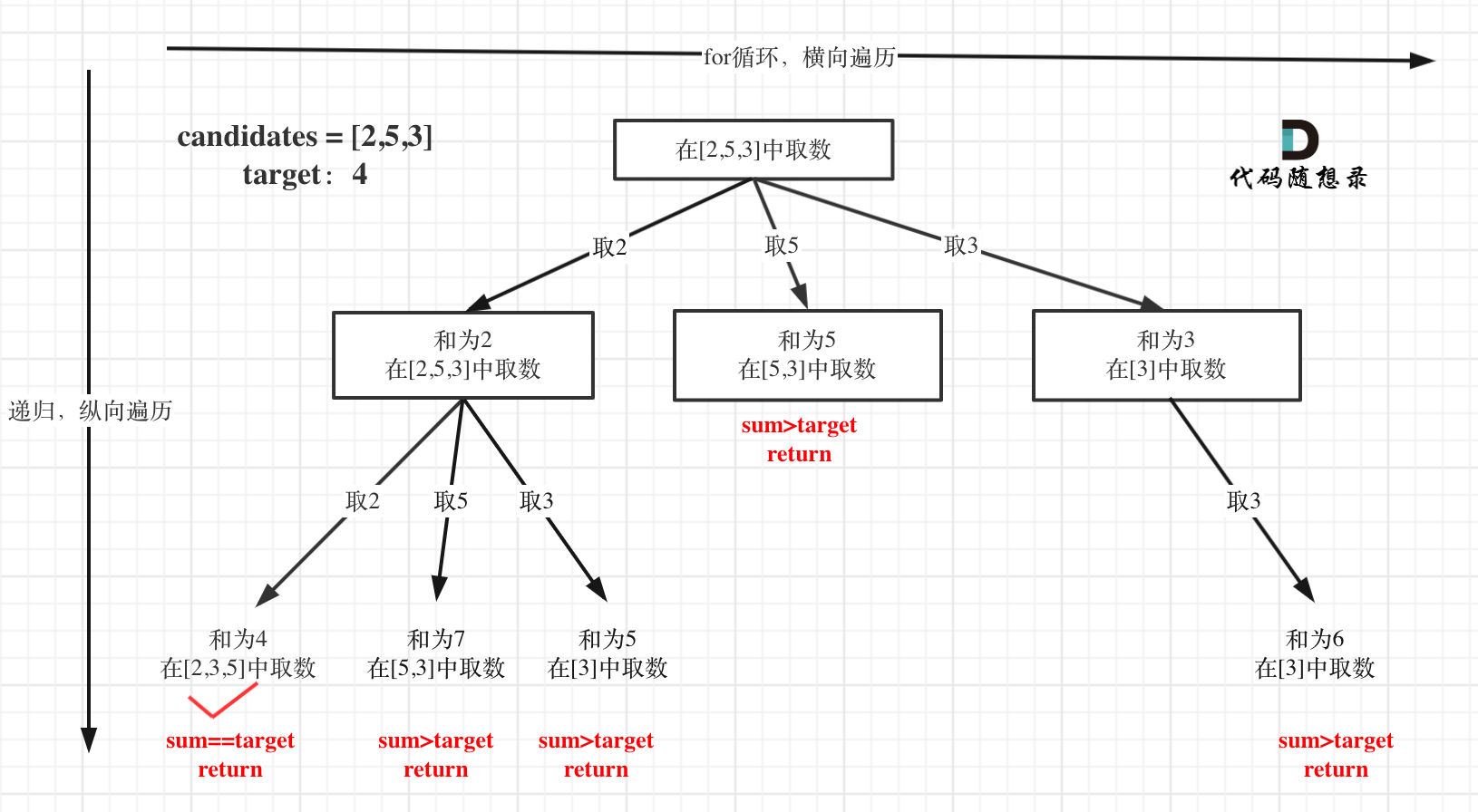
本题中需要注意及时剪枝(即当sum_>target之后就可以不用往下进行回溯了),并且可以使用一个累加的sum_代替掉使用内置的sum方法,节省时间开销。
class Solution:def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:res = []sum_ = 0def backtracking(startIndex, path):nonlocal sum_if sum_ > target:returnif sum_ == target:res.append(path[:])returnfor i in range(startIndex, len(candidates)):path.append(candidates[i])sum_ += candidates[i]backtracking(i, path)sum_ -= path.pop()backtracking(0, [])return res
40、组合总数II(*)
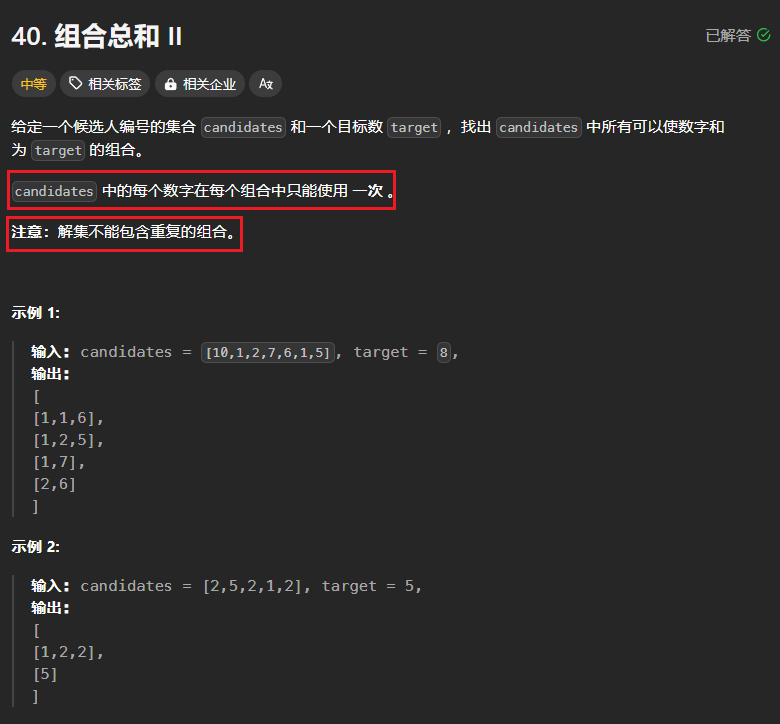
本题需要注意的是,跟前面不同的地方在于每个数字在每个组合中只能使用一次,同时在解集中不能包含重复的组合。因此想到设置一个used数组来表示每个元素是否已经被访问过。 此处也可以不使用used数组
其中candidates数组需要进行排序,这样能够保证如果数字相同的情况下,只会使用一次。
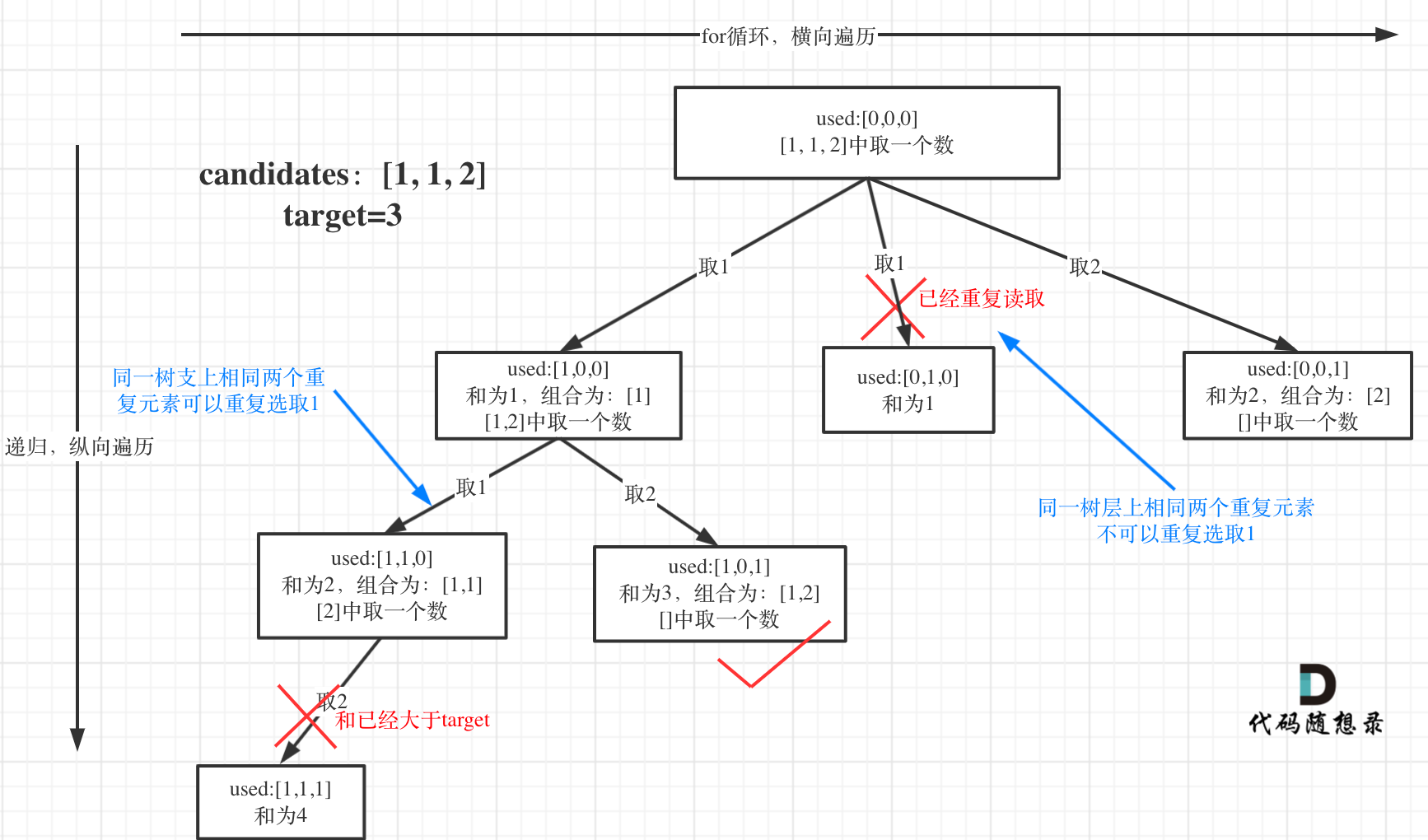
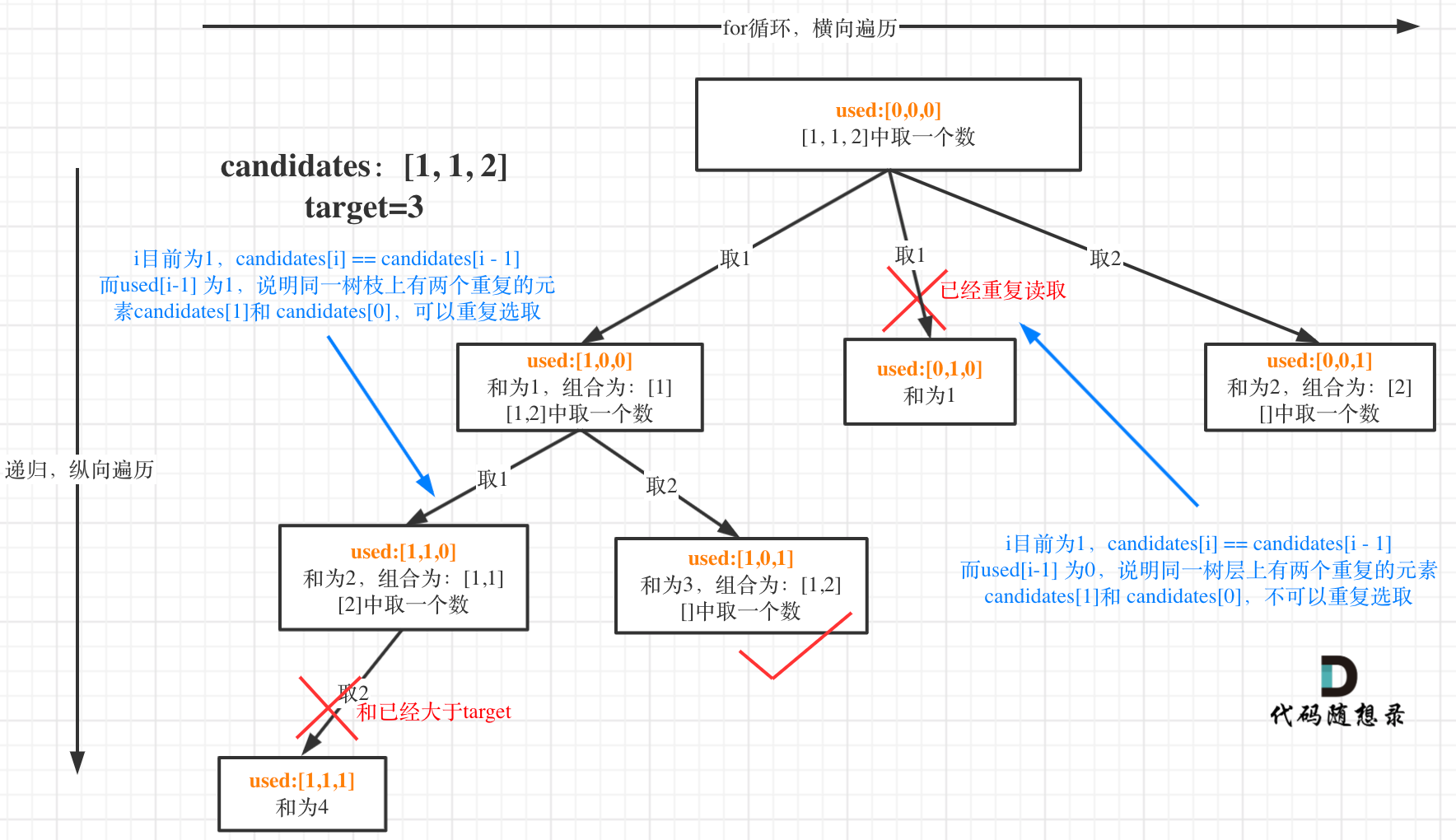
要去重的是同一层上是否使用过,可以看出在candidates[i] == candidates[i - 1]相同的情况下:
- used[i - 1] == true,说明同一树枝candidates[i - 1]使用过
- used[i - 1] == false,说明同一树层candidates[i - 1]使用过
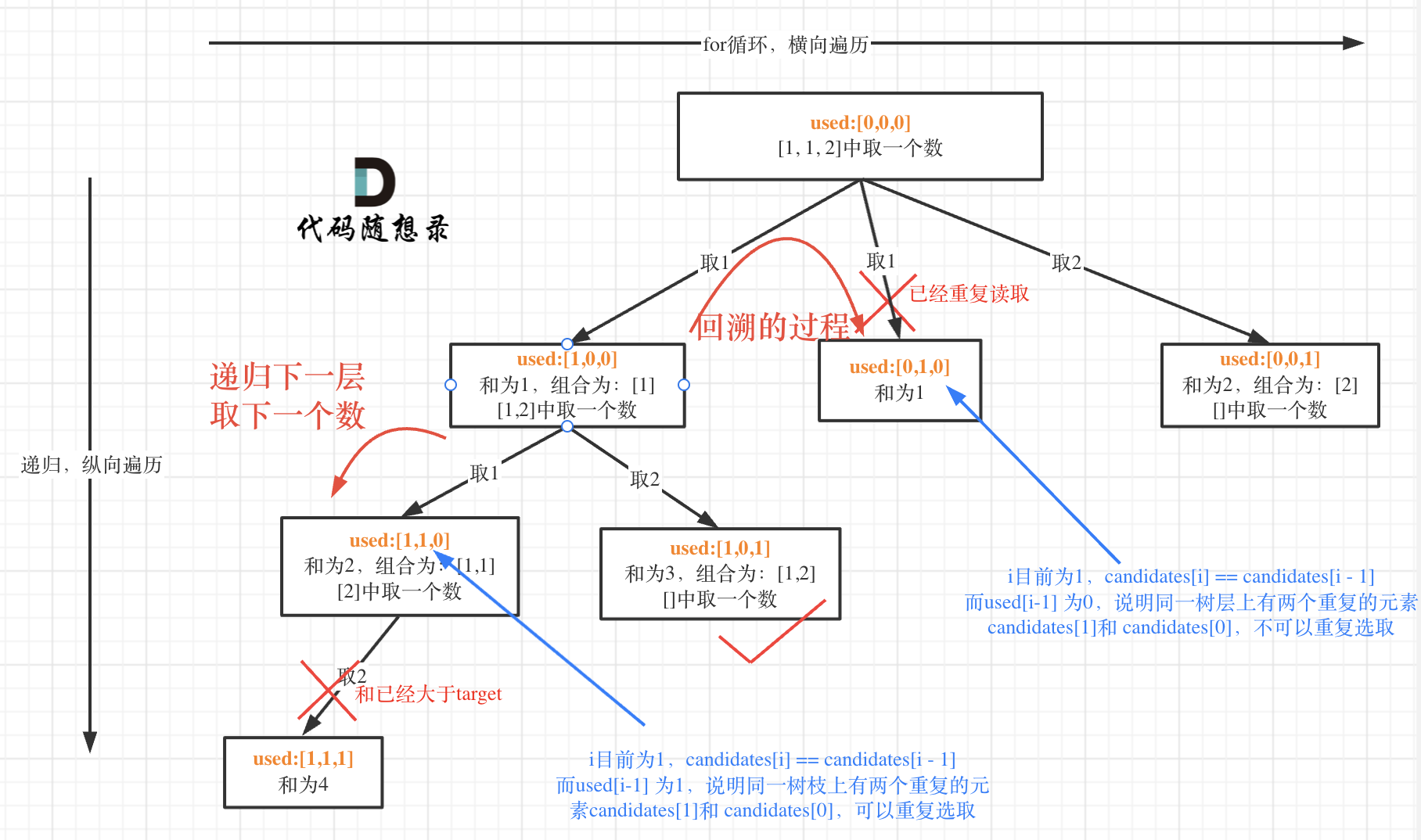
class Solution:def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:res = [] # 用于记录返回结果sum_ = 0def backtracking(candidates,target,path,startindex,used):nonlocal sum_if sum_>target:return if sum_==target:res.append(path[:])return for i in range(startindex,len(candidates)):if i>startindex and candidates[i]==candidates[i-1] and not used[i-1]:continuepath.append(candidates[i])sum_+=candidates[i]used[i]=Truebacktracking(candidates,target,path,i+1,used)sum_-=candidates[i]used[i]=Falsepath.pop()# candidates需要进行排序,否则相同的数字可能不会连续candidates.sort()backtracking(candidates,target,[],0,[False]*len(candidates))return res
优化 + 不使用used数组
class Solution:def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:res = []def backtracking(candidates,target,startindex,sum_,path):if sum_==target:res.append(path[:])returnfor i in range(startindex, len(candidates)):if i>startindex and candidates[i]==candidates[i-1]:continuesum_+=candidates[i]# 这里进行判断,如果超过target则直接break 免去了后面的循环 节省时间开销 if sum_ > target:breakpath.append(candidates[i])backtracking(candidates,target,i+1,sum_,path)sum_-=candidates[i]path.pop()candidates.sort()backtracking(candidates,target,0,0,[])return res
class Solution:def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:res = []sum_ = 0def backtracking(startIndex, path):nonlocal sum_if sum_ > target:returnif sum_ == target:res.append(path[:])returnfor i in range(startIndex, len(candidates)):if i > startIndex and candidates[i] == candidates[i - 1]:continuepath.append(candidates[i])sum_ += candidates[i]backtracking(i + 1, path)sum_ -= path.pop()candidates.sort()backtracking(0, [])return res
131、分割回文串(*)
本题递归结束的条件是当startindex==字符串s 的长度时,往结果集中添加数据并返回。
递归的参数是startindex,和path,需要进行递归的字符串为s[startindex:i+1]进行切片,同时本题要求是回文子串,所以还需要加上判断是否是回文数字,如果是回文数字才进行回溯,不是回文数字的话不进行任何操作。
在递归体部分,需要一个for循环,其遍历范围是startindex到len(s),然后往path列表中添加的元素是s[startindex:i+1],这里注意字符串的切片是左闭右开的,因此这里区间是i+1,然后递归进行遍历backtracking(s,i+1,path),注意这里的startindex需要从i+1开始,这是因为根据题目的要求,不会有重复出现的子串。
在**【39、组合总数】**一题中,题目说明candidates中的元素是可以重复出现的,因此我们在进行递归的时候传入的startindex就为for循环遍历的层数i,这样就可以一直递归下去找到符合条件的答案。但是本题中不能出现重复的所以传入的参数是i+1
递归三要素
- 参数和返回值
def backtracking(s, startindex, path):
- 递归终止条件
if startindex==len(s):res.append(path[:])return
- 递归体 单层搜索过程
for i in range(startindex,len(s)):if huiwen(s[startindex:i+1]):path.append(s[startindex:i+1])backtracking(s,i+1,path)path.pop()
全部代码:
class Solution:def partition(self, s: str) -> List[List[str]]:res = []def backtracking(s,startindex,path):# print(startindex)# 如果分割到字符串末尾,则该轮结束if len(s)==startindex:res.append(path[:])for i in range(startindex,len(s)):# print(s[startindex:i+1])# 如果不是回文子串 不往path中添加if huiwen(s[startindex:i+1]):path.append(s[startindex:i+1])backtracking(s,i+1,path)path.pop()def huiwen(s):return True if s==s[::-1] else False# i = 0# j = len(s)-1# while i<j:# if s[i]!=s[j]:# return False# i+=1# j-=1# return Truebacktracking(s,0,[])return res

93、复原IP地址(*)
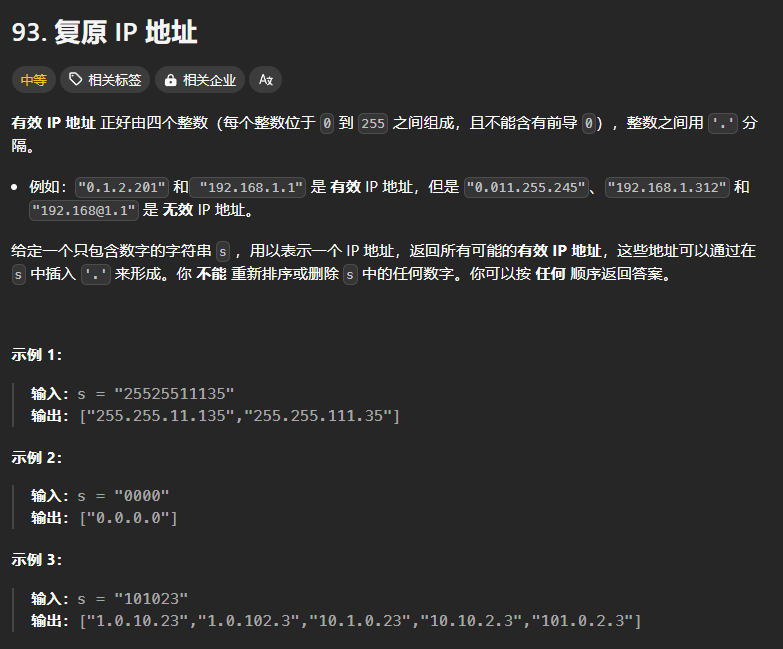

本题与分割字符串有几分相似,也属于分割问题。
递归三要素
- 递归参数
字符串s,startindex和pointNum
pointNum表示IP地址中的.,如果有三个.的话,就说明当前的IP地址已经被分成四段了。
- 递归结束的条件
根据本题要求,只要我们当前的字符串已经被分割成四段,即pointNum==3的时候,往res列表中添加结果并返回
- 单层递归体中的操作
for i in range(startindex, len(s)):# IP 地址合法性剪枝if isValid(s[startindex:i+1]):sub = s[startindex:i+1]# 这里不能直接修改 path,而是使用一个副本进行传参backtracking(i + 1, path + sub + ".", pointNum + 1)else:break
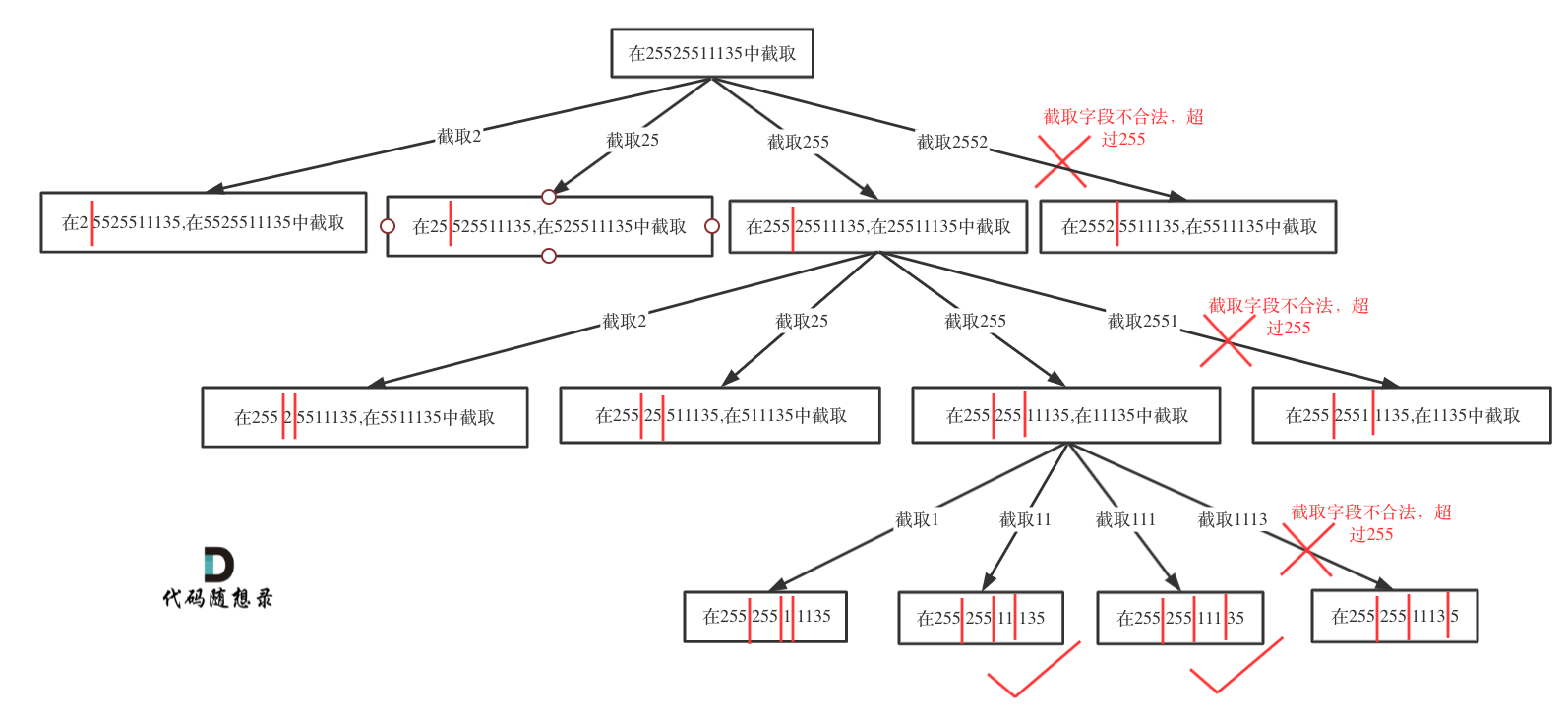
校验逻辑:
- 每一段以0开头则不合法
- 每一段有非正整数数字不合法
- 每一段数字如果大于255则不合法
def isValid(s):if len(s) == 0 or (s[0] == "0" and len(s) > 1) or int(s) > 255:return Falsereturn True
完整代码
class Solution:def restoreIpAddresses(self, s: str) -> List[str]:res = []def backtracking(startindex, path, pointNum):# 长度剪枝if len(s) - startindex > (4 - pointNum) * 3:returnif len(s) - startindex < (4 - pointNum):returnif pointNum == 3:if isValid(s[startindex:]):res.append(path + s[startindex:])returnfor i in range(startindex, len(s)):# IP 地址合法性剪枝if isValid(s[startindex:i+1]):sub = s[startindex:i+1]# 这里不能直接修改 path,而是使用一个副本进行传参backtracking(i + 1, path + sub + ".", pointNum + 1)else:breakdef isValid(s):if len(s) == 0 or (s[0] == "0" and len(s) > 1) or int(s) > 255:return Falsereturn Truebacktracking(0, "", 0)return res
78、子集
思路:
如果把子集问题抽象成一颗树的话,组合问题和分割问题都是收集树的叶子结点,子集问题是找树的所有结点。
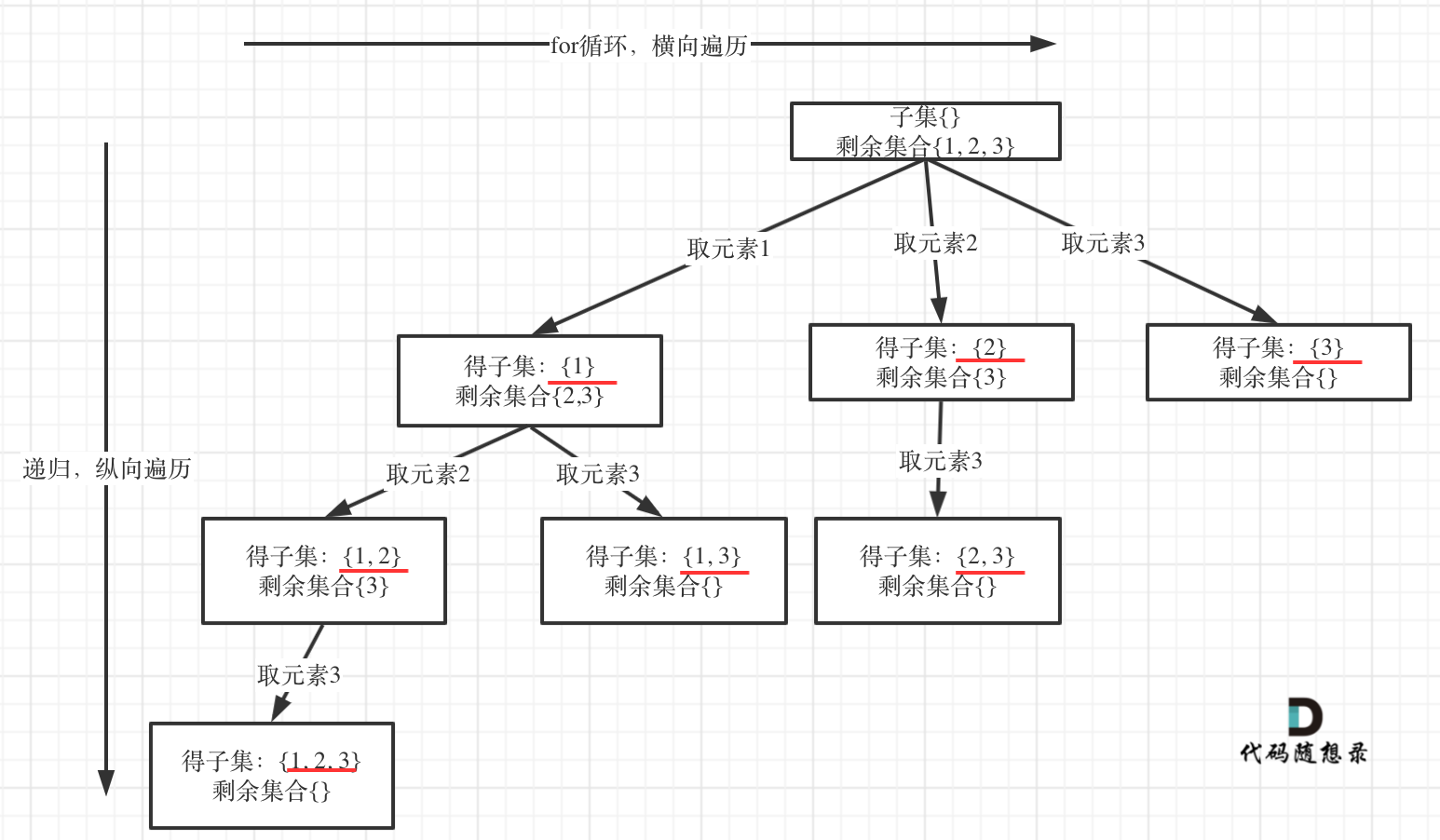
子集是无序的,{1,2}和{2,1}是等价的,也就是说之前取过的元素后面不会再取,因此在递归的过程中还需要传递一个参数startindex,每次都是从startindex继续往后进行搜索,而不是从0开始,如果是排列问题的话,for循环就要从0开始了,因为在排列中{1,2}和{2,1}是两个不一样的排列。
class Solution:def subsets(self, nums: List[int]) -> List[List[int]]:res = []def backtracking(nums,startindex,path):res.append(path[:])# 这里不需要加递归结束的条件,当startindex达到len(nums)的时候程序也就自动返回了for i in range(startindex,len(nums)):path.append(nums[i])backtracking(nums,i+1,path)path.pop()backtracking(nums,0,[])return res
90、子集II(*)
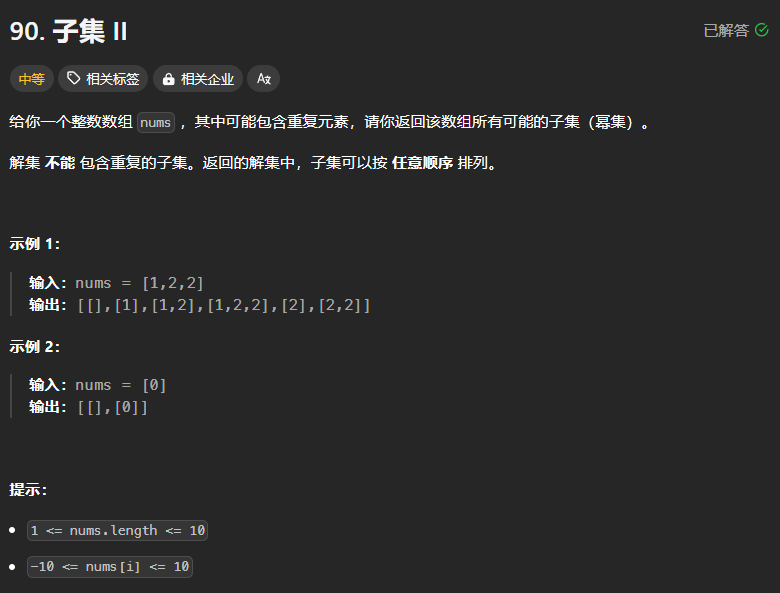
本题和上一题的区别在于nums数组中可能包含重复元素,我们首先将其进行排序,然后在往res列表中添加数据的时候,进行判断只有不在res列表中的结果才能添加进去。其余部分和上一题一样。
- 使用
in操作去重
class Solution:def subsetsWithDup(self, nums: List[int]) -> List[List[int]]:# nums = list(set(nums))res = []def backtracking(nums, startindex, path):if path not in res:res.append(path[:])if startindex>len(nums):returnfor i in range(startindex,len(nums)):path.append(nums[i])backtracking(nums,i+1,path)path.pop()nums.sort()backtracking(nums,0,[])return res
本题是树层去重,在同一层重复出现的需要去除重复值;树层去重的话需要对数组进行排序。
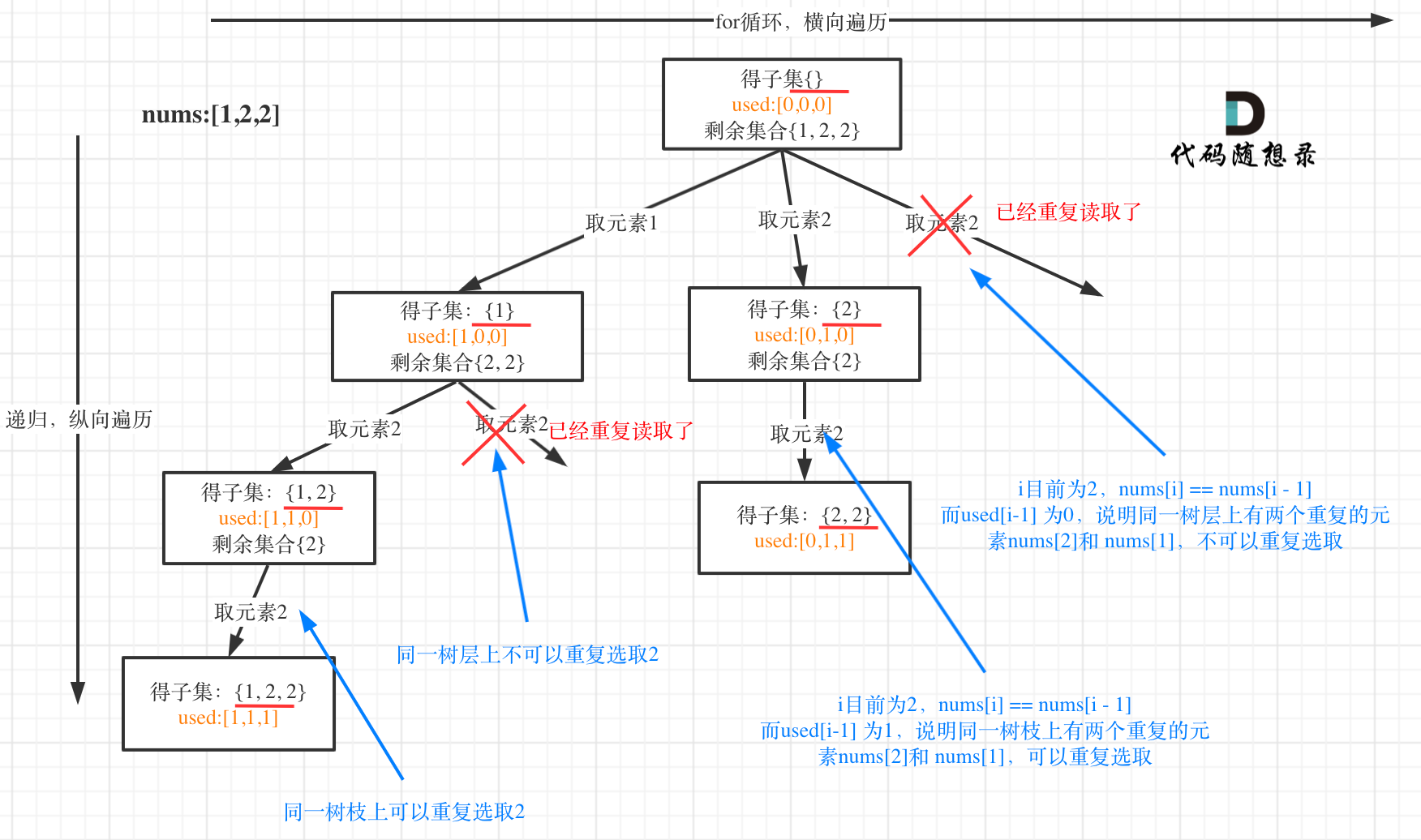
- 直接判断去重
class Solution:def subsetsWithDup(self, nums: List[int]) -> List[List[int]]:res = []def backtracking(startIndex, path):res.append(path[:])for i in range(startIndex, len(nums)):if i > startIndex and nums[i] == nums[i - 1]:continuepath.append(nums[i])backtracking(i + 1, path)path.pop()nums.sort()backtracking(0, [])return res
- 使用used数组去重(推荐)
class Solution:def subsetsWithDup(self, nums: List[int]) -> List[List[int]]:res = []used = [False]*len(nums)def backtracking(nums,startindex,path,used):res.append(path[:])if startindex > len(nums):return for i in range(startindex,len(nums)):if i>0 and nums[i]==nums[i-1] and not used[i-1]:continueused[i] = Truepath.append(nums[i])backtracking(nums,i+1,path,used)used[i] = Falsepath.pop()nums.sort()backtracking(nums,0,[],used)return res
491、递增子序列(*)
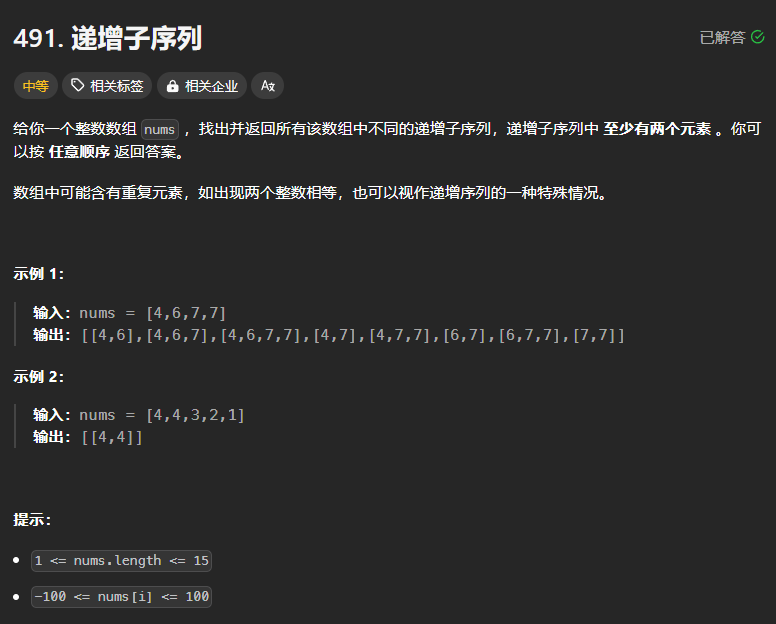
本题需要再输入的序列中找到全部的递增子序列,同时需要注意的是题目中输入的数组会包含重复的元素,并且说明如果出现两个整数相等也会看作是递增序列的一种特殊情况。
利用回溯的思路,我们写出递归的三要素:
- 参数和返回值
参数有:startindex用于记录下一层遍历的起始位置; path 用于记录结果列表
def backtracking(startindex, path):
- 递归终止条件
题目中要求递增子序列中至少2个元素,因此可以判断如果len(path)>1则往res列表中添加结果并返回
这里需要注意,不能加return,加上了return的话,就会导致同一个树枝上的其他结果不能得到保存,这点类似于子集问题,子集问题是需要寻找叶子上的节点。
if len(path)>1:res.append(path[:])# return
- 单层搜索逻辑
本题需要寻找递增子序列,不像之前的题目可以直接通过排序解决去重问题,因此需要使用另一种去重的方式,使用python中的集合,在Python中集合也是一个哈希表,可以在O(1)时间复杂度查询到想要的结果。
这里注意条件是和递增是或者or的关系的,即如果该数字已经在uset中,说明已经使用过了,需要跳过该数字。
同时uset是在每一层都会重新进行定义的,uset只会负责本层的结果。同一个父节点下的一层内如果出现重复数字则直接跳过
这里的一层指的是节点拥有同一个父节点
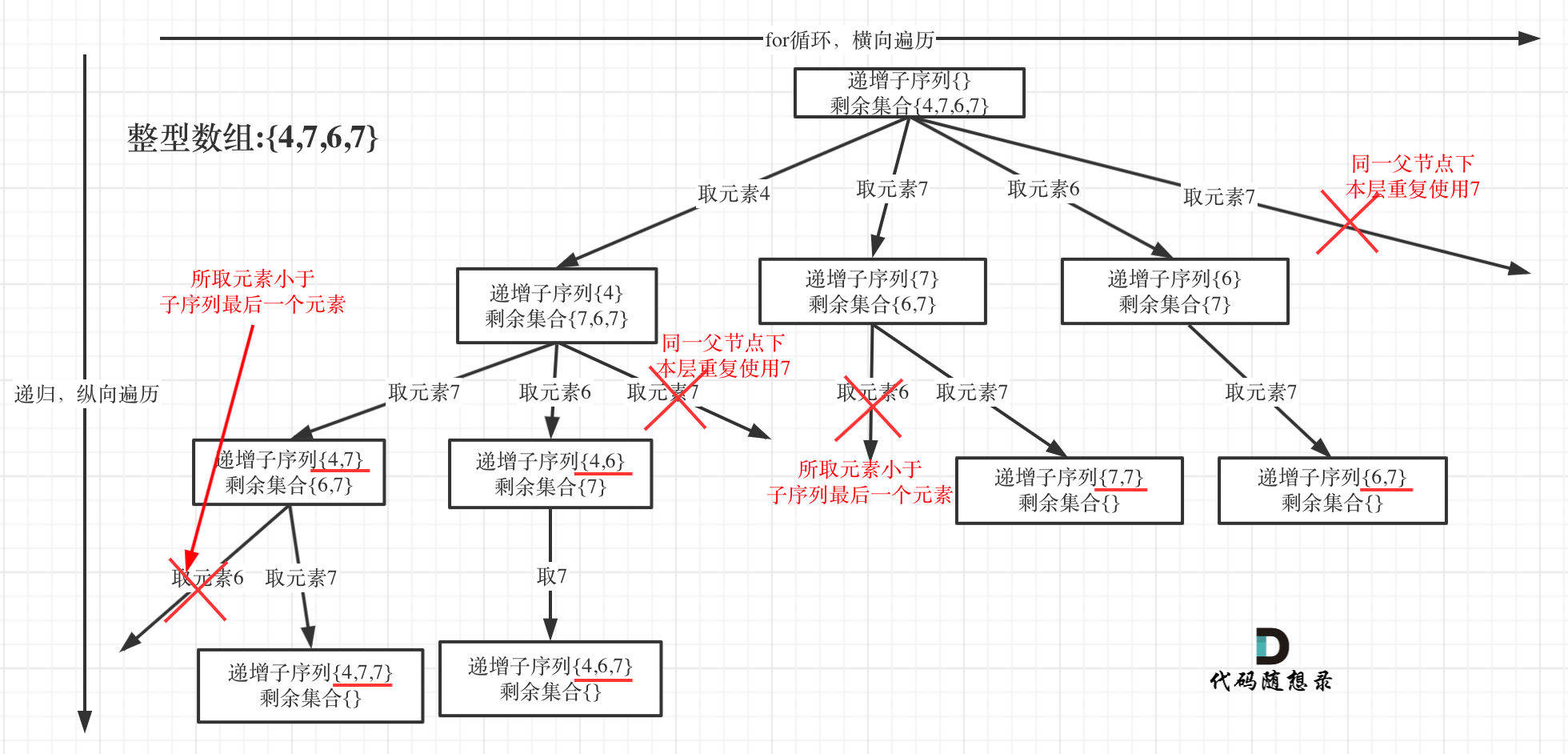
uset = set()
for i in range(startindex, len(nums)):if (path and path[-1]>=nums[i]) or nums[i] in uset:continueuset.add(nums[i])path.append(nums[i])backtracking(nums,i+1,path)path.pop()
完整代码:
class Solution:def findSubsequences(self, nums: List[int]) -> List[List[int]]:res = []def backtracking(startIndex, path):if len(path) > 1:res.append(path[:])uset = set()for i in range(startIndex, len(nums)):if (path and path[-1] > nums[i]) or nums[i] in uset:continueuset.add(nums[i])path.append(nums[i])backtracking(i + 1, path)path.pop()backtracking(0, [])return res
46、全排列
全排列和组合问题、切割问题以及子集问题的区别就在于每次遍历都需要从0开始,而不是传进来的startindex,也就是说全排列问题中是不需要startindex的。
另外在之前的几种问题中,有几个我们传入参数不是i+1而是i的,这是因为题目中说明可以出现重复元素。如果要求是不能出现重复元素的话,只能传入i+1。
本题中因为下标都是从0开始进行遍历的,所以就需要记录哪些数字之前已经被使用过了,所以这里有两个方法:
- 使用used数组进行记录
- 使用uset集合进行记录
上面的这两种方法都需要在函数的参数中进行传递
递归三部曲
- 参数和返回值
def backtracking(path,used):
- 递归终止条件
if len(path)==len(nums):res.append(path[:])return
- 单层搜索逻辑
for i in range(0, len(nums)):if used[i]:continueused[i]=Truepath.append(nums[i])backtracking(nums,path)used[i]=Falsepath.pop()
完整代码:
class Solution:def permute(self, nums: List[int]) -> List[List[int]]:res = []used = [False] * len(nums)def backtracking(path, used):if len(path) == len(nums):res.append(path[:])returnfor i in range(len(nums)):if used[i]:continueused[i] = Truepath.append(nums[i])backtracking(path, used)path.pop()used[i] = Falsebacktracking([], used)return res
使用uset集合避免使用个重复的数组
class Solution:def permute(self, nums: List[int]) -> List[List[int]]:res = []def backtracking(path, uset):if len(path) == len(nums):res.append(path[:])returnfor i in range(len(nums)):if nums[i] in uset:continueuset.add(nums[i])path.append(nums[i])backtracking(path, uset)uset.remove(path.pop())backtracking([], set())return res
47、全排列II(*)

本题因为nums中包含重复的数字,因此需要去重,去重的时候因为需要判断相邻的两个数是否相等,所以在一开始需要对nums进行排序。【排序和重复数字去重是一个配套操作需要一起来】
之后本题的和全排列的区别就在于需要判断相邻的两数是否相等并且前一个数是否没有用过。
for循环是横向遍历,递归是纵向遍历(即沿着树枝进行遍历的效果)
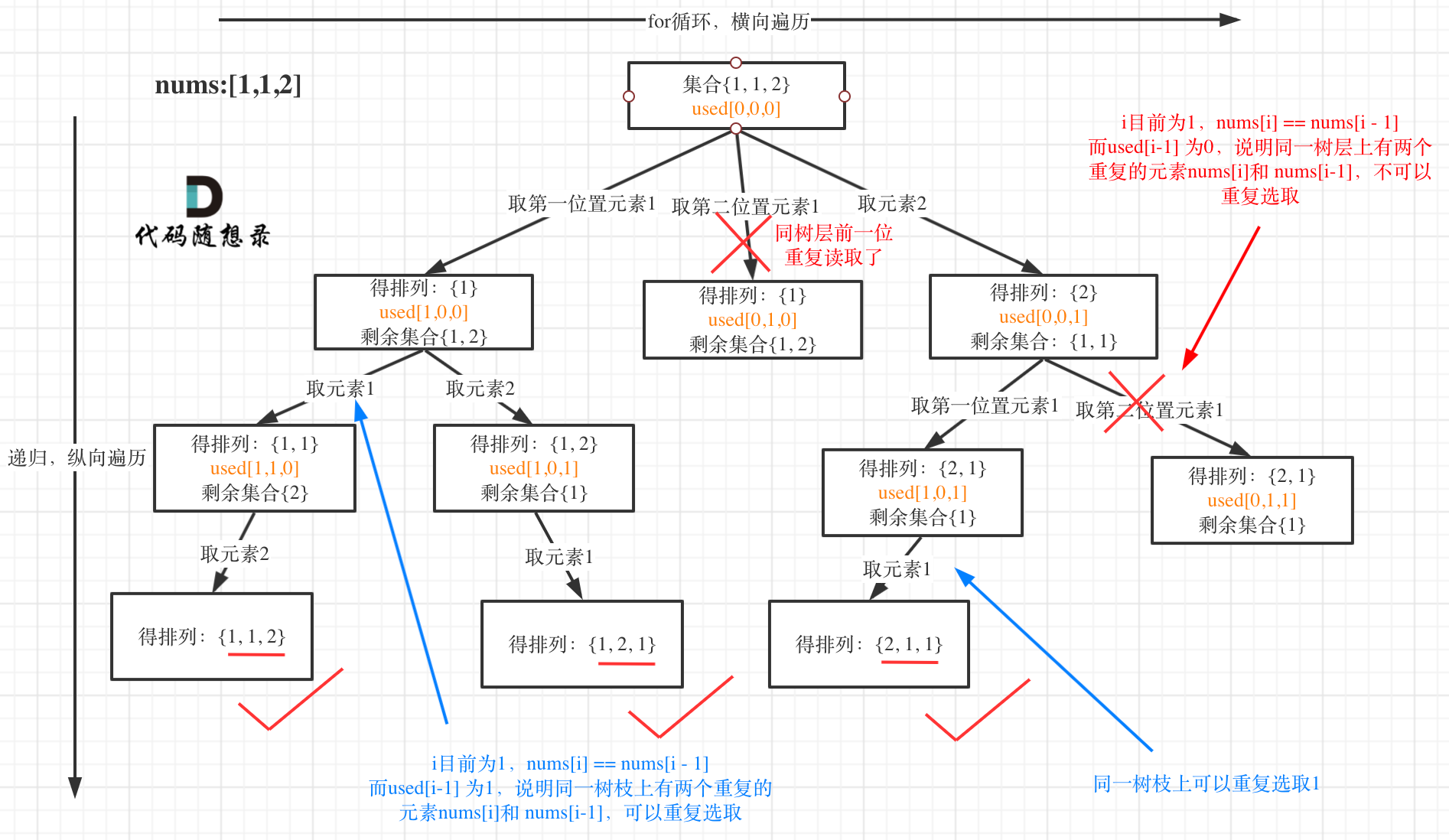
used数组主要使用来记录哪些元素已经使用过了,全排列问题中元素不能重复使用,每个元素都只能适用一次。
class Solution:def permuteUnique(self, nums: List[int]) -> List[List[int]]:res = []def backtracking(path, used):if len(path) == len(nums):res.append(path[:])returnfor i in range(len(nums)):if i > 0 and nums[i] == nums[i - 1] and not used[i - 1]:continueif used[i]:continuepath.append(nums[i])used[i] = Truebacktracking(path, used)path.pop()used[i] = Falsenums.sort()backtracking([], [False] * len(nums))return res
组合问题和排列问题是在树形结构的叶子结点上收集结果,而子集问题就是取树上所有结点的结果。
and not used[i - 1]这部分代码是用来跳过重复的数字,如果前一个数字没有被选取,并且和当前数字值一致,则可以跳过这部分,这样的操作可以避免答案中出现重复的值。
使用uesd数组进行去重:
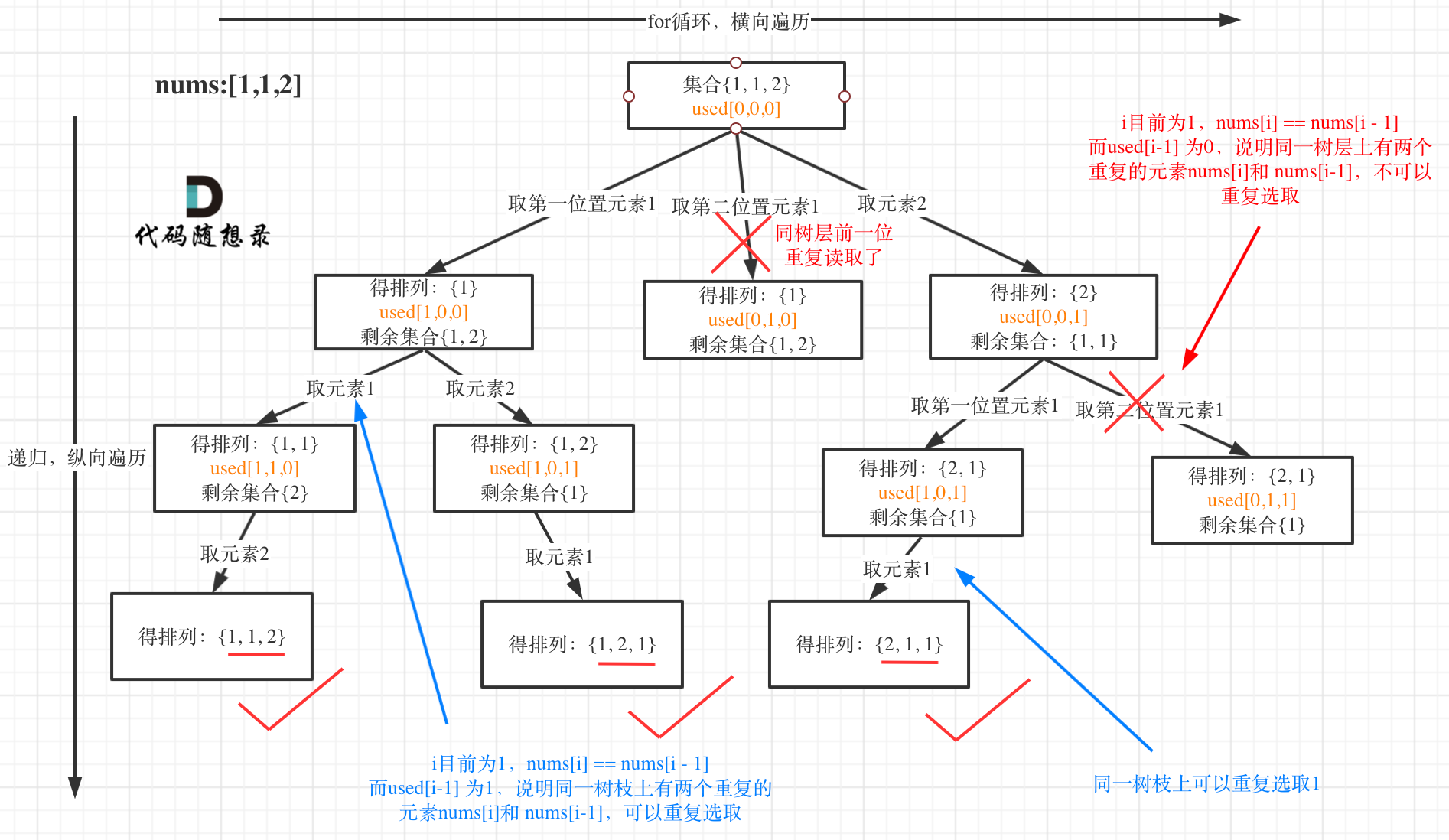
class Solution:def permuteUnique(self, nums: List[int]) -> List[List[int]]:res = []used = [False] * len(nums)def backtracking(path, used):if len(path) == len(nums):res.append(path[:])returnfor i in range(len(nums)):if i>0 and nums[i]==nums[i-1] and not used[i-1]:continueif used[i]:continueused[i] = Truepath.append(nums[i])backtracking(path, used)used[i] = Falsepath.pop()nums.sort()backtracking([], used)return res
784、字母大小写全排列
322、重新安排行程(hard)
51、N皇后

递归参数
定义res来存放最终的结果,n棋盘大小,row记录当前遍历到棋盘的第几层
递归终止条件
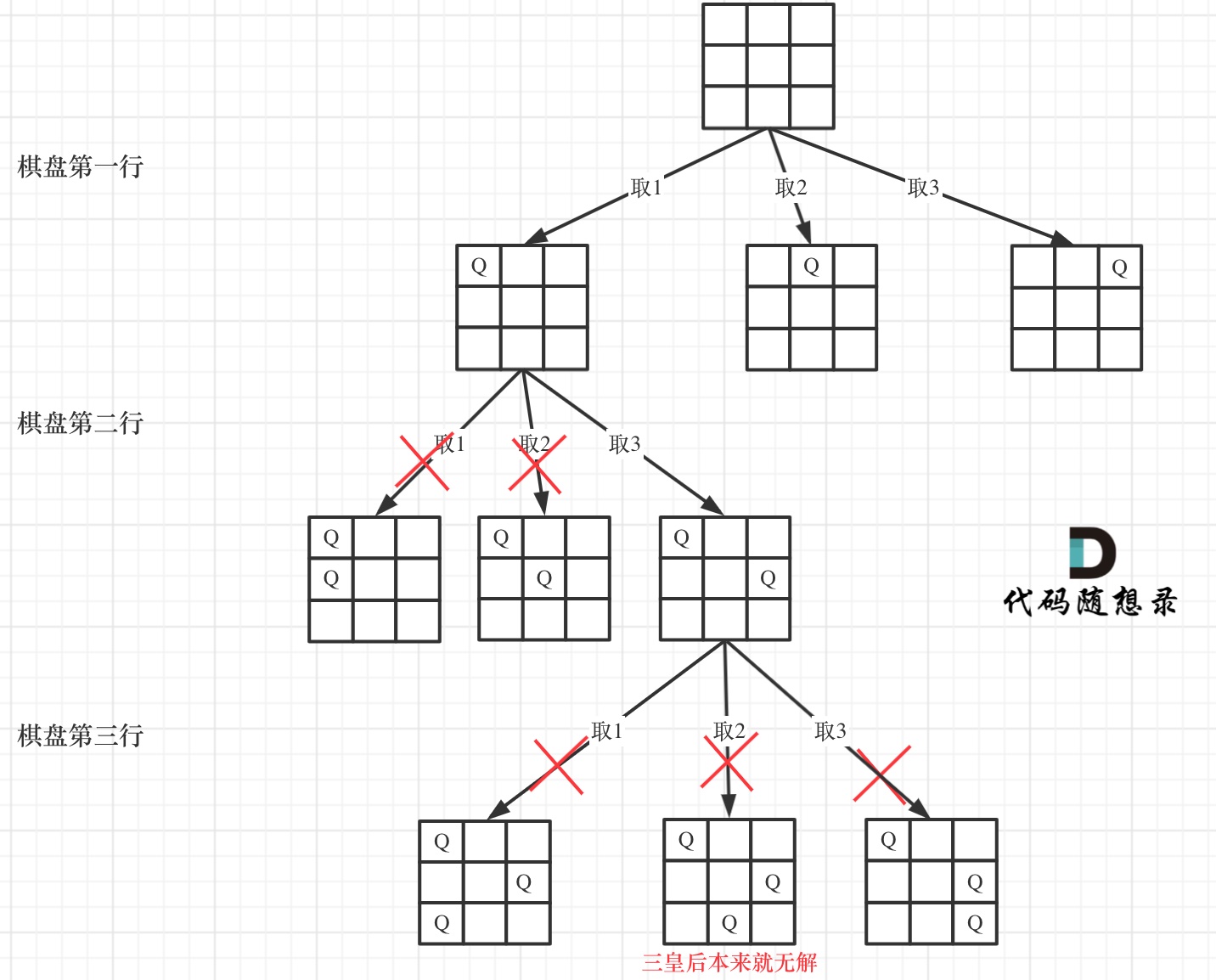
当递归到叶子结点的时候就可以收集结果了。
if row==n:res.append(chessboard)return ;
单层递归逻辑
遍历这个棋盘的每一行,在python中,二维数组的表示就用嵌套列表表示即可。
验证棋盘是否合法
- 皇后不能同行
- 皇后不能同列
- 皇后不能斜对角线(45度和135度)
def isValid(row, col, chessboard):# 列检查for i in range(row):if chessboard[i][col] == "Q":return False# 45°角检查 这里的检查是从row col往前找i,j = row-1,col-1while i>=0 and j>=0:if chessboard[i][j] == "Q":return Falsei-=1j-=1# 135°角检查i,j = row-1, col+1while i>=0 and j<len(chessboard):if chessboard[i][j]=="Q":return Falsei -= 1j += 1return True
class Solution:def solveNQueens(self, n: int) -> List[List[str]]: def backtracking(n,row,chessboard):# 递归终止的条件 当递归参数row==n时就进行发返回 并将结果添加到res中if row==n:res.append(chessboard[:])return# 对棋盘的每一行进行操作 判断是否合法for col in range(n):if isValid(row,col,chessboard):chessboard[row] = chessboard[row][:col] + "Q" + chessboard[row][col+1:]backtracking(n,row+1,chessboard)chessboard[row] = chessboard[row][:col] + "." + chessboard[row][col+1:]def isValid(row, col, chessboard):# 列检查for i in range(row):if chessboard[i][col] == "Q":return False# 45°角检查 这里的检查是从row col往前找i,j = row-1,col-1while i>=0 and j>=0:if chessboard[i][j] == "Q":return Falsei-=1j-=1# 135°角检查i,j = row-1, col+1while i>=0 and j<len(chessboard):if chessboard[i][j]=="Q":return Falsei -= 1j += 1return Trueres = []chessboard = ["."*n for _ in range(n) ]print(chessboard)backtracking(n,0,chessboard)return res
解数独
回溯总结
需要startIndex的题目有:
需要return的情况有:
一般情况下,如果题目中要求不能出现重复的数据,需要搭配这used数组进行使用,除此之外还需要对集合进行一个排序,这样可以在值相同的情况下进行判断。
if i>0 and nums[i]==nums[i-1] and not used[i-1]:continue
used[i-1]==False 说明在同一层的前面结点已经使用过该数据了,后面不需要重复进行操作。
如果集合中存在重复的数字序列,则需要对其进行排序
- 组合总数II
- 子集II
- 全排列II
相关文章:
【LeetCode】回溯算法类题目详解
所有题目均来自于LeetCode,刷题代码使用的Python3版本 回溯算法 回溯算法是一种搜索的方法,在二叉树总结当中,经常使用到递归去解决相关的问题,在二叉树的所有路径问题中,我们就使用到了回溯算法来找到所有的路径。 …...

java实现请求缓冲合并
业务背景: 我们对外提供了一个rest接口给第三方业务进行调用,但是由于第三方框架限制,导致会发送大量相似无效请求,例如:接口入参json包含两个字段,createBy和receiverList,完整的入参json示例…...

分布式锁的原子性问题
4.6 分布式锁的原子性问题 更为极端的误删逻辑说明: 线程1现在持有锁之后,在执行业务逻辑过程中,他正准备删除锁,而且已经走到了条件判断的过程中,比如他已经拿到了当前这把锁确实是属于他自己的,正准备删…...

从零自制docker-8-【构建实现run命令的容器】
文章目录 log "github.com/sirupsen/logrus"args...go moduleimport第三方包失败package和 go import的导入go build . 和go runcli库log.SetFormatter(&log.JSONFormatter{})error和nil的关系cmd.Wait()和cmd.Start()arg……context.Args().Get(0)syscall.Exec和…...

2024.03.31 校招 实习 内推 面经
绿*泡*泡VX: neituijunsir 交流*裙 ,内推/实习/校招汇总表格 1、自动驾驶一周资讯 -小米SU7上市24小时,大定达88898台;小鹏汽车正式进入德国市场;地平线递交港股上市申请 自动驾驶一周资讯 -小米SU7上市24小时&…...

邦芒职场:塑造职场人气王的秘诀
在职场中,有些人总能吸引众人的目光,成为团队的焦点;而有些人却常常默默无闻,难以融入。那么,如何在职场中脱颖而出,成为一个受欢迎的人呢?下面,让我们来探讨一下塑造职场人气王的秘…...

滤波器网络变压器的作用
网络变压器的作用主要包括以下几点: 1. 信号传输:网络变压器可以将PHY送出来的差分信号用差模耦合的线圈耦合滤波以增强信号,并且通过电磁场的转换耦合到不同电平的连接网线的另外一端以达到传输数据的目的。 2. 电气电压隔离:…...

Python —— 简述
Houdini Python | 笔记合集 - 知乎 Houdini内置三大语言: 表达式,主要用于节点参数控制,可实现跨模块控制;vex,速度最快(比表达式和Python快一个数量级),非常适合密集型计算环境&…...

使用Rust加速Python程序,让代码飞起来
作为一种解释型语言,Python在开发速度和灵活性方面具有明显的优势,但在性能方面却不如编译型语言如C或Rust。对于性能要求苛刻的应用程序,如果纯粹使用Python编写可能会运行缓慢,影响用户体验。因此,如何利用Rust来加速…...
- 向量整数算术指令)
【RISC-V 指令集】RISC-V 向量V扩展指令集介绍(八)- 向量整数算术指令
1. 引言 以下是《riscv-v-spec-1.0.pdf》文档的关键内容: 这是一份关于向量扩展的详细技术文档,内容覆盖了向量指令集的多个关键方面,如向量寄存器状态映射、向量指令格式、向量加载和存储操作、向量内存对齐约束、向量内存一致性模型、向量…...

Qt Designer在布局中调整控件垂直伸展或者水平伸展之后控件没有变化
QtDesigner设置垂直伸展 在Qt Designer中,要对网格布局中的每一个网格设置垂直伸展,可以按照以下步骤操作: 1.打开Qt Designer并打开你的UI文件。 2.确保你的布局是一个网格布局(QGridLayout)。 3.选中你想要设置垂直…...
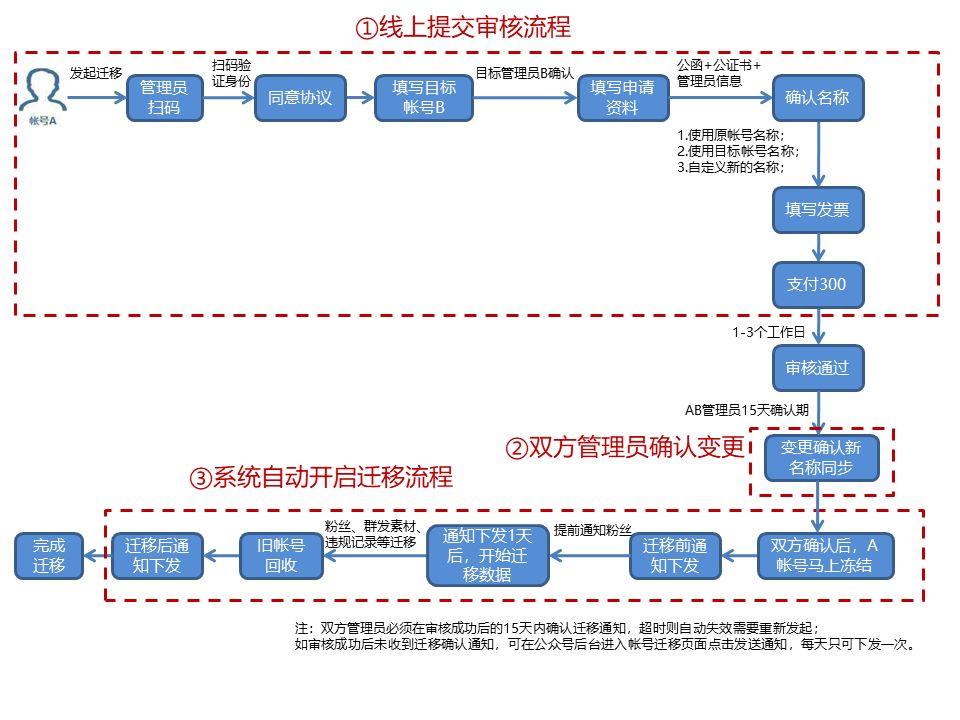
微信公众号粉丝迁移费用是多少?
公众号迁移后原来内容还在么?通过公众号迁移,可以实现这些目的:主体变更、开通留言功能、多号合并、订阅号升级为服务号、服务号转为订阅号。公众号迁移流程:①申请公证;②提交迁移申请;③第三方审核&#…...
基于Vue3 中后台管理系统框架
基于Vue3 中后台管理系统框架 文章目录 基于Vue3 中后台管理系统框架一、特点二、源码下载地址 一款开箱即用的 Vue 中后台管理系统框架,支持多款 UI 组件库,兼容PC、移动端。vue-admin, vue-element-admin, vue后台, 后台系统, 后台框架, 管理后台, 管理…...

Agent调研--19类Agent框架对比
代理(Agent)指能自主感知环境并采取行动实现目标的智能体,即AI作为一个人或一个组织的代表,进行某种特定行为和交易,降低一个人或组织的工作复杂程度,减少工作量和沟通成本。 背景 目前,我们在探…...

蓝桥杯-求阶乘
问题描述 满足 N!的末尾恰好有 区 个o的最小的 N 是多少? 如果这样的 N 不存在输出 -1。 输入格式 一个整数 区。 输出格式 一个整数代表答案。 样例输入 样例输出 10 评测用例规模与约定 对于 30% 的数据,1<K<106 对于 100% 的数据,1<K<1018 运行限制 最大运行时…...

计算两个日期之间相差的天数的四种方法
计算两个日期之间相差的天数的四种方法 第一种:时间戳的方式,计算两个日期的时间戳的差,再除当天的毫秒数即可得到相差的天数。 public static void main(String[] args) {DateFormat dft new SimpleDateFormat("yyyy-MM-dd");t…...
)
【leetcode面试经典150题】42. 有效的字母异位词(C++)
【leetcode面试经典150题】专栏系列将为准备暑期实习生以及秋招的同学们提高在面试时的经典面试算法题的思路和想法。本专栏将以一题多解和精简算法思路为主,题解使用C语言。(若有使用其他语言的同学也可了解题解思路,本质上语法内容一致&…...

Windows 2003 R2与Windows 2022建立域信任报错:本地安全机构无法跟域控制器获得RPC连接。请检查名称是否可以解析,服务器是否可用。
在Windows Server 2003 R2与Windows Server 2022之间建立域信任时遇到“本地安全机构无法与域控制器获得RPC连接”的错误,可能是由于以下几种原因: DNS 解析问题: 确保源域和目标域的DNS配置正确,能够互相解析对方的域名和IP地址。…...

UE5、CesiumForUnreal实现加载建筑轮廓GeoJson数据生成白模功能
1.实现目标 在UE5.3中,通过加载本地建筑边界轮廓面GeoJson数据,获取底面轮廓和楼高数据,拉伸生成白模,并支持点选高亮。为防止阻塞Game线程,使用了异步任务进行优化,GIF动图如下所示: 其中建筑数量:128871,顶点索引数量:6695748,三角面数量:2231916,顶点数量:165…...
JavaGUI编程
目录 GUI概念 Swing概念 组件 容器组件 窗口(JFrame) 代码 运行 面板(JPanel) 代码 运行 布局管理器 FlowLayout 代码 运行 BorderLayout 代码 运行 GridLayout 代码 运行 常用组件 标签(JLabel) 代码 运…...

如何使用ChatGPT for Google:让搜索结果与AI回答完美协作的终极指南
如何使用ChatGPT for Google:让搜索结果与AI回答完美协作的终极指南 【免费下载链接】chatgpt-google-extension This project is deprecated. Check my new project ChatHub: 项目地址: https://gitcode.com/gh_mirrors/ch/chatgpt-google-extension ChatGP…...

tcpdive性能评估报告:CPU占用率与QPS影响分析终极指南
tcpdive性能评估报告:CPU占用率与QPS影响分析终极指南 【免费下载链接】tcpdive A TCP performance profiling tool. 项目地址: https://gitcode.com/gh_mirrors/tc/tcpdive tcpdive作为一款专业的TCP性能分析工具,在生产环境中的性能表现至关重要…...

什么是大模型:概念、分类与当前主流模型全梳理
什么是大模型? 大模型,通常指的是参数规模很大、训练数据很多、具备较强通用能力的人工智能模型。它之所以叫“大”,通常体现在几个方面: 第一,参数量大。 从早期的几千万、几亿参数,发展到几十亿、上百亿&…...
)
别再手动数脉冲了!用STM32定时器编码器模式搞定增量编码器(附CubeMX配置)
STM32硬件编码器模式实战:精准捕获增量编码器信号的工程指南 在电机控制、机器人关节定位和精密测量系统中,增量式编码器作为核心反馈元件,其信号处理质量直接影响整个系统的控制精度。传统的中断计数方式在高速脉冲场景下往往捉襟见肘&#…...

5个关键场景下如何选择DINOv2模型:从ViT-S到ViT-G的完整指南
5个关键场景下如何选择DINOv2模型:从ViT-S到ViT-G的完整指南 【免费下载链接】dinov2 PyTorch code and models for the DINOv2 self-supervised learning method. 项目地址: https://gitcode.com/GitHub_Trending/di/dinov2 DINOv2是Meta AI Research开发的…...

完整指南:如何用3D打印技术构建高精度六轴机械臂Faze4
完整指南:如何用3D打印技术构建高精度六轴机械臂Faze4 【免费下载链接】Faze4-Robotic-arm All files for 6 axis robot arm with cycloidal gearboxes . 项目地址: https://gitcode.com/gh_mirrors/fa/Faze4-Robotic-arm Faze4是一个完全开源的6轴工业级机械…...

环境配置与基础教程:保姆级教程:在 Mac M 芯片上利用 MPS 加速 YOLO 训练与推理的完整环境搭建
写在前面:为什么你的 Mac 也能跑深度学习? 几年前,如果有人告诉你用 MacBook 训练深度学习模型,你大概会笑出声。那时候 Mac 上的 PyTorch 只能依赖 CPU 吭哧吭哧地算,训练一个小模型都要等到天荒地老。但自从 Apple Silicon 芯片(M1、M2、M3、M4,以及最新的 M5)横空出…...

别再“另存为”了!职场人90%的无效内耗都源于这一个操作。企业文档如何管理?
加班到晚上八点,职场人小林终于改完了项目方案,随手点了“另存为”,命名为“方案_最终版.doc“后发到了工作群。本以为可以安心下班,群里却炸锅了:“小林,你这个最终版和我手里的不一样啊?”“我…...

基于MCP协议构建本地AI短信分析工具:mac_messages_mcp项目详解
1. 项目概述:一个让AI“读懂”你Mac短信的桥梁如果你正在折腾AI智能体,尤其是那些能帮你处理日常信息的自动化工具,你可能会遇到一个核心痛点:如何让AI安全、便捷地访问你设备上的原生应用数据?比如,Mac上的…...

从点灯到项目:手把手教你为TMS320F28335创建可复用的工程模板
从点灯到项目:手把手教你为TMS320F28335创建可复用的工程模板 当你第一次点亮TMS320F28335开发板上的LED时,那种成就感无与伦比。但很快你会发现,随着项目复杂度提升,代码开始变得混乱不堪——头文件散落各处、函数命名随意、每次…...