微软卡内基梅隆大学:无外部干预,GPT4等大语言模型难以自主探索
目录
引言:LLMs在强化学习中的探索能力探究
研究背景:LLMs的在情境中学习能力及其重要性
实验设计:多臂老虎机环境中的LLMs探索行为
实验结果概览:LLMs在探索任务中的普遍失败
成功案例分析:Gpt-4在特定配置下的探索成功
探索失败的原因分析
相关工作回顾:LLMs能力研究的相关文献
讨论与未来工作方向
总结
引言:LLMs在强化学习中的探索能力探究
在强化学习和决策制定的核心能力中,探索(exploration)扮演着至关重要的角色。探索能力指的是智能体为了评估不同选择并减少不确定性而有意识地收集信息的能力。近年来,大型语言模型(Large Language Models,简称LLMs)在多种任务中展现出了令人瞩目的性能,特别是在无需训练干预的情况下,通过上下文学习(in-context learning)来解决问题。然而,LLMs在没有额外训练干预的情况下是否能够展现出探索行为,尤其是在简单的多臂老虎机(multi-armed bandit,简称MAB)环境中,这一问题仍然不甚明了。
本研究通过将LLMs部署为代理,放置在MAB环境中,通过LLM提示(prompt)完全指定环境描述和交互历史,来探究LLMs的探索能力。实验结果显示,只有在使用了特定提示设计的情况下,LLMs才能表现出满意的探索行为。这一发现提示我们,为了在更复杂的环境中获得理想的行为,可能需要非平凡的算法干预,例如微调或数据集策划。本文的研究为理解LLMs作为决策制定代理的潜力提供了新的视角,并指出了未来研究的方向。
论文标题:Can large language models explore in-context?
机构:Microsoft Research, Carnegie Mellon University
论文链接:https://arxiv.org/pdf/2403.15371.pdf
公众号【AI论文解读】后台回复“论文解读” 获取论文PDF!
研究背景:LLMs的在情境中学习能力及其重要性
在人工智能领域,大型语言模型(LLMs)的出现标志着一个新的时代。这些模型,如GPT-3.5、GPT-4和Llama2,已经展示了在没有参数更新的情况下,通过简单地在模型提示(prompt)中指定问题描述和相关数据,即所谓的“情境中学习”(in-context learning),来解决问题的能力。这种能力的出现并非由于模型被显式地训练来执行这些任务,而是因为这些算法能够从大规模训练语料库中提取出来,并在大规模应用时显现出来。
情境中学习的发现自GPT-3模型以来,已经成为研究的热点。尽管对于情境中的监督学习(ICSL)的理论进展仍处于初级阶段,但我们对如何在实践中使用ICSL的理解正在迅速形成。然而,除了监督学习之外,许多应用要求使用机器学习模型进行下游决策制定。因此,情境中的强化学习(ICRL)和序列决策制定成为了自然的下一个研究前沿。LLMs已经被用作从自然科学实验设计到游戏玩耍等应用的决策制定代理,但我们对ICRL的理论和操作理解远不如ICSL。
决策制定代理必须具备三个核心能力:泛化(对于监督学习是必需的)、探索(为了收集更多信息而做出可能在短期内不是最优的决策)和规划(考虑决策的长期后果)。本文关注探索,即有意识地收集信息以评估替代方案和减少不确定性的能力。最近的一系列论文证明了当LLMs被明确训练以产生包括探索在内的强化学习行为时,变换器模型会表现出情境中的强化学习行为。然而,这些发现并未阐明是否在标准训练方法下获得的通用LLMs中会表现出探索行为,这引出了以下基本问题:LLMs是否能够作为通用的决策制定代理。
实验设计:多臂老虎机环境中的LLMs探索行为
1. 多臂老虎机问题简介
多臂老虎机(MAB)是一种经典且被广泛研究的强化学习问题,它突出了探索与利用之间的权衡,即根据可用数据做出最佳决策。MAB的简单性、对RL的中心性以及对探索与利用的关注使其成为系统研究LLMs情境中探索能力的自然选择。
2. 实验中的提示设计多样性
我们使用LLMs作为在MAB环境中操作的决策制定代理,通过提示来与MAB实例进行交互。我们的提示设计允许多种独立选择,包括“场景”(例如作为选择按钮的代理或作为向用户显示广告的推荐引擎)、“框架”(明确提示需要平衡探索和利用的需要或保持中立)、历史呈现方式(作为一系列原始列表或通过每个臂的播放次数和平均奖励进行总结)、最终答案的请求方式(单个臂或臂的分布)以及是否允许LLM提供“思维链”(CoT)解释。这些选择共同导致了32种提示设计。
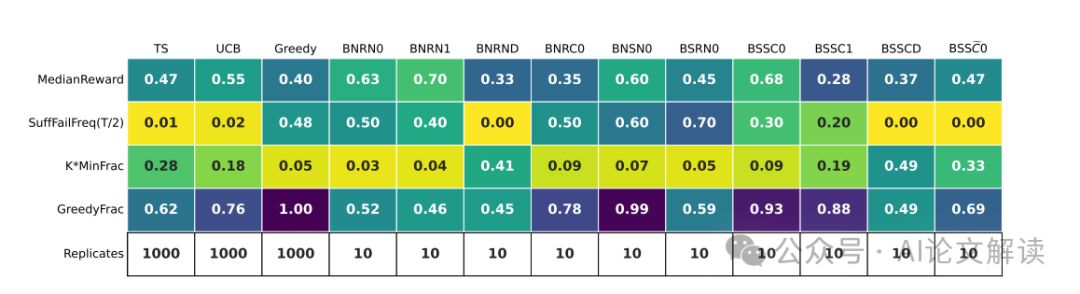
我们发现,只有一种配置(即提示设计和LLM配对)在我们的实验中表现出令人满意的探索行为。所有其他配置都表现出探索失败,未能显著概率地收敛到最佳决策(臂)。我们得出结论,尽管当前一代LLMs在适当的提示工程下或许可以在简单的RL环境中探索,但可能需要进一步的训练干预,例如微调或数据集策划,以赋予LLMs在更复杂环境中所需的更复杂的探索能力。
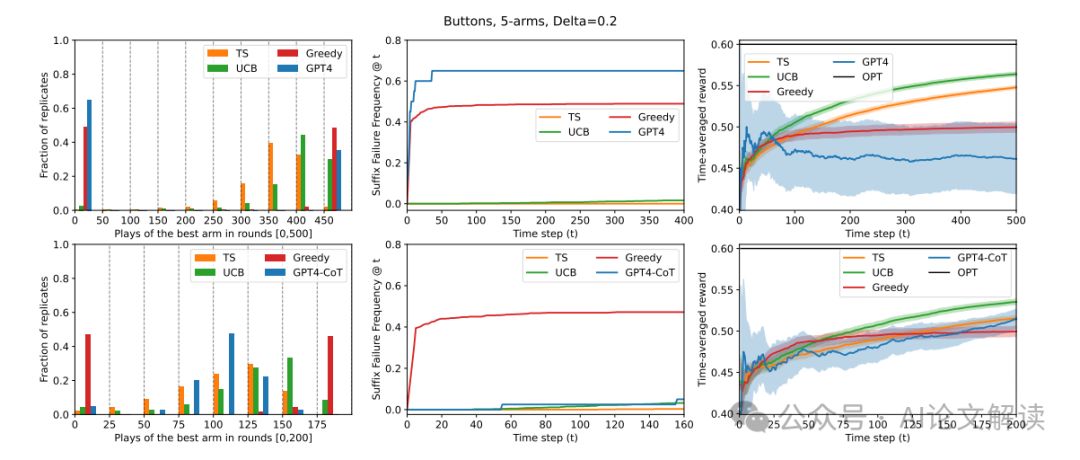
实验结果概览:LLMs在探索任务中的普遍失败
在研究大型语言模型(LLMs)在探索任务中的表现时,我们发现它们在没有额外训练干预的情况下普遍无法有效地进行探索。我们使用了多种提示设计,部署了Gpt-3.5、Gpt-4和Llama2作为代理,在多臂老虎机环境中进行实验。实验结果显示,除了一种特定配置外,其他所有配置都未能展现出稳健的探索行为。这些配置中,即使包含了链式推理(chain-of-thought reasoning)但没有经过外部总结的历史记录,也未能成功引导模型进行有效探索。这表明在更复杂的环境中,如果无法进行外部总结,LLMs可能无法进行有效的探索。
成功案例分析:Gpt-4在特定配置下的探索成功
成功配置的详细介绍
在我们的实验中,唯一一种成功的配置涉及到Gpt-4模型,结合了增强型提示设计。这种配置包括:使用按钮场景(buttons scenario)、建议性框架(suggestive framing)、外部总结的互动历史(summarized interaction history),以及要求模型使用零次射击链式推理(zero-shot chain-of-thought reasoning)。此外,该配置使用了温度参数为0,以确保模型的确定性行为,从而隔离了模型自身的“有意”探索行为。
成功配置与基线算法的对比
与基线算法相比,Gpt-4在这种配置下的表现与UCB(上置信界算法)和TS(汤普森采样算法)等具有理论保证的标准多臂老虎机算法有着根本的不同。在实验中,Gpt-4的这种配置避免了后缀失败(suffix failures),并且在奖励方面与TS相当。这表明,通过精心设计提示,最新的LLMs确实具备稳健探索的能力。然而,这种配置如果没有外部总结,就会失败,这进一步表明在需要外部算法设计的复杂环境中,LLMs可能无法进行有效探索。因此,我们得出结论,为了在复杂环境中赋予LLMs更复杂的探索能力,可能需要进行非平凡的算法干预,如微调或数据集策划。
探索失败的原因分析
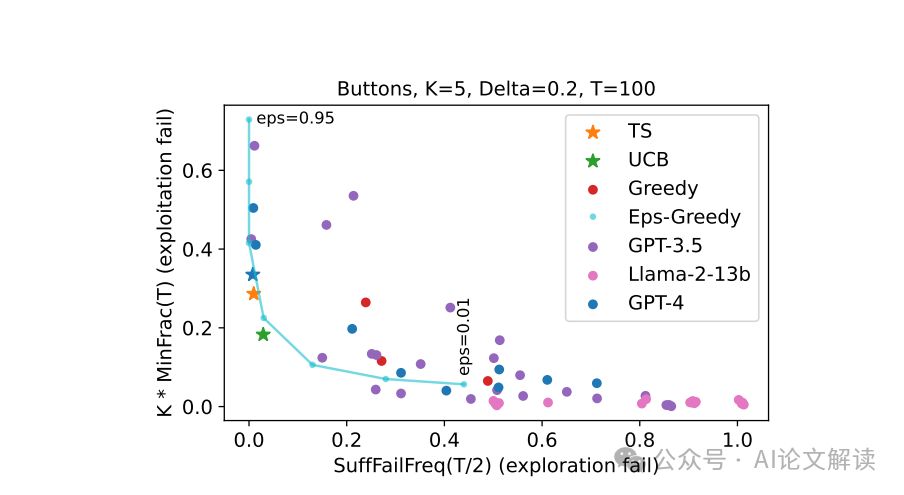
1. 后缀失败与均匀失败的定义与检测
在研究大型语言模型(LLMs)的探索能力时,我们发现了两种主要的失败模式:后缀失败和均匀失败。后缀失败指的是在一系列尝试之后,模型未能选择最佳选项,即使在后续的尝试中也是如此。这种情况通常发生在某个时间段的后半部分,表明模型在初期的探索之后未能继续探索。例如,Gpt-4在基本提示设计下的后缀失败率超过60%。均匀失败则是指模型在选择时表现出近似均匀的行为,未能区分表现好的和表现差的选项。
为了检测这些失败模式,我们引入了两个代理统计量:SuffFailFreq和MinFrac。SuffFailFreq衡量的是在一定时间段内未选择最佳选项的频率,而MinFrac则衡量的是模型选择每个选项的最小比例。通过这些统计量,我们可以在实验的适度规模下检测长期探索失败,即使在标准性能度量(如奖励)过于嘈杂时也是如此。
2. 失败配置的行为模式
我们发现,除了一种特定的配置外,大多数LLM配置都表现出探索失败。这些配置未能在显著的概率下收敛到最佳选项。唯一的例外是Gpt-4结合增强提示、外部总结的交互历史和零次射击链式推理(chain-of-thought reasoning)的配置。这表明,只有在提示设计得当时,LLMs才能表现出强大的探索能力。然而,没有外部总结的相同配置失败了,这表明在更复杂的环境中,LLMs可能无法进行探索,因为在这些环境中外部总结历史是一个非平凡的算法设计问题。
相关工作回顾:LLMs能力研究的相关文献
在研究LLMs的能力时,已有大量文献集中于探索这些模型的各种能力。例如,Brown等人(2020)发现了LLMs的在上下文中学习(in-context learning)的能力,这是一种使得预训练的LLM能够通过在LLM提示中完全指定问题描述和相关数据来解决问题的能力。Garg等人(2022)通过在提示中包含数值协变量向量和标量目标,然后在提示中包含新的协变量向量来获得类似回归的预测,展示了LLMs的这一能力。
讨论与未来工作方向
对LLMs探索能力的启示
在探索Large Language Models(LLMs)在强化学习和决策制定中的探索能力时,我们发现现有的LLMs并不能在没有显著干预的情况下稳定地进行探索。在多臂老虎机(multi-armed bandit, MAB)环境中,只有Gpt-4结合链式推理(chain-of-thought reasoning)和外部总结的交互历史,表现出了令人满意的探索行为。这一发现提示我们,尽管LLMs在设计合适的提示(prompt)时能够表现出探索能力,但在更复杂的环境中,这种能力可能会受限,因为外部总结历史在这些环境中可能是一个复杂的算法设计问题。
提高LLMs决策能力的潜在干预措施
为了提高LLMs在复杂环境中的决策能力,可能需要采取非平凡的算法干预措施,例如微调(fine-tuning)或数据集策展(dataset curation)。这些干预措施的目的是为LLMs赋予更复杂的探索能力,使其能够在更具挑战性的设置中有效地作为决策代理。此外,我们可能需要进一步的方法论或统计进步,以便成本效益地诊断和理解LLM代理的行为。
总结
本文的研究表明,当前代LLMs在没有适当的提示工程或训练干预的情况下,可能无法在简单的强化学习环境中进行探索。尽管Gpt-4在特定配置下展现了一定的探索能力,但这一成功配置依赖于外部总结的交互历史和增强的链式推理提示,这在更复杂的环境中可能不可行。因此,我们得出结论,为了在复杂环境中赋予LLMs更高级的探索能力,可能需要进行更深入的算法干预研究。
相关文章:
微软卡内基梅隆大学:无外部干预,GPT4等大语言模型难以自主探索
目录 引言:LLMs在强化学习中的探索能力探究 研究背景:LLMs的在情境中学习能力及其重要性 实验设计:多臂老虎机环境中的LLMs探索行为 实验结果概览:LLMs在探索任务中的普遍失败 成功案例分析:Gpt-4在特定配置下的探…...
探索设计模式的魅力:简单工厂模式
个人主页: danci_ 🔥系列专栏:《设计模式》《MYSQL应用》 💪🏻 制定明确可量化的目标,坚持默默的做事。 🚀 转载自热榜文章:探索设计模式的魅力:简单工厂模式 简单工厂模式&#x…...

【数据结构】-----双链表(小白必看!!!)
c语言中的小小白-CSDN博客c语言中的小小白关注算法,c,c语言,贪心算法,链表,mysql,动态规划,后端,线性回归,数据结构,排序算法领域.https://blog.csdn.net/bhbcdxb123?spm1001.2014.3001.5343 给大家分享一句我很喜欢我话: 知不足而奋进,望远山而前行&am…...
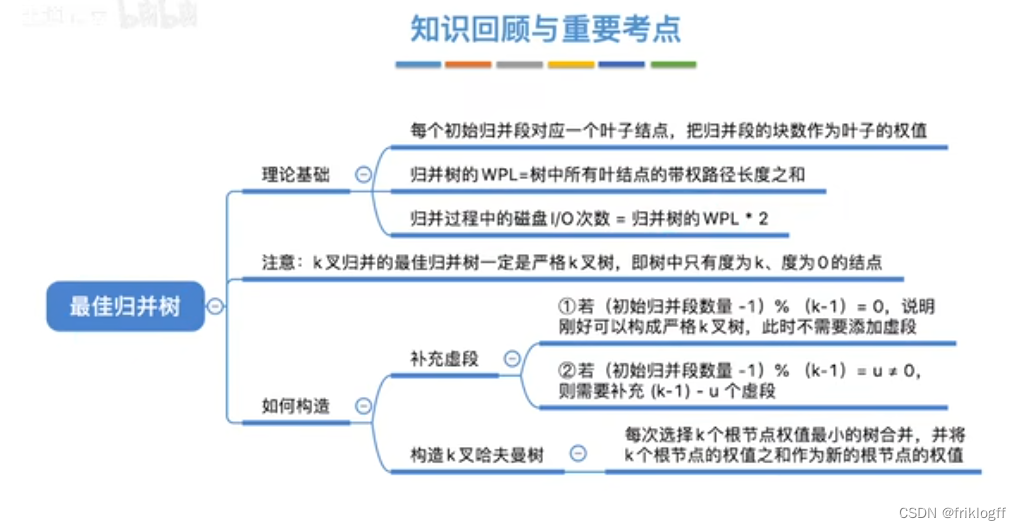
【数据结构】考研真题攻克与重点知识点剖析 - 第 8 篇:排序
前言 本文基础知识部分来自于b站:分享笔记的好人儿的思维导图与王道考研课程,感谢大佬的开源精神,习题来自老师划的重点以及考研真题。此前我尝试了完全使用Python或是结合大语言模型对考研真题进行数据清洗与可视化分析,本人技术…...

数字乡村可视化大数据-DIY拖拽式设计
DIY拖拽式大数据自由设计万村乐可视化大数据V1.0 随着万村乐数字乡村系统的广泛使用,我们也接收到了客户的真实反馈,最终在公司的决定下,我们推出了全新的可视化大数据平台V1.0版本,全新的可视化平台是一个通过拖拽配置生成可视化…...

数据集学习
1,CIFAR-10数据集 CIFAR-10数据集由10个类的60000个32x32彩色图像组成,每个类有6000个图像。有50000个训练图像和10000个测试图像。 数据集分为五个训练批次和一个测试批次,每个批次有10000个图像。测试批次包含来自每个类别的恰好1000个随机…...
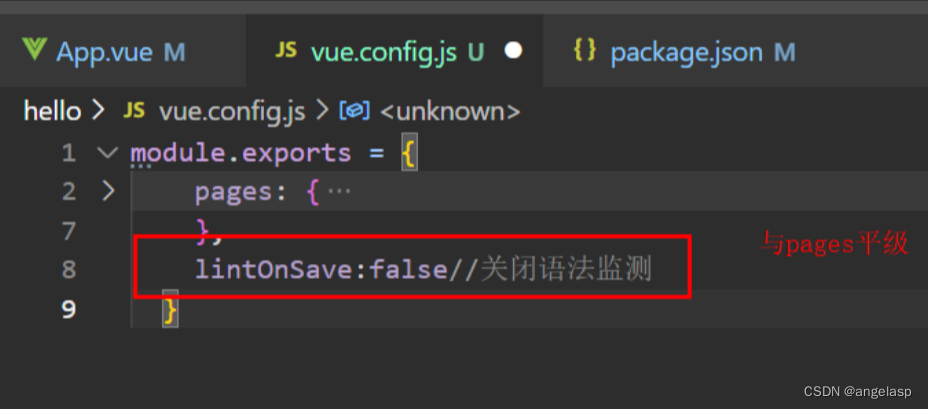
【解决】npm run dev Syntax Error: TypeError: eslint.CLIEngine is not a constructor
问题: 由于代码语法不符合eslint而照成此错误,可以参照eslint规则修改语法,或者将eslint停掉 以下为停掉eslint的方法。 You may use special comments to disable some warnings. Use // eslint-disable-next-line to ignore the ne…...

Android 如何通过屏幕大小来适配不同大小的图片
可以使用Android中的dp(密度无关像素)单位来设置不同屏幕密度下的图片大小。dp是Android中的一种尺寸单位,它与屏幕密度无关,只与字体大小有关。在开发过程中,可以使用dp来设置布局和控件的大小,以便在不同的屏幕密度下保持一致的…...

【面试题】细说mysql中的各种锁
前言 作为一名IT从业人员,无论你是开发,测试还是运维,在面试的过程中,我们经常会被数据库,数据库中最经常被问到就是MySql。当面试官问MySql的时候经常会问道一个问题,”MySQL中有哪些锁?“当我…...
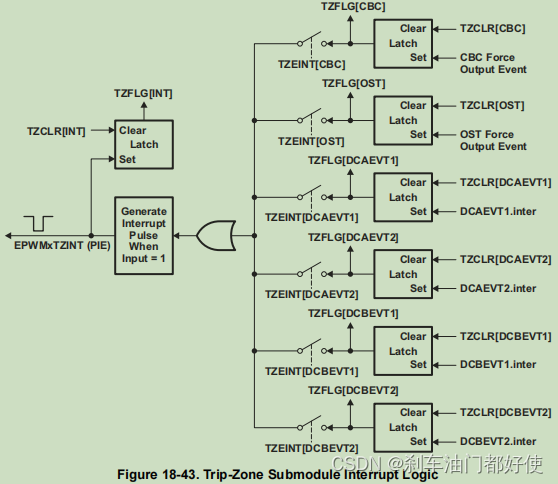
TMS320F280049 EPWM模块--TZ子模块(6)
下图是TZ子模块在epwm中的位置,可以看到TZ子模块接收内外部多种信号,经过处理后生成最终epwm波形,然后通过gpio向外发出。 TZ的动作有4个:拉高/拉低/高阻/不变。 TZ的内部框图见下图,可以看出: 1…...

数字乡村创新实践探索农业现代化路径:科技赋能农业产业升级、提升乡村治理效能与农民幸福感
随着信息技术的快速发展和数字化时代的到来,数字乡村建设正成为推动农业现代化、提升农业产业竞争力、优化乡村治理以及提高农民幸福感的重要途径。本文将围绕数字乡村创新实践,探讨其在农业现代化路径中的积极作用,以及如何通过科技赋能实现…...

linux中rpm包与deb包的区别及使用
文章目录 1. rpm与deb的区别2. deb软件包的格式和使用2.1 deb软件包命令遵行如下约定2.2 dpkg命令2.3 apt-命令 3. Unix和Linux的区别Reference 1. rpm与deb的区别 有的系统只支持使用rpm包安装,有的只支持deb包安装,混乱安装会导致系统问题。 关于rpm和…...
Linux中安装seata
Linux中安装seata 一、准备1、环境2、下载3、上传到服务器4、解压 二、配置1、备份配置文件2、导入sql3、修改配置前4、修改配置后5、在nacos中配置 三、使用1、启动2、关闭 一、准备 1、环境 因为要在 nacos 中配置,要求安装并启动 nacos 。可以参考这篇博客。 …...
预印本仓库ArXiv——防止论文录用前被别人剽窃
文章目录 一、什么是预印本二、什么是ArXiv2.1 ArXiv的领域2.2 如何使用 一、什么是预印本 预印本(Preprint)是指科研工作者的研究成果还未在正式出版物上发表,而出于和同行交流目的自愿先在学术会议上或通过互联网发布的科研论文、科技报告…...

LNMP 架构
1. 环境准备 环境准备 lnmp 需要 安装 nginx mysql php 软件 1.1 关闭防火墙 systemctl disable --now firewalld setenforce 0 1.2 安装依赖包 yum -y install pcre-devel zlib-devel gcc gcc-c make 1.3 创建运行用户、组 (Nginx 服务程序默认以 nobody 身份…...

谈谈Python中的单元测试和集成测试
谈谈Python中的单元测试和集成测试 Python中的单元测试和集成测试是软件开发过程中的重要环节,它们确保了代码的质量和稳定性。单元测试主要关注代码的最小可测试单元——通常是函数或类的方法,而集成测试则关注这些单元之间的协作和交互。下面…...

【2024】Prometheus通过node_exporter都监控了什么
我们通过prometheus进行监控,通过node_exporter进行Linux系统的监控。 那么我们通过node_exporter都监控了什么? 目录 常用指标CPU相关内存相关磁盘相关网络相关其他指标常用监控告警案例:cpu案例:内存案例:磁盘案例:网络案例:常用指标 Prometheus通过node_exporter可以…...
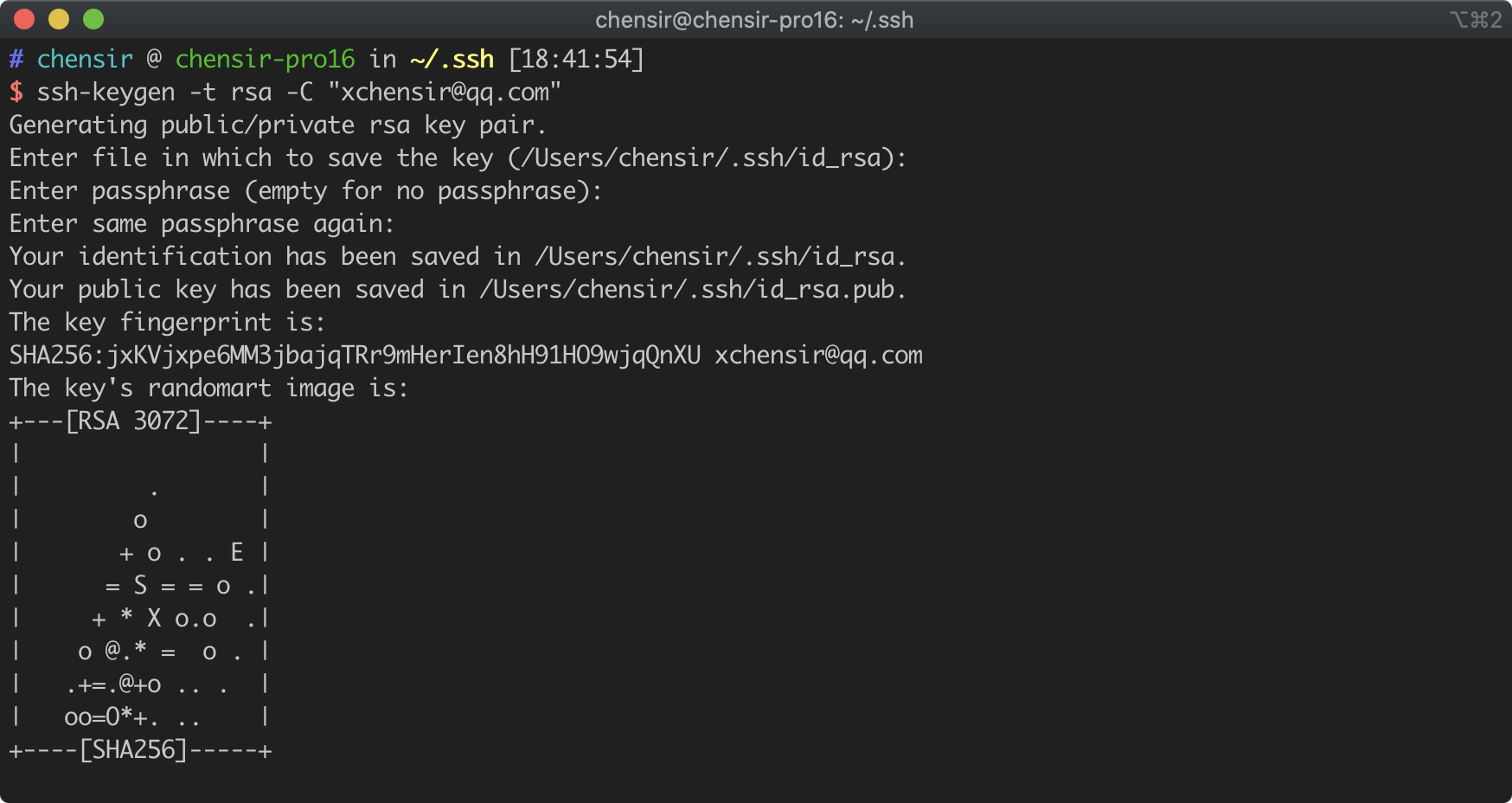
Centos7配置秘钥实现集群免密登录
设备:MacBook Pro、多台Centos7.4服务器(已开启sshd服务) 大体流程:本机生成秘钥,将秘钥上传至服务器即可实现免密登录 1、本地电脑生成秘钥: ssh-keygen -t rsa -C "邮箱地址 例:*****.163.com"一路回车…...
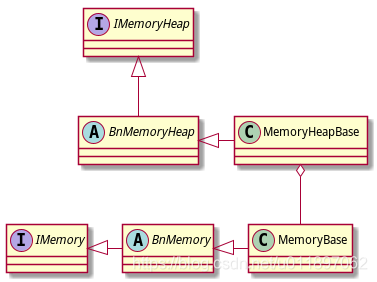
Android匿名共享内存(Ashmem)
在Android中我们熟知的IPC方式有Socket、文件、ContentProvider、Binder、共享内存。其中共享内存的效率最高,可以做到0拷贝,在跨进程进行大数据传输,日志收集等场景下非常有用。共享内存是Linux自带的一种IPC机制,Android直接使用…...

MySOL之旅--------MySQL数据库基础( 3 )
本篇碎碎念:要相信啊,胜利就在前方,要是因为一点小事就停滞不前,可能你也不适合获取胜利,成功的路上会伴有泥石,但是走到最后,你会发现身上的泥泞皆是荣耀的勋章! 今日份励志文案: 凡是发生皆有利于我 目录 查询(select) 1.全列查询 2.指定列查询 3.查询字段为表达式 编…...

DelphiOpenAI:原生集成OpenAI API,赋能Delphi开发者构建智能应用
1. 项目概述:DelphiOpenAI,一个为Delphi开发者打造的AI桥梁如果你是一名Delphi开发者,看着Python、JavaScript社区热火朝天地集成各种AI能力,自己却苦于没有成熟、好用的原生库,只能望“AI”兴叹,那么今天介…...

Helm模板智能助手:提升Kubernetes应用部署效率的VSCode插件
1. 为什么你需要一个Helm模板智能助手如果你和我一样,每天都在和Kubernetes的Helm Charts打交道,那你一定对编写templates/目录下那些.yaml文件又爱又恨。爱的是Helm的模板引擎确实强大,能把一堆重复的YAML配置抽象成可复用的模板;…...

Windows和Office激活难题?KMS智能激活脚本让你轻松告别烦恼
Windows和Office激活难题?KMS智能激活脚本让你轻松告别烦恼 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾经因为Windows系统突然弹出激活提示而中断工作?是否遇…...

利用ODX实现整车诊断数据库管理
一:背景与挑战| 背景:在全球汽车行业快速发展的背景下,对车辆诊断技术的要求也在不断提升。ODX(Open Diagnostic data eXchange)作为行业标准的诊断数据库,已被各大汽车制造商广泛采用,并贯穿于ECU的整个生…...
:从token消耗策略、种子可控性、多主体一致性到商用合规链路的断代式升级)
Midjourney版本战争白皮书(V7终结篇 vs V8统治纪元):从token消耗策略、种子可控性、多主体一致性到商用合规链路的断代式升级
更多请点击: https://intelliparadigm.com 第一章:V7终结篇与V8统治纪元的战略分水岭 V7 版本的正式 EOL(End-of-Life)标志着一个技术周期的谢幕,而 V8 的全面 GA(General Availability)则开启…...

JPlag代码抄袭检测:你的学术诚信守护神
JPlag代码抄袭检测:你的学术诚信守护神 【免费下载链接】JPlag State-of-the-Art Source Code Plagiarism & Collusion Detection. Check for plagiarism in a set of programs. 项目地址: https://gitcode.com/gh_mirrors/jp/JPlag 你是否曾为学生的代码…...

免费AI聊天机器人部署指南:整合多模型与全栈技术实践
1. 项目概述与核心价值最近在折腾一些AI应用,发现很多朋友都想自己部署一个免费的、功能强大的聊天机器人,但要么被高昂的API费用劝退,要么被复杂的部署流程搞得头大。如果你也有同样的困扰,那么今天聊的这个项目——CNSeniorious…...

DOM NodeList 深入解析
DOM NodeList 深入解析 概述 DOM NodeList 是 Web 开发中常用的一种数据结构,它代表了文档中一系列元素的集合。在本文中,我们将对 DOM NodeList 进行深入解析,包括其定义、特点、使用方法以及在实际开发中的应用。 定义 DOM NodeList 是一个类似数组的对象,它包含了文…...

线性调频等离子鞘套目标雷达探测平台【附代码】
✨ 长期致力于等离子鞘套、脉内多普勒频率、干扰目标抑制、FPGA研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)等离子鞘套回波建模与脉内多普勒参数提…...

避坑指南:SciencePlots安装后样式不生效?手把手教你排查Matplotlib的stylelib路径问题
科学绘图样式失效?彻底解决Matplotlib样式库路径配置难题 当你第一次尝试用SciencePlats的science样式美化科研图表时,却发现Python报出KeyError: science is not a valid style的错误提示——这种挫败感我深有体会。作为每天与数据可视化打交道的从业者…...