【深度学习】YOLO-World: Real-Time Open-Vocabulary Object Detection,目标检测
介绍一个酷炫的目标检测方式:
论文:https://arxiv.org/abs/2401.17270
代码:https://github.com/AILab-CVC/YOLO-World
文章目录
- 摘要
- Introduction
- 第2章 相关工作
- 2.1 传统目标检测
- 2.2 开放词汇目标检测
- 第3章 方法
- 3.1 预训练公式:区域-文本对
- 3.2 模型架构
- 3.3 可重参数化的视觉-语言路径聚合网络(RepVL-PAN)
- 3.4 预训练方案
- 4. 实验
- 4.1 实现细节
- 4.2 预训练
- 4.3 消融实验
- 4.6 可视化
- 5 结论
- 实际测试例子demo
- 帮助、问询
摘要
YOLO-World是一种实时开放词汇目标检测系统,它通过视觉-语言建模和大规模数据集上的预训练,增强了YOLO(You Only Look Once)系列检测器的开放词汇检测能力。具体来说,该研究提出了一个新的可重新参数化的视-语路径聚合网络(RepVL-PAN)和区域-文本对比损失函数,以促进视觉和语言信息之间的交互。YOLO-World在零样本方式下检测广泛对象类别方面表现出色,并且效率很高。在具有挑战性的LVIS数据集上,YOLO-World在V100上达到了52.0 FPS的帧率和35.4的AP值,这在准确性和速度方面都超过了当前许多最先进的方法。此外,经过微调的YOLO-World在多个下游任务上,包括目标检测和开放词汇实例分割,都取得了显著的性能。
Introduction
目标检测是计算机视觉中一个长期存在且基础性的挑战,其在图像理解、机器人技术和自动驾驶等领域有着众多应用。随着深度神经网络的发展,许多研究工作已经取得了重大突破,取得了显著的目标检测成果。尽管这些方法取得了成功,但它们仍然存在一定局限性,因为它们只能处理具有固定词汇表的目标检测,例如 COCO 数据集中的 80 个类别。一旦确定和标记了对象类别,训练好的检测器只能检测那些特定的类别,从而限制了开放场景的能力和适用性。
最近的研究已经探索了流行的视觉语言模型来解决开放词汇检测问题,通过从语言编码器(例如 BERT)中提炼词汇知识来实现 [8, 13, 48, 53, 58]。然而,由于训练数据的稀缺性以及词汇的有限多样性,这些基于提炼的方法受到了很大限制,例如 OV-COCO 只包含 48 个基本类别。一些方法则将目标检测训练重新构建为区域级视觉语言预训练,并在规模上训练开放词汇对象检测器 [24, 30, 56, 57, 59]。然而,这些方法仍然在实际场景中检测方面遇到困难,存在两个方面的问题:(1)计算负担重,(2)边缘设备的部署复杂。以前的工作已经展示了大型检测器的有希望的性能,但尚未探索将小型检测器预训练以赋予它们开放识别能力的可能性。
在本文中,我们介绍了 YOLO-World,旨在实现高效的开放词汇目标检测,并探索大规模预训练方案,将传统的 YOLO 检测器推向新的开放词汇世界。与先前的方法相比,所提出的 YOLO-World 具有显著的高效性和高推理速度,并且易于部署到下游应用中。具体来说,YOLO-World 遵循标准的 YOLO 架构,并利用预训练的 CLIP 文本编码器来编码输入文本。我们进一步提出了可重新参数化的视觉语言路径聚合网络(RepVL-PAN),以便更好地连接文本特征和图像特征进行更好的视觉-语义表示。在推理过程中,文本编码器可以被移除,并且文本嵌入可以重新参数化为 RepVL-PAN 的权重,以实现高效的部署。我们进一步研究了基于区域-文本对比学习的开放词汇预训练方案,该方案将检测数据、定位数据和图像-文本数据统一为区域-文本对。在大量的区域-文本对上预训练的 YOLO-World 展现出了强大的大词汇检测能力,而训练更多的数据将带来对开放词汇能力的更大提升。
此外,我们探索了一个提示-然后-检测的范式,以进一步提高实际场景中开放词汇目标检测的效率。正如图 2 所示,传统的目标检测器侧重于具有预定义和训练类别的固定词汇(闭集)检测。而以前的开放词汇检测器则使用文本编码器对用户的提示进行在线词汇编码,并检测对象。值得注意的是,这些方法往往倾向于使用具有沉重骨干(例如 Swin-L)的大型检测器来增加开放词汇容量。相比之下,提示-然后-检测范式首先对用户的提示进行编码以构建离线词汇表,该词汇表随着不同需求而变化。然后,高效的检测器可以在不重新编码提示的情况下即时推断离线词汇表。对于实际应用,一旦我们训练好了检测器,即 YOLO-World,我们就可以预编码提示或类别以构建离线词汇表,然后无缝地将其集成到检测器中。
我们的主要贡献可以总结为三个方面:
- 我们介绍了 YOLO-World,一个具有高效性的最新开放词汇目标检测器,适用于实际应用。
- 我们提出了可重新参数化的视觉语言 PAN,以连接视觉和语言特征,并提出了一种开放词汇区域-文本对比预训练方案。
- 在大规模数据集上预训练的 YOLO-World 展示了强大的零次表现,并在 LVIS 上实现了 35.4 的 AP 和 52.0 的 FPS。预训练的 YOLO-World 可轻松适应下游任务,例如开放词汇实例分割和指涉对象检测。此外,YOLO-World 的预训练权重和代码将开源,以促进更多实际应用的发展。
第2章 相关工作
2.1 传统目标检测
目前流行的目标检检测研究主要集中在固定词汇量(闭集)检测上,即在预定义类别的数据集上训练目标检测器,例如COCO数据集[26]和Objects365数据集[46],然后检测固定类别集合中的目标。在过去的几十年里,传统目标检测的方法主要可以分为三类:基于区域的方法、基于像素的方法和基于查询的方法。基于区域的方法[11, 12, 16, 27, 44],如Faster R-CNN[44],采用两阶段框架进行建议生成[44]和感兴趣区域(RoI)分类和回归。基于像素的方法[28, 31, 42, 49, 61]倾向于是单阶段检测器,它们在预定义的锚点或像素上进行分类和回归。DETR[1]首次通过变换器[50]探索目标检测,并激发了大量基于查询的方法[64]。在推理速度方面,Redmon等人提出了YOLO[40-42],它利用简单的卷积架构实现实时目标检测。一些工作[10, 23, 33, 52, 55]提出了各种架构或设计来改进YOLO,包括路径聚合网络[29]、交叉阶段部分网络[51]和重参数化[6],这进一步提高了速度和精度。与以前的YOLO相比,本文中的YOLO-World旨在检测超出固定词汇的目标,并具有强大的泛化能力。
2.2 开放词汇目标检测
开放词汇目标检测(OVD)[58]作为现代目标检测的新趋势已经出现,旨在检测超出预定义类别的目标。早期工作[13]遵循标准OVD设置[58],通过在基类上训练检测器并评估新的(未知的)类别。然而,这种开放词汇设置可以评估检测器检测和识别新目标的能力,但在开放场景中仍然受限,并且由于在限定数据集和词汇量上的训练,缺乏对其他领域的泛化能力。受图像-语言预训练[19, 39]的启发,近期的工作[8, 22, 53, 62, 63]将开放词汇目标检测形式化为图像-文本匹配,并利用大规模图像-文本数据扩大训练词汇量。OWL-ViTs[35, 36]通过检测和定位数据集对简单的视觉变换器[7]进行微调,并建立了具有可观性能的简易开放词汇检测器。GLIP[24]提出了一种基于短语定位的开放词汇检测预训练框架,并在零样本设置中进行评估。Grounding DINO[30]将定位预训练[24]融入到检测变换器[60]中,实现了跨模态融合。多种方法[25, 56, 57, 59]通过区域-文本匹配统一了检测数据集和图像-文本数据集,并通过大规模图像-文本对预训练检测器,实现了有希望的性能和泛化。然而,这些方法通常使用像ATSS[61]或DINO[60]这样的重型检测器以Swin-L[32]作为骨架,导致了较高的计算需求和部署挑战。相比之下,我们提出了YOLO-World,致力于实现高效的开放词汇目标检测,具备实时推理能力和更易于下游应用部署。与同样探索基于YOLO[58]的开放词汇检测的ZSD-YOLO[54]不同,YOLO-World引入了一个新颖的YOLO框架,采用有效的预训练策略,增强了开放词汇性能和泛化能力。
第3章 方法
3.1 预训练公式:区域-文本对
传统目标检测方法,包括YOLO系列[20],是在实例标注Ω = {B_i, c_i}_i=1^N上训练的,包含了边界框{B_i}和类别标签{c_i}。在本文中,我们将实例标注重新公式化为区域-文本对Ω = {B_i, t_i}_i=1^N,其中t_i是与区域B_i对应的文本。具体来说,文本t_i可以是类别名称、名词短语或对象描述。此外,YOLO-World将图像I和文本T(一组名词)作为输入,并输出预测边界框{B_k}和相应的对象嵌入向量{e_k}(e_k ∈ R^D)。
3.2 模型架构
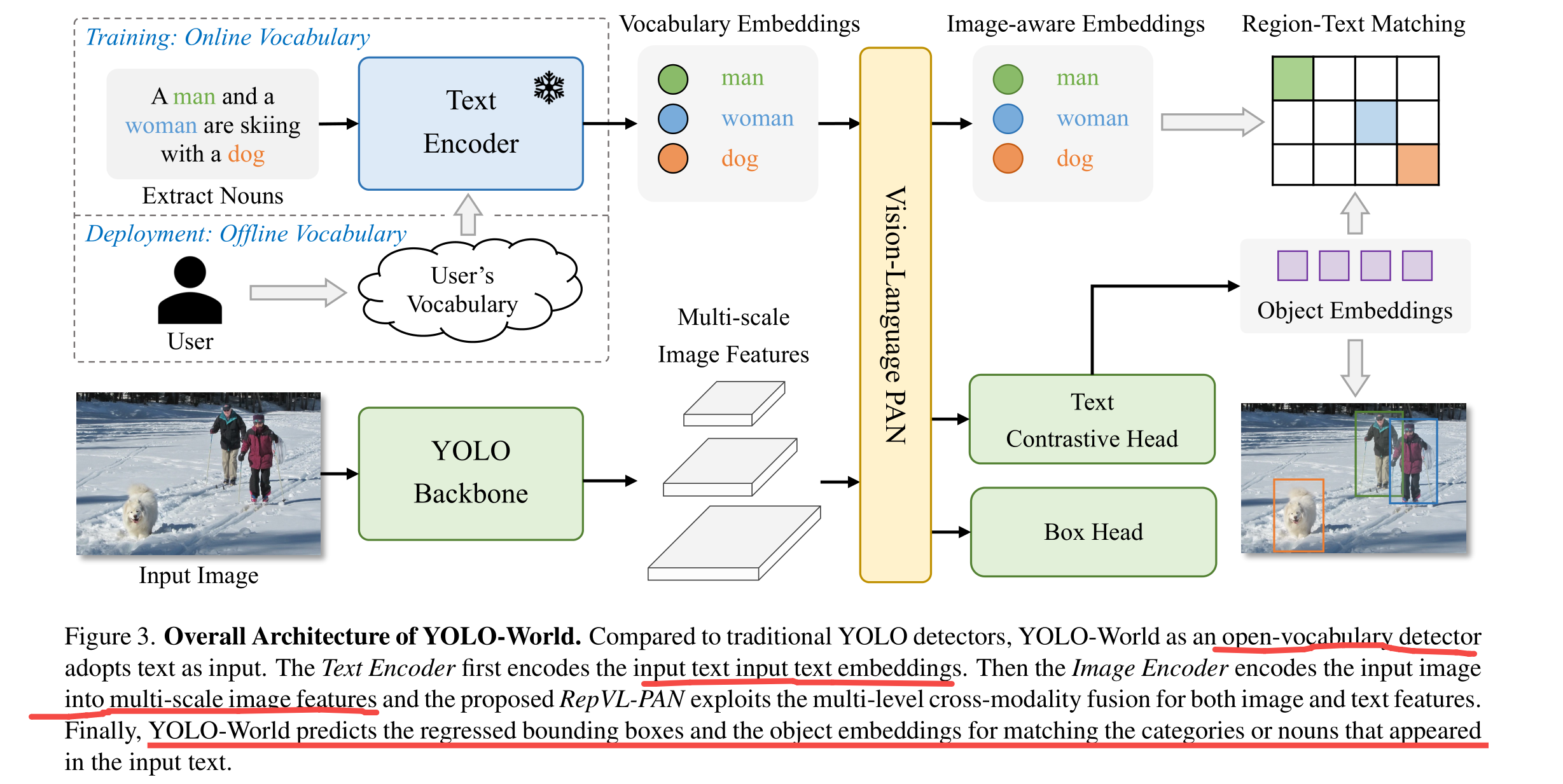
所提出的YOLO-World的整体架构如图3所示,包含一个YOLO检测器、一个文本编码器和一个可重参数化的视觉-语言路径聚合网络(RepVL-PAN)。给定输入文本,YOLO-World中的文本编码器将其编码为文本嵌入向量。YOLO检测器中的图像编码器从输入图像中提取多尺度特征。然后我们利用RepVL-PAN通过利用图像特征和文本嵌入向量之间的跨模态融合来增强文本和图像的表示。
YOLO检测器。YOLO-World主要基于YOLOv8[20]开发,包含一个用作图像编码器的Darknet骨架[20, 43]、一个用于多尺度特征金字塔的路径聚合网络(PAN),以及一个用于边界框回归和对象嵌入向量的头部。
文本编码器。给定文本T,我们采用由CLIP[39]预训练的Transformer文本编码器提取相应的文本嵌入向量W = TextEncoder(T) ∈ R^C×D,其中C是名词数量,D是嵌入维度。与纯文本的语言编码器[5]相比,CLIP文本编码器提供了更好的视觉-语义能力,以连接视觉对象和文本。当输入文本是标题或提及表达式时,我们使用简单的n-gram算法提取名词短语,然后将其输入文本编码器。
文本对比头。遵循以前的工作[20],我们采用带有两个3×3卷积层的解耦头来回归边界框{b_k}和对象嵌入向量{e_k},其中K表示对象数量。我们提出了一个文本对比头,通过以下方式获得对象-文本相似度s_k,j:
[ s_{k,j} = \alpha \cdot \text{L2-Norm}(e_k) \cdot \text{L2-Norm}(w_j)^\top + \beta ]
其中,L2-Norm(·)是L2规范化,并且w_j ∈ W是第j个文本嵌入向量。此外,我们添加了具有可学习的缩放因子α和平移因子β的仿射变换。L2规范化和仿射变换都对区域-文本训练的稳定性至关重要。
在线词汇训练。在训练期间,我们为含有4张图像的每个马赛克样本构建一个在线词汇表T。具体来说,我们对马赛克图像中涉及的所有积极名词进行采样,并从相应的数据集中随机抽取一些消极名词。每个马赛克样本的词汇表最多包含M个名词,M默认设置为80。
使用离线词汇的推理。在推理阶段,我们提出了一种使用离线词汇的提示然后检测策略以进一步提高效率。如图3所示,用户可以定义一系列自定义提示,其中可能包括标题或类别。然后我们利用文本编码器对这些提示进行编码,获得离线词汇嵌入。离线词汇允许避免针对每一输入的计算,并提供根据需要调整词汇的灵活性。
3.3 可重参数化的视觉-语言路径聚合网络(RepVL-PAN)
图4展示了所提出的RepVL-PAN的结构,该结构遵循[20, 29]中的自顶向下和自底向上路径来建立特征金字塔{P3,P4,P5},使用多尺度图像特征{C3,C4,C5}。此外,我们提出了文本引导的CSPLayer(T-CSPLayer)和图像池化注意力(I-Pooling Attention),以进一步增强图像特征和文本特征之间的交互,这可以改善视觉-语义表示,以提升开放词汇能力。在推理时,离线词汇嵌入可以被重参数化为卷积或线性层的权重进行部署。
文本引导CSPLayer。如图4所示,在自顶向下或自底向上融合后,使用交叉阶段局部层(CSPLayer)。我们通过将文本指导融入多尺度图像特征,扩展了[20]的CSPLayer(也称为C2f)来形成文本引导的CSPLayer。具体来说,给定文本嵌入W和图像特征(X_l \in R^{H×W×D} (l \in {3,4,5})),我们在最后的暗瓶颈模块后使用最大化sigmoid注意力,通过以下公式将文本特征聚合入图像特征:
[X’l = X_l \cdot \delta(\max{j \in {1…C}}(X_lW\top_j))\top,]
其中更新后的(X’_l)与交叉阶段特征进行连接作为输出。σ表示sigmoid函数。
图像池化注意力。为了用图像感知信息增强文本嵌入,我们提出图像池化注意力,通过聚合图像特征来更新文本嵌入。我们不直接在图像特征上使用交叉注意力,而是利用在多尺度特征上的最大池化来获取3×3区域,最终得到总共27个补丁代币(\tilde{X} \in R^{27×D})。然后通过以下方式更新文本嵌入:
[W’ = W + \text{MultiHead-Attention}(W, \tilde{X}, \tilde{X})]
3.4 预训练方案
在本节中,我们展示了在大规模检测、定位和图像-文本数据集上预训练YOLO-World的训练方案。
学习自区域-文本对比损失。给定马赛克样本I和文本T,YOLO-World输出K个目标预测({B_k, s_k}{k=1}^K)以及注释(\Omega = {B_i, t_i}{i=1}^N)。我们遵循[20]并利用任务对齐标签分配[9]来匹配预测与真实标注,并为每个正预测分配一个文本索引作为分类标签。基于这个词汇,我们通过在目标-文本(区域-文本)相似度和目标-文本分配之间的交叉熵,构造区域-文本对比损失(L_{\text{con}})。此外,我们还采用IoU损失和分布式焦点损失对边界框回归进行训练,总训练损失定义为:(L(I) = L_{\text{con}} + \lambda_I \cdot (L_{\text{iou}} + L_{\text{dfl}})),其中(\lambda_I)是指示因子,当输入图像I来自检测或定位数据时设置为1,来自图像-文本数据时设置为0。考虑到图像-文本数据集包含噪声边框,我们只为准确边界框的样本计算回归损失。
使用图像-文本数据的伪标签。我们提出一种自动标注方法来生成区域-文本对,而不是直接使用图像-文本对进行预训练。具体来说,标注方法包含三个步骤:(1)提取名词短语:我们首先使用n-gram算法从文本中提取名词短语;(2)伪标注:我们采用预训练的开放词汇检测器,如GLIP[24],为每个图像给定的名词短语生成伪边界框,从而提供粗略的区域-文本对。(3)过滤:我们采用预训练的CLIP[39]来评估图像-文本对和区域-文本对的相关性,并过滤掉相关性低的伪注释和图像。我们进一步通过使用非极大值抑制(NMS)等方法过滤冗余边界框。我们建议读者参考附录了解详细方法。通过上述方法,我们从CC3M[47]样本中抽样并标注了246k图像,共获得821k伪注释。
4. 实验
在本节中,我们通过在大规模数据集上预训练所提出的YOLO-World,并在LVIS基准和COCO基准上以零样本方式评估YOLO-World(第4.2节),展示了所提出YOLO-World的有效性。我们还评估了YOLO-World在COCO、LVIS上用于目标检测的微调性能。
4.1 实现细节
YOLO-World基于MMYOLO工具箱[3]和MMDetection工具箱[2]开发。遵循[20],我们提供了三个不同延迟要求的YOLO-World变体,例如小(S)、中(M)和大(L)。我们采用开源的CLIP[39]文本编码器和预训练权重来编码输入文本。除非特别说明,我们在一台NVIDIA V100 GPU上测量所有模型的推理速度,不使用额外加速机制,例如FP16或TensorRT。
4.2 预训练
实验设置。在预训练阶段,我们采用AdamW优化器[34],初始学习率为0.002,权重衰减为0.05。YOLO-World在32个NVIDIA V100 GPU上预训练了100个周期,总批量大小为512。在预训练期间,我们遵循以前的工作[20],采用颜色增强、随机仿射、随机翻转和带4张图像的马赛克进行数据增强。预训练期间文本编码器保持冻结。
预训练数据。对于YOLO-World的预训练,我们主要采用包括Objects365(V1)[46]、GQA[17]、Flickr30k[38]在内的检测或定位数据集,如表1所规定。遵循[24],我们从GoldG[21](GQA和Flickr30k)中排除了来自COCO数据集的图像。用于预训练的检测数据集的注释包含边界框和类别或名词短语。另外,我们还通过图像-文本对扩展了预训练数据,即CC3M†[47],我们通过第3.4节讨论的伪标签方法为其标注了246k图像。
零样本评估。预训练后,我们直接在LVIS数据集[14]上以零样本方式评估所提出的YOLO-World。LVIS数据集包含1203个目标类别,比预训练检测数据集的类别多得多,可以衡量大词汇量检测的性能。遵循之前的工作[21, 24, 56, 57],我们主要在LVIS minival[21]上评估,并报告固定AP[4]进行比较。预测的最大数量设置为1000。
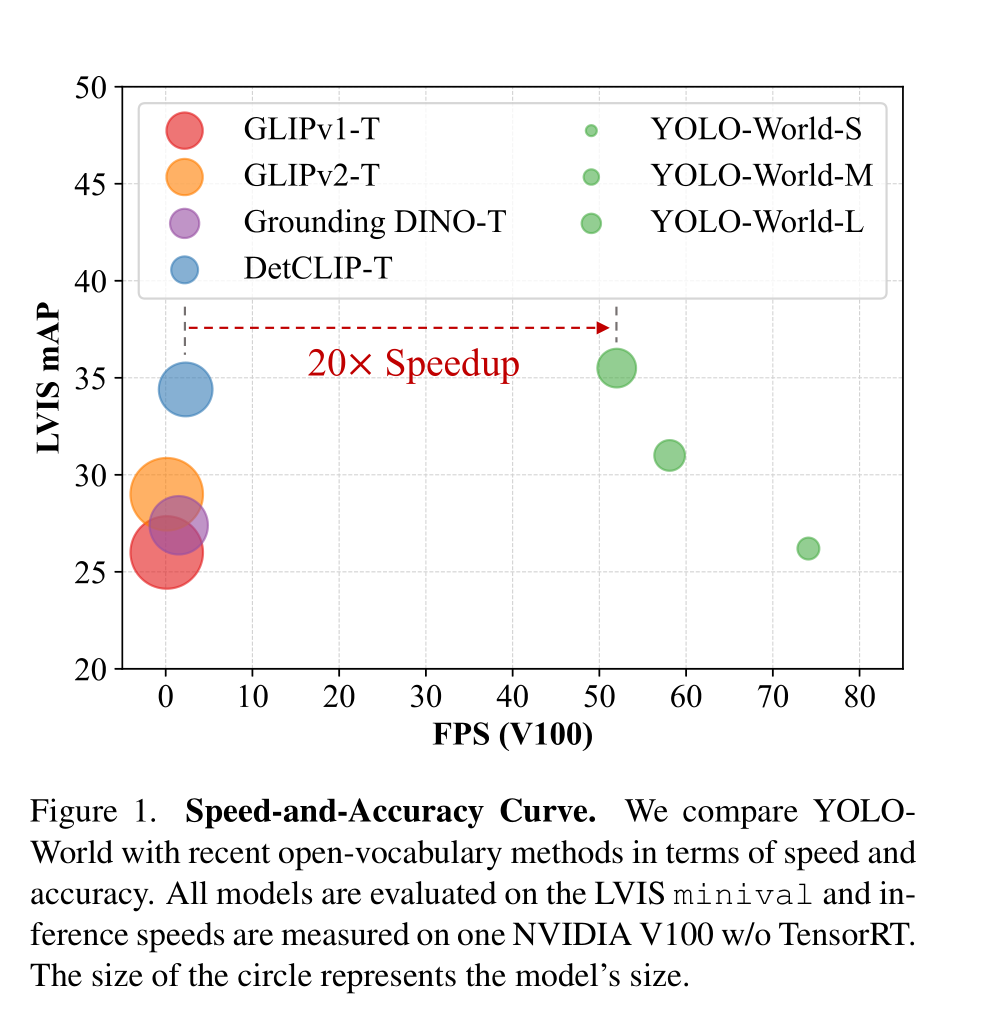
LVIS目标检测的主要结果。在表2中,我们将所提出的YOLO-World与最近的最先进方法[21, 30, 56, 57, 59]在LVIS基准上进行了零样本比较。考虑到计算负担和模型参数,我们主要与那些基于轻量级骨干网络,例如Swin-T[32]的方法进行比较。值得注意的是,YOLO-World在零样本性能和推理速度方面都超越了以前的最先进方法。与GLIP、GLIPv2和Grounding DINO相比,后者纳入了更多数据,例如Cap4M(CC3M+SBU[37]),即使YOLO-World的模型参数较少,也在预训练O365和GolG上获得了更好的性能。与DetCLIP相比,YOLO-World实现了可比性能(35.4对34.4),同时推理速度提高了20倍。实验结果还表明,小型模型,例如带有13M参数的YOLO-World-S,可用于视觉-语言预训练并获得强大的开放词汇能力。
4.3 消融实验
我们提供了广泛的消融研究,从两个主要方面分析YOLO-World,即预训练和架构。除非特别说明,我们主要基于YOLO-World-L进行消融实验,并在LVIS minival上进行Objects365的零样本评估。
预训练数据。在表3中,我们评估了使用不同数据预训练YOLO-World的性能。与仅在Objects365上训练的基线相比,添加GQA可以显著提高性能,在LVIS上增加了8.4 AP。这一改进可归因于GQA数据集提供的丰富文本信息,可以增强模型识别大词汇量目标的能力。添加CC3M样本的一部分(完整数据集的8%)可以进一步带来0.5 AP的提升,以及在稀有目标上的1.3 AP提升。表3表明,添加更多数据可以有效地提高在大词汇量场景下的检测能力。此外,随着数据量的增加,性能继续提高,凸显了利用更大更多样化的数据集进行训练的好处。
RepVL-PAN上的消融。表4展示了所提出的YOLO-World的RepVL-PAN,包括文本引导的CSPLayers和图像池化注意力,对零样本LVIS检测的有效性。具体来说,我们采用了两种设置,即(1)预训练在O365上和(2)预训练在O365和GQA上。与仅包含类别注释的O365相比,GQA包含丰富的文本,特别是以名词短语的形式。如表4所示,所提出的RepVL-PAN将基线(YOLOv8-PAN[20])在LVIS上提高了1.1 AP,并且在LVIS的稀有类别(APr)方面的改进尤为显著,这些类别难以检测和识别。此外,当YOLO-World在GQA数据集上进行预训练时,改进更为显著,实验表明所提出的RepVL-PAN在丰富的文本信息下表现更好。
4.6 可视化
我们提供了预训练的YOLO-World-L在三种设置下的可视化结果:(a)我们执行LVIS类别的零样本推理;(b)我们输入自定义提示,带有细粒度类别和属性;(c)提及检测。可视化结果还展示了YOLO-World具有强大的泛化能力,以适应开放词汇场景以及提及能力。
LVIS上的零样本推理。图5展示了基于LVIS类别的可视化结果,这些结果是由预训练的YOLO-World-L以零样本方式生成的。预训练的YOLO-World展现了强大的零样本迁移能力,并能够在图像中尽可能地检测到更多对象。
使用用户的词汇推理。在图6中,我们探索了YOLO-World与我们定义的类别的检测能力。可视化结果展示了预训练的YOLO-World-L还展示了(1)细粒度检测(即检测一个对象的部分)和(2)细粒度分类(即区分不同子类别的对象)的能力。
提及目标检测。在图7中,我们利用一些描述性(区别性)名词短语作为输入,例如,站立的人,来探索模型是否能够定位图像中与我们给定输入匹配的区域或对象。可视化结果显示了短语及其对应的边界框,证明了预训练的YOLO-World具有提及或基础定位能力。这一能力可以归因于我们提出的使用大规模训练数据的预训练策略。
5 结论
我们提出了YOLO-World,这是一个尖端的实时开放词汇检测器,旨在提高现实世界应用中的效率和开放词汇能力。在本文中,我们重新塑造了流行的YOLO作为视觉-语言YOLO架构,用于开放词汇预训练和检测,并提出了RepVL-PAN,它将视觉和语言信息与网络连接起来,并且可以为高效部署重新参数化。我们进一步提出了有效的使用检测、定位和图像-文本数据的预训练方案,以赋予YOLO-World强大的开放词汇检测能力。实验结果展示了YOLO-World在速度和开放词汇性能方面的优越性,并指出了在小型模型上进行视觉-语言预训练的有效性,这为未来研究提供了有益的见解。我们希望YOLO-World能成为解决现实世界开放词汇检测问题的新基准。
实际测试例子demo
https://huggingface.co/spaces/stevengrove/YOLO-World
帮助、问询
https://docs.qq.com/sheet/DUEdqZ2lmbmR6UVdU?tab=BB08J2
相关文章:
【深度学习】YOLO-World: Real-Time Open-Vocabulary Object Detection,目标检测
介绍一个酷炫的目标检测方式: 论文:https://arxiv.org/abs/2401.17270 代码:https://github.com/AILab-CVC/YOLO-World 文章目录 摘要Introduction第2章 相关工作2.1 传统目标检测2.2 开放词汇目标检测 第3章 方法3.1 预训练公式:…...

debian安装和基本使用
🐇明明跟你说过:个人主页 🏅个人专栏:《Kubernetes航线图:从船长到K8s掌舵者》 🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、Debian系统简介 2、Debian与其他Lin…...
nvm安装详细教程(安装nvm、node、npm、cnpm、yarn及环境变量配置)
一、安装nvm 1. 下载nvm 点击 网盘下载 进行下载 2、双击下载好的 nvm-1.1.12-setup.zip 文件 3.双击 nvm-setup.exe 开始安装 4. 选择我接受,然后点击next 5.选择nvm安装路径,路径名称不要有空格,然后点击next 6.node.js安装路径&#…...

优优嗨聚集团:如何优雅地解决个人债务问题,一步步走向财务自由
在快节奏的现代生活中,个人债务问题似乎已成为许多人不得不面对的挑战。正确处理个人债务,不仅关系到个人信用和财务状况,更是实现财务自由的重要一步。本文将为您提供一些实用的建议,帮助您优雅地解决个人债务问题,走…...
SpringCloud实用篇(四)——Nacos
Nacos nacos官方网站:https://nacos.io/ nacos是阿里巴巴的产品,现在是springcloud的一个组件,相比于eureka的功能更加丰富,在国内备受欢迎 nacos的安装 下载地址:https://github.com/alibaba/nacos/releases/ 启动…...
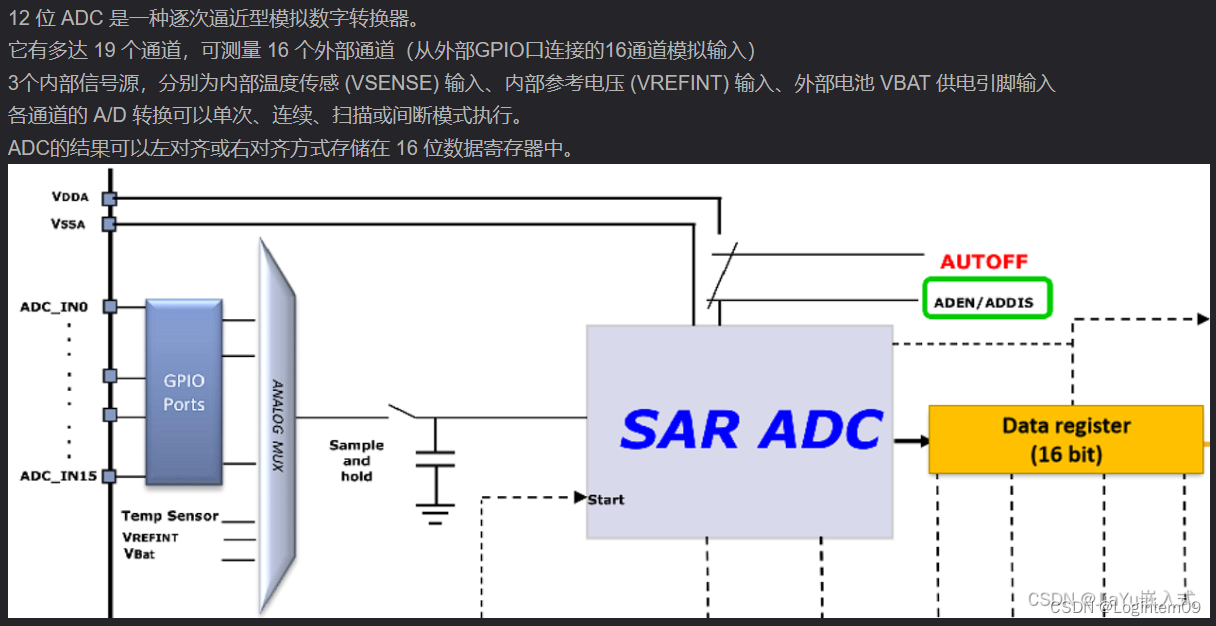
【嵌入式基础知识学习】AD/DA—数模/模数转换
AD/DA—数模/模数转换概念 数字电路只能处理二进制数字信号,而声音、温度、速度和光线等都是模拟量,利用相应的传感器(如声音用话筒)可以将它们转换成模拟信号,然后由A/D转换器将它们转换成二进制数字信号,…...

Swift中的结构体
Swift中的结构体是一种自定义的数据类型,可用于存储多个相关的值。结构体可以包含属性和方法,从而使其具有特定的功能。 结构体与类相似,但有一些重要的区别。最重要的区别是,结构体是值类型,而类是引用类型。这意味着…...

Selenium - java - 屏幕截图
文档地址 Selenium 浏览器自动化项目 | Selenium 安装 <dependency><groupId>org.seleniumhq.selenium</groupId><artifactId>selenium-java</artifactId><version>4.19.1</version></dependency>使用 创建WebDriver实例 …...
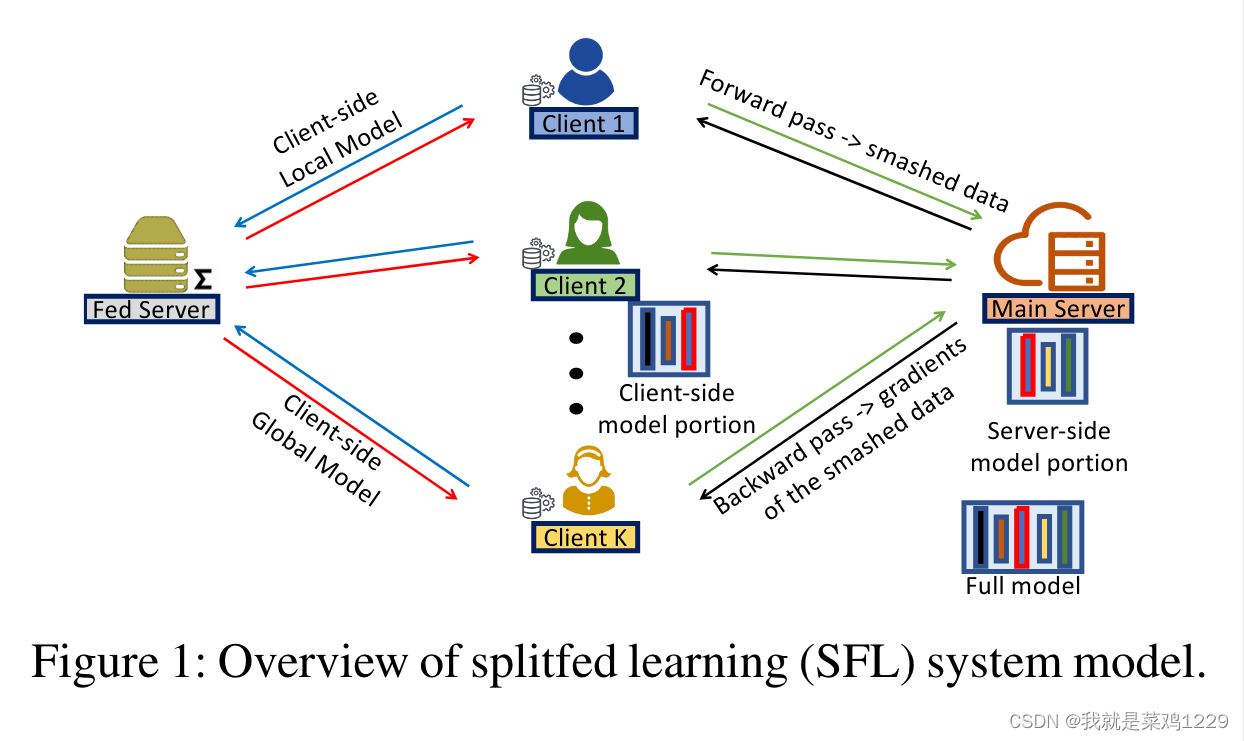
【论文阅读——SplitFed: When Federated Learning Meets Split Learning】
级别CCFA 1.摘要 联邦学习(FL)和分割学习(SL)是两种流行的分布式机器学习方法。两者都采用了模型对数据的场景;客户端在不共享原始数据的情况下训练和测试机器学习模型。由于机器学习模型的架构在客户端和服务器之间…...

Python使用方式介绍
1.安装与版本和IDE 1.1 python2.x和python3.x区别 python2在2020已经不再维护,目前主流开发使用python3. 二者语法上略有区别:输入输出、数据处理、异常和默认编码等,如:python3中字符串为Unicode字符串,使用UTF-8编码ÿ…...

浅述python中NumPy包
NumPy(Numerical Python)是Python的一种开源的数值计算扩展,提供了多维数组对象ndarray,是一个快速、灵活的大数据容器,可以用来存储和处理大型矩阵,支持大量的维度数组与矩阵运算,并针对数组运…...

jvm的面试回答
1、jvm由本地方法栈、虚拟机栈、方法区、程序计数器、堆组成,其中堆和方法区是线程间共享的,程序计数器、虚拟机栈和本地方法栈是线程私有的。 2、虚拟机栈: 保存每个java方法的调用、保存局部变量表、等 栈可能出现内存溢出,如果…...

打不动的蓝桥杯
打不动的蓝桥杯 2024-4-13 今天的蓝桥杯打得很烂,8题写了4题,100分可能有20来分吧。我写了的题好像都很简单,没什么竞争力。又觉得我知道的东西不止这么点,没能发挥。 这次比赛,首先,有强烈的陌生感。pytho…...
)
学习笔记——C语言基本概念文件——(13)
1、文件操作 1.1、文件概念 文件:实现数据存储的载体 1.2、文件的分类 按照数据的组织形式分类: 1.字符文件/文本文件 2.二进制文件 按照用途分类: 1.系统文件 2.库文件--标准库文件/非标准库文件(第三方库) 3.用…...
【MySQL】事务篇
SueWakeup 个人主页:SueWakeup 系列专栏:学习技术栈 个性签名:保留赤子之心也许是种幸运吧 目录 本系列专栏 1. 什么是事务 2. 事务的特征 原子性(Atomicity) 一致性(Consistency) 隔离性&…...
tsconfig.json文件常用配置
最近在学ts,因为tsconfig的配置实在太多啦,所以写此文章用作记录,也作分享 作用? tsconfig.jsono是ts编译器的配置文件,ts编译器可以根据它的信息来对代码进行编译 初始化一个tsconfig文件 tsc -init配置参数解释 …...

【Linux】tcpdump P1 - 网络过滤选项
文章目录 选项 -D选项 -c X选项 -n选项 -s端口捕获 port选项 -w总结 tcpdump 实用程序用于捕获和分析网络流量。系统管理员可以使用它来查看实时流量或将输出保存到文件中稍后分析。本文将演示在日常使用 tcpdump时可能想要使用的几种常见选项。 选项 -D 使用-D 选项的 tcpdu…...
网络篇04 | 应用层 mqtt(物联网)
网络篇04 | 应用层 mqtt(物联网) 1. MQTT协议介绍1.1 MQTT简介1.2 MQTT协议设计规范1.3 MQTT协议主要特性 2 MQTT协议原理2.1 MQTT协议实现方式2.2 发布/订阅、主题、会话2.3 MQTT协议中的方法 3. MQTT协议数据包结构3.1 固定头(Fixed header…...

Transformer模型-decoder解码器,target mask目标掩码的简明介绍
今天介绍transformer模型的decoder解码器,target mask目标掩码 背景 解码器层是对前面文章中提到的子层的包装器。它接受位置嵌入的目标序列,并将它们通过带掩码的多头注意力机制传递。使用掩码是为了防止解码器查看序列中的下一个标记。它迫使模型仅使用…...

All in One:Prometheus 多实例数据统一管理最佳实践
作者:淡唯(啃唯)、阳其凯(逸陵) 引言 Prometheus 作为目前最主流的可观测开源项目之一,已经成为云原生监控的事实标准,被众多企业广泛应用。在使用 Prometheus 的时候,我们经常会遇…...

智能路由器项目解析:基于策略路由实现多线路流量智能调度
1. 项目概述:一个“聪明”的路由器能做什么?最近在GitHub上看到一个挺有意思的项目,叫smart-router,作者是c0nSpIc0uS7uRk3r。光看名字,你可能会觉得这又是一个关于家庭网络优化的工具,但点进去仔细研究后&…...

Swagger2Word终极指南:3种方法实现API文档自动化转换
Swagger2Word终极指南:3种方法实现API文档自动化转换 【免费下载链接】swagger2word 项目地址: https://gitcode.com/gh_mirrors/swa/swagger2word 还在为手动编写API文档而烦恼吗?Swagger2Word为你提供了一站式自动化解决方案,将Swa…...

荣品RV1126 SDK编译避坑指南:从环境配置到分区调整,手把手解决常见编译错误
RV1126 SDK编译实战:从环境搭建到分区优化的全流程解决方案 1. 开发环境配置与初始化 RV1126开发环境的搭建是整个开发流程的第一步,也是后续所有工作的基础。一个稳定、高效的开发环境能够显著提升开发效率,减少不必要的错误。 首先需要确保…...

构建轻量级LLM工具集:模块化设计、多模型集成与本地化部署实践
1. 项目概述:一个面向日常的轻量级LLM工具集最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“Daily-LLM”。光看名字,你可能会觉得这又是一个庞大的、需要海量算力才能跑起来的“大模型”项目。但点进去仔细研究后,我…...

Gitclaw:封装复杂Git操作,提升开发效率的命令行工具
1. 项目概述:一个为Git操作注入“爪牙”的命令行工具如果你和我一样,日常开发工作重度依赖Git,那你肯定也经历过这样的时刻:面对一个需要多步操作才能完成的复杂Git任务,比如清理多个已合并的分支、批量重写提交历史中…...

Go语言实现Hermes引擎:高性能JavaScript字节码虚拟机解析与实践
1. 项目概述:一个Go语言实现的Hermes引擎最近在折腾一些需要高性能模板渲染的后端服务,偶然间在GitHub上发现了LAI-755/hermes-go这个项目。简单来说,这是一个用纯Go语言实现的Hermes引擎。如果你对前端生态熟悉,可能听说过Hermes…...

017、Docker在TinyML开发中的应用
017 Docker在TinyML开发中的应用 从一次“环境地狱”说起 上个月帮团队调一个STM32上的TinyML推理延迟问题,模型是MobileNetV2量化版,在开发板上跑得好好的,换到同事的Ubuntu 20.04机器上编译,死活链接不上CMSIS-NN库。折腾半天发现他系统里默认的arm-none-eabi-gcc版本是…...

基于BLE信号强度的寻物游戏:用CircuitPython实现无线接近探测
1. 项目概述:一个用蓝牙信号“捉迷藏”的硬件游戏几年前我第一次接触Adafruit的Circuit Playground系列开发板时,就被它那种“开箱即玩”的理念吸引了。它把LED、按钮、传感器都集成在一块板子上,让你不用焊接就能快速验证想法。后来出的Circ…...

智能跨平台文件同步革命:OpenMTP让Mac与Android无缝连接
智能跨平台文件同步革命:OpenMTP让Mac与Android无缝连接 【免费下载链接】openmtp OpenMTP - Advanced Android File Transfer Application for macOS 项目地址: https://gitcode.com/gh_mirrors/op/openmtp 你是否曾经为Mac和Android设备之间的文件传输而烦…...

复杂会场巡检机器人路径规划【附代码】
✨ 长期致力于路径规划、RRT~*算法、人工势场法、自动巡检研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)提出基于安全边界与朝向合力场随机游走的改…...