【爬虫开发】爬虫从0到1全知识md笔记第5篇:Selenium课程概要,selenium的其它使用方法【附代码文档】

爬虫开发从0到1全知识教程完整教程(附代码资料)主要内容讲述:爬虫课程概要,爬虫基础爬虫概述, ,http协议复习。requests模块,requests模块1. requests模块介绍,2. response响应对象,3. requests模块发送请求,4. requests模块发送post请求,5. 利用requests.session进行状态保持。数据提取概要,数据提取概述1. 响应内容的分类,2. 认识xml以及和html的区别,1. jsonpath模块的使用场景,2. jsonpath模块的使用方法,3. jsonpath练习,1. 了解 lxml模块和xpath语法。Selenium课程概要selenium的介绍,selenium提取数据。Selenium课程概要,反爬与反反爬selenium的其它使用方法。反爬与反反爬常见的反爬手段和解决思路。反爬与反反爬验证码处理,chrome浏览器使用方法介绍。反爬与反反爬,Mongodb数据库JS的解析,介绍,内容,mongodb文档,Mongodb的介绍和安装,小结。Mongodb数据库介绍,内容,mongodb文档,mongodb的简单使用,小结,Mongodb的的增删改查。Mongodb数据库介绍,内容,mongodb文档,mongodb的聚合操作,2 mongodb的常用管道和表达式,Mongodb的索引操作。Mongodb数据库,scrapy爬虫框架介绍,内容,mongodb文档,mongodb和python交互,小结,介绍。scrapy爬虫框架,scrapy爬虫框架介绍,内容,scrapy官方文档,scrapy的入门使用,小结,介绍。scrapy爬虫框架介绍,内容,scrapy官方文档,scrapy管道的使用,小结,scrapy的crawlspider爬虫。scrapy爬虫框架介绍,内容,scrapy官方文档,scrapy中间件的使用,小结,scrapy_redis概念作用和流程。scrapy爬虫框架介绍,内容,scrapy官方文档,scrapy_redis原理分析并实现断点续爬以及分布式爬虫,小结,scrapy_splash组件的使用。scrapy爬虫框架介绍,内容,scrapy官方文档,scrapy的日志信息与配置,小结,scrapyd部署scrapy项目。利用appium抓取app中的信息,利用appium抓取app中的信息介绍,内容,appium环境安装,介绍,内容,利用appium自动控制移动设备并提取数据。appium环境安装,Mongodb的介绍和安装,小结。scrapy的概念和流程 ,小结,selenium的介绍,常见的反爬手段和解决思路。数据提取概述1. 响应内容的分类,2. 认识xml以及和html的区别,爬虫概述,http协议复习。mongodb的简单使用,小结,scrapy的入门使用,小结。selenium提取数据,利用appium自动控制移动设备并提取数据。验证码处理。数据提取-jsonpath模块1. jsonpath模块的使用场景,2. jsonpath模块的使用方法,3. jsonpath练习,chrome浏览器使用方法介绍,Mongodb的的增删改查,小结。scrapy数据建模与请求,小结,selenium的其它使用方法。数据提取-lxml模块1. 了解 lxml模块和xpath语法,2. 谷歌浏览器xpath helper插件的安装和使用,3. xpath的节点关系,4. xpath语法-基础节点选择语法,5. xpath语法-节点修饰语法,6. xpath语法-其他常用节点选择语法。JS的解析,mongodb的聚合操作,2 mongodb的常用管道和表达式。scrapy模拟登陆,小结,Mongodb的索引操作,小结,scrapy管道的使用,小结。Mongodb的权限管理,小结,scrapy中间件的使用,小结。mongodb和python交互,小结,scrapy_redis概念作用和流程,小结,scrapy_redis原理分析并实现断点续爬以及分布式爬虫,小结。scrapy_splash组件的使用,小结,scrapy的日志信息与配置,小结。scrapyd部署scrapy项目,13.Gerapy,13.Gerapy。1.2.1-简单的代码实现,目标urlscrapy的crawlspider爬虫。
,http协议复习。requests模块,requests模块1. requests模块介绍,2. response响应对象,3. requests模块发送请求,4. requests模块发送post请求,5. 利用requests.session进行状态保持。数据提取概要,数据提取概述1. 响应内容的分类,2. 认识xml以及和html的区别,1. jsonpath模块的使用场景,2. jsonpath模块的使用方法,3. jsonpath练习,1. 了解 lxml模块和xpath语法。Selenium课程概要selenium的介绍,selenium提取数据。Selenium课程概要,反爬与反反爬selenium的其它使用方法。反爬与反反爬常见的反爬手段和解决思路。反爬与反反爬验证码处理,chrome浏览器使用方法介绍。反爬与反反爬,Mongodb数据库JS的解析,介绍,内容,mongodb文档,Mongodb的介绍和安装,小结。Mongodb数据库介绍,内容,mongodb文档,mongodb的简单使用,小结,Mongodb的的增删改查。Mongodb数据库介绍,内容,mongodb文档,mongodb的聚合操作,2 mongodb的常用管道和表达式,Mongodb的索引操作。Mongodb数据库,scrapy爬虫框架介绍,内容,mongodb文档,mongodb和python交互,小结,介绍。scrapy爬虫框架,scrapy爬虫框架介绍,内容,scrapy官方文档,scrapy的入门使用,小结,介绍。scrapy爬虫框架介绍,内容,scrapy官方文档,scrapy管道的使用,小结,scrapy的crawlspider爬虫。scrapy爬虫框架介绍,内容,scrapy官方文档,scrapy中间件的使用,小结,scrapy_redis概念作用和流程。scrapy爬虫框架介绍,内容,scrapy官方文档,scrapy_redis原理分析并实现断点续爬以及分布式爬虫,小结,scrapy_splash组件的使用。scrapy爬虫框架介绍,内容,scrapy官方文档,scrapy的日志信息与配置,小结,scrapyd部署scrapy项目。利用appium抓取app中的信息,利用appium抓取app中的信息介绍,内容,appium环境安装,介绍,内容,利用appium自动控制移动设备并提取数据。appium环境安装,Mongodb的介绍和安装,小结。scrapy的概念和流程 ,小结,selenium的介绍,常见的反爬手段和解决思路。数据提取概述1. 响应内容的分类,2. 认识xml以及和html的区别,爬虫概述,http协议复习。mongodb的简单使用,小结,scrapy的入门使用,小结。selenium提取数据,利用appium自动控制移动设备并提取数据。验证码处理。数据提取-jsonpath模块1. jsonpath模块的使用场景,2. jsonpath模块的使用方法,3. jsonpath练习,chrome浏览器使用方法介绍,Mongodb的的增删改查,小结。scrapy数据建模与请求,小结,selenium的其它使用方法。数据提取-lxml模块1. 了解 lxml模块和xpath语法,2. 谷歌浏览器xpath helper插件的安装和使用,3. xpath的节点关系,4. xpath语法-基础节点选择语法,5. xpath语法-节点修饰语法,6. xpath语法-其他常用节点选择语法。JS的解析,mongodb的聚合操作,2 mongodb的常用管道和表达式。scrapy模拟登陆,小结,Mongodb的索引操作,小结,scrapy管道的使用,小结。Mongodb的权限管理,小结,scrapy中间件的使用,小结。mongodb和python交互,小结,scrapy_redis概念作用和流程,小结,scrapy_redis原理分析并实现断点续爬以及分布式爬虫,小结。scrapy_splash组件的使用,小结,scrapy的日志信息与配置,小结。scrapyd部署scrapy项目,13.Gerapy,13.Gerapy。1.2.1-简单的代码实现,目标urlscrapy的crawlspider爬虫。
全套笔记资料代码移步: 前往gitee仓库查看
感兴趣的小伙伴可以自取哦,欢迎大家点赞转发~
全套教程部分目录:


部分文件图片:
Selenium课程概要
本阶段课程主要学习selenium自动化测试框架在爬虫中的应用,selenium能够大幅降低爬虫的编写难度,但是也同样会大幅降低爬虫的爬取速度。在逼不得已的情况下我们可以使用selenium进行爬虫的编写。
selenium的其它使用方法
知识点:
- 掌握 selenium控制标签页的切换
- 掌握 selenium控制iframe的切换
- 掌握 利用selenium获取cookie的方法
- 掌握 手动实现页面等待
- 掌握 selenium控制浏览器执行js代码的方法
- 掌握 selenium开启无界面模式
- 了解 selenium使用ip
- 了解 selenium替换user-agent
1. selenium标签页的切换
当selenium控制浏览器打开多个标签页时,如何控制浏览器在不同的标签页中进行切换呢?需要我们做以下两步:
- 获取所有标签页的窗口句柄
-
利用窗口句柄字切换到句柄指向的标签页
-
这里的窗口句柄是指:指向标签页对象的标识
-
[关于句柄请课后了解更多,本小节不做展开](
-
具体的方法
# 1. 获取当前所有的标签页的句柄构成的列表current_windows = driver.window_handles# 2. 根据标签页句柄列表索引下标进行切换driver.switch_to.window(current_windows[0])
- 参考代码示例:
import time
from selenium import webdriverdriver = webdriver.Chrome()
driver.get("time.sleep(1)
driver.find_element_by_id('kw').send_keys('python')
time.sleep(1)
driver.find_element_by_id('su').click()
time.sleep(1)# 通过执行js来新开一个标签页js = 'window.open("
driver.execute_script(js)
time.sleep(1)# 1. 获取当前所有的窗口windows = driver.window_handlestime.sleep(2)# 2. 根据窗口索引进行切换driver.switch_to.window(windows[0])
time.sleep(2)
driver.switch_to.window(windows[1])time.sleep(6)
driver.quit()
知识点:掌握 selenium控制标签页的切换
2. switch_to切换frame标签
iframe是html中常用的一种技术,即一个页面中嵌套了另一个网页,selenium默认是访问不了frame中的内容的,对应的解决思路是driver.switch_to.frame(frame_element)。接下来我们通过qq邮箱模拟登陆来学习这个知识点
- 参考代码:
import time
from selenium import webdriverdriver = webdriver.Chrome()url = '
driver.get(url)
time.sleep(2)login_frame = driver.find_element_by_id('login_frame') # 根据id定位 frame元素
driver.switch_to.frame(login_frame) # 转向到该frame中driver.find_element_by_xpath('//*[@id="u"]').send_keys('1596930226@qq.com')
time.sleep(2)driver.find_element_by_xpath('//*[@id="p"]').send_keys('hahamimashicuode')
time.sleep(2)driver.find_element_by_xpath('//*[@id="login_button"]').click()
time.sleep(2)"""操作frame外边的元素需要切换出去"""
windows = driver.window_handles
driver.switch_to.window(windows[0])content = driver.find_element_by_class_name('login_pictures_title').text
print(content)driver.quit()
-
总结:
-
切换到定位的frame标签嵌套的页面中
driver.switch_to.frame(通过find_element_by函数定位的frame、iframe标签对象)
-
利用切换标签页的方式切出frame标签
- ```python windows = driver.window_handles driver.switch_to.window(windows[0])
---##### 知识点:掌握 selenium控制frame标签的切换---### 3. selenium对cookie的处理>
selenium能够帮助我们处理页面中的cookie,比如获取、删除,接下来我们就学习这部分知识#### 3.1 获取cookie>
`driver.get_cookies()`返回列表,其中包含的是完整的cookie信息!不光有name、value,还有domain等cookie其他维度的信息。所以如果想要把获取的cookie信息和requests模块配合使用的话,需要转换为name、value作为键值对的cookie字典
```python# 获取当前标签页的全部cookie信息print(driver.get_cookies())# 把cookie转化为字典cookies_dict = {cookie[‘name’]: cookie[‘value’] for cookie in driver.get_cookies()}
3.2 删除cookie
#删除一条cookiedriver.delete_cookie("CookieName")# 删除所有的cookiedriver.delete_all_cookies()
知识点:掌握 利用selenium获取cookie的方法
4. selenium控制浏览器执行js代码
selenium可以让浏览器执行我们规定的js代码,运行下列代码查看运行效果
import time
from selenium import webdriverdriver = webdriver.Chrome()
driver.get("
time.sleep(1)js = 'window.scrollTo(0,document.body.scrollHeight)' # js语句
driver.execute_script(js) # 执行js的方法time.sleep(5)
driver.quit()
- 执行js的方法:
driver.execute_script(js)
知识点:掌握 selenium控制浏览器执行js代码的方法
5. 页面等待
页面在加载的过程中需要花费时间等待网站服务器的响应,在这个过程中标签元素有可能还没有加载出来,是不可见的,如何处理这种情况呢?
- 页面等待分类
- 强制等待介绍
- 显式等待介绍
- 隐式等待介绍
- 手动实现页面等待
5.1 页面等待的分类
首先我们就来了解以下selenium页面等待的分类
- 强制等待
- 隐式等待
- 显式等待
5.2 强制等待(了解)
- 其实就是time.sleep()
- 缺点时不智能,设置的时间太短,元素还没有加载出来;设置的时间太长,则会浪费时间
5.3 隐式等待
-
隐式等待针对的是元素定位,隐式等待设置了一个时间,在一段时间内判断元素是否定位成功,如果完成了,就进行下一步
-
在设置的时间内没有定位成功,则会报超时加载
-
示例代码
from selenium import webdriverdriver = webdriver.Chrome() driver.implicitly_wait(10) # 隐式等待,最长等20秒 driver.get('driver.find_element_by_xpath()
5.4 显式等待(了解)
-
每经过多少秒就查看一次等待条件是否达成,如果达成就停止等待,继续执行后续代码
-
如果没有达成就继续等待直到超过规定的时间后,报超时异常
-
示例代码
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By driver = webdriver.Chrome()driver.get('# 显式等待WebDriverWait(driver, 20, 0.5).until(EC.presence_of_element_located((By.LINK_TEXT, '好123'))) # 参数20表示最长等待20秒# 参数0.5表示0.5秒检查一次规定的标签是否存在# EC.presence_of_element_located((By.LINK_TEXT, '好123')) 表示通过链接文本内容定位标签# 每0.5秒一次检查,通过链接文本内容定位标签是否存在,如果存在就向下继续执行;如果不存在,直到20秒上限就抛出异常print(driver.find_element_by_link_text('好123').get_attribute('href'))
driver.quit()
5.5 手动实现页面等待
在了解了隐式等待和显式等待以及强制等待后,我们发现并没有一种通用的方法来解决页面等待的问题,比如“页面需要滑动才能触发ajax异步加载”的场景,那么接下来我们就以[淘宝网首页](
-
原理:
-
利用强制等待和显式等待的思路来手动实现
-
不停的判断或有次数限制的判断某一个标签对象是否加载完毕(是否存在)
-
实现代码如下:
import time
from selenium import webdriver
driver = webdriver.Chrome('/home/worker/Desktop/driver/chromedriver')driver.get('
time.sleep(1)# i = 0# while True:for i in range(10):i += 1try:time.sleep(3)element = driver.find_element_by_xpath('//div[@class="shop-inner"]/h3[1]/a')print(element.get_attribute('href'))breakexcept:js = 'window.scrollTo(0, {})'.format(i*500) # js语句driver.execute_script(js) # 执行js的方法
driver.quit()
知识点:掌握 手动实现页面等待
6. selenium开启无界面模式
绝大多数服务器是没有界面的,selenium控制谷歌浏览器也是存在无界面模式的,这一小节我们就来学习如何开启无界面模式(又称之为无头模式)
-
开启无界面模式的方法
-
实例化配置对象
options = webdriver.ChromeOptions()
-
配置对象添加开启无界面模式的命令
options.add_argument("--headless")
-
配置对象添加禁用gpu的命令
options.add_argument("--disable-gpu")
-
实例化带有配置对象的driver对象
driver = webdriver.Chrome(chrome_options=options)
-
注意:macos中chrome浏览器59+版本,Linux中57+版本才能使用无界面模式!
- 参考代码如下:
from selenium import webdriveroptions = webdriver.ChromeOptions() # 创建一个配置对象
options.add_argument("--headless") # 开启无界面模式
options.add_argument("--disable-gpu") # 禁用gpu# options.set_headles() # 无界面模式的另外一种开启方式driver = webdriver.Chrome(chrome_options=options) # 实例化带有配置的driver对象driver.get('
print(driver.title)
driver.quit()
知识点:掌握 selenium开启无界面模式
7. selenium使用ip
selenium控制浏览器也是可以使用ip的!
-
使用ip的方法
-
实例化配置对象
options = webdriver.ChromeOptions()
-
配置对象添加使用ip的命令
- `options.add_argument('--proxy-server=
-
实例化带有配置对象的driver对象
driver = webdriver.Chrome('./chromedriver', chrome_options=options)
-
参考代码如下:
from selenium import webdriveroptions = webdriver.ChromeOptions() # 创建一个配置对象
options.add_argument('--proxy-server= # 使用ipdriver = webdriver.Chrome(chrome_options=options) # 实例化带有配置的driver对象driver.get('
print(driver.title)
driver.quit()
知识点:了解 selenium使用ip
8. selenium替换user-agent
selenium控制谷歌浏览器时,User-Agent默认是谷歌浏览器的,这一小节我们就来学习使用不同的User-Agent
-
替换user-agent的方法
-
实例化配置对象
options = webdriver.ChromeOptions()
-
配置对象添加替换UA的命令
options.add_argument('--user-agent=Mozilla/5.0 HAHA')
-
实例化带有配置对象的driver对象
driver = webdriver.Chrome('./chromedriver', chrome_options=options)
-
参考代码如下:
from selenium import webdriveroptions = webdriver.ChromeOptions() # 创建一个配置对象
options.add_argument('--user-agent=Mozilla/5.0 HAHA') # 替换User-Agentdriver = webdriver.Chrome('./chromedriver', chrome_options=options)driver.get('
print(driver.title)
driver.quit()
知识点:了解 selenium替换user-agent
反爬与反反爬
本阶段课程主要学习爬虫的反爬及应对方法。
未完待续, 同学们请等待下一期
全套笔记资料代码移步: 前往gitee仓库查看
感兴趣的小伙伴可以自取哦,欢迎大家点赞转发~
相关文章:
【爬虫开发】爬虫从0到1全知识md笔记第5篇:Selenium课程概要,selenium的其它使用方法【附代码文档】
爬虫开发从0到1全知识教程完整教程(附代码资料)主要内容讲述:爬虫课程概要,爬虫基础爬虫概述,,http协议复习。requests模块,requests模块1. requests模块介绍,2. response响应对象,3. requests模块发送请求,4. request…...

【我的代码生成器】React的FrmUser类源码
FrmUser 类的源码中:FrmUser btnSaveClick 等命名方式都是参考VB.Net的写法。 import React, { forwardRef, useImperativeHandle, useState, useEffect, } from "react"; import { makeStyles, TextField, Grid, Paper, Button, ButtonGroup, } from &q…...

Flutter 单例模式的多种实现方法与使用场景分析
单例模式是一种常用的设计模式,用于确保一个类只有一个实例,并提供一个全局访问点。在Flutter应用程序中,单例模式可以有效地管理全局状态、资源共享和对象的生命周期。本文将介绍Flutter中实现单例模式的多种方法,并分析它们的使…...

C语言洛谷题目分享(9)奇怪的电梯
目录 1.前言 2.题目:奇怪的电梯 1.题目描述 2.输入格式 3.输出格式 4.输入输出样例 5.说明 6.题解 3.小结 1.前言 哈喽大家好啊,前一段时间小编去备战蓝桥杯所以博客的更新就暂停了几天,今天继续为大家带来题解分享,希望大…...
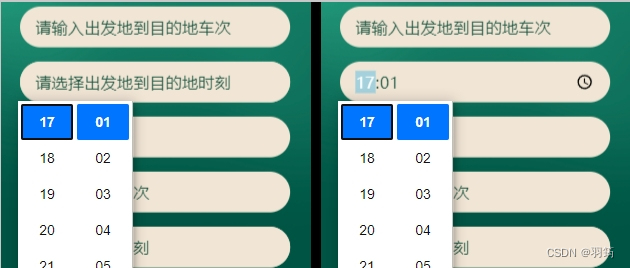
vue 中使 date/time/datetime 类型的 input 支持 placeholder 方法
一般在开发时,设置了 date/time/datetime 等类型的 input 属性 placeholder 提示文本时, 发现实际展示中却并不生效,如图: 处理后效果如图: 处理逻辑 判断表单项未设置值时,则设置其伪类样式,文…...
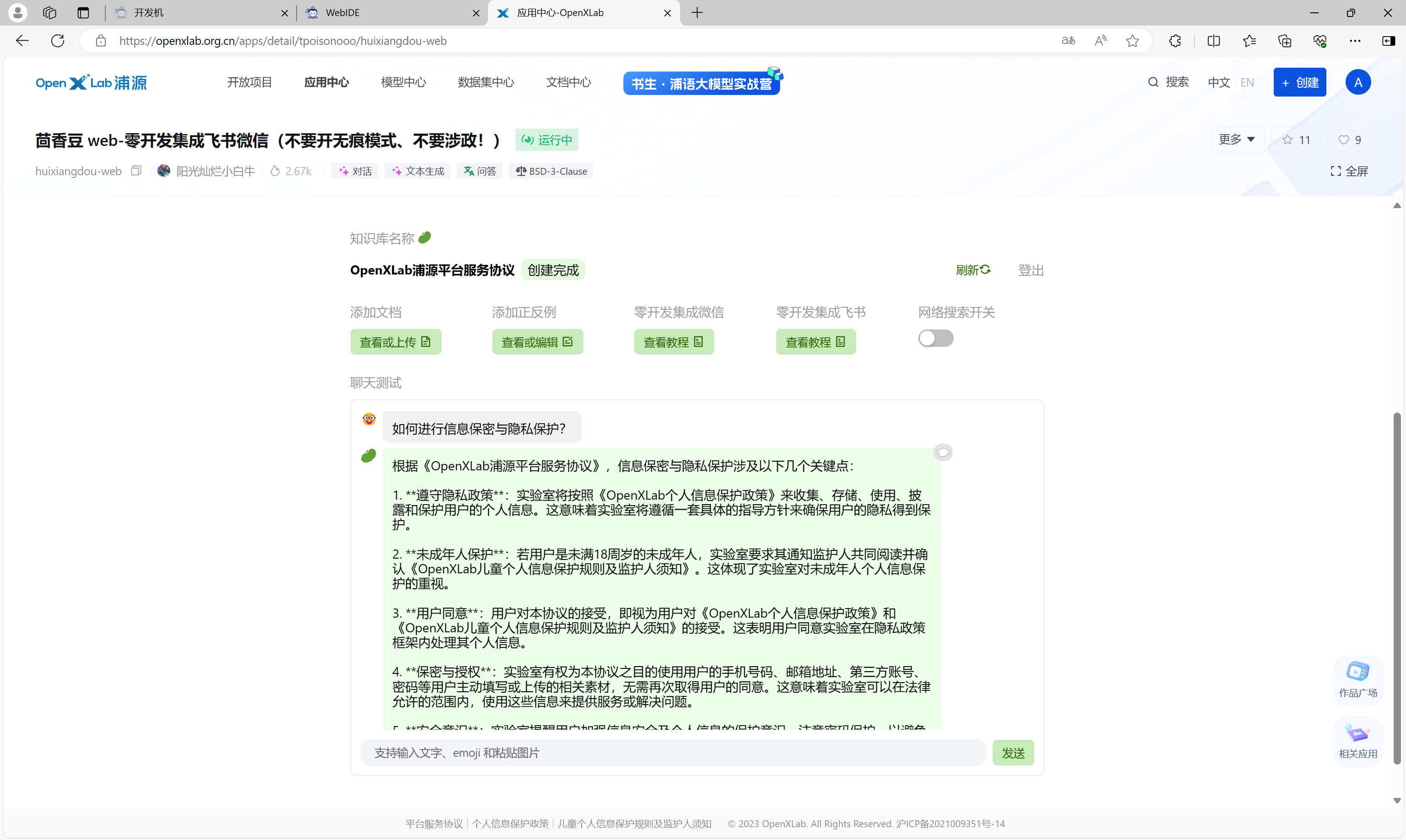
书生·浦语大模型全链路开源体系-第3课
书生浦语大模型全链路开源体系-第3课 书生浦语大模型全链路开源体系-第3课相关资源RAG 概述在 InternLM Studio 上部署茴香豆技术助手环境配置配置基础环境下载基础文件下载安装茴香豆 使用茴香豆搭建 RAG 助手修改配置文件 创建知识库运行茴香豆知识助手 在茴香豆 Web 版中创建…...
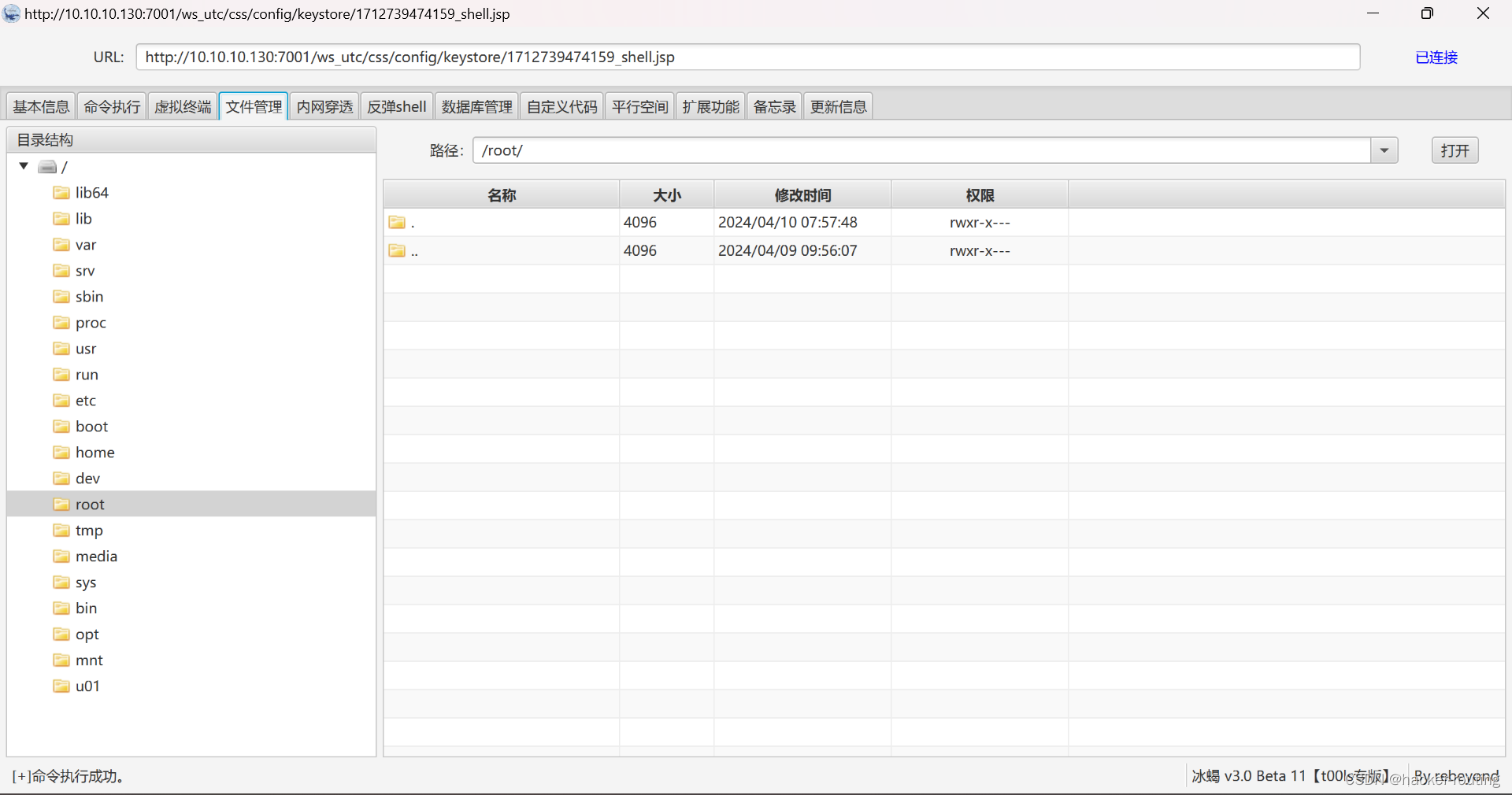
Weblogic任意文件上传漏洞(CVE-2018-2894)漏洞复现(基于vulhub)
🍬 博主介绍👨🎓 博主介绍:大家好,我是 hacker-routing ,很高兴认识大家~ ✨主攻领域:【渗透领域】【应急响应】 【Java、PHP】 【VulnHub靶场复现】【面试分析】 🎉点赞➕评论➕收…...
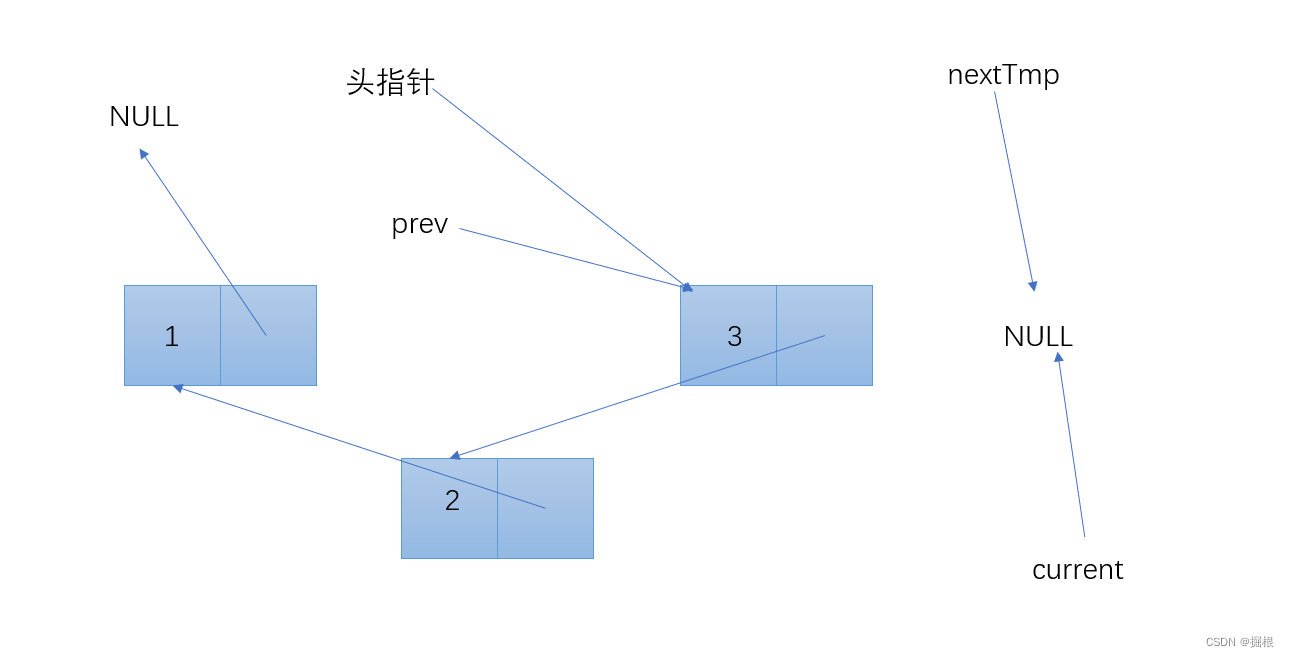
链表基础3——单链表的逆置
链表的定义 #include <stdio.h> #include <stdlib.h> typedef struct Node { int data; struct Node* next; } Node; Node* createNode(int data) { Node* newNode (Node*)malloc(sizeof(Node)); if (!newNode) { return NULL; } newNode->data …...

Fiddler:网络调试利器
目录 第1章:Fiddler简介和安装 1.1 Fiddler概述 1.2 Fiddler的安装步骤 步骤1:下载Fiddler 步骤2:运行安装程序 步骤3:启动Fiddler 1.3 配置Fiddler代理 配置操作系统代理 配置浏览器代理 Google Chrome Mozilla Firefox 第2章:Fiddler界面和基本操作 2.1 Fi…...
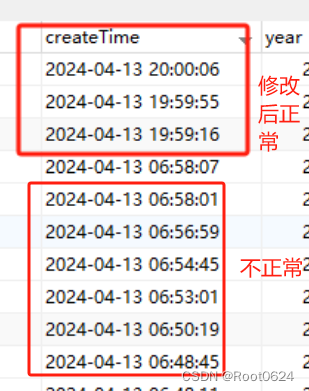
【笔记】mysql版本6以上时区问题
前言 最近在项目中发现数据库某个表的createTime字段的时间比中国时间少了13个小时,只是在数据库中查看显示时间不对,但是在页面,又是正常显示中国时区的时间。 排查 项目中数据库的驱动使用的是8.0.19,驱动类使用的是com.mysq…...

Scala实战:打印九九表
本次实战的目标是使用不同的方法实现打印九九表的功能。我们将通过四种不同的方法来实现这个目标,并在day02子包中创建相应的对象。 方法一:双重循环 我们将使用双重循环来实现九九表的打印。在NineNineTable01对象中,我们使用两个嵌套的fo…...
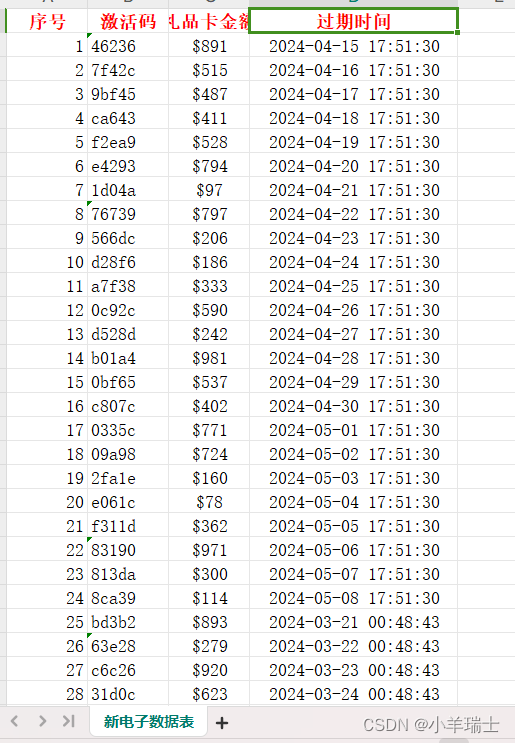
Excel文件解析
在此模块的学习中,我们需要一个新的开源类库---Apahche POI开源类库。这个类库的用途是:解析并生成Excel文件(Word、ppt)。Apahche POI基于DOM方式进行解析,将文件直接加载到内存,所以速度比较快,适合Excel文件数据量不…...

纯css实现switch开关
代码比较简单,有需要直接在下边粘贴使用吧~ html: <div class"switch-box"><input id"switch" type"checkbox"><label></label></div> css: .switch-box {position: relative;height: 25px…...

Unity3d 微信小游戏 AB资源问题
简介 最近在做微信小游戏,因为对unity比较熟悉,而且微信也支持了用unity3d直接导出到小游戏的工具,所以就记录下这期间遇到的问题 微信小游戏启动时间主要受以下三点影响: 下载小游戏首包数据文件下载和编译wasm代码引擎初始化…...

Leetcode二叉树刷题
给你一个二叉树的根节点 root , 检查它是否轴对称。 示例 1: 输入:root [1,2,2,3,4,4,3] 输出:true public boolean isSymmetric(TreeNode root) {if(rootnull)return true;return compare(root.left,root.right);}public boole…...

如何给自己的网站添加 https ssl 证书
文章目录 一、简介二、申请 ssl 证书三、下载 ssl 证书四、配置 nginx五、开放 443 端口六、常见问题解决(一)、配置后,访问 https 无法连接成功(二) 证书配置成功,但是访问 https 还是报不安全 总结参考资料 一、简介 相信大家都知道 https 是更加安全…...

Vue路由跳转及路由传参
跳转 跳转使用 router vue 的路由跳转有 3 个方法: go 、 push 、 replace go :接收数字, 0 刷新,正数前进,负数后退 push :添加,向页面栈中添加一条记录,可以后退 replace &#…...
计算机网络常见面试总结
文章目录 1. 计算机网络基础1.1 网络分层模型1. OSI 七层模型是什么?每一层的作用是什么?2.TCP/IP 四层模型是什么?每一层的作用是什么?3. 为什么网络要分层? 1.2 常见网络协议1. 应用层有哪些常见的协议?2…...
时隔一年,再次讨论下AutoGPT-安装篇
AutoGPT是23年3月份推出的,距今已经1年多的时间了。刚推出时,我们还只能通过命令行使用AutoGPT的能力,但现在,我们不仅可以基于AutoGPT创建自己的Agent,我们还可以通过Web页面与我们创建的Agent进行聊天。这次的AutoGP…...

项目三:学会如何使用python爬虫请求库(小白入门级)
根据上一篇文章我们学会的如何使用请求库和编写请求函数,这一次我们来学习一下爬虫常用的小技巧。 自定义Headers Headers是请求的一部分,包含了关于请求的元信息。我们可以在requests调用中传递一个字典来自定义Headers。代码如下 import requests h…...
)
Linux驱动开发避坑指南:手把手教你实现三种mmap内存映射(附完整代码)
Linux驱动开发实战:三种mmap内存映射方案深度解析与性能对比 在嵌入式系统和图形处理领域,直接访问内核内存的需求日益增长。想象一下这样的场景:你正在开发一个视频处理驱动,需要将摄像头采集的高清帧数据传输到用户空间进行实时…...

PowerToys汉化完整指南:3分钟让Windows效率工具说中文
PowerToys汉化完整指南:3分钟让Windows效率工具说中文 【免费下载链接】PowerToys-CN PowerToys Simplified Chinese Translation 微软增强工具箱 自制汉化 项目地址: https://gitcode.com/gh_mirrors/po/PowerToys-CN 你是否曾经因为PowerToys的英文界面而感…...

1.8.1 掌握Scala类与对象 - Scala类
本次实战通过两组对比鲜明的案例,带你快速入门Scala面向对象编程的核心。首先,通过创建User类,我们掌握了Scala普通类的定义方式,了解了如何使用private修饰符封装成员变量,以及如何通过new关键字实例化对象并调用其公…...

taotoken api key管理与访问控制保障企业开发安全
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API Key 管理与访问控制:保障企业开发安全 在团队协作开发中,安全、可控地使用大模型能力是技术负…...
)
别再手动敲表格了!用Python+PaddleOCR,5分钟搞定图片转Excel(附完整代码)
智能表格提取革命:用PaddleOCR实现图片转Excel的工业级解决方案 在数据驱动的商业环境中,每天有数百万份纸质表格、扫描文档和截图等待被数字化处理。传统的手动录入不仅效率低下,错误率高达18%-22%(国际数据公司2023年办公自动化…...

微信聊天记录终极备份指南:5步将珍贵对话永久保存到电脑
微信聊天记录终极备份指南:5步将珍贵对话永久保存到电脑 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因手机丢失、系统崩溃或更换设备而永远失去了…...

mikupad:单文件AI写作前端,兼容多后端与深度创作控制
1. 项目概述:一个单文件全能的AI写作前端如果你和我一样,经常折腾各种本地大语言模型,那你一定对“前端界面”这件事深有体会。Oobabooga的WebUI功能强大但略显臃肿,KoboldCPP的界面简洁但可定制性有限,而各种API调用又…...

AI Agent变现难题与破局之道:小白程序员必备收藏,2026年蓝海掘金指南!
文章深入分析了当前AI Agent行业的冰火两重天现象,揭示了技术不成熟、伪需求泛滥、基础设施不完善等六大核心底层逻辑导致变现困难。同时,文章指出了电商全链路、企业办公自动化、本地生活商家、开发者垂直、垂类定制化等五大变现蓝海赛道,并…...

VirtualRouter:3分钟将Windows电脑变身为免费WiFi热点
VirtualRouter:3分钟将Windows电脑变身为免费WiFi热点 【免费下载链接】VirtualRouter Wifi Hotspot for Windows computers (Windows 7, 8.x, Server 2012 and newer!) 项目地址: https://gitcode.com/gh_mirrors/vi/VirtualRouter 你是否曾遇到这样的情况&…...

React 18 + Vite + Tailwind CSS 构建现代化SaaS落地页实战
1. 项目概述与设计思路最近在做一个保险科技(InsurTech)相关的概念项目,需要为这个名为“Insura”的SaaS平台打造一个现代化的落地页(Landing Page)。这个页面的核心目标很明确:向潜在客户(主要…...