Pytorch手撸Attention
Pytorch手撸Attention
注释写的很详细了,对照着公式比较下更好理解,可以参考一下知乎的文章
注意力机制

import torch
import torch.nn as nn
import torch.nn.functional as Fclass SelfAttention(nn.Module):def __init__(self, embed_size):super(SelfAttention, self).__init__()self.embed_size = embed_size# 定义三个全连接层,用于生成查询(Q)、键(K)和值(V)# 用Linear线性层让q、k、y能更好的拟合实际需求self.value = nn.Linear(embed_size, embed_size)self.key = nn.Linear(embed_size, embed_size)self.query = nn.Linear(embed_size, embed_size)def forward(self, x):# x 的形状应为 (batch_size批次数量, seq_len序列长度, embed_size嵌入维度)batch_size, seq_len, embed_size = x.shapeQ = self.query(x)K = self.key(x)V = self.value(x)# 计算注意力分数矩阵# 使用 Q 矩阵乘以 K 矩阵的转置来得到原始注意力分数# 注意力分数的形状为 [batch_size, seq_len, seq_len]# K.transpose(1,2)转置后[batch_size, embed_size, seq_len]# 为什么不直接使用 .T 直接转置?直接转置就成了[embed_size, seq_len,batch_size],不方便后续进行矩阵乘法attention_scores = torch.matmul(Q, K.transpose(1, 2)) / torch.sqrt(torch.tensor(self.embed_size, dtype=torch.float32))# 应用 softmax 获取归一化的注意力权重,dim=-1表示基于最后一个维度做softmaxattention_weight = F.softmax(attention_scores, dim=-1)# 应用注意力权重到 V 矩阵,得到加权和# 输出的形状为 [batch_size, seq_len, embed_size]output = torch.matmul(attention_weight, V)return output
多头注意力机制

class MultiHeadAttention(nn.Module):def __init__(self, embed_size, num_heads):super().__init__()self.embed_size = embed_sizeself.num_heads = num_heads# 整除来确定每个头的维度self.head_dim = embed_size // num_heads# 加入断言,防止head_dim是小数,必须保证可以整除assert self.head_dim * num_heads == embed_sizeself.q = nn.Linear(embed_size, embed_size)self.k = nn.Linear(embed_size, embed_size)self.v = nn.Linear(embed_size, embed_size)self.out = nn.Linear(embed_size, embed_size)def forward(self, query, key, value):# N就是batch_size的数量N = query.shape[0]# *_len是序列长度q_len = query.shape[1]k_len = key.shape[1]v_len = value.shape[1]# 通过线性变换让矩阵更好的拟合queries = self.q(query)keys = self.k(key)values = self.v(value)# 重新构建多头的queries,permute调整tensor的维度顺序# 结合下文demo进行理解queries = queries.reshape(N, q_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)keys = keys.reshape(N, k_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)values = values.reshape(N, v_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3)# 计算多头注意力分数attention_scores = torch.matmul(queries, keys.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))attention = F.softmax(attention_scores, dim=-1)# 整合多头注意力机制的计算结果out = torch.matmul(attention, values).permute(0, 2, 1, 3).reshape(N, q_len, self.embed_size)# 过一遍线性函数out = self.out(out)return out
demo测试
self-attention测试
# 测试自注意力机制
batch_size = 2
seq_len = 3
embed_size = 4# 生成一个随机数据 tensor
input_tensor = torch.rand(batch_size, seq_len, embed_size)# 创建自注意力模型实例
model = SelfAttention(embed_size)# print输入数据
print("输入数据 [batch_size, seq_len, embed_size]:")
print(input_tensor)# 运行自注意力模型
output_tensor = model(input_tensor)# print输出数据
print("输出数据 [batch_size, seq_len, embed_size]:")
print(output_tensor)
=======print=========
输入数据 [batch_size, seq_len, embed_size]:
tensor([[[0.7579, 0.7342, 0.1031, 0.8610],[0.8250, 0.0362, 0.8953, 0.1687],[0.8254, 0.8506, 0.9826, 0.0440]],[[0.0700, 0.4503, 0.1597, 0.6681],[0.8587, 0.4884, 0.4604, 0.2724],[0.5490, 0.7795, 0.7391, 0.9113]]])输出数据 [batch_size, seq_len, embed_size]:
tensor([[[-0.3714, 0.6405, -0.0865, -0.0659],[-0.3748, 0.6389, -0.0861, -0.0706],[-0.3694, 0.6388, -0.0855, -0.0660]],[[-0.2365, 0.4541, -0.1811, -0.0354],[-0.2338, 0.4455, -0.1871, -0.0370],[-0.2332, 0.4458, -0.1867, -0.0363]]], grad_fn=<UnsafeViewBackward0>)
MultiHeadAttention
多头注意力机制务必自己debug一下,主要聚焦在理解如何拆分成多头的,不结合代码你很难理解多头的操作过程
1、queries.reshape(N, q_len, self.num_heads, self.head_dim).permute(0, 2, 1, 3) 处理之后的 size = torch.Size([64, 8, 10, 16])
- 通过上述操作,
queries张量的最终形状变为[N, self.num_heads, q_len, self.head_dim]。这样的排列方式使得每个注意力头可以单独处理对应的序列部分,而每个头的处理仅关注其分配到的特定维度self.head_dim - 这个形状是为了后续的矩阵乘法操作准备的,其中每个头的查询将与对应的键进行点乘,以计算注意力分数
2、attention_scores = torch.matmul(queries, keys.transpose(-2, -1)) / torch.sqrt( torch.tensor(self.head_dim, dtype=torch.float32)) 将reshape后的quries的后两个维度进行转置后点乘,对应了 Q ⋅ K T Q \cdot K^T Q⋅KT ;根据demo这里的头数为8,所以公式中对应的下标 i i i 为8
3、在进行完多头注意力机制的计算后通过 torch.matmul(attention, values).permute(0, 2, 1, 3).reshape(N, q_len, self.embed_size) 整合,变回原来的 [batch_size,seq_length,embed_size]形状
# 测试多头注意力
embed_size = 128 # 嵌入维度
num_heads = 8 # 头数
attention = MultiHeadAttention(embed_size, num_heads)# 创建随机数据模拟 [batch_size, seq_length, embedding_dim]
batch_size = 64
seq_length = 10
dummy_values = torch.rand(batch_size, seq_length, embed_size)
dummy_keys = torch.rand(batch_size, seq_length, embed_size)
dummy_queries = torch.rand(batch_size, seq_length, embed_size)# 计算多头注意力输出
output = attention(dummy_values, dummy_keys, dummy_queries)
print(output.shape) # [batch_size, seq_length, embed_size]
=======print=========
torch.Size([64, 10, 128])
如果你难以理解权重矩阵的拼接和拆分,推荐李宏毅的attention课程(YouTobe)
相关文章:
Pytorch手撸Attention
Pytorch手撸Attention 注释写的很详细了,对照着公式比较下更好理解,可以参考一下知乎的文章 注意力机制 import torch import torch.nn as nn import torch.nn.functional as Fclass SelfAttention(nn.Module):def __init__(self, embed_size):super(S…...
PyCharm 2024.1 发布:全面升级,助力高效编程!
PyCharm 2024.1 发布:全面升级,助力高效编程! 文章目录 PyCharm 2024.1 发布:全面升级,助力高效编程!摘要引言 Hugging Face:模型和数据集的快速文档预览针对 JavaScript 和 TypeScript 的全行代…...
)
Nginx基础(06)
Nginx基础(05) uWSGI 介绍 uWSGI 是一个 Web服务器 主要用途是将Web应用程序部署到生产环境中 可以用来连接Nginx服务与Python动态网站 1. 用 uWSGI 部署 Python 网站项目 配置 Nginx 使其可以将动态访问转交给 uWSGI 安装 python 工具及依赖 安…...

【Qt 学习笔记】QWidget的windowOpacity属性 | cursor属性 | font属性
博客主页:Duck Bro 博客主页系列专栏:Qt 专栏关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ QWidget的windowOpacity属性 | cursor属性 | font属性 文章编号&#…...
Python爬虫:requests模块的基本使用
学习目标: 了解 requests模块的介绍掌握 requests的基本使用掌握 response常见的属性掌握 requests.text和content的区别掌握 解决网页的解码问题掌握 requests模块发送带headers的请求掌握 requests模块发送带参数的get请求 1 为什么要重点学习requests模块&…...

C++traits
traits C的标准库提供了<type_traits>,它定义了一些编译时基于模板类的接口用于查询、修改类型的特征:输入的时类型,输出与该类型相关的属性 通过type_traits技术编译器可以回答一系列问题:它是否为数值类型?是否为函数对象…...
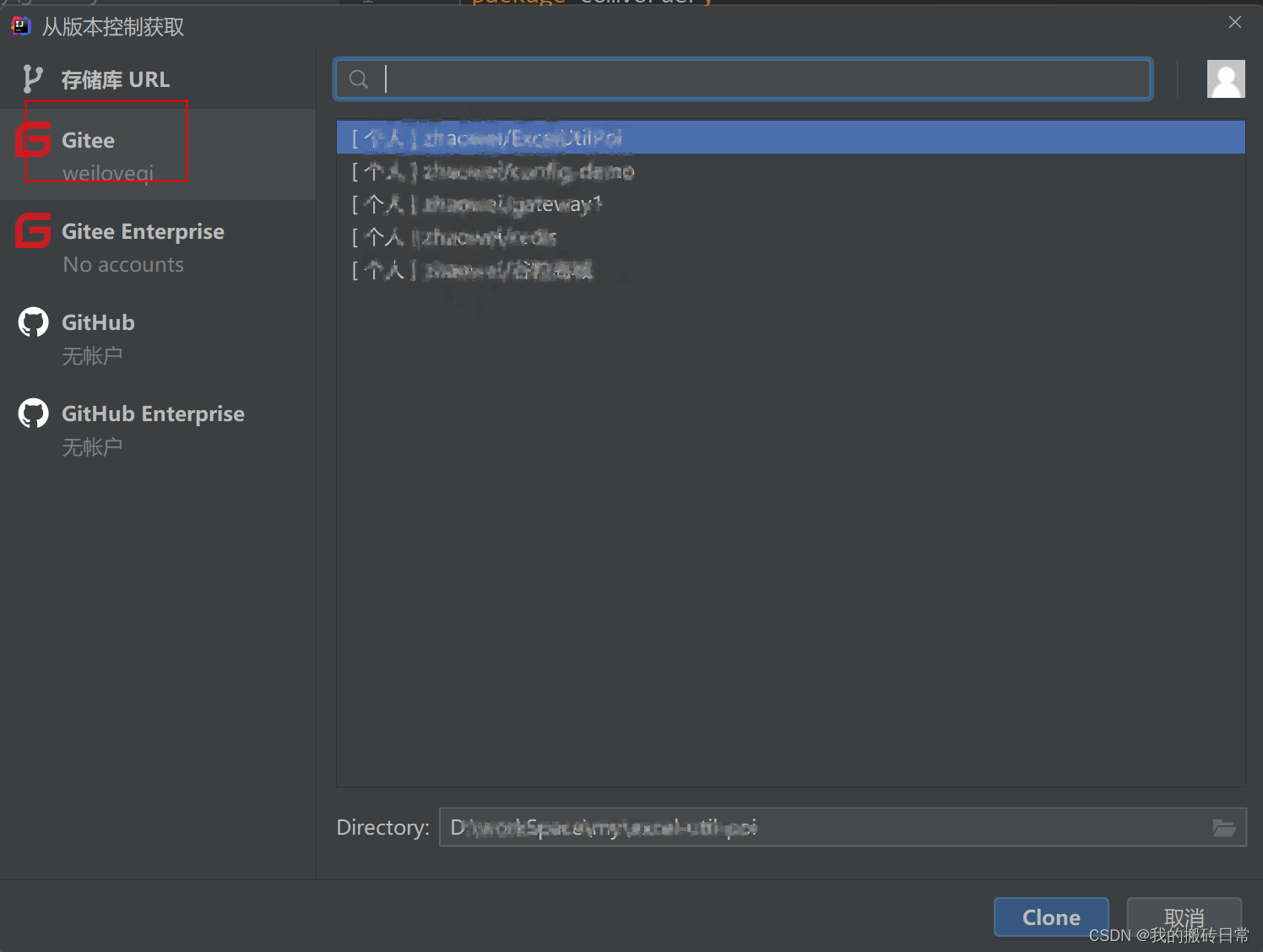
gitee和idea集成
1 集成插件 2 配置账号密码 3 直接将项目传到仓库 4直接从gitee下载项目...
研究成果对人工智能领域的应用有哪些影响)
阿维·威格德森(Avi Wigderson)研究成果对人工智能领域的应用有哪些影响
AI人工智能的影响 威格德森(Avi Wigderson)的研究成果对人工智能领域的应用产生了深远的影响。 首先,威格德森在计算复杂性理论、算法和优化方面的贡献为人工智能领域提供了高效、准确的计算模型和算法。他的研究帮助我们更好地理解计算问题…...

【免费领取源码】可直接复用的医院管理系统!
今天给大家分享一套基于SpringbootVue的医院管理系统源码,在实际项目中可以直接复用。(免费提供,文中自取) 系统运行图(设计报告和接口文档) 1、后台管理页面 2、排班管理页面 3、设计报告包含接口文档 源码免费领取方式 后台私信…...
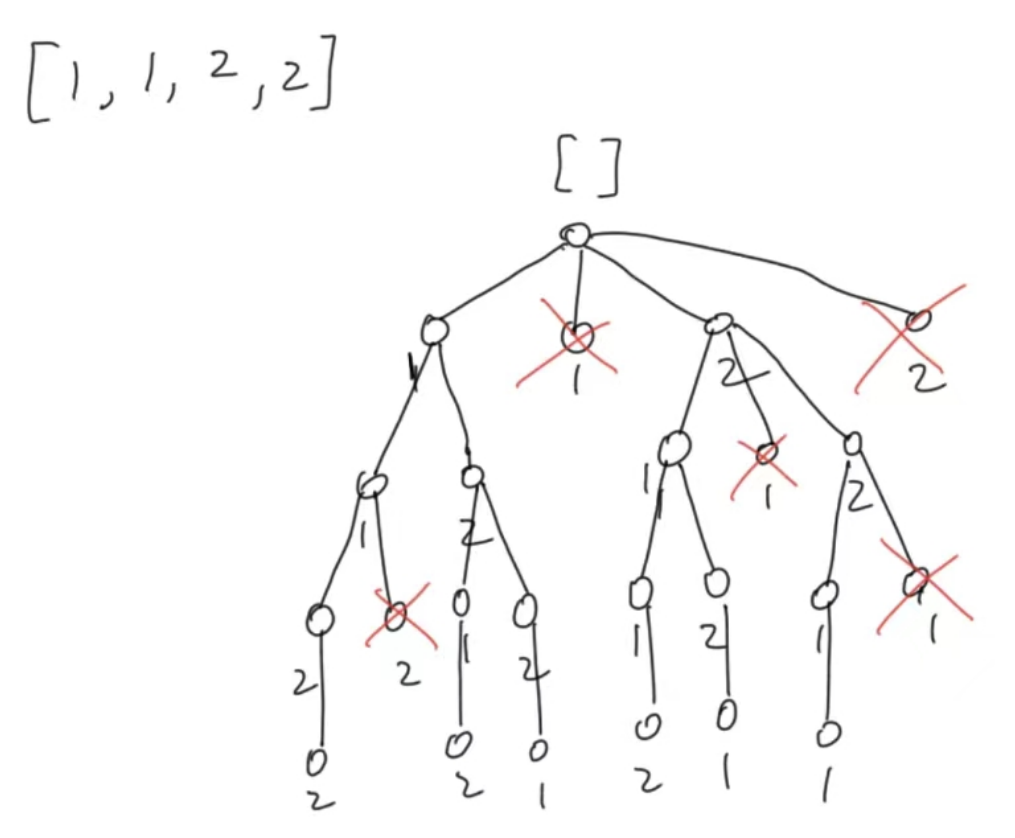
leetcode代码记录(全排列 II
目录 1. 题目:2. 我的代码:小结: 1. 题目: 给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。 示例 1: 输入:nums [1,1,2] 输出: [[1,1,2], [1,2,1], [2,1…...

【数据结构与算法】之双向链表及其实现!
个人主页:秋风起,再归来~ 数据结构与算法 个人格言:悟已往之不谏,知来者犹可追 克心守己,律己则安! 目录 1、双向链表的结构及概念 2、双向链表的实现 2.1 要实现的接口…...
记一次奇妙的某个edu渗透测试
前话: 对登录方法的轻视造成一系列的漏洞出现,对接口确实鉴权造成大量的信息泄露。从小程序到web端网址的奇妙的测试就此开始。(文章厚码,请见谅) 1. 寻找到目标站点的小程序 进入登录发现只需要姓名加学工号就能成功…...

设计模式学习笔记 - 设计模式与范式 -总结:1.回顾23中设计模式的原理、背后的思想、应用场景等
1.创建型设计模式 创建型设计模式包括:单例模式、工厂模式、建造者模式、原型模式。它主要解决对象的创建问题,封装复杂的创建过程,解耦对象的创建代码和使用代码。 1.单例模式 单例模式用来创建全局唯一的对象。一个类只允许创建一个对象…...
22 文件系统
了解了被打开的文件,肯定还有没被打开的文件,就是磁盘上的文件。先从磁盘开始认识 磁盘 概念 内存是掉电易失存储介质,磁盘是永久性存储介质 磁盘的种类有SSD,U盘,flash卡,光盘,磁带。磁盘是…...

OVITO-2.9版本
关注 M r . m a t e r i a l , \color{Violet} \rm Mr.material\ , Mr.material , 更 \color{red}{更} 更 多 \color{blue}{多} 多 精 \color{orange}{精} 精 彩 \color{green}{彩} 彩! 主要专栏内容包括: †《LAMMPS小技巧》: ‾ \textbf…...
【Java开发指南 | 第一篇】类、对象基础概念及Java特征
读者可订阅专栏:Java开发指南 |【CSDN秋说】 文章目录 类、对象基础概念Java特征 Java 是一种面向对象的编程语言,它主要通过类和对象来组织和管理代码。 类、对象基础概念 类:类是一个模板,它描述一类对象的行为和状态。例如水…...

Neo4j 图形数据库中有哪些构建块?
Neo4j 图形数据库具有以下构建块 - 节点属性关系标签数据浏览器 节点 节点是 Graph 的基本单位。 它包含具有键值对的属性,如下图所示。 NEmployee 节点 在这里,节点 Name "Employee" ,它包含一组属性作为键值对。 属性 属性是…...

002 springboot整合mybatis-plus
文章目录 TestMybatisGenerate.javapom.xmlapplication.yamlReceiveAddressMapper.xmlreceive_address.sqlReceiveAddress.javaReceiveAddressMapper.javaIReceiveAddressServiceReceiveAddressServiceImpl.javaReceiveAddressController.javaTestAddressService.javaSpringboo…...

代码随想录训练营第三十五期|第天16|二叉树part03|104.二叉树的最大深度 ● 111.二叉树的最小深度● 222.完全二叉树的节点个数
104. 二叉树的最大深度 - 力扣(LeetCode) 递归,可以前序遍历,也可以后序遍历 前序遍历是backtracking 下面是后序遍历的代码: /*** Definition for a binary tree node.* public class TreeNode {* int val;* …...
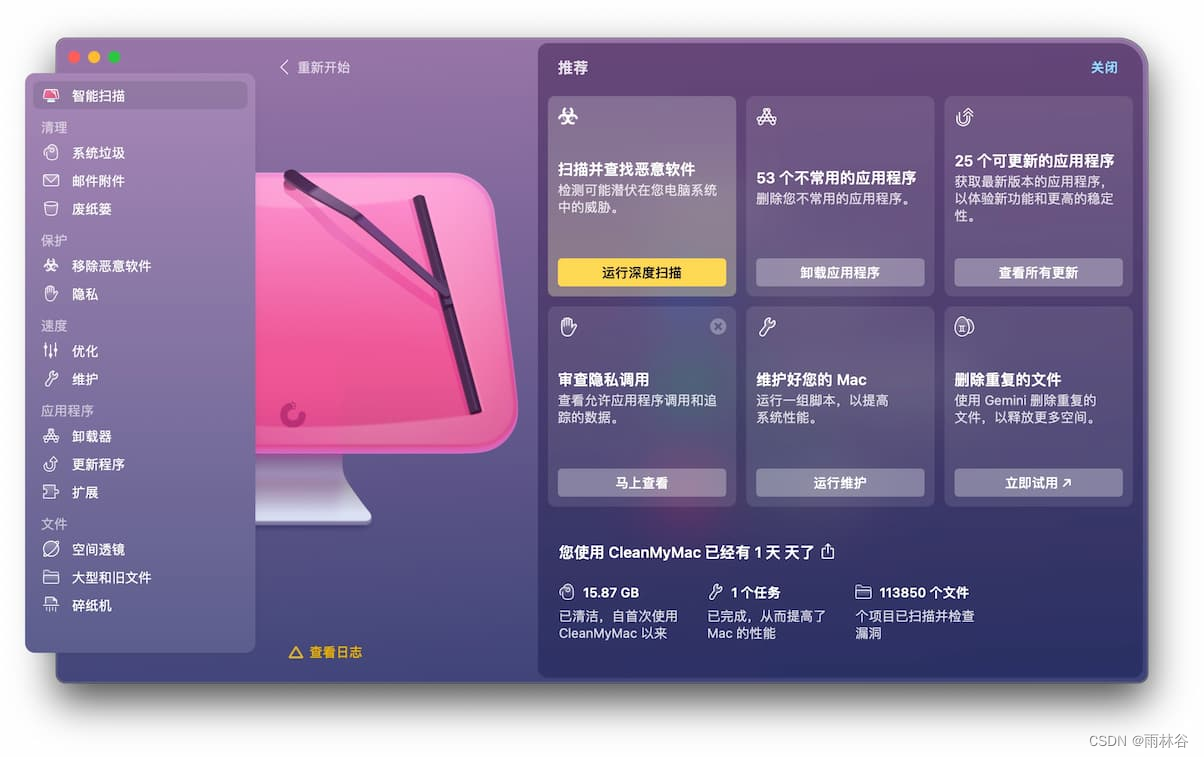
Mac版2024 CleanMyMac X 4.15.2 核心功能详解 cleanmymac这个软件怎么样?cleanmymac到底好不好用?
近些年伴随着苹果生态的蓬勃发展,越来越多的用户开始尝试接触Mac电脑。然而很多人上手Mac后会发现,它的使用逻辑与Windows存在很多不同,而且随着使用时间的增加,一些奇奇怪怪的文件也会占据有限的磁盘空间,进而影响使用…...

Crush性能优化指南:如何利用半懒惰流处理大数据集
Crush性能优化指南:如何利用半懒惰流处理大数据集 【免费下载链接】crush Crush is a command line shell that is also a powerful modern programming language. 项目地址: https://gitcode.com/gh_mirrors/cr/crush Crush是一个革命性的命令行shell和现代…...

【Kanzi 资源系统完全笔记】
一、Resource 的类层次结构Kanzi 中所有资源(Resource)都继承自 Object 基类。下图是常见的资源继承体系(根据图片整理):Object└── Resource├── GPUResource # 位于 GPU 显存中的资源(纹理、…...

工程师的调试礼仪:如何避免一次问候毁掉两小时工作成果
1. 项目概述:一次关于“Bug礼仪”的职场博弈在硬件开发的深水区,尤其是在产品临近交付的冲刺阶段,工程师与管理者之间的互动,往往比电路板上的信号完整性更考验“设计”。这不是一个关于具体芯片型号或调试命令的技术教程…...

模块二-数据选择与索引——08. 条件筛选
08. 条件筛选 1. 概述 条件筛选是数据分析中最常用的操作之一。通过布尔表达式,可以快速筛选出满足特定条件的数据行,实现数据过滤、异常检测、子集提取等功能。 import pandas as pd import numpy as np# 创建示例数据 np.random.seed(42) df pd.DataF…...

终极指南:如何使用Harepacker-resurrected打造你的MapleStory游戏Mod
终极指南:如何使用Harepacker-resurrected打造你的MapleStory游戏Mod 【免费下载链接】Harepacker-resurrected All in one .wz file/map editor for MapleStory game files 项目地址: https://gitcode.com/gh_mirrors/ha/Harepacker-resurrected 如果你是一…...
)
告别按钮!用Qt实现STM32小车的键盘与手柄控制方案(附串口通信源码)
超越按钮控制:Qt框架下STM32小车的键盘与手柄交互方案 在嵌入式开发领域,人机交互体验往往被忽视,而实际上它直接影响着用户的操作效率和舒适度。对于STM32遥控小车这类需要实时操控的项目,传统的按钮点击方式存在明显局限——操作…...

微创式电子设备设计:从自动化到自主化的智能革命
1. 项目概述:从“工具”到“魔法”的隐形革命十几年前,我在《EE Times》上读到一篇由西蒙巴克(Simon Barker)撰写的文章,标题是一个直击灵魂的提问:“微创式电子设备在哪里?” 这个问题像一颗种…...
指标解析——专业级语音稳定性评估体系首度披露)
【限时解密】ElevenLabs未公开的“Voice Stability Index”(VSI)指标解析——专业级语音稳定性评估体系首度披露
更多请点击: https://intelliparadigm.com 第一章:【限时解密】ElevenLabs未公开的“Voice Stability Index”(VSI)指标解析——专业级语音稳定性评估体系首度披露 VSI 的本质与工程意义 Voice Stability Index(VSI&…...

终极网盘直链下载助手完整指南:告别限速,快速获取八大平台真实下载地址
终极网盘直链下载助手完整指南:告别限速,快速获取八大平台真实下载地址 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里…...
)
告别Keil!用VSCode+OpenOCD+STLink一键下载STM32程序(保姆级教程)
用VSCodeOpenOCDSTLink打造高效STM32开发环境 在嵌入式开发领域,Keil和IAR等传统IDE长期占据主导地位,但它们臃肿的安装包、昂贵的授权费用和略显陈旧的用户界面让许多开发者开始寻找更现代化的替代方案。Visual Studio Code(VSCodeÿ…...