2024------MySQL数据库基础知识点总结
-- 最好的选择不是最明智的,而是最勇敢的,最能体现我们真实意愿的选择。

MySQL数据库基础知识点总结
一、概念
-
数据库:DataBase,简称DB。按照一定格式存储数据的一些文件的组合顾名思义: 存储数据的仓库,实际上就是一堆文件。这些文件中存储了具有特定格式的数据。
-
数据库管理系统:DataBaseManagement,简称DBMS。数据库管理系统是专门用来管理数据库中数据的,数据库管理系统可以对数据库当中的数据进行增删改查。
- 常见的数据库管理系统:
MySQL、 OracleMS SqlServer、 DB2、 sybase等
- 常见的数据库管理系统:
-
SQL: 结构化查询语言程序员需要学习SQL语句,程序员通过编写SQL语句,然后DBMS负责执行SQL语句,最终来完成数据库中数据的增删改查操作。
-
以上三者关系:
DBMS --(执行)--> SQL --(操作)--> DB
二、基础
-
在Windows操作系统中,使用命令来启动和停止MySQL服务:
net stop MySQL; net start MySQL; #其他服务的启停也可以使用以上命令,修改服务名称即可 -
使用客户端登录MySQL数据库:(前提:MySQL安装了,服务启动了)
使用bin目录下的mysql.exe命令来连接mysql数据库服务器
-
本地登录(显示编写密码):
mysql -uroot -p123 #root是用户名,123是密码 -
本地登录(隐藏密码):
mysql -uroot -p #p后面不加密码直接回车
-
-
表(table)
数据库中是以表格的形式表示数据的
任何一张表都有行和列:
行(row):被称为数据/记录。
列(column):被称为字段。[每一个字段都有:字段名、数据类型、约束等属性]
-
SQL语句的分类
-
DQL:数据查询语言(凡是带有select关键字的都是查询语句)
select…
-
DML:数据操作语言(凡是对表当中的数据进行增删改的都是DML)
insert:增
delete:删
update:改
!注意:DML主要是操作表中的数据data。
-
DDL:数据定义语言(凡是带有create、drop、alter的都是DDL)
create:新建,等同于增
drop:删除
alter:修改
!注意:DDL主要是操作表结构。
-
TCL:事务控制语言
commit:事务提交
rollback:事务回滚
-
DCL:数据控制语言
grant:授权
revoke:撤销权限
……
-
-
导入.sql数据:
source D:\document\mysql\node.sql #路径中不要有中文 -
MySQL常用命令
*以下命令不区分大小写,且命令要有";"才能执行
退出mysql:
exit查看mysql中有哪些数据库:
show databases; #以英文分号结尾 #mysql默认自带了4个数据库选择使用某个数据库:
use 数据库名;创建数据库:
create database 数据库名;查看某个数据库下的表:
show tables;查看表中的数据:
select * from 表名;查看表的结构,不看表的数据:
desc 表名; # “describe 表名;” 的缩写查看MySQL数据库的版本号:
select version();查看当前使用的数据库:
select database();
-
增删改查又叫做CRUD
Create
Retrive
Update
Delete
三、查询
(一)单表查询
1、简单查询
- 查询一个字段:
select 字段名 from 表名;
- 查询多个字段:
select 字段1,字段2,... from 表名;
- 查询所有字段:
select * from 表名; #这种方式效率低、可读性差,在实际开发中不建议使用
select 所有字段名 from 表名;
- 给查询的列起别名:
select 字段名 (as) 别名 from 表名;
#as可以省略,原表列名不变,只是将查询的字段显示为别名
#如果起的别名有空格,可以用单引号or双引号将别名括起来
- 对查询的字段进行运算操作:
select 字段表达式 from 表名;
#比如 “select sal*12 as '年薪' from emp;”
注意:在所有的数据库中,字符串统一使用单引号括起来。(单引号是标准,双引号在Oracle数据库中用不了,在MySQL中可以使用)
select后面可以跟某个表的字段名(可以等同看做变量名),也可以跟字面量/字面值(数据)。
2、条件查询
条件查询需要用到where语句,where必须放到from语句表的后面
select 字段1,字段2,... from 表名 where 条件;
| 运算符 | 说明 |
|---|---|
| = | 等于 |
| <>或!= | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| between...and... | 两个值之间,等同于>=and<=(要遵循左小右大,闭区间) |
| is null | 为null(is not null表示不为空)(null不能用=进行衡量) |
| and | 并且 |
| or | 或者 |
| in | 包含,相当于多个or(not in表示不在这个范围内)(in后面加的是具体的值,不是区间) |
| not | not可以取非,主要用在is或in中 |
| like | like称为模糊查询,支持%或下划线匹配 %:匹配任意个字符 下划线:一个下划线只匹配一个字符 \为转义字符 |
and和or的优先级:and > or。如果想让or先执行,需要加()。
3、排序
-
单字段排序:
select 字段 from 表名 order by 字段; #默认升序 select 字段 from 表名 order by 字段 desc; #指定降序 select 字段 from 表名 order by 字段 asc; #指定升序 -
多字段排序:
select 字段 from 表名 order by 字段a (desc/asc), 字段b (desc/asc); #先按照字段a进行排序,序号相同的再按照字段b进行排序 -
根据字段位置进行排序:
select 字段 from 表名 order by 2; #2表示第2列,按照第2列进行排序 #不建议使用这种方式,列的顺序会改变,不健壮 -
条件查询+排序:
select ... from ... where ... order by ...; #关键字顺序不能变 #执行顺序:from、where、select、order by
4、数据处理函数/单行处理函数
- 单行处理函数:一个输入对应一个输出
| 函数 | 含义 |
|---|---|
| lower | 转换小写 |
| upper | 转换大写 |
| substr | 取子串 [ substr(被截取的字符串, 起始下标, 截取的长度) ] |
| length | 取长度 |
| trim | 去空格 |
| str_to_date | 将字符串varchar类型转换成date类型 |
| date_format | 格式化日期。将date类型转换成具有一定格式的varchar字符串类型。 格式:date_format(日期类型数据, '日期格式') 这个函数通常使用在查询日期方面。设置展示的日期格式。 |
| format | 设置千分位。 format(数字, '格式') |
| round | 四舍五入 |
| rand | 生成0~1的随机数 |
| ifnull | 可以将null转换成一个具体值[ ifnull(字段, 如果为null被当作哪个值) ] |
| concat | 进行字符串的拼接 |
| case...when...then...when...then...else...end | 当怎样就怎么做,当怎样就怎么做,其余情况怎么做 |
实例:
select lower(name) as name from student; select substr(name,1,1) as name from student; #将会输出所有name的第1个字符 select name from student where substr(name,1,1)='A'; #相当于:select name from student where name like 'A%'; select concat(upper(substr(name, 1, 1)), substr(name, 2, length(name)-1)) as result from student; #将name字段的数据首字母大写 select round(1236.567, 2) as result form student; #round(数据, 保留小数位数),生成的结果行数为student表的行数 select name,job,sal as oldsal,(case job when 'MANAGER' then sal*1.1 when 'SALEMAN' then sal*1.5 else sal end) as newsal from emp;*在所有数据库中,只要有null参与的数学运算,结果就为null
-
MySQL的日期格式
符号 含义 %Y 年 %m 月 %d 日 %h 时 %i 分 %s 秒
5、分组函数/多行处理函数
- 多行处理函数:输入多行,输出一行。
| 函数 | 含义 |
|---|---|
| count | 计数 |
| sum | 求和 |
| avg | 平均值 |
| max | 最大值 |
| min | 最小值 |
实例:
select max(sal) from emp;
-
分组函数在使用的时候必须先进行分组,然后才能使用。如果没有对数据进行分组,默认整张表为一组。
-
注意事项:
-
分组函数自动忽略NULL,你不需要提前对null进行处理。
-
count(*)和count(具体字段)的区别:
count(*):统计表中的总行数。(只要一行数据中有一列不为NULL,则这行数据有效)
count(具体字段):表示统计该字段下所有不为NULL的元素的总数。
-
分组函数不能直接使用在where子句中。
-
6、分组查询(重点!!!)
-
分组查询语法
select ... from ... group by ...
实例:
#找出每个工作岗位的工资和 select job,sum(sal) from emp group by job;#找出每个部门,不同工作岗位的最高薪资 #技巧:两个字段联合成一个字段看 select deptno,job,max(sal) from emp group by deptno,job;
-
重要结论:
在一条select语句中,如果有group by语句的话,select后面只能跟:参加分组的字段、分组函数。其他的不能跟。
-
having
-
having可以对分完组后的数据再次进行过滤。
-
having不能单独使用,不能代替where,只能和group by搭配使用。
#找出每个部门最高薪资,并显示最高薪资大于3000的 select deptno,max(sal) from emp group by deptno having max(sal)>3000; #或者先使用where过滤 select deptno,max(sal) from emp where sal>3000 group by deptno; -
优化策略:where和having,优先选择where。
-
-
执行顺序
select ... from ... where ... group by ... having ... order by ...
#以上关键字只能按照这个顺序来,不能颠倒
以上语句的执行顺序:from、where、group by、having、select、order by
实例:
#找出每个岗位的平均薪资,要求显示平均薪资大于1500的,除MANAGER岗位之外,要求按照平均薪资降序排 select job,avg(sal) as avgsal from emp where job <> 'MANAGER' group by job having avg(sal)>1500 order by avgsal desc;
7、查询结果去重:distinct
select distinct 字段 from 表名;
-
distinct只能出现在所有字段的前面
-
distinct出现在两个字段之前,则表示两个字段联合起来去除
实例:
#统计工作岗位数量 select count(distinct job) from emp;
(二)连接查询
*** 重点!!!**
1、连接查询
-
连接查询分类:
根据语法的年代分类:SQL92、SQL99(重点学习SQL99)
根据表连接的方式分类:内连接(等值连接+非等值连接+自连接)、外连接(左外连接/左连接+右外连接/右连接、全连接
-
笛卡尔积现象:当两张表进行连接查询,没有任何条件限制时,最终查询结果的条数是两张表条数的乘积。(数学现象)
如何避免?
连接时加条件,满足这个条件的记录将会被筛选出来。
#各个员工对应的部门 select e.ename,d.dname from emp e,dept d where e.deptno=d.deptno; #SQL92语法 #SQL99语法在‘内连接之等值连接’中- 此时最终查询的结果条数变少了,匹配次数没有减少,还是两张表的条数的乘积。
- 通过笛卡尔积现象得出,表的连接次数越多,效率越低,尽量避免表的连接次数。
2、内连接
等值连接
-
SQL99语法(内连接):
select ... from a (inner) join b on a和b的连接条件 where 筛选条件 #inner可以省略,加上可读性更强,表示内连接实例:
#各个员工对应的部门 select e.ename,d.dname from emp e join dept d on e.deptno=d.deptno; #SQL99语法(将sql92中from后面的,换成join,where换成了on) -
SQL92和SQL99对比
SQL92缺点:结构不清晰,表的连接条件和后期进一步筛选的条件,都放到了where后面,用and连接。
SQL99优点:表连接的条件时独立的,连接之后,如果还需要进一步筛选,则再往后添加where
-
在on后面是一个等值条件,所以称为等值连接
非等值连接
- 非等值连接:on后面的条件不是等值关系。
实例:
#找出每个员工的薪资等级,并显示员工名、薪资、等级 select e.ename, e.sal, s.grade from emp e (inner) join salgrade s on e.sal between s.losal and s.hisal;
自连接
- 自连接技巧:一张表看作两张表。
实例:
#查询员工的上级领导,要求显示员工名和对应的领导名 select a.ename as '员工名', b.ename as '领导名' from emp a join emp b on a.mgr=b.empno; #将一张表看成两张表
3、外连接
-
外连接与内连接的区别:内连接中,连接的两张表没有主次关系,平等的;在外连接中,两张表连接,产生主次关系。(主要看join前面有无right/left来区分)
-
带有right的是右外连接,又叫做右连接。
带有left的是左外连接,又叫做左连接。
任何一个右连接都有左连接的写法。
任何一个左连接都有右连接的写法。
-
外连接的查询结果条数一定是>=内连接的查询结果条数
实例:
#各个员工对应的部门,同时将没有员工对应的部门也显示出来 select e.ename,d.dname from emp e right (outer) join dept d on e.deptno=d.deptno; #右外连接
- 这里的right:表示将join关键字右边的这张表看成主表,主要是为了将这张主表的数据全部查询出来,捎带着关联查询左边的表emp。
- outer可以省略,加上可读性就强一些,表示外连接。
4、多表连接
-
语法:
select ... froma joinb ona和b的连接条件 joinc ona和c的连接条件 joind ona和d的连接条件 ...- 一条SQL中,内连接和外连接可以混合,都可以出现。
实例:
#找出每个员工的部门名称以及工资等级,还有上级领导,要求显示出员工名、领导名、部门名、薪资、薪资等级 select e.ename, l.ename, e.sal, d.dname, s.grade from emp e join dept d on e.deptno=d.deptno join salgrade s on e.sal between s.losal and s.hisal left join emp l on e.mgr=l.empno;
(三)子查询
- 子查询:select语句中嵌套select语句,配嵌套的select语句称为子查询。
在where语句中使用子查询
实例:
# 找出比最低工资高的员工名字和工资 select ename,sal from emp where sal > (select min(sal) from emp);
在from语句中使用子查询
- from后面的子查询,可以将子查询的查询结果当作一张临时表。
实例:
#找出每个岗位的平均工资的薪资等级 select t.*, s.grade from (select job, avg(sal) as avgsal from emp group by job) t on t.avgsal between s.losal and s.hisal; #🔺这里不能使用t.avg(sal)
在select语句中使用子查询
// 这个内容不需要掌握,掌握即可
实例:
#找出每个员工的部门名称,要求显示员工名,部门名 select e.ename, (select d.dname from dept d where e.deptno=d.deptno) as dname from emp e;
-
对于select后面的子查询来说,这个子查询只能一次返回一条结果,多于一条就报错了,比如:
select e.ename, e.deptno, (select dname from dept) as dname from emp; #报错
(四)union
-
union用于合并查询结果集
实例:
#查询工作岗位是MANAGER和SALESMAN的员工 select ename,job from emp where job='MANAGER' union select ename,job from emp where job='SALESMAN'; #使用union #或者: select ename,job from emp where job='MANAGER' or job='SALESMAN'; #或者: select ename,job from emp where job in ('MANAGER', 'SALESMAN');-
以上例子,union的效率要高一些。对于表连接来说,每连接一次新表,其匹配次数都满足笛卡尔积。union可以减少匹配的次数,并且完成两个结果集的拼接。
a 连接 b 连接
a 10条记录
b 10条记录
c 10条记录
匹配次数是: 1000
a 连接 b一个结果: 10 * 10 --> 100次
a 连接 C一个结果: 10*10 -> 100次
使用union的话是: 100次 + 100次 = 200次。 (union把乘法变成了加法运算)
-
-
使用union的注意事项:
- 两个要合并的结果集的列数要相同;
- 结果集合并时列的数据类型要相同。(MySQL可以不同,Oracle不行)
(五)limit
-
limit是将查询结果集的一部分取出来,通常使用在分页查询中。
- 分页的作用:提高用户体验,因为一次性全都查出来,用户体验差。可以一页一页翻页看。
-
用法:
-
完整用法:limit startIndex,length;
startIndex是起始下标,length是长度。起始下标从0开始。
-
缺省用法:limit 5;
这是取前5,默认起始下标为0。
-
-
注意:MySQL中limit在order by之后执行!!!
-
分页
每页显示pageSize条记录,第pageNum页:
limit (pageNum-1)*pageSize,pageSize
-
DQL语句大总结:
select ... from ... where ... group by ... having ... order by ... limit ...- 执行顺序:from->where->group by->having->select->order by->limit
四、表
1、表的创建(建表)create
-
建表属于DDL语句(DDL包括:create、drop、alter)
-
语法格式:
create table 表名(字段名1 数据类型,字段名2 数据类型,... );- 表名:建议以 t_ 或者 tbl_ 开始,可读性强。(表名和字段名都属于标识符)
-
MySQL中常见的数据类型:
数据类型 含义 varchar 可变长的字符串
比较智能
可根据实际的数据长度动态分配空间
最长255位。
优点:节省空间
缺点:需要动态分配空间,速度慢char 定长字符串
不管实际的数据长度是多少,都分配固定长度的空间去存储数据。
最长255位。
优点:不需要动态分配空间,速度快
缺点:使用不恰当时,可能会导致空间浪费int 数字中的整数型。等同于Java中的int。
最长11位。bigint 数字中的长整型。等同于Java中的long。 float 单精度浮点型数据。 double 双精度浮点型数据。 date 短日期类型。只包括年月日信息。
mysql短日期默认格式:%Y-%m-%ddatetime 长日期类型。包括年月日时分秒信息。
mysql长日期默认格式:%Y-%m-%d %h:%i:%sclob 字符大对象(Character Large Object)。最多可以存储4G的字符串。
超过225个字符的都要采用CLOB字符大对象来存储。
比如:存储一篇文章,存储一个简介说明。blob 二进制大对象(Binary Large Object)。专门用来存储图片、声音、视频等流媒体数据。
往BLOB类型的字段上插入数据时,需要使用IO流。- 在数据类型后面加括号'()',是表示该字段的建议长度。
-
创建表时指定默认值:在字段的数据类型后加 **'default 默认要取的值' **。
-
数据库的命名规范:所有标识符都小写,单词和单词之间使用下划线进行衔接。
-
快速创建表:(表的复制)
create table 要创建的表名 as select 字段名 from 要复制的表名 ...;- 原理:将一个查询结果当作一张表新建,可以完成表的快速复制。表创建出来,同时表中的数据也存在了。
2、删除表drop
-
语法:
drop table 表名; #当这张表不存在的时候会报错 drop table if exists 表名; #当表不存在时不会报错
3、插入数据insert
-
语法:
insert into 表名(字段名1, 字段名2, 字段名3, ...) values(值1, 值2, 值3,...);- 注意:字段名和值的数量和数据类型要一一对应。
- 每执行成功一次insert语句,记录就会增加一条。
- 如果没有给其他字段指定值,其值默认为NULL(创建表时已经指定默认值的除外)。
- insert语句中的字段名可以省略,相当于所有的字段名都被写上了。
-
mysql中,获取系统当前时间:now()函数(获取的时间有时分秒信息,是datetime类型)
-
插入多条记录
insert into 表名1(字段名1, 字段名2, 字段名3, ...) values (值1, 值2, 值3,...), (值1, 值2, 值3,...), ...; -
将查询结果插入到一张表中:
insert into 要插入的表名 select 字段名 from 要查询的表名; #很少用- 查询结果要符合要插入的表的数据类型
4、修改 update(DML)
-
语法格式:
update 表名 set 字段名1=值1, 字段名2=值2, ... where 条件;- 注意:如果没有条件限制,会导致全部数据更新。
5、删除数据 delete(DML)
-
语法格式:
delete from 表名 where 条件;-
注意:如果没有条件,整张表的数据会被全部删除。
-
delete删除数据的原理:表中的数据被删除了,但是这个数据在硬盘上的真实存储空间不会被释放。
缺点:删除效率低。
优点:支持回滚(rollback),删除后可以恢复数据。
-
-
快速删除表中的数据(truncate):
truncate table 表名;缺点:不支持回滚。
优点:快速,表被一次截断,物理删除。
- truncate是删除表中的数据,表还在!
-
delete属于DML语句,truncate属于DDL语句。
6、对表结构的增删改
* 这个内容不重要
-
对表结构的修改:添加一个字段,删除一个字段,删改一个字段
-
修改表结构是不需要写到Java代码中的。
-
使用alter语句。(属于DDL语句)
7、约束(重点!!!)
-
约束(constraint):在创建表的时候,就可以给表中的字段加上一些约束,来保证这个表中数据的完整性、有效性。
-
约束包括哪些?
非空约束:not null
唯一性约束:unique
主键约束:primary key(简称PK)
外键约束:foreign key(简称FK)
检查约束:check(mysql不支持,Oracle支持)
(1)非空约束not null
- 非空约束not null约束的字段不能为NULL。
实例:
create table t_vip(id int,name varchar(225) not null );这里的name不能为null。
小tip:
xxx.sql这种文件被称为sql脚本文件。
sql脚本文件中编写了大量的sql语句。
sql脚本被执行时,该文件的所有sql语句都会被执行。
批量执行sql语句时,就能使用sql脚本文件。
source .sql文件路径
-
not null只有列级约束,没有表级约束。
(2)唯一性约束unique
- 单独字段唯一(列级约束)
实例:
create table t_vip(id int,name varchar(255) unique,email varchar(255) );每一条数据的name不能重复,但可以为null。
-
两个字段联合唯一(表级约束)
-
在字段后面加上unique(字段名1, 字段名2)
实例:
create table t_vip(id int,name varchar(255),email varchar(255),unique(name, email) ); -
需要给多个字段联合起来添加某个约束的时候,需要使用表级约束。
-
-
unique和not null联合使用:
实例:
create table t_vip(id int,name varchar(255) not null unique );mysql> desc t_vip;
+--------------+----------------------------+----------+----------+-----------------+----------+
| Field | Type | Null | Key | Default | Extra |
+--------------+----------------------------+----------+----------+-----------------+----------+
| id | int(11) | YES | | NULL | |
| name | varchar(255) | NO | PRI | NULL | |
+--------------+----------------------------+----------+----------+-----------------+----------+- 在mysql中,如果一个字段同时被not null和unique约束,该字段就会自动变成主键字段。(Oracle中不一样!!)
(3)主键约束primary key(重点!!!)
-
相关术语:
主键约束:一种约束。
主键字段:加上了主键约束的字段。
主键值:主键字段中的每一个值。
-
主键
- 主键值是每一行记录的唯一标识。(相当于身份证号)
- 任何一张表都要有主键,没有主键则表无效。
- 主键的特征:not null + unique(主键值不能为null,也不能重复)
-
主键分类
(1)单一主键、复合主键
(2)自然主键:主键值是一个自然数,和业务没关系。
业务主键:主键值和业务紧密关联,例如使用银行卡号做主键值。
在实际开发中,自然主键使用的比较多。主键只需要做到不重复即可,不需要意义。主键如果跟业务挂钩,业务一改变就会影响到主键。
单一主键实例:
#列级约束 create table t_vip(id int primary key,name varchar(255) ); #表级约束 create table t_vip(id int,name varchar(255),primary key(id) );以上,id为主键。
复合主键实例:
create table t_vip(id int,name varchar(255),email varchar(255),primary key(id, name) );以上,id和name联合起来做复合主键。
在实际开发中,不建议使用复合主键,建议使用单一主键。(复合主键比较复杂)
-
一个表中主键约束只能添加一个,不能加两个。(主键只能有一个)
-
建议使用int,bigint,char等类型做主键值,不建议用varchar来做主键。
-
在mysql中,有一种可以自动维护一个主键的机制:
create table t_vip(id int primary key auto_increment,name varchar(255) );使用auto_increment后,不需要在insert的时候给主键赋值,主键会自动从1开始自增赋值。
(4)外键约束foreign key(重点!!!)
- 相关术语:
外键约束:一种约束。
外键字段:加上了外键约束的字段。
外键值:外键字段中的每一个值。
-
语法:
在字段定义后面加上:
foreign key(要约束的字段名) references 被引用的表名(被引用的字段名)
实例:
drop table if exists t_student; drop table if exists t_class; create table t_class(classno int primary key,classname varchar(255) ); create table t_student(no int primary key auto_increment,name varchar(255),cno int,foreign key(cno) references t_class(classno) );被引用的表是父表/主表。
引用了父表的表是子表/从表。
- 顺序:
删除表的顺序:先删子,再删父
创建表的顺序:先创建父,再创建子
插入数据的顺序:先插入父,再插入子
- 子表中的外键引用的父表中的某个字段,被引用的这个字段可以不是主键,但一定要有unique。(被引用的字段具有唯一性)
- 外表值可以为null。
五、存储引擎
1、存储引擎的使用
-
存储引擎:一个表存储/组织数据的方式。不同的存储引擎,表存储的方式不同。(mysql叫存储引擎,Oracle不这么叫)
-
数据库中的各表均被指定的存储引擎来处理。(在创建表时)
-
服务器可用的引擎依赖于以下因素:MySQL的版本、服务器在开发时如何被配置、启动选项
-
给表指定存储引擎:
在建表的时候可以在最后小括号 ')' 的右边使用:ENGINE来指定存储引擎(默认为InnoDB),CHARSET来指定这张表的字符编码方式(默认为utf8)。
create table 表名(... )ENGINE=存储引擎 default CHARSET=字符编码方式; -
查看当前服务器中可使用的存储引擎:
show engine \G版本不同,支持情况不同。
2、常用的存储引擎
MyISAM
使用三个文件表示每个表:
格式文件——存储表结构的定义(mytable.frm)
数据文件——存储表行的内容(mytable.MYD)
索引文件——存储表上的索引(mytable..MYI)
灵活的AUTO_INCREMENT字段处理。
优点:可被转换成压缩、只读表来节省空间。
tips:
对于一张表来说,只要有主键,或者加有unique约束的字段上会自动船舰索引。
InnoDB
MySQL默认的存储引擎。
- 每个InnoDB表在数据库目录以.frm格式文件表示
- InnoDB表空间tablespace被用于存储表的内容(表空间是一个逻辑名称。表空间存储数据+索引)
- 提供一组用来记录事务性活动的日志文件
- 用COMMIT(提交)、SAVEPOINT及ROLLBACK(回滚)支持事务处理
- 提供全ACID兼容
- 在MySQL服务器奔溃后提供自动恢复
- 多版本(MVCC)和行级锁定
- 支持外键及引用的完整性,包括级联删除和更新
- 缺点:效率不是很高,不能压缩,不能转换为只读。不能很好的节省存储空间
- 特点:最大特点:支持事务,支持数据库奔溃后自动恢复机制。(安全)
MEMORY
使用MEMORY存储引擎的表,其数据存储在内存中,且行的长度固定,这两个特点使得MEMORY存储引擎非常快。
- 在数据库目录内,每个表均以.frm格式的文件表示
- 表数据及索引被存储在内存中
- 表级锁机制
- 不能包含TEXT或BLOB字段
- 优点:查询效率是最高的。不需要和硬盘交互。
- 缺点:不安全,关机之后数据消失。因为数据和索引都是在内存中。
六、事务
* 重要!!!
1、概述
-
事务(transaction):一个事务就是一个完整的业务逻辑。是一个最小的工作单元,不可再分。
什么是一个完整的业务逻辑?
假设是转账,从A账户向B账户中转账1w,
将A账户的钱减去1w(update语句)
将B账户的钱加上1w(update语句)
这就是一个完整的业务逻辑。
以上的操作就是一个最小的工作单元,这两个update语句要么同时成功要么同时失败,这样才是一个完整的转账过程,才能保证钱是正确的。
-
只有DML语句(insert、delete、update)才会有事务这一说,其他语句和事务无关!!
因为只有以上的三个语句是对数据库表中数据进行增删改的。只要操作涉及到数据的增删改,就一定要考虑事务。(数据安全第一位)
-
说到底,一个事务本质上就是多条DML语句同时成功,或者同时失败!
如果所有的事务都只要一条DML语句就能完成的话,就没有必要存在事务机制了。正是因为做某件事务的时候,需要多条DML语句共同联合起来才能完成,所以才需要事务。
-
在事务的执行过程中,每一条DML操作都会记录到“事务性活动的日志文件”中。
2、事务的提交与回滚
-
在事务的执行过程中,可以提交事务,也可以回滚事务。
-
提交事务:
清空事务性活动的日志文件,将数据全部彻底持久化到数据库表中。
提交事务标志着事务的结束。并且是一种全部成功的结束。
-
回滚事务:
将之前所有的DML操作全部撤销,并且清空事务性活动的日志文件。
回滚事务标志着事务的结束。并且是一种全部失败的结束。
-
-
提交事务(commit)
-
mysql默认情况下是支持自动提交事务的,每执行一条语句,则提交一次事务。(不利于开发)
-
怎么将mysql的自动提交机制关闭呢?
#🔺在执行事务前,先开启事务 start transaction; -
手动提交事务:
commit; #🔺提交事务
-
-
回滚事务(rollback):回滚永远只能回滚到上一次
rollback; #🔺回滚事务回滚到start transaction之前,或commit之后,或是上条语句之后。
3、事务的隔离级别
-
事务的特性
A:原子性:说明事务是最小的工作单元,不可再分。
C:一致性:所有事务要求,在同一个事务中,所有操作必须同时成功,或者同时失败,以保证数据的一致性。
I:隔离性:A事务和B事务之间具有一定的隔离。
D:持久性:事务最终结束的一个保障。事务提交,就相当于将没有保存到硬盘上的数据保存到硬盘上。
-
事务的隔离性
-
隔离级别:
相当于A教室和B教室之间有一道墙,这道墙越厚,表示隔离级别越高。
事务与事务之间的隔离级别:
-
读未提交:read uncommitted(最低的隔离级别)【没有提交就读到了】
事务A可以读取到事务B未提交的数据。
脏读现象:事务A可以读取到事务B的脏数据。
这种隔离级别一般是理论上的,大多数的数据库隔离级别都是二档起步。
-
读已提交:read committed【提交之后才读到】
事务A只能读到事务B提交之后的数据。
缺点:不可重复读取数据。在事务A开启之后,事务B可能还有还未提交的事务正在进行中,此时第一次读到的数据就与后面读到的数据不同了,即事务A每次读取的数据不一定相等。
优点:解决了脏读现象。且这种隔离级别每次读到的数据都是真实的。
Oracle数据库默认的隔离级别:read committed
-
可重复读:repeatable read【提交之后也读不到,永远读取的都是刚开启事务时读到的数据】
事务A开启之后,不管是多久,每次在事务A中读到的数据都是一致的。即使事务B已经将数据改变,并且提交了,事务A读取到的数据还是没有发生改变。
优点:解决了不可重复读取数据。
缺点:会出现幻影读。每一次读取到的数据都是幻象,不真实。
mysql中默认的事务隔离级别:repeatable read
-
序列化/串行化:serializable(最高的隔离级别)
这种隔离级别最高,效率最低。
表示事务排队,不能并发!
每一次读到的数据都是最真实的,并且效率是最低的。
-
-
-
设置全局事务隔离级别:
set global transaction isolation level read uncommitted; #设置全局事务隔离级别,可以将read committed换成其他隔离级别 -
查看隔离级别:
select @@tx_isolation;
七、索引
-
概述
-
索引:索引是在数据库表的字段上添加的,是为了提高查询效率存在的一种机制。
一张表的一个字段可以添加一个索引,多个字段联合起来也可以添加索引。
索引相当于一本书的目录,是为了缩小扫描范围而存在的一种机制。
-
MySQL在查询方面主要有两种方式:全表扫描、根据索引检索。
-
注意:在mysql数据库中的索引也是需要排序的,并且这个索引的排序和TreeSet数据结构相同。TreeSet(TreeMap)底层是一个自平衡的二叉树(遵循左小右大原则存放,采用中序遍历方式遍历取数据)。在索引当中是一个B-Tree数据结构。(表中的字段不会动,是索引进行排序)
-
索引是各种数据库进行优化的重要手段。
-
-
索引的实现原理
-
在任何数据库上,主键上都会自动添加索引对象。
-
在mysql中,一个字段上如果有unique约束的话,也会自动创建索引对象。
-
在任何数据库中,任何一张表的任何一条记录在硬盘存储上都有一个硬盘的物理存储编号。
-
在mysql中,索引是一个单独的对象。不同的存储引擎以不同的形式存在,在MyISAM存储引擎中,索引存储在一个.MYI文件中。在InnoDB中,索引存储在一个逻辑名称叫tablespace的表中。在MEMORY存储引擎中,索引存储在内存中。不管索引存储在哪,索引在MySQL中都是以一个树的形式存在(自平衡二叉树:B-Tree)。
-
索引的实现原理:就是缩小扫描的范围,避免全表扫描。
-
什么条件下,会考虑给字段添加索引?
条件1:数据量庞大
条件2:该字段经常出现在where后面,即该字段总是被扫描
条件3:该字段很少使用DML(insert、delete、update)操作(因为使用DML后索引需要重新排序)
建议不要随意添加索引,因为索引也是要维护的,太多了反而会降低系统的性能。
建议通过主键查询,建议通过unique约束的字段进行查询,效率较高。
-
-
索引相关语法
-
创建索引:
create index 索引名 on 表名(字段名); -
删除索引:
drop index 索引名 on 表名; -
在MySQL中,查看一个SQL语句是否使用了索引进行检索:
explain 语句;
-
-
索引失效
- 失效的第一种情况:模糊匹配中以"%"开头
实例:
select * from emp where ename like '%T';以上语句,索引失效,即使有添加索引,也不会使用索引。因为模糊匹配中以"%"开头了。所以尽量避免模糊查询的时候以"%"开头。(一种优化的策略)
- 失效的第二种情况:使用or的时候其中一个字段没有索引
使用or的时候,只有or左右的两个字段都有索引,索引才不会失效。如果其中一边有一个字段没有索引,则索引失效。建议少用or。
- 失效的第三种情况:使用复合索引时没有使用左侧的列查找
使用复合索引的时候,如果没有使用左侧的列查找,索引就会失效。
-
复合索引:两个字段,或者更多的字段联合起来添加一个索引。
create index 索引名 on 表名(字段名1,字段名2);
- 失效的第四种情况:在where中索引参加了运算
实例:
select * from emp where sal+1 = 800; #索引失效- 失效的第五种情况:在where中的索引列使用了函数
实例:
select * from emp where lower(ename) = 'smith'; #索引失效... ...
-
索引的分类
单一索引:在一个字段上添加索引
复合索引:两个字段或者更多的字段上添加索引
主键索引:主键上添加索引
唯一性索引:具有unique约束的字段上添加索引(唯一性比较弱的字段上添加索引用处不大)
八、视图
-
视图(view):站在不同的角度去看待同一份数据。
-
创建视图对象:create view
create view 视图名 as DQL语句; #🔺as后面只能是DQL语句实例:
create view dept2_view as select * from dept; -
删除视图:drop view
drop view 视图名; -
注意:只有DQL语句才能以view 的形式创建。
-
视图的特点:通过对视图的增删改,会影响原表的数据。(相当于引用)
-
使用视图的时候,可以像使用table一样
-
视图的作用:
- 简化sql语句,简化开发,利于维护。(可以将复杂的sql语句以视图对象的形式新建)
九、DBA命令
-
数据的导入和导出(数据的备份)
-
数据的导入:
mysqldump 数据库名>要保存的.sql文件绝对路径 -u用户名 -p密码; #导出整个数据库 mysqldump 数据库名 表名>要保存的.sql文件绝对路径 -u用户名 -p密码; #导出数据库中指定的表以上命令在Windows的dos命令窗口中运行,不是在MySQL中运行。
-
数据的导出:
# 1、创建数据库 create database 数据库名; # 2、使用数据库 use 数据库名; # 3、初始化数据库 source .sql文件路径;以上命令在MySQL上运行。
-
十、数据库设计的三范式
* 面试常问
- 数据库设计范式:数据库表的设计依据。
1、第一范式:要求任何一张表必须有主键,每一个字段原子性不可分。(最核心、最重要的)
2、第二范式:建立在第一范式的基础之上,要求所有非主键字段完全依赖于主键,不要产生部分依赖。(数据冗余,空间浪费)
tips:多对多,三张表,关系表两个外键。
3、第三范式:建立在第二范式的基础之上,要求所有非主键字段必须直接依赖主键,不要产生传递。
tips:一对多,两张表,多的表加外键。
一对一:一对一,外键唯一。
-
数据库设计三范式是理论上的。
实践和理论有的时候是有偏差的。
最终的目的都是为了满足客户的需求,有的时候会拿冗余换执行速度。
因为在sql中,表和表之间连接次数越多,效率越低。(笛卡尔积)
而且对于开发人员来说,sql语句的编写难度也会降低。
相关文章:
2024------MySQL数据库基础知识点总结
-- 最好的选择不是最明智的,而是最勇敢的,最能体现我们真实意愿的选择。 MySQL数据库基础知识点总结 一、概念 数据库:DataBase,简称DB。按照一定格式存储数据的一些文件的组合顾名思义: 存储数据的仓库,实际上就是一…...
机器学习之基于Jupyter中国环境治理投资数据分析及可视化
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。 文章目录 一项目简介 二、功能三、系统四. 总结 一项目简介 机器学习之基于Jupyter中国环境治理投资数据分析及可视化项目是一个结合了机器学习和数据可视化技术的项目…...
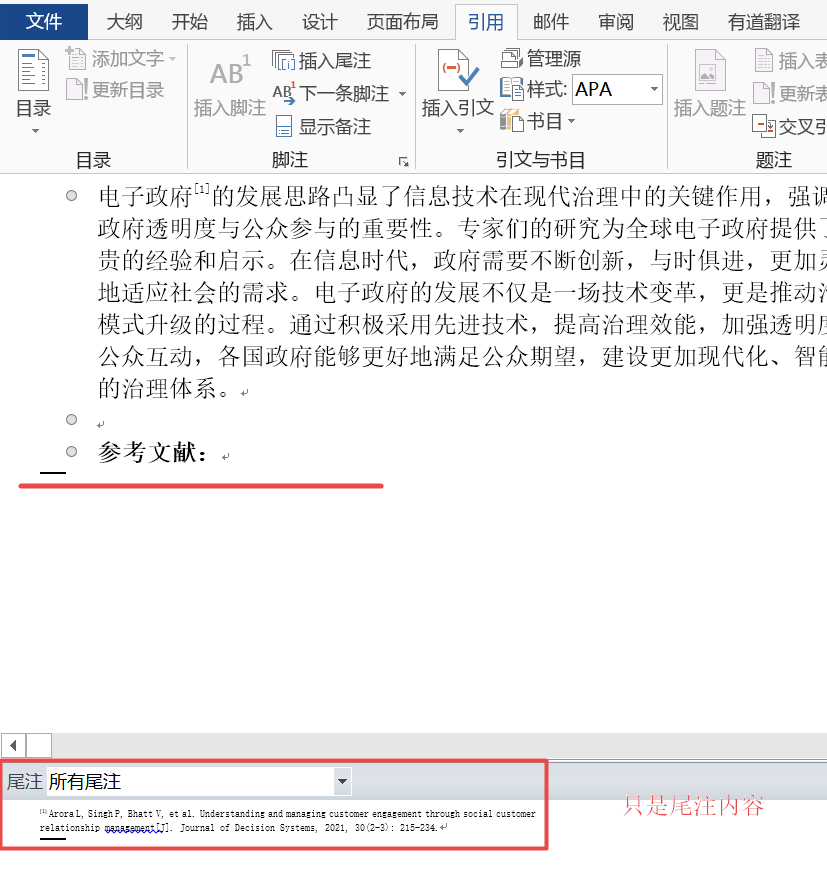
【Word】写论文,参考文献涉及的上标、尾注、脚注 怎么用
一、功能位置 二、脚注和尾注区别 1.首先脚注是一个汉语词汇,论文脚注就是附在论文页面的最底端,对某些内容加以说明,印在书页下端的注文。脚注和尾注是对文本的补充说明。 2.其次脚注一般位于页面的底部,可以作为文档某处内容的…...
能将图片转为WebP格式的WebP Server Go
本文完成于 2023 年 11 月 之前老苏介绍过 webp2jpg-online,可以将 webp 格式的图片,转为 jpg 等,今天介绍的 WebP Server Go 是将 jpg 等转为 webp 格式 文章传送门:多功能图片转换器webp2jpg-online 什么是 WebP ? WebP 它是由…...

省份数量00
题目链接 省份数量 题目描述 注意点 1 < n < 200isConnected[i][j] 为 1 或 0isConnected[i][i] 1isConnected[i][j] isConnected[j][i] 解答思路 最初想到的是广度优先遍历,当某个城市不属于省份,需要从该城市开始,根据isConne…...

Android Native内存泄漏检测方案详解
文章目录 1. AddressSanitizer (ASan)2. LeakSanitizer (LSan)3. Valgrind4. 手动检测5. 实践建议6. 总结 在Android Native层开发过程中,内存泄漏是一个常见的问题。内存泄漏不仅会导致应用程序占用越来越多的内存,还可能引发性能问题和崩溃。因此&…...

有限单元法-编程与软件应用(崔济东、沈雪龙)【PDF下载】
专栏导读 作者简介:工学博士,高级工程师,专注于工业软件算法研究本文已收录于专栏:《有限元编程从入门到精通》本专栏旨在提供 1.以案例的形式讲解各类有限元问题的程序实现,并提供所有案例完整源码;2.单元…...

蓝桥杯练习系统(算法训练)ALGO-950 逆序数奇偶
资源限制 内存限制:256.0MB C/C时间限制:1.0s Java时间限制:3.0s Python时间限制:5.0s 问题描述 老虎moreD是一个勤于思考的青年,线性代数行列式时,其定义中提到了逆序数这一概念。不过众所周知我们…...

uniapp踩坑 uni.showToast 和 uni.showLoading
uniapp踩坑 uni.showToast 和 uni.showLoading 一、问题描述 uni.showLoading 和 uni.showToast 混合使用时,showLoading和showToast会相互覆盖对方,调用hideLoading时也会将toast内容进行隐藏。 二、触发条件 1.uniapp中使用自己封装的axois&#x…...
BIGRU、CNN-BIGRU、CNN-BIGRU-ATTENTION、TCN-BIGRU、TCN-BIGRU-ATTENTION合集
(BIGRU、CNN-BIGRU、CNN-BIGRU-ATTENTION、TCN-BIGRU、TCN-BIGRU-ATTENTION)时,我们可以从它们的基本结构、工作原理、应用场景以及优缺点等方面进行详细介绍和分析。 BIGRU、CNN-BIGRU、CNN-BIGRU-ATTENTION、TCN-BIGRU等(matlab…...
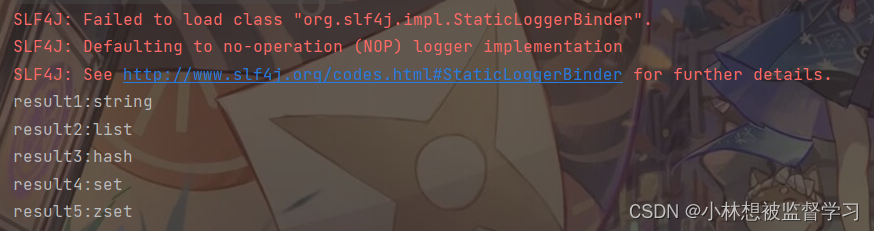
通过 Java 操作 redis -- 基本通用命令
目录 使用 String 类型的 get 和 set 方法 使用通用命令 exists ,del 使用通用命令 keys 使用通用命令 expire,ttl 使用通用命令 type 要想通过 Java 操作 redis,首先要连接上 redis 服务器,推荐看通过 Java 操作 redis -- 连接 redis 关…...
Jenkins集成Kubernetes 部署springboot项目
文章目录 准备部署的yml文件Harbor私服配置测试使用效果Jenkins远程调用参考文章 准备部署的yml文件 apiVersion: apps/v1 kind: Deployment metadata:namespace: testname: pipelinelabels:app: pipeline spec:replicas: 2selector:matchLabels:app: pipelinetemplate:metada…...

个股期权是什么期权?个股期权什么时候推出?
今天期权懂带你了解个股期权是什么期权?个股期权什么时候推出?期权也称选择权,是指期权的买方有权在约定的期限内,按照事先确定的价格,买入或卖出一定数量某种特定商品或金融指标的权利。 个股期权是什么期权ÿ…...

TCP UDP
传输层 端口号 tcp udp 网络层 IP地址 IP TCP,UDP 1,TCP是面向链接的协议,而UDP是无连接的协议; 2,TCP协议的传输是可靠的,而UDP协议的传输“尽力而为” 3,TCP可以实现流控,但UDP不行;…...
PCIE协议-1
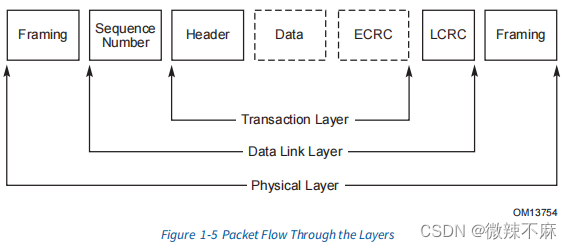
1. PCIe结构拓扑 一个结构由点对点的链路组成,这些链路将一组组件互相连接 - 图1-2展示了一个结构拓扑示例。该图展示了一个称为层级结构的单一结构实例,由一个根复合体(Root Complex, RC)、多个端点(I/O设备…...

[C++][PCL]pcl安装包预编译包国内源下载地址
版本名称下载地址PCL-1.14.1-AllInOne-msvc2022-win64含pdb.zip点我下载PCL-1.14.0-AllInOne-msvc2022-win64含pdb.zip点我下载PCL-1.13.1-AllInOne-msvc2022-win64含pdb.zip点我下载PCL-1.13.0-AllInOne-msvc2022-win64含pdb.zip点我下载PCL-1.12.1-AllInOne-msvc2019-win64含…...

海洋行业工业气体检测传感器的重要性
海洋行业是一个广阔而复杂的领域,涉及多个分支和应用,包括浮式生产、储存和卸载(FPSO)装置、渡轮和潜艇等。这些船舶和设施在执行任务时,都可能遇到各种潜在的气体危害。因此,对于海洋行业来说,…...

免费在线录屏、无需注册、免费可用、无限制
免费在线工具 https://orcc.online/ 在线录屏 https://orcc.online/recorder pdf在线免费转word文档 https://orcc.online/pdf 时间戳转换 https://orcc.online/timestamp Base64 编码解码 https://orcc.online/base64 URL 编码解码 https://orcc.online/url Hash(MD5/SHA…...
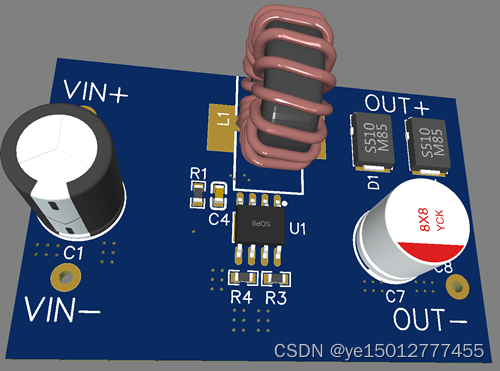
5V升9V2A升压恒压WT3231
5V升9V2A升压恒压WT3231 WT3231,一款性能卓越的DC-DC转换器,采用了集成10A、26mΩ功率的MOSFET电源开关转换器。它能够输出高达12V的电压,稳定可靠。这款产品以固定的600KHz运行,因此可以使用小型的外部感应器和电容器࿰…...

Java中枚举类的使用详解
Java中枚举类的使用详解 在Java编程中,枚举(Enum)是一种特殊的类,用于表示固定数量的常量。与常量相比,枚举类型具有类型安全、可读性强和易于管理的优点。下面我们将详细讲解Java中枚举类的使用,并通过示…...
)
告别手动传图!用PicGo+Gitee给Typora配个自动图床(保姆级配置+避坑清单)
打造无缝Markdown写作体验:自动化图床配置全攻略 在技术写作和知识管理的世界里,Markdown已经成为事实上的标准格式。然而,一个长期困扰写作者的问题始终存在——图片管理。传统方式需要手动上传图片到图床,复制链接,再…...

别再盯人内耗!避开误区,找准员工自主管理核心
很多车间管理者都深陷盯人式管理的内耗:每天耗在车间现场,时刻盯着员工操作、催进度、查规范,忙得焦头烂额、身心俱疲,可车间管理依然不尽如人意——员工被动应付、消极怠工,操作不规范、物料乱堆放、隐患不排查&#…...

福特押注五款新车型,含电动车与Bronco,欲重振欧洲市场
福特计划未来三年内在欧洲推出五款全新乘用车,以重振其在欧洲市场日渐式微的品牌形象。这一"福特欧洲乘用车新纪元"计划涵盖一款全新的多能源Bronco SUV、一款小型纯电掀背车、一款纯电SUV,以及两款多能源跨界SUV,所有车型均专为欧…...
)
2026年唯一通过广电AIGC内容安全认证的3款视频生成工具(附检测报告编号+审核链路图解)
更多请点击: https://kaifayun.com 第一章:2026年AI视频生成工具排行榜 2026年,AI视频生成技术已迈入“语义帧精控”与“跨模态时序对齐”新阶段。主流工具普遍支持 毫秒级动作锚点标注、 物理引擎协同渲染及 多镜头逻辑自动剪辑,…...
用C++实现信奥题 P8929 「TERRA-OI R1」别得意,小子)
打卡信奥刷题(3286)用C++实现信奥题 P8929 「TERRA-OI R1」别得意,小子
P8929 「TERRA-OI R1」别得意,小子 题目背景 战至中途,蓝紫色天空瞬间变为黑压压一片,噬神者身上一些紫色外壳开始脱落,化为更小的蟒蛇,这些小家伙从出现开始便不要命的向你冲过来,刚清理掉这些小家伙&…...
)
仅限内部团队使用的Perplexity行业扫描协议(附可复用Prompt模板库+信源可信度评分表v2.3)
更多请点击: https://codechina.net 第一章:Perplexity行业扫描协议的定位与适用边界 Perplexity行业扫描协议(Perplexity Industry Scanning Protocol,简称PISP)并非通用型AI评估框架,而是一套面向垂直领…...

别再死记硬背了!用Pointer Network让AI学会‘抄作业’,搞定文本摘要和对话生成
别再死记硬背了!用Pointer Network让AI学会‘抄作业’,搞定文本摘要和对话生成 想象一下,当你面对一篇冗长的技术文档时,最有效的学习方法是什么?不是逐字背诵,而是用荧光笔划出关键概念——这正是Pointer …...
:解决合并冲突,处理“代码打架”)
分支管理(二):解决合并冲突,处理“代码打架”
1. 问题场景 你已经学会了创建分支和合并分支。在上一篇文章里,合并过程顺滑得像切黄油——Git 自动完成了所有工作。但真实世界里,你和一个同事可能同时修改了同一个文件的同一处代码。当你试图把两个分支合并在一起时,Git 会停下来…...

慢时钟域到快时钟域控制信号传递:原理、方案与实战
1. 控制信号跨时钟域传递:一个资深工程师的实战拆解在数字电路设计里,尤其是涉及多时钟域的复杂系统,比如SoC、高速接口或者异构计算单元,控制信号的跨时钟域传递(CDC, Clock Domain Crossing)绝…...

RAG夺命10连问,你能抗住第几问?
前言最近金三银四,很多小伙伴在准备大厂面试,几乎每个人都被问到了同一个技术点——RAG(检索增强生成)。从阿里到字节,从腾讯到美团,RAG已经成为大模型应用方向必考的“压轴题”。但是,很多求职…...