如何使用Tushare+ Backtrader进行股票量化策略回测

数量技术宅团队在CSDN学院推出了量化投资系列课程
欢迎有兴趣系统学习量化投资的同学,点击下方链接报名:
量化投资速成营(入门课程)
Python股票量化投资
Python期货量化投资
Python数字货币量化投资
C++语言CTP期货交易系统开发
数字货币JavaScript语言量化交易系统开发
典型股票量化回测流程
典型的股票量化策略回测流程包括以下几个步骤:
-
数据获取:首先需要获取所需的股票市场数据,包括股票价格、交易量、财务数据等。这些数据可以从金融数据供应商、交易所、财经网站或者专门的数据提供商处获取。
-
数据预处理:对获取到的数据进行预处理和清洗,以确保数据的质量和一致性。这包括去除异常值、处理缺失数据、调整股票价格(如复权处理)等。
-
策略开发:根据具体的量化策略目标,设计和开发相应的交易策略。这可能涉及技术指标的计算、信号生成规则的制定、风险管理规则的定义等。
-
回测执行:使用历史数据执行所开发的策略。按照时间顺序,逐个周期模拟交易决策,并记录每次交易的执行价格、成交量、手续费等信息。
-
绩效评估:根据回测结果评估策略的绩效表现。常见的评估指标包括累计收益、年化收益率、最大回撤、夏普比率等。此外,还可以进行风险敞口、交易频率等方面的分析。
如何使用Tushare获取股票数据
上述流程中,1、2我们可以使用Tushare配合Pandas库来进行,而3、4、5步骤可以使用Backtrader库来完成。接下来,我们就来介绍Tushare和Backtrader在量化回测中的使用。
Tushare是一个基于Python语言的开源金融数据接口包,提供了丰富的股票、期货、基金等金融数据获取功能。Tushare为金融从业者和开发者提供了方便快捷的数据获取和处理工具,帮助他们进行金融数据分析和量化策略开发。
要安装和使用Tushare,我们需要按照以下步骤进行操作:
1. 安装Python:首先,确保你的计算机上已经安装了Python。Tushare支持Python 3.x版本。
2. 安装Tushare包:打开命令行终端(Windows用户可以使用命令提示符或PowerShell),输入以下命令安装Tushare包:
pip install tushare这将自动从Python包索引(PyPI)下载并安装Tushare包及其依赖项。
3. 获取Tushare的Token:在使用Tushare之前,你需要在Tushare官网(https://tushare.pro)注册一个账号,并获取API令牌(Token)。登录后,在用户中心页面可以找到你的Token。
4. 使用Tushare:在Python中引入Tushare包,并使用你的Token进行初始化。以下是一个简单的示例代码:
import tushare as ts# 初始化Tushare,替换YOUR_TOKEN为你的Token
ts.set_token('YOUR_TOKEN')# 创建Tushare接口对象
pro = ts.pro_api()# 调用Tushare接口函数,获取股票行情数据
data = pro.daily(ts_code='000001.SZ', start_date='20220101', end_date='20220131')# 打印获取的数据
print(data)在上面的示例中,首先使用set_token函数设置你的Token,然后使用pro_api函数创建Tushare接口对象。接下来,可以使用各种Tushare接口函数(如daily)获取不同类型的金融数据。
请根据Tushare的文档(https://tushare.pro/document/2)和API参考(https://tushare.pro/document/1)查看更多的接口函数和详细用法。
需要注意,上述示例中的Tushare Pro的接口需要付费订阅才能访问高级数据。如果你想省去注册和付费的麻烦,而且只取有限的简单数据做个尝试,可以使用Tushare的免费接口。免费接口的示例代码更简单
import tushare as ts
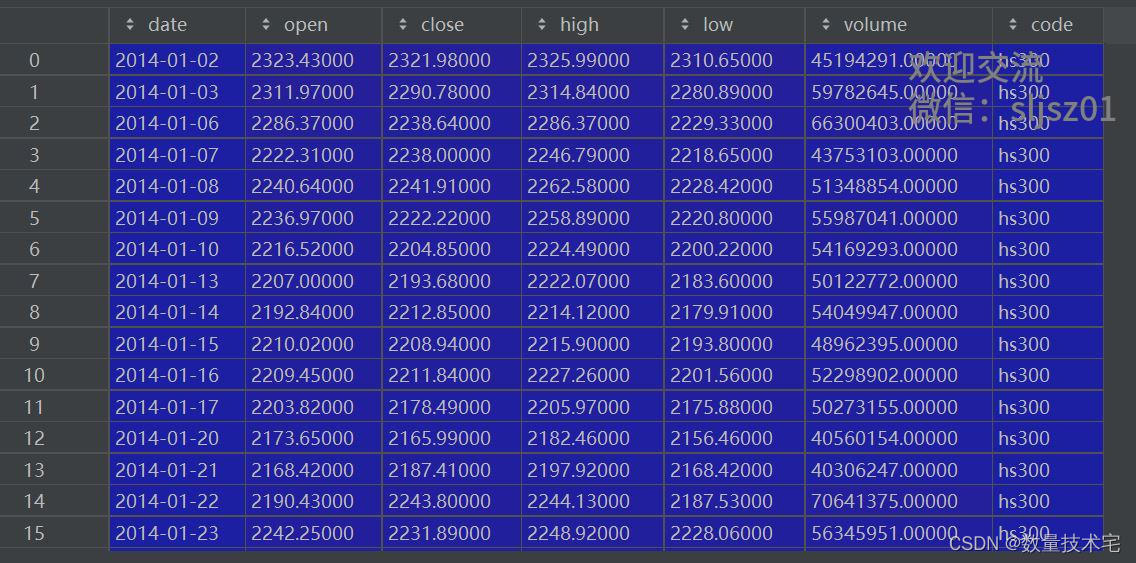
# 获取沪深300指数从2014年1月1日到最新的行情数据
hs300 = ts.get_k_data('hs300', start='2014-01-01')由此,我们就获取到了免费版本的沪深300指数从2014年1月1日到最新的日K线数据:
如何对数据进行可视化
在获取到沪深300的历史K线数据后,我们如果想初步计算一些技术指标,并把技术指标和历史行情展现出来,给我们下一步进行策略开发提供一些思路,应该如何实现?
对于数据可视化,有两种实现方式,一种是采用Python自带的plt库,另一种是专门处理显示K线数据的三方库:mplfinance。我们先来看第一种实现方式:
首先我们定义一个RSI函数,并输入刚才获取到的沪深300指数数据,然后,再调用plt库的相关方法,将RSI指标和历史价格,共同显示在一张图上。
# 将RSI值添加到hs300数据中
hs300['RSI'] = RSI(hs300)# 画图
plt.figure(figsize=(12,6))
plt.plot(hs300['date'], hs300['close'], label='Close') # 画出收盘价曲线
plt.legend(loc='upper left')
plt.twinx()
plt.plot(hs300['date'], hs300['RSI'], 'r', label='RSI') # 画出RSI曲线
plt.legend(loc='upper right')
plt.show()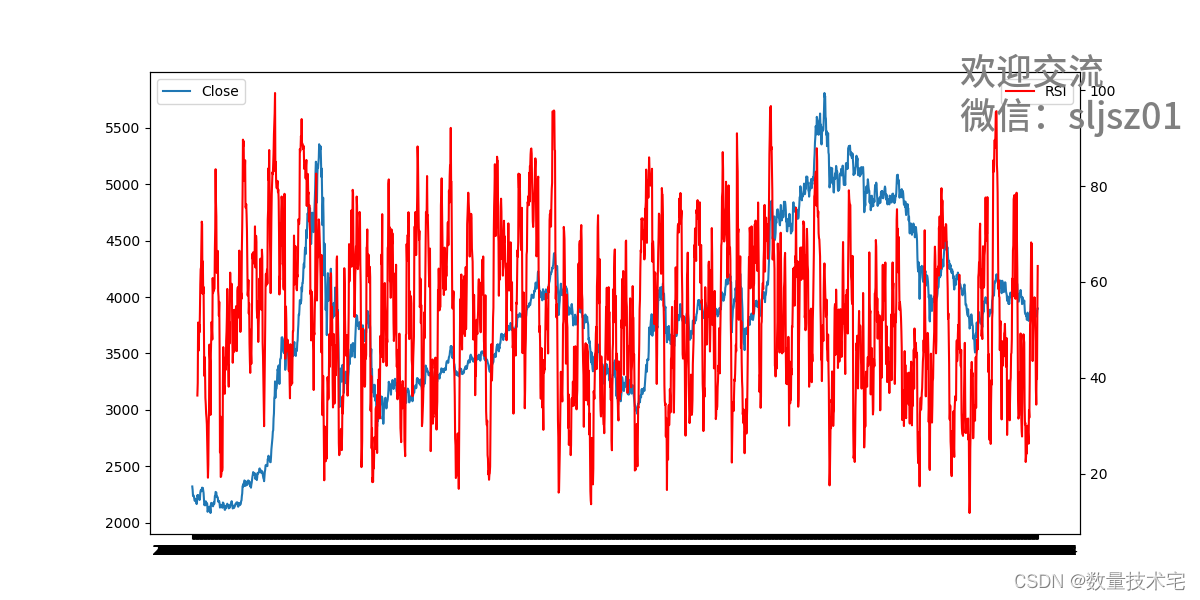
另一种方式,我们也可以使用mplfinance库,绘制出获取到沪深300的历史K线数据的K线量价图。这里,我们留下同时绘制RSI指标的问题,给读者思考和练习。
import mplfinance as mpfhs300 = hs300.set_index('date')
hs300.index = pd.to_datetime(hs300.index)
mpf.plot(hs300, type='candle', volume=True, mav=(5,10,20), figratio=(12,6), title='HS300 Candlestick Chart')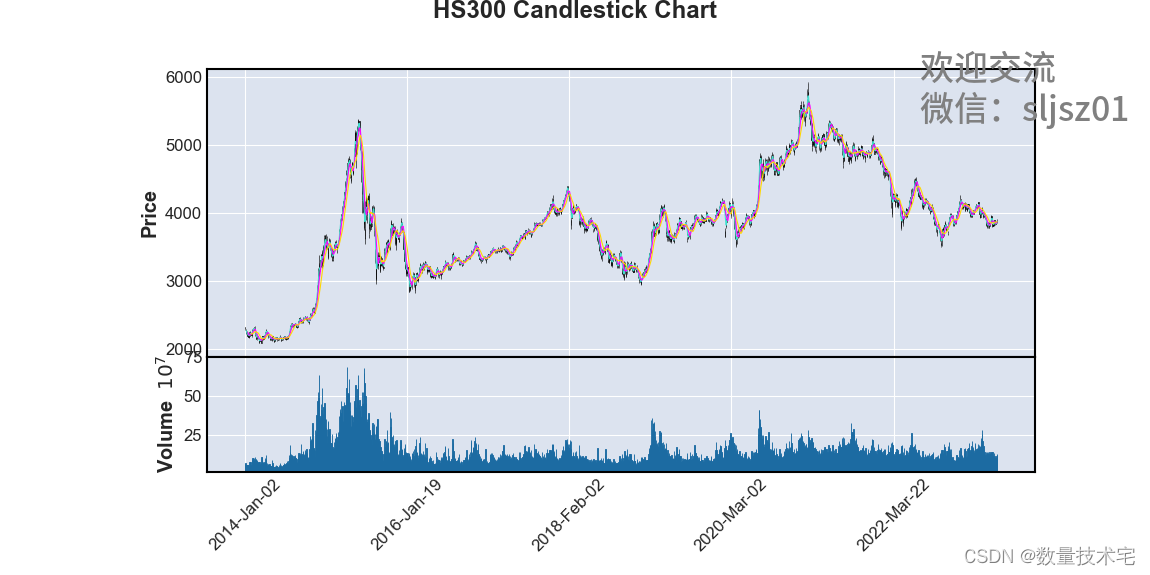
如何使用BackTrader进行回测
Backtrader是一个功能强大的Python量化交易框架,用于开发、回测和执行交易策略。它提供了广泛的功能和工具,使得量化交易策略的开发和测试变得更加简单和高效。
Backtrader的一些主要特点和功能:
-
灵活的策略开发:Backtrader提供了简洁而灵活的API,使得策略的开发变得方便。你可以通过继承和扩展Backtrader的基础类来创建自定义的交易策略,并在其中定义买入、卖出信号和风险管理规则等。
-
多种交易工具支持:Backtrader支持多种交易工具,包括股票、期货、外汇等。你可以使用Backtrader来开发各种市场的交易策略。
-
多样化的交易指标和分析工具:Backtrader内置了大量的交易指标和分析工具,如移动平均线、布林带、相对强弱指标(RSI)、夏普比率等。这些工具可以帮助你分析市场趋势、计算策略绩效等。
-
灵活的数据回测:Backtrader提供了丰富的回测功能,可以使用历史数据对策略进行测试和优化。你可以使用不同的时间周期和数据频率进行回测,模拟真实的交易环境。同时,Backtrader还支持多线程回测,加快回测速度。
具体到Backtrader的使用,我们还是以获取到的沪深300指数历史数据、和RSI指标一起,构建量化策略的回测。首先,需要做的是把获取到的K线数据,转换成Backtrader的回测数据格式。
# Get data from tushare
df = ts.get_k_data('hs300', start='2014-01-01')
df['date'] = pd.to_datetime(df['date']) # 将日期转换为datetime格式
df = df.set_index('date', drop=True) # 将日期设置为索引
data = bt.feeds.PandasData(dataname=df, datetime=None,open=0, high=1, low=2, close=3, volume=4, openinterest=-1) # 创建数据源第二步,我们构建一个RSI策略的回测函数,在这个回测函数中,我们先计算RSI指标14周期的数值,并以RSI<30作为买入信号,RSI>70作为卖出信号。
# Define the strategy
class RSI(bt.Strategy):params = (('rsi_period', 14),)def __init__(self):self.rsi = bt.indicators.RSI(period=self.params.rsi_period)def next(self):if not self.position:if self.rsi < 30:self.buy(size=1)else:if self.rsi > 70:self.sell(size=1)第三步,调用BackTrader库相关方法,添加回测数据、设置初始资金和手续费、输出初始资金,运行策略,后输出最终资金并绘制图表。
cerebro = bt.Cerebro()
cerebro.adddata(data) # 添加数据源
cerebro.addstrategy(RSI)
cerebro.broker.setcash(1000000.0) # 设置初始资金
cerebro.broker.setcommission(commission=0.001) # 设置佣金
print('Starting Portfolio Value: %.2f' % cerebro.broker.getvalue()) # 输出初始资金
cerebro.run() # 运行策略
print('Final Portfolio Value: %.2f' % cerebro.broker.getvalue()) # 输出最终资金
cerebro.plot() # 绘制图表通过上述三步,我们就完成了数据BackTrader格式的预处理、构建策略信号逻辑函数、以及运行BackTrader回测和展示回测结果,一起来看BackTrader展示的回测结果吧。
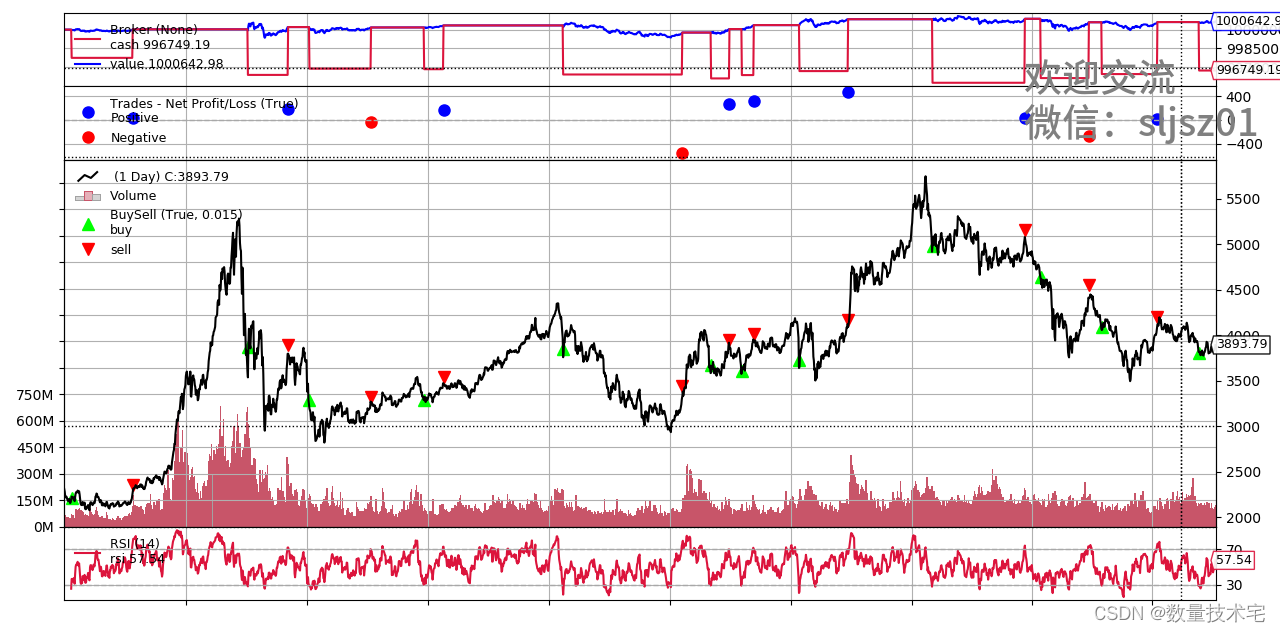
可以看到,BackTrader所展示的回测结果很丰富,包括了历史量价和RSI指标的展示、买卖点的标记、资金曲线、回撤线以及NetValue的数值。
综上,我们就完成了从数据获取、到数据可视化、再到策略回测的整个构建过程,感兴趣的朋友,可以把示例中Tushare获取的数据替换成其他标的历史数据,也可也修改RSI策略模块逻辑,构建自己的量化交易策略。总之,本文提供的是一个通用的回测框架,更多的玩法留给我们的读者。
相关文章:
如何使用Tushare+ Backtrader进行股票量化策略回测
数量技术宅团队在CSDN学院推出了量化投资系列课程 欢迎有兴趣系统学习量化投资的同学,点击下方链接报名: 量化投资速成营(入门课程) Python股票量化投资 Python期货量化投资 Python数字货币量化投资 C语言CTP期货交易系统开…...

Guid转换为字符串
在理想情况下,任何计算机和计算机集群都不会生成两个相同的GUID。GUID 的总数达到了2128(3.41038)个,所以随机生成两个相同GUID的可能性非常小,但并不为0。GUID一词有时也专指微软对UUID标准的实现。 (1). GUID&#…...

OpenAI的搜索引擎要来了!
最近的报道和业界泄露信息显示,OpenAI正秘密研发一款新的搜索引擎,可能叫SearchGPT或Sonic,目标是挑战Google的搜索霸权。预计这款搜索引擎可能在5月9日即将到来的活动中正式亮相。 SearchGPT的蛛丝马迹 尽管OpenAI对SearchGPT尚未表态&…...

PaddlePaddle与OpenMMLab
产品全景_飞桨产品-飞桨PaddlePaddle OpenMMLab算法应用平台...

HBuilderX uniapp+vue3+vite axios封装
uniapp 封装axios 注:axios必须低于0.26.0,重中之重 重点:封装axios的适配器adapter 1.安装axios npm install axios0.26.0创建api文件夹 2.新建adapter.js文件 import settle from "axios/lib/core/settle" import buildURL…...
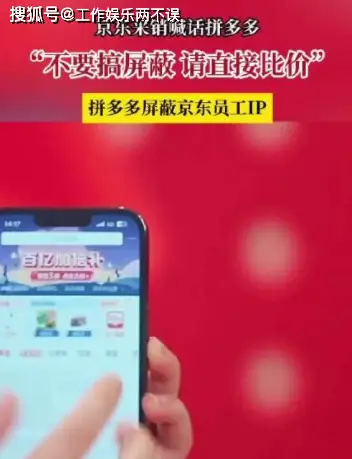
【网络安全产品】---应用防火墙(WAF)
what Web应用防火墙(Web Application Firewall) WAF可对网站或者App的业务流量进行恶意特征识别及防护,在对流量清洗和过滤后,将正常、安全的流量返回给服务器,避免网站服务器被恶意入侵导致性能异常等问题,从而保障…...
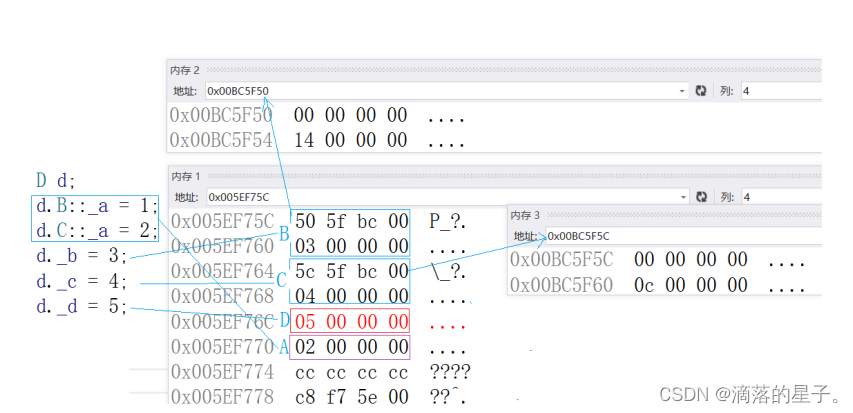
C++学习第十二天(继承)
1、继承的概念以及定义 继承的概念 继承机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保持原有类特性的基础上进行拓展,增加功能,这样产生新的类,称派生类。继承呈现了面向对象程序设计的层次结构&#x…...

WPF DataGrid绑定后端 在AutoGeneratingColumn事件中改变列名
public void OnAutoGeneratingColumn(DataGridAutoGeneratingColumnEventArgs e){var propertyDescriptor (PropertyDescriptor)e.PropertyDescriptor;if (propertyDescriptor.IsBrowsable){e.Column.Header propertyDescriptor.DisplayName;}else{e.Cancel true;}}实体类中…...

2024 CorelDraw最新图形设计软件 激活安装教程来了
2024年3月,备受瞩目的矢量制图及设计软件——CorelDRAW Graphics Suite 2024 正式面向全球发布。这一重大更新不仅是 CorelDRAW 在 36 年创意服务历史中的又一重要里程碑,同时也展现了其在设计软件领域不断创新和卓越性能的领导地位。 链接: https://pan…...

双网口扩展IO支持8DO输出
M320E以太网远程I/O数据采集模块是一款工业级、隔离设计、高可靠性、高稳定性和高精度数据采集模块,嵌入式32位高性能微处理器MCU,集成2路工业10/100M自适应以太网模块里面。提供多种I/O,支持标准Modbus TCP,可集成到SCADA、OPC服…...
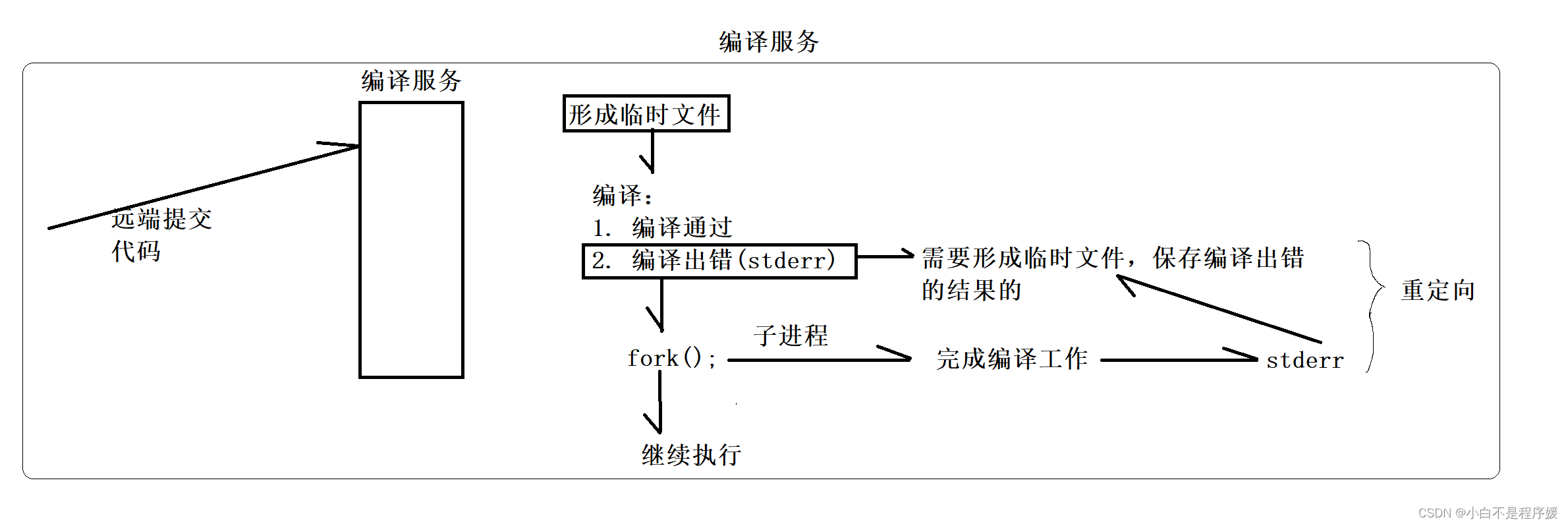
【负载均衡在线OJ项目日记】编译与日志功能开发
目录 日志功能开发 常见的日志等级 日志功能代码 编译功能开发 创建子进程和程序替换 重定向 编译功能代码 日志功能开发 日志在软件开发和运维中起着至关重要的作用,目前我们不谈运维只谈软件开发;日志最大的作用就是用于故障排查和调试&#x…...
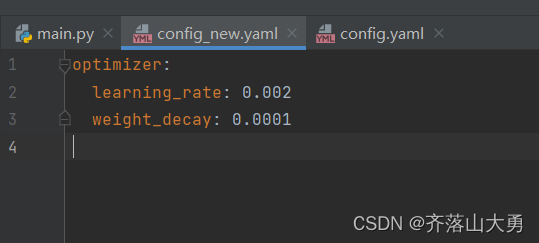
yaml配置文件的在深度学习中的简单应用
1 .创作灵感 小伙伴们再阅读深度学习模型的代码的时候,经常会遇到yaml格式的配置文件。用这个配置文件是因为我们在训练模型的时候会涉及很多的参数,如果这些参数东一个,西一个,我们调起来的时候就会很不方便,所以用y…...

spring boot 核心配置文件是什么?
Spring Boot 的核心配置文件主要是 application.properties 或 application.yml(也称为 YAML 格式)。这两个文件通常位于项目的 src/main/resources 目录下,用于配置 Spring Boot 应用程序的各种属性和设置。 application.properties…...

Python的奇妙之旅——回顾其历史
我们这个神奇的宇宙里,有一个名叫Python的小家伙,它不仅聪明,而且充满活力。它一路走来,从一个小小的编程语言成长为如今全球最受欢迎的编程语言之一。今天,我们就来回顾一下Python的历史,看看它如何从一个…...

Flink面试整理-Flink的性能优化策略
Apache Flink 的性能优化是一个多方面的任务,涉及硬件资源、算法选择、配置调整等多个层面。以下是一些常见的 Flink 性能优化策略: 1. 资源分配和管理 合理配置 TaskManager 和 JobManager:根据作业的需求和可用资源,合理分配内存和 CPU 给 TaskManager 和 JobManager。适…...

SpringBoot与SpringMVC的区别
SpringBoot与SpringMVC的区别是什么? SpringBoot和SpringMVC是Java开发中常用的两个框架,它们都是由Spring框架所提供的,但在功能和使用方式上有着一些区别。本文将分别介绍SpringBoot和SpringMVC的特点和区别。 一、SpringBoot的特点&#…...

漏洞挖掘之某厂商OAuth2.0认证缺陷
0x00 前言 文章中的项目地址统一修改为: a.test.com 保护厂商也保护自己 0x01 OAuth2.0 经常出现的地方 1:网站登录处 2:社交帐号绑定处 0x02 某厂商绑定微博请求包 0x02.1 请求包1: Request: GET https://www.a.test.com/users/auth/weibo?…...
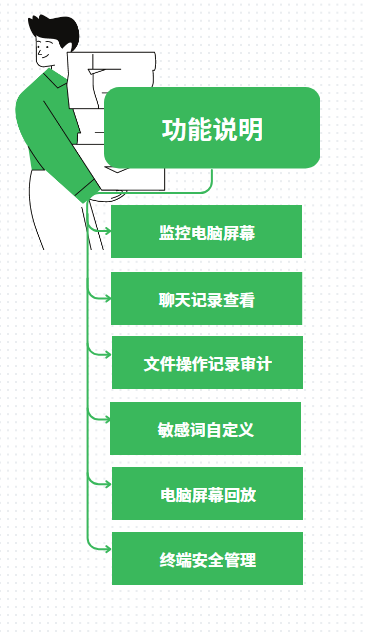
电脑屏幕监控软件都有哪些 | 五大好用屏幕监控软件盘点
电脑屏幕监控软件在企业管理、家庭教育等方面发挥着越来越重要的作用。 这些软件通过实时监控电脑屏幕活动,为用户提供了强大的管理和监控功能。 本文将为您盘点五大好用的电脑屏幕监控软件,帮助您更好地了解并选择适合自己的软件。 电脑屏幕监控软件都…...

数据结构-线性表-链表-2.3-2
在带头节点的单链表L中,删除所有值为x的结点,并释放其空间,假设值为x的结点不唯一, 是编写算法实现上述操作。 双指针,用p从头至尾扫描单链表,pre指向*p结点的前驱,若p所指结点的值为x&#x…...
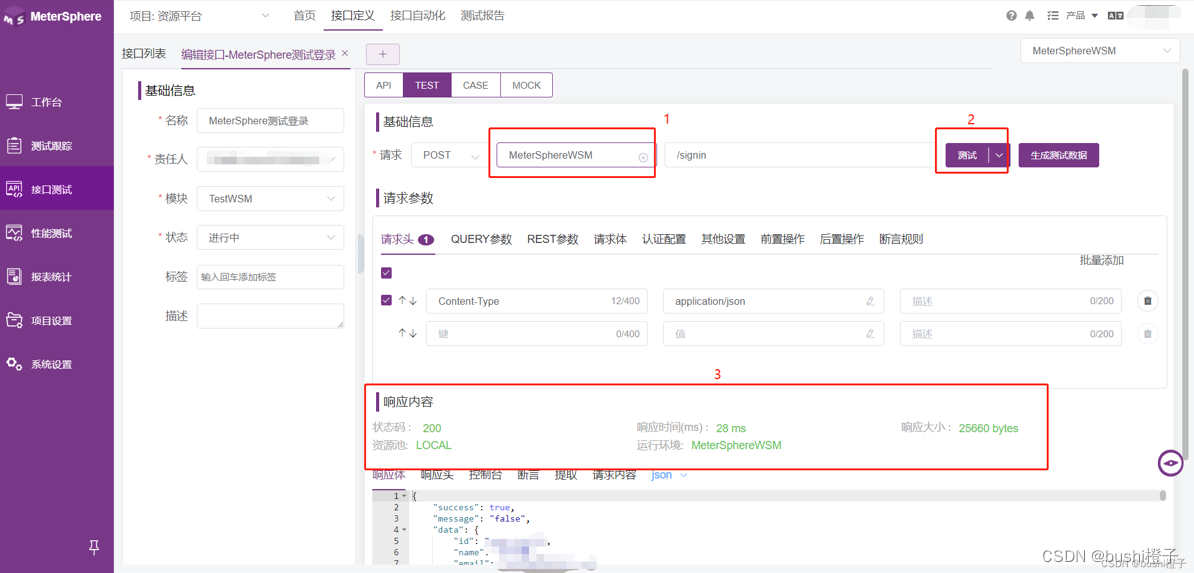
【自动化测试】使用MeterSphere进行接口测试
一、接口介绍二、接口测试的过程三、接口自动化测试执行自动化流程 四、接口之间的协议HTTP协议 五、 接口测试用例设计接口文档 六、使用MeterSphere创建接口测试创建接口定义设计接口测试用例 一、接口介绍 自动化测试按对象分为:单元测试、接口测试、UI测试等。…...

DNS 泄露是什么?为什么网络环境检测时要看 DNS
很多人在检查网络环境时,第一反应通常是看 IP。比如 IP 显示在哪个地区、运营商是谁、是不是数据中心网络。 但实际上,除了 IP 之外,DNS 也是一个很容易被忽略的关键指标。如果 DNS 查询结果和当前网络出口不一致,就可能出现所谓的…...

Linux文本管道效率稳定性治理方法
Linux文本管道效率稳定性治理方法这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在文本管道效率,重点讨论管道组合、文本过滤和执行开销。在真实生产环境中,文本管道效率相关问题往往不会以单一错误形式出现,而是混杂在日志、…...

STM32驱动WS2812灯珠颜色错乱?可能是你的GRB顺序和位序搞反了!
STM32驱动WS2812灯珠颜色错乱?GRB顺序与位序的深度解析 当你第一次用STM32成功点亮WS2812灯珠时,那种成就感难以言表。但紧接着,你可能遇到了一个令人困惑的问题:明明在代码里设置了纯红色(255, 0, 0)&…...

京东滑块验证码JS逆向实战:从接口分析到轨迹加密
1. 京东滑块验证码逆向分析入门 第一次接触京东滑块验证码逆向时,我也被那一堆加密参数搞得头晕眼花。但经过多次实战后,我发现只要掌握几个关键点,就能轻松破解这个看似复杂的验证系统。滑块验证码的核心逻辑其实很简单:系统通过…...

数组指针VS指针数组
【C语言】指针数组 VS 数组指针 原来这么简单! - 知乎 数组的名字就是数组首元素的指针。 判断指针类型指针口诀:先右后左,由近及远,括号优先。(从变量名看起) 指针数组: int *p[5] &…...
:谷歌AI团队内部培训手册泄露版)
NotebookLM具身智能落地实战(从零部署到ROS2集成):谷歌AI团队内部培训手册泄露版
更多请点击: https://intelliparadigm.com 第一章:NotebookLM具身智能研究 NotebookLM 是 Google 推出的基于用户自有文档进行语义理解与推理的 AI 助手,其核心能力在于“文档感知”(document-grounded reasoning)。当…...
RV1126B TF卡电路)
瑞芯微(EASY EAI)RV1126B TF卡电路
1. TF卡电路RV1126B核心板集成了1个SDMMC控制器和1个SDIO控制器,均可支持SDIO3.0协议,以及MMC V4.51协议。4线的数据总线宽度支持SDR104模式,速率达到200MHz。SDMMC控制器是由PMIC单独供电,可以动态的在1.8V和3.3V之间调节&#x…...

告别预编译包!手把手教你为Qt6项目定制编译OpenCV,解锁WITH_QT支持
告别预编译包!手把手教你为Qt6项目定制编译OpenCV,解锁WITH_QT支持 在计算机视觉开发领域,OpenCV无疑是使用最广泛的库之一。然而,许多开发者可能没有意识到,直接从官网下载的预编译版本OpenCV可能无法充分发挥其与Qt框…...

虚幻引擎网络协议逆向分析:从抓包到安全加固的工程实践
1. 项目概述与核心价值最近在游戏开发圈里,特别是那些深耕UE(Unreal Engine,虚幻引擎)网络同步和反外挂的同行们,可能都听说过或者正在研究一个叫venetianglassmaking858/UnrealClientProtocol的项目。这个名字听起来有…...

LM265 手持式频谱分析仪:交通超宽频监测旗舰
LM265 手持式频谱分析仪是成都鼎讯信通科技打造的超宽频高性能便携设备,覆盖 9kHz~26.5GHz,射频指标对标台式仪器,兼顾便携与精度,为铁路、高速等交通领域提供全频段信号监测与干扰排查能力。设备集成频谱分析、场强测量、信道扫描…...